
Abstract
Within the graph mining context, frequent subgraph identification plays a key role in retrieving required information or patterns from the huge amount of data in a short period. The problem of finding frequent items in traditional mining changed to the innovation of subgraphs that recurrently occurs in graph datasets containing a single huge graph. Majority of the existing methods target static graphs, and the distributed solution for dynamic graphs has not been explored. But, in modern applications like Facebook, robotics utilizes large evolving graphs. The goal is to design a method to find recurrent subgraphs from a single large evolving graph. In this research paper, a novel approach is proposed called DFSME, which uses SPARK to discover frequent subgraphs from an evolving graph in a distributed environment. DFSME maintains a set of subgraphs between frequent and infrequent subgraphs, which is used to decrease the search space. Our experiments with synthetic and real-world datasets authorize the effectiveness of DFSME for mining of recurrent subgraphs from huge evolving graph datasets.
Introduction
Data mining is the method of acquiring information from a vast amount of data. Mining is common in many applications, such as transportation, medicine, social networks, bioinformatics, communication networks, robotics, and link analysis. Multi-relational data mining is a recent research topic, regarding the finding of a pattern from a composite dataset [48]. Extracting knowledge or information from a composite dataset is a difficult task because of its exponent growth. An effective methodology is required to handle such massive data. The graph data structure is the best way to represent complex datasets, and it is incorporated in most applications. In the traditional method, finding frequent items in an evolving database is a hectic task. Similarly, finding recurrent subgraphs from graph dataset is difficult. Frequent subgraph mining (FSM) is the method of identifying entire subgraphs that are recurrent in a graph dataset. To discover recurrent subgraphs, many methodologies have been proposed over the past two decades. Many applications use this frequent subgraph mining technique and achieve maximum utilization. For instance, nuclear smuggling is a hazardous threat in the modern world. Mining the patterns from nuclear smuggling data prevents the threat, and the information garnered can be used for further investigations. Since this data is dynamic, a novel approach is required to handle the data efficiently and effectively. Most professional organizations use configuration management databases to illustrate the IT infrastructure entities and their relationships.
Mining a configuration management database graph for recurrent subgraphs can disclose infrastructure patterns. IT policies can be framed using these patterns. So, FSM is useful and utilized in many fields. To quickly discover subgraphs, a distributed solution is needed. FSM-H and MRFSM were proposed, which uses a MapReduce based framework [7, 35]. But this problem will work for static graphs. Yan and Han investigated recurrent graph-based pattern mining in a graph dataset and used a method called gSpan that discovers frequent items without candidate generation. The Depth-First Search (DFS) lexicographic approach is applied to efficiently mine recurrent subgraphs and map to a unique DFS code. The determined gSpan performs better than FSG and can extract large recurrent subgraphs in a larger graph dataset with fewer minimum supports than prior studies [50]. A sample for frequent subgraph is shown in Fig. 1.
Example for frequent subgraph.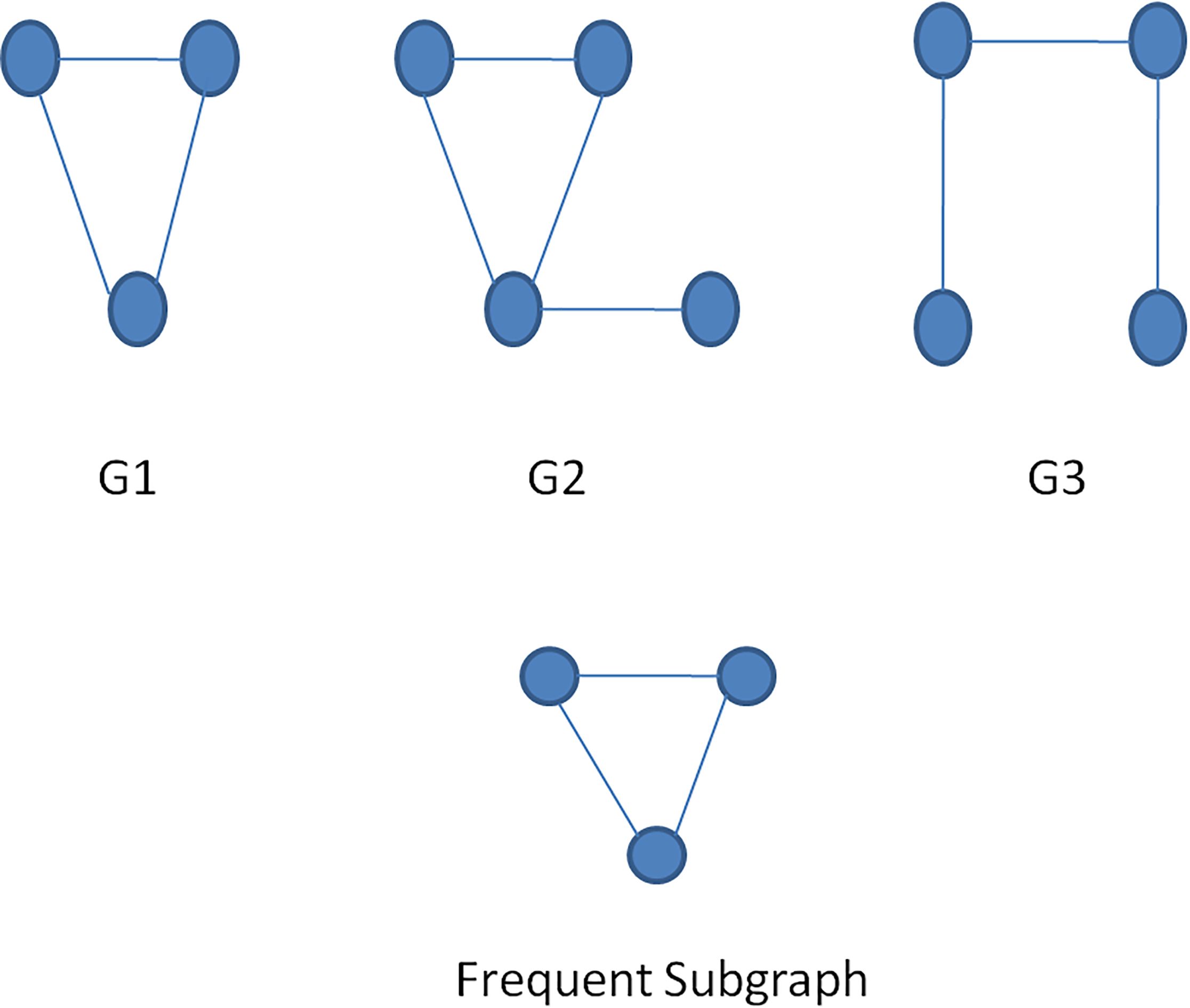
In the above figure, three different graphs represented by G1, G2, and G3 and a recurrent subgraph is shown. This subgraph occurred twice in the given set and also crossed the threshold value to prune the search space. Practically, frequent subgraphs can be easily extended to a very large graph database containing suitably variant labels for edges and vertices [32]. In a distributed environment, input graphs are divided and assigned to diverse worker nodes. Local support count of the subgraph in a portion of the node is not much helpful for determining whether or not the subgraph is recurrent. Aggregation of the count among various nodes is not possible in MapReduce because it doesn’t have any inbuilt system to convey with a global state. Apache Spark with pregel API is more suitable for graph applications.
