
Abstract
Quantifying the abnormal degree of each instance within data sets to detect outlying instances, is an issue in unsupervised anomaly detection research. In this paper, we propose a robust anomaly detection method based on principal component analysis (PCA). Traditional PCA-based detection algorithms commonly obtain a high false alarm for the outliers. The main reason is that ignores the difference of location and scale to each component of the outlier score, this leads to the cumulated outlier score deviates from the true values. To address the issue, we introduce the median and the Median Absolute Deviation (MAD) to rescale each outlier score that mapped onto the corresponding principal direction. And then, the true outlier scores of instances can be obtained as the sum of weighted squares of the rescaled scores. Also, the issue that the assignment of the weight for each outlier score will be solved. The main advantage of our new approach is easy to build with unsupervised data and the recognition performance is better than the classical PCA-based methods. We compare our method to the five different anomaly detection techniques, including two traditional PCA-based methods, in our experiment analysis. The experimental results show that the proposed method has a good performance for effectiveness, efficiency, and robustness.
Keywords
Introduction
The detection of outlying instances within data sets has received much attention in the field of machine learning and data mining research. The process of identifying abnormalities, who have different patterns from the majority of instances within datasets, is usually referred to as anomaly detection or outlier detection. The early application of anomaly detection is common to get rid of the contaminated instances. It is important because many machine learning algorithms are so sensitive to the abnormalities that the errors may be achieved in pattern tasks. The procedure is commonly known as data cleaning. However, the extended applications of anomaly detection also get much attention, such as fraud detection, intrusion detection, and fault diagnosis, etc. In these applications, the abnormalities are usually containing interesting information, unknown patterns, or novelty records. Generally, the existing anomaly detection algorithms can roughly fall into two major categories: identified in univariate (such as box plot rule and gaussian model-based) [1] and multivariate data sets [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26]. In practice, the data with univariate, or even bivariate is rarely in real applications. Thus, multivariate detection techniques have received far more attention. In this paper, we limit ourselves to multivariate anomaly detection techniques.
There are many multivariate detection methods have been proposed in recent decades. Including neighbor-based methods (e.g.
A new definition of abnormalities based on PCA was introduced in [8]. The definition computes the abnormal degrees by the sum of weighted squares of the principal component scores. This means the top
the z-scores of
To overcome the above problem, we propose a novel PCA-based approach with the standardization of each outlier score. Our approach is based on the method in [8]. The main contribution of our method is to introduce the median and MAD to rescale each principal component score. And also, we resolved the issue that the assignment of the weight of each outlier score. The new PCA-based approach is a very simple mechanism, and we will show in follow that it is both effective and efficient.
In the remainder of this paper, we first review the related works of the PCA-based anomaly detection methods in Section 2. After that, we will introduce two traditional PCA-based anomaly detection algorithms and their drawbacks in Section 3 and also discuss our proposed algorithm in detail. In Section 4, we perform several extensive experimental evaluations. They include the performance of identifying abnormalities, the time cost of different methods, the robustness in high dimensional data, and the availability of the situation when training dataset contains normal instances only, to prove the superiority of our method. In Section 5, we conclude the paper.
Related work
In this section, we review the previous PCA-based anomaly detection work and illustrate the advantages of our method.
In recent decades, many anomaly detection methods based on PCA have been proposed [8, 9, 10, 11, 12, 13, 14, 15, 16]. The classical PCA approach has some advantages, for instance, it is simple and non-parametric technology with low consumption of time, and it does not need any assumptions on the distribution of data [8]. However, there are also some problems in traditional PCA, so many PCA-based anomaly detection algorithms focus on developing robust PCA methods to overcome the shortcomings. For instance, typical PCA is generally applied to principal components with linear relation. In the non-linear case, kernel PCA has been used. In [12, 13], the principal components of the data distribution were extracted by kernel PCA and then computed the distance between data and corresponding principal to measure anomalies. To handle high-dimensional data, some new robust PCA methods have been proposed [15, 16]. Also, typical PCA is sensitive to the deviated instances, leading to incorrect principal directions are extracted. Two approaches have been introduced in work [10, 11] respectively, they develop the robust covariance estimation. To measure the degree of deviation, the methods use the outlier scores model proposed in work [8]. Besides, to meet computation and memory requirements in a big data scenario, a new way is to develop the online oversampling PCA method to identify the deviated instances in [14] and the anomalies can be spotted by the variation of the principal directions.
