
Abstract
The theories about crime and correction have their inception in the eighteenth century, highly influenced by the anthropological thoughts emerging during the age of Enlightenment. Throughout the decades, the criminological studies observed their sociological essence encompassing practices from other scientific fields to explain the more contemporary questions, becoming Criminology an inherently interdisciplinary science as a result. The adoption of concepts from Exact Sciences is a recent moving, originating it a novel research area, called Computational Criminology, which employs procedures from Applied Mathematics, Statistics and Computer Science to provide original or enhanced solutions to such questions. One of the most prominent tasks brought by this rising field is crime prediction, which attempts to uncover potential targets for future police intervention and also help solving already committed offenses. The present comparative analysis thus investigates the employment of statistical inference by means of Bayesian network for predictive policing, using the openly accessible registers from Chicago Police Department. Numerous algorithms are available to learn the structure for a Bayesian network purely from data and a comparative examination about them is hence described, with the purpose to establish the most precise and efficient one, according to the attributes of the said criminal dataset, for the implementation of the intended inference.
Keywords
Introduction
In a concise definition, Criminology is the science that analyzes the nonlegal aspects of crime, from its causes and consequences to correction and prevention measures [23]. A more elucidative description comes from Edwin Sutherland, considered by many the most famous criminologist of the twentieth century, who described Criminology as the study of the making of laws, the breaking of laws and the society’s reaction to the breaking of laws [47]. Therefore, the science in its core focuses on the analysis of the crime and its perpetrators and victims as well as the criminal justice and penal systems.
Historically, the earliest criminological thoughts emerged in the pre-Enlightenment period, when people started to react to the arbitrariness and cruelty of the then systems of punishment and justice. It was only in the age of Enlightenment that the first formal principles about crime and correction were theorized, mainly of them deriving from the Classical School and its assumption that crime is the product of a deliberated choice of someone exercising free will and rationality. The offender should thus be punished according to the extent of the injuries infringed to the others by his violation [47, 41].
Under the impact of Charles Darwin’s studies on evolution of the species, in the late nineteenth century, the classical conception about crime started being intensively affected by scientific thoughts. The nature of the criminal, considered by the Classical School to be freewilled and rational, was thereby believed to be driven by biological and psychological influences, according to the ideas of the rising Positive School. The premise that factors beyond the individual’s self-control would induce him to commit the crime was one of the major critics against the positive theory, since the individual’s own responsibility in the infraction could not be taken into account by this belief [47, 41].
Several other criminological thoughts followed these two major schools of Criminology throughout the twentieth century, being the Chicago School one of the most preeminent examples. According to the idea of social ecology developed at the Department of Sociology at the University of Chicago from the First World War onwards, crime is a response to the excluding and unhealthy society in which the offender lives. Hence, understanding socio-economic contrasts helps comprehend social and geographical variation in crime and delinquency [47, 10].
With a theoretical basis explaining the essence of crime already established and in constant development, a change in the direction was a natural movement for the investigations in Criminology to fulfill the practical demands that started arising during the second half of the twentieth century. Not only the science should be concerned with what motivates a criminal incident, but also with strategies for preventing or even predicting an occurrence, opening a path to interdisciplinary studies not undertaken until then to be performed.
As a result, disciplines from Exact Sciences began to be contemplated by Criminology scholars to accomplish these more recent challenges, originating this advance a particular research area. Computational Criminology implements methods from Applied Mathematics, Statistics and Computer Science to offer original or enhanced solutions to criminological problems by means of computer-intensive applications and algorithmic procedures [7], an improvement made possible with the continuous increase in computing performance experienced in the last decades.
Thereby, operations executed in a manual mode theretofore, such as crime mapping and its pinpoint physical maps, could start being digitized. Moreover, with the aid of complex computational routines executed on more powerful machines, criminal databases comprised of thousands of millions of entries became processable, permitting the reveal of hidden qualitative information underneath them that were impossible to be noticed just by gazing at that massive amount of registers.
These advances altogether, along with many others provided by the blossom of Computational Criminology, allowed the development of novel criminological practices, being crime forecasting [50, 45] a remarkable example. By combining diverse mathematical and computational strategies, this predictive task attempts to unveil potential targets for police intervention and prevent crime [50], changing the paradigm of police action from reactive to preemptive.
Crime prediction practices may also be employed to solve already committed offenses. Through the use of statistical procedures, concealed patterns in databases of former crimes are revealed, enabling some variables of a present incident to be inferred according to its already evidenced characteristics and, consequently, orientating police strategies in the resolution of the occurrence. For example, suppose that it has been detected from past criminal records that a burglary in a certain neighborhood is usually perpetrated by a man in his twenties who lives in the industrial district. A crime prediction proceeding may tell how probable it is the offender of a newly perpetrated burglary in the same neighborhood to reside in the industrial district or even the transgression to be solved, information that gives the local police a more solid direction to the investigation of that crime.
