
Abstract
Mining frequent simultaneous attribute co-variations in numerical databases is also called frequent gradual pattern problem. Few efficient algorithms for automatically extracting such patterns have been reported in the literature. Their main difference resides in the variation semantics used. However in applications with temporal order relations, those algorithms fail to generate correct frequent gradual patterns as they do not take this temporal constraint into account in the mining process. In this paper, we propose an approach for extracting frequent gradual patterns for which the ordering of supporting objects matches the temporal order. This approach considerably reduces the number of gradual patterns within an ordered data set. The experimental results show the benefits of our approach.
Introduction
Gradual patterns that capture the order correlations of the form “The more/less X, the more/less Y” play an important role in many real-world applications where numerical data must be handled. Data mining algorithms are more commonly used to automatically extract such patterns [5, 8, 10, 17].
Condensed representations are sometimes used to reduce the number of extracted pattern, as in [2] which proposes an approach for frequent closed gradual patterns as a post-processing step of the approach in [8]. This approach does not procure the benefits of reduced runtime and memory and thus does not provide any added value for running the algorithms. The authors of [10] thus tackle this by proposing an algorithm known as GLCM that reduces the number of patterns during the mining process. GLCM is based on an extension of the idea developed in the LCM [25] algorithm and allows the efficient computation of gradual itemsets over large real-world databases with a linear time complexity in the number of closed frequent gradual patterns and a constant memory complexity w.r.t. the number of closed frequent gradual patterns.
In [20], ParaMiner, a generic and parallel algorithm for closed pattern mining is proposed. This algorithm outperforms the state of the art gradual pattern mining algorithm on the problem of mining gradual itemsets. It is built on the principle of pattern enumeration in strongly accessible set systems and its efficiency is the result of a dataset reduction technique called EL-reduction, combined with a technique for performing data set reduction in a parallel execution on a multi-core architecture. ParaMiner is currently the most efficient algorithm for mining frequent closed gradual patterns from large numerical databases.
Although the gradual patterns mining algorithms reported in the literature allows to efficiently extract gradual patterns, they do not assume that there is temporal constraint on the data. However, there are applications with a temporal order among objects (or rows) i.e. objects have a temporal meaning. An example is the paleoecological data described in [17]. In that context, one can only take into account the patterns whose order of concordant objects (rows) respects the temporal order, whereby other patterns are irrelevant. Thus, the reported algorithms are not suitable for extracting gradual patterns under temporal constraints on rows (or transactions).
Most recently, [17] exploits the principle given in [5] and uses an Apriori algorithm to extract frequent gradual patterns by taking into account the temporal constraint during the mining process. The authors apply their approach on the paleoecological data and show through the extracted gradual patterns, the interest to search gradual patterns from an ordered data set. However, this approach is limited to finding the gradualities only between consecutive objects and does not benefit from the efficiency of the techniques proposed in ParaMiner[20].
We therefore propose herein an approach to extract frequent closed gradual patterns with temporal constraint on objects. Our approach extends the previous work proposed in [17] by overcoming the two limitations mentioned above, extract the gradualities between distant objects and exploit the efficiency of the techniques proposed in ParaMiner[20]. This approach exploits the encoding proposed in the ParaMiner algorithm and uses the generic algorithm that computes the closure of a pattern by augmenting it with elements from the intersection of the transactions in its support set. In fact, in the ParaMiner algorithm, the closure of a pattern
The paper is organized as follows: after introducing the notion of gradual patterns in Section 2, Section 3 describes our approach to mining frequent closed gradual patterns under temporal constraint. Before concluding, experimental results on two data sets are presented and compared to ParaMiner in Section 4.
Gradual itemsets and related works
In this section, we define the notion of gradual itemsets (patterns), and illustrate it on a sample data set.
Preliminary definitions
We assume that we are given a data set
: Ordered numerical data set
The gradual itemsets extracted from
Let us illustrate the notion of gradual itemsets using the numerical data set given in Table 1. This data set contains seven objects on which is defined a relation of temporal order and seven attributes.
