
Abstract
Due to the rapid increase in the amount of data generated in many fields of science and engineering, information retrieval methods tailored to large-scale datasets have become increasingly important in the last years. Semantic hashing is an emerging technique for this purpose that works on the idea of representing complex data objects, like images and text, using similarity-preserving binary codes that are then used for indexing and search.
In this paper, we investigate a hashing algorithm that uses a deep variational auto-encoder to learn and predict the codes. Unlike previous approaches of this type, that learn a continuous (Gaussian) representation and then project the embedding to obtain hash codes, our method employs Bernoulli latent variables in both the training and the prediction stage. Constraining the model to use a binary encoding allow us to obtain a more interpretable representation for hashing: each factor in the generative model represents a bit that should help to reconstruct and thus identify the input pattern. Interestingly, we found that the binary constraint does not lead to a loss but an increase of search accuracy. We argue that continuous formulations learn a representation that can significantly differ from the code used for search. Minding this gap in the design of the auto-encoder can translate into more accurate retrieval results. Extensive experiments on seven datasets involving image data and text data illustrate these findings and demonstrate the advantages of our approach.
Keywords
Introduction
Many applications in computer science are based on similarity search, i.e., finding elements in a database that are similar to a given sample object [1]. The greater availability of complex data types such as image, audio, and text, has increased the interest for this type of search in the last years and raised the need for methods that can reduce the processing time and storage cost of traditional paradigms. Tree-based indexing methods such as KD-trees, Ball-trees and R-trees have been shown to degrade quickly as the dimensionality of the data (descriptors) increases [46], and thus novel approaches, often tailored to large-scale image retrieval, have started to be investigated. Among these techniques, hashing algorithms have received significant attention.
The purpose of hashing techniques is to represent the data using compact binary codes that preserve their semantic content and can be used as cells into a hash table. Items similar to a query can then be found by accessing all the cells of the table that differ a few bits from the query. As binary codes are storage-efficient, hashing can be performed efficiently in main memory even for very large datasets [34].
Hashing algorithms can be broadly categorized into data-independent and data-dependent methods. Data-independent methods exploit properties of some probability distributions to ensure that the similarity function of the original space is approximately preserved by the embedding into the code space [22]. These methods usually require codes much longer than those obtained with data-dependent techniques, that leverage data and machine learning techniques to explicitly optimize the embedding, at the cost of some training time [38, 50]. Supervised, unsupervised and semi-supervised approaches have been studied. Supervised methods rely on explicit annotations, such as topic or similarity labels, to learn the hash codes. For instance, [24] implements a hash function by training a deep neural net on pairs of images previously labelled as similar or dissimilar examples. Unfortunately, the performance of these methods degrades quickly when there is not enough labelled data for training or it is noisy. Unsupervised methods deal with this issue, providing learning mechanisms that do not require explicit supervisory signals [38] and can thus leverage unlabelled data, which is usually abundant and cheap [45]. Often, these methods can be transformed into semi-supervised models that can also exploit labels if available.
Recently, significant progress has been made in the field of deep generative models. The so-called variational autoencoder (VAE) framework [19], provides algorithms for probabilistic inference and learning that scale to very large datasets and provide state-of-the-art performance in many tasks. A natural question is whether these advances can be exploited to devise novel hashing algorithms. It has been shown indeed that VAEs can be successfully trained to learn hash codes [5], improving on previous techniques when labelled data is scarce. A disadvantage of this approach is that, as conventional VAEs use a Gaussian encoder, the continuous representation learnt by the model needs to be quantized to obtain binary codes. This step introduces an error that is not account for in the learning process and can seriously degrade information retrieval performance. Also, it is difficult to interpret this model as a hash function, because there is nothing that rewards learning binary codes in the training phase.
In this paper, we propose to learn a deep hashing model using a VAE with Bernoulli latent variables that maps an object or input pattern directly to a binary code representation of the different bits. The main technical difficulty of this approach, i.e. back-propagation through discrete nodes, can be circumvent by specializing the method proposed in [17] to handle Bernoulli distributions [30]. Experiments on text and image retrieval tasks demonstrate that this approach works well for unsupervised hashing, leading to more effective and interpretable binary codes than those produced by a continuous VAE and state of the art methods.
This work is an extension of the research presented in [32]. The main differences are:
Related work has been extended. The experiments are expanded by adding 3 image domain datasets and 1 text domain dataset, using Deep Learning models. The discussion and analysis regarding the quantization factor of the learned representation is extended.
The rest of this paper is organized as follows. In the next section, we outline the idea of hashing for similarity search. Related work is discussed in Section 3. In Section 4, we present the proposed formulation. In Section 5, we report experimental results, comparing the codes of our method with those of a continuous VAE. Finally, Section 6 summarizes the conclusions and final remarks of this work.
Similarity search
Consider a dataset
Hashing
Hashing algorithms address similarity-search problems by devising an embedding
Quantization error
Many hashing approaches obtain
Focus
We focus on learning a hash function
Standard loss functions on discrete data
Many machine learning approaches used information functions as loss function or quality measurements. For example, consider a categorical random variable
The cross entropy of another probability distribution
The Kullback-Leibler divergence (or KL divergence) from
The mathematical relation between these concepts (entropy, cross entropy and KL divergence) is given by:
The problem of representing data using binary codes that preserve semantic content and support efficient indexing has been extensively studied in the last years. Below we present a brief description of the main ideas developed in the literature, stressing the relationships and differences between our approach and previous research.
Randomized methods
Early hashing algorithms were randomized methods devised to preserve specific similarity functions or distance metrics [3, 15]. For instance, SimHash [6], based on random projections, was devised to approximately preserve cosine similarity, a function widely used to compare documents in the vector space model (VSM). MinHash [40, 3] preserves the “resemblance” or Jaccard similarity of two documents by using random permutations of sets (bags of words). E2LSH [7] was created to approximately preserve the Euclidean distance used e.g. in image search applications.
All these and more data-independent approaches to hashing can be described as particular cases of the so-called Locality Sensitive Hashing (LSH, [7]) framework. Unfortunately, despite the strong theoretical guarantees that the framework provides in the limit of many bits [10], the performance of these techniques is often unsatisfactory in applications that require compact hash keys (low memory footprint) or in scenarios where search needs cannot be easily encoded into a similarity function. Learning based methods, such as that proposed in this paper, attempt to overcome these limitations using machine learning formulations to optimize the hash codes.
