
Abstract
Access to one of the richest data sources in the world, the web, is not possible without cost. Often, this cost is not taken into account in data acquisition processes. In this paper, we introduce the Learning Agents (LA) method for automatic topical data acquisition from the web with minimum bandwidth usage and the lowest cost. The proposed LA method uses online learning topical crawlers. The online learning capability makes the LA able to dynamically adapt to the properties of web pages during the crawling process of the target topic, and learn an effective combination of a set of link scoring criteria for that topic. That way, the LA resolves the challenge in the mechanism of combining the outputs of different criteria for computing the value of following a link, in the formerly approaches, and increases the efficiency of the crawlers. A version of the LA method is implemented that uses a collection of topical content analyzers for scoring the links. The learning ability in the implemented LA resolves the challenge of the unclear appropriate size of link contexts for pages of different topics. Using standard metrics in empirical evaluation indicates that when non-learning methods show inefficiency, the learning capability of LA significantly increases the efficiency of topical crawling, and achieves the state of the art results.
Introduction
The web is a rich source of data that can be used to create archives and data sets for tasks such as training machine learning models and performing data mining processes. But it is not possible to access this data at no cost. The cost-based data mining paradigm considers the data mining process comprehensively and evaluates the cost of each step according to standard criteria [1, 2, 3]. This paradigm specifically, for the classification problem, addresses three separate costs, which are the cost of data acquisition, cost of model induction, and cost of model application [1]. The cost of collecting data has been ignored by researchers more than other costs. While this may, in some cases, be the main cost of the whole process, such as creating topical archives [4, 5].
We suggest the use of learning topical crawlers for cost-sensitive topical data acquisition from the web. Since the most essential resource for crawlers is the available Internet bandwidth, we consider efficient use of this resource as the main cost. A topical crawler is an agent that navigates a subset of the web to find pages related to a particular topic. It predicts the relevancy of the corresponding page of a given link to the target topic and avoids links that lead to irrelevant pages. As a result, using a limited amount of network resources and bandwidth, the topical crawler will be able to collect target pages with acceptable coverage from the web [6]. Topical crawlers have been used for the acquisition of target data from the web with minimum cost by some researches [4, 5, 7, 8].
The main issue in the design of topical web crawlers is to make them able to predict the relevancy of the target pages of current links. The relevancy of the link context is one of the most effective parameters in calculating the potential of a hyperlink to lead the crawler to relevant pages [6, 9, 10, 11]. According to [9], the context of a hyperlink or link context is the terms that appear around the hyperlink within a web page. It has a special role in topical web crawling algorithms. The challenging question in link context extraction is how to determine which terms are around and related to a hyperlink? A human user can easily do that but, it is not an easy task for a crawler agent.
A variety of methods are provided to determine the link context, from methods that consider it broadly equivalent to the entire text of the page, to methods that consider it narrowly equal to link text [12]. Some methods also try to find the link context in a more effective way, such as the Text Window method [9], which considers a window of
Block-based methods such as [6], which uses vision-based page segmentation (VIPS) algorithm [13], have tried to dynamically determine the size and position of link context using the block text where the link is located. Block-based methods perform better than the text window method [6]. But such methods are sensitive to predefined parameters, such as PDoC in the VIPS algorithm [13], as well as other errors in extracting blocks that result in the extraction of wrong blocks and wrong link contexts [11].
These problems have led to proposing the Block Text Window (BTW) method [11], which combines the Text window and VIPS-based methods and uses the ability of each method to solve the challenges of the other one. Although this method has achieved better performance than each one of the two combined methods, it still faces the inherent problems of these methods, namely the static properties of the Text Window method and the predefined sensitive parameters of the VIPS algorithm. To solve these challenges, in the face of the dynamic and unpredictable web pages, we need methods to be able to adapt to the properties of web pages of a target topic during the crawling process and learn an appropriate link context for the hyperlinks of that topic. The online learning capability of the proposed method in this paper can overcome these challenges.
Many methods use more than one criterion for scoring the links to increase their efficiency; they combine several scoring methods [10, 14, 15, 16, 17, 18]. For example, [9] combines the computed score of the relevancy of the whole page text with outcome scores of some other criteria such as the relevancy of the link context. The mechanism of combining computed scores based on different criteria for a link is a challenge for all of the methods which use more than one scoring criterion. The more number of combined scoring criteria are the more serious challenge in the mechanism of combination.