Contributions to this research article:
We proposed a novel approach called Distributed Frequent Subgraph mining on an evolving graph (DFSME) that finds recurrent subgraphs in a distributed manner in less time than the traditional method. We designed an optimized data structure to record and subsequently disseminate the information of the mining process for the recurring iterations. We conducted experiments on big real-world datasets as well as synthetic datasets. DFSME is faster and more accurate than other competitors and scales to much bigger graphs.
This article aims to identify all recurrent subgraphs from a huge evolving graph in a distributed approach. The article is structured as follows: Section 2 discusses existing works in recurrent subgraph mining. Section 3 describes the basic information about the graph and ApacheSpark. Section 4 explains the proposed system, and Section 5 examines the proposed approach’s experiment results. Section 6 deduces the paper with the summary and future work directives.
Extracting the recurrent subgraphs that exist in a graph dataset has been a trend in research on big data. Fast Frequent Subgraph Mining (FFSM) is a technique used to generate candidate graphs (all possible combination with existing entities for example a, b, c, d 4 entities – a, ab, ac, abc…etc.) without duplicates while also avoiding subgraph isomorphism by preserving an embedding set for each recurrent subgraph [26]. But, it is used for small graphs and maintaining a complete set of embeddings leads to memory overhead. Another method, called GREW, is a heuristic algorithm intended to operate on a big graph; it finds patterns related to linked subgraphs that have a huge number of vertex-disjoint embeddings [33]. In some situations, the candidate set is huge, and not all patterns are valuable. So, a new technique has been proposed with approximate algorithms to discover recurrent subgraphs [40]. Dhiman and Jain proposed a filtration method that minimizes the number of candidate subgraphs and dropping the overall time complexity [13]. Nijssen and Kok figured out frequent subgraph mining algorithm called GASTON. It searches frequent paths, frequent trees, and lastly cyclic graphs, which provides results for large molecular databases [37, 38]. The drawback is to navigate the chain of embeddings to get complete information about a particular embedding. The FD-CDS algorithm captures the frequent itemsets and uses the storage composition, called FP-CDS tree, which reflects the frequent itemsets over time. The FP-CDS tree is used to dynamically record the change of the recurrent closed itemsets in a landmark window [36].
Frequent subgraph mining is widely used, but it is difficult to extend to data streams as more information has to be tracked and greater complexity has to be addressed. An effective pattern-tree based structure was developed for mining recurrent patterns from data streams [18]. An efficient bit-sequence representation of items is used to minimize time and memory for sliding windows, making the algorithm significantly faster while consuming less memory than the existing algorithms [34, 47]. Washio and Motoda proposed the AGM algorithm, which uses an adjacency matrix for efficiently mining the association rules amongst the frequently appearing substructure in a given graph dataset [29]. Current techniques address static graphs and not dynamic graphs. So, evolving graphs with edge insertions and deletions need to be considered. Frequent subgraph mining algorithms have been extended to graphs’ time series [8]. Bringmann and Nijssen discussed what is frequent in a single graph. Most of the relational data or hyper-graphs are mapped into multiple-sets, normally called transactional setting. But, some graph databases are found to be difficult to represent, such as web or social media, since it is a single large graph that one may not wish to split it into small parts, which is called a single-graph setting [9]. Kuramochi and Karypis addressed the difficulty of finding every subgraph having many edge-disjoint sets in a big, sparse graph. The proposed algorithm is based on vertical and horizontal paradigms. Results depict that these paradigms show better performance in finding frequent subsets in a real dataset. The vertical paradigm proved to be two to five times faster [31].
The extended Apriori algorithm derives all recurrent induced subgraphs from both directed and undirected graph-structured data [30]. AprioriTid algorithm outperforms AIS and STEM on real-time and synthetic data. The execution time decreased a little with an increase in the number of items in the database. The performance gap increased with an increase in problem size [3]. Graph clustering mostly partitions the objects in a graph database into dissimilar clusters based on vertex-connectivity and neighborhood similarity. To overcome this partition, Seeland et al. proposed a Structural Graph Clustering. This method uses the frequent subgraph miner gSpan, which reduces the time complexity and gives more accurate results by providing overlapping (non-disjoint) and non-exhaustive searches [43]. Finding the threshold of a subgraph from a huge graph is a tough job. The support of a subgraph is the highest independent node set of the overlap graph of the embeddings of the subgraph. This description may become too restrictive; hence, this paper proves that the threshold defined in this way is anti-monotone [17]. Subgraph indexing is a process of finding the entire occurrences of a query graph in a very big connected graph database, but this method is static. Jiong Yang and Wei Jin proposed dynamic indexing of a graph using the BR-indexing algorithm. This is done by constructing a Feature lattice, which maintains and searches the relevant features. Using the overlapping relationship, the index regions are pruned [52]. GraphSig technique converts the given graph into feature vectors where each vector represents an area within the graph. Domain information is used to choose a meaningful feature set. This technique accesses only a little part of the search space and groups all candidate subgraphs into sets based on their similarity. Hence, recurrent subgraph mining can be performed on every set with a high-frequency threshold [41].