For instance, considering the data set of Table 1,
A gradual itemset is thus defined as follows:
For example,
A gradual itemset imposes a variation constraint on several attributes simultaneously.
The support (frequency) of a gradual itemset in a database amounts to the extent to which a gradual pattern appears in a given database. Several support definitions have been proposed in the literature [12, 5, 14, 8], showing that gradual itemsets can follow different semantics. The choice thereof generally depends on the application.
In this paper, we consider the variation semantic proposed in [8] which is implemented in Paraminer and we have adapted it to temporal constraint. This has enabled to discover new kinds of gradual itemsets reported here as temporal gradual itemsets, which are gradual itemsets whose longest list of transactions respects the temporal order.
Definitions of important notions about the gradual itemset proposed in [8] are recalled hereafter.
Note that there may be several lists of objects respecting
By considering the data set of Table 1 and the pattern
The longest list from
Referring to the previous example from Table 1,
This order is only a partial order. For example consider
The complementary gradual itemset of
Proposition 6 avoids unnecessary computations, as generating only half of the gradual itemsets is sufficient to automatically deduce the other ones. This means that, for each gradual itemset, there is a symmetric gradual itemset having the same support.
A gradual itemset is said to be frequent if its support is greater than or equal to a user-defined threshold. The problem of mining frequent gradual itemsets is to find the complete set of frequent gradual itemsets in a given database
The approach described above allows closed frequent gradual patterns in the numerical database to be automatically extracted. However, this approach doesn’t suppose any temporal constraint between objects in the database, which is unsuitable for the case of a database whose objects follow a temporal order relation.
With temporal constraint, for a given numerical database
In this paper, we propose to integrate the temporal constraint into the Paraminer algorithm in order to automatically extract the frequent gradual itemsets within the mining process. This approach exploits the encoding of the gradual itemset mining problem proposed in [20] and uses the principle of the conventional algorithms to solve pattern mining problems in order to overcome the problem posed by the non-symmetrical patterns respecting the temporal order. Our approach is a constraint-based pattern mining approach that is different to the one proposed in [20], which prevents use of the algorithm to solve conventional pattern mining problems.
Closed gradual itemsets
Closed itemsets are the key to obtaining concise representation of patterns without loss of information [19, 23, 4, 3]. This notion of closure was introduced for the first time when extracting gradual patterns in [2], where the authors propose a pair of functions
In our approach, the closure is seen as another constraint and is efficiently combined with temporal constraint to mine closed gradual patterns whose lists of objects respect the temporal order.
Related works
As mentioned above, several works have been interested in the gradual pattern mining problem. Certain works propose algorithms to efficiently extract gradual patterns [8, 7, 14, 20, 10] from numerical data set and other works are instead focused on extracting other variants of gradual patterns from different types of data [21, 15, 22].
In [8], the authors propose an Apriori[1] principles based method in order to extract gradual itemsets in an efficient manner from large databases. This method takes advantage of a binary representation of lattice structure and deals with binary matrices to represent how tuples are ordered (adjacency matrix) with regard to a gradual itemset. The data are represented through a graph whose nodes are defined as the objects in the data, and the vertices express the precedence relationships derived from the considered itemset. This graph is called precedence graph. [7] propose a conflict sets based approach for extracting gradual itemsets. This approach computes the support for gradual itemsets, in a level-wise process that consists in discarding, at each level, the rows whose so-called conflict set is maximal, i.e. the rows that prevent the maximal number of rows to be sorted. In [14], the authors propose to compute the support of a gradual itemset by using the Kendall tau ranking correlation coefficient. In fact, instead of evaluating the support as the length of the longest path in precedence graph as in [8], the authors consider the number of pairs of objects that are correctly ordered (concordant and discordant pairs) with respect to gradual itemset. [9] propose a
In order to tackle the time-consuming problem, the authors of [16] exploit the multiple processors and cores that are now available on computers to enhance the performances of the GRITE algorithm proposed by [8]. Following the same idea, [20] proposes a generic and parallel algorithm for closed gradual patterns mining based on a data set reduction technique called EL-reduction, combined with a technique for performing data set reduction in a parallel execution on a multi-core architecture.