Since it is not clear that how potent a criterion is for predicting the value of following a given link, each of the previous researches uses their own method for determining the degree of influence for each criterion in the final score. To the best of our knowledge, a linear algebraic combination is used for combining link scores in all of the previous methods that use more than one scoring criterion. The degree of influence of each criterion in computing the final score is determined based on their coefficients in the linear combination. Although Some researches, such as [14], established some experiments for determining these coefficients manually [15], many other works such as [6, 9, 10, 11, 16, 17, 18], set them based on intuitive argumentations. For example, [6, 9, 11] has used coefficients of 0.25 and 0.75 respectively for page text and link context relevancies; based on the assumption that the page text must have lower influence than the link context in the final score, and [10, 16, 17] has just used the average of the scoring criteria. Following this approach, if a method tries to combine four, five, or even more criteria, then it will face a severe challenge in determining the influence of each one in the final score.
The challenge in the mechanism of combining the methods, and more specifically, their outcome scores, is due to the inability to determine an algebraic combination of the scores for reaching the desired efficiency. Predetermining such a combination seems impossible because the dynamic nature of the web and the variety of page layouts do not allow such a static combination to be defined. In computing the final score of the links of a target topic, a method is needed which can automatically determine the degree of influence of each criterion. So far, no research has proposed such an approach for combining different link scoring methods for topical crawling.
In this paper, we introduce The Learning Agents (LA) method for topical crawling. The online learning capability of LA makes it able to dynamically adapt to properties of web pages during the crawling process of the target topic, and learn an effective combination of any set of link scoring criteria for that topic. This way, the novel approach overcomes the challenge in the mechanism of combining link scoring criteria. A version of the method is implemented that uses a collection of topical content analyzers for scoring the links. By utilizing the ability of online learning in LA, this implemented method resolves the challenge of the unclear appropriate size of link contexts for pages of different topics. The main contributions of this paper are:
Proposing a novel topical crawling method called Learning Agents, which has the online learning capability, and resolving the challenge in the mechanism of combining link scoring criteria. Implementing and evaluating a version of the LA method that resolves the challenge of the unclear appropriate size of link contexts for hyperlinks of different topics.
The key element of LA’s architecture that enables online learning is the score combiner component of the agents. This component predicts the relevancy of the page corresponding to a link by combining scores calculated by different criteria for that link. During the crawling process, when a page is fetched, the score combiner can correct its model online by comparing the true page relevancy (feedback) with the predicted value. The empirical studies are done on the performance of the implemented version of LA. The results are compared with the most effective existing approaches based upon different metrics, indicating the superiority of the proposed method.
The rest of this paper is organized as follows: in the next section, we take a look at existing topical crawling methods, Section 3 describes the proposed method in detail, Section 4 describes an implemented version of the method, Section 5 discusses experimental results, and the last section contains the conclusion.
In the present paper, we have focused on the cost of collecting web page instances, which can be considered as efficient bandwidth usage by topical crawlers. In this section we investigate topical crawling methods. The topical crawling methods can be divided into two main categories. The first category includes methods that analyze the content of pages for scoring links, and the methods of the second category, combine content analysis methods with link structure analysis methods. The reported results in [10] show that content analysis methods like Best First, which only considers the topic of pages, have better overall performance than combinatorial methods like improved HMM [10], and in some cases they are in close competition.
From another perspective, there are a number of topical crawling methods that train crawlers online with an adaptive approach [15, 19]. Considering the similarity of the main idea of the proposed LA method to these types of methods, in a separate subsection, these methods are described in order to clarify the LA differences with them. Below we describe the methods that belong to these three categories.
Content analysis for topical crawling
Content analysis methods have two major subcategories. Methods of the first subcategory compute the relevancy of some parts of a web page to the desired topic and score links of the page based on these relevancies [20]. In these topical content analysis methods, link context extraction plays an essential role in computing link scores. The simplest way for link context extraction is considering the entire text of the web page as a link context of the links of that page. Fish Search [21] and a version of Best First [12] used this method to score links of the web page. Another version of Best First method uses link text as link context but scores each link using a combination of the relevancy of page text and link context to the desired topic. It is done based on the following formula:
where link_score is the score of the link within the page, page_text is the entire page’s text, and link_context is the extracted link context of the link, which is the link text, in a typical Best First method. The Relevancy function is responsible for computing the score of a given text, based on the target topic. The
In some researches, such as [10], to implement the Relevancy function, the topic vector is compared with the page vector in the Vector Space Model (VSM) representation [22]. In some other researches, such as [9, 11], pre-trained classifiers have been used to determine the relevancy of the pages. The authors of [10, 23] have used ontology-based semantic methods to increase the efficiency of page content analysis. In one of these methods, all synonyms and hyponyms of a word in the VSM of the topic are added to the topic vector. Another semantic method uses only the synonym words to expand the topic representation vector.