The present article focuses on inference procedures in predictive policing practices, using Bayesian networks and the criminal records from Chicago Police Department [18]. Several algorithms are available to build a Bayesian network purely from data and a comparative analysis was implemented to establish the most precise and efficient one, depending on the attributes of that input. With the fittest Bayesian network found, inference tests were then performed to assess how robust the returned network was.
The remaining of the text is organized as follows. Section 2 conceptualizes and mathematically defines Bayesian networks. An overview of the studies that have been carried out on Bayesian network structure learning algorithms is detailed in Section 3, followed by the description of the proposed methodology for the comparison of them in Section 4 and the discussion of the experimental results obtained from the implementation of this methodology in Section 5. Section 6 presents some final remarks about the ongoing research and directions for future work regarding investigations on statistical inference within the scope of Computational Criminology.
Bayesian networks
Suppose that a study aiming to link the economic situation of a certain city to the oscillations of robbery rate in it was carried out, unveiling the presence of four binary-valued random variables in such scenario. Let the variable
Since the considered variables are all binary-valued, an extensively calculation of the joint probability distribution
Probabilistic graphical models, or simply graphical models, combine knowledge from the fields of Graph Theory, Statistics and Computer Science to provide a generally more compact and efficient framework of a joint probability distribution, which is achieved by contemplating only the dependences between the random variables of the problem for the construction of the probabilistic model [58]. A graph is the usual structure underneath a graphical model, representing the random variables by its vertices or nodes and the statistical relationships between the variables by the presence or absence of edges connecting the nodes that depict them. Therefore, graphs offer a more intuitive way of understanding and abstracting out the conditional independence relations inherent to the problem, a commonly impracticable task by only analyzing the joint distribution table and its probabilities.
The possible structures of the graph underneath a graphical model may be diverse, according to its dynamic and the nature of its edges and random variables [58]. The cases where the graph is acyclic and has only directed edges, or arcs, represent a special class of graphical models called Bayesian networks [40, 51]. Mathematically, a Bayesian network
where
Bringing back the initial example, suppose, then, that a Bayesian network
Bayesian network for the robbery rate problem.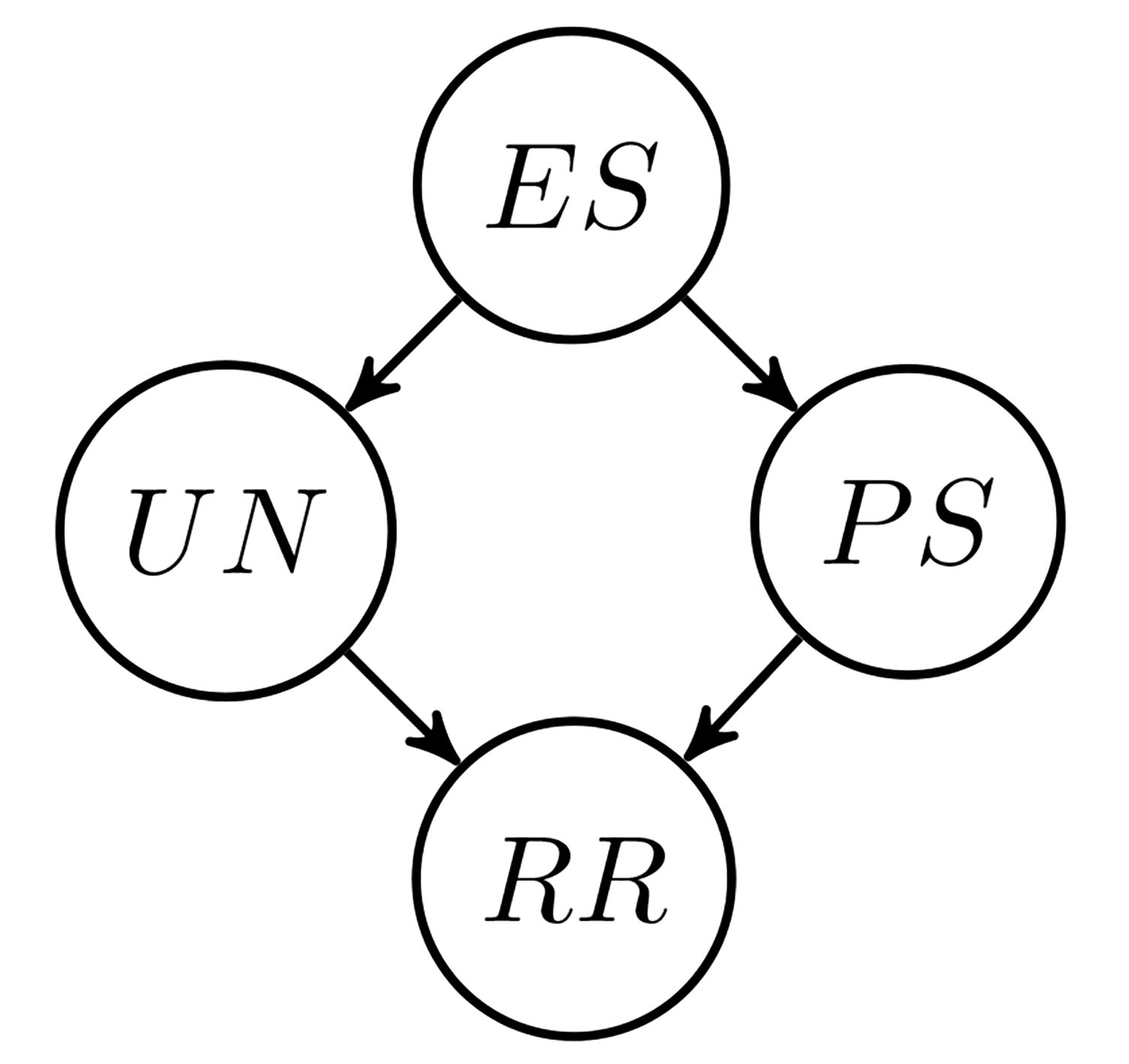
From Eq. (1) and Fig. 1, the joint probability distribution
from which the cardinality of the set of parameters
Following similar reasoning, the second factor demands two parameters to be kept, determined by the values of the conditional probability
In this example, the cardinality of the set of parameters
Modeling real-life problems for reasoning under uncertainty with Bayesian networks used to rely solely upon domain knowledge. Generally, such expert systems were constructed from comprehension obtained with human specialists, a task found to be computational and financially expensive and also highly susceptible to errors [39]. Automating this process of building knowledge for a fully-automated model construction routine was the solution encountered to overcome these issues, a paradigm shift that allowed Bayesian networks to gain notability outside academia and be widely applied in many different fields [58, 51, 39].
