
Abstract
In the area of time series data mining, a challenging task is to design an effectively and efficiently low-dimensional representation of high-dimensional time series data. Such an effective and efficient representation is important for dimensionality reduction of time series while preserving the core information embedded in the original one. Among popular representations of time series, Symbolic Aggregate approXimation (SAX) has been widely used and is the core of many successful time series data mining systems. SAX firstly normalizes the given time series, then divides a time series into segments and finally assigns each segment a symbol based on its average value. In fact, many segments have different shapes but the same average value are mapped to a sole symbol. In order to overcome this drawback, in this work, we propose an improvement of SAX by using complexity invariance, namely Complexity-invariant SAX (CSAX). In particular, our proposed method transforms a time series into a sequence of symbols based on both average values and the complexity invariance of its segments. By experiments, we demonstrate that CSAX outperforms the SAX and its improvements, i.e., ESAX, SAX_TD, SAX_SD, in time series classification.
Introduction
Time series data is ubiquitous in real-life areas range from economics, finance, climate change, biology to medicine. However, the challenge is that time series data has high volume, high dimensionality and massive amount of noise. Therefore, many representation methods have been proposed to decrease runtime and storage space for time series mining. To date, most common representation methods are Discrete Fourier Transform (DFT) [1, 2], Discrete Wavelet Transform (DWT) [3], Discrete Cosine Transform (DCT) [4], Singular Value Decomposition (SVD) [5], Piecewise Aggregate Approximation (PAA) [6], Adaptive Piecewise Constant Approximation (APCA) [7] and Symbolic Aggregate Approximation (SAX) [8].
SAX have had a significant influence on the improvements of time series data mining tasks [9]. This representation consists of two main steps to transform a time series into a sequence of alphabetic symbols. The first step transforms the original time series into Piecewise Aggregate Approximation (PAA) representation based on the average values of equal-sized segments. The second step converts the PAA representation of the time series to a symbolic string. As pointed out in [8], the most important characteristic of SAX is that it lower-bounds Euclidean distance. As a result, it speeds up the execution time of time series data mining applications, as well as maintains the performance of mining results [8]. Therefore, SAX has been successfully employed in many applications of various domains, such as shape discovery [10], semantic sensor network [11] and mobile data management [12].
Two different time series have the same SAX representation “bcbcba”.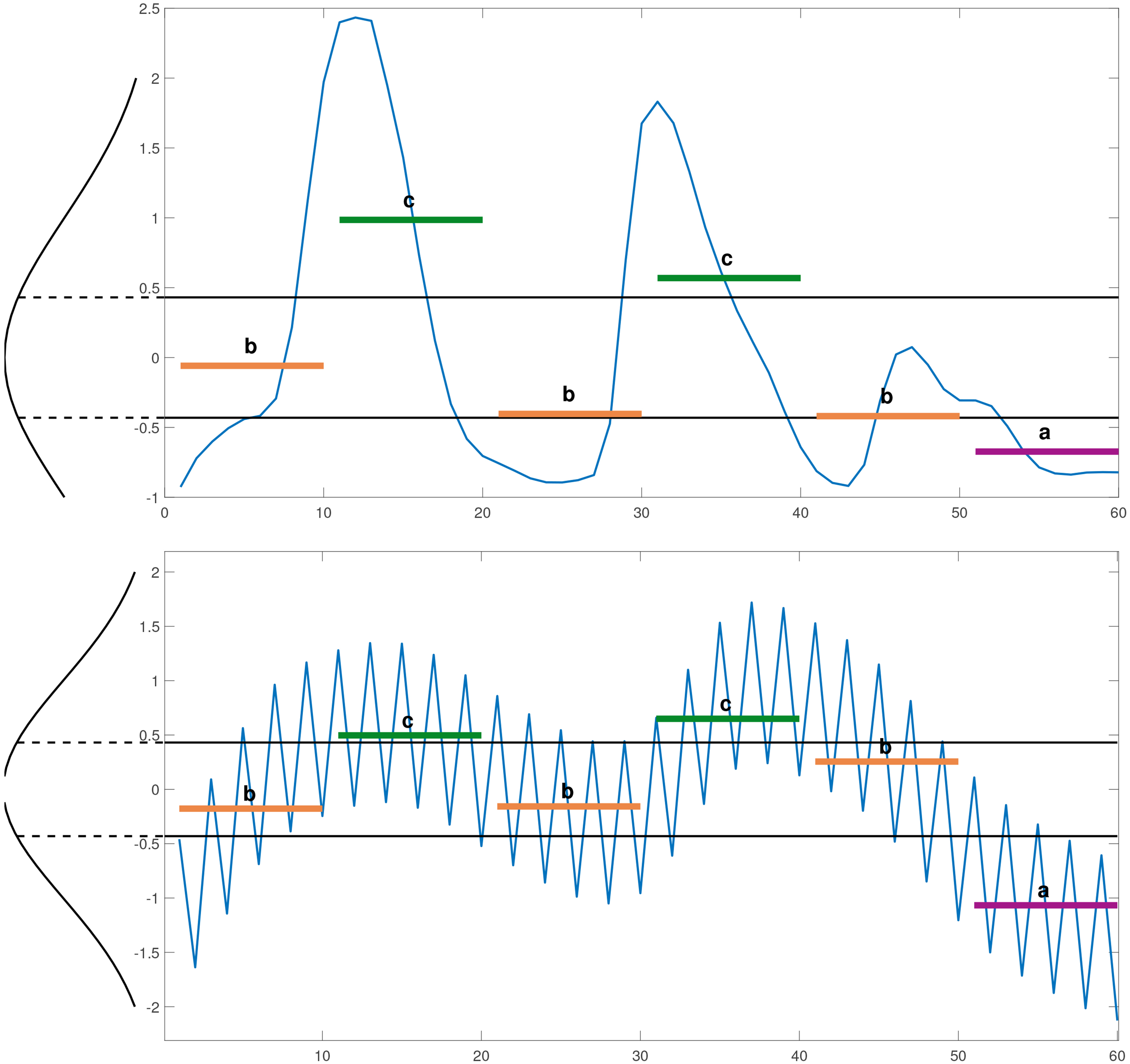
However, the major drawback of SAX representation is that it transforms time series to symbols based on the average values of the segments and ignore important information in the segment. Hence, several different segments having the same average value may be mapped into the same symbol, which is prone to errors in similarity search and classification. Figure 1 shows two very different time series in shape, trend and complexity invariance, but have same SAX representation “bcbcba”. In order to overcome this drawback, some improvements of SAX have been proposed [13, 14, 15].