Window-based methods can deal with varying length of pages and outperforms more complicated methods that use DOM tree information [9] for a variety of topics. In the Text Window method [9, 24] for each hyperlink, the window will have
Related parts of a page are called page blocks, and the procedure of extracting page blocks from a web page is called page segmentation. Link context extraction methods based on page segmentation use text of the page block as the link context of the hyperlinks positioned in that block. These methods are more accurate than other topical web crawling methods [6, 11, 18, 25]. In [6], Naghibi et al. propose a topical crawling method based on the VIPS algorithm [13]. VIPS determines page blocks. Since the VIPS algorithm utilizes visual clues in its page segmentation process and is independent of the HTML structure of the page, it can find link contexts more accurately, and the empirical study of this research shows it.
One of the main problems with block-based methods is the blocks that have been extracted incorrectly. As a solution to this problem, in a recent research [11], Naghibi et al. introduced a block-based link context extraction method that combines the VIPS algorithm with the Text Window method to modify the incorrect blocks and extract more accurate link contexts. This method, which is called Block Text Window (BTW), produced competitive results in comparison with the technique that uses the VIPS algorithm for topical crawling; specifically, the BTW crawlers have a better average harvest rate than VIPS-based crawlers, for the selected topics in [11]. Despite the improvements made, the BTW method still faces the inherent problems of combined methods, namely the static properties of the Text Window method and the predefined sensitive parameters of the VIPS, algorithm as mentioned in Section 1. The online learning capability of the proposed LA method has solved these problems.
The second major subcategory of content analysis methods tries to find the relation between the content of a web page and its distance from on-topic pages, regardless of the page topic, and compute contained hyperlinks scores based on this distance. Diligenti et al. introduced an interesting data model called Context Graph [26]. This model keeps the contents of some training web pages, and their distances from relevant target pages in a layered structure. Each layer represents pages with the same distances to relevant pages. By training a classifier for each layer, the distance of newly visited pages to target pages can be determined. Rennie et al. utilized a Q-learning framework for topical web crawling [27]. In their method, the quality or Q value of links is computed using a Naïve Bayes classifier. They mentioned that the concept of delayed reward is what makes reinforcement learning an appropriate framework for training topical web crawlers. A limited environment was used for the evaluation of their crawlers, and the training was done offline using a lot of human user efforts. Researchers of [28] used Hidden Markov Model (HMM) to compute the probability that the current links lead to relevant pages. Each page is characterized by two states: the visible state corresponding to the cluster that the page belongs to according to its content, and the hidden state corresponding to the distance of the page from a target one. Link scores are computed based on their page’s hidden states in HMM. This model needs considerable user interactions for making the HMM model. If a homogeneous path to target pages doesn’t exist, the methods belonging to this subcategory will get in trouble. Results of [10] show lower performance of methods like HMM [28] in comparison with methods of the first subcategory of content analysis methods like Best First [12].
Methods belong to this category use a combination of different methods [16, 17]. A major subcategory of combinatorial methods combines two subcategory of content analysis methods to use the advantages of both of them and let each one fill shortages of the other one. The Relevancy Context Graph [29], an improved version of the HMM method [10], and the proposed method in [30] are three examples for this subcategory of combinatorial methods. In [30], Han et al. utilized reinforcement learning for topical web crawling and formulated the problem as a Markov decision process (MDP). They proposed a new representation of states and actions which considers both content information and the link structure. Reported results in [10, 29] show combining these two subcategory of content analysis methods improves their performance. Another subcategory of combinatorial ways, combines content analysis with link structure analysis methods. The link structure analysis methods determine the score of the page based on the structural analysis of the web graph [31, 32]. Chakrabarti’s Topical Crawler [33] and OTIE algorithm [34] belongs to this subcategory. Since in topical web crawling, the content of web pages plays a vital role in guiding crawlers to the target pages, methods only based on link structure analysis will not have acceptable performance. The unclear appropriate mechanism of combining methods is the main challenge of most of the combinatorial methods.