Among the most prominent earlier methods developed to learn a Bayesian network purely from data is PC (named after its authors, Peter and Clark [57]), which employs order-increasing conditional independence tests in the set of the problem variables to find, starting from an initial complete graph, the skeleton of the network, thereby reducing the adjacencies between nodes and consequently improving the running times in the following edge-orienting steps [44]. The continuously-growing high dimensionality of the manipulated datasets motivated the development of more efficient learning algorithms, such as Grow-Shrink [44], which implements the conditional independence tests over the Markov blankets computed for each variable in the set instead, making the structure discovery phase faster.
Several other methods were later devised to mainly enhance these ideas. Incremental Association and its variants [61, 67] focused on strengthening the heuristic used to uncover the Markov blankets from Grow-Shrink, in order to avoid variables to be incorrectly attributed to a specific blanket and that would have to be removed in a later stage, augmenting the overall performance time. PC-stable [20] modified the skeleton building phase from PC to resolve the order-dependence supposedly inherent to it that would lead the resulting Bayesian network to depend on the order in which the variables were evaluated during that step. MPC [60], in turn, left the original skeleton building phase unchanged and adjusted the edge-orienting rules to effectively prevent cycles. Parallel-PC [42] incorporated parallelization techniques to improve both the efficiency and accuracy of the conditional independence tests.
In a general framework, all the aforementioned algorithms initially unveil the undirected graph underlying the Bayesian network to be constructed by means of conditional independence tests, or constraints, and then orient the edges of the graph in a sequence of subsequent steps. Employing statistical tests as their typical routines have thus led these methods to be known as constraint-based structure learning algorithms. Score-based algorithms comprise a second group of structure learning methods that obey a more compact framework, by which a series of directed acyclic graphs is constructed and a score for each of them is assigned by a prior specified score function, being selected the graph that maximizes that value, that is, the network with the highest score. This procedure clearly reduces the structure learning exercise to a simpler search problem [46, 36].
Being the search space superexponential in the number of nodes of the Bayesian network to be constructed, an exhaustive evaluation of all candidate networks by a score-based method is thus unfeasible. A primary practice to address this issue would be reducing the size of the search space with the assistance of domain experts, who could establish which nodes were certainly connected and also the direction of the arcs between them [58]. Since expert knowledge is often a resource not easily available, heuristic strategies are regularly implemented as the main nonextensive alternative to tackle the search space size problem in a score-based learning process [36, 43].