Extended SAX (ESAX) [13] improves SAX by using additional two discrete points, e.g., maximum and minimum points, besides the average value of a segment. SAX_TD [14] overcomes the drawback of SAX based on a trend distance using the starting and the ending points of segments. Then, the original SAX distance is integrated with weighted trend distance to form the SAX_TD’s distance measure. Alternatively, the improvement based on its statistical features has been proposed in [15], called SAX_SD. Besides storing the symbol of original SAX, SAX_SD uses the standard deviation of the corresponding segment to make more efficient performance.
Recently, complexity invariance has been successfully exploited in time series classification tasks [16]. Intuition tells us that six different time series shown in Fig. 2 are different in complexity invariance (at 0.0951, 0.07231, 0.05866, 0.04836, 0.02364, 0.0093 in the order from left to right and top to bottom), but the same in average values (at 0) and trends; very similar in their starting and ending points; approximate in standard deviation. Hence, the complexity-invariant values may help improving the performance of time series classification and also of time series representation.
Six time series are different but they have the same average value (at 0).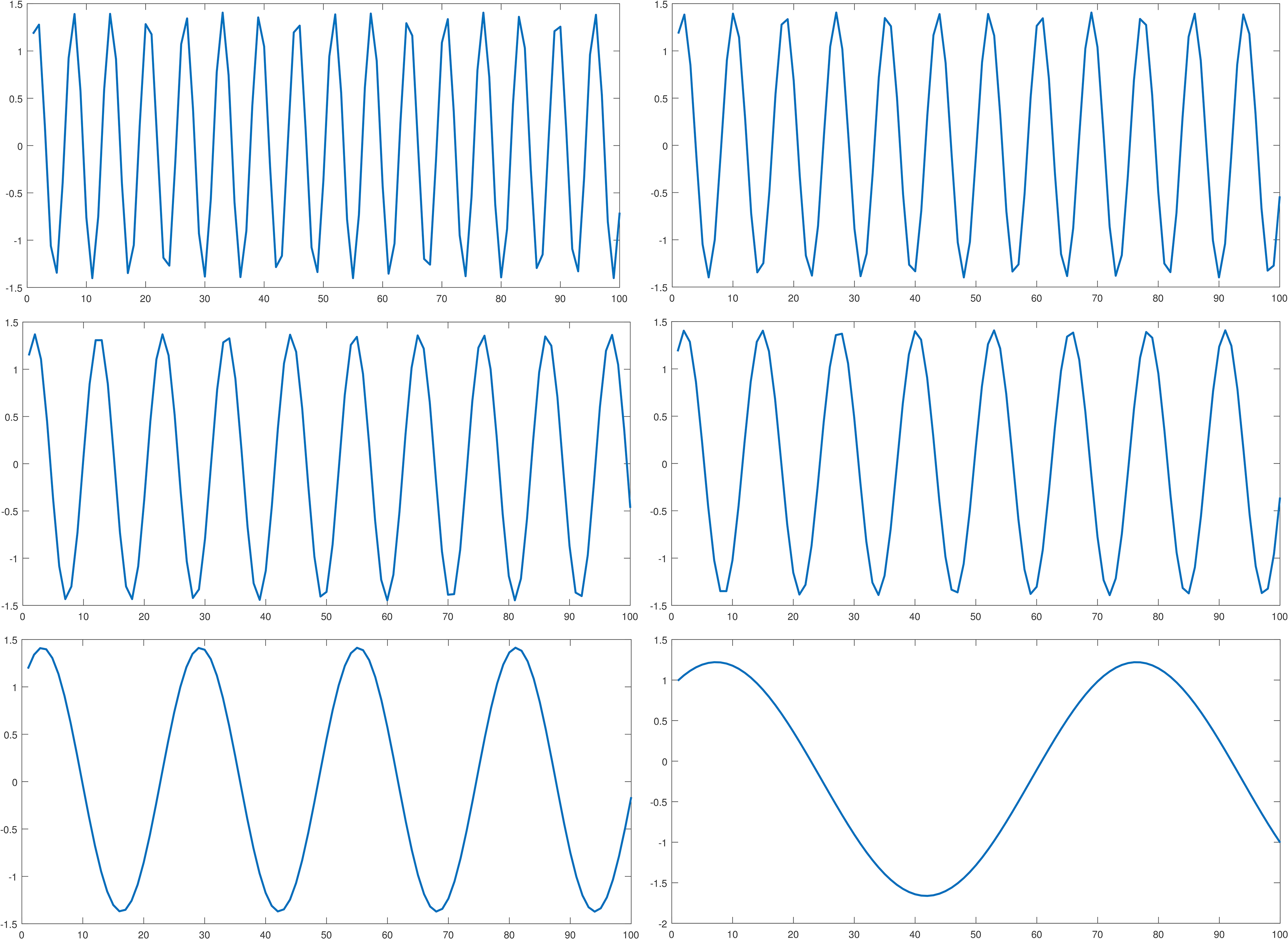
In this work, we proposed a novel representation of time series, called CSAX. Our method represents time series to sequence of original SAX’s alphabetic symbols and the complexity-invariant value. We also create a new distance measure for our representation. Our comprehensive experiments in time series classification demonstrate that CSAX outperforms SAX and its state-of-the-art improvements. It also has dimensionality reduction ratio better than SAX. In other word, the main contributions of our work are as follows: (1) we propose CSAX that improves SAX representation by using complexity invariance, (2) we define a new distance measure based on CSAX, and (3) we conduct experiments to evaluate CSAX and show that it outperforms SAX and its state-of-the-art improvements.