In [15], the authors introduce emerging gradual patterns which are defined as gradual patterns that describe a data set by contrast to a reference data set, i.e. occur in a data set but not in another. [24] extends the notion of gradual pattern to the case in which the co-variations are expressed between attributes of different database relations. The authors hence propose the relational gradual pattern concept, which enables to examine the correlations between attributes from a graduality point of view in multi-relational data. [22] are interested in mining gradual rules from Stream Data. Due to the complexity of data streams that is increased as the data must be handled on the fly and can be seen only once, the authors propose an approach based on OWA (Ordered Weighted Aggregation) operators [26, 27] and B-Trees in order to speed up the mining process.
Most recently, [21] addresses the spatial gradual pattern mining problem with an application to the measurement of potentially avoidable hospitalizations. In [13], the authors propose a sequential pattern mining based approach for efficient extraction of frequent gradual patterns with their corresponding sequence of tuples.
Mining closed gradual itemsets under temporal constraint
This section presents our extraction process for discovering, from a numerical database, the frequent closed gradual itemsets whose lists of objects follow a temporal order.
Graduality under the temporal constraint
The semantic to be considered within the context of our study differs from that reported in [20] in the following points:
The support of a gradual item is not always 100%. In fact, in a conventional context [8], it is always possible to order all of the objects by one column. This is not always possible in the temporal context. For example, none of the gradual items extracted from Table 1 has a support equal to 100% under temporal constraint. The gradual itemsets sought after here are not symmetrical unlike conventional gradual itemsets. Thus, the Proposition 6 is no longer valid. All gradual itemsets must be sought with their corresponding complementary itemset. The computation of the closure of a gradual itemset is defined in a much simpler way than that proposed in [20]. This is due to the fact that the gradual itemsets are not symmetrical in the temporal context. The extraction process is faster and the number of extracted patterns is smaller because taking into account the temporal constraint reduces the number of object paths to be explored in the data set.
The paragraphs below give a formal definition of the problem of mining frequent gradual patterns under temporal constraint. This is then illustrated by an example using the database of Table 1, and shows that the semantics of graduality of the state of the art are not suitable.
The determination that the complementary gradual itemset of a gradual itemset is one of its siblings is of little importance.
Let
The encoding of Table 1 is given in Table 2.
With this encoding, the support of a given gradual pattern
In the temporal context, the closure of a gradual pattern
Algorithm 1 computes the unique closure of every gradual itemset respecting the temporal order. It is defined in a much simpler way than that proposed in [20].
[h] Mining closed gradual itemset from an ordered data set0.3em0.7em An ordered data set
Proof. Proof of this is clear since Algorithm 1 is a simplification of the classical algorithm to compute closed patterns given in [6], which has been shown to compute the set of closed patterns.
Proof.
Let Let
Suppose that
Proof. Let
Proposition 13 prevents unnecessary computations within the mining process, as a gradual itemset and its sibling itemsets cannot both be frequent if the minimum support threshold is greater than half of the data set size.