Shallow learning based approaches
As real data often lie in a low-dimensional sub-space (or manifold) of the feature space [18], data-dependent methods can dramatically reduce the number of bits required to preserve similarity by learning and projecting the data into a set of directions that summarize the data distribution. If available, learning based methods can also exploit annotations to surrogate the knowledge of a specific similarity function.
AnnoSearch [49], one of the first data-dependent approaches to hashing, computes the bits by projecting the data into the top PCA directions, i.e. the best fitting sub-space in terms of variance preservation. SSH [44] relaxes the orthogonality constraints of this method to obtain more balanced projections (and so bits) in terms of explained variance. KLSH [22] uses kernel methods to implicitly perform PCA in a high-dimensional feature space where linear relationships can be more easily found. ITQ [11] improves PCA based hashing by learning a rotation matrix that minimizes the quantization error introduced by a continuous formulation of hashing.
In a different and influential vein, Spectral Hashing (SpH) [50] poses hashing as the problem of partitioning a similarity graph, where the vertices represent training points and the edges are weighted using similarity scores that are computed using a kernel. Each bit of the codeword identifies a (different) partition of the graph that should have as low cut as possible to optimize the intra-cluster (within) similarity of the groups. As pointed out in [28], the extension of SpH to unseen data is based on strong assumptions about the data distribution that ignores the information provided by the training data. Anchor Graph Hashing (AGH) attempts to overcome this limitation using the Nystrom method on a sub-graph of the original similarity graph that approximates its geometric structure. As both SpH and AGH determine the hash bits by thresholding eigenfunctions of a similarity graph Laplacian, these approaches relate hashing to manifold learning techniques for dimensionality reduction that have emerged in the last years [48, 18]. Unfortunately these techniques are often very sensitive to the choice of the metric used to build the neighbourhood graph.
In contrast to spectral and PCA-based methods, our method is an unsupervised approach [12] that learns the data distribution without the assumption of a specific similarity function or kernel. Supervised hashing algorithms such as LDA-Hash [43], CCA-ITQ [11], BRE [21] and SSH [45] succeed in this goal, but assumes that some type of metadata which conveys information about the data similarity structure is available. For instance, CCA-ITQ extends ITQ using pointwise annotations, e.g. topic or category labels. LDA-Hash [43] improves the projection directions of PCA-based hashing assuming that pairwise annotations (similar/dissimilar pairs) are available. In the same vein, KLSH [27] and MLH [33] learn more discriminative directions by explicitly penalizing the distances between similar points. Even more complex supervision schemes, such as triplets of examples has been explored [47, 54], and hence, there is plenty of methods we can use assuming supervision. Unfortunately, annotation procedures are often expensive and slow to be adopted in many applied domains. On the other hand, with budgeted data, these methods are prone to over-fitting, leading to unsatisfactory search performance.
Deep learning methods
Deep learning methods typically improve hashing by learning a representation of the input data that works well for the task [12], that is, they equip the model with a learnable transformation
Departing from previous image retrieval applications based on hand-crafted descriptors such as GIST or SIFT, Deep Supervised Hashing (DSH) [26] uses a convolutional neural net (CNN, see [36] for a review) to extract those features directly from images. The difficulty of learning visual features and hash codes simultaneously is circumvented using a two-stage approach originally proposed in [23]. The first stage learns hash codes for the training examples using a formulation closely related to KLSH [27]. The second stage trains a supervised model to reproduce the codes learned in the first stage. By decomposing the task in this way, specialized solvers are required only for the first stage and the neural net can be trained using standard back-propagation. The same strategy is employed in [51], where one-dimensional CNNs are trained for text hashing. In this case however, the hash codes of the first stage are obtained using a supervised variant of Spectral Hashing (SpH) [50] and pre-trained word embeddings (GloVe) are used to feed the text into the net.
Our review of recent research confirms this tendency to construct deep hash functions using pre-trained models also in image retrieval. For instance, the method in [52] uses the first
Autoencoders
As autoencoders play a fundamental role in unsupervised learning [2], our method is naturally related to hashing techniques that exploit this machinery to circumvent the need of explicit annotations. As in other deep learning approaches, these methods learn an encoding function
In [4], a linear autoencoder is used to learn hash codes. The model, termed Binary Autoencoder (BA), is trained to minimize the reconstruction error
Tailored to large-scale image retrieval, the method in [9] replaces the feed-forward layers used in previous research by convolutional layers, which can learn more easily the local patterns that often arise in image data. In contrast to the work of [4], this method introduces the binary constraints as penalties into the objective function, which allows the model to be trained with gradient descent. The method uses also regularization terms present in various previous formulations (e.g. [11]) that maximize the variance of the learned representation and enforce the bits to be pairwise uncorrelated.
Deep graphical models
In practice, the variational autoencoder (VAE) we propose in this paper has an architecture similar to the traditional autoencoders described in Section 3.4. However, as we cast the problem of learning the representation
Up to our knowledge, the use of a graphical model to learn hash codes without supervision was first proposed in [38] with the so-called Semantic Hashing (SH) approach. The model was composed of multiple layers of latent variables. The top two layers formed a Restricted Boltzmann Machine (RBM) and the remaining layers defined a Deep Belief Net (DBN) with directed top-down connections. At the training stage, the activation of the binary nodes in the deepest layer allowed to identify topics from which the visible nodes had to reconstruct the input data, just as an autoencoder does. Indeed, SH can be seen today as a stochastic autoencoder where encoder and decoder share architecture and weights. Unfortunately, training this model is often computationally hard because it is based on layer-wise pre-training and specialized optimization routines. Perhaps for this reason, most subsequent research on unsupervised hashing preferred shallow architectures or replaced the graphical model by a traditional autoencoder (Section 3.4).
There are some exceptions to the latter. In [55], a graphical model for multi-modal hashing is presented. The method adopts a maximum a-posteriori (MAP) formulation that requires intra-modality and inter-modality labels. In addition, the method learns codes for the training set only, and complex out-of-sample extensions are required to hash novel data. In similar fashion, the method in [53] adopts MAP inference for learning and a linear extension for out-of-sample predictions. More recently, a complete probabilistic treatment of hashing, that avoids MAP inference, has been presented in [14]. Unfortunately, this algorithm requires pairwise annotations, relies on a continuous relaxation of the code distributions, and requires an out-of-sample extension to hash novel data. Finally, in the vein of [55] and [53], this method does not exploit deep learning to build the hash function.
