We review neural network architectures which were motivated by Fourier series and integrals and which are referred to as Fourier neural networks. These networks are empirically evaluated in synthetic and real-world tasks. Neither of them outperforms the standard neural network with sigmoid activation function in the real-world tasks. All neural networks, both Fourier and the standard one, empirically demonstrate lower approximation error than the truncated Fourier series when it comes to approximation of a known function of multiple variables.
Machine learning is an actively developing area studying algorithms and statistical models that perform specific tasks without using explicit instructions, relying on patterns and inference instead. It is seen as a subset of artificial intelligence. Machine learning algorithms build a mathematical model based on sample data, known as “training data”, in order to make predictions or decisions without being explicitly programmed to perform the task [26, 6]. For example, in image recognition, they might learn to identify images that contain cats by analyzing example images that have been manually labeled as “cat” or “no cat” and using the results to identify cats in other images. They do this without any prior knowledge of cats, for example, that they have fur, tails, whiskers and cat-like faces. Instead, they automatically generate identifying characteristics from the examples that they process. Machine learning algorithms are used in a wide variety of applications, such as email filtering and computer vision, where it is difficult or infeasible to develop a conventional algorithm for effectively performing the task.
Artificial neural networks (ANN) are machine learning models vaguely inspired by the biological neural networks that constitute animal brains. An ANN is based on a collection of connected units or nodes called artificial neurons, which loosely model the neurons in a biological brain (Fig. 1).
An artificial neural network as an interconnected group of nodes (left). Neuron and myelinated axon, with signal flow from inputs at dendrites to outputs at axon terminals (right). Source: Wikipedia.
Each connection, like the synapses in a biological brain, can transmit a signal to other neurons. An artificial neuron that receives a signal then processes it and can signal neurons connected to it. In ANN implementations, the “signal” at a connection is a real number, and the output of each neuron is computed by some non-linear function of the sum of its inputs. The connections are called edges. Neurons and edges typically have a weight that adjusts as learning proceeds. The weight increases or decreases the strength of the signal at a connection. Neurons may have a threshold such that a signal is sent only if the aggregate signal crosses that threshold. Typically, neurons are aggregated into layers. Different layers may perform different transformations on their inputs. Signals travel from the first layer (the input layer), to the last layer (the output layer), possibly after traversing the layers multiple times.
The original goal of the ANN approach was to solve problems in the same way that a human brain would. However, over time, attention moved to performing specific tasks, leading to deviations from biology. ANNs have been used on a variety of tasks, including computer vision, speech recognition, machine translation, social network filtering, playing board and video games, medical diagnosis and even in activities that have traditionally been considered as reserved to humans, like painting [11].
In this work we explore several neural network architectures, the authors of which were inspired by Fourier analysis, the branch of mathematics that studies the way general functions may be represented or approximated by sums of simpler trigonometric functions. Fourier analysis grew from the study of Fourier series, and is named after Joseph Fourier, who showed that representing a function as a sum of trigonometric functions greatly simplifies the study of heat transfer. We will collectively refer to the NN architectures inspired by the Fourier analysis as Fourier Neural Networks (FNNs). First FNNs were proposed in 80s and 90s, but they are not widely used nowadays. Is there any reasonable explanation for this, or were they simply not given enough attention? To answer this question we perform empirical evaluation of the FNNs, found in the existing literature, on synthetic and real-world datasets. We are mainly interested in the following hypotheses: Is any of the FNNs superior to others? Does any FNN outperform conventional feedforward neural network with the logistic sigmoid activation? Our experiments show that the FNN of [10] outperforms all other FNNs, and that all FNNs are not better than the standard feedforward neural architecture with sigmoid activation function except the case of modeling synthetic data.
Related work
Approximation properties of standard feedforward neural networks were studied earlier by Hornik et al. [14], Cybenko [7]. The approximation error bound for such networks was first derived by Barron[4]. The study of convergence rates of Fourier series goes back to 1960-s and we refer the reader to the works of Alimov et al. [2, 3] for a survey of the results in this area.
The first Fourier Neural Networks were introduced by Gallant and White[10], who also showed that their networks possess the convergence guarantees of the Fourier series. McCaffrey and Gallant [22] derived the approximation error bound for the FNN of Gallant and White[10]. Later, Silvescu[27] introduced another type of a FNN, but did not investigate its approximation error. Finally, Liu [20] suggested one more version of a FNN, but did only empirical evaluation of its performance.