In this paper, we focus on the use of classical PCA for anomaly detection. A new computational model of the outlier score was established. The major advantage of our method is the merits of simple calculation and well performance for anomaly detection. Especially, our method can determine anomalies accurately when the correct principal directions were extracted by the use of improved PCA methods.
PCA-based methods
Principal component analysis
PCA is a statistical analysis method that reduces the dimension of data to a few comprehensive principal components. The reduction approach retains maximally the important information of original variables. The information is often measured by using the variance. Principal components are linear combinations of the original variables, are aimed at explaining the multivariate data structure. It is easy to compute through eigen analysis of the covariance matrix of the original variables.
From now on,
Where
The classical PCA is sensitive to deviated data instances because of the mean and variance are attracted toward outlying objectives. One of the solutions is to develop robust PCA approaches. In past decades, various robust PCA methods have been proposed [10, 11, 12, 13, 14, 15, 16, 17]. Surely, these methods help obtain the correct principal components. The robust PCA will help to improve the discrimination of outliers [30]. In our method, we use the original PCA to transform the feature space of data, but the proposed method also improves performance for anomaly detection when the correct principal component extracted. And we design an experiment to check this situation (see the experiment in Section 4.5).
A scatter plot of 200 observations in two-dimensional plane, where the red points denote the normal observations that extract from a standard normal distribution. Obviously, the blue point is an outlier.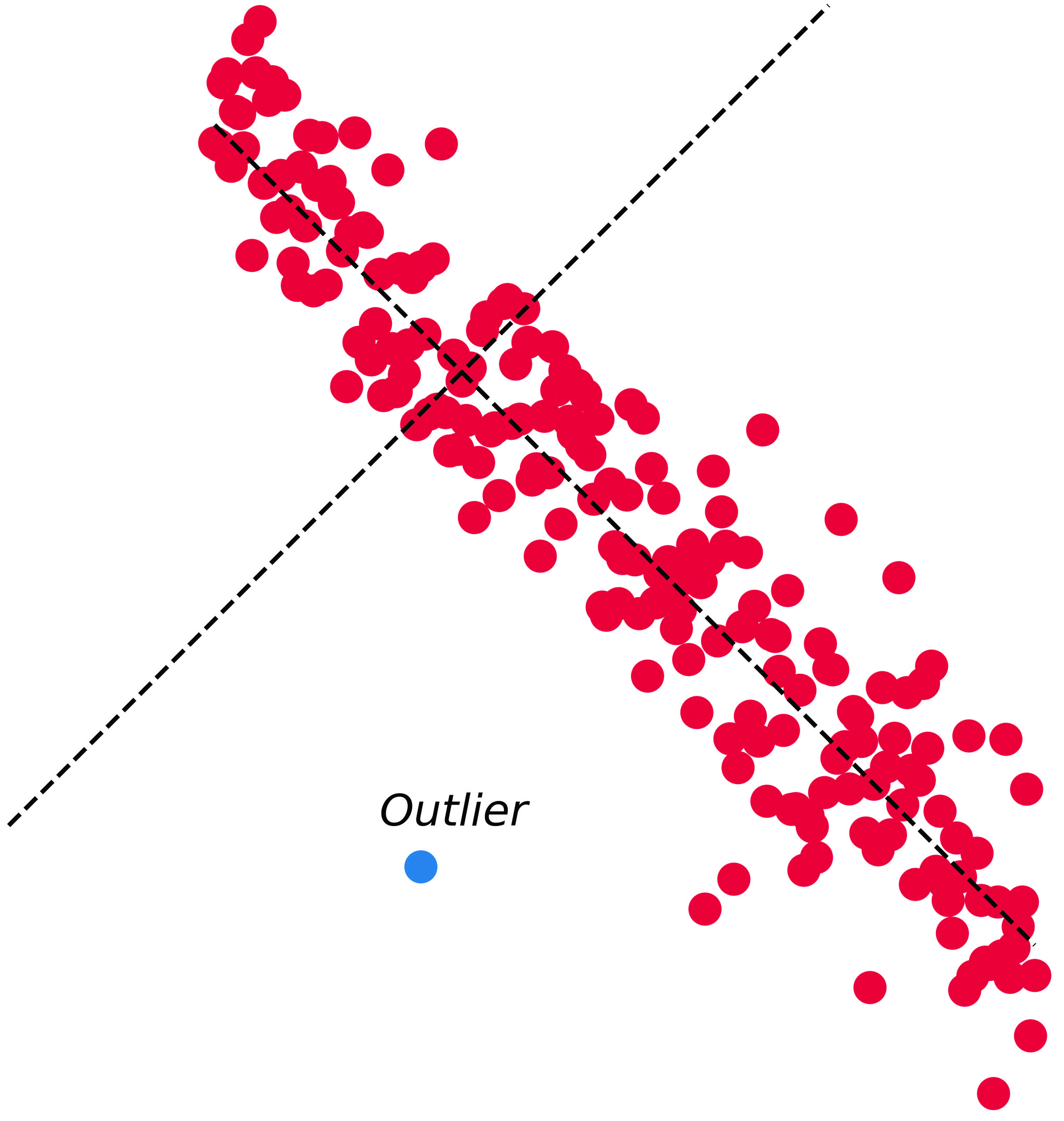