Hill Climbing [52], also known as Greedy Local Search, is a heuristic commonly performed for such purpose, by which the search starts from an initial position and continually advances in the direction of increasing value of the evaluated function, until no higher values are obtained. In the context of Bayesian network structure learning, such strategy usually begins with an empty network, or a structure suggested by an expert in the problem domain, and carries out arc operations that do not result in a cyclic network, by adding, removing or reversing the direction of a single arc at a time, until the score assessed to the network obtained from these operations is no longer improved.
The structure returned by this routine may be a local and not a global optimum, though, as it regularly happens with heuristic search algorithms. One widely-known technique to overcome this drawback is to reinitialize the search with an initial state randomly generated after a fixed amount of iterations is completed, being selected the network with the maximum score throughout the whole process [36, 52]. Another popular approach is Tabu Search [29], which keeps a fixed-numbered tabu list of previously visited states that are forbidden to be revisited, allowing the search to escape from local minima and improving the heuristic efficiency as well [52].
For the score evaluation to guide the aforesaid search proceeding, various notable functions have been developed. Akaike Information Criterion [1], Bayesian Information Criterion [53] and Mutual Information Test [21] are examples of information-theoretic-based score functions, while K2 [39], Bayesian Dirichlet and its variants [33, 12, 59, 54] rely on Bayesian computation of posterior probability distributions. Practical guidelines recommend using the functions from the former group with large datasets and those from the latter with small ones [11], although it is not a strict rule.
This search-and-score strategy inherent to score-based algorithms, combined with the conditional independence tests routine intrinsic to the constraint-based ones, constitutes a third category of structure learning methods, called hybrid algorithms. In the first phase of their common two-stage single procedure, a restrict proceeding reduces the set of possible parents of each node in the graph through independence statistical tests, thus lessening the search space of candidate networks or even providing a basic network to work as a seed in the second stage, which seeks to maximize a predetermined score function, evaluated for all the structures in the restricted set returned by the first stage [46, 43].
The routines executed in each of these two stages depend on the hybrid algorithm chosen. A remarkable example is Max-Min Hill Climbing [63], that runs the Max-Min Parents and Children [62] and Hill Climbing algorithms in the restrict and search stages respectively. A more recent hybrid method, called Hybrid HPC [25], employs constraint-based Hybrid Parents and Children [22] to reconstruct the skeleton of the Bayesian network and score-based Hill Climbing to orient the edges, an association that outperforms Max-Min Hill Climbing in terms of goodness of fit and quality of the network structure [25].
Even though such a diversified number of methods has already been developed, the research area of structure learning algorithms is continuously receiving novel contributions. The fact that both Integer Linear Programming and Bayesian network structure learning are NP-complete [13, 24, 49] drove the usage of techniques from the former to encode problems from the latter as an integer linear optimization problem [5, 6]. Evolutionary algorithms, for instance, Particle Swarm Optimization [26, 66, 56], Cuckoo Search [4, 8] and Ant Colony Optimization [69, 68], among others, have been applied to enhance the search routines in score-based learning methods. Remarkable contributions also come from studies employing Simulated Annealing [48, 34] and Learning Automata [27, 28] procedures. These examples show that Bayesian network structure learning remains a research area open to the fostering of more solutions, either original or improved ones, and thus constantly reckoning on comparative analysis of the developed methods so far for further advancements.
Methodology
The methodology employed by the present analysis starts with a data processing step, in which the input is treated by means of data conversion and selection. The processed data then feeds the Bayesian network validation and construction stages, executed both for each structure learning method considered for examination, assessing this proceeding the metrics and graphs to be used by the intended global comparison evaluation. With the most dependable learning algorithm eventually ratified, the data goes through another processing step to extract the subset over which the final model is to be validated and constructed by the established method. After an occasional refinement stage, statistical predictions are then carried out using the definitive model, as a final step. This methodological flowchart is illustrated in Fig. 2.