Variational autoencoders
In the last years, significant progress has been made in the field of deep generative models. In particular, it has been shown that Variational Autoencoder (VAE) models [19] lead to efficient algorithms for topic modeling and text hashing [5, 41]. The method in [5] obtains hash codes by first training a standard VAE, i.e., a stochastic autoencoder with a Normal latent distribution, and then thresholding the learned representation around the median (zero). Setting the threshold at the median encodes the prior belief that, in a balanced hash table, half of the bits should be active and half inactive. This method, named Variational Deep Semantic Hashing (VDSH), improves the results of previous unsupervised techniques on text hashing, besides being more scalable and stable than the prior work of [38].
A discrete (categorical) VAE (Ca-VAE) for discovering topics in text documents is presented in [41]. The latent variables are modeled with a Multinomial distribution such that only one topic can be present at the same time on a document. Though useful in the context of text clustering, the latter constraint makes the technique difficult to adapt for hashing.
Proposed method
Motivated by the effectiveness of variational autoencoders [19] to learn latent representations, we pose hashing as an inference problem where the objective is to learn a posterior distribution
In the literature, the distribution
Resorting to a more standard formulation of the VAE, [5] chooses
1-bit quantization of a Gaussian variable (standard VAE) and two Gumbel-Softmax variables (B-VAE) at different temperatures. In practice, all the points below/greater than 0 are rounded to 
An illustration of the latter issue is provided in Fig. 1 for a single bit. Here we can see that, even if the distribution is optimally centered, samples from a Gaussian can significantly differ from their projections on the two bit states 0 and
As in the traditional VAE, where the parameters of the Gaussian posterior
Due the current benefits and flexibility of deep learning models, the choice of learning the model parameters by neural nets, allow us to adapt the architecture of
Learning approach
The composition of the encoder
where the first term of
As shown in [30], with the introduction of the CONCRETE distribution, and in [17], with the introduction of the Gumbel-Softmax distribution, samples of a discrete random variable can be well approximated by sampling a carefully designed continuous distribution. This idea can be adapted to the special case of Bernoulli random variables, as proposed in [30]. Indeed if
converges to
To complete the application of the VAE framework [19], we need to introduce a prior distribution
With the proposed prior, the KL divergence in Eq. (4), can be calculated analytically for any data point
where the second term represents the regularization factor, expressed as the negative of the binary entropy (
With the derivations commented earlier, the lower bound in Eq. (4) can be specialized for the data domain that we are facing. For instance, in the text domain,
where the decoder is
For the image domain, we can use dense descriptors for the representation of images
where
Note also that in both Eqs (7) and (8), there is a constant
Illustration of the forward (left) and backward (right) pass implementing the proposed method as a deep neural net. The dashed line represents a stochastic layer. Only the forward pass requires passing through stochastic layers.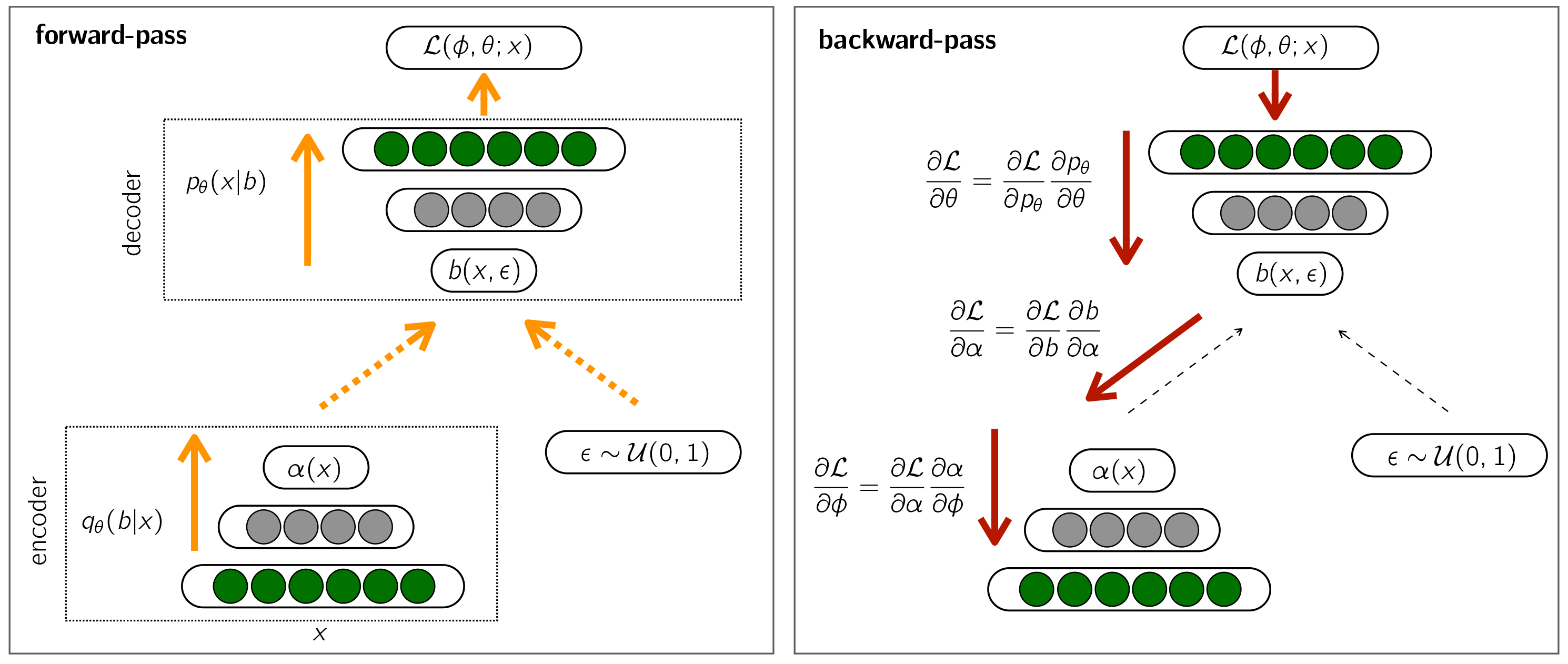
We illustrate in Fig. 2 the neural net architecture that implements our method. As other VAEs [19], it can be easily trained with vanilla back-propagation. In the
Compute Simulate uniform noise Pass the result to
During the
Compute the gradient of Eq. (4) with respect to the net’s output. Back-propagate the error signal through the decoder parameters Back-propagate the error signal through the encoder parameters
As our model is stochastic, a straightforward use of the encoder
To provide additional intuition about the robustness of a Bernoulli latent representation to the quantization step, we compare in Fig. 3 the distances between the representations before thresholding (using the Euclidean distance) and after thresholding (using the Hamming distance), computed on samples drawn different distributions. We can observe that Gumbel-Softmax samples at low temperature lead to similarities well correlated before and after thresholding. That means that the distance scores are preserved on the representation space after quantization. Indeed, this contrasts with samples drawn from the Gaussian distribution employed by the Gaussian variational encoder. This suggests that a Bernoulli VAE is well suited for hashing, even substituting sampling by a thresholding operation to obtain deterministic codes.
