
Abstract
Collaborative filtering recommendation with implicit feedbacks (i.e., clicks, views, check-ins) has been gaining increasing attention in various real applications. Tagging information is the common resource to complement implicit feedbacks to assist collaborative filtering recommendation. However, existing tag-aware recommendation methods still suffer from the problem of high dimension and sparsity of tagging information. They also fail to realize that recommendation is inherent a ranking-oriented optimization task. To this end, we propose a novel tag-aware recommendation framework by incorporating tag mapping scheme into ranking-based collaborative filtering model, to boost ranking-oriented personalized recommendation performance. We first build ranking-oriented optimization model based on Bayesian personalized ranking optimization criterion with matrix factorization, by leveraging implicit feedbacks to learn the latent feature vectors of users and items. Then, we propose an explicit-to-implicit feature mapping scheme, mapping the high-dimensional and sparse explicit tags (i.e., user-tag weighting matrix and item-tag weighting matrix) to low-dimensional and compact implicit features of uses and items. This could serve as the regularization constraint of latent features derived from implicit feedbacks. To further enhance recommendation performance, we also introduce users’ neighbor relationships to regularize user latent features based on manifold learning. Experiments on real-world recommendation datasets show that the proposed recommendation method outperformed competing methods on ranking-oriented recommendation performance.
Introduction
Recent years have witnessed the prevalence of personalized recommendation in various real applications, which makes it much easier for people to acquire their needs. Researches indicated that recommendation with implicit feedbacks (i.e., clicks, browsing, shopping records, etc.) has been receiving more and more attention than explicit feedbacks (i.e., ratings). This is due to that implicit feedbacks are relatively more abundant in real applications and are easily collected. Both rating-based and ranking-based methods are popular, while some recent studies have demonstrated that ranking-based methods may be more suitable for top-
There have been numbers of researches on tag-aware collaborative filtering (CF) recommendation, which are divided into two mainstreams, including neighborhood-based and model-based methods. 1) Neighborhood-based methods recommend items to the target user in two ways: items similar to that the user has selected, items that similar users have selected. Tag-based features takes tags as explicit features in describing user preferences and item properties, and could be used to compute item similarity and user similarity, which can be well incorporated into neighborhood-based CF methods [3, 4]. 2) Model-based methods, including matrix factorization [5, 6, 7], diffusion-based model [8] and random-walk-based algorithm [9], tensor factorization [10, 11, 12], deep learning [13], could absorb tagging information in a nice way to assist item recommendation. For example, Zheng and Li [3] proposed two variants of the standard user-based and item-based methods by calculating user and item similarities based on TF-IDF weighted tag vectors. Ma et al. [7] designed a general framework by incorporating tags issued by users and tags associated with items into probability matrix factorization model, which connect user-item and user-tag (or item-tag) tagging information through the shared user latent feature space (or item latent feature space). Wu et al. [6] proposed a neighborhood-aware probabilistic matrix factorization regularized by user similarity and item similarity in the tag space. Tensor factorization approaches investigate the ternary association among users, items, and tags simultaneously to generate recommendations [10, 11, 12]. Unfortunately, they cannot be applied to our scenario where users only annotate tags to only a few items they have selected. They are unable to capture interactions without tag assignment, due to tensor decomposition algorithms require users, items, and tags to co-occur simultaneously. Besides, this kind of approach is generally expensive.
In addition, there are also works considering other types of explicit content information (e.g., reviews, attributes) to assist item recommendation. Both tags and reviewers are user-generated textual annotations on items. For instance, Zhang et al. proposed an explicit factor model to generate explainable recommendations, which first extracted explicit product features and user opinions, then generated recommendations according to the specific product features to the user’s interests and the hidden features learned [14]. Afterwards, Chen et al. introduced a tensor factorization algorithm to learn to rank user preferences on explicit features, and then combined it with collaborative filtering method to boost the performance of item recommendation [15]. However, tensor factorization for feature ranking is easily affected by the sparsity problem of explicit features.
