
Abstract
Inferring user interest over large-scale microblogs have attracted much attention in recent years. However, the emergence of the massive data, dynamic change of information and persistence of microblogs pose challenges to interest inference. Most of the existing approaches rarely take into account the combination of these microbloggers’ characteristics within the model, which may incur information loss with nontrivial magnitude in real-time extraction of user interest and massive social data processing. To address these problems, in this paper, we propose a novel User-Networked Interest Topic Extraction in the form of Subgraph Stream (UNITE_SS) for microbloggers’ interest inference. To be specific, we develop several strategies for the construction of subgraph stream to select the better strategy for user interest inference. Moreover, the information of microblogs in each subgraph is utilized to obtain a real-time and effective interest for microbloggers. The experimental evaluation on a large dataset from Sina Weibo, one of the most popular microblogs in China, demonstrates that the proposed approach outperforms the state-of-the-art baselines in terms of precision, mean reciprocal rank (MRR) as well as runtime from the effectiveness and efficiency perspectives.
Introduction
Microblogs, which are important social platforms, can provide microbloggers with the ability to communicate and share information with each other. In the past decade, a lot of microblogs have been constructed for business applications and achieved tremendous successes. For example, Facebook has achieved more than two billion registered users, accounting for more than a quarter of the global population. In addition, Twitter has owned about 319 million active users every month, and hundreds of millions of tweets are generated every day. Meanwhile, the number of the registered users of Sina Weibo have exceeded 500 million, and the daily volume of microblogers’ posts reaches more than 100 million. Inferring interest for microbloggers from microblogs plays an important role for improving user experiences and satisfactions. With identified interest from microblogs, the enterprises or companies can provide proper services such as information searching, targeted advertising and personalized recommendation for users. Therefore, inferring user interest from microblogs has become an emerging issue in the recent years. However, the information of these microblogs generates unique characteristics such as massive data size, dynamic change of information and persistence, which put forward the underlying challenge for user interest inference. Figure 1 shows a simple example of inferring users’ interest in different environments. As shown in the left side of Fig. 1, in traditional environments, large-scale information of microblogs which are composed of both massive users and posts published by these users, cannot be tackled at once by traditional methods for user interest inference. In addition, these posts are updated as the time goes by, which further increase the difficulty of inferring user interest.
User interest inference in different environment.
Generally, most existing methods pay far less attention on the combination of afore-mentioned characteristics for microbloggers’ interest extraction [1, 2, 3], and only take one of these three characteristics of microblogs for inferring user interest into consideration. For example, several significant findings only focused on the dynamic change of information in microblogs [4, 5]. They inferred microbloggers’ real-time interest by analyzing information of microblogs in a given time interval. However, these methods are batch algorithms, and it is difficult to process massive information simultaneously with every increasing size of microbloggers and posts. In addition, several promising findings only focused on the characteristic of massive data size for microbloggers’ interest extraction [6, 7]. These findings coped with the massive social data by utilizing the big data technologies such as Hadoop. Nonetheless, the characteristics of social data such as dynamicity and persistence are ignored during data processing. As a consequence, the effectiveness of mining user interest is extremely low. Therefore, how to effectively and efficiently infer user interest over large-scale microblogs is a crucial research challenge.
To address the aforementioned challenge, we develop a microbloggers’ interest inference approach by making use of the data structure of subgraph stream. Specifically, the proposed method, named User-Networked Interest Topic Extraction in the form of Subgraph Stream (UNITE_SS for short), is shown in the right side of Fig. 1. The idea of the data structure in the proposed method is motivated by the data stream [8], where the characteristic of microblogs is similar to that of data stream, except for the social relations such as ‘following/follower’ and ‘retweet’ characteristics of microblogs. Hence, we name the data structure as “subgraph stream”. In UNITE_SS, we transfer a traditional processing framework into “subgraph stream” by social relations, and then infer microbloggers’ interest by means of each subgraph. As can be seen from the right side of Fig. 1, a sequence of subgraphs
The main contributions of this study are summarized as follows:
In view of the traditional methods for user interest inference ignoring the combination of the massive data size, dynamic change of information and persistence characteristics of microblogs, we propose a microbloggers’ interest inference approach based on the data structure of subgraph stream. Note that the data structure can be extended to exploit not only an effective way for user interest inference, but also a solution to the problem of large-scale graph partitioning with constraints resources. To find an effective subgraph stream for user interest inference, several strategies for subgraph stream construction are proposed. To the best of our knowledge, we propose the first subgraph stream approach considering the sequence of subgraphs by using correlations between subgraphs to improve user interest inference. Furthermore, to evaluate the effectiveness of the subgraph stream, these strategies are applied into traditional user interest inference methods. Experiments are performed on a real dataset from Sina Weibo, which can demonstrate the efficiency and effectiveness of the proposed approach. Moreover, our proposed approach consistently outperforms the state-of-the-art methods in terms of precision, mean reciprocal rank (MRR) and runtime.
The remainder of the paper is organized as follows. Section 2 summarizes the related work. Section 3 gives the formulation of the problems. Section 4 reveals the details of our proposed approach. Furthermore, Section 5 experimentally compares our proposed approach with the state-of-the-art methods on the Sina Weibo dataset and discusses the experimental results. Finally, Section 6 draws conclusions.