Experiments
We evaluate our method on text and image retrieval tasks, previously used to assess hashing algorithms [5, 24]. First we adopt the Gaussian variational autoencoder recently proposed in [5] as our main baseline (VDSH). We then extend the comparison to non-variational methods.
Information of the data used for the evaluation of objects retrieval
Information of the data used for the evaluation of objects retrieval
Euclidean distance before quantization (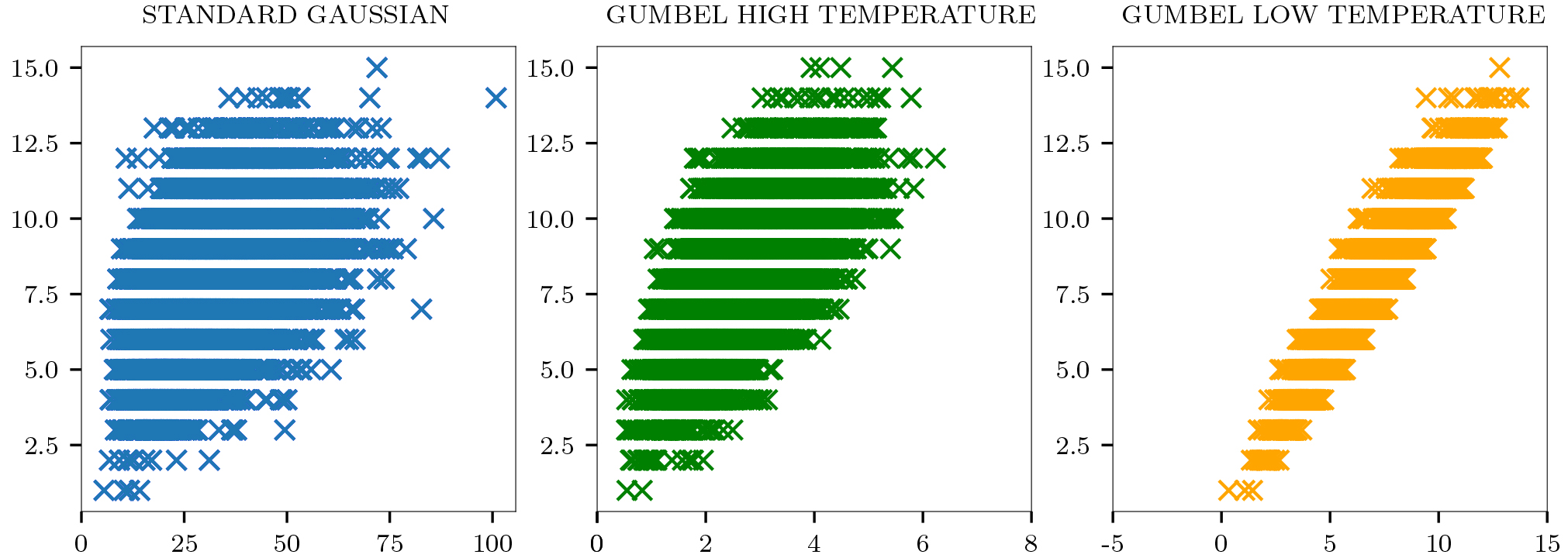
We define four well-known text datasets: 20 Newsgroups, containing 18000 long documents (newsgroup posts) organized into 20 mutually exclusive classes; Reuters21578, containing 11000 news documents annotated with 90 non-exclusive tags (topics); TMC, containing 28000 documents (air traffic reports) organized into 22 non-exclusive tags; and Google Search Snippets, with 12000 short documents organized into 8 mutually exclusive classes (domains). These datasets were selected to experiment with documents of different length. The first three datasets have used in [5] to demonstrate the ability of standard VAEs to learn hash codes. The latter has been used in [51] with convolutional neural nets with the same purpose.
The value of weight
We selected three widely-use image datasets: MNIST,2
The value
The trained encoders are used to embed the corpus into the Hamming space. Based on this embedding, each test or validation document was then provided to the system as a query and used to retrieve similar documents from the training set. We consider two querying methods: (1) top-
with
Meanwhile, for the image datasets we also calculated the mean average precision (MAP) [37] of the Hamming ranking as several recent works do [24, 8, 39]. This metric represents an overall measurement of the retrieval performance. Let
Convolutional features for image representation
Precision and recall on the validation set using the first querying mechanism (top-100) on the MNIST dataset. The best result are bolded
Precision and recall on the validation set using the first querying mechanism (top-100) on the
On Table 2, we can see the effect of using the VGG descriptors instead of the raw pixels in the MNIST dataset. The difficulty of using the raw pixels comes from the many parameters that encoder and decoder had to learn if trained from scratch. Here, it can be seen that the VGG representation outperforms the raw representation for all the bits and all the methods. As for the recall, the VGG representation is uniformly better, except for 32 bits where the raw representation performs equal. This experiment illustrate the effectiveness of convolutional layers to extract visual features and the advantage of using pre-trained models to reduce the number of trainable parameters.
In this section we compare the performance of Gaussian (VDSH, [5]) versus Bernoulli (proposed) variational autoencoders for hashing. As stated before, we present results in text and image datasets using the two querying mechanisms usually adopted in the literature.