Adaptive methods for topical crawling
The authors of [19] proposed an adaptive topical crawler that utilizes page text and link text for scoring hyperlinks. This method uses interactive and automatic adaption approaches for online learning of hyperlink selection policy, from previously crawled pages. In their process, classifiers are retrained periodically by incorporating the newly found samples, to address the potential initial unavailability of sufficient and appropriate training data for representing the domain of interest, and the changes occurring in the domain of interest over time. Limited experiments were done for the evaluation of the method.
In [15] based on the idea that texts in different parts of a page and their distances from a hyperlink can be utilized for predicting the relevancy of the target page of that hyperlink, the authors used DOM tree of a web page to compute distances of words positioned in different leaves of DOM tree from a hyperlink within that page. After fetching the target page of a hyperlink, its relevancy is calculated. The set of the related
The proposed LA method is inspired by apprentice learner [15] and has similarities to adaptive crawlers [19]. The difference between LA and these two methods is that the provided feedback by relevancy evaluator in the architecture of apprentice learner (which they called the base learner) and adaptive crawlers, is only used for training the apprentice learner [15], and two page text and link context classifiers [19], respectively. The way of learning in [15, 19], corresponds to using only one or two analyzers inside the agents of LA. In other words, in LA, it is possible to train many analyzers at the same time, and the apprentice learner of [15] may be one of them. Also, the learning ability of the score combiner makes it possible to attain the appropriate combination of computed scores. Thus it can be said that LA is more general than [15, 19].
Proposed learning agents method
As we mentioned earlier, the mechanism of combining computed scores for a link is a challenge for almost all the methods which use more than one scoring criterion. In this section, we propose the Learning Agents method, which by using machine learning algorithms, can learn an effective combination of any set of link scoring methods and resolve the discussed challenge. The proposed LA, by learning an appropriate combination of a set of methods, establishes combinatorial methods with higher performance.
Modules of LA
Figure 1 illustrates the architecture of the proposed method. LA consists of four main modules: priority queue, relevancy evaluator, learning agents, and data repository. In the following, we describe the main modules of the architecture in detail.
The architecture of the proposed LA.
The priority queue contains the links which are likely to point to relevant pages and should be fetched from the web for analysis. The queue is initialized with a set of seed pages. The crawler fetches target pages of these links from the web, and links of each newly fetched page are scored and put to the priority queue. The queue keeps links sorted based on their scores.
Relevancy evaluator
Since, in the topical crawling process, the crawler automatically fetches a considerable number of pages, it is difficult to determine the degree of relevancy of pages to the topic by a human user. The relevancy evaluator is a replacement of human user to compute the relevancy of crawled pages to the topic automatically. The researchers proposed different methods for constructing a relevancy evaluator; Such as using a set of keywords and computing their similarity with fetched page [35, 36] or using a set of seed pages which are determined by the user and computing the similarity between them and the fetched page [10]. Another method is using a classifier that is trained by a set of relevant and irrelevant pages to the topic [9, 37, 38]. The relevancy of a page to the topic is determined based on the output of the classifier. The output of the relevancy evaluator is a measure of relevancy of pages to the topic. Also, it is given to the score combiner as feedback. The score combiner is trained using this feedback. The learning agents can utilize this feedback for training the analyzers, which are responsible for computing link scores, any time it is necessary.
Learning agents
This module consists of a set of learning agents, and each of these agents contains three main components: crawler, analyzers, and score combiner. We explain these components in detail.
Crawler
The crawler is responsible for acquiring pages that belong to the desired topic from the web. This component gets links from the priority queue and performs the crawling by fetching target pages of these links. After fetching a page, the learning agent uses a set of analyzers to process the page and produces a set of scores for each link of the page.
Analyzers
A set of analyzers make an intelligent component for the learning agent. An analyzer is an algorithm that takes a page as input and computes the score of links of the page as output. Each score, shows the value of following the link from the viewpoint of the analyzer. Formally if
be the set of
where analyzer
The range of
The score vector
Score combiner
This intelligent component of a learning agent is provided for resolving the challenge in previous methods and their inability to effectively combining the scores computed by more than one analyzing method. The score combiner is a learning algorithm that computes the final score of a link, based on the set of calculated scores by the analyzers of the learning agent. The algorithm uses a supervised learning strategy. Still, since the supervisory signal, which is the true output of the score combiner, is automatically provided by the relevancy evaluator module as the feedback, from an external viewpoint, the learning process is fully automatic. As a result, LA does not need any direct user interference. Also, the score combiner is trained during an online learning process.