Comparative evaluation of our approach vs the original Paraminer and the approach proposed in [17] (on a real data set of 111 objects and 40 attributes).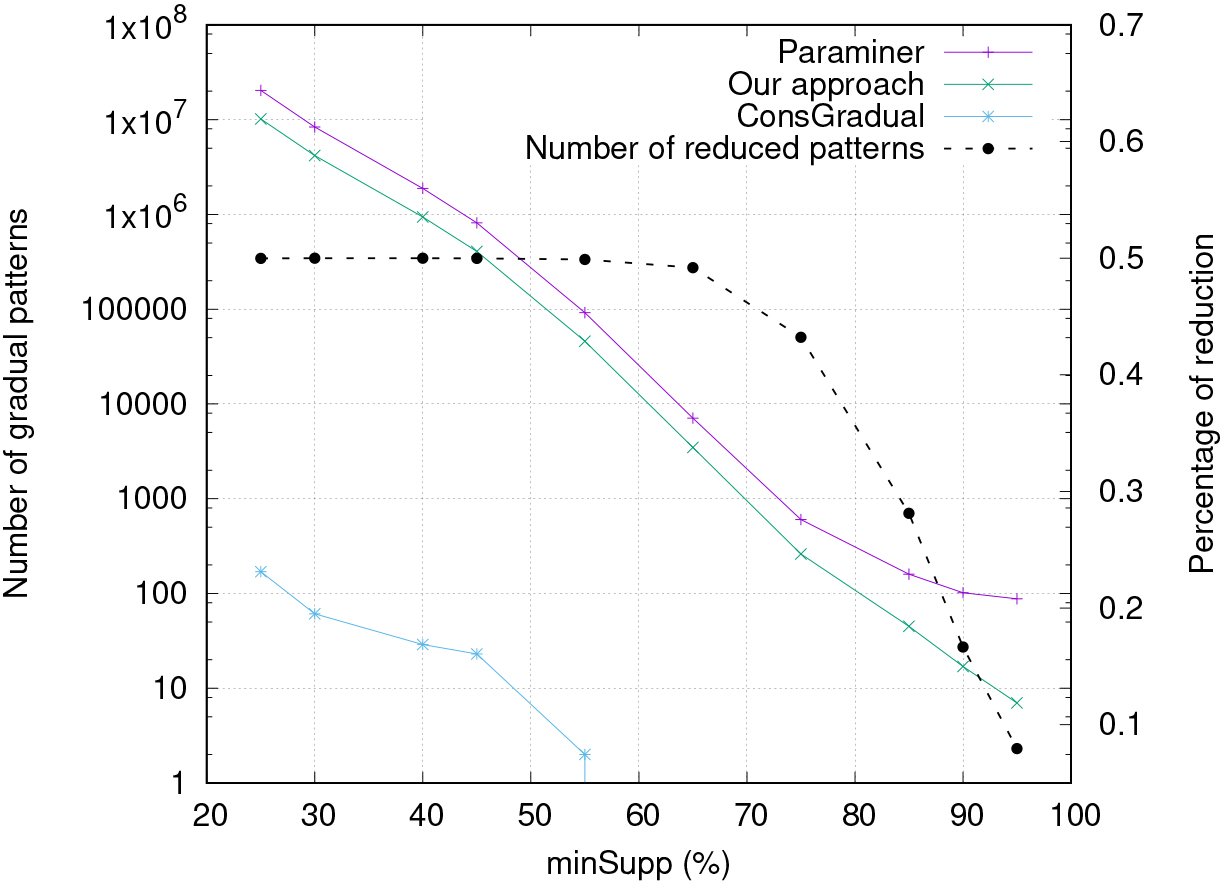
As mentioned in introduction, a first approach for extracting frequent closed gradual itemset from the ordered data set have been proposed by [17]. However, this approach does not allow to extract in this context the gradual itemsets between distant objects. For instance, the gradual itemset
This section presents our experimental study on a real world data set of paleoecological indicators [17] and on a synthetic data set. The efficiency of the original ParaMiner algorithm is firstly compared with the new algorithm integrating the temporal constraint in terms of the number of extracted patterns. We also compare our proposed approach that we call LongOrdGradual with the one proposed by [17] called here ConsGradual in terms of the number of extracted patterns.
Figure 1 shows the number of extracted frequent closed gradual patterns with support variation for a paleoecological data set containing 111 objects and 40 attributes (items) [17]. Focus is placed on the variation of frequent closed gradual patterns respecting the temporal order with regard to conventional ones extracted using Paraminer according to the minimum support value minSupp. We can see that the number of patterns extracted with LongOrdGradual is generally smaller than the number of patterns extracted with Paraminer. This is because LongOrdGradual takes into consideration the temporal constraint during the mining process.