Results for top
Searches on image and text data
Precision and recall on the test set using the first querying mechanism (top-100) by different number of bits. The best method on each bit configuration is bolded
Precision and recall on the test set using the first querying mechanism (top-100) by different number of bits. The best method on each bit configuration is bolded
In Table 3, we compare the results obtained by the Gaussian [5] and Bernoulli autoencoders using the first querying mechanism, for different number of bits
In summary, our variational autoencoder outperforms the more traditional Gaussian autoencoder in terms of precision and recall in most cases. We achieved some large gaps of improvement on some cases. For instance, using 16 bits, the precision of the proposed method is
MAP on the test set using all the hamming ranking by different number of bits. Best method on each bit configuration is on bold
In Table 4, we compare the test performance of the methods in terms of mean average precision (MAP) overall hamming ranking. The obtained results are similar to those remarked previously in terms of ranked precision, i.e. our method outperforms the MAP of the baseline in most cases (bits) on the different datasets. In some datasets (Newsgroup, MNIST and CIFAR-10), our method is the best independently of number of bits (4 cases), while in other cases it is better in most of them (3 against 1 in TMC, Snippets and NUS-WIDE). In the Reuters dataset, the results are more evenly split between the algorithms: our method outperforms the baseline in only two cases. Overall, these results show that the proposed method maintains its advantages when the ranking on the whole dataset is considered. Sometimes we observe large gaps of improvement. For instance, the MAP of our method is
Precision (circles) and recall (triangles) using the second querying mechanism (ball search), 32 bits are used. Points are obtained using different values of 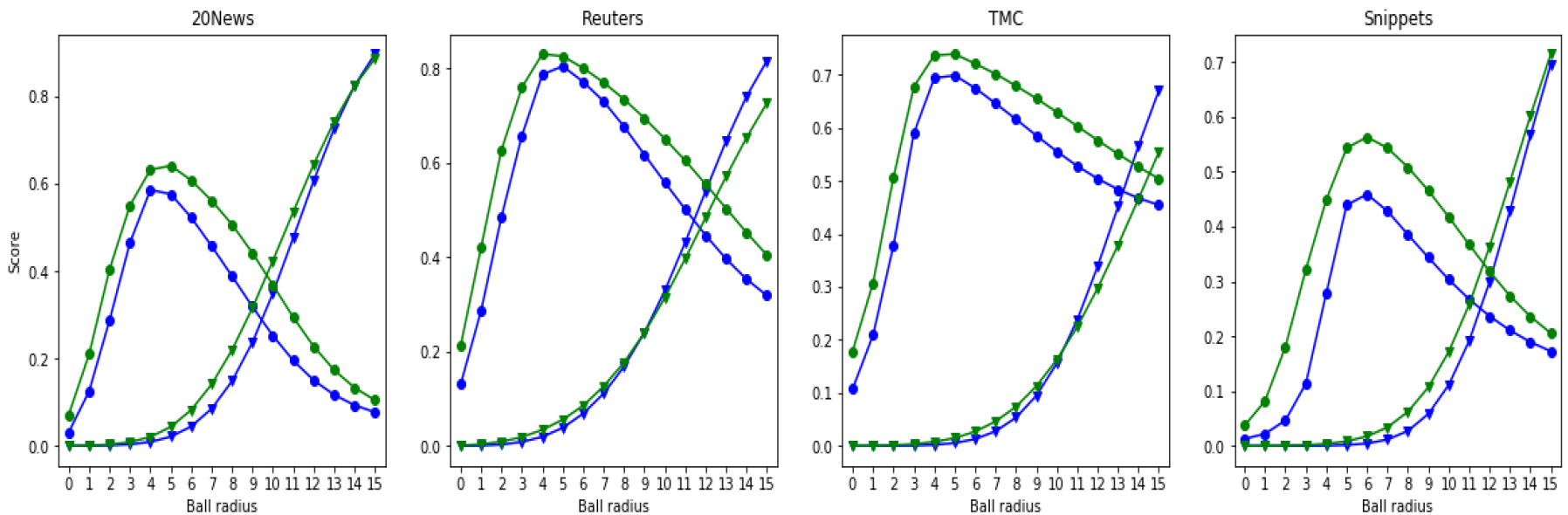
In Fig. 4, we show the performance obtained by both types of autoencoder on the text datasets using the second querying mechanism, ball search. We fix the number of bits of the codes to 32 and vary, as usual, the value of search parameter (radius)
Figure 4 also illustrates the advantage of using the second querying mechanism instead of the first one. For example, using
Precision (circles) and recall (triangles) using the second querying mechanism (ball search), 32 bits are used. Points are obtained using different values of 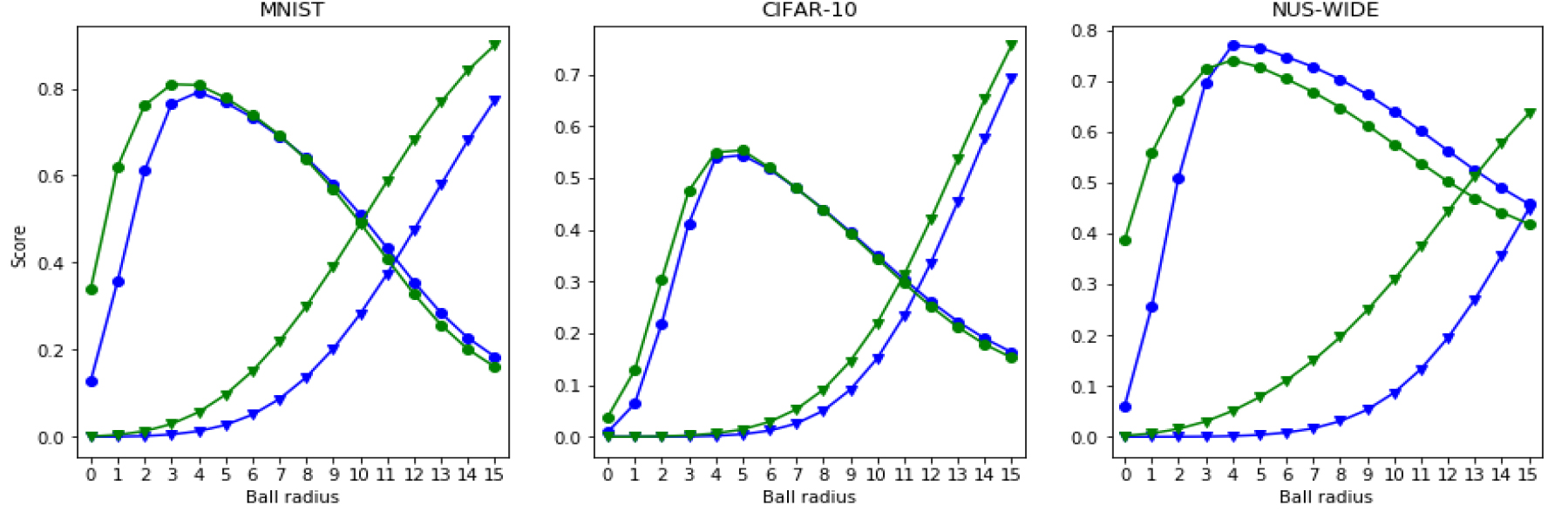
In Fig. 5, we show the results obtained in the image datasets. Conclusions are similar to those drawn from the previous experiments. The proposed method obtains a better precision and recall in most cases, being the recall the metric that gets a more clear improvement. Also, based on same criteria commented earlier, it can be seen that in MNIST and NUS-WIDE, similar objects are very close in Hamming space. In CIFAR-10 one has to explore more the Hamming space to find similar objects.