Forecasting protein function from protein interaction networks is difficult due to the complex relationship between proteins but can be accomplished by identifying recurrent patterns of useful relations in a protein interaction network [11]. The TSP algorithm mines the patterns which have temporal data and forms a connective subgraph. TSP recursively grows the patterns in the dfs manner. Since TSP works to examine the database once and doesn’t produce needless candidates, the results illustrate that TSP outperforms the modified Apriori on time-efficiency [21]. Graph-based anomaly detection (GBAD) uses a subdue method in all of the three anomaly detections: insertion, deletion, and modification. When implemented in frequent subgraph miners, GBAD algorithms produce a significant increase in performance. GBAD algorithm is applied in emails for identifying insider threats [14]. A closed frequent itemset mining technique can be used instead of a general graph mining algorithm. This assures each discovered graph pattern is connected. The paper concludes that algorithms used on the single relational graph can be re-examined for multiple relational graphs as well [51]. A closed graph mining algorithm is developed by using pruning methods that substantially reduce needless subgraphs and also increases the efficiency of mining. But, to detect one failure condition, half of the performance is sacrificed [49].
The SPIN algorithm mines maximal frequent subgraphs from the graph dataset and decreases the size of the output set and also reduces the mined patterns by many orders of magnitude [25]. An incremental pattern matching algorithm was designed to minimize unnecessary computation. Incremental matching problems are unbounded, but there are some special cases wherein the incremental algorithm gives bounded as well as optimal solutions. The complexity of the solution is independent of the size of the data graph, but this algorithm produces better results than batch algorithms [16]. SSIGRAM, WFSM-MR, and DistGraph are distributed methods which were proposed to find the recurrent subgraphs from a large graph [39, 4, 44, 23, 46, 27, 42, 28]. Moment method is used to find frequent subgraph from a single large graph [10]. Danai Koutra has proposed many techniques for graph processing [22]. The existing methods are consuming too much memory space for pattern mining, and it’s rectified in the proposed system by introducing maximal frequent subgraph set. The time is taken to discover frequent subgraph in the existing system is very high. To overcome the existing limitations, we have proposed a parallel processing method using apache spark. The existing methods are used for a static graph, and parallel computation has been not considered for dynamic graph, so it takes more time. The proposed system identifies frequent patterns from the static graph as well as from dynamic graph and also work is done parallelly to reduce time.
Preliminaries
Static graphs are singular, large graphs in which there is no inclusion or exclusion of nodes or edges during the evaluation process.
A static graph contains set of nodes,
Recently, most of the applications are dynamic. For example, consider a social network in which many operations are dynamic: new friends are added, some followers are removed, or a profile is modified [1]. So, static is no longer feasible and a dynamic or evolving model suits recent applications and problems.
An evolving graph or dynamic graph contains set of nodes,
Candidate graph is the generation of all possible graph combinations with the existing nodes.
A graph
Two different graphs, A and B, are isomorphic if there is a one-to-one association between the nodes of A and those of B such that the number of relations joining any two nodes of A is equal to the number of relations joining the subsequent nodes of B [6], as revealed in Fig. 2.
Isomorphic Graphs A and B.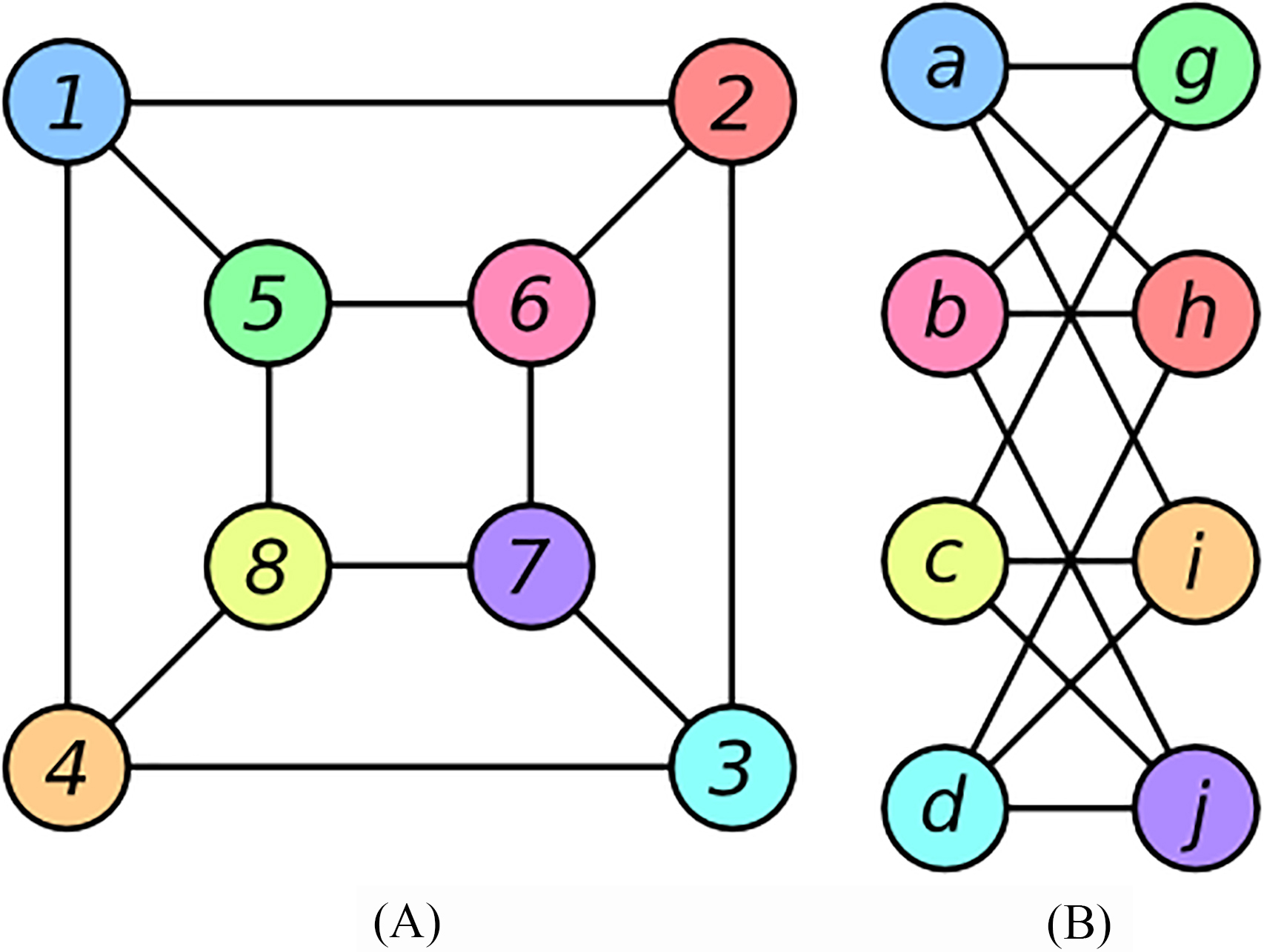
Minimal infrequent subgraph (MIS) is a set of all MIS such that for every
Frequent subgraph or pattern mining is the problem of identifying all the patterns or subgraphs from the given big dataset, whose support value is equal or more than a certain user-specified level. For a given graph database
MapReduce has to turn out to be an admired platform for analyzing large data. The MapReduce algorithm contains two significant tasks: Map and Reduce.