We observe from Fig. 1 that the proposed approach LongOrdGradual extracts more patterns than the one proposed in [17]. Thus, it allows to extract other gradual itemsets that can not be captured by [17]. The interest of such patterns whose sequence of objects respects the temporal order has been shown in [17]. Another important difference is that [17] extracts only the gradualities for which the attribute values do not stay constant between the objects. On Fig. 1, the curve called “Number of reduced patterns” shows the percentage of reduced patterns by LongOrdGradual compared to Paraminer.
Figure 2 shows the computational time taken by our algorithm and the other algorithms. We can see that the proposed approach in [17] have shorter execution times than the other approaches as it extracts fewer patterns than the others (see Fig. 1 on the number of extracted gradual patterns). Runtimes of LongOrdGradual are slightly shorter than those of the Paraminer algorithm.
Comparative evolution of the computation time of our approach vs the original Paraminer and the approach proposed in [17] (on a real data set of 111 objects and 40 attributes).
Comparative evaluation of our approach vs the original Paraminer and the approach proposed in [17] (on a synthetic data set of 108 objects and 30 attributes).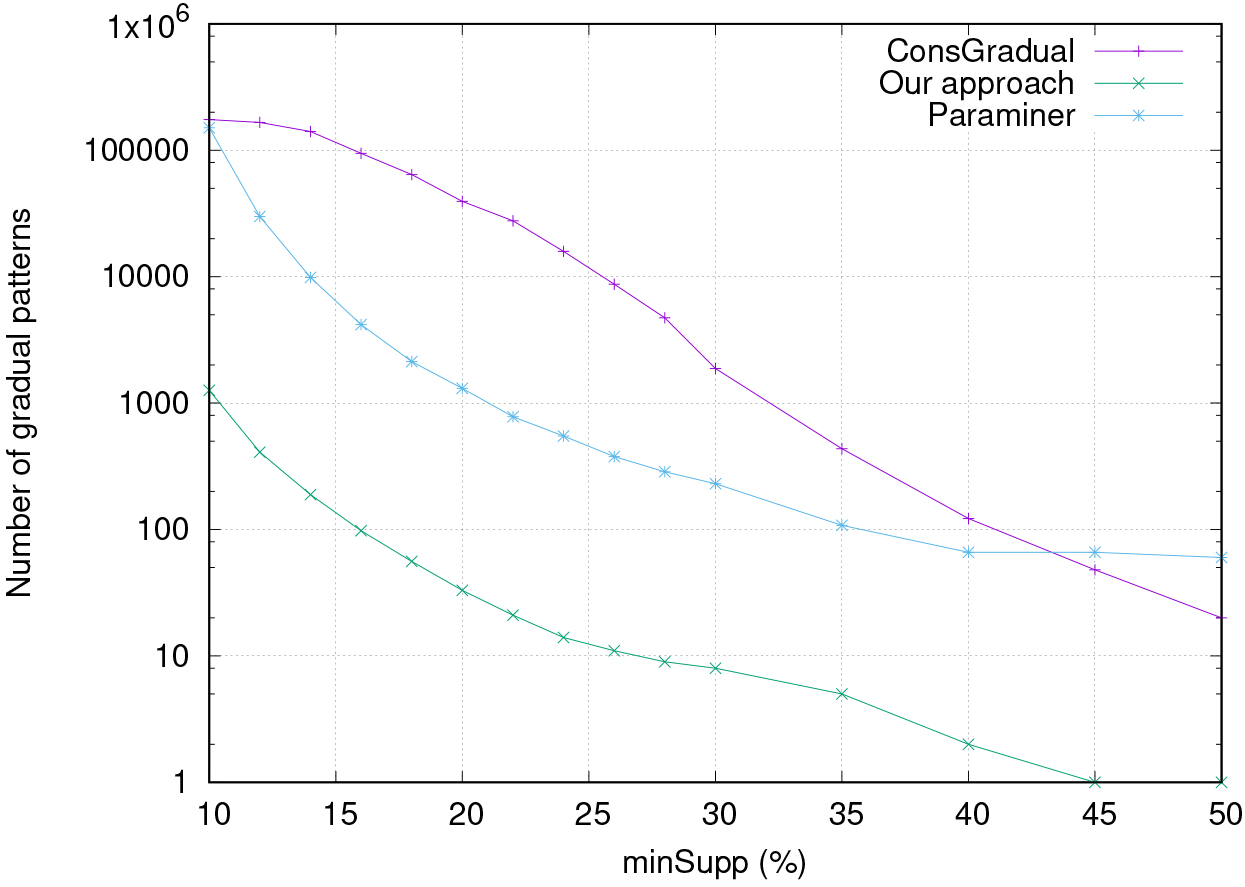
Comparative evolution of the computation time of our approach vs the original Paraminer and the approach proposed in [17] (on a synthetic data set of 108 objects and 30 attributes).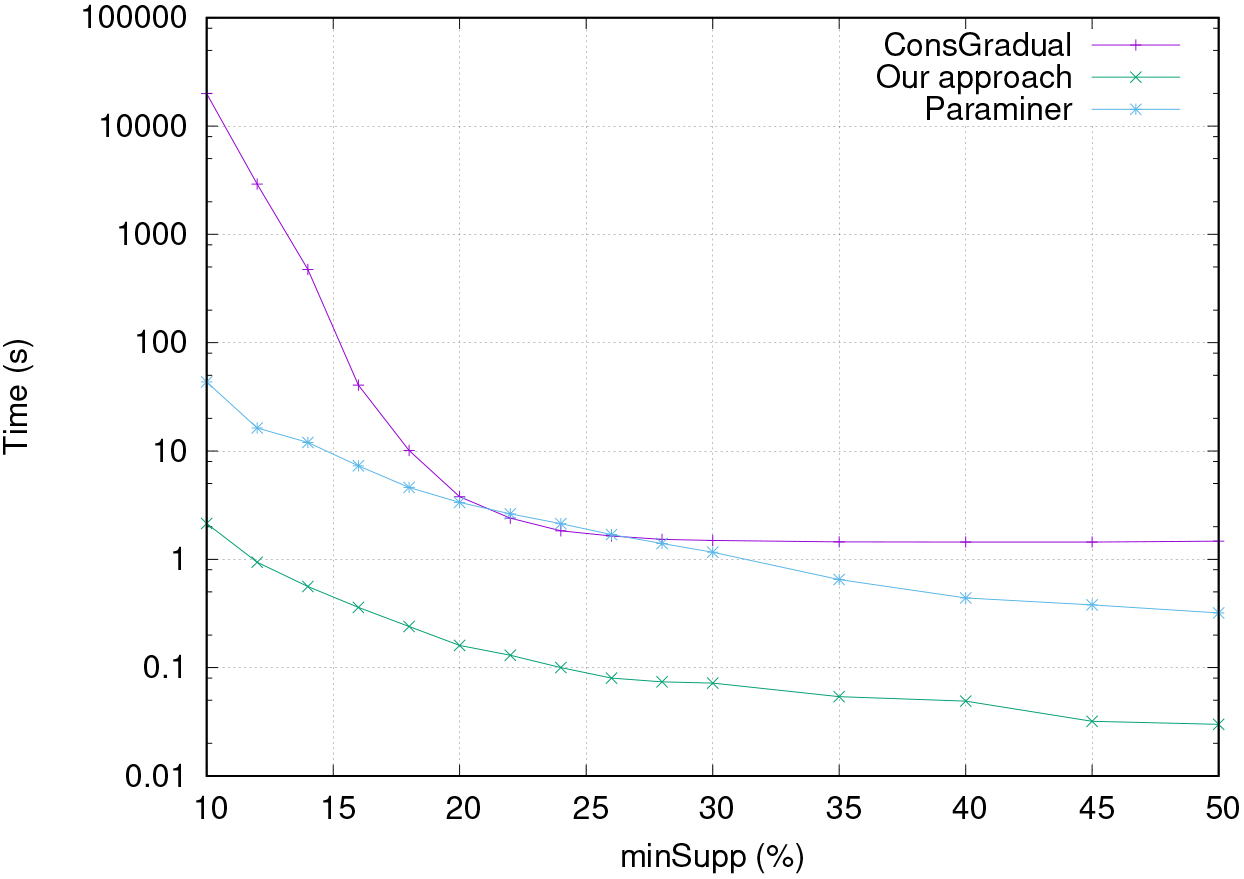
Comparative evaluation of our approach vs the original Paraminer and the approach proposed in [17] (on a synthetic data set of 1000 objects and 20 attributes).