PCA is usually considered as an effective data reduction method for machine learning or data mining tasks, not an anomaly detection tool. However, owing to PCA algorithm have comprehensibility and does not impose too many restrictions on the data, more and more studies to identify the outlying instances based on PCA. In some cases, the abnormalities may immediately be revealed in the principal components’ space. For instance, Fig. 1 shows a scatter plot of several observations in 2-dimensional space. The point in the lower-left hand corner is an obvious outlier point, but not outlying in any of the univariate dimensions. Therefore, the outlier point will be easily identified if all observations can be projected onto the NE-SW diagonal. In practice, the direction of the NE-SW diagonal is the direction of the second principal component of the observations. Hence, mapping the data to the right principal component direction may make it easier to identify outliers. For the PCA-based anomaly detection method, modeling the outlier score function in the principal components’ space is a key issue. In [8] attempt to compute the outlier scores by the sum of weighted squares of the principal components of a random observation
We know that
In general, Euclidean distance is applied to
where
However, the mean is not robust, it is often attracted toward outlying objectives. Using the Eq. (2), the standardization outlier scores will be small. An example has been present in work [30], we refer to the example here to intuitively revealing the non-robust of the mean. Considering a simple univariate observation with five measurements {5.27, 5.34, 5.25, 5.31, 5.28}. Suppose that the last measurement has been contaminated, so the measurements become {5.27, 5.34, 5.25, 5.31, 52.8}. Thus, in that observation with contaminated one, the z-scores of them are {
Where MAD can be computed by the median of all absolute deviations from the median:
In the above formula, the constant 1.4826 denotes a correction factor that makes the MAD unbiased at the normal distribution [30]. Thus, in the above-mentioned contaminated measurements, the rescaled values by using Eq. (5) are {0.6745, 0.5059, 1.0117, 0, 800.79}. Clearly, the last rescaled value, which is contaminated, is greater than others.
Left: pairwise scatterplot of the first three components of outlier scores (above is SATIMAGE-2 data set, below is WINE data set). Non-outliers are blue real circles, outliers are yellow real circles. Right: pairwise scatterplot of the last components of outlier scores.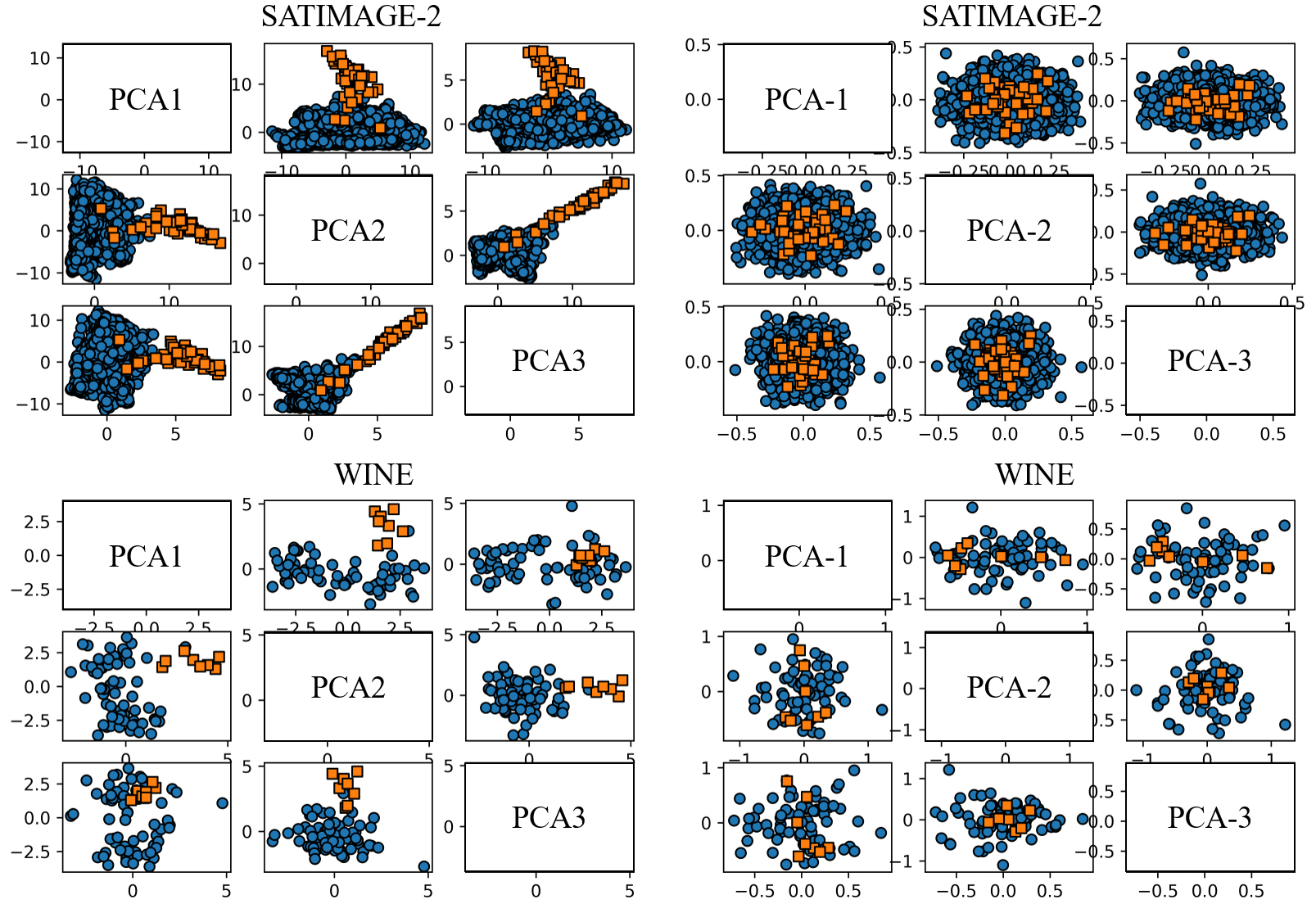