The rest of our paper is organized as follows. Section 2 presents background and related work. Section 3 presents CSAX and new distance measure based on CSAX. Section 4 presents experiments and evaluation. Finally, we draw conclusion in Section 5.
Time series
A time series X is a sequence of real numbers collected at regular intervals over a period:
Some time series in ECGFiveDay dataset in UCR Time Series Classification Archive.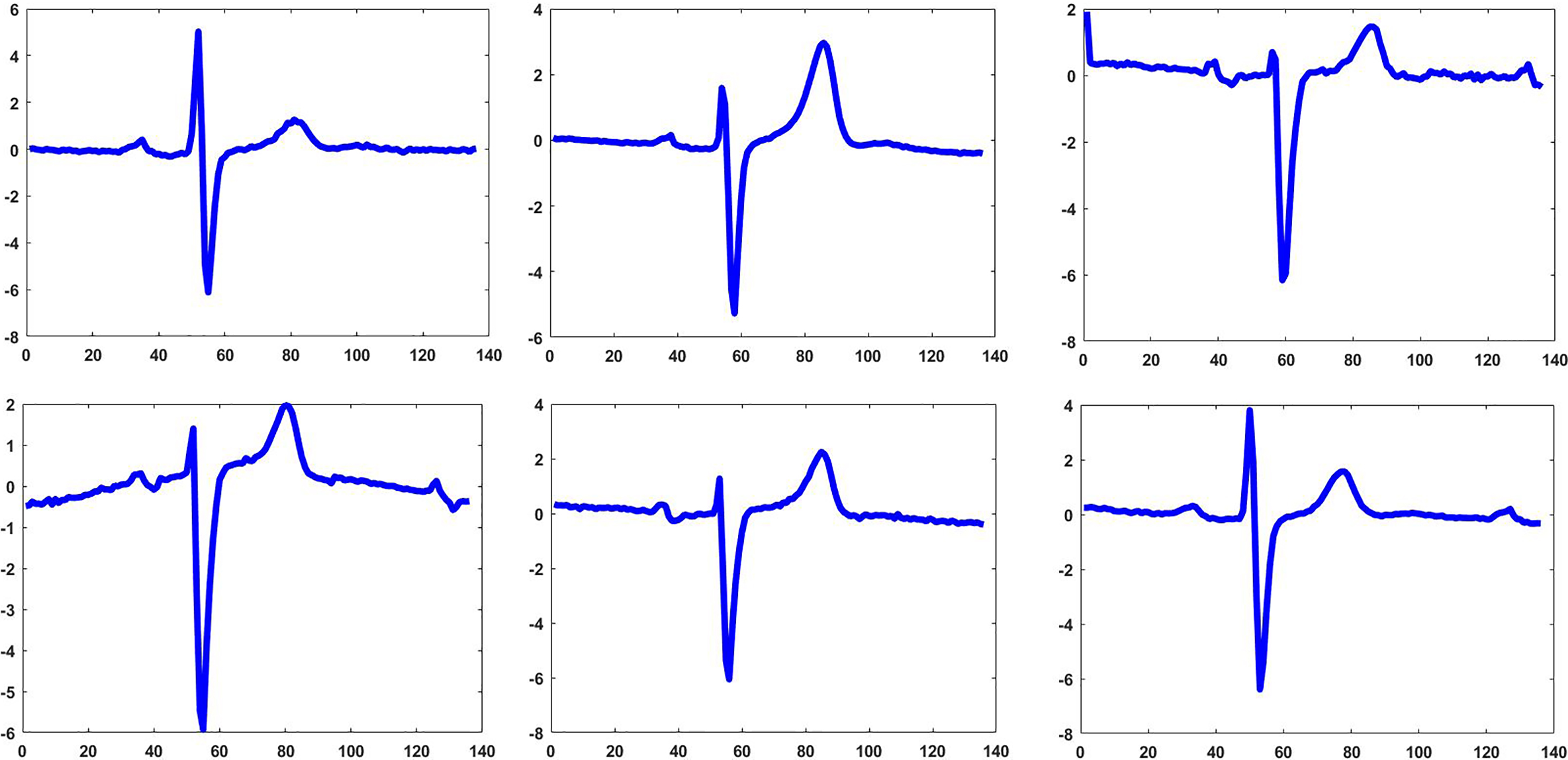
SAX is a most well-known symbolic representation of time series. It transforms the original time series with the length
The time series is transformed into Piecewise Aggregate Approximation (PAA) representation [6]. The PAA representation divides the time series
where
Figure 4 shows an example of SAX for time series representation.