Text retrieval tasks
We use the same experimental setting of [5], same datasets and evaluation protocol, in order to compare the variational methods against other unsupervised techniques for text hashing: LSH [7] (data-independent method) SH [50] (popular shallow baseline) and Stacked RMBs [38] (deep graphical model).
Precision on the test set using the first querying mechanism (top-
). Values are extracted from [5]. The VDSH
stands for our own implementation of the VDSH model. Best result on each dataset and bit is presented in bold
Precision on the test set using the first querying mechanism (top-
The results are presented in Table 5. First, it is worth noting that our own implementation of the Gaussian variational autoencoder (VDSH) obtains slightly better results in most cases. This could be due to the parameter used to weight the KL divergence in the objective function used for training that is selected using a validation set.
The results in Table 5 show that the variational (stochastic) models are better for hashing and information retrieval than the classic shallow models and the deep generative baseline. In most cases, the Bernoulli autoencoder outperforms all the unsupervised methods. In the Newsgroups dataset, this advantage is independent of the number of bits, while on Reuters and TMC our method outperforms all the baselines using 16 and 32 bits. With 8 bits, the proposed method is the second best performer after the VDSH method. Overall, these results show that a variational autoencoder with Bernoulli latent variables is an effective technique for text hashing, often providing state of the art performance.
We use the same setting of [39], same datasets and evaluation protocol, in order to compare against more unsupervised hashing techniques specialized on image retrieval. Here we compare the Bernoulli autoencoder against: LSH [7], SH [50], ITQ [11], and UH-BDNN [8], a state-of-the-art deterministic autoencoder model. All the methods use
MAP on hamming ranking and Precision at 5000 on test set retrieval. Values are extracted from [39]. The VDSH
stands for our implementation of the VDSH model. Best results on each bit and dataset are presented in bold. All methods use VGG descriptors
MAP on hamming ranking and Precision at 5000 on test set retrieval. Values are extracted from [39]. The VDSH
The results on the image datasets, comparing MAP and Precision at top-5000, are presented in Table 6. Here it can be seen that the variational Gaussian autoencoder (VDSH) outperforms classic shallow models only on MNIST, being competitive against ITQ model in CIFAR-10 and NUS-WIDE. However, the proposed model is better than all the shallow models, in all the datasets and considering both retrieval metrics (MAP and ranked precision). Furthermore, the Bernoulli autoencoder is the best among all the methods (shallow and deep) in the MNIST dataset (MAP and ranked precision) and partially in NUS-WIDE (only MAP). The deep deterministic autoencoder (UH-BDNN) is competitive with the variational autoencoders on all the datasets: it exhibits the best MAP and ranked precision in CIFAR-10 and the best precision in NUS-WIDE, where our method is the second best option.
In summary, our B-VAE method shows the best MAP on 2 of 3 datasets and deep deterministic autoencoder presents the best precision on 2 of 3 datasets. Obtaining a good MAP is something commonly desired in image retrieval applications [8, 39, 9], because it considers the order of the search results. The better MAP scores of the Bernoulli autoencoder indicates that it puts more relevant documents on the top of the list.
As earlier experiments shows, our proposal is often the best among the variational models. However, the results in Table 6 shows that there is no a uniform winner in image hashing. It depends on the dataset type and the metric used to assess the models (e.g. MAP or ranked precision).
Examples of most probable words by activating a bit on the hash code
Examples of most probable words by activating a bit on the hash code
As the proposed method uses binary latent variables, each factor of the latent representation learned by this model can be understood as a bit of the address assigned to data point in the Hamming space. To show that this interpretation offers practical advantages, we conduct experiments aimed to analyze the properties of the codes learned by the model.
As a first experiment, we use the decoder (generator) learned on the text datasets, to determine if the bits can be assigned a semantics as in topic models used for text mining. As the reconstruction layer computes a probability distribution over the words/tokens, we can activate a single bit of the hash code and compute the top most probable words generated by the decoder. Table 7 shows a selection of the results of this experiment. We can see that in Newsgroups, bit number 9 seems to detect political discussions regarding sexuality. In Reuters, bit number 31 captures computer-related concepts. In Snippets, bit number 25 seems to detect terms associated with health or sport.