Methodological flowchart.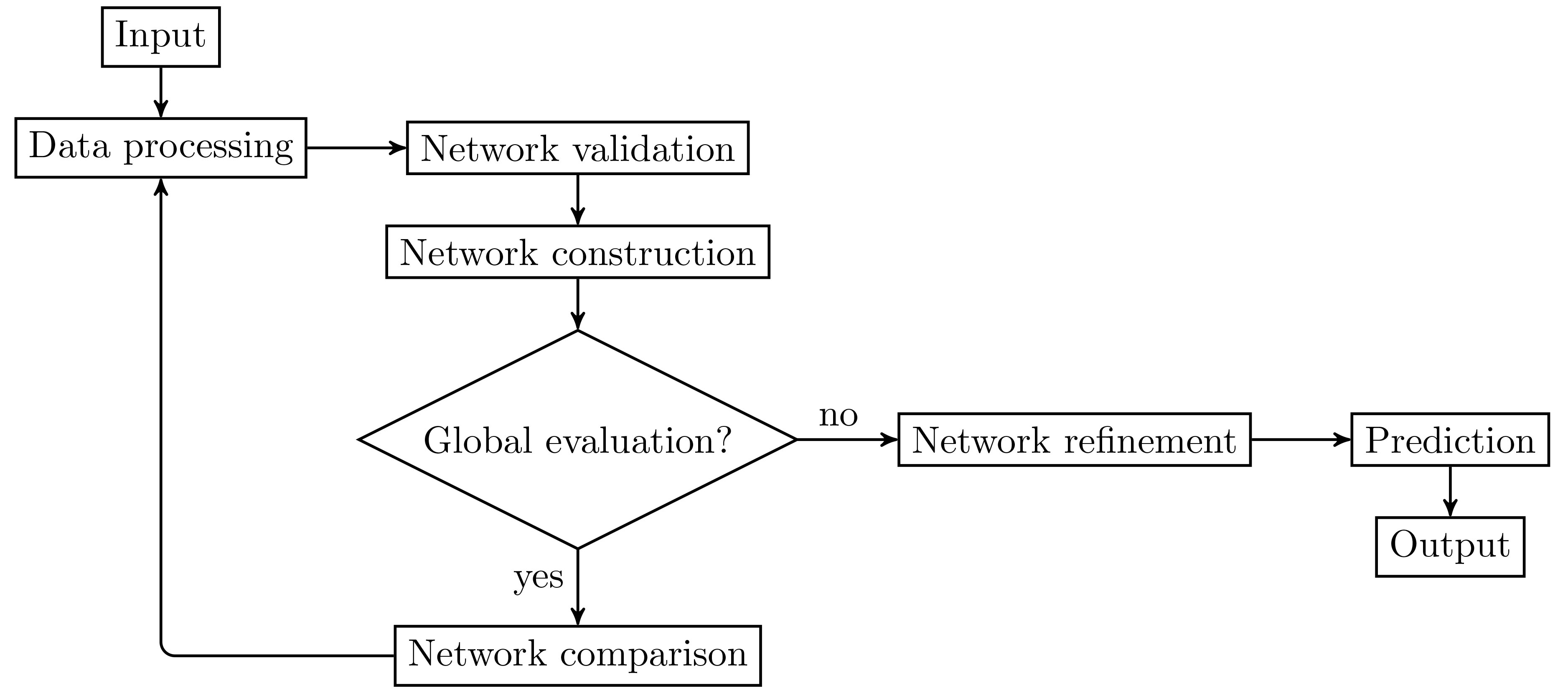
Although devised to describe a fully-automated Bayesian network structure learning routine, domain experts may play a key role during the execution of the methodology described above, for more reliable results. Such part is explained in the next subsections, along with a more detailed exposition of each aforementioned methodological stage.
For the input data, among the criminal records openly provided by police departments from some of the biggest metropolitan cities throughout the globe, such as London [30] and San Francisco [14], those from Chicago Police Department [18] were chosen, as they are more detailed in comparison with the others and include Boolean fields susceptible to be worked as the decision variables for the intended Bayesian networks.
Structurally, the Chicago Police Department dataset comprises more than six million rows, each row representing a reported crime from 2001 to present and characterized by twenty-two descriptive columns. Among these fields, there are two working as unique identifiers for the criminal record; one for the best estimated date and time when the incident occurred and another one for the year; seven depicting, physical and geographically, the location where the crime happened; four locating the occurrence in different sectional divisions of Chicago city; four describing the type of crime; two indicating, in a Boolean manner, whether or not an arrest was made or the incident was domestic-related; and one for the date and time when the record was last updated.
For the global comparison stage, in which different-sized Bayesian networks are built and evaluated in terms of fitting errors and construction times, nine of these twenty-two columns were removed, either for them being mostly empty or representing variables with meaningless information, such as the ID number particular to each register. The data in all of the thirteen remaining columns were handled in their original form, with exception made for the one contained in the field Date, indicating the best estimated date and time when the incident occurred, that was processed to situate the crime in one of the five different parts of the day and renamed to Part.