To the best of our knowledge, our work is the first one that compares systematically the known Fourier Neural Networks on synthetic and real-world data.
Preliminaries
Notation. We let and denote the integer and real numbers, respectively. Bold-faced letters (, ) denote vectors in -dimensional Euclidean space , and plain-faced letters (, ) denote either scalars or functions. denotes inner product: ; and , denote the Euclidean norm: .
Feedforward neural networks. Following a standard convention, we define a feedforward neural network with one hidden layer of size on inputs in as
where is the activation function, and , , , are parameters of the network. The universal approximation theorem [14, 7] states that a feedforward network Eq. (1) with any “squashing” activation function , such as the logistic sigmoid function, can approximate any Borel measurable function with any desired non-zero amount of error, provided that the network is given enough hidden layer size . Universal approximation theorems have also been proved for a wider class of activation functions, which includes the now commonly used ReLU[19]. The neural network (1) with logistic sigmoid activation is referred to as standard or vanilla feedforward neural network.
Fourier series. Let be a function integrable in the -dimensional cube . The Fourier series of the function is the series
where the numbers , called Fourier coefficients, are defined by
Conceptually, the feedforward neural network with one hidden layer Eq. (1) and the partial sum of the Fourier series Eq. (2) are similar in a sense that both are linear combinations of non-linear transformations of the input . The major differences between them are as follows:
The Fourier series has a direct access to the function being approximated, whereas the neural network does not have it – instead it is usually given a training set of pairs , where is a noise (error).
The coefficients and linear transformations of the input in the Fourier series are fixed, but they are trainable in the neural network and are subject to estimation based on the training set .
There exists a variety of results on convergence of different types of partial sums (rectangular, square, spherical) of the multiple Fourier series Eq. (2) to in various senses (uniform, mean, almost everywhere). We refer the reader to the works of [2, 3] for a survey of such results. It seems that the existence of such convergence guarantees has motivated several authors to design the activation functions for Eq. (1) in such a way that the resulting neural networks mimic the behavior of the Fourier series Eq. (2). In the next section we give a brief overview of such networks.
Overview of the Fourier neural networks
FNN of Gallant and White[10]: The earliest attempt on making a neural network resemble the Fourier series is due to Gallant and White[10] who have suggested the “cosine squasher”
as an activation function in the feedforward network Eq/ (1). Moreover, they show that when additionally the connections , from input to hidden layer are hardwired in a special way, the obtained feedforward network yields a Fourier series approximation to a given function . Thus, such networks possess all the approximation properties of Fourier series representations. In particular, approximation to any desired accuracy of any square integrable function can be achieved by such a network, using sufficiently many hidden units. McCaffrey and Gallant[22] showed that the squared approximation error for sufficiently smooth functions is of order , where is the network’s hidden layer size. We notice here that Barron[4] has established the same order of the approximation error for the feedforward networks with any sigmoidal activation1
A bounded measurable function on the real line is called sigmoidal if as and as .
and when the function being approximated has a bound on the first moment of the magnitude distribution of the Fourier transform. FNN of Gallant and White[10] is denoted as .
FNN of Silvescu[27]: Another attempt to mimic the behavior of the Fourier series by a neural network was done by Silvescu[27], who introduced the following FNN:
with
where , are trainable parameters. As we can see, Silvescu’s FNN Eq. (4) does not follow the framework of the standard feedforward neural networks Eq. (1), and moreover its activation function is not sigmoidal. Figure 2 depicts the difference between Eqs (1) and (4) for the case when and .
Standard feedforward NN (top) vs Silvescu’s Fourier NN (bottom). In the standard NN non-linearity is applied on top of the linear transformation of the whole input, whereas in the Silvescu’s network non-linearity is applied separately to each component of the input vector.
Because of this difference, the result of Barron[4] is not applicable to Silvescu’s FNN. However, we conjecture that the same convergence rate is valid for the Silvescu’s FNN. The proof (or disproof) of this conjecture is deferred to our future work.
FNN of Liu[20]: More recently, several authors suggested the following architecture
where , are either hardwired or trainable, and are trainable parameters. Tan[28] explored aircraft engine fault diagnostics using Eq. (6), Zuo and Cai[29, 30], Zuo et al. [31] used it for the control of a class of uncertain nonlinear systems. The above-mentioned authors did not provide rigorous mathematical analysis of this architecture, instead they used it as an ad-hoc solution in their engineering tasks. Although this FNN fits into the general feedforward framework Eq. (1), its activations are not sigmoidal, and thus the result of Barron[4] is not applicable here as well. Liu [20] empirically evaluated Eq. (6) on various datasets and showed that in certain cases it converges faster than the feedforward network with sigmoid activation and has equally good predicting accuracy and generalization ability. Also, only in the work of Liu [20] all the weights in Eq. (6) are allowed to be trainable, hence we refer to this architecture as .