An example of SAX Representation for a time series data in Yoga dataset [23] (time series of length 426 is mapped to the sequence of symbols as “eddbbedaaaacdbce”, the segment size, 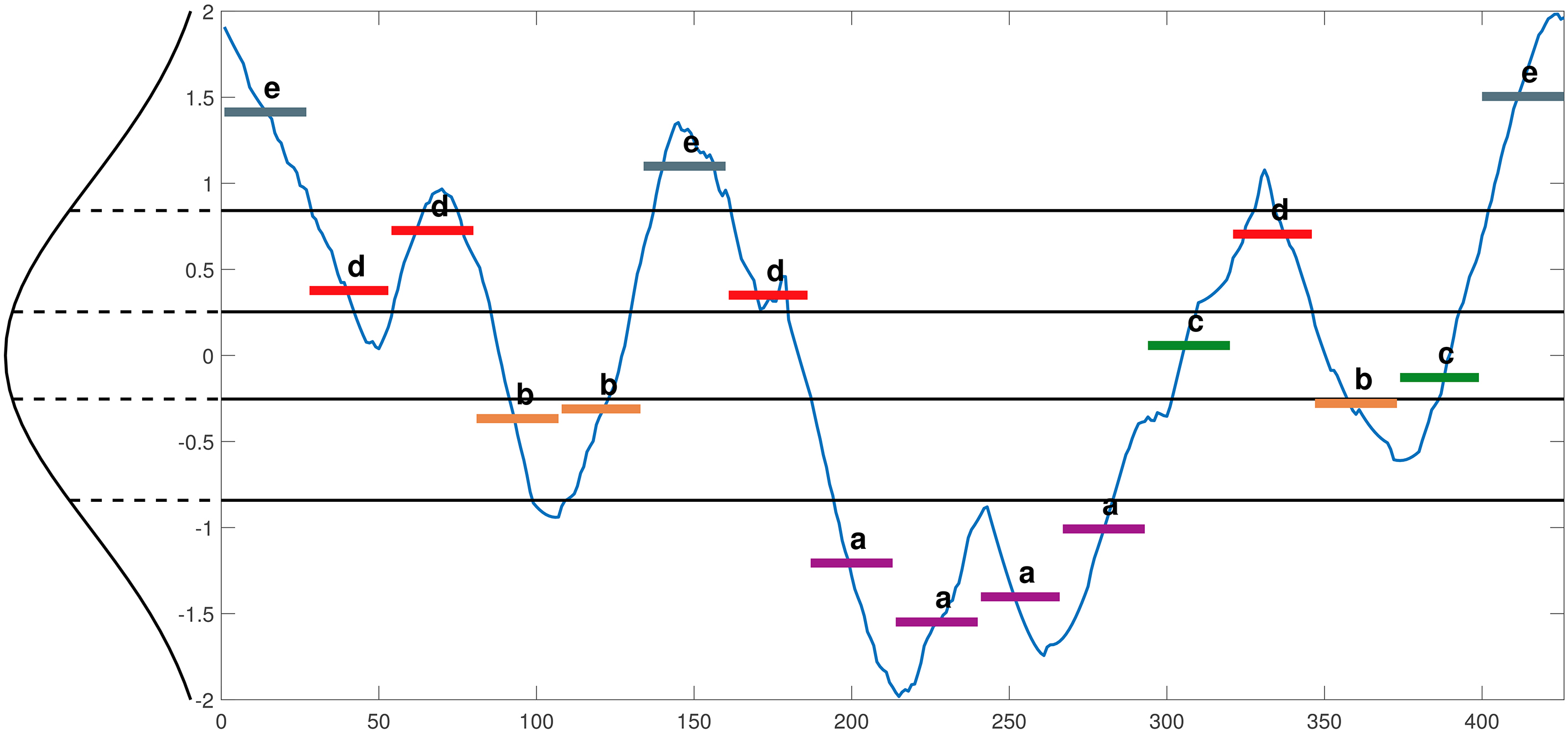
The PAA coefficients are mapped to alphabetic symbols based on the breakpoints
Given two time series
where
Table 2 shows the sample of lookup table for MINDIST function.
In the case of real-valued time series, Euclidean distance is one of the most well-known methods. Given two time series
SAX just uses the average values to represent the time series. Hence, it ignores some important information. This drawback causes errors in classification and other data mining tasks for time series. In this section, we introduce improvements of SAX in time series classification.
In [18], Hugueney introduced a method that uses Adaptive Piecewise Constant Approximation (APCA) [7] in place of PAA [6] in original SAX. In [19], Marwan et al. proposed Genetic Algorithm SAX (GASAX) to determine breakpoints based on Genetic Algorithm (GA) [20]. The authors argued that Gaussianity’s assumption oversimplifies the problem of SAX representation and may result in high values of error when performing time-series mining tasks. The objective of GA is to find the configuration that provides the best value of a fitness function [19]. The configuration means the optimal or nearly optimal solution for the problem. It has the following elements: a individual’s population, selection according to fitness, crossover to produce new offspring, and random mutation of new offspring. Although GASAX works well on both normalized and non-normalized time series data, GA needs to determine the appropriate control parameters for its elements and it is important to keep a balance between elements to obtain an optimal solution.
Then, Extended SAX method (ESAX) is proposed by Lkhagva [13]. This representations improved original SAX by adding two new points (min and max points) besides the average values in each equal-sized segments. After that, those points are transformed into alphabetic symbols by the same way of SAX. ESAX has been demonstrated to be effective for financial time series data. However, the storage space of ESAX is triple times than that of SAX representation and the execution time of ESAX is significantly higher than the original SAX.
In 2015, Yin et al. proposed a method called Trend Feature Symbolic Approximation (TFSA) [21]. It uses a two-step segmentation technique to segment long time series data rapidly. TFSA proved that it guarantees the lower bounding distance, better segmentation, and classification accuracy. In 2013 and 2014, there are two methods that improve the original SAX by using trend feature of time series: 1d-SAX [17] of Malinowski et al. and SAX-TD [14] of Youqiang et al. The trend feature in 1d-SAX is calculated by using the quantization of linear regression on each segment. That is why the method called 1d-SAX [17]. SAX_TD uses the value of starting point and ending point to determine the trend feature of each segment. The experimental results in [14] show that SAX_TD outperforms the original SAX and ESAX.
SAX_SD is other improvement of SAX [15]. It is proposed by Zan et al. It improve the SAX by using the standard deviation values and average values to represent the time series. The authors in [15] indicated that SAX_SD outperforms the original SAX, ESAX and SAX_TD.