Algorithm 1 presents the pseudo-code of our method. Different from Eqs (2) and (3), we use standardized principal components to multiply by corresponding eigenvalues
An intuitive example is shown in Fig. 2. The observations are easier to discriminate between the normal and the abnormality on the first three components’ space of outlier scores. In contrast, projecting onto the last three ones, the observations are overlapping. This phenomenon exists in most data sets from the Outlier Detection Data Set (ODDS) [31]. Thus, we propose a new computational method of outlier scores, it follows that
where
It is generally known that the eigenvalues reflect the discrete degrees of the original data in relative principal direction. The magnitude of eigenvalues corresponding to the first principal components are greater than the others, that is
where
In a real application, it is generally to examine some principal component for outliers, therefore, the Eq. (9) can be rewritten as:
How to choose
Data sets and measurements
Here, we plan to evaluate the discrimination between our methods and five effective methods on several benchmark data sets. These data sets are included in ODDS, which have been made publicly available (these data sets can be downloaded at
The benchmark algorithms include Histogram-based Outlier Score (HBOS) [32], Local Outlier Factor (LOF),
ROC and P@N performance
In this sub section, we evaluate anomaly detectors on the nineteen benchmark data sets that are presented in Table 1. They include the continuous-valued data sets, such as ANNTHYROID, THYROID, MAMMOGRAPHY, VOWELS, WINE, GLASS, and WBC. Others are the discrete-valued data sets. The hardware specification of our experimental is represented in Table 2. It should be pointed out that the hardware environment solely affecting the execution time, but the performance of anomaly detection does not be affected. To better distinguish between the two classical PCA-based algorithms in subsequent experiments, we name the PCA-based anomaly detector relied on the Eq. (3) as PCA-1, and call the algorithm based on the Eq. (2) as PCA-2. In our methods, the evaluation model built by Eqs (7) and (9) is referred to as PCA-MAD and PCA-MAD++, respectively.