There have been several fruitful findings related to inferring user interest from microblog, and most of these findings have only focused on one characteristic of microblogs, such as dynamic change of information or massive data size of microblogs for user interest inference. Therefore, these findings are classified as dynamic-based interest inference methods and large-scale-based interest inference ones. Besides, in this section, several theoretical achievements related to subgraph stream construction will be introduced as well.
Dynamic-based interest extraction methods
Most previous methods for user interest inference concentrated on the short text feature of microblogs, without taking into account the massive data size, dynamic change of information and persistence characteristics of microblogs. Some studies enriched the short text of microblogs by using external knowledge base such as Wikipedia [1, 2]. Meanwhile, some research work extended the insufficient context of microblogs by utilizing social graph structure. For example, Wang et al. [3] proposed a user interest propagation method to infer new users’ interest by the combination of textual content with social network relationships. User-Networked Interest Topic Extraction (UNITE) [11] was proposed to extract general microbloggers’ interest by using both the contextual information and the ‘following’ relations between microbloggers. Nonetheless, these methods for user interest inference utilized the static information of microblogs within a fixed period of time without considering the dynamic change of information in microblogs.
Recent years, several significant insights have focused on the dynamic characteristic of microblogs to inferring user interest. For example, Zarrinkalam et al. [4] inferred users’ interest over the emerging topic on Twitter in a given time interval by exploiting external semantic concepts. Budak et al. [12] proposed a probabilistic generative model to infer online user interest from Twitter. Literatures [5, 13] collected microbloggers’ information in time order, and then proposed variant topics models to identify microbloggers’ interest at each time. Bao et al. [14] proposed a social probabilistic matrix factorization model to predict users’ interest by the combination of time information and social network structure. However, with the growth of microbloggers and their published posts, these methods are batch algorithms and cannot handle large amounts of social data due to the resource restriction. Therefore, these methods are not suitable for inferring microbloggers’ interest over large-scale microblogs.
Large-scale-based interest extraction methods
With the prevalence of social networks, some research work for large-scale social data analysis in several areas has been emerged to find the value of information. For example, large-scale social network data has been discussed to discover drug users and potential adverse events [15], user profiles [16], privacy issues [17, 18], influential users [19] user behavior analysis [32] and social user interest [6].
Only few of them focus on inferring users’ interest over large-scale microblogs. Pennacchiotti and Gurumurthy [6] discovered millions of microbloggers’ interest on the basis work of Parallel LDA [20] and operated this work on a Hadoop cloud computing architecture of 1000 machines, which called “ParallelLDA”. Spasojevic et al. [7] proposed an infrastructure for inferring users’ topical interest and built it on the platform of Hadoop and querying infrastructure of Hive. However, all these methods directly utilized big data technologies such as Hadoop, Cloud Computing and Big Table to improve the processing performance of large-scale data, which fails to address the key characteristics of microblogs such as dynamicity and persistence. Hence, the effectiveness of mining user interest over large-scale microblogs is often poor.
Community detection methods
Similar to the work of designing a subgraph stream, some community detection approaches [9, 10] can be applied to divide the large-scale information of microblogs into small subgraphs (communities). More specifically, Newman [10] divided the network into communities based on the similarity or the strength of the connection between nodes. Mitrović and Tadić [21] detected communities in the network based on spectral algorithms. Blondel et al. [9] extracted the community structure of large networks based on Modularity [22] optimization. However, they have several drawbacks: 1) the directivity of social relations between users, 2) the sequence of communities (subgraphs), and 3) the balanced nodes in a community, which may cause some large communities still cannot be processed.
The aim of these approaches for constructing communities (subgraphs) on the basis of that the internal of a subgraph has a strong structural relation between nodes. However, the nodes belonging to different communities (subgraphs) are weakly connected, and these methods may cause that these communities (subgraphs) have imbalanced nodes. Different from it, the goal of our work for subgraph stream construction is designing a sequence of directed and balanced subgraphs, and there is association between adjacent subgraphs, which is more consistent with the characteristics of microblogs.
Recently, graph partitioning has been prevalent in scientific computing [26, 27, 28, 29]. Similar to community detection, graph partitioning are designed to construct a lot of subgraphs for parallel computing. However, in contrast with our problem setup, all these methods do not consider the correlations between subgraphs. Due to these differences, we do not discuss graph partitioning further.
Problem formulation
As described in Section 1, due to the massive data size, dynamicity and persistence of microblogs, we propose a subgraph stream for user interest inference. In the following, we formally define a subgraph stream, and then illustrate the research problems.
.
(Subgraph). A subgraph
.
(Subgraph stream). A subgraph stream
.
(User interest). Given a set of topics
Additionally, there are two following hypotheses in our work.
To handle these problems effectively, the framework of our approach proposes strategies for constructing subgraph stream
Our proposed UNITE_SS approach
In this section, we first give an overview of our proposed approach (refer to Section 4.1) and its corresponding algorithm UNITE_SS (refer to Section 4.2), and then explore various subgraph stream construction strategies to choose the best subgraph stream for microbloggers’ interest inference (refer to Section 4.3). Finally, we describe some traditional user interest extraction methods and give the idea that how to apply these methods based on the data structure of subgraph streams (refer to Section 4.4).