Despite that encouraging performance of the previous methods, they still suffer from several issues. First, some mainly focus on explicit user-item interactions (i.e., real-valued ratings) other than implicit feedbacks, which is not practical in real-world scenarios where most people are unwilling to give ratings. Second, the rating-based methods may not suitable for the top-
Based on the above analysis, we propose a novel tag-aware recommendation framework by incorporating tag mapping scheme into ranking-based collaborative filtering model, to boost ranking-oriented recommendation performance. We first build Bayesian personalized ranking optimization model with matrix factorization, by leveraging collaborative information to learn latent feature vectors of users and items. Then, we propose an explicit-to-implicit feature mapping scheme, to map the explicit tagging features (i.e., user-tag weighting matrix and item-tag weighting matrix) with high dimension and sparsity to low-dimensional and compact implicit features of uses and items. This could well serve as the regularization term of latent user and item features that learned from collaborative information. In order to further enhance recommendation performance, we introduce users’ neighbor information to regularize user latent feature based on manifold learning. It can alleviate the overfitting problem suffered by the matrix factorization model by leveraging the two kinds of regularization constraints. Experiments on real-world recommendation datasets show that the proposed recommendation method can outperform the baselines on several ranking-oriented recommendation evaluation metrics.
The remainder of this paper is organized as follows. Section 2 briefly reviews prior work on collaborative filtering recommendation with implicit feedbacks and tag-aware recommendation. Section 3 describes the details of our proposed model. Section 4 experimentally compares our method with competitive baselines, followed by the conclusions and future work in Section 5.
Two streams of researches are related to this article: collaborative filtering recommendation with implicit feedbacks and tag-aware recommendation.
Collaborative filtering recommendation with implicit feedbacks
With the ability to leveraging the wisdom of crowds, collaborative filtering techniques have achieved great success in personalized recommendation systems. For collaborative filtering recommendation with implicit feedbacks, both pointwise regression and pairwise ranking approaches are popular in the top-
Pointwise regression approaches [16, 17] take implicit feedbacks as absolute preferences (ratings), and it is a type of rating prediction-based method aiming at predicting ratings of unobserved items and performing personalized ranking indirectly. This kind of approaches reduce the collaborative filtering problem to pointwise regression (or recovery) via minimizing the pointwise square error loss between observed ratings and predicted ratings [16, 18]. Typically, Hu et al. [16] treated ratings of observed items as 1 and 0 otherwise, and exploited weighting regularized matrix factorization strategy to fit the ratings with varying confidential levels. Likewise, Pan et al. [19] formulated the collaborative filtering problems with implicit feedback as one-class collaborative filtering (OCCF) problem, then proposed two frameworks to tackle OCCF problems based on weighted low rank approximation and negative example sampling. Recently, He et al. [17] proposed to weight the missing data based on item popularity to enhance the prediction effectiveness. Nevertheless, the pointwise regression method has some weakness in view of ranking-oriented task, since there is no guarantee that the higher accuracy in rating prediction results in the better ranking results [19]. For instance, the truth ratings of two items are {0.8, 0.4}, and two kinds of predicted ratings are {0.4, 0.8} and {1.2, 0} respectively. Although they both have the same prediction accuracy with the same square errors, it leads to totally opposite ranking orders of items.
Pairwise rank approaches regard implicit feedbacks as relative preferences rather than absolute ones, and are directly optimized for ranking. It assumes that a user likely prefers an observed item to an unobserved item. As a matter of fact, the assumption of pairwise preferences over two items is the relaxation of the assumption of pointwise preferences. Empirically and experimentally, pairwise ranking methods are more competitive than pointwise approaches in real ranking-oriented recommendation scenarios [20]. Bayesian personalized ranking (BPR) proposed by Rendle et al. [21] was the first method with pairwise preference assumption to address the ranking-oriented recommendation problems. Afterwards, various researches based on BPR framework have been made, and attracted many attentions due to their good recommendation quality. On the one side, some related works suggested to improve via exploiting valuable information underlying the raw data, such as improving negative sampling strategy [22], exploiting information from neighbors [6, 23], learning pairwise preferences over user-groups [24] and item-sets [20], integrating pairwise ranking loss and pointwise regression loss [25], etc. On the other side, some researches are proposed to leverage auxiliary information to improve recommendation quality, such as social connections [26], contents of items [15], heterogeneous implicit feedbacks [27], etc.