The Mapper accepts a set of data as input and converts it to another form of data, where individual elements are split into tuples. The Reducer takes data from the Mapper and combines those data tuples into a smaller set of tuples.
The reducer job is always performed after the mapper task. Frequent subgraph mining was done using MapReduce, but it doesn’t have any inbuilt system to convey with a global state. So, it takes more time to compute. Apache Spark is a technology designed for rapid computation [45, 20, 2, 5, 12, 19]. It is based on Hadoop MapReduce platform and extends the model to other types of powerful computations. It is well suited for graph applications. So, this model is utilized for the current graph problem. GraphX with Pregel API is used for graph computations. A spark cluster has a Master and numerous Workers. The driver and the executors run their Java processes and users can run them on a horizontal spark cluster or a vertical spark cluster.
In this research work, a new approach is presented for extracting the subgraphs, which are recurrently occurring in a large evolving single graph or a set of small graphs in a distributed fashion. The DFSME algorithm is proposed to identify the recurrent pattern in a distributed environment called apache spark. Before starting the actual process, it is mandatory to do preparatory tasks. This includes candidate generation, isomorphism checking, and support counting.
Basic processing in FSM
Usually, recurrent tasks start with a frequent pattern of size one (one edge pattern); later it will be extended until ‘K’. Once a pattern of a different size is identified, for example, size three frequent patterns, the recurrent patterns of size three will merge to provide a new pattern. Check whether the new pattern is frequent or not and avoid duplicate generation because duplication removal will consume the computation time. To avoid it, use rightmost path generation [50] that permits edge is adjoining only with vertices