Empirical evaluation
In this section we will perform empirical evaluation of the Fourier neural networks , , from Section 4 against vanilla feedforward network Eq. (1) with sigmoid activation2
on synthetic and real-world datasets. By “synthetic datasets” we mean datasets generated from a known function. In this case we can also compare the performance of Fourier neural networks to the approximation error given by the partial Fourier series.
Synthetic tasks
We try to approximate a function of one variable , , and a function of variables: , , where is the indicator function.3
This means that if , and 0 otherwise.
In both cases we sampled data instances uniformly from the domains of the functions. To each instance, we associated a target value according to the target function or . We did not add noise to the target values. Another examples were generated in a similar manner, of which examples were used as a validation set, and examples were used as a test set. We trained 32 networks on these datasets: for each of the above-mentioned models (vanilla feedforward network, , , ) we varied the hidden layer size from 100 to 800 with the step 100. Training was performed with Adam optimizer (Algorithm 5.1) using the TensorFlow ([1]) library.4
Our implementation of FNNs is available at https://github.com/zh3nis/FNN.
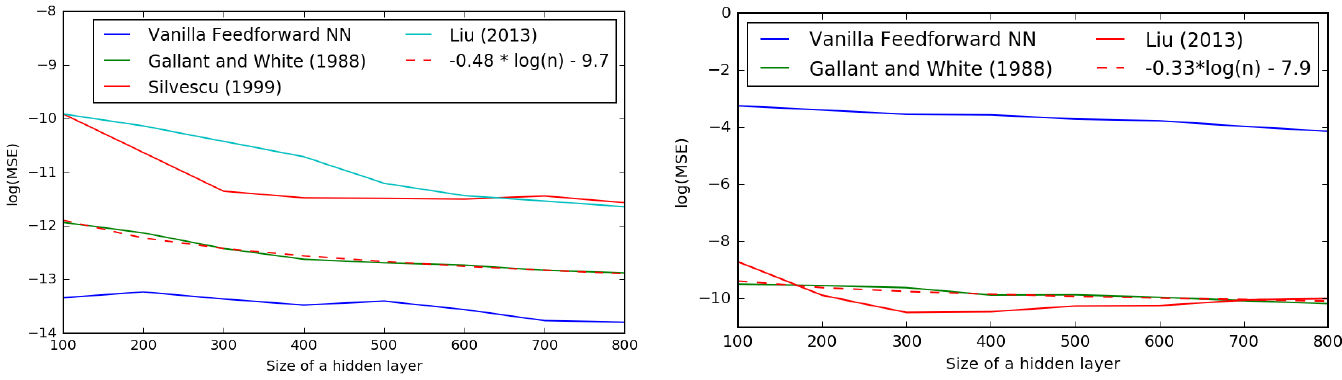
We used the squared loss and batches of size 100. For each model, a learning rate was tuned separately on the validation set. The results are presented in Fig. 3. Vanilla feedforward network Eq. (1) obtains lowest mean squared error (MSE) for , whereas the FNN of [10] outperforms all other models for . According to the regression fits (dashed curves in Fig. 3), the function is approximated by the neural networks with error , and this is much worse than the approximation error given by the partial sums of the Fourier series of , which, according to Lemma 1 below, is of order . For the function results are to other way around: the approximation error by the neural networks is of order , while it is of the order by the truncated Fourier series (see Lemma 2 below). We keep in mind that the theoretical result of Barron[4] states that for any function from a certain class5
Functions with bounded first moment of the magnitude distribution of the Fourier transform, which we refer to as Barron functions in agreement with [18].
(to which the indicator function does belong) a feedforward neural network with one hidden layer of size will be able to approximate this function with a squared error of order . We are not guaranteed, however, that the training algorithm will be able to learn that function. Even if the neural network is able to represent the function, learning can fail, since the optimization algorithm used for training may not be able to find the value of the parameters that corresponds to the desired function. We attribute the mismatch, instead of , between the orders of approximation errors to the suboptimal estimation of the parameters of the networks by the Adam optimizer. However, in general we have experimentally confirmed Barron’s claim that neural networks with hidden units can approximate functions with much smaller error than series expansions with terms.