Overview
To overcome the challenge of the dynamicity and persistence characteristics of microblog information, we propose an approach named UNITE_SS (User-Networked Interest Topic Extraction in the form of Subgraph Stream), which can be divided into two main parts: subgraph stream construction and user interest inference based on the data structure of subgraph stream, as shown in Fig. 2. When a subgraph is constructed, traditional methods for user interest extraction can be performed on each subgraph to infer microbloggers’ interest, where these methods contain 1) candidate user interest extraction, 2) social relations graph building, and 3) user interest ranking.
The workflow of our proposed UNITE_SS approach.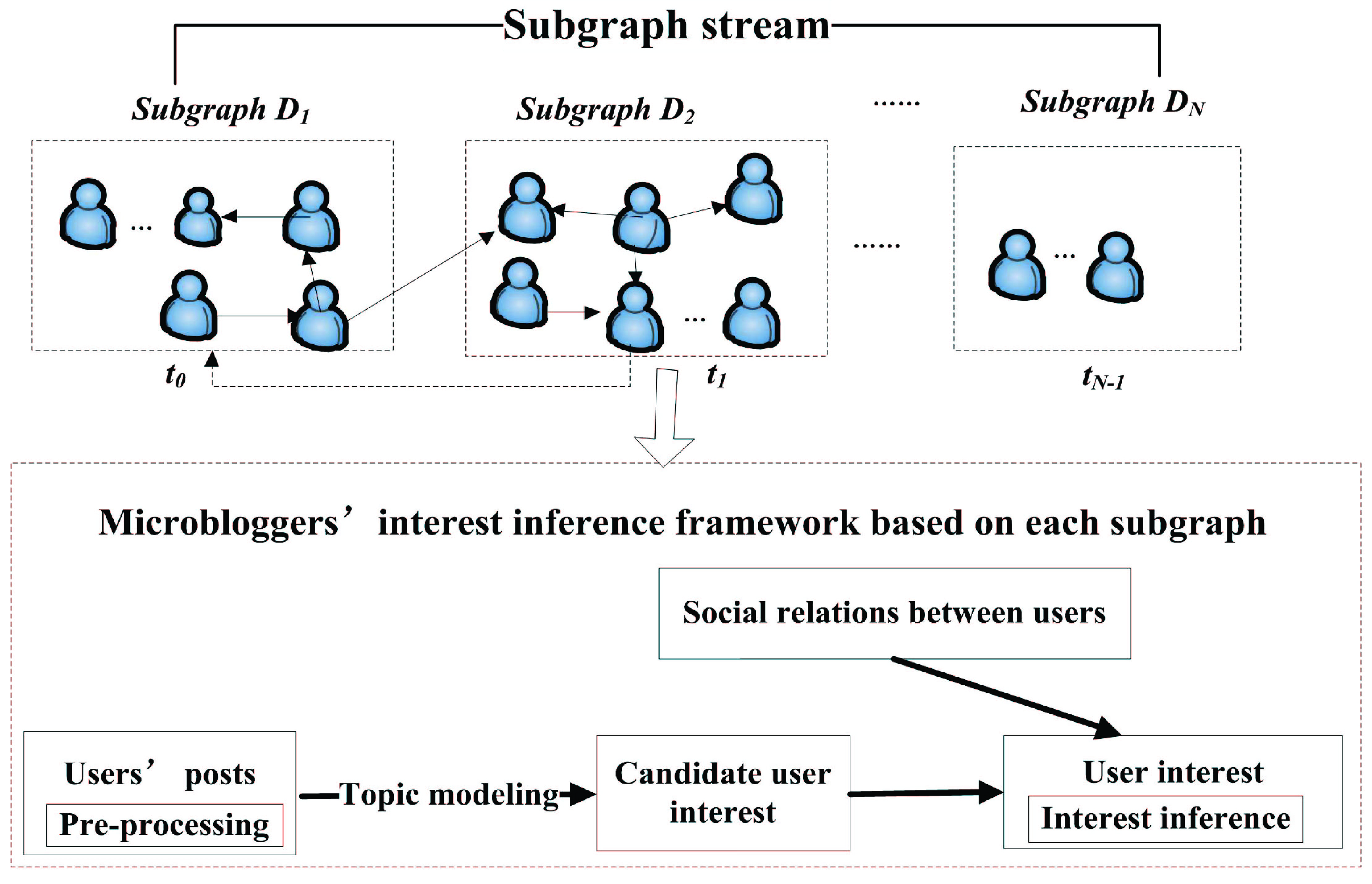
Based on the above descriptions, we present the framework of UNITE_SS in the form of Pseudo-code, as shown in Algorithm 1. The algorithm takes candidate users in List and their graph structural information of microblog as input, and then iteratively generates subgraphs by choosing the users that satisfies some conditions from List and crawling posts of the users immediately. When a subgraph
Step 1: initialize a subgraph stream
Step 2: delete users contained in
Step 3: choose a subgraph stream construction strategy proposed in Section 4.3 for selecting users from List through Line 5 of Algorithm 4.2. According to the chosen subgraph construction strategy presented in Section 4.3, select a user
Step 4: delete the user
Step 5: according to the chosen strategy for subgraph construction (detailed in Section 4.3), select the user
Step 6: a subgraph
Step 7: repeat Step 3 to Step 6 respectively until
More details regarding the UNITE_SS algorithm are illustrated in Algorithm 4.2.
UNITE_SS algorithm Candidate users in List and their graph structural information of microblog Interest of microbloggers.