on the rightmost path. The graph isomorphism problem is common in graph processing. Two edges are believed to be of the same class if they are isomorphic to each other in having similar node labels and edge label. This will increase the computation time, to avoid isomorphism use the minimal DFS-code technique [50]. Embedding scheme is used to find frequent subgraphs having support count more than the user specified one. In graph processing, node labels and edge labels are allocated. Then, the embedding list will be created for every candidate graph. For example, three-node or edge subgraph is there, for that embedding is
The input graph S in Fig. 4 contains twenty-three nodes and twenty-seven edges unto which labels will be allocated. In this sample, the frequently occurred pattern is {
MNI table support count
MNI table support count
Subgraph X.
Embeddings for
Input raph S.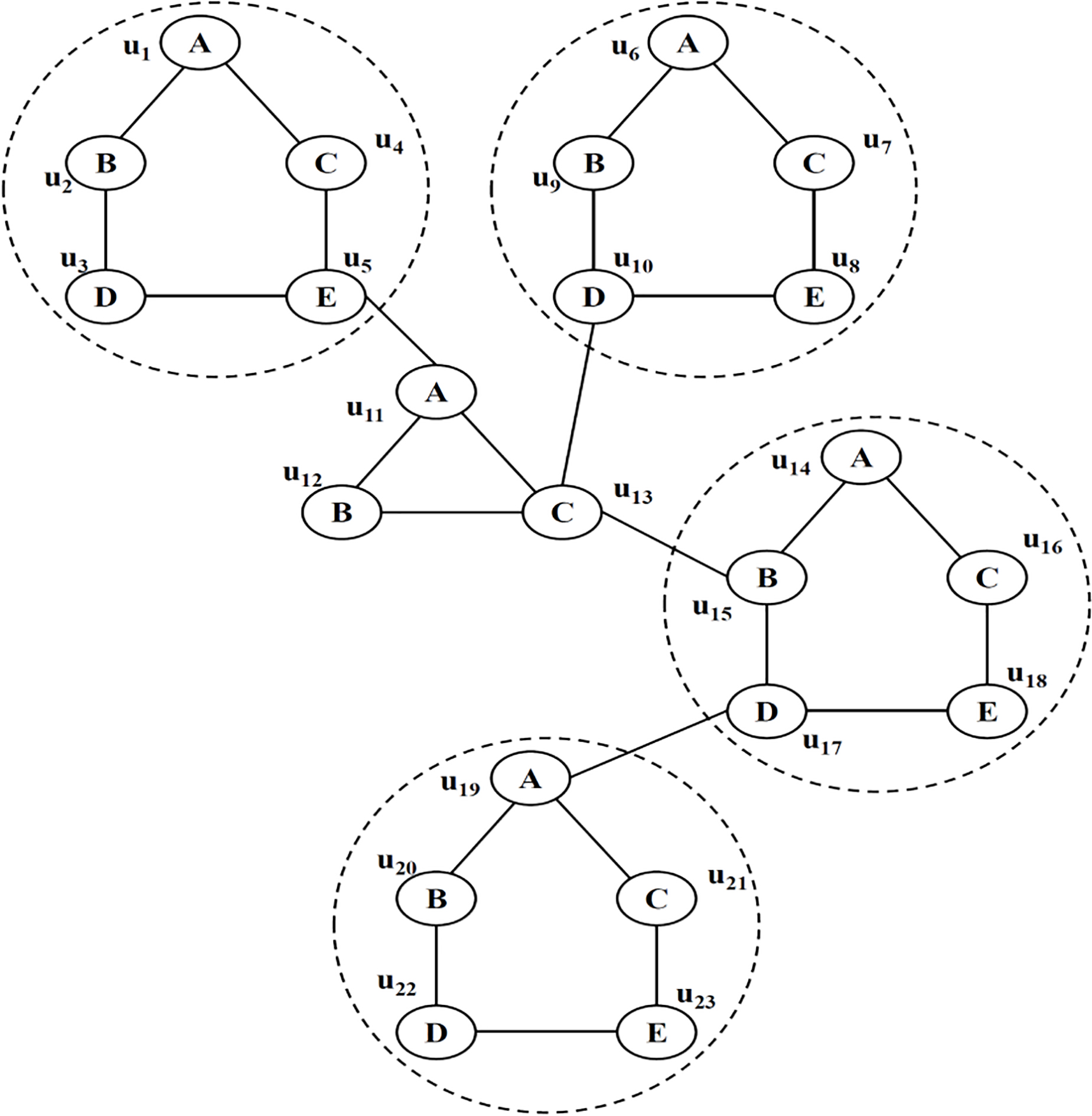
Architecture of distributed frequent subgraph mining on evolving graph.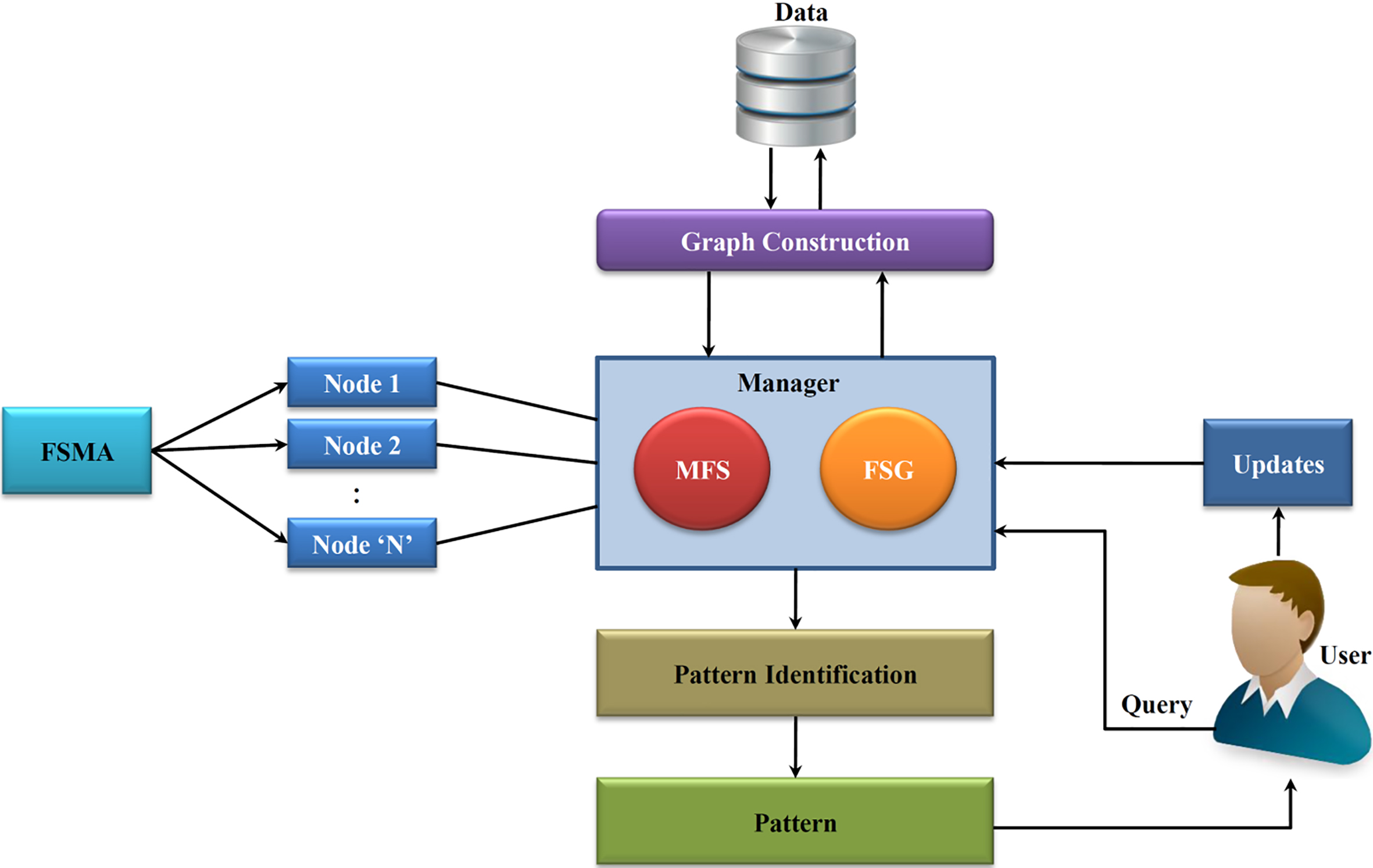
Frequent subgraph mining usually is done for static graphs, but nowadays many applications utilize dynamic data. So, subgraph identification for a dynamic graph is made in a distributed fashion to reduce computation time. The Apache Spark platform is used in this research to accomplish this task. The proposed system was shown in Fig. 5. The components of the proposed method are data collection, graph construction, manager (maintain FSG and MFS), the user (query, updates), distributed FSMA, and pattern recognition. The first step in this process is data collection. Dynamic data can be collected from Twitter, Facebook, Yahoo, and betterenvi datasets. After collecting the dataset, we use the apache spark tool called GraphX to construct the graph with nodes and edges. Nodes will represent a thing or human or machine, and edges will represent its relationships. Since it is dynamic in nature, nodes and edges will be added or deleted at any moment.