Initialize to a random point Initialize , not converged Sample random indices Adam Optimizer [16] for finding a local minimum of a cost function , where , is the loss for an observation, and are hyperparameters. For a subset of indices denote .
Results of approximating (left) and (right) by Fourier neural networks and Fourier series. MSE stands for the mean squared error, . Dashed curves were obtained by regressing of on .
We also notice here that directly comparing neural networks with truncated Fourier series is somewhat unfair, as these are two different categories of approximation: Fourier series serve as some theoretical reference, which is possible only when we have access to the function being approximated.
.
For the -periodic function , , let be the partial sum of its Fourier series. Then, for some constant ,
Proof..
The Fourier series expansion of is given by
(see Example 1, p. 23, from Folland[9]), and therefore by Parseval’s Theorem,
Since is a monotonically decreasing sequence, we have
Let and be the indicator function of the unit ball in , that is, . Let be the truncated Fourier Series of , where is the radius of the partial spherical summation and is the number of terms in the partial sum. Then, for some dimensional dependent constant , the following holds
Here “” means that “”, for some dimensional dependent constant . Analogously, we write “” if “” and “”. Denoting , we obtain the following decomposition
Thus the latter sum in Eq. (15) can be estimated as follows,
The number of terms in the spherical partial sum is equal to the number of integer points in the -ball of radius , which is, according to Götze[12], approximated by the volume of such ball up to an error , i.e.
We performed evaluation of the FNNs in the image recognition task using the MNIST dataset [17], which is commonly used for training various image processing systems. It consists of handwritten digit images, pixels in size (see Fig. 4), organized into 10 classes (0 to 9) with 60,000 training and 10,000 test samples. As one can see, some examples are noisy and it is difficult to make a correct classification even for a human. Portion of training samples was used as validation data. Images were represented as vectors , hidden layer size was fixed at 64 for all networks, and classification was done based on the softmax normalization. Mathematically, our networks perform the following computation6
Vectors are assumed to be row vectors, which are right multiplied by matrices (). This choice is somewhat non-standard but it maps better to the way networks are implemented in code using matrix libraries such as TensorFlow.
for a single image :
where is one of the FNNs from Section 4. Training was performed with Adam optimizer (Algorithm 5.1). We used the cross-entropy loss
where is a one-hot vector that represents the true label for the image, and is applied elementwise to the predicted distribution . We used batches of size 100. Learning rate was tuned separately for each model on the validation data. Table 2 compares classification accuracy obtained by the models.
As we can see, all the networks demonstrate similar performance in this task. In fact, the differences between accuracy results are not significant across the models, Pearson’s Chi-square test of independence 5.6449, -value 0.1.
Language modeling
Recurrent neural networks (RNN) have demonstrated tremendous success in sequence modeling in general and in language modeling in particular. The most basic RNN [8] suffers from the problem of vanishing and exploding gradients [5] and is hard to train efficiently. One of the most widespread and efficient alternatives to the basic RNN is the Long-Short Term Memory (LSTM) model [13], which effectively addresses the problem of vanishing gradients. However, LSTM is a fairly complex model with excessive number of parameters and its inner functionality is not obvious. This complexity has motivated some of the researchers to find more apparent and less complex alternatives. One of such alternative models is a Structurally Constrained Recurrent Network (SCRN) proposed by Mikolov et al.[23]. They encouraged some of the hidden units to change their state slowly by making part of the recurrent weight matrix close to identity, thus forming a kind of longer term memory and showed that their SCRN model can outperform the simple RNN and achieve the performance comparable with the LSTM under no regularization and small parameter budget. Below we specify the SCRN-based neural language model.
SCRN cell.
Let be a finite vocabulary of words. We assume that words have already been converted into indices. Let be an input embedding matrix for words – i.e., it is a matrix in which the th row (denoted as ) corresponds to an embedding of the word . Based on word embeddings for a sequence of words , the SCRN model produces two sequences of states, and , according to the equations
where , , , , and are dimensions of and , is the logistic sigmoid function. The last couple of states is assumed to contain information on the whole sequence and is further used for predicting the next word of a sequence according to the probability distribution
where and are output embedding matrices. For the sake of simplicity we omit bias terms in Eqs (21) and (22). Being conceptually much simpler (Fig. 5), the SCRN architecture demonstrates performance comparable to the widely used LSTM model in language modeling task [15], and this is why we chose it for our experiments.
