
Abstract
In meteorology, ensemble forecasting aims to post-process an ensemble of multiple members’ forecasts and make better weather predictions. While multiple individual forecasts are generated to represent the uncertain weather system, the performance of ensemble forecasting is unsatisfactory. In this paper we conduct data analysis based on the expertise of human forecasters and introduce a machine learning method for ensemble forecasting. The proposed method, Label Distribution Learning with Climate Probability (LDLCP), can improve the accuracy of both deterministic forecasting and probabilistic forecasting. The LDLCP method utilizes the relevant variables of previous forecasts to construct the feature matrix and applies label distribution learning (LDL) to adjust the probability distribution of ensemble forecast. Our proposal is novel in its specialized target function and appropriate conditional probability function for the ensemble forecasting task, which can optimize the forecasts to be consistent with local climate. Experimental testing is performed on both artificial data and the data set for ensemble forecasting of precipitation in East China from August to November, 2017. Experimental results show that, compared with a baseline method and two state-of-the-art machine learning methods, LDLCP shows significantly better performance on measures of RMSE and average continuous ranked probability score.
Introduction
Ensemble forecasting for modeling nonlinear dynamic weather system has become increasingly critical to meteorology [31]. The ensemble members derived from Numerical Weather Prediction (NWP) are generated with various model physics and perturbed input data [3], representing likely scenarios of the future atmospheric development [18]. How to optimally combine the forecasts of ensemble members remains a challenge [1], for both research and operational applications.
In this paper, we focus on the case of real-valued meteorological variable,
where
An illustration of the ensemble forecasting task. The multiple individual forecasts are used for generating ensemble forecast by post-processing model. The “model” can be either mathematical model or experienced human forecaster, e.g., given the initial forecasts, the human forecaster can decide which to trust and how to use them according to domain knowledge. The ensemble forecast is always generated ahead, then the corresponding observation is measured with a time delay. In this example, 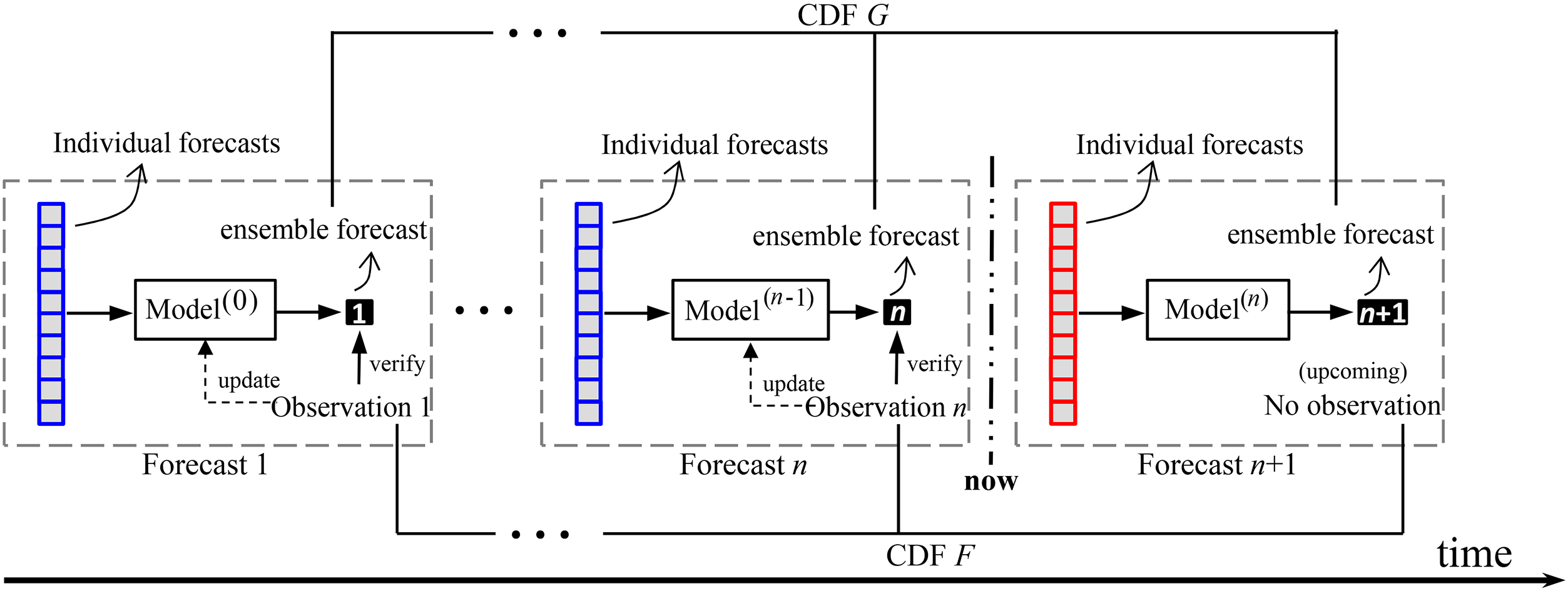
Ensemble forecasts in meteorology include deterministic forecasts and probabilistic forecasts [17]. For example, forecasting tomorrow’s maximum surface temperature is deterministic, while forecasting the probability of tomorrow’s maximum surface temperature larger than some level (e.g., 283
Among these methods, an intuitive and widely used strategy for combination is weighted average [28], which can reflect the members’ relative contributions to predictive skill. With assumptions regarding the probability distributions of forecasts and observations (e.g., Gaussian, Gamma, etc.), Raftery et al. [26] utilized Bayesian model averaging for combining predictive distributions of surface temperature and sea level pressure. Later, Sloughter et al. [29] generalized this method for precipitation. By contrast, Mallet [23] considered distribution assumption unnecessary and targeted the optimal combination in a nonparametric way, i.e., sequential aggregation [7]. Under the scope of online learning (also called online prediction, [21, 20]), various algorithms [22] and loss functions [30] have been proposed to perform better sequential aggregation for ensemble forecasting. The nature of weighted average is to produce a convex combination, namely linear opinion pool. However, Ranjan and Gneiting [27] theoretically demonstrated that linear opinion pools are suboptimal and suggested nonlinear generalization.