The user gives a query to the system (Manager), asking for information or patterns, and the manager will respond to that query. Frequently, data is updated and the graph structure is subsequently modified. The heart of the system is the manager component which identifies the frequent pattern. The manager’s first task is to partition the data in which the total quantity of edges accumulated over the graphs in a partition is close to each other. Apache kMetis library is available and is used for partitioning the given graph [24]. Once the partition task is completed, the graph dataset is allocated to worker nodes. The number of worker nodes required is based on the size of the given data. Each worker node now imposes the FSMA algorithm to find all the possible patterns starting from node one or edge one till ‘K’ node or edge for its own given graph dataset. It will maintain a MNI table for count based on the embedding scheme.
Accordingly, every other worker node maintains a counter table submitted to the manager. Once the manager determines all possible patterns received from all worker nodes, it will eliminate duplicates and consolidate the results. The results are examined with the user threshold value, and finally, the frequent patterns are identified. Since it is dynamic, the graph will change every moment. So, considering the entirety of the data is time-consuming and useless. Re-computation is not required because subgraphs are maintained properly in embeddings format. Therefore, we concentrate only on two sets, frequent subgraphs (FSG) and maximal frequent subgraphs (MFS). A frequent one is above or equal to the threshold set by the user, and the maximal frequent is on the border.
For example, support count is 80 and above, as set by the user. Some subgraphs are present whose count is 78 or 79; in such case, any changes (updates in the graph) will affect only MFS sets, yet any deletions can change the frequent set (FSG). To reduce the search space, this logic of considering only FSG or MFS is imposed. Figure 6 illustrates an example of a dynamic graph at a particular time, t1, where subgraph y is frequent, and z is maximal frequent for a graph G where the support count is 2. At time t2, graph G is updated and now z becomes frequent. Hence, in order to prune search space, considering only MFS without addressing infrequent subgraphs is logical. If new updates arrive, then forward them to the manager; the manager submits the updates to all worker nodes. Then each worker node updates the table with the new data if applicable.
Otherwise, the worker will send back the previous support table. Now, the manager collects the support count from all the workers and check for changes, if any, in the set MFS and FSG. Some subgraphs from the MFS set moves to FSG after the update, and some will move from FSG to MFS. Repeatedly, the process will continue for an evolving graph. Computation time is reduced because of the Apache Spark environment, GraphX, Pregel API and pruning the search space. This approach outperformed other existing approaches, as discussed in the next section. The manager component does two tasks. First, it distributes the task to worker nodes and then receives the count. Next, the manager consolidates the count and checks and maintains frequent and maximal frequent lists. The manager will respond to the user query, giving the pattern or information required for the user to make a further decision. The pseudo code represented below Algorithm 1 will give a detailed description of the proposed approach.
(a) Dynamic graph at different time. (b) Subgraph Y. (c) Subgraph Z.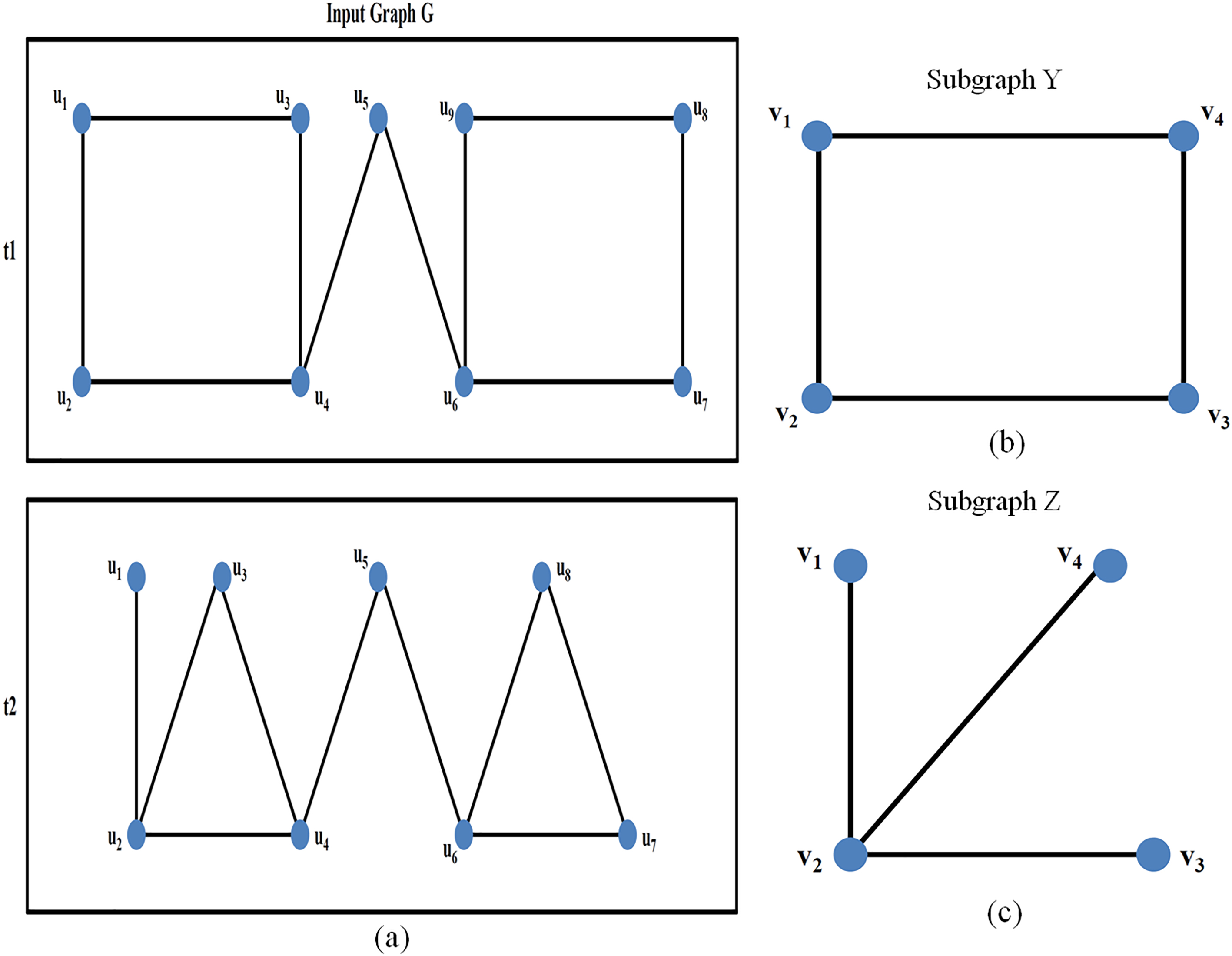
The algorithm uses the MNI Table to determine whether the subgraph is frequent or not. Every individual edge is taken, and a subgraph is formed that has only one edge and two vertices (lines 3–5). Then the occurrences of the similar graph (graph isomorphism with two different vertex labels and an edge connecting them) within the input graph is searched and the number of satisfying vertices is obtained. If the quantity of satisfying vertices is larger than the given threshold, then the subgraph is considered to be frequent (line8-isFrequentGraph). createGraph (edge) returns a graph with two vertices connected and the edge involved. All such one edge graphs are stored in an array, and every graph is check for the number of satisfying vertices that decides whether the involved subgraph is frequent or not (line 8). If the graph is frequent, the graph is extended by one more vertex and then added back to the graph (line 9). All frequent subgraphs are immediately stored into an array named MFS (line 11). This algorithm can handle updations on the input graph as it is keeping track of all the possible MFS.