Tag-aware collaborative filtering recommendation
There have been numbers of researches on tag-aware collaborative filtering recommendation in recent years. Most researches take tags as explicit features in describing user preferences and item properties. The tag-based features are then incorporated into traditional collaborative Filtering methods, including neighborhood-based and model-based methods, to help enhance recommendation performance.
Neighborhood-based CF methods recommend items to the target user in two ways: items similar to that the user has selected, items that similar users have selected. Tag-based features could be used to compute item similarity and user similarity, which can be well incorporated into neighborhood-based CF methods [3, 13]. For example, Zheng and Li [3] proposed two variants of the standard user-based and item-based methods by calculating user and item similarities based on TF-IDF weighted tag vectors. Zuo et al. [13] proposed a tag-aware personalized recommendation method by incorporating deep learning and user-based CF. It leverages a deep neural network to extract users’ in-depth features from user-generated tags, and then uses user deep features to find user neighbors and perform neighborhood-based CF recommendation.
Model-based CF methods could absorb tagging information in a nice way to assist model-based recommendation, e.g., matrix factorization [5, 6, 7], diffusion-based model [8] and random-walk-based algorithm [9]. Generally, model-based CF are relatively more popular than neighborhood-based CF methods. For instance, Zhen et al. [5] employed tag histories of users to regularize user latent feature vectors learned from probabilistic matrix factorization model, which is based on only user-item interactions. Ma et al. [7] design a general framework by incorporating tags issued by users and tags associated with items into probability matrix factorization model, which connect user-item and user-tag (or item-tag) tagging information through the shared user latent feature space (or item latent feature space). Wu et al. [6] proposed a neighborhood-aware probabilistic matrix factorization regularized by user similarity and item similarity in the tag space. Zhang [8] proposed a personalized recommendation algorithm via integrated diffusion on user-item-tag tripartite graphs, where the information is limited to propagate within user-item and item-tag bipartite graphs. However, the sparse problem also limits the performance of recommender systems both in the conventional user-item setting and in the context of social tagging systems. In case of this issue, Zhang et al. [9] proposed a random-walk-based algorithm to deal with the sparse problem in social tagging data, which captures the potential transitive associations between users and items through their interaction with tags. There are also approaches investigate the ternary association among users, items, and tags simultaneously by leveraging tensor factorization to generate recommendations [11, 12]. However, they are unable to capture interactions without tag assignment, since tensor decomposition algorithms require users, items, and tags to co-occur simultaneously. Indeed, in real recommendation scenarios, users commonly select specific items without assigning tags. There exists more user-item interaction information than user-item-tag tagging information. Thus, the tensor factorization methods cannot be directly applied to our task which aims to leverage tagging information to assist item recommendation.
In addition, some works also consider other types of explicit content information, such as reviews, to assist item recommendation. Both tags and reviewers are user-generated textual annotations on items, and they have something in common in assisting CF recommendation. For instance, Zhang et al. proposed an explicit factor model to generate explainable recommendations, which first extract explicit product features and user opinions, then generate recommendations according to the specific product features to the user’s interests and the hidden features learned [14]. Afterwards, Chen et al. introduced a tensor matrix factorization algorithm to learn to rank user preferences on explicit features, and then combines it with collaborative filtering method to boost the performance of item recommendation [15]. However, tensor factorization for feature ranking is easily affected by the sparsity problem of explicit features.
Proposed method
Problem definition
Let
Following matrix factorization, we denote users and item as
Tag-aware recommendation model
Bayesian personalized ranking optimization criterion
As selecting the preferred items for each user is an inherently ranking-oriented task, we care more about users’ relative preference on items rather than the rating predictions on them, and that a ranking-based approach can be more suitable than the rating-based criterion. We introduce the current ranking-based optimization criterion, i.e., Bayesian personalized ranking (BPR) with matrix factorization, to perform item ranking.