Subgraph stream construction
In this subsection, we propose various strategies for subgraph stream construction to solve Problem 1 which mentioned in Section 3. Furthermore, we discuss which subgraph stream construction strategy can better improve the quality of user interest.
Before introducing subgraph stream construction strategies, a simple toy example from Fig. 1 is prepared to demonstrate different subgraph stream construction strategies. There are ten users
As mentioned in UNITE_SS algorithm, subgraph stream construction can be transformed into the problem that how to select the candidate users from List to construct a strongly connected graph that containing equals or less than
Random strategy for subgraph stream construction
We propose a subgraph stream construction strategy named Random.
(1) Idea of Random strategy
As mentioned in UNITE_SS algorithm, to continually select a candidate user
Running Random strategy with a example.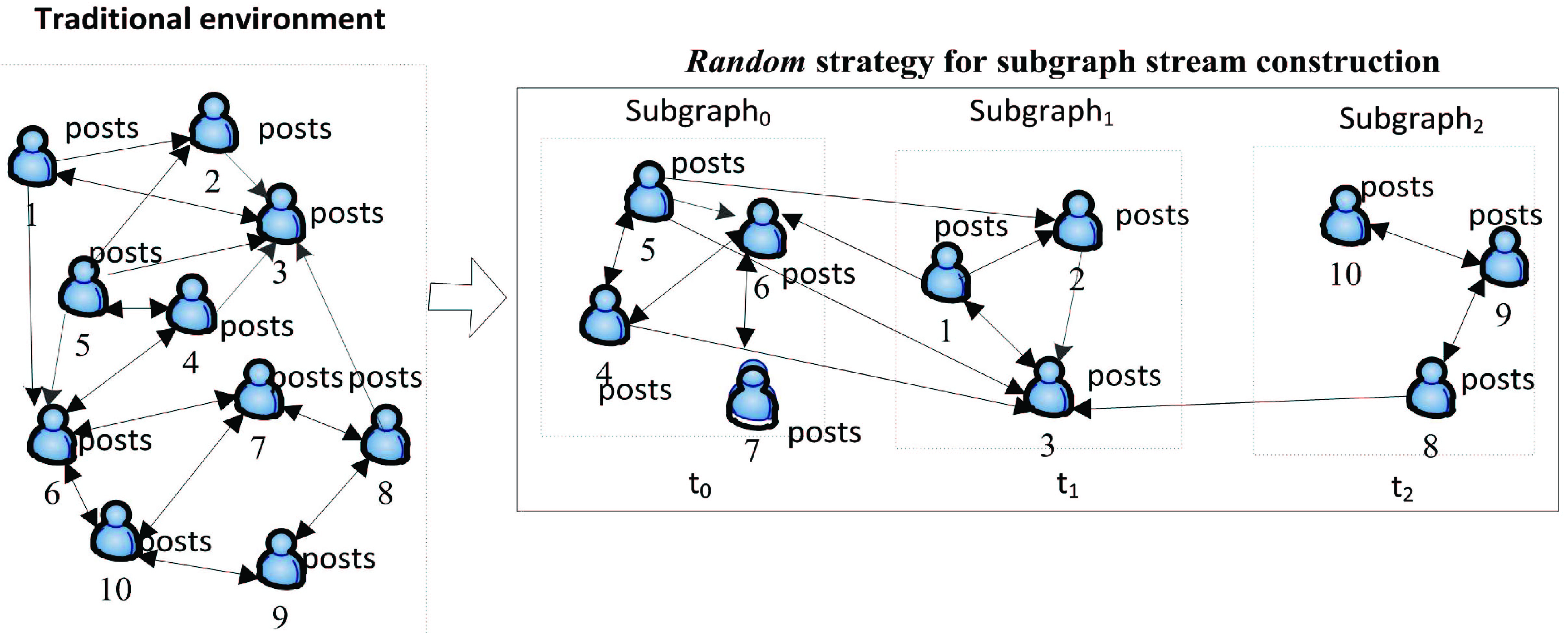
(2) Run Random strategy by the toy example
By incorporating Random strategy into UNITE_SS algorithm, a subgraph stream can be obtained. The process of constructing a subgraph stream is given in Fig. 3.
Given
Furthermore, if the condition that described in Line 11 of UNITE_SS algorithm is true, a random number
Finally, according to the same iterative process, we can repectively generate subgraph
As discussed previously, a subgraph stream can be generated by Random strategy. However, each time Random strategy is executed, the result of subgraph stream is different. Therefore, it is desired to explore relatively stable subgraph stream construction strategies for overcoming this limitation. Here, we propose a subgraph stream construction strategy named MaxAssociation.
(1) Idea of MaxAssociation strategy
Given the hypotheses
Algorithm 4.3 presents the pseudo-code of MaxAssociation. In Line 3 of Algorithm 4.3,
[htbp] MaxAssociationList and their graph structural information, subgraph
(2) Run MaxAssociation strategy by the toy example
By incorporating MaxAssociation strategy into UNITE_SS algorithm, a subgraph stream can be obtained, as shown in Fig. 4. The process of constructing a subgraph stream is given in Fig. 4.