Edge addition
The graph with a maximum number of edges and that contains labels from and to vertices of the added edge is obtained, and the edge added to the graph also obtained (lines 24–29). If the graph is to be frequent, it added to the MFS set and the extended graph is added to the list of graphs (lines 30–33).
Vertex addition
The graph with a maximum number of edges and that contains a label of the added vertex is obtained, and that vertex is added to that graph (line 18). If the graph is found to be frequent (line 19), it added to the MFS set and the extended graph is added to the list of graphs (lines 20–22).
Edge deletion
The graph with a maximum number of edges and that contains labels from and to vertices of the deleted edge are obtained, and the edge is added to the graph obtained (lines 46–51). If the graph is found to be frequent, it added to the MFS set and the extended graph is added to the list of graphs (lines 52–55). If the graph is not frequent, then the graph is deleted from the MFS list (line 57).
Vertex deletion
The graph with a maximum number of edges and that contains a label of the deleted vertex is obtained, and the vertex is deleted from that graph (line 35–38). If the graph is found to be frequent (line 19), it added to the MFS set and the extended graph is added to the list of graphs (lines 39–42). If the graph is not frequent, then the graph is deleted from the MFS list (line 44).
The explanation for the above-represented Algorithm 2 is discussed here; the task is done in a distributed environment using SPARK. The manager component contains DFSME that assigns the task to the Cluster-manager. The Cluster-manager distributes the task to every worker. In the Cluster-manager, a key-value pair is a dictionary of elements with the hash value of the graph as its key and object as the value. Every candidate of length k-1 is iterated and checked for isomorphism. If their corresponding adjacency list has elements, then the hash and the object are passed to the worker. The worker calculates the count of each generated subgraphs and the key-value pair containing the hash and object is passed to the Cluster Manager. Hash is calculated for every candidate subgraph so that while comparing them, it is not necessary to go through every element in the subgraph.
The worker returns all possible subgraphs to the cluster-manager, which in turn forwards the information to the manager. DFSME, which is running in the manager, uses the support table MNI to determine whether the subgraph is frequent or not. The occurrences of similar subgraph within the input graph are searched, and the number of satisfying vertices is obtained. If the quantity of satisfying vertices is larger than the given threshold, then the subgraph is considered to be frequent. All frequent subgraphs are immediately stored into an array named FSG and some subgraphs near to threshold stored in graphs, i.e. MFS. This algorithm can handle updates in the input graph as it is keeping track of all possible FSG. If any addition occurs as an update, the MFS sets that are affected by the update, if it has the particular edge and vertices, are accordingly updated and checked again using the isFrequent (graph, r) and added to FSG if it is frequent.
The deletion updates can cause some changes to the existing FSG graphs that can make the individual subgraph no longer frequent or potentially moved to MFS. Hence, after performing the updates, the graph needs to be checked using isFrequent (graph, r) method and removed if found infrequent. This process will continue indefinitely because it is evolving every moment. Finally, frequent patterns identified based on the requirement of the user will be delivered. Most of the existing algorithms are not scalable, it works only for sparse graph, and it won’t find the complete set of subgraphs and takes too much time for computation. Only minimal patterns are identified by the existing methods, but DFSME identifies all important patterns for the user given threshold, and the proposed work is more scalable. DFSME identifies patterns if the given input graph is larger and dynamic.
This section compares the performance of the proposed work with existing methodologies. The performance is evaluated using real graphs collected from Stanford University datasets (
Datasets used
Datasets used
Frequent subgraphs of twitter dataset for support count 20%.
DFSME was experimented with by changing the support value. When support was set to 10%; 321 frequent one edge subgraphs, 233 frequent two edge subgraphs, and 127 frequent three edge subgraphs were found. When the threshold value is very low, more frequent subgraphs are obtained. The support value was then changed to 20%; 157 frequent one edge subgraphs, 88 frequent two edge subgraphs, and 39 frequent three edge subgraphs were found. For the 60% threshold value, only 15 frequent subgraphs were found. From this observation, it is concluded that an increased minimum support value resulted in a decrease in the number of recurrent subgraphs. Twitter data compose medium density graphs, whereas other datasets are densely populated. Even in other datasets, if the threshold value is low, more frequent subgraphs are obtained and increasing the threshold value results in very few frequent subgraphs. Figure 8 shows some of the frequent subgraphs identified by DFSME for the user given 20% support count of the twitter graph dataset. Figure 7a–d frequent subgraphs indicate that likes for a tweet about a domain.
