
Abstract
Knowledge bases (KBs) provide a large amount of structured information for entities and relations, which are successfully leveraged in many natural language processing tasks. However, distantly supervised relation extraction only utilizes KBs to automatically generate datasets, while ignoring the background information in KBs during the relation extraction process. We herein propose a knowledge-embodied attention that leverages knowledge information in KBs to reduce the impact of noisy data for distantly supervised relation extraction. Specifically, we pre-train distributed representations of KBs with the knowledge representation learning (KRL) model, and subsequently incorporate them into relation extraction to learn sentence-level attention weights. The experimental results demonstrate that our approach outperforms all baselines, thus indicating that we can focus our attention on valid data by leveraging background information in KBs.
Keywords
Introduction
Extracting semantic relations between entities in text is an important and well-studied task in natural language processing (NLP). Traditional supervised methods[1, 2] rely heavily on hand-labeled corpora, which is laborious and expensive. To address the insufficient training data issue, Mintz et al.[3] proposed the distant supervision (DS) paradigm for relation extraction to automatically generate training data via aligning knowledge bases (KBs) and texts. Specifically, for a triplet
Distant Supervision paradigm generates training data automatically by aligning triplets in a KB with free texts. However, some sentences (i.e., S3 in the figure) do not express the relation of the given triplet.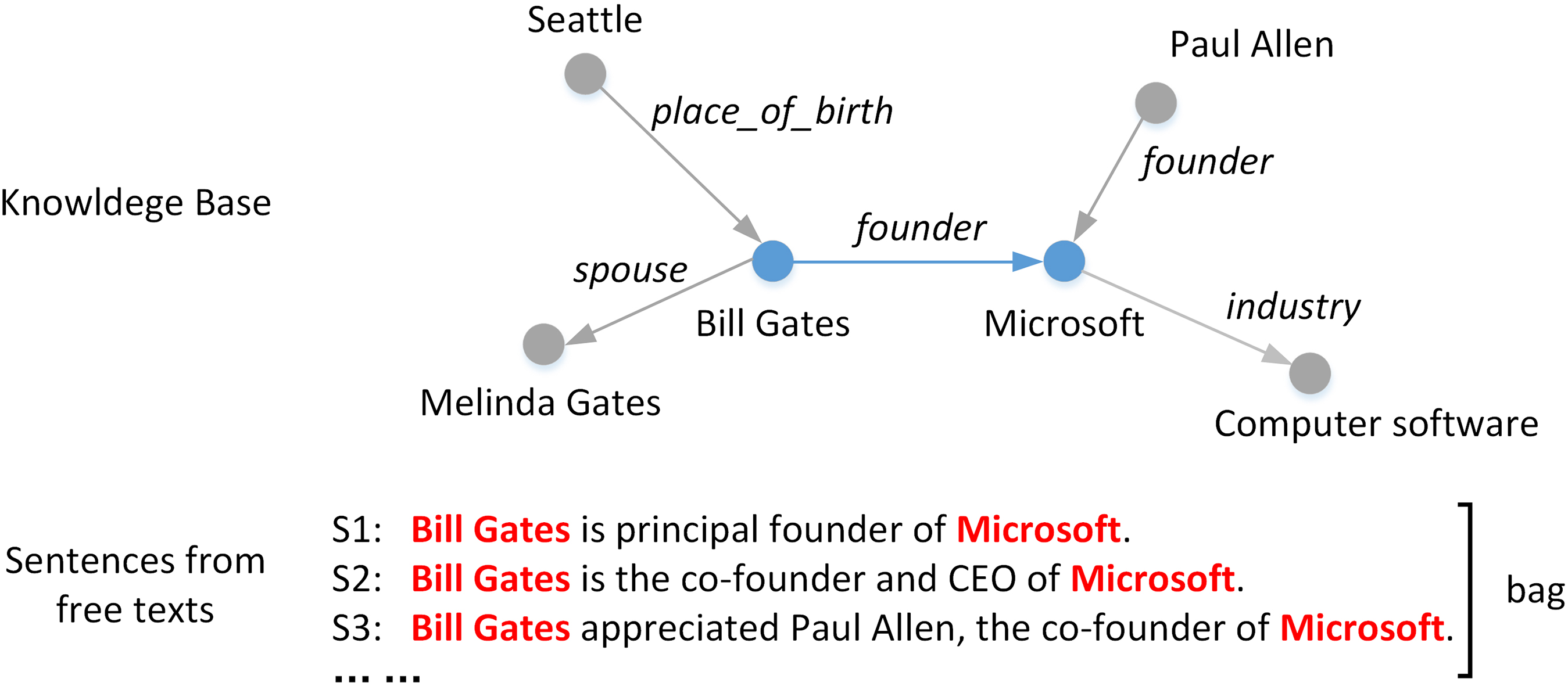
Recently, neural networks methods have been widely explored on DS relation extraction[4, 5, 6, 7, 8]. These methods use all of the words as input without complicated preprocessing. First, words in sentences are transformed to low-dimensional vectors by looking up the word embeddings. Subsequently, sentence-level and bag-level features are learned using convolutional neural networks (CNNs) or recurrent neural networks (RNNs). Finally, the bag-level features are fed into a softmax classifier to predict the relationship between the head and tail entities. Compared with feature-based methods, neural networks methods achieve significant improvements without any features derived from lexical resources or NLP tools.