As a second experiment we use the encoder of the variational autoencoders to inspect the properties of the representation learned by these modes. Figure 6 shows histograms of the representations generated by both methods in the text datasets. For the Gaussian autoencoder we show the expectation
Histograms of the representations learned by B-VAE and VDSH (activation probabilities and mean values respectively) in the 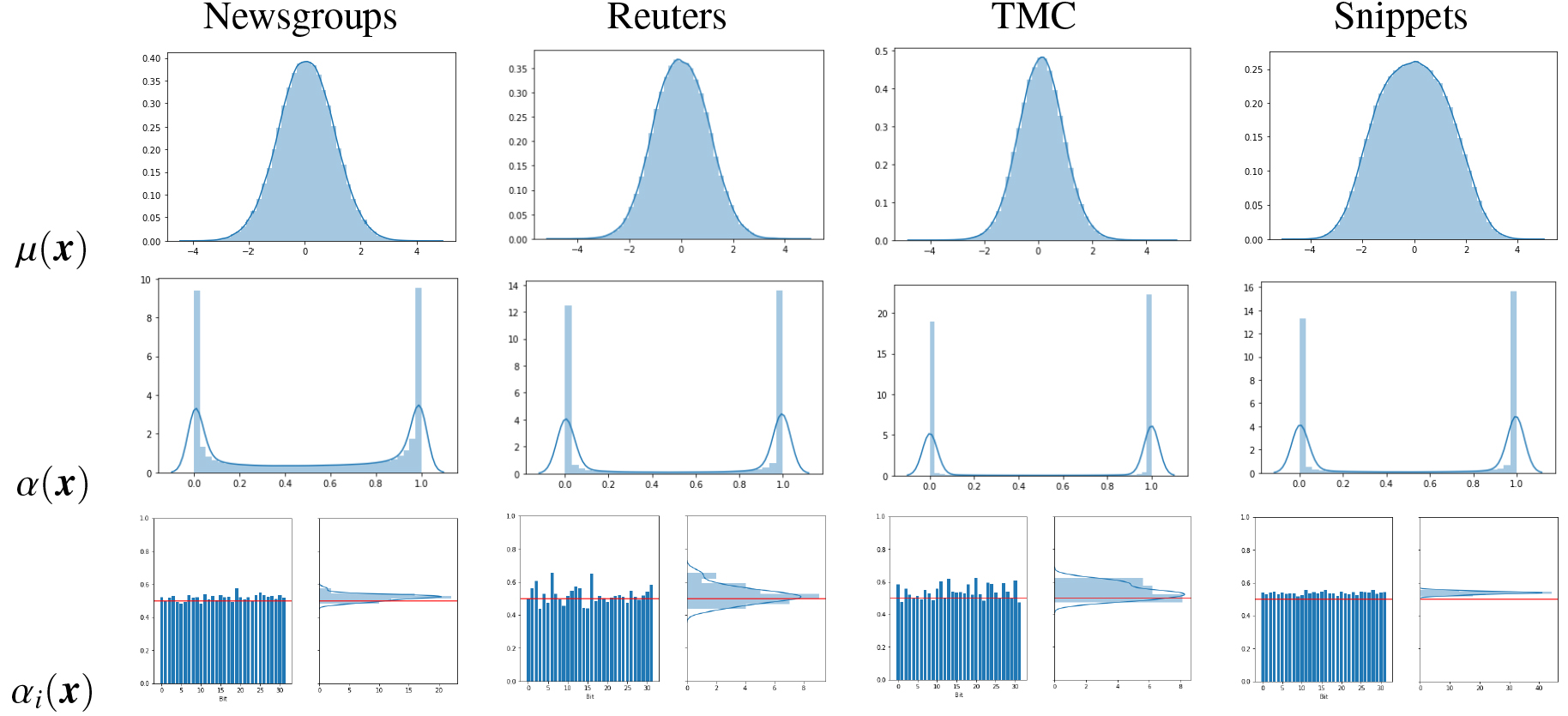
It can be seen that the activation probabilities of the bits learned for every object
By inspecting the marginal activation probabilities in text datasets (Fig. 6), it can be seen another good property of the proposed model: the average activation probability is close to 0.5. As the activations are saturated at the extremes, that implies that every bit is 1 for about half of the dataset and 0 for the other half and so practically every bit is used to discriminate/separate. On the image datasets (Fig. 7) we observe a different result. For example, in the MNIST and NUS-WIDE datasets, some bit averages are very close to 1 and other very close to 0. That means that in these cases, some bits practically do not change their values. This perhaps explains why in these datasets, the proposed method is not always the top performer, and suggests that there is room for improvement in the design of the objective function.
Histograms of the representations learned by B-VAE and VDSH (activation probabilities and mean values respectively) in the 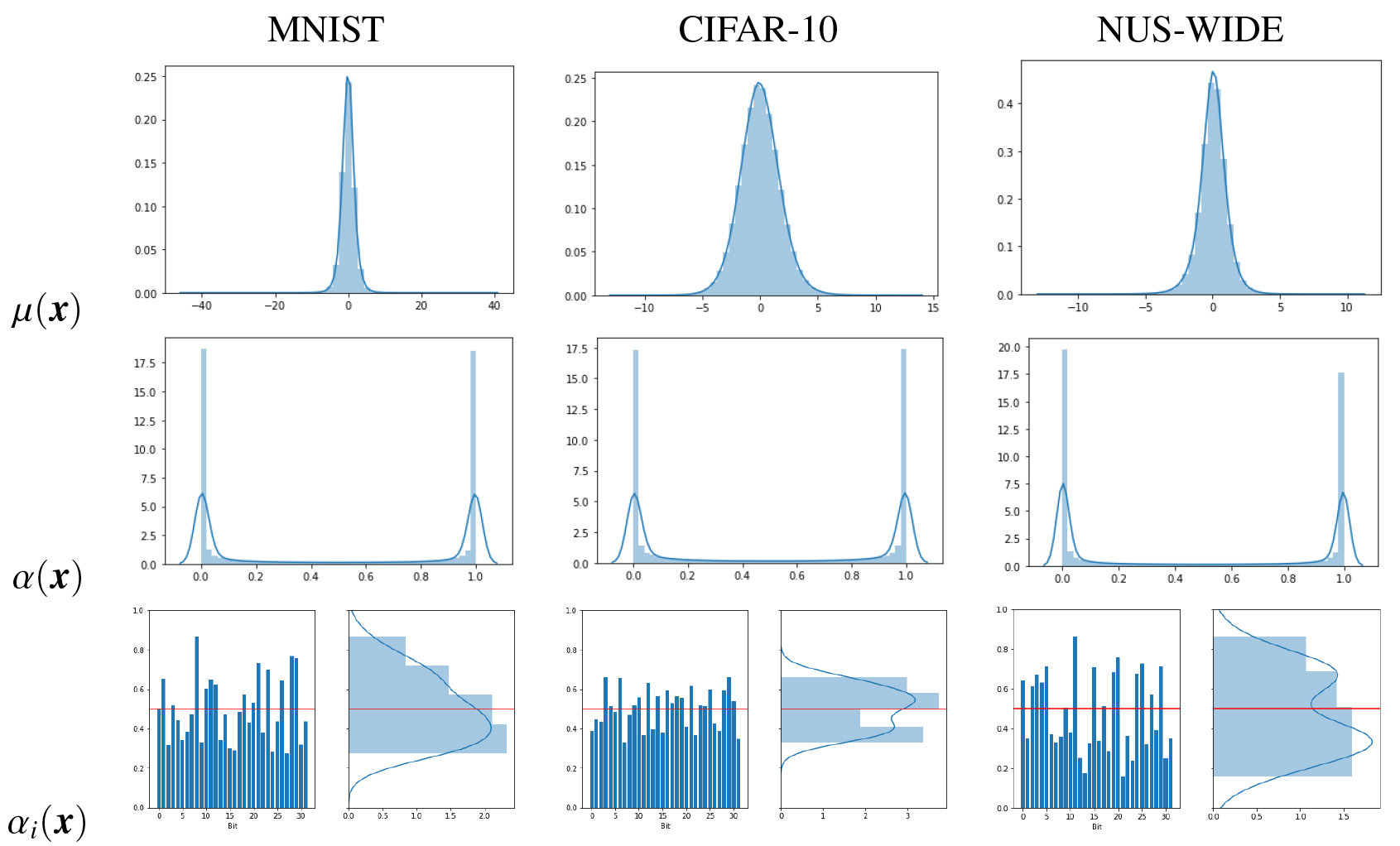
To analyze the effect of quantization on the representations learned by the traditional and the proposed autoencoder, we conduct extrinsic evaluation experiments which use classification as the desired (in this case auxiliary) task. To this end, we use a shallow fully connected network with one hidden layer of 256 ReLU units and a Softmax output layer that predicts the classes or tags corresponding to the input pattern.