Running MaxAssociation strategy with an example.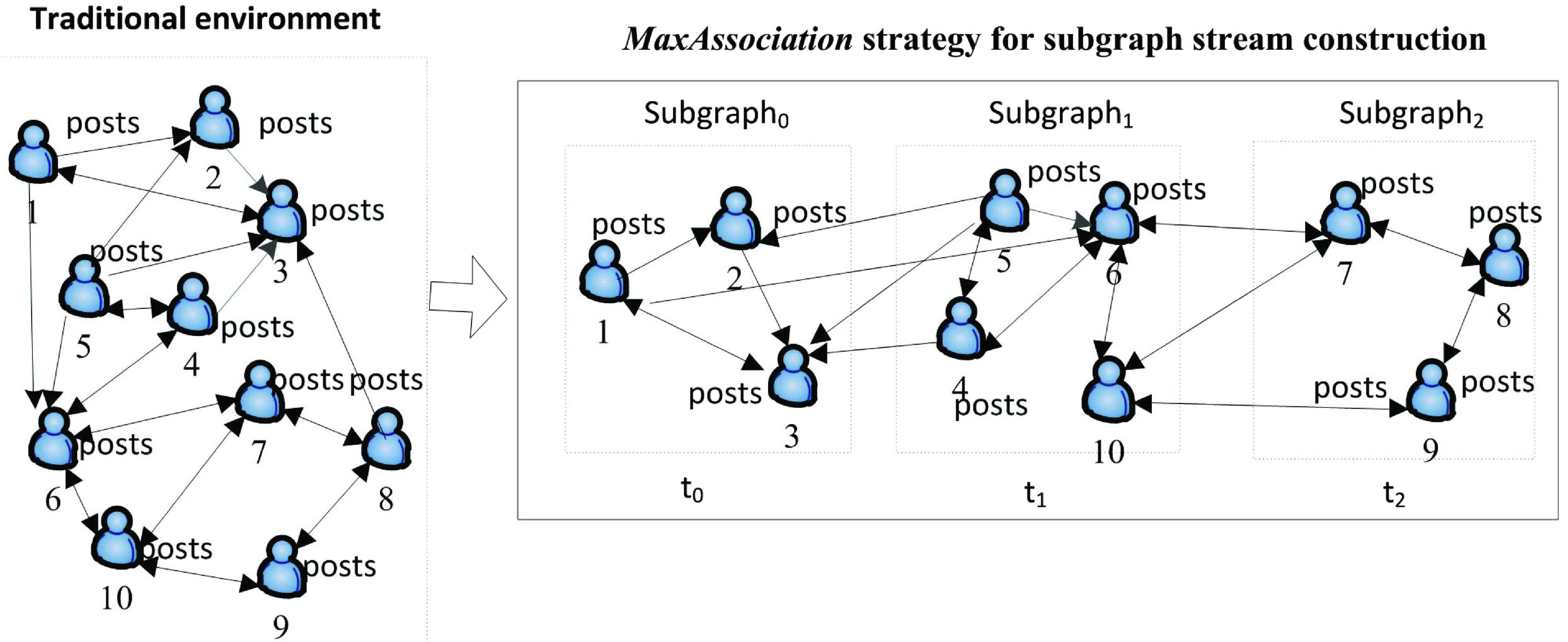
First, we can get
Then, based on the principle that there are most number of overlapping users between the followers/followees of candidate users selected from List and
Next, if the condition that described in Line 11 of UNITE_SS algorithm is true and
Finally, according to the aforementioned iterative process, we can generate
Although MaxAssociation can construct a relatively stable subgraph stream, the effectiveness of this strategy often depends on the initial subgraph. Hence, we propose another strategy named HighFrequency.
(1) Idea of HighFrequency strategy
Based on the principle that the candidate user has the highest frequency of updating his/her microblogs within a period of time
[htbp] HighFrequencyList and their graph structural information. subgraph
(2) Run HighFrequency strategy by the toy example
By incorporating HighFrequency strategy into UNITE_SS algorithm, a subgraph stream can be obtained, as shown in Fig. 5. The process of constructing a subgraph stream is given in Fig. 5.