BPR is derived by a Bayesian analysis of the ranking-based recommendation problem, which tries to find the correct personalized ranking for all items
where
Here,
where
Thus, we can formulate the maximum posterior estimator for
We can also translate the above formulation into the minimization of the following loss function
where
Besides, the preference value
In terms of
where
Thus, we rewrite the above formulation (Eq. (5)) as
From the tagging information, we derive two matrices: user-tag weighting matrix
We assume that selecting an item is also influenced by the user’s underlying opinions over various item aspects (i.e., tags). Based on this assumption, we try to capture latent representations of users and items from explicit tagging information. We can build a feature embedding/mapping model over user-tag matrix
In this way, by integrating regularized feature mapping term (Eq. (8)) with BPR optimization model (Eq. (8)), we get a more accurate recommendation model
where
However, the recommendation model above assumes that users are independent with each other, it ignores the fact that users’ selection action is easily influenced by other users that have similar interests. If we integrate the user relationship information into the above model, it would help further enhance recommendation performance.
To further alleviate the overfitting problem and enhance recommendation performance, we introduce user graph regularization to the original objective function. Graph regularization has been wildly used in dimensionality reduction, clustering and semi-supervised learning [28]. The key assumption of user graph regularization is that if two users
Inspired by [29], which proposed a similarity-based social regularization term that makes an assumption that every user’s preference is close to the average taste of this user’s friends. In the meanwhile, the similarity-based social regularization term treats all friends differently based on how similar they are. However, we have no explicit social friends in our case, we could just obtain the nearest neighbors of target users according to their tagging history based on similarity measurement.
In real implementation, to reduce the computation complexity, we only consider the top
where
The similarity
where
Integrating the Bayesian personalized ranking optimization objective with two regularization constraints based on explicit-to-implicit feature mapping and the user neighbors respectively, we obtain a unified tag-aware recommendation model
where
We simply call our integrated model BPR-T. BPR-T helps us find the more compact and informative latent features of users and items.
To learn the parameters
In each epoch, on one hand, when we are updating the latent feature matrix (
On the other hand, given the latent feature matrix, the optimization objective w.r.t mapping matrix
The updating rule for
In the practical training process, for each observed pair
After estimating the parameters
Datasets
To evaluate our recommendation method with implicit feedbacks and tagging information, we perform experiments on two real-world datasets: Lastfm6
Lastfm. Lastfm is the world’s largest online music catalogue, and allows user tagging music tracks and artists. In the dataset, we take artists as items. This dataset contains a subset of 92834 user-artist listening information from 1892 users on 17632 artists from Last.fm online music system. For the purpose of our experiments, we keep users with at least 10 observations and get 62376 observations from 1797 users and 1507 artists [19]. In consideration of computation complexity, we select the top 2000 tags for training. Citeulike. CiteUlike is a scientific article sharing service where users create personal libraries by posting the articles they like. Each article has information such as title, abstract, authors, publications and keywords. As mentioned before, the content information we used contains the title and abstract. The subset we used contains 5551 users and 16980 articles with 204,986 observed user-item pairs, which is very sparse. For the purpose of our experiments, we keep users with at least 15 observations and get 73788 observations from 2029 users and 3601 articles.
In the comparison, we randomly select 80% of the ratings from the Lastfm and Citeulike as the training data, and leave the remaining 20% as prediction performance testing. We repeat the random splits 5 times to get the average result. The best set of model parameters are tuned by cross-validation over the training set.
We study the recommendation performance on various commonly used evaluation metrics, including Pre@
We also define some notations. For item ranking list
Pre@ MAP@ NDCG@ ARP. ARP is defined as the average relative position (RP) over all users in the test dataset, which is defined as AUC. AUC is defined as the average
We compare the proposed BPR-T (Algorithm 1) with five baselines, which are introduced as below.