Our first goal is to determine if a continuous (Gaussian) representation has advantages before thresholding (binarization). Hence, we first use the encoders of the Gaussian and the Bernoulli models to represent the data, train the neural net on these representation, and evaluate the accuracy and Jaccard score of the classifier on the training and test sets. The first column of Table 8 presents the results for a code length of 32 bits. We can see that the baseline (VDSH) obtains always the best performance, except in the test set of Snippets. This advantage is completely expected because the Gaussian model is trained to preserve information about the data in the form of a continuous embedding while the Bernoulli model constraints the latent variables to have only two states.
Performance of labels prediction on training and test set, using the representation with 32 bits obtained before and after thresholding. Accuracy and Jaccard score for unique and multi label datasets. Best results on each set are presented in bold
We now binarize the data representation of both methods using the thresholding operation required to obtain hash codes, and repeat the procedure of training and evaluating the neural net. The second column of Table 8 summarizes the results. We can see that the superiority of the continuous Gaussian representation is lost after thresholding. The representation learned by our model outperforms the baseline in most cases (except NUS-WIDE) on the training and test sets. In addition, we can see that the Bernoulli representation has quite similar performance before and after thresholding. This is very clear in Reuters, TMC, Snippets and NUS-WIDE. We can conclude that (i) using Bernoulli latent variables the representation learned by the model is practically the same before and after thresholding; (ii) as the Bernoulli autoencoder learns to preserve the information about the dataset in the form of bits, it has advantages over a model trained to preserve that information in the form continuous features, when binary codes are required.
We conducted a additional experiment in which we train the classifier using the raw representations computed by the encoder but test the model using the representation after thresholding. The last column of Table 8 presents the results (“before
Altogether, the results obtained in this section confirm that a standard variational autoencoder has an advantage if a continuous representation is required, but the Bernoulli VAE that we propose (B-VAE) is better suited for applications where a binary representation is required, as in indexing and search using hash codes.
In this paper we have approached the problem of hashing in the framework of variational autoencoders and deep learning. This led to a novel algorithm to learn hash codes that resorts to an auxiliary generator network to compensate the lack of a supervisor. In contrast to methods based on traditional autoencoders, the model is not trained to learn a query-code association deterministically. Instead, an encoder network predicts the most likely region of the Hamming space where the input pattern could be allocated, in such a way that the generator net can reconstruct the observation by sampling from that region.
Our model for hashing differs from a previous technique using variational autoencoders by a simple but crucial decision: the latent codes are constrained to be binary. This is achieved by imposing Bernoulli instead of Gaussian distributions to the encoder, which leads to a model more easy to interpret in the context of hashing. The implementation and experimental analysis that resulted from this research proved that the latter choice is not problematic in a computational sense. The reparametrization trick is an effective technique to perform backpropagation through Bernoulli random layers and no specialized solvers are required.
We have assessed the proposed technique using seven public datasets from two different domains, namely image and text data, comparing the results with various methods from the state of the art. We found that learning Bernoulli rather than Gaussian latent variables improves similarity search metrics in the large majority of cases. In image retrieval tasks, the proposed method outperformed the Gaussian variational autoencoder in all the cases. A deterministic autoencoder with active binary constraints showed better ranked precision in many cases, suggesting than there is no silver bullet for hashing. As in these experiments, the proposed model provided the second best result, we can conclude that a Bernoulli autoencoder is a robust technique for hashing image data, even if sometimes it is not the top performer. Experiments on document retrieval tasks on the other hand, showed that in most cases the proposed method outperforms the Gaussian variant also in this type of problems. Together, the variational autoencoders were found always more effective than other techniques from the state of the art. Overall, these experiments demonstrated that the proposed method is functionally flexible and can be adapted to different types of data - it is enough to specialize the architecture of the neural nets for a particular application.
Experiments to illustrate the interpretability of the proposed model were also performed using the encoder and the decoder. In the text datasets, we found that most bits of the code learned by the model can be associated with a topic or set of words semantically related. We also found that most bits in the model are activated with a distribution that, in average, respects the model’s priors. All the bits were used to preserve information about the dataset, but they were activated selectively for some inputs but not for others. Finally, specific experiments were performed to measure the effect of quantization in both types of autoencoder. We found, as expected, that learning a continuous representation gives an advantage to the Gaussian autoencoder in tasks that do not require quantization. However, after quantization, the representations learned by the Bernoulli autoencoder preserves significantly more information about the dataset, and outperforms the Gaussian representations in all the extrinsic evaluations conducted except one (in which both perform about the same).
Overall, we conclude that Bernoulli variational autoencoders are an effective, interpretable and flexible approach to learn hash codes. In future work, we plan to extend this model to semi-supervised problems in which labels are available only for a small part of the dataset. We are also conducting experiments with novel training criteria inspired in information theory.
Footnotes
Acknowledgments
F. Mena thanks the Programa de Iniciación Científica PIIC-DGIP of the Federico Santa María University for funding this work.