However, most conventional neural networks methods only utilize KBs to generate datasets, where the input of the neural networks is only text or a sequence of words, and numerous background knowledge in KBs is disregarded. The importance of background knowledge in NLP has long been recognized. Earlier NLP studies primarily exploited limited linguistic knowledge such as manually encoded syntactic patterns. With the development of knowledge-based construction, numerous semantic knowledge have become available. Recently, researchers have proposed several improved neural networks to introduce KBs into NLP tasks. Yang et al.[9] proposed KBLSTM , an extension to bidirectional long short-term memory neural networks (BiLSTMs) that can leverage continuous representations of KBs to enhance the learning of RNNs for machine reading. Wang et al.[10] incorporated KB representations into news recommendation by deep knowledge-aware networks.
Inspired by the wide success of leveraging KBs, we attempt to use the background knowledge in KBs to solve the wrong label problem[11] in DS relation extraction. The simple assumptions of distant supervision are not always consistent with the actual situation. There are a lot of wrong-labeling data in the automatically labeled dataset. A sentence that mentions two entities may not express the relation that links them in a KB, i.e., S3 in Fig. 1. Early approaches typically adopted multi-instance learning[12, 13] to select the most likely valid sentence from a bag. Neural network-based methods often used the sentence-level attention mechanism[6, 14, 15] to solve this problem; it attempts to assign weights for instances by the similarity or relatedness between the current input and the target output. However, these sentence-level attentions only use the word embeddings features of the input entity pair or sentences to compute the target relation representation, which is very limited to predict an accurate relation representation.
We have noticed that knowledge representation learning (KRL) models, such as TransE[16] and TransH[17], build entity and relation embeddings by regarding a relation as translation from the head entity to tail entity, i.e.,
Our primary contributions in this study can be summarized as follows:
We proposed an extension to PCNN with a knowledge-embodied attention mechanism that can incorporate KB representations into relation extraction to reduce the impact of noisy data in the DS paradigm. We evaluated our PCNN We further analyzed the effect of different training strategies in detail to explore the influence factors of the model performance. Further, we conducted a detailed analysis on a representative case, thus confirming the power of our attention in selecting valid sentences.
Distantly supervised relation extraction
Although distant supervision is an effective method to automatically label training data, it inevitably suffers from the wrong-labeling problem. To reduce the impact of noisy data, Riedel et al.[11] regarded distantly supervised relation extraction as a multi-instance single-label problem, where only the most likely sentence for each entity pair in training and prediction was selected. Hoffmann et al.[12] and Surdeanu et al.[13] used a probabilistic graphical model to select valid sentences.