Pop [31]. Pop ranks items via popularity of the items. The more visiting users the item has, the higher position in the recommendation list. Note that it is a non-personalized recommendation approach: for any target user, the recommendations are always the same. WRMF [19]. WRMF (weighted regularized matrix factorization) employs a pointwise rating-based assumption for solving recommendation problems with implicit feedbacks. It leverages flexible weighting scheme on unobserved data to tackle the one-class collaborative filtering problem. BPR [21]. BPR (Bayesian personalized ranking) employs a pairwise ranking-based assumption for solving recommendation problems with implicit feedbacks. BPR represents the state-of-the-art optimization framework of collaborative filtering for binary relevance data [21]. Matrix factorization is the common choice of representing user’s preference to items. In addition, we employ the uniform sampling in model learning. NHPMF [6]. NHPMF (neighborhood-aware probabilistic matrix Factorization) explores auxiliary tagging data to regularize latent user feature and item feature to achieve more accurate recommendations. NHPMF leverages the tagging data to select neighbors of each user and each item, and incorporates the neighborhood information into the probabilistic matrix factorization model of the explicit ratings, to ensure similar users (items) will have similar latent features. LRPPM-CF [15]. LRPPM-CF introduces a tensor matrix factorization algorithm to learn to rank user preferences on items’ explicit features, and then combines it with collaborative filtering method (rating-based optimization objective via matrix factorization) to boost the performance of recommendation.
For fair comparison, we use the same initializations for the model variables
We analyze how the two regularization parameters
Effect of parameters 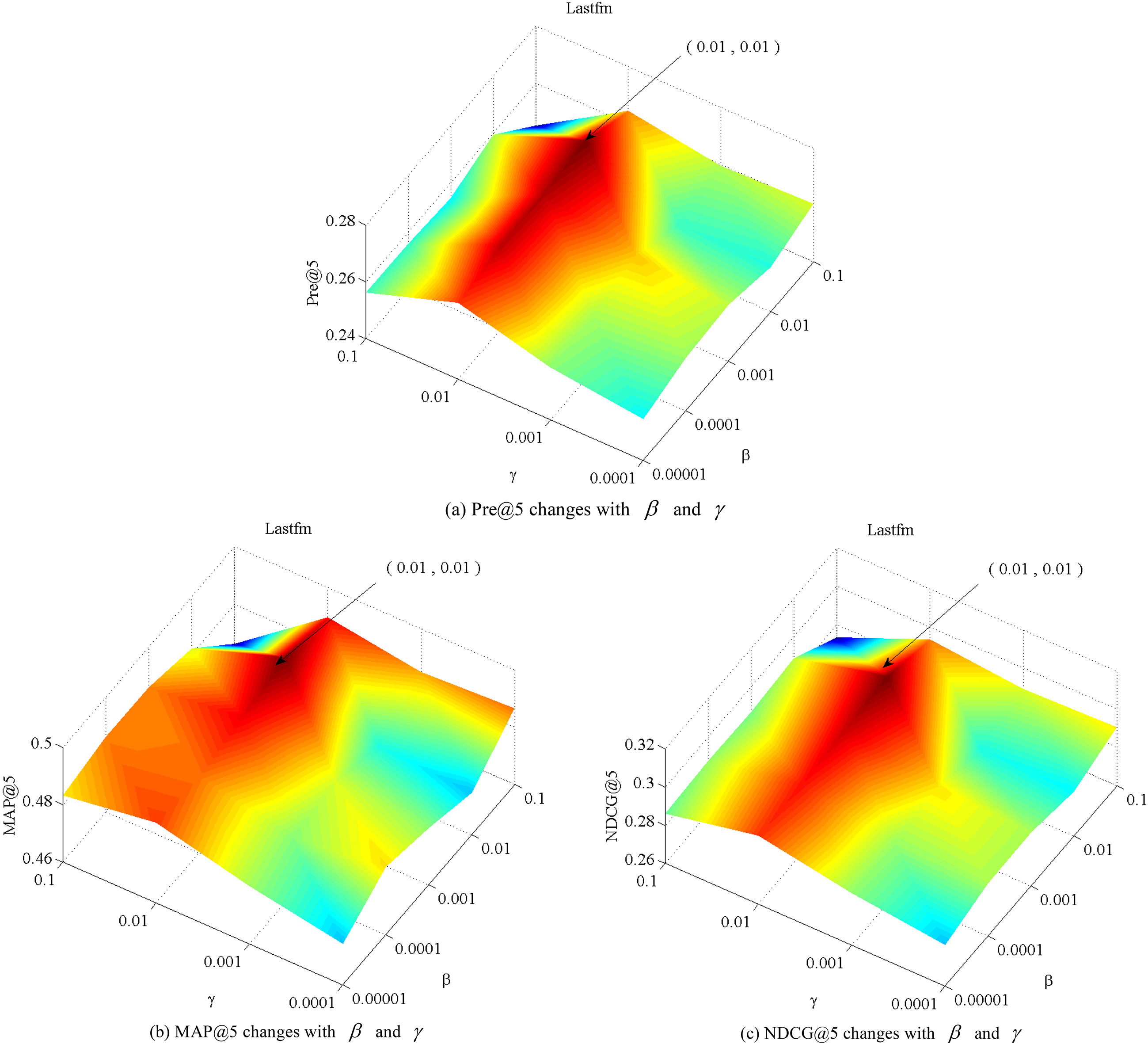
Effect of parameters 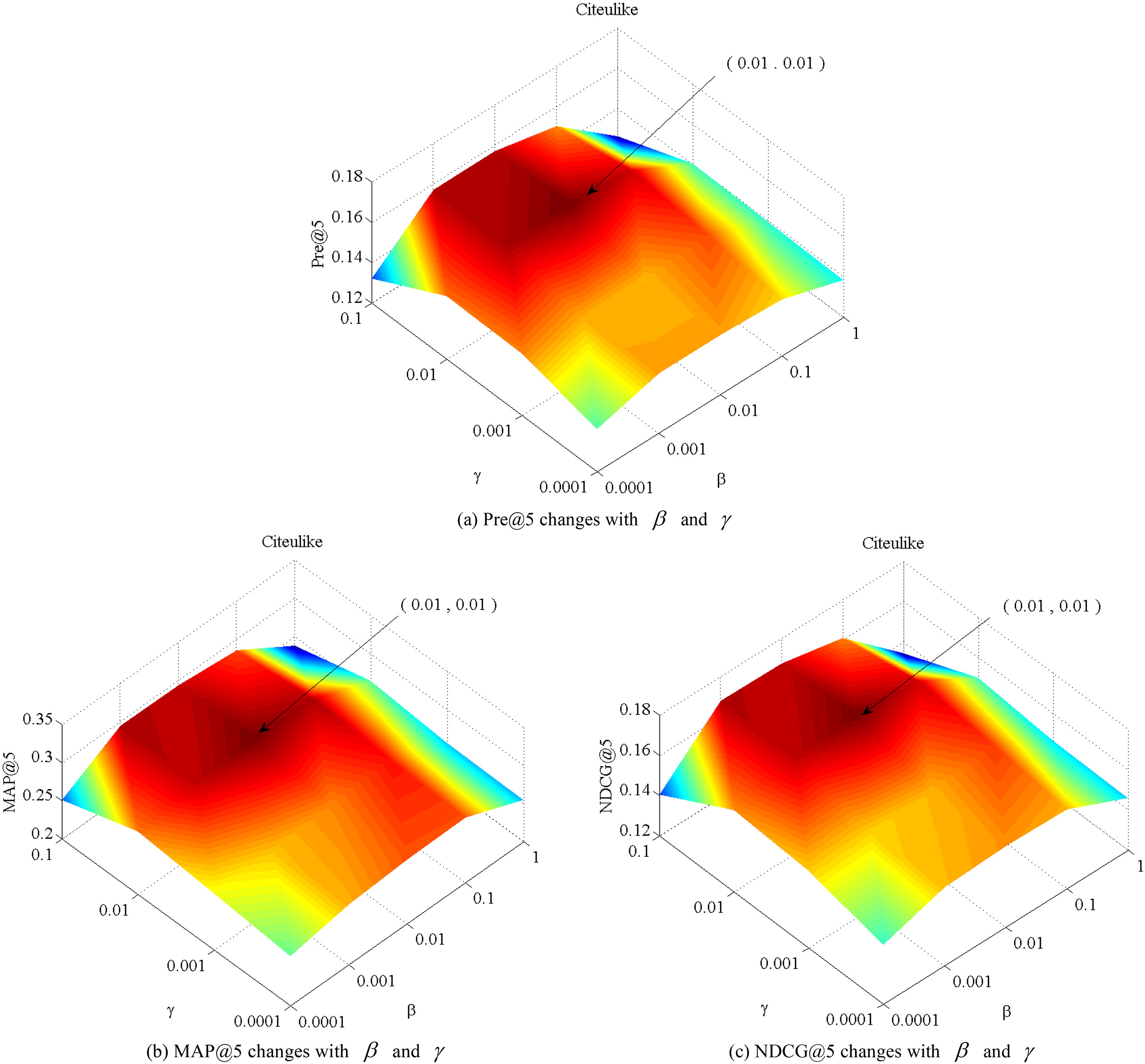
For Lastfm dataset, we set the value of
For Citeulike dataset, we set the value of
Therefore, in our experiments, we set
We compare our model BPR-T with the mentioned baselines on the Lastfm and Citeulike datasets on several evaluation metrics, including Pre@
We firstly study how the Pre@
Top-
Top-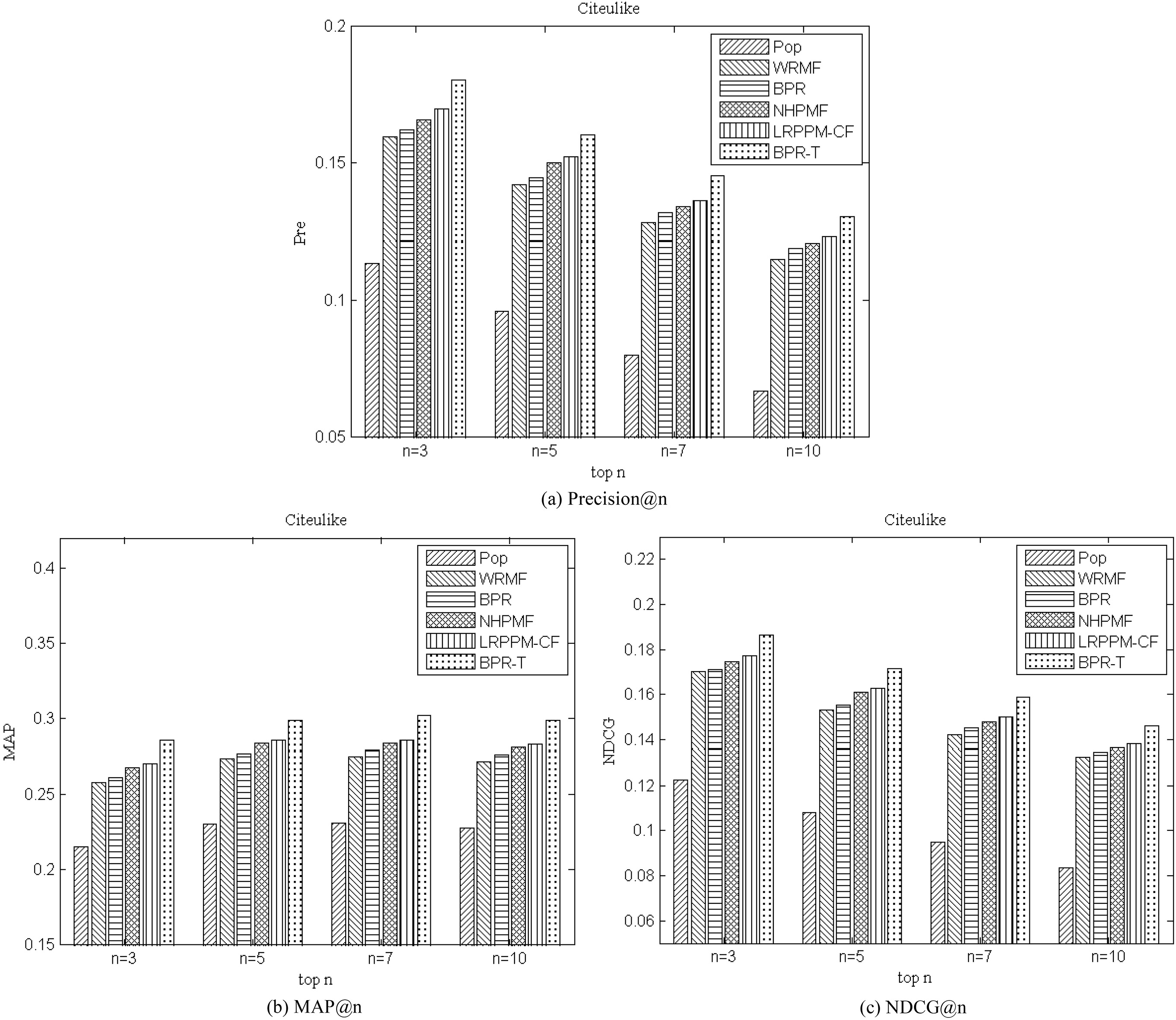
We also give the recommendation result in terms of the other two ranking-oriented evaluation metrics: AUC and ARP, which is independent of the cutoff n of ranking list(see Table 1). In view of AUC, the larger value means the better recommendation ability. For ARP, the smaller value indicates the better recommendation performance. Bold-font indicates the best results.
Performance comparisons in terms of ARP and AUC on Lastfm and Citeulike datasets
From Figs 3 and 4 and Table 1, we can have the following observations,