The original SAX has been improved in various different aspects in different tasks. However, the complexity invariance of time series is still not exploited. Figure 2 shows the major limitation of the original SAX and its improvements. Hence, in order to overcome this drawback, we propose a novel improvement of SAX.
Complexity invariance measure for time series
It was first proposed by Yan et al. [22] and was used by Batista and Keogh [16] for enhance the accuracy of their novel distance measure, called Complexity-invariant Distance. It is based on the fact that complex time series are commonly considered more similar to simple time series than to other complex time series they look like. For instance, in Fig. 2, we have six time series with the same in average value (at 0), the same trend, very similar in their starting and ending points, and approximate in standard deviation. The only different between those time series is the complex of them. In [16] the time series’ complexity invariance is calculated by Eq. (5)
CSAX: Complexity-invariant SAX
This section presents a novel representation for time series. It is an improvement of SAX representation by using complexity invariance, namely CSAX. In particular, given a time series, our method provides an additional complexity-invariant feature besides the average feature of SAX representation. The complexity invariance that we use in CSAX is a significant important feature to determine difference in shape of time series. As shown in Fig. 2, six different time series are the same in average value; similar in values of starting and ending points (the features which SAX_TD exploit); similar in maximum and minimum points (two new additional points in ESAX), respectively; the same in up and down trend; and the same standard deviation value (SAX_SD uses the standard deviation as an additional feature). However, those time series in Fig. 2 are different in the complexity-invariant values: 0.0951, 0.07231, 0.05866, 0.04836, 0.02364, 0.0093, decreasing from the first time series to sixth time series, respectively. It means that the complexity invariance can help to fix the limitation of the original SAX representation and its improvements.
Our method transforms the time series to a sequence of alphabetic symbols in an alphabet based on the original SAX. Then, it calculates complexity-invariant value of each segment corresponding to a symbol in the sequence. In particular, given a segment of a time series