Running HighFrequency strategy with an example.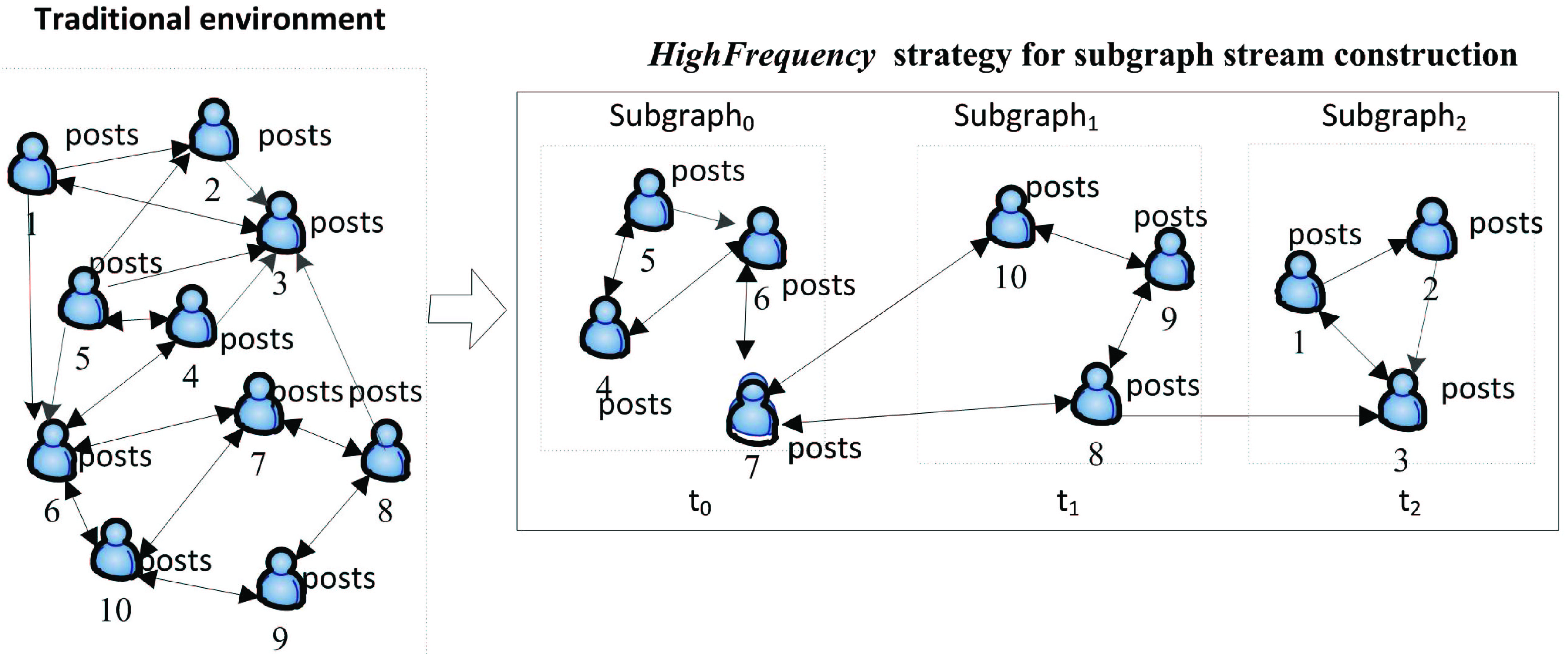
First, based on the high frequency of each user in List within a week,
Furthermore,
Subsequently, if the condition that described in Line 11 of UNITE_SS algorithm is true and
Finally, based on the iterative process mentioned above, we can respectively produce
Previous strategies may cause less close associations between adjacent subgraphs because of the uncertainty of selecting initial users from List to construct subgraphs. Therefore, we propose another strategy named ShortDistance.
(1) Idea of ShortDistance strategy
Given a previous subgraph
where
Then, user
where
Based on the above preparations, Algorithm 4.3 presents the ShortDistance algorithm for subgraph stream construction.
[htbp] ShortDistanceList and their graph structural information, subgraph
(2) Run the strategy of ShortDistance by the toy example
By incorporating ShortDistance strategy into UNITE_SS algorithm, a subgraph stream can be obtained as shown in Fig. 6. Compared with HighFrequency strategy shown in Fig. 5, the subgraph stream in Fig. 6 has more associations between adjacent subgraphs, which is benefit for user interest extraction. The reason is that the closer associations between subgraphs are, the more network information can be obtained to improve the quality of microbloggers’ interest further.
Comparison ShortDistance with other strategy using an example.
HighFrequency can early find active users, therefore it prones to generate more relations in a subgraph. However, active users who are not influential person may cause less users in a subgraph, which will cause poor quality of extracting user interest. Meanwhile, the effectiveness of MaxAssociation depends on the initial subgraph. Therefore, we propose another strategy named MaxAssociation&HighFrequency.
(1) Idea of MaxAssociation
HighFrequency strategy
According to the principle that the combination of MaxAssociation and HighFrequency, List is sorted by the associations. Then subgraph
(2) Run MaxAssociation
HighFrequency strategy by the toy example
As the example described in MaxAssociation strategy, candidate users
In a word, there are four algorithms discussed in Sections 4.2 and 4.3 respectively. To better illustrate the associations between the proposed algorithms, a diagram is shown in Fig. 7. As seen from Fig. 7, there are five strategies for subgraph stream construction consisting the algorithm list, where three of them is given corresponding algorithm, and the idea of MaxAssociation&HighFrequency strategy is a combination of Algorithm 4.3 and Algorithm 4.3. Besides, when Step 3 in UNITE_SS algorithm is executed, a subgraph stream strategy must be chosen from the algorithm list.