In this study, Label Distribution Learning with Climate Probability (LDLCP), as a novel machine learning method without distribution assumption, is proposed to realize nonlinear combination. LDLCP inherits the core idea of quantile regression (QR, [14]), which is a kind of CDF-based regression for sequential aggregation [5]. Further, LDLCP takes the expertise of human forecasters (domain knowledge) into consideration. Though the basic weather forecasts are made by various numerical models, in real applications the role of human forecasters is important in at least two aspects. First, given the initial forecasts from various NWPs around the world, human forecasters decide which to trust and how to use them according to their experience of how the forecasts are consistent with local climate. This inspires us to optimize the probabilistic relation between ensemble forecasts and observations using label distribution learning (LDL, [11]) paradigm. Second, conventional statistical models usually post-process the varibale to be forecasted directly, while human forecasters prefer to incorporate additional variables when they forecast. [9] has verified the potential benefit of jointly utilizing the relevant variables for machine learning models. Thus, the proposed LDLCP also considers the relevant variables.
Note that LDLCP is a novel LDL method, because the previous LDL methods can’t be used directly. More specifically, previous LDL methods aim to capture the underlying label distribution just for classification tasks, e.g., facial age estimation [10] and crowd counting [32]. They mostly use the Kullack-Leibler divergence as the similarity measure and regard the maximum entropy model [4] as the parametric model for the conditional probability mass function, which is not suitable for CDF-based ensemble forecasting task. Instead, we specialize the target function and the corresponding conditional probability function for this special problem.
The main contributions of this paper are summarized as follows:
We formulate the ensemble forecasting problem in LDL paradigm, relaxing the limitation of linear opinion pools and distribution assumptions for ensemble forecasting. We adapt LDL to effectively handle real-valued regression problems through specialized algorithm. We conduct evaluation of LDLCP on artificial and real-world ensemble forecasting data sets. The results confirm the advantages of our proposed method and demonstrate the potential of CDF-based extension for LDL.
The rest of this paper is organized as follows. Section 2 introduces our proposed method in detail and presents its implementation for ensemble forecasting. Experimental study is presented in Section 3. Finally, we conclude the paper and present our future work in Section 4.
Generally, the proposed LDLCP includes learning stage and forecasting stage. Figure 2 shows the LDLCP flowchart. The pseudocode of LDLCP is presented in Algorithm 2.2.2.