where
A novel distance measure for CSAX is defined based on the sequence of symbols and their corresponding complexity-invariant values. Given two time series
where
In the term of dimensionality reduction, the time series of length
SAX-CID and SAX distance with different values of
Description of 20 datasets in UCR Time Series Classification Archive [23]
In this section, we present experiments to evaluate CSAX. Firstly, we introduce the used datasets, comparison methods, and parameter settings. Then we compare the experimental results of our proposed CSAX with those of Euclidean distance, the original SAX, ESAX, SAX_TD and SAX_SD in the terms of classification error rate, dimensionality reduction and efficiency. We implemented methods in Matlab R2016a and conducted the experiments on an Intel(R) Core(TM) i7-4700MQ CPU @ 2.40 GHz, 16 GB RAM, Lenovo y510p Laptop.
Datasets
We use first 20 datasets in UCR Time Series Classification Archive [23] in order to compare with the previous methods that were evaluated on the same datasets. Each dataset is divided into a training set and a testing set. Table 4 shows the brief description of each dataset: name, number of classes, size of training and testing set, length of the time series and its type.
Comparison methods and parameter settings
We deploy the same comparison method used in [14, 15] for evaluation. In particular, we compare the experimental results of our proposed CSAX with those of Euclidean distance, the original SAX, and three other improvements of SAX: ESAX, SAX_TD and SAX_SD. The reason to choose these three improvements is that distance measures for these representations have been modified as well. Because 1-Nearest Neighbor (1-NN) classifier directly reflects the performance of the distance measures, we use this classifier to compare their classification accuracy. For Euclidean distance, we do not need to set any parameter because it is a parameter-free distance. For other distances, i.e., SAX, ESAX, SAX_TD and SAX_SD, two parameters that are
Given time series of length
Searching the value of Searching the value for Choosing the smaller set of parameters (priority
For the dimensionality reduction ratio, we measure this ratio using Eq. (8) [14].
Reduction ratio and space complexity of each representation in comparison
Based on Eq. (8), we show the dimensionality reduction ratio and the space complexity of each comparison method in Table 5 where