An illustration diagram showing links between the proposed algorithms.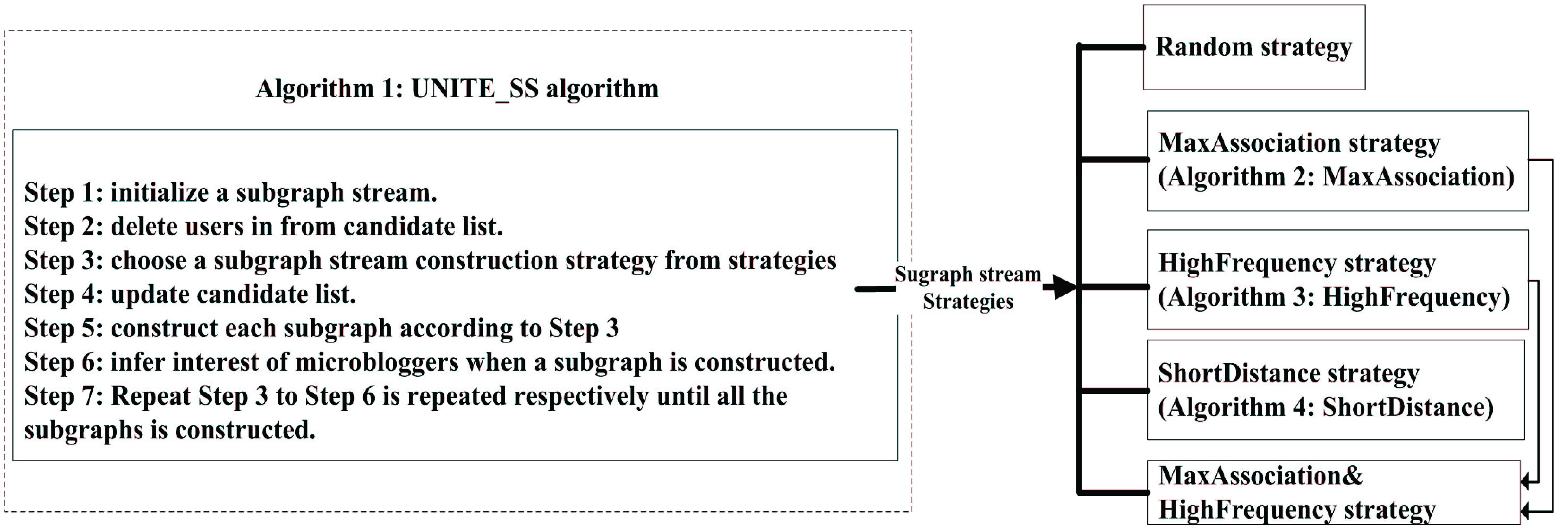
Traditional methods such as UNITE (User-Networked Interest Topic Extraction) [11] and RWTP (Random Walk Topic Propagation) [3] can be applied and extended in the data structure of subgraph stream to infer microbloggers’ interest from dynamic information of microblogs, where UNITE is effective for mining microbloggers’ interest from the static information of microblog [11]. Therefore, we choose UNITE as the example and extend UNITE on each subgraph, which can be divided down into three steps to extract user interest, namely, candidate user interest topic generation, network construction and interest topic ranking.
(1) Candidate interest generation
To extract candidate interest topics by a user on a subgraph, we perform a topic model (such as Twitter-user [23]) over the posts of each subgraph
where
(2) Network construction
Besides the network between the users within a subgraph, there are associations between the adjacent subgraphs, so we construct the subgraph
(3) Interest ranking
According to each user’s candidate interest and graph
where
where
In this section, the process of data collection and the general statistics of the data are described. Subsequently, the evaluation measures are given. Furthermore, the influences of subgraph construction strategies are explored. Finally, the experimental results are performed to show the advantages in comparison with the baselines.
Dataset
In order to verify the effectiveness of our proposed approach, we collect data from Sina Weibo, which is one of the most famous and representative microblogs in China. The crawling of dataset is performed as follows.
Initially, we collect the user Kaifu Lee to the initiate user list named List. That is due to Kai-fu Lee is a famous and active user in Sina Weibo. Based on the intuition that the followees of microblogger are most likely to be active users, we collect the followees of each user
After completing iterative process, we can obtain a large social stream named SubGraphData by collecting users in List and their information such as posts, the follower list and the followee list, where each user’s recent 100 posts are collected, and up to 200 followees or followers for each user can be crawled because the maximum visible number of followees or followers in Sina Weibo is 200.
There are 259,185,126 original posts created by 2,433,429 users. In fact, some users have more than 200 followees or followers. However, there are an average of 42 missing followees or followers per user due to the crawling restrictions imposed by Sina Weibo and network delay. On the other hand, for the posts published by users is noisy, we make use of the same pre-processing method of [11] to denoise. After pre-processing, SubGraphData contains 192,309,705 posts with an average of 25.8% denoising rate, and 2,072,727 users with an average of 14.8% denoising rate. The general statistics information of our experimental dataset with an average of 54.31 following relations between users are shown as Table 1. To the best of our knowledge, SubGraphData has more users than any dataset reported in the field of user interest inference.
General statistics of SubGraph data
General statistics of SubGraph data
To evaluate the quality of user interest inference from microblogs, we introduce the measures of Precision and Mean Reciprocal Rank (MRR) as two famous metrics in Natural language processing for ranking the quality of the results. In addition, both of them are widely used in the literature [1, 11, 30, 31] for measuring the quality of user interest. The brief descriptions of Precision and MRR are outlined as follows.
(1) Precision
where
(2) MRR
MRR [25] is used to evaluate how the first correct interest for each user is ranked. MRR for the top-
where
In our experiments, we exploit various subgraph stream construction strategies to choose the better strategy for user interest inference in microblogs. In addition, we choose UNITE as the unified user interest extraction method when different subgraph stream strategies are compared.
Effectiveness comparison of subgraph stream construction strategies
Figure 8 shows the comparing results with different subgraph construction strategies under MRR, where the value of
Comparison for all subgraph stream construction strategy using MRR.
First, MaxAssociation
Second, as the number of sampled users
Third, CommunityDetection doesn’t perform best. The reason should be attributed to that this method ignores the directivity of social relations between users, and these communities (subgraphs) constructed by CommunityDetection have either a great deal of users or few users. Furthermore, user interest extracted from communities (subgraphs) that has plenty of users cannot keep pace with the updating posts of the user, which leads to that the extracted interest is out of date, and some communities even cannot be well handled due to large-scale nodes in the communities.