The flowchart of LDLCP method. LDLCP firstly estimates the climate probability according to the observations in learning stage. Then, LDLCP constructs a new training set with the climate probability and optimizes a CDF-based label distribution model. Finally, in the forecasting stage, the predicted label distribution can be obtained for ensemble forecasting.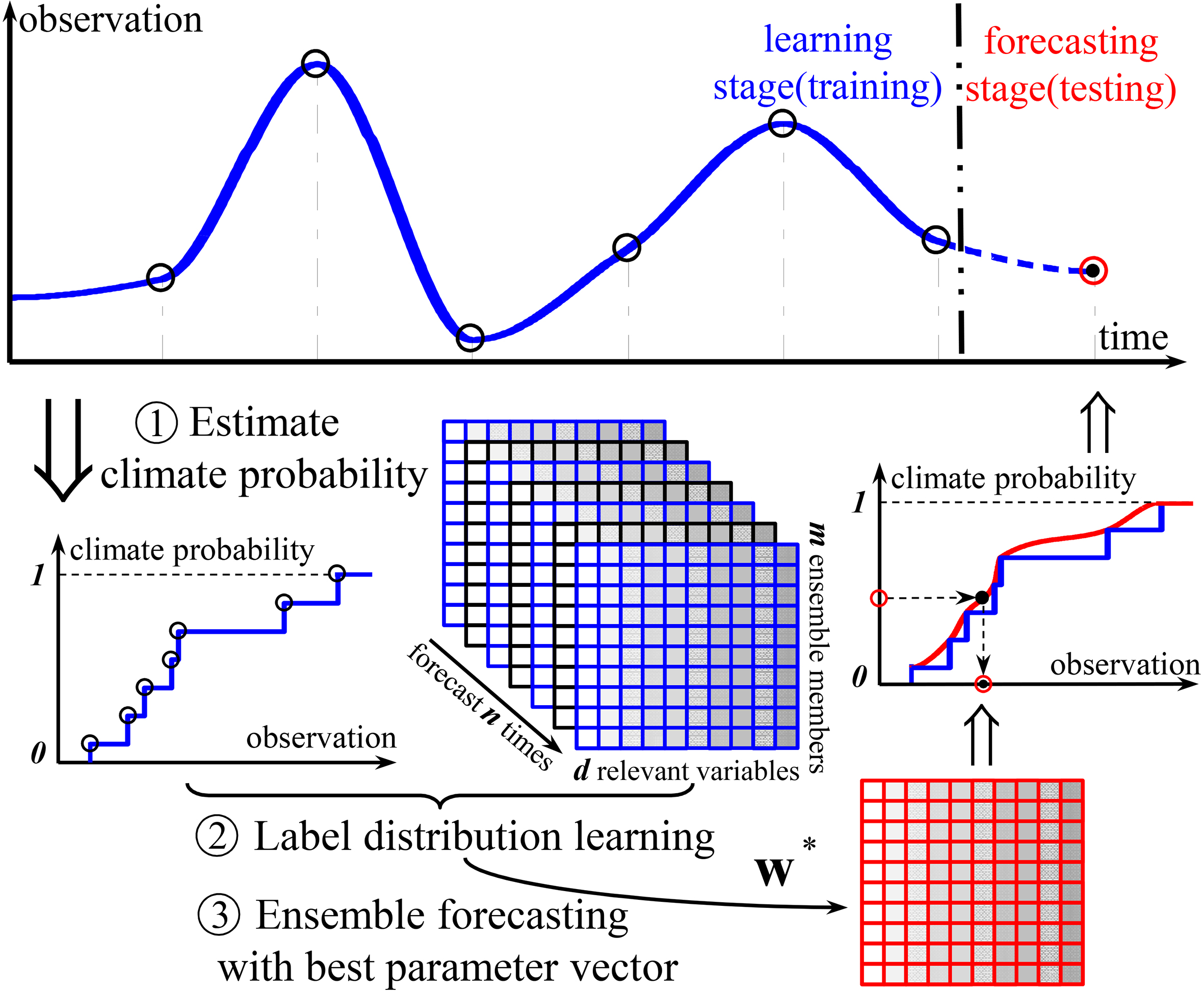
The training set of
where
In the training set, the corresponding climate probability can be empirically estimated with the Heaviside step function
where
Also, since
where
Thus, the final target function of w is:
Inspired by [11], the minimization of Eq. (2) follows the idea of an effective quasi-Newton optimization technique named Broyden-Fletcher-Goldfard-Shanno (BFGS, more details can be found in [25]). We consider iteratively minimizing the second-order Taylor series of
where
Here,
where
With respect to Eq. (2),
To avoid computing
where
The best parameter vector
In the forecasting stage, we first apply the piecewise cubic Hermite interpolating polynomial (PCHIP) [2] to
Deterministic ensemble forecast
As
where
Replacing
Different from
In the forecasting stage, we generate
[t] LDLCPTraining set
In this section, we first give the descriptions of data sets, competitors, parameters and evaluation methods.1
Source code and data are available at:
There are two data sets used in the experiments including a widely used artificial data set in meteorological data analysis and a real-world data set with respect to precipitation ensemble forecasting. The first data set is generated to show in a direct and visual way how the proposed LDLCP method can capture the potential label distribution and realize nonlinear combination for ensemble members. The second data set includes real precipitation processes in four months, which helps to analyse how well the proposed LDLCP method can capture the tendency of observations in different scenarios.