More formally, the score combiner learns a function that provides an appropriate mapping between the computed scores by the analyzers (input), and the final score of the link (output). If we consider
where
The actual relevancy of a newly fetched page to the topic, and the set of computed scores in previous steps, for the link (or links) which points to this page, provides a learning instance for the training of the score combiner model. The computed scores by the analyzers are equivalent to the input, and the relevancy of the page, which is calculated by the relevancy evaluator, is equivalent to the true output of the learning model. Suppose, previously fetched page
where
where
where
where
Illustration of LA functionality as an algorithm.
The data repository is a place for saving relevant, crawled pages. Different types of content in an acquired web page, including text, images, etc. can be extracted from the page and be used for making data instances that will be used for further data mining and machine learning tasks.
Functionality of LA
Figure 2 shows the functionality of LA in the form of an algorithm. After initializing analyzers of the learning agents and the relevancy evaluator, a set of seed URLs are put to the priority queue. Then a learning agent is selected from the set of learning agents, and the crawler component of the chosen agent, gets the URL with the highest score from the queue and fetches its target page from the web. The fetched page is given to the relevancy evaluator by the agent. The relevancy evaluator determines the relevancy degree of the fetched page to the topic and provides feedback that is given to the learning agent. The agent provides the fetched page to each of its analyzers. The analyzers process the page and compute a score vector for each of its links. The calculated score vectors are given to the score combiner. The score combiner computes the final score of each link of the page by combining the calculated score vectors; then, the agent puts links with final scores in the priority queue. By utilizing the provided feedback by the relevancy evaluator, the online learning analyzers can modify their score computing models, if it is needed. The score combiner creates a learning instance by matching the provided feedback by the relevancy evaluator with the corresponding computed score vector. The process of learning the mechanism of combining the scores is done, and the score combiner modifies its model if it is necessary. The learning process of the score combiner can be stopped after satisfying some predefined conditions; for example, after crawling a predefined number of pages or if the loss of score combiner gets less than a threshold during a specific crawling period. If the fetched page is recognized as relevant, it can be saved in the repository. The crawling process will be stopped based on some conditions, and if they are not satisfied, the learning agents continue their tasks by getting new URLs from the priority queue.
Domain experts can be involved in two parts of the overall process. First, in creating the datasets to train analyzer and relevancy evaluator models, which has been done in some way by data labeling volunteers (e.g. DMOZ [40]), and the work of these domain experts has been used in the form of datasets. The second role of the domain expert in the overall process is to act as a human relevancy evaluator to determine the relevancy of the crawled web pages; in this way, the domain expert can completely replace the relevancy evaluator classifier, or take over the labeling of samples that the relevancy evaluator classifier is not sure about.
In the web environment, there are a lot of noisy data and links that are corrupted or do not lead to relevant pages. For this reason, using a set of criteria and not relying on a few limited criteria strengthens the link scoring model in topical crawlers. If one or more criteria for scoring links for a given topic do not work well due to input data noise, the adaptive learning process in the proposed LA method reduces the impact of these criteria on the final score and increases the impact of other scoring criteria in the score combiner model. The score combiner maintains the performance of the crawlers at an appropriate level. Also, if some input data related to a particular link is noisy, due to the combination of multiple scoring criteria, the proposed LA method will be more robust than other methods that use a limited number of criteria.
An implemented version of LA
Different methods can be designed and implemented based on the proposed architecture of LA; it can efficiently combine different types of methods and produce an effective combinatorial one. In this section, we describe the modules and components of an implemented version of LA, and in the next section, we examine its capabilities based on empirical evaluations. Based on the discussions in Section 2 about the advantages and disadvantages of different analyzing methods used for the conduction of topical crawlers, we utilize a combination of some topical content analysis methods in the implemented version of LA. Since the LA is capable of learning an effective combination of the outputs of utilized topical content analysis methods, it is expected that the proposed method outperforms the sole use of each of its combined methods. In the follows, we describe the modules and components of the implemented LA. The priority queue and the data repository modules, and the crawler component of the learning agent are implemented as described in the previous section.