Fourth, Random shows the worst performance. This is due to the fact that inactive user is usually selected as the first node for subgraph construction, which may cause the subgraph have less users and less association between these users.
To validate the efficiency of constructing a subgraph stream, Table 2 shows the Runtime of each subgraph construction strategy combining with the different subgraph selection strategies, where the Runtime can be divided into two main procedures: the Runtime of a subgraph stream construction and the Runtime of user interest extraction on each subgraph.
The Runtime of different subgraph stream strategies for user interest extraction
The Runtime of different subgraph stream strategies for user interest extraction
According to the results presented in Table 2, we can obtain the following observations.
First, CommunityDetection performs the worst in terms of efficiency, this strategy constructs communities (subgraphs) based on the globe network, and thus it spends more time than other strategy on constructing subgraphs. Moreover, the number of users in the subgraph constructed by CommunityDetection are not balance, some subgraphs contain hundreds of thousands of users, while the number of users in each subgraph constructed by our proposed strategies are balance and are no more than
Second, ShortDistance consumes most time in all the subgraph stream constructions. Since each candidate user selected from List for a subgraph construction needs to search all the List, which is time-consuming.
Based on the above experimental results, we choose the combination of MaxAssociation
To validate the effectiveness of our proposed approach, we compare the performance of different user interest extraction methods by leveraging the same subgraph stream. The baselines and our proposed methods are outlined as follows:
RWTP [3] based on a subgraph stream, where RWTP is a user interest propagation method to extract microbloggers’ interest by combining both text and link information. Here, we use the strategy of MaxAssociation&HighFrequency for subgraph stream construction. In addition, we implement RWTP on each subgraph to extract user’s interest. IFT (Interest Found by Time) [4] based on a subgraph stream, where IFT can identify users’ interest within a specific time interval. The subgraph stream used in IFT is same as that in RWTP. ParallelLDA [6], which extracts user interest by building a large-scale LDA model and implement it on Hadoop. UNITE_SS, which utilizes UNITE [11] based on a subgraph stream, where UNITE is a user interest inference method to extract microbloggers’ interest with both the contextual information and the ‘following’ relations between microbloggers. The subgraph stream used in UNITE_SS is same as that in RWTP.
Additionally, we do not directly apply approaches such as RWTP [3], IFT [4] and UNITE [11] to SubGraphData, because these approaches cannot be performed on SubGraphData due to resource constraints.
Table 3 shows the comparing results with different approaches for user interest inference on SubGraphData regarding MRR, Precision and Runtime, respectively. As can be seen from Table 3, it is feasible to extend traditional approaches for user interest extraction on a subgraph stream, which solves the problem that user interest cannot be extracted from large-scale microblogs. Additionally, three observation are concluded in the following.
Results of different approaches for user interest inference on SubGraphData
First, UNITE_SS is much more effective and efficient than RWTP based on a subgraph stream, which is consistent with the results of [3]. Since RWTP ranks users’ candidate interest heavily depending on the influences of their neighbors, slightly considering that of posts, which is not suitable for extracting general users. Different from this, UNITE balances the effect of textual posts and social neighbors for performance improving. The details can be found in [11].
Second, IFT based on a subgraph stream doesn’t perform better than RWTP based on a subgraph stream. Since IFT identifies user interest relying on posts published by microbloggers and ignores the social relations between microbloggers, leading to poor quality of microbloggers’ interest. On the other hand, IFT spends more time than RWTP because of incorporating external knowledge such as Wikipedia.
Third, ParallelLDA performs best on efficiency and worst on effectiveness. ParallelLDA performs best because the big data technology such as Hadoop are applied to implement LDA for user interest extraction. On the other hand, ParallelLDA only use short and noisy posts published by microbloggers, and LDA is more effective in regular document such as news than short posts, leading to spoor effectiveness.
In summarize, our proposed approach UNITE_SS takes the trade-off between effectiveness and efficiency into consideration, which provide a better solution to infer user interest over large-scale microblogs comparing with the state-of-the art baseline approaches.
In this paper, we proposed a microbloggers’ interest inference approach based on a subgraph stream. We first proposed different strategies of subgraph stream construction. Furthermore, we introduced the steps of extending traditional user interest extraction approaches on each subgraph. Compared with the previous work which only leveraged static information of microblog or few information of microbloggers to extract interest, our proposed approach UNITE_SS can extract a real-time and effective interest for microbloggers from dynamic, persistence and large-scale microblogs. The data structure of the subgraph stream proposed in our work can solve the problem of extracting microbloggers’ interest, and the idea of subgraph stream can also provide a solution for the problem of large-scale graph partitioning with constraint resources. In our future work, we will study the improvement of efficiency of subgraph stream construction and use more test data for evaluation to validate the robustness of our proposed approach.
Footnotes
Acknowledgments
This work was supported in part by the National Key Research and Development Program of China under grant 2016YFB1000900, the National Natural Science Foundation of China (NSFC) under grant 61503114 and 61906060, the Key Project of the Natural Science Foundation of Educational Commission of Anhui Province under grants KJ2019A0642 and KJ2018A0432, the Anhui Provincial Natural Science Foundation under 1808085MF177 and 2008085MF224, and the Project of the Natural Science Foundation of Educational Commission of Anhui Province under grant KJ2018B03.