MLT
The artificial data set described in [6] is used (with some modifications) in the experiment to mimic local temperatures (MLT). The observations and ensemble member values are generated from the following time series:
where
Parameters used for generating the artificial data
The observations over 730 time steps (a) and the corresponding CDFs (b) of the MLT data set.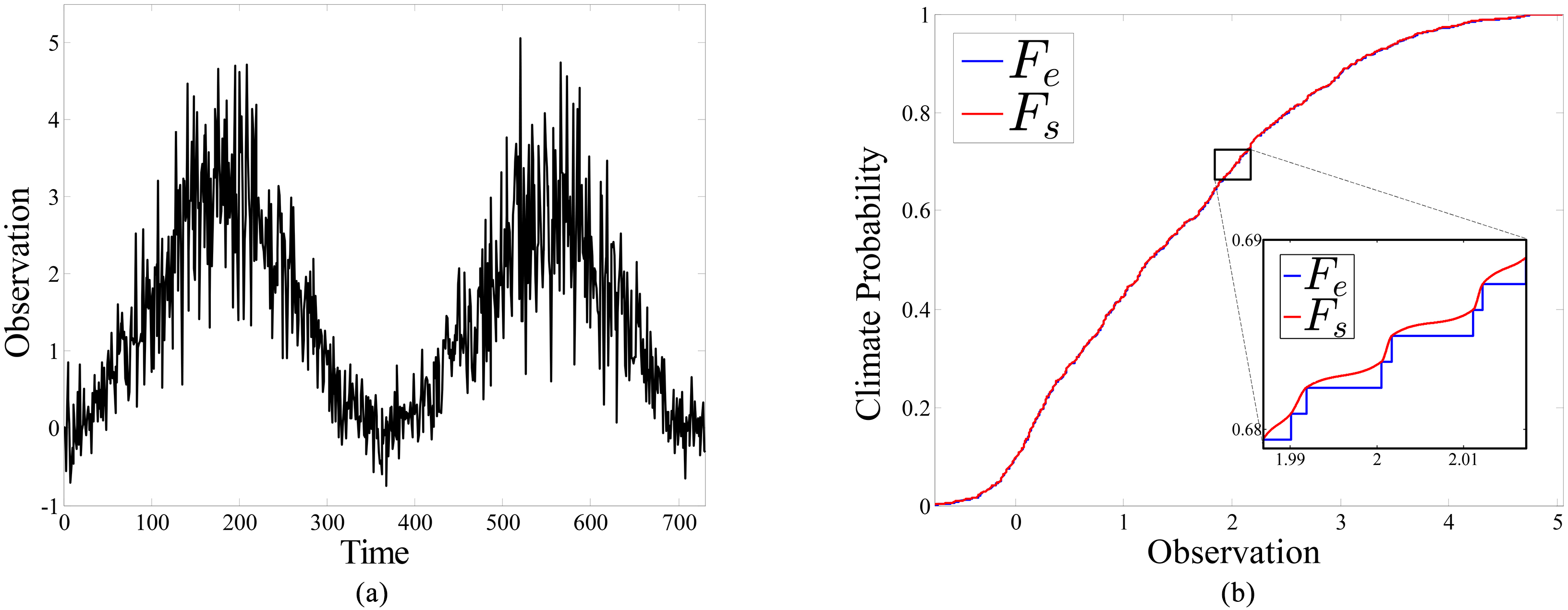
This original data set provided by China Meteorological Administration (CMA) corresponds to ensemble forecasts of 6 h accumulated precipitation (EFP) in East China ([116
The study area of the EFP data set. The circles show the spatial distribution of the national AWS network within the study area.
In this study, our proposed LDLCP method is compared with a baseline and two machine learning methods:
RAW: refers to raw ensemble. As a baseline, RAW always averages the forecasts of ensemble members. Accordingly, RAW simply generates probabilistic ensemble forecast as BMA[26, 29]: refers to Bayesian model averaging. This method is a well-known parameterized post-processing method used in operation. BMA assumes the forecast probability mass function EG[30]: refers to exponentiated gradient. EG is one of the state-of-the-art online learning methods for ensemble forecasting. EG assumes the forecast CDF to be the form of
where
We use the Matlab programming language to implement RAW and EG, and use the R statistical package [29] to implement BMA. For a fair comparison, we implement all the methods without additional calibration strategies. For BMA and EG, the initial
We start the evaluation from
where for the
For each of the evaluation measures, the lower it is, the better the performance is. Note that EFP records real precipitation processes, while MLT is randomly generated according to Eqs (12), (13) and (14). Due to the randomness of MLT, MLT is generated 100 times and the experiments on MLT are conducted with 100 independent runs for a fair evaluation.