The criminal records containing blank fields, that is, not completely filled during the register of the occurrence, were likewise discarded, since imputing arbitrary values to complete these faulty records could bias the results. Lastly, the whole dataset was restricted to the period between 2015 and 2017, from the idea that crime, being influenced by the natural non-static social conjuncture where it happens, shows a dynamic behavior over time and so it is more significantly affected by events from short-term past.
Thus, in the data processing step, the comma-separated values file containing the reported crimes obtained from Chicago Police Department goes through a dimensionality reduction by means of field selection, followed it by a data treatment and a sequential temporal constriction to the most recent years. Once this procedure is done, the processed file is then read by a computational routine into a data structure suitable to feed the Bayesian network validation and construction stages.
Bayesian network validation
Several well-established methods are available to build a Bayesian network purely from data, making the assessment of their performance a necessary practice to choose the best one [32]. For this purpose, the input data is randomly split into two mutually exclusive sets, namely, the training set, employed to fit the cogitated models to the data, and the validation set, applied to estimate the error between the instances of this set and their respective predicted values returned by the trained models.
Although theoretical and computationally simple, the error estimated by this routine depends on the way the data is split into the training and the validation sets and may thus highly vary from one division to another [35]. Cross-validation is a traditional strategy commonly used to address this issue that can be applied to almost any structure learning algorithm, as it relies only on the assumption that the input data are independent and identically distributed [3].
Among all cross-validation techniques provided by literature, one of the most widely implemented is
These
where
Bringing Eq. (3) into Bayesian network
be the log-likelihood loss calculated in the
being the most suitable structure learning method, for the given data, the one with the lowest
Regarding how to appropriately choose the parameter
Additional qualitative constraints, provided by expert knowledge, may be incorporated into the validation process to elicit the model parameters, or some of them, and consequently generate a more dependable primary network for the following methodological steps, especially in cases where there is insufficient data. Nevertheless, such practice could bias the structure to be constructed and methods to minimize the risk of errors resulting from it are usually infeasible for larger problems [31, 65]. Since the present study focused on a fully-automated structure learning methodology performed on a robust input dataset, this approach was not considered.
That all explained, the Bayesian network validation step generates random subsets of the processed input data at first, differing them solely in the number
With the purpose to offer a broad comparative analysis of the most prominent available structure learning algorithms, methods from all the three categories theoretically introduced in Section 3 were investigated in the present study. Therefore, the mathematical rules shared in common by the algorithms in each group are explained below, for a better comprehension of the work done.
Constraint-based algorithms
As described in Section 3, the techniques in the first category of structure learning algorithms essentially rely on statistical tests carried out on the dataset. Thereby, let
For these conditional independence constraints, the chi-squared test
expression straightforwardly extensible to the cases where
In Eq. (4), the minuend
where the factors are computed according to the sums
over the observed frequencies
The afore-explained chi-squared test
A two-step edge-orienting procedure follows this graph-constructing stage, starting by detecting the v-structures present in the graph. According to this topological pattern, every set of three variables
Essential framework for constraint-based structure learning methods[1] initialize
Essential framework for score-based structure learning methods[1] initialize
The algorithms belonging to the second group of learning methods are ruled by a comparatively simpler search-and-score framework, presented in Algorithm 4.3.1 and which follows what was previously stated in Section 3. For the score function inherent to this strategy, among all the ones introduced earlier, the Bayesian Information Criterion, also known as Schwarz Criterion, was the methodological choice for both score-based learning routines evaluated, namely, Hill Climbing and Tabu Search.
To mathematically represent the criterion, denote the Bayesian network to be evaluated by
be the total number of configurations over the variables in
where the dividend
that is,
Hybrid algorithms
From Section 3, the methods in the third category of learning algorithms are a hybrid combination of constraint-based conditional independence tests routines and score-based search-and-score strategies. For the present comparative analysis, both Max-Min Hill Climbing and Hiton Hill Climbing methods were executed, the latter being an informal naming of a hybrid implementation of Hiton Parents and Children [2] and Hill Climbing algorithms.
Construction evaluation
The time spent to structure the Bayesian network
Bayesian network comparison
With all the metrics finally estimated, a performance comparison of all learning methods is then executed, to define the most suitable one. From the losses retrieved in Subsection 4.2, it is possible to determine which algorithm returns the lowest fitting error on average; from the time measurements quantified in Subsection 4.3, the average efficiency of each learning method may be established.
In addition to these examinations, the effectiveness of each learning algorithm may also be evaluated through a comparison of the structural logic underneath the Bayesian networks built, by analyzing the presence or absence of connections between nodes as well as the directions of the arcs that represent them, a task suitable to be executed with the aid of domain experts, if possible, for a more dependable network.