Our method BPR-T performs best among baselines in terms of top- BPR-T beats LRPPM-CF and NHPMF. The results, on one hand, mean that in terms of the datasets in this paper the ranking-based recommendation methods are more qualified than rating-based methods for top- The methods including BPR-T, LRPPM-CF and NHPMF perform better than BPR, WRMF and Pop, this is due to that the latter three methods only use the implicit feedbacks to make recommendation, while the former methods leverage both tagging information and implicit feedbacks to perform recommendation. The comparison results indicate the significance of integrating tagging information with traditional collaborative information, since tagging information provides explicit content-based representation of users and items. In view of all the compared methods, we can see that all methods beat Pop method, which is a non-personalized recommendation strategy. This result demonstrates the effectiveness of personalized recommendation methods, including WRMF, BPR, NHPMF, LRPPM-CF, and our BPR-T. In view of all the personalized recommendation methods, we can see that all methods beat WRMF, which shows the effectiveness of the pairwise preference assumptions of BPR, BPR-T, and the effectiveness of leveraging extra tagging information in NHPMF, LRPPM-CF in our case. Though, all the baselines still perform worse than our proposed method BPR-T. From the comparative results, we also observe that the evaluation values of generated by all the methods on Lastfm dataset are much higher than those on Citeulike dataset, it is because that the Citeulike dataset is sparser than the Lastfm dataset.
This paper presents a new tag-aware recommendation algorithm which integrates tagging information with collaborative information to enhance ranking-oriented recommendation performance. Based on the popular ranking-based recommendation model (i.e., BPR) with matrix factorization, we employ two critical regularization constraints by leveraging explicit-to-implicit feature mapping and user neighbor relationship, to help alleviate the overfitting problem and enhance ranking-oriented recommendation performance. Evaluation on two real-world datasets shows that our proposed method significantly outperformed several competitive baselines on several recommendation measure metrics.
For future works, we are mainly interested in extending our method in two aspects, (1) studying how to leverage tag recommendation strategy to further alleviate the sparsity problem of tagging information, (2) further researching the explanation of recommendation results in a clearer way.
Footnotes
Acknowledgments
This work is supported by the Natural Science Foundation of China under Grant 61371196. The authors would like to thank the anonymous reviewers for their constructive comments.