Implemented analyzers of the agents
A learning agent of LA uses eight analyzers for computing link scores. These analyzers use: whole text of the page, link text, small text window, medium text window, large text window, the text of the block which contains the link, text of whole links of the page, and text of whole links of the block which contains the link. Figure 3 illustrates the implemented analyzers of the learning agents and shows how they are linked to the score combiner to produce the combined score.
Illustration of the implemented analyzers of the learning agents and their connections to the score combiner.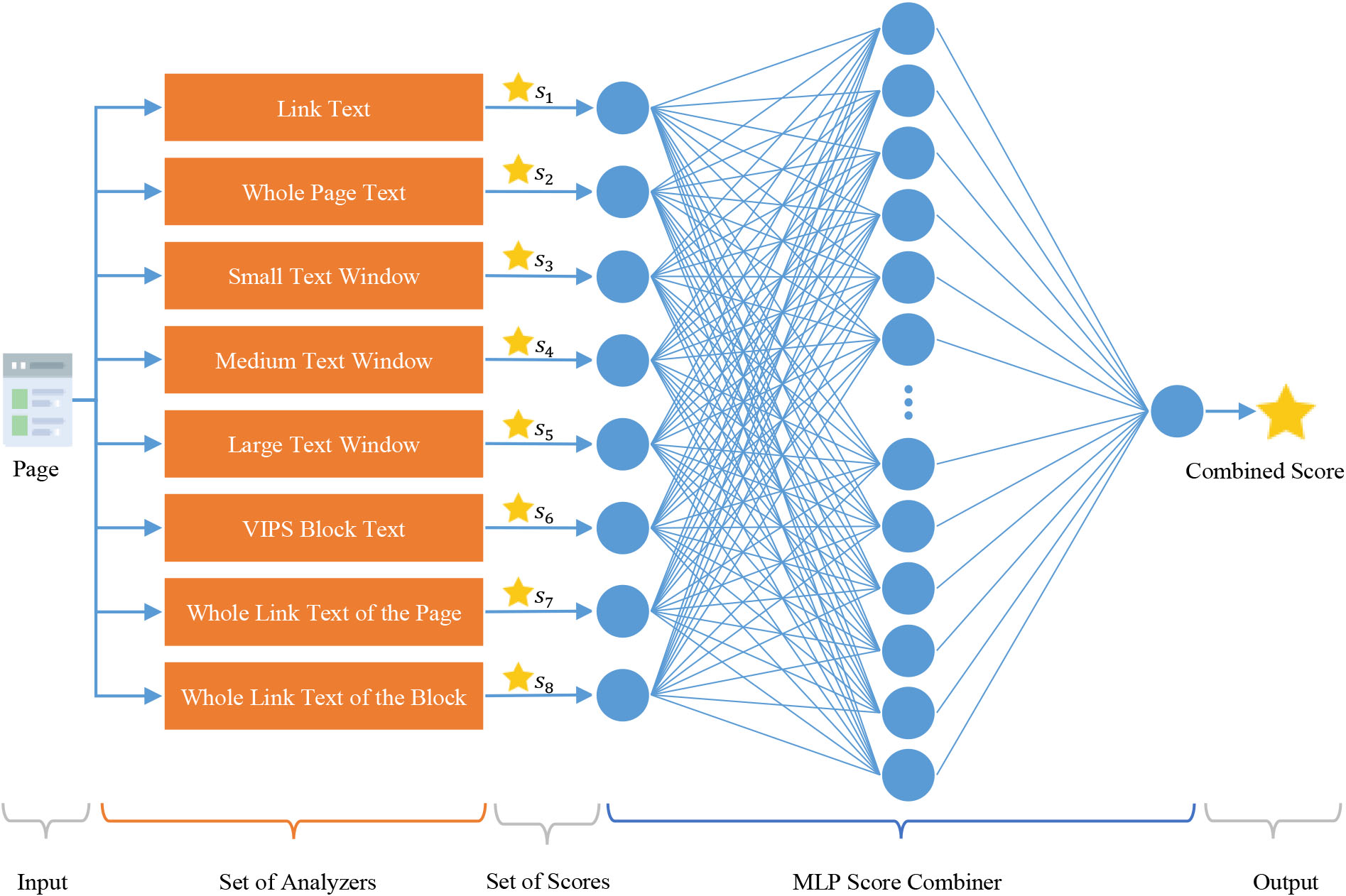
All of the analyzers use Multi-Layer Perceptron (MLP) classifiers for determining the degree of relevancy of a given text to the topic. The classifiers are trained using some positive and negative instances collected from the DMOZ [40]. DMOZ is a directory of a considerable number of web pages that are categorized hierarchically by a group of volunteers. After determining the target topic for the topical crawler, pages belonged to the topic, and if it is needed, pages belonged to its sub-topics (which are placed in the lower levels of the topics hierarchy and can be considered as the parts of the target topic), will be given to the classifier as the positive instances. A set of pages which are belonged to any part of the directory expect the related parts to the target topic and their sub-parts (or sub-topics), will be served to the classifier as the negative instances. The DMOZ dataset does not contain much noise because it is manually labeled by qualified volunteers. In cases where the data of web pages is not fully retrievable, they are removed from the dataset to prevent the creation of noisy data. In the following, we describe each part of the text of the page, which is analyzed by topical content analyzers of the implemented version of LA.