GraphGen is a tool used to generate synthetic graph datasets. Using GraphGen, some 50000 graphs were generated and 5000 graphs were used for experimentation. Each utilized graph has some 50 nodes and 120 edges. DFSME was applied on this synthetic graph; here too, when the support count was minimum, more frequent subgraphs were obtained. Once the support count was increased, much less frequent subgraphs were obtained. Then, existing methods like FSM, FSM-H, and MRFSM were applied to the Twitter dataset. These methods identifying recurrent subgraphs of different support values but took more time for computation compared to the proposed DFSME algorithm. Figure 8 shows the relationship between minimum support count and time taken by different methods to identify frequent subgraphs for the Twitter dataset. Computation in the proposed methodology was done in a distributed manner using apache spark with pregel API. The task is assigned to worker nodes by cluster-manager, which will send the data back to the manager. The manager consolidates and maintains frequent patterns. The ultimate use of finding frequent patterns is to make decisions or to set policies that depend on the applications.
The distributed frequent subgraph mining on an evolving graph (DFSME) proposed algorithm execution time for twitter dataset is 55.03 minutes. Threshold varied from 10% to 70% for the same dataset; it is observed that time taken gradually decreased. Similarly, the execution time of MRFSM for twitter dataset is 65.06 minutes, for A-FSM its 59.22 minutes and for FSM-H 61.23 minutes. Time taken was gradually decreased according to the varying support count value. For traditional FSM, execution time is 90.56 minutes, as shown in Table 3.
Time taken by various algorithms for different support value to identify frequent subgraph on Twitter data
Time taken by various algorithms for different support value to identify frequent subgraph on Twitter data
Line plot shows the association between the minimum support count and the runtime of DFSME, FSM-H, MRFSM, and Traditional-FSM for the Twitter dataset.
Table 4 shows the runtime taken by each algorithm and DFSME outperforms other existing methods. Twitter is a medium density graph with 81306 nodes, 1768149 edges, and 325 distinct node labels. Consider the comparatively dense graph dataset, web-google, with 3774768 nodes, 16518948 edges, with 676 distinct node labels for the experiment. In this case, DFSME still takes less computation time when compared to Approximate-FSM, FSM-H, MRFSM, and FSM when identifying frequent patterns. DFSME runtime is 77.11 minutes, A-FSM takes 81.03 minutes, FSM-H takes 84.09 minutes, MRFSM takes 91.36 minutes, and traditional FSM takes 115.89 minutes.
Comparison of DFSME, FSM-H, A-FSM, MRFSM, and FSM
Comparison of DFSME and fullrecompute for updates in Twitter and Web-Google.
The computation completed for the particular twitter dataset will change, as nodes or edges are added to the graph, or some nodes or edges are deleted from the graph because it is evolving. Any new member can be added to twitter at any time, and any relationship (edge) can be deleted at any moment. DFSME handles this dynamic situation efficiently by focusing on only frequent subgraph (FSG) and maximal frequent subgraph (MFS). FSG is above or equal to the threshold set by the user, and maximal frequent is on the border. For example, the support count is 80 and above set by the user. Some subgraphs whose count is 78 or 79 exist; in such case, any new updates in the graph will affect only the MFS set, but any deletions can change the frequent set (FSG). To reduce the search space, logic of considering only FSG or MFS is imposed. Other methods, like traditional FSM, will recompute everything from scratch with every change. Therefore, it will take more time to identify recurrent patterns. Consider the same evolving twitter dataset for comparison between FSM and the proposed DFSME algorithm. When the update is 250 addition of nodes or edges, the fullrecompute method takes 80 ms, but DFSME takes only 9.5 ms. When the update is 500, fullrecompute takes 170 ms, but DFSME takes only 18.9 ms. When the update is 750, fullrecompute takes 255 ms, but DFSME takes only 28.1 ms.
For twitter dataset in deletion, when the update is 250, fullrecompute takes 120 ms. But DFSME takes only 8.78 ms. When the update is 500, fullrecompute takes 252 ms, but DFSME takes only 19.01 ms. When the update is 750, fullrecompute takes 355 ms, but DFSME takes only 29.33 ms. For dense graph web-google, these methods are also applied and execution time was computed. For addition, when the update is 200 fullrecompute takes 225 ms, but DFSME takes only 10.45 ms. When the update is 500, fullrecompute takes 431.09 ms, but DFSME takes only 40.5 ms. When the update is 700, fullrecompute takes 551.33 ms, but DFSME takes only 67.7 ms. For deletion, when the update is 200 fullrecompute takes 221.4 ms, but DFSME takes only 12.5 ms. When the update is 500, fullrecompute takes 445.6 ms, but DFSME takes only 41.88 ms. When the update is 700, fullrecompute takes 578.32 ms, but DFSME takes only 69.12 ms.
The computational time varies depends on the density of the graph. Still, DFSME execution time is less compared to other methods. Figure 9 shows the update histograms for the different datasets, representing the time taken per edge update. DFSME outperforms other methods in computation time, as clearly visible in the Fig. 9. Finally, it is concluded that DFSME is the best algorithm in identifying frequent patterns from a large evolving graph. Identifying frequent patterns is very useful in fields such as the nuclear industry to avoid nuclear proliferation.
In this research article, we considered the difficulty of recurrent subgraph mining on dynamic graphs. Existing methods give a solution suited to static graphs. Since data is big and dynamic, finding frequent patterns using existing methodology takes more time for identification. So, a novel approach is proposed called DFSME that discovers frequent subgraphs from an evolving graph in a distributed manner using apache spark with pregel API. We showed the efficiency of DFSME over real and synthetic datasets for diverse input configurations. We compared the execution time of DFSME and other existing methods, which shows DFSME is superior than existing algorithms. In future, as the data size exponentially increases, we planned to use Cloud Computing to handle the problem of finding the frequent subgraph. We planned to apply DFSME on different real-life applications like nuclear industry and network security monitoring system to acquire potential interesting patterns. Usually, the user will set the minimum support value, for that algorithm gives you frequent patterns. But, in the future based on the size of data and the number of partitions the algorithm sets the threshold value automatically.
Footnotes
Acknowledgments
The authors are grateful to Science and Engineering Research Board (SERB), Department of Science and Technology, New Delhi, for the financial support (No. MTR/2019/000542). Authors express their gratitude to SASTRA Deemed University, Thanjavur, for providing the infrastructural facilities to carry out this research work.