The sign test results of CSAX vs. other methods. A
-value less than or equal to 0.05 indicates a significant improvement
The sign test results of CSAX vs. other methods. A
1-NN classification error rate of Euclidean distance, the best error rate of 1-NN classification, the best set of
Classification error rate of compared methods with different values of parameters 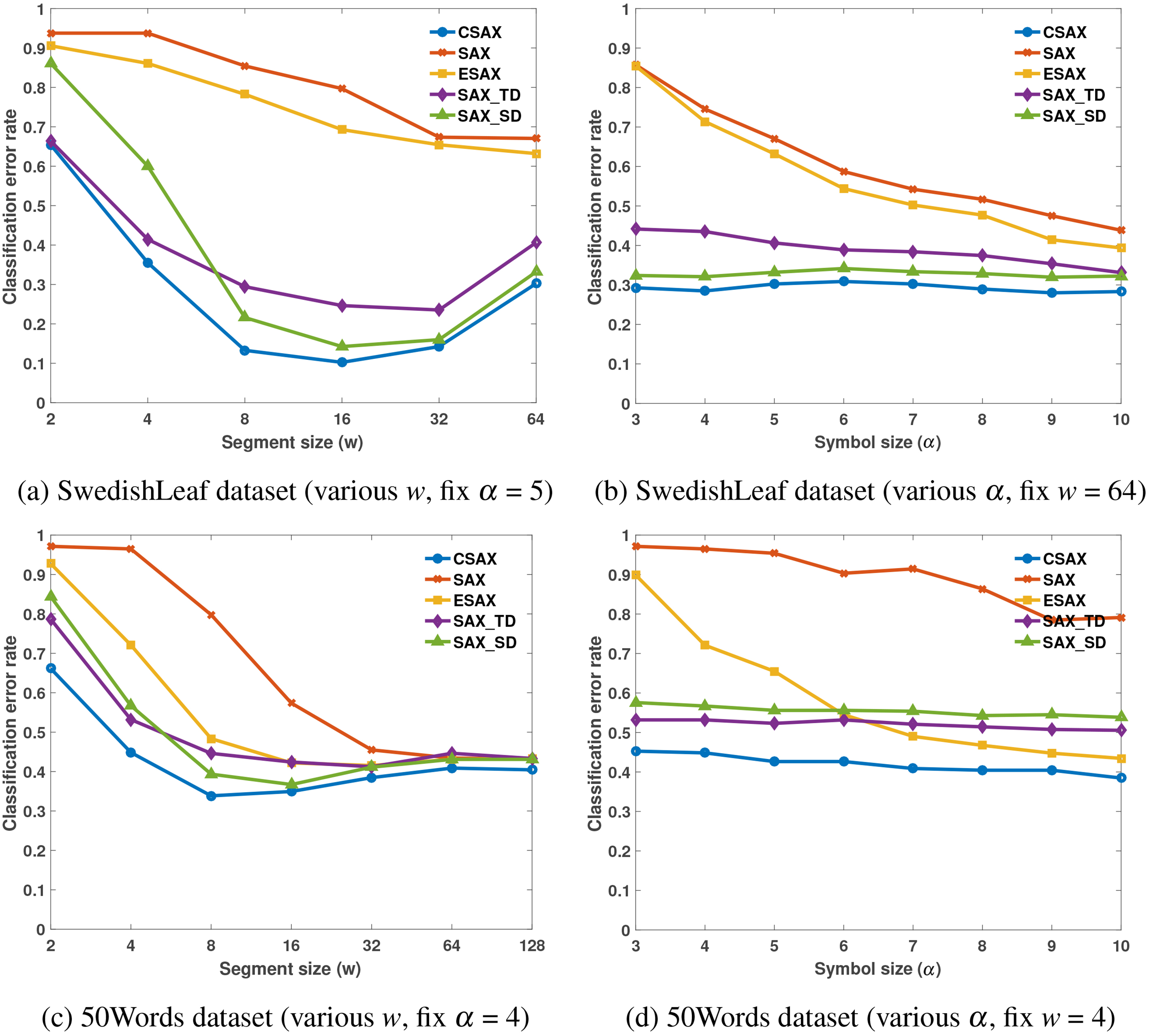
The scatter charts indicate the pairwise of error rates of our proposed CSAX and Euclidean distance, distances of SAX, ESAX, SAX_TD, SAX_SD on 20 datasets in UCR Time Series Classification Archive. In the lower triangle, the square points illustrate the datasets in which our CSAX is more accuracy than other methods. In Upper triangle, the round points illustrate the datasets in which other methods are more accuracy than CSAX. In diagonal line, the triangle points illustrate the datasets in which our CSAX and other methods have same accuracy.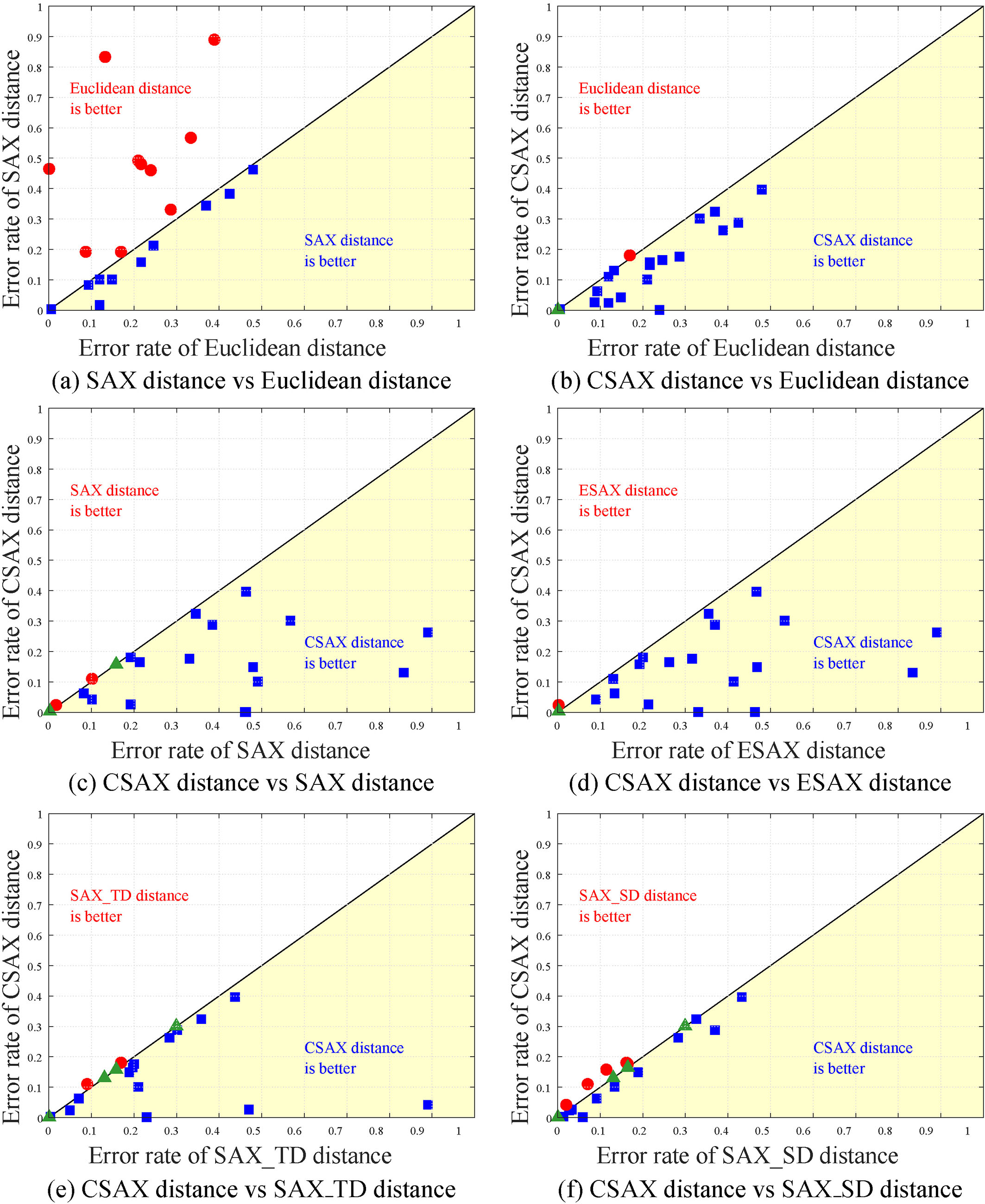
The running time of five compared methods with different values of the parameter 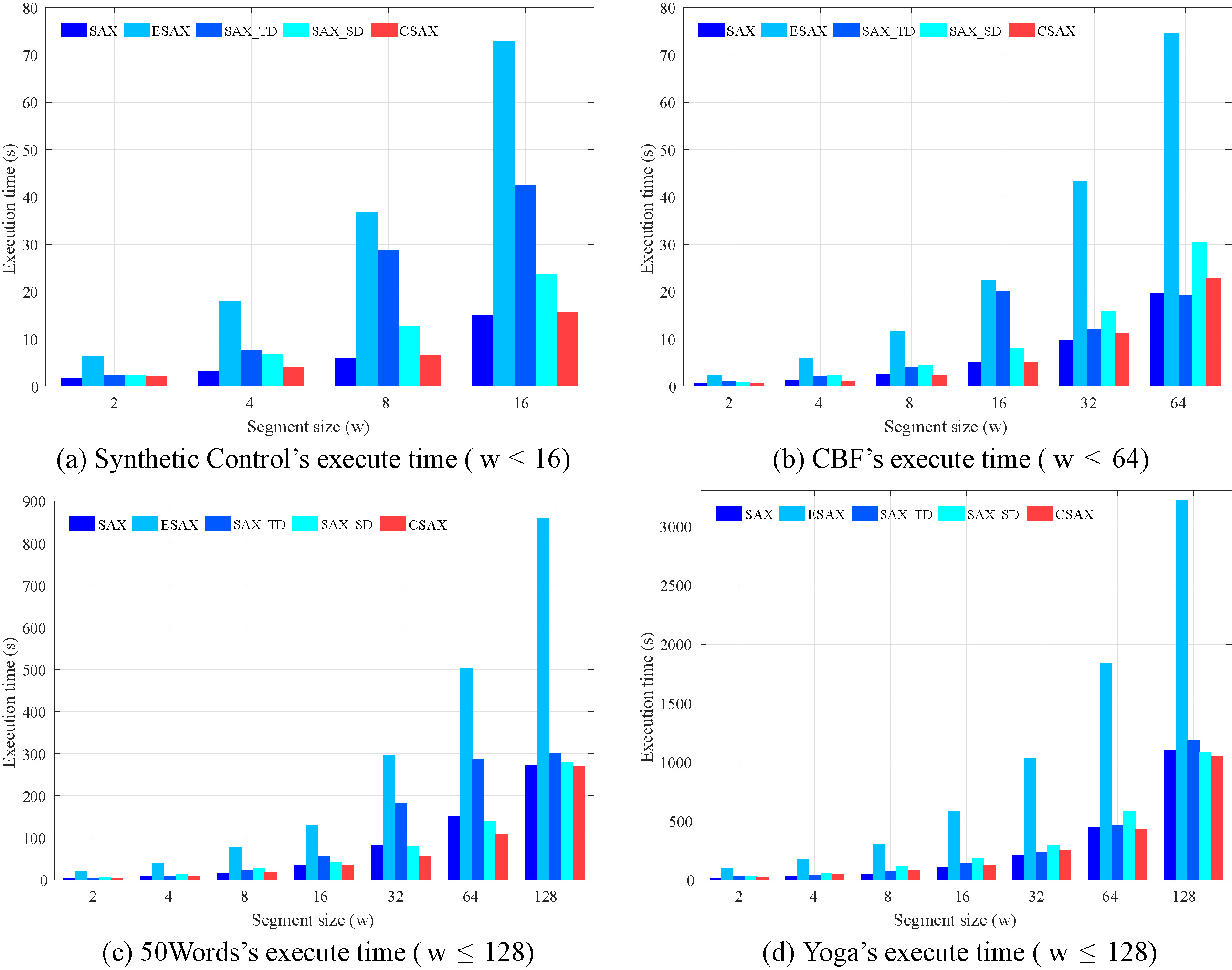
The dimensional reduction ratio of SAX, ESAX, SAX_TD, SAX_SD, and proposed CSAX
Table 6 shows the overall results of 1-NN classification in 20 datasets represented in Table 4. In which, we highlight the lowest classification error rates for each distance measure. The proposed CSAX has the lowest error rate in most of datasets (15/20). SAX_SD has the lowest error rate in 7/20 datasets, followed by SAX_TD and ESAX with 2/20 datasets. Finally, the original SAX and Euclidean have the lowest error rate in just 1/20 dataset. In Table 7,
In Fig. 5, we provide four line charts to compare CSAX with SAX, ESAX, SAX_TD, and SAX_SD using different parameters
We provide six scatter charts for illustrating the performance of pairwise distance measures in Fig. 6. In those charts, error rates of two compared methods are used as the
In Fig. 6b–f, we compare our proposed CSAX with Euclidean distance, SAX, ESAX, SAX_TD, and SAX_SD, respectively. In general, our proposed CSAX outperforms other methods in the number of data points in its region and the distances of these points from the diagonal line. Especially, in Trace and Fish datasets, CSAX has the error rate at 0 and 0.149, respectively, while the lowest error rate of other methods at 0.06 (the error rate of SAX_SD) and 0.189 (the error rate of both SAX_TD and SAX_SD), respectively.