On Fig. 3, we compare over a synthetic data set, LongOrdGradual with both Paraminer and ConsGradual. The comparison is made on the number of closed frequent gradual patterns returned by each approach with the variation of minimum support threshold (minSupp). The synthetic data set used which contains 108 objects and 30 attributes was produced with the same modified version of IBM Synthetic Data Generator for Association and Sequential Patterns as the one used in [8]. It comes from this experiment that LongOrdGradual extracts less patterns than ConsGradual (the curve called “ConsGradual” on Fig. 3). In fact although the two approaches integrate the temporal constraint during the process mining, they do not extract the same forms of patterns. On this synthetic data set, the number of patterns extracted with LongOrdGradual is lower than the number of patterns extracted using Paraminer.
Comparative evaluation of our approach vs the original Paraminer and the approach proposed in [17] on the synthetic data sets with the variation of objects number.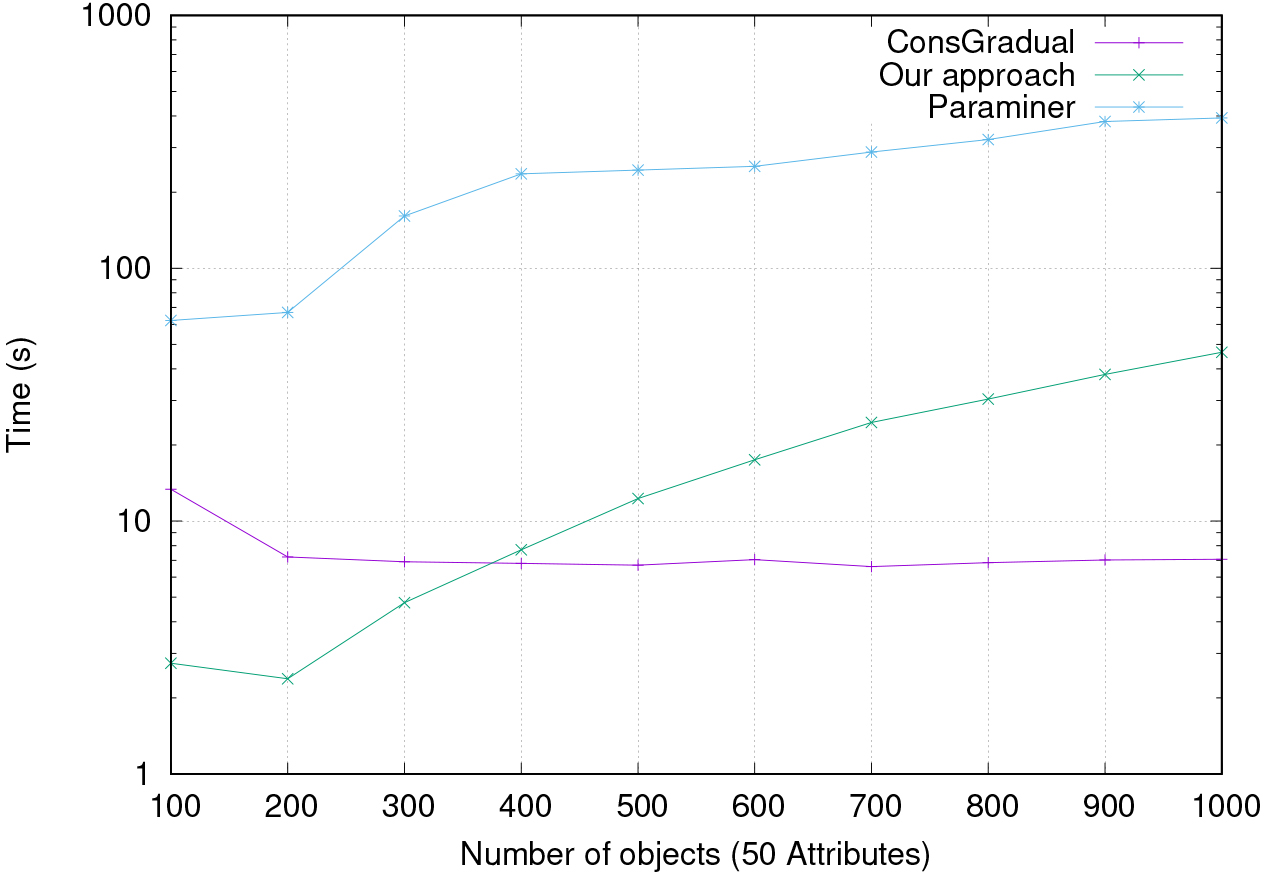
Comparative evaluation of our approach vs the original Paraminer and the approach proposed in [17] on the synthetic data sets with the variation of attributes number.
Figure 4 shows the runtime evolution of each approach for discovering gradual patterns on a synthetic data set according to the minimal support. Our approach exhibits a better speedup than the other ones as it extracts fewer patterns than the others (see Fig. 3).
Figure 5 shows the number of extracted patterns on a data set having a bigger set of objects (1000 objects). On this data set our proposed approach extracts fewer patterns than the other approaches. In most of the cases, techniques allowing to obtain gradual knowledge are generally driven on bases containing a weak number of objects and attributes. Also, the synthetic data sets generated by IBM Synthetic Data Generation Code for Associations and Sequential Patterns are very dense, a huge number of gradual patterns can be extracted, and the computational times can be longer. Experimental results obtained on these synthetic data sets show that the number of extracted patterns by our approach is generally smaller than the number of extracted patterns by the other algorithms, the difference is very large (see Figs 3 and 5).