Initial reexecution
Once the most appropriate method is established, the methodology goes through another sequence of data processing and network validation and construction. Initially, and to serve the purpose of this analysis, the priorly processed input is further reduced, as many of its descriptive fields offer redundant information and can be discarded. Thereby, only six of those columns remained, namely, Community Area, situating the occurrence in one of the seventy-seven Chicagoan community areas [15]; Location Description, depicting the site where the violation took place; Primary Type, describing the type of the perpetrated crime; Arrest and Domestic, representing both the Boolean variables mentioned in Subsection 4.1; and Part, a treated version of the field Date, as earlier explained.
Subsequently, the processed data once again feeds the network validation and construction steps. While the former aims to determine the overall fitting error particular to the established learning algorithm, the latter focuses on eventually building the definitive Bayesian network
Bayesian network refinement
Since structure learning algorithms are nondeterministic, for relying upon heuristic methods, subtle modifications in the network
The network refinement step thus implements an arc direction check to verify whether or not the implicit cause and consequence associations present in the graph are adequate, reversing the direction of an arc if the dependence relationship depicted by it is not, a procedure where expert knowledge can play a significant role for more faithful results, as in Subsection 4.4. The average loss for the network
Prediction and output
Let
which states that the value of the response
where
where Arrest was chosen to play the role of the response
Equation (7) exemplifies how a Bayesian network may be employed to query about the behavior of some of its variables, in terms of newly observed evidences of some others, through the computation of posterior probabilities, a procedure known as probabilistic reasoning or belief updating [58, 39, 46]. Hence, the answer for a general inference question in a Bayesian network
Prediction with hidden variables is naturally handled by Bayesian networks through stochastic simulation algorithms [58, 39], by which several samples are generated from the network distribution, with the values for the noninstantiated variables randomly chosen according to their respective original conditional probabilities. The posterior probability
Thus, during this step of the methodology, posterior probabilities for the response variable Arrest are inferred, given different sets of evidences for the predictors, by means of likelihood weighting [58, 39, 36, 52], a well-known and literal example of a stochastic simulation algorithm, mathematically proven to return consistent estimations for inference questions in a Bayesian network [39]. In addition to this theoretical guarantee of precision, the results can be further validated by domain experts, by checking whether or not the calculated probabilities relate to what was hypothetically expected.
All the previously described methodology was computationally coded in R language and implemented on a Windows 10 64-bit notebook, with an Intel Core i7-7700HQ processor and 16 GB RAM.
Initially, the criminal dataset from Chicago Police Department went through a dimensionality reduction and a subsequent temporal constriction to the years of 2015 and 2017, as described in Subsection 4.1, returning it a preliminary input data comprised of thirteen columns and 800,718 registers. Among these rows, there were 2,413 containing blank fields that were discarded thereafter, representing only 0.3% of the total. A numerical examination over this processed dataset was then performed to investigate how the fitting errors and the construction times behave, depending on the number of nodes
Number of nodes versus measured metrics for each structure learning algorithm evaluated.
From Fig. 3a, the average losses estimated for all the evaluated methods are approximately equivalent, for networks with
However, this pairwise similitude is not seen in Fig. 3b, where each method shows a particular performance, in terms of construction time. Comprehensively, the curves for Tabu Search and Hill Climbing score-based methods stand out, the former for being higher than the others and the latter for being lower, for most of the values of
Regarding the constraint-based algorithms, all of them returned partially directed acyclic graphs as their solutions to the learning problem, representing them equivalence classes of directed acyclic graphs that were able to adequately represent the intended Bayesian network interchangeably. Such singularity usually occurs when both directions of a specific arc are equivalent, that is, when they identify equivalent decompositions of the global distribution, and are thus left undirected [55]. Since this study aimed to devise a fully-automated Bayesian network structure learning routine, these methods were remarkably not included in this preliminary analysis and in the subsequent ones likewise.
A structure evaluation procedure followed this numerical examination, by which several networks with different sizes were built by each algorithm, providing it material for a comparison of the logic underneath their graphs. Some of these structures are illustrated in Fig. 4, grouped according to the value of
Generated graphs for structure evaluation.
The graphical aspect to be noticed is the inability of hybrid methods to unveil some connections, particularly those between the variables regarding the sectional divisions of the city of Chicago [15, 17, 16] and the remaining ones, generating this issue disconnected graphs, a drawback not seen in the networks constructed by both score-based algorithms. On the other hand, the dependences between the five variables Location Description, Primary Type, Arrest, Domestic and Part were unrestrictedly disclosed, despite some arc directions dissimilarities.