The whole text of the page and link text are used in many conventional topical content analysis methods [10, 12, 19]. The empirical results show the sole use of each of them, results in lower performance in comparison with using a simple linear combination of computed scores based on both of them. Generally, the whole text of the page can show the topic of the page, and somehow, the topic of target pages of its links; the link text shows the topic of its target page more specifically.
Text windows with different sizes
Text Window is one of the most simple and at the same time, one of the most efficient methods for link context extraction. As pointed in [9], the optimal size of the window is not apparent. In that work, Pant and Sirinisavan established a set of empirical experiments to determine the appropriate size of the window and in each test considered it as a constant value. To resolve the challenge of the unclear size of the window, in the implemented LA, we used a set of text windows with small, medium, and large sizes and allocated one analyzer to each one. Hence, the score combiner by determining the degree of influence of analyzers with different window sizes on the final computed score will be able to implicitly determine the appropriate size of the window for pages of a given topic.
Text of the block which contains the link
If a page segmentation method that uses both the DOM tree and the visual layout of the page, be utilized for determining blocks of the page, then the text of the block can be considered as a candidate link context for the links of the block. Since VIPS algorithm has been successfully used in many fields of web mining [41, 42, 43], and topical crawling [6, 11] for page segmentation, we used this algorithm for segmenting web pages and extracting their blocks.
Text of whole links of the page and the block which contains the link
The text of the whole links of the page is produced from the concatenation of all of the link texts of the page. Similarly, for a block, this kind of text is provided by the concatenation of text of all links which are inside the block. We introduce these two types of text and justify using them by reason of using link text together with the text of the whole page for computing scores. We know it is possible that a given page is relevant to the topic, but its outgoing links don’t lead to relevant pages. The concatenated text of the links of the page or the block can show the overall topics of pointed pages from the current page or block. These texts can help in determining the topic of the target pages of the links, more specifically than the text of the whole page and more generally than the link text. Thus we utilize them in computing link scores and delegate the task of determining their influence besides the other scores to the score combiner.
Implemented relevancy evaluator
In the implemented LA, we used classifiers for determining the degree of relevancy of the crawled pages to the target topic. Since a classifier uses a set of positive and negative instances for training, it can determine the relevancy of a page to the topic better than other methods like using a representative vector of keywords, as mentioned in Section 3. The classifier of the relevancy evaluator is trained just like the classifiers of topical content analyzers with only one difference; it uses more learning instances than the classifiers of the analyzers. We used an MLP as the classifier of the relevancy evaluator for each selected topic. In the implemented version of LA, the relevancy evaluator is not updated. However, by receiving new pages and considering these pages as positive and negative samples after classifying them, the relevancy evaluator can be updated periodically using these new training samples.
Implemented score combiner of the agents
Any algorithm which has the capability of learning a mapping from a set of inputs to a set of outputs can be used for implementing the score combiner component of the learning agents. In the implemented LA, we used an MLP as our score combiner which its input is the computed scores by the analyzers for a given link, and its output is the final computed score, which is an estimation of the value of following the given link.
Empirical study
In this section, at first, we describe the evaluation metrics used for performance evaluation. Then we explain the implementation of the proposed method and other compared methods in detail, and we talk about the experimental settings of our evaluation. After that, we compare the performance of the proposed method with some topical crawling methods which owned the state of the art results in previous researches.
Evaluation metrics
We use standard metrics that can evaluate topical crawling methods based on their success on minimum waste of bandwidth resource; because the main cost in topical data acquisition problem is the cost of bandwidth usage. We have used two standard