We provide the comparison of the running time, with various
Since the difference in computation time is mainly determined by the value of parameter w, we fix the value of
Dimensionality reduction ratios of the SAX, the ESAX, the SAX_TD, the SAX_SD, and CSAX on 20 data sets with their smallest error rates.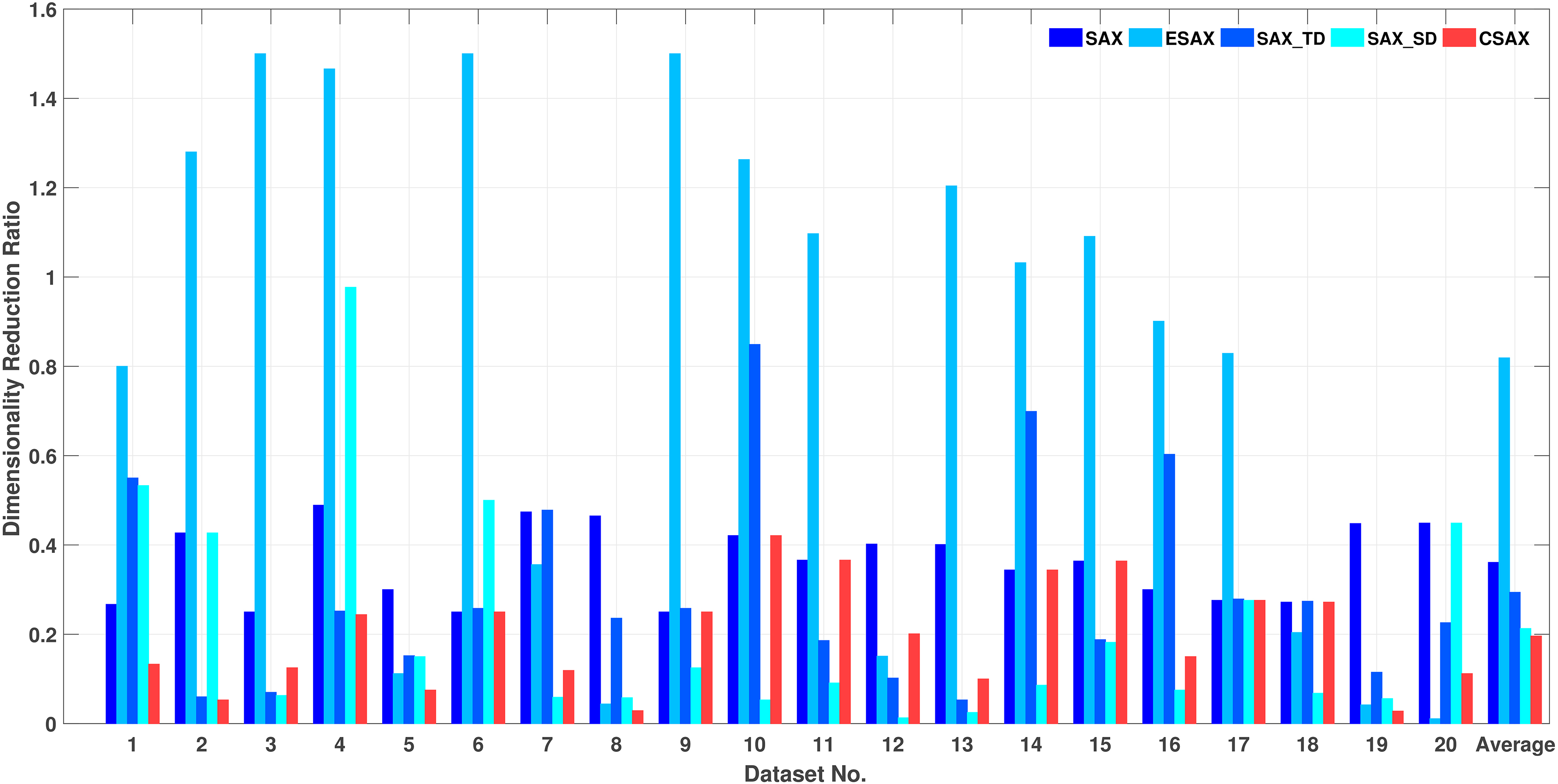
Overall, the running time of CSAX is similar to the original SAX and lower than those of ESAX, SAX_TD and SAX_SD in most of different
Finally, SAX is very well-known for dimensionality reduction with the ratio (
In this paper, we first summarize the background knowledge of SAX representation and its most well-known improvements. Then, we point out the drawback of SAX and propose a novel improvement of SAX representation, called CSAX. CSAX uses the complexity-invariant values of segments of the original time series as additional features besides the average values used in the original SAX. The experimental results demonstrate that CSAX outperforms SAX and its three well-known improvements, i.e., ESAX, SAX_TD and SAX_SD, in 20 dataset of UCR Time Series Classification Archives in the terms of classification accuracy and dimensionality reduction ratio. In addition, CSAX also achieves computational efficiency better than that of ESAX, SAX_TD, and SAX_SD.
We have gradually entered into a new era of Internet of Things (IoT), where billions of connected devices constantly produce a tremendous amount of streaming time series in a period of time. One can first apply CSAX to transform each time series into an alphabetic string, then adapt language model pre-training such as word2vec [26] or Transformer [25] in the field of natural language processing or the embedding of DNA reads [27] in the field of computational biology to learn distributed representations of the obtained alphabetic strings in the unsupervised setting. After that, the pre-trained models are exploited to extract features or fine-tune for downstream tasks such as classification, clustering, or search of time series. In [24], the authors initially prove that the distributed representation of time series, namely Singnal2vec, trained by using Skip-gram model [26] outperforms SAX and PAA. We put these lines of research in future.