The properties of the data used in the experiments
The properties of the data used in the experiments
The AUCs of seven anomaly detectors on all data sets are presented in Table 3. As for the average performance, the PCA-MAD++ method has a subtle worse than
The hardware specification used in the experiments
Note that, the hardware has an influence of the execution time only, the results of ROC and P@N will not be affected.
ROC performance of seven different anormal detectors
Further, P@N is applied to evaluate the detection precision of the abnormalities. As shown in Table 4,
P@N performance of seven different anormal detectors
In sum, the results indicate our methods perform better than the two classical PCA-based methods and LOF. And having a similar performance relative to the state-of-the-art method, i.e.,
In this subsection, we focus on the execution time required of the different methods on each dataset by measuring the CPU time. Especially, we consider the computational expense of different algorithms at both the training and test phases. The results are summarized in Fig. 3. We observe that the execution time of HBOS, two classical PCA-based methods, and our algorithms are low on all of the data sets in both of the training and test phases. And the execution time of
Execution time of seven outlier detectors on both training data sets and test data sets.
Here, we want to evaluate the discrimination of the abnormalities of our algorithms versus
To compare three methods on the robustness when the noise features are increasing, we choose two data sets: CARDIO and SATIMAGE-2 on which the methods can obtain approximate AUCs. For each data set, 500 random features are simulated from
ROC performance of the proposed methods on training sets that contains both normal instances and anomalies
ROC performance of the proposed methods on training sets that contains both normal instances and anomalies
The ROC performance of our method versus 
P@N performance of the proposed methods on training sets that contains both normal instances and anomalies
Figure 4 gives the detailed results of the ROC performance from three anomaly detectors. The ROC performances will peak when the subspace size comes close to the original number of features. Thus, the feature selection is useful to anomaly detection with a high dimensional feature. For the detection performance, the results of our methods are promising. In our methods, the increase of dimensionality brings a litter degradation of performance than
In the real-world, the abnormalities are often rarely in some applications, that is to say, the detection algorithms are usually trained with normal instances only. Thus, we further verify our method work well when the training set contains normal instances only. To achieve the goal, we cut off the anomalies from the training sets are shown in Table 1, and then evaluate the anomaly detectors with both abnormal and normal instances. The average AUCs and P@Ns are presented in Tables 5 and 6. We can see that our methods trained with instances only, can get better detection performance than trained with both normal instances and anomalies.
Other anomaly detection methods also perform better when the anomalies removed from the training data set. That might seem obvious as the anomaly detectors will build a correct outlier score model from training data without abnormalities. For instance, the PCA-based methods are very sensitive to anomalies because the standard PCA is unable to extract the correct principal axis from the data set with abnormalities.
In sum, the results in the above experiment indicate that our methods can get better performance for anomaly detection when the correct principal directions are extracted. One of the solutions that can extract correct principal directions, is to develop the robust PCA, which is meaningful research but not within the scope of this paper.
Conclusion
In this paper, we propose a novel unsupervised anomaly detection approach, which computes outlier scores based on PCA. The classical PCA-based methods failed to get high accuracy on identifying abnormalities as they cannot take the location and scale of each score into account. In comparison to traditional methods, we introduce the median and MAD to robustly rescale outlier scores projected onto each principal direction. Thus, the true outlier score can be computed. Also, a new method to assign the weight of the univariate scores is presented in this work. The empirical comparison with five classical anomaly detection techniques on the benchmark data sets indicates that our approaches are superior in terms of runtime (especially in large datasets) and detection effectiveness. For the training dataset with normal instances only, the proposed approach also performs well. Besides, our approach will also work well than
Footnotes
Acknowledgments
The authors thank the associate editor and two anonymous referees for their valuable suggestions. They are also very grateful to Xiaoguang Wei for the comments on a preliminary version of this paper. This research is partially supported by the Fundamental Research Funds for the Central Universities under Grants No. 2682017CX046 and No. A0920502052820-21. The Equipment Development Department Funds grant 61403120304, and the Science and Technology Major Project of the science and Technology Department of Sichuan Province (2018GZDZX0043).