In neural network methods, Zeng et al.[5] explored a PCNN to extract sentence-level features with a multi-instance learning paradigm. The multi-instance learning strategy only selects one sentence with the maximum probability, and does not fully utilize the supervision dataset. Therefore, Lin et al.[6] used a selective attention over multiple instance by generating the inner attentions for each sentence in a bag. Ji et al.[14] proposed a sentence-level attention model based on PCNNs (called APCNN) that directly uses the vector
Our work is inspired by the APCNN. The major difference between PCNN
Knowledge representation learning
We further relate to prior works regarding KRL; the latter aims to project both entities and relations in a KB into a continuous low-dimensional semantic space. Translation-based methods could leverage both effectiveness and efficiency in KRL, and thus have attracted particular attention in recent years. TransE[16] encodes both entities and relations into the same vector space, with relations considered to be translating operations between the head and tail entities. For a triplet
TransE is both effective and efficient, while the simple translating operation may result in conflicts when modeling more complicated relations such as 1-to-N, N-to-1, and N-to-N. To address this issue, TransH[17] proposed a relation-specific hyperplane for translations between entity pairs. TransR[19] directly modeled entities and relations in separate entities and relation spaces.
Our method attempts to introduce knowledge representations into the distantly supervised relation extraction task that uses the TransE model to pre-train the knowledge embeddings of KBs. Compared with other improved KRL models, TransE is relatively simple and is faster for training large-scale knowledge graph. In future work, we will try to combine other KRL models with relation extraction task.
Methodology
In this section, we present our PCNN
Neural networks architecture for PCNN
The PCNN model is a widely used neural network in the previous DS relation extraction work[5, 6], which is used to extract the feature vector of a sentence in a bag. Suppose that a sentence consisting of t words
Structure of PCNN model. Input a sentence with 
Input vectors: Because we use neural networks, we must transform raw words into low-dimensional vectors as the input. In our method, each word vector is concatenated by word embeddings and position embeddings, similar to[4, 5, 6]. Word embeddings are distributed representations of words that map each word in texts to a low-dimensional vector. We employ the word2vec model[20] to pre-train the word embeddings. Position embeddings are defined as the combination of the relative distance from the current word to
Convolution Layer: The convolution of
For the input sentence
where
For sentence
Piecewise max-pooling: The size of the convolution output matrix
Furthermore, to capture the fine-grained features and structure information, the PCNN divides a sentence into three segments according to the given entity pair, and subsequently perform max-pooling on each segment. For each filter result
where
As shown in Fig. 2, we use the KB as the external information resource, and use the TransE model to pre-train the knowledge embeddings for all entities and relations in the KB. That is, for a triplet
To introduce the knowledge embeddings of the entities into the relation extraction task, we must first transfer the knowledge embeddings from the knowledge space to the word space. Inspired by[18], we transfer the entity embeddings from the knowledge space into the word space with a shared projection matrix. The knowledge embeddings
in which
We expect that our attention mechanism could reduce the impact of noisy data by using information in the KB; this implies that our attention must learn higher weights for valid sentences and lower weights for invalid ones in the bag. Once the bag embeddings have been calculated, we feed them into a softmax classifier.
Attention Mechanism: The simple assumption of distantly supervision inevitably accompanies with the wrong-labeling problem. To address this issue, we require an effective attention mechanism over sentences in a bag that is expected to dynamically reduce the weights of those noisy sentences.
As stated in Section 3.2, the TransE model entities and relations in a KB in the same vector space, with relations considered to translate between the head and tail entities. Hence, for a triplet
Because we use a shared matrix to project the knowledge embeddings of the head entity
Motived by these ideas, we utilize the difference vector to represent the feature of the relation
Suppose
where
where
Softmax: Finally, we feed the sentence embedding into a softmax classifier as follows:
where
For each entity
where
Assume that N bags in exist in the training dataset
To learn the relation extraction task using the projection matrix, the overall objective function of our method is
where
The experiments are intended to prove that our PCNN
Dataset and evaluation metrics
In this section, we introduce our dataset and evaluation metrics.
Dataset: We evaluate our method on a widely used dataset developed by[11]. This dataset is generated by aligning the Freebase triplets with the New York Times corpus (NYT). The entity mentions are annotated with the Stanford NER and further linked to Freebase. The training dataset is aligned to the 2005–2006 NYT corpus, and the testing dataset is aligned to the 2007 NYT corpus. The dataset contains 53 possible relationships including the NA relation, which indicates that no relation exists between the entity pairs.
The training dataset contains 570,088 sentences, 63,428 entities, 291,010 entity pairs, and 19,601 relational triplets (except NA). The testing set contains 172,448 sentences, 16,705 entities, 96,678 entity pairs, and 1,950 relational triplets (except NA). We train the word embeddings with word2vec1
Our methods use KBs as the external information by modeling entities and relations in a KB into a low-dimensional vector space. To capture richer semantic information, we combine all training triplets related to DS relation extraction with a subset of Freebase (called FB15K) as a new KB to train the knowledge embeddings. To prevent overfitting, we remove the triplets in the test set from FB15K. Finally, our KB dataset contains 78,639 entities, 1,371 relations, and 1,225,678 relation triplets. We pre-train the knowledge embeddings with KB2E,2
Evaluation metrics: Following the previous work[3], we evaluate our method in two ways: the held-out evaluation and manual evaluation. The held-out evaluation automatically compares the extracted relation triplets against those in Freebase, and reports the result in precision/recall curves. Considering the incomplete nature of Freebase, we use human evaluation to manually verify the newly discovered relation triplets that are not in Freebase. We report the Precision@N for the manual evaluation.
In our experiments, we use three-fold validation to tune all of the models on the training set, and use a grid search to determine the optimal parameters. We select the dimension of word embedding
It is noteworthy that we use the TensorFlow3
To evaluate our PCNN
Held-out evaluation: Figure 4 shows the precision/recall curves for each method, where our PCNN
Manual evaluation: As shown in Fig. 4, a sharp decline occurs in the held-out precision/recall curves of most models at low recalls; this is due to the incomplete nature of Freebase. A manual verification for the misclassified instances with high confidence can eliminate the problems[11, 4, 6, 14]. Table 1 shows the manual evaluation on the top-100, top-200, and top-500 extracted relation instances. The results show that PCNN+KeATT achieves the best performance and exhibits significant improvements over the traditional methods especially in the top-500 instances. The evaluation results have proven the effectiveness of our method.
Precision for the top 100, 200, 500 extracted relations
Precision for the top 100, 200, 500 extracted relations
The precision/recall curves of PCNN
As stated in Section 3, we use the general score function[21] to compute the attention weight for each sentence in a bag. It is noteworthy that two score functions are widely used[21]. Hence, for two vectors
where
In addition, we jointly learn the projection matrix with the relation extraction task. In fact, we can learn the projection matrix separately, and subsequently use the projected knowledge embeddings on the relation extraction task.
In this section, we further explore the effect of training strategies by conducting four experiments; Fig. 5 shows the precision/recall curves. As shown: (1) The performance of joint learning modes based on two score functions are better than that of separate learning models, demonstrating that the reverse transmission of loss from the space projection model in the joint learning methods can further feed the knowledge information to the master model. (2) Using the general score function, the performance of the DS relation extraction model has been improved. This shows that in our task, the general function can evaluate the similarity or relatedness between two vectors better than the concatenation function.
An example of attention weights by KeATT. The bag is aligned by /location/location/contains (Ukraine, Kiev)
An example of attention weights by KeATT. The bag is aligned by /location/location/contains (Ukraine, Kiev)
Precision/recall curves of PCNN
Table 2 shows a representative example of knowledge-embodied attention weights from the testing data. The bag contains 12 sentences, with four valid ones according to manual assessment. Table 2 shows that our attention assigns higher weights to valid sentences and lower weights to invalid ones. It demonstrates that our attention can reduce the impact of noisy data. For valid sentences, we found that longer sentences are assigned with lower attention weights, although they do not exhibit obvious semantic differences with shorter sentences. (i.e., the weight of S6 is much lower than the other valid sentences, but still significantly higher than the invalid ones.) This shows that the PCNN model can still be improved when handling long sentences.
Conclusion and future work
We herein proposed the knowledge-embodied attention for distantly supervised relation extraction, using knowledge information from KBs to reduce the impact of noisy data. Our experimental results proved the effectiveness of our method.
We will explore the following in the future: (1) The quality of knowledge embeddings is critical in our model. We will utilize more sophisticated KRL models, such as TransR or TransH, to extract better knowledge features. (2) Our method is based on the PCNN that has shown its weak ability to handle long sentences in our case study. We will explore other sentence representation models in the future.
Footnotes
Acknowledgments
This research is supported by the National Natural Science Funds No. 61802327 and Natural Science Foundation of Hunan Province No. 2018JJ3511.