Figure 6 shows, for 50 ttributes and a minimal support minSupp set to 0.1, the variation in computational time taken by each algorithm as the size of the data set is increased (variation of object number). On this figure, we can see that the computational times increase when the object number increases except for the approach proposed in [17] whose the runtimes slightly decrease when the object number increases. Nevertheless, our approach takes less time than Paraminer on these data sets.
Figure 7 shows, for a data set containing 1000 objects and with a minimal support set to 0.1, the variation in computational time taken by each approach to extract gradual patterns. From this figure, we observe an increase of computational time when the attribute number increases. Indeed, the number of extracted gradual patterns increases when the attribute number increases and thus increasing the computational time. Paraminer algorithm takes longer than the other algorithms.
In this paper, we propose an approach for the automatic extraction of frequent closed gradual patterns when the ordering of supporting objects follows a temporal order. We show that, in this context, taking into account the temporal constraint during the mining process allows us to significantly reduce the quantity of extracted patterns by eliminating patterns containing lists of inconsistent objects i.e where the lists of objects do not respect the temporal order. An algorithm dedicated to the extraction of frequent closed gradual patterns under temporal constraint has been proposed and implemented. The experiments carried out on the real world data sets made it possible to extract other forms of patterns in the ordered data sets by considering the gradualities between distant objects. Unlike current approaches, it would be interesting in this temporality context, to consider the cases for which an attribute has the equal values between two objects (i.e., neither decreasing nor decreasing order of values) in order to select the most suitable results. We also plan to take variation strength into account during the mining process.
Footnotes
Acknowledgments
The authors would like to thank Auvergne-Rhône-Alpes region and European Union for their financial support through the European Regional Development Fund (ERDF). The authors would also like to thank the authors of Paraminer for making available their algorithm.