Table 2 shows the performance results for MLT and EFP when applying RAW, BMA, EG and LDLCP. In Table 2, we report “mean
Evaluation results on MLT and EFP
Evaluation results on MLT and EFP
The best result is in bold face.
For RMSE and
Recall Eq. (16), a lower
For MLT, we intentionally generate the ensemble members similar to the observations. The ensemble members are composed of two classes of equal size. Empirically, the members with
As there are no additional relevant variables in MLT, MLT can be viewed as a reduced case. In this case, each competitor makes forecasts through assigning weights for the individual forecasts. Note that the weights should be non-negative and sum to one for RAW, BMA and EG, while LDLCP needn’t follow these restrictions. We track the variation of cumulated weights of the two classes and test whether the competitors can favor the class of more skillful members (see Fig. 5). With respect to BMA and EG, as expected, the class with
Cumulated weights of ensemble members with 
However, the situation is quite different for LDLCP. Figure 5 shows that LDLCP does not tend to just rely on the class with
Comparisons between observations and different deterministic forecasts with (b, d and f) and without (a, c and e) post-processing methods. The grey area represents the range of individual forecasts from 72 ensemble members and RAW represents the ensemble mean. Three examples of different scenarios (total precipitation: 13.1 (a and b), 34.6 (c and d) and 94.4 mm (e and f)) from 2400 UTC 5 November to 2400 UTC 8 November 2017 are shown. 
For EFP, to further examine the quality of deterministic ensemble forecasting with respect to the whole precipitation processes in different scenarios, three examples are presented to show the comparisons between observations and different deterministic forecasts (see Fig. 6). Note the difference of scales in Fig. 6.
With respect to light precipitation process (Fig. 6a and b) and moderate precipitation process (Fig. 6c and d), LDLCP generally achieves the best performance (i.e., the forecasts applying LDLCP approximately match the observations), while the ensemble members tend to overestimate the precipitation processes (e.g., at 1200 UTC 7 November 2017).
Nonetheless, decreased performance of machine learning methods can be found with respect to heavy precipitation process (Fig. 6e and f). In this scenario, though LDLCP and EG can well capture the tendency of the precipitation process, they can not make satisfying forecasts for extreme precipitation. For example, at 0600 UTC 7 November 2017, obvious underestimations can be found for EG (17.6 versus 56.6 mm) and LDLCP (31.7 versus 56.6 mm). The reason may include the skewed distribution of different kinds of precipitation processes and the heavy precipitation processes are very few in the training set. In addition, extreme precipitation itself is difficult to forecast due to the weather uncertainty. In this perspective, LDLCP needs specialized adjustment for the precipitation with relatively low occurrence frequency (e.g., extreme precipitation).
In this paper, a machine learning method (LDLCP) for ensemble forecasting is proposed. LDLCP jointly utilizes the relevant variables and applies the paradigm of LDL to optimize the distribution of ensemble forecasts to be consistent with climate probability. LDLCP adapts specialized target function and conditional probability function for ensemble forecasting and doesn’t need any assumption about the probability distribution. Experiments were implemented on both artificial data (MLT) and the data set for ensemble forecasting of precipitation in East China (EFP). The results confirm that LDLCP can improve the performance of both deterministic forecasting and probabilistic forecasting, showing promising RMSE and
Though LDLCP is designed for ensemble forecasting task, as a general learning framework, LDLCP may also be used to solve other kinds of time-series prediction problems. Except for climate data, LDLCP could be useful if the characteristics of data include: 1) multiple predictors like ensemble members; 2) periodic underlying distribution like local climate.
Future research will include the following: 1) for probabilistic ensemble forecasting, a more effective approach to increase the sharpness of the forecasts obtained by LDLCP; 2) for deterministic ensemble forecasting, a suitable strategy to improve the performance of LDLCP when extreme precipitation occurs.
Footnotes
Acknowledgments
The authors would like to express their gratitude to the CMA Public Meteorological Service Center for providing the meteorological data. The authors are thankful for the financial support from the National Natural Science Foundation of China (U1636220 and 61602482).