We train and evaluate the SCRN model for {(40, 10), (90, 10), (100, 40), (300, 40)} on the PTB [21] data set, for which the standard training (0–20), validation (21–22), and test (23–24) splits along with pre-processing per Mikolov et al.[24] is utilized. The PTB data is based on texts from the Wall Street Journal, and thus it is a clean dataset with no particular noise. We replace in Eq. (21) with , , and defined in Section 4, and we refer to such modification as Fourier layers. The choice of hyperparameters is guided by the work of Kabdolov et al.[15], except that for the Fourier layers we additionally tune the learning rate, its decay schedule and the initialization scale over the validation split.7
Our SCRN implementation is available at https://github.com/zh3nis/scrn.
To evaluate the performance of the language models we use perplexity (PPL) over the test set
The results are provided in Table 2. As one can see, the conventional sigmoid activation outperforms all Fourier activations, and, as in the case of synthetic data, the Fourier layer of [10] is better than other Fourier layers for most of the architectures.
Evaluation of the SCRN language models on the PTB data. Results are in perplexities of the test set, the lower the better. Columns 2–5 correspond to different configurations of the hidden () and context () states sizes
Activation
(40, 10)
(90, 10)
(100, 40)
(300, 40)
128.0
118.6
118.7
120.6
132.8
119.6
120.1
127.9
144.4
133.4
127.7
125.9
165.7
139.3
147.5
156.8
Discussion
Why do the FNNs of Silvescu[27] and of Liu [20] underperform the one of Gallant and White [10]? These FNNs have non-sigmoidal activations, which makes their optimization more difficult. As was mentioned in Section 4, the convergence guarantees of [4] are not applicable to these models, thus it is not clear whether they can compete with the sigmoidal networks in terms of approximation errors. We will investigate the convergence rates of these FNNs analytically in our future work.
Why does the FNN of Gallant and White [10] underperform the vanilla feedforward network? Although the activation function of is sigmoidal, it still underperforms the standard feedforward neural network in almost all cases. We hypothesize that this is because is constant outside , while is never constant. This means that : , i.e. the activation of Gallant and White[10] Eq. (3) does not distinguish between any values to the right from (and to the left from ). The standard sigmoid activation , on the other hand, can theoretically8
In practice, when implemented on a computer will also be “constant” outside an interval , where depends on the type of precision used for computations.
distinguish between any pair : . To see whether the constant behavior of indeed causes problems, we look at the pre-activated values for from the validation split in the synthetic task of approximating , . The histogram of these pre-activated values for the with hidden layer size 100 is given in Fig. 6.
Histogram of pre-activated values () in the FNN of Gallant and White [10]. Frequencies are at log-scale.
It turns out that 8% of pre-activated values are outside of , and this information is lost when filtered through .
Conclusion and future work
All Fourier neural networks are not better than the standard neural network with sigmoid activation except when it comes to modeling synthetic data. The architecture of [10] is the best among Fourier neural networks. When the function being approximated is known and depends on multiple variables, the neural networks with just one hidden layer may provide much better approximation compared to truncated Fourier series.
In this paper we focused on neural architectures with one hidden layer. It is interesting to compare Fourier neural networks in a multilayer setup. We defer such study to our future work which will also include experiments with a larger variety of functions, as well as mathematical analysis of the approximation of Barron functions by Silvescu’s and Liu’s Fourier neural networks.
Footnotes
Acknowledgments
This work has been supported by the Committee of Science of the Ministry of Education and Science of the Republic of Kazakhstan, IRN AP05133700.
References
1.
AbadiM.BarhamP.ChenJ.ChenZ.DavisA.DeanJ.DevinM.GhemawatS.IrvingG.IsardM. et al., Tensorflow: A system for large-scale machine learning, In OSDI, volume 16, 2016, pp. 265–283.
2.
AlimovS.A.Il’inV.A. and NikishinE.M., Convergence problems of multiple trigonometric series and spectral decompositions, Russian Mathematical Surveys31(6) (1976), 29.
3.
AlimovS.A.Il’inV.A. and NikishinE.M., Problems of convergence of multiple trigonometric series and spectral decompositions, Russian Mathematical Surveys32(1) (1977), 115–139.
4.
BarronA.R., Universal approximation bounds for superpositions of a sigmoidal function, IEEE Transactions on Information Theory39(3) (1993), 930–945.