Since the direction established by a learning method to a determined arc may be straightforwardly adjusted as required, while inserting a new one in the constructed network would affect the connections throughout it both direct and indirectly, arc detection is thus a more sensitive proceeding than arc direction, from what is possible to conclude that score-based algorithms offered more reliable structures than those originated by hybrid methods. Upon this observation and the initial numerical analysis, Hill Climbing was thereby evaluated as the most dependable structure learning algorithm among the ones examined.
For a more detailed investigation relating the case study and to consequently ratify the prior conclusion, the validation and construction steps were reexecuted, this time over the dataset of interest, as stated in Subsection 4.5. The overall losses
Numerical analysis for the criminal case study
The measured metrics presented in Table 1 clearly corroborate what was formerly asserted concerning Hill Climbing score-based algorithm. Therefore, the network constructed by it and depicted in Fig. 4c was chosen to represent the Bayesian network for the criminal case study. Before implementing predictions over this structure, an arc direction check was carried out to verify whether or not the implicit cause and consequence relationships were adequate.
Figure 5a portrays the original chosen network from Fig. 4c, prior to any arc direction reversion. Examining the established causal relations between the variables, it is more logical to assume that the node Community Area has an influence on the place where the crime is perpetrated, represented it by the variable Location Description, than the opposite reasoning, as a violation in an apartment is more likely to be committed in a residential area than in an industrial one, for example, and hence the arc between those nodes was reversed. An analogous thinking can be made regarding how the local in which a crime occurs depends on the part of the day, and so the arc connecting the respective nodes Location Description and Part had its direction changed likewise.
Both arcs incident to the node Domestic were also reversed, from the logic that a domestic-related crime is a consequence, and not a cause, of the relations between the actors of it. Finally, the outlined dependence between the variables Location Description and Primary Type was also inverted, since the offense can be thought as the outcome of a local opportunity found by the criminal to execute it.
The structure after the specified reversions, represented by dotted lines, is illustrated in Fig. 5b. Recalling the explanation made in Subsection 4.6, this refinement procedure reasonably improved the fitting error of the constructed network and a gain in the overall loss was indeed observed between the graphs in Fig. 5, where the mean error dropped from 10.86045027 for Fig. 5a to 10.81592963 for Fig. 5b.
Bayesian network for the criminal case study.
Having the definitive Bayesian network
Predictions for the response variable Arrest
The first block in Table 2 comprises predictions with the set
Scenarios with hidden variables are investigated in the following blocks. The second one in the table shows that an assault in an apartment is unlikely to be clarified, independently of the community area where it happened and whether it was domestic-related or not. Analogously, from the third block, it is possible to infer that batteries or thefts perpetrated inside an aircraft are highly probable to remain unsolved, with a resolution probability even lower if they were committed somewhen during morning or evening.
A different behavior for the response variable is observed in the fourth block, regarding homicides. Without any evidences for the remaining predictors, this felony has a low to average chance of elucidation. However, once it is evidenced that the crime occurred in a house or a restaurant, the probability assumes a much higher value and the response state changes from false to true. This same positive output was ascertained for all the analyzed cases involving narcotics presented in the fifth block of predictions, ensuring it that drug violators are captured with probability approximately 1, whichever part of the day when the offense ensues.
Criminology is an essentially sociological science which started adopting concepts from Applied Mathematics, Statistics and Computer Science just recently. Such movement not only offered original solutions to established criminological questions, but also allowed the development of novel practices to understand or even fight against violence, being crime prediction a prominent example. In this work, a comparative analysis of Bayesian network learning algorithms was implemented to uncover the most suitable structure to model a criminal dataset, yielding it a tool for crime prediction through statistical inference. For this purpose, several Bayesian networks were primarily constructed by different methods to assess the most reliable and efficient one, in terms of fitting error, construction time and structural logical. Once such model was found, the Bayesian network over the data of interest was eventually constructed, providing the definitive statistical tool to execute the in tended crime prediction task. From the results obtained, it is possible to observe that predictive policing can be accomplished by means of Bayesian networks, since they depict the dynamics of crime in a particular location in a more comprehensible way, offering a preventive paradigm for police action, therefore.
Since the reported comparative analysis focused, in this first phase of a broader study, on the more traditional Bayesian network structure learning algorithms, the application of the outlined methodology using more up-to-date methods is contemplated as a direction for future work. Employment of criminal data other than those from Chicago Police Department, as well as an investigation of the use of different graph structures to model the intrinsic relationships between the data variables, such as Petri nets, are likewise planned.
Footnotes
Acknowledgments
This work was supported by São Paulo Research Foundation [grant number 2017/02073-6].