5.
BengioY.SimardP. and FrasconiP., Learning long-term dependencies with gradient descent is difficult, IEEE Transactions on Neural Networks5(2) (1994), 157–166.
6.
BishopC.M., Pattern recognition and machine learning, springer, 2006.
7.
CybenkoG., Approximation by superpositions of a sigmoidal function, Mathematics of Control, Signals and Systems2(4) (1989), 303–314.
8.
ElmanJ.L., Finding structure in time, Cognitive Science14(2) (1990), 179–211.
9.
FollandG.B., Fourier analysis and its applications, volume 4. American Mathematical Soc., 1992.
10.
GallantA.R. and WhiteH., There exists a neural network that does not make avoidable mistakes, In Proceedings of the Second Annual IEEE Conference on Neural Networks, San Diego, CA, I, 1988.
11.
GatysL.A.EckerA.S. and BethgeM., A neural algorithm of artistic style, arXiv preprint arXiv:1508.06576, 2015.
12.
GötzeF., Lattice point problems and values of quadratic forms, Inventiones Mathematicae157(1) (2004), 195–226.
13.
HochreiterS. and SchmidhuberJ., Long short-term memory, Neural Computation9(8) (1997), 1735–1780.
14.
HornikK.StinchcombeM. and WhiteH., Multilayer feedforward networks are universal approximators, Neural Networks2(5) (1989), 359–366.
15.
KabdolovO.AssylbekovZ. and TakhanovR., Reproducing and regularizing the scrn model, In Proc. of COLING, 2018.
16.
KingmaD.P. and BaJ., Adam: A method for stochastic optimization, In Proceedings of ICLR, 2015.
17.
LeCunY.BottouL.BengioY. and HaffnerP., Gradient-based learning applied to document recognition, Proceedings of the IEEE86(11) (1998), 2278–2324.
18.
LeeH.GeR.MaT.RisteskiA. and AroraS., On the ability of neural nets to express distributions, In Conference on Learning Theory, 2017, pp. 1271–1296.
19.
LeshnoM.LinV.Y.PinkusA. and SchockenS., Multilayer feedforward networks with a nonpolynomial activation function can approximate any function, Neural Networks6(6) (1993), 861–867.
20.
LiuS., Fourier neural network for machine learning, In Machine Learning and Cybernetics (ICMLC), 2013 International Conference on, volume 1, IEEE, 2013, pp. 285–290.
21.
MarcusM.P.MarcinkiewiczM.A. and SantoriniB., Building a large annotated corpus of english: The penn treebank, Computational Linguistics19(2) (1993), 313–330.
22.
McCaffreyD.F. and GallantA.R., Convergence rates for single hidden layer feedforward networks, Neural Networks7(1) (1994), 147–158.
23.
MikolovT.JoulinA.ChopraS.MathieuM. and RanzatoM., Learning longer memory in recurrent neural networks, In Proc. of ICLR Workshop Track, 2015.
24.
MikolovT.KarafiátM.BurgetL.CernockỳJ. and KhudanpurS., Recurrent neural network based language model, In Proc. of INTERSPEECH, 2010.
25.
PinskyM.A.StantonN.K. and TrapaP.E., Fourier series of radial functions in several variables, Journal of Functional Analysis116(1) (1993), 111–132.
26.
SamuelA.L., Some studies in machine learning using the game of checkers, IBM Journal of Research and Development, 1959, pp. 71–105.
27.
SilvescuA., Fourier neural networks, In Neural Networks, 1999. IJCNN’99. International Joint Conference on, volume 1, IEEE, 1999, pp. 488–491.
28.
TanH., Fourier neural networks and generalized single hidden layer networks in aircraft engine fault diagnostics, Journal of Engineering for Gas Turbines and Power128(4) (2006), 773–782.
29.
ZuoW. and CaiL., Tracking control of nonlinear systems using fourier neural network, In Advanced Intelligent Mechatronics, Proceedings, 2005 IEEE/ASME International Conference on, IEEE, 2005, pp. 670–675.
30.
ZuoW. and CaiL., Adaptive-fourier-neural-network-based control for a class of uncertain nonlinear systems, IEEE Transactions on Neural Networks19(10) (2008), 1689–1701.
31.
ZuoW.ZhuY. and CaiL., Fourier-neural-network-based learning control for a class of nonlinear systems with flexible components, IEEE Transactions on Neural Networks20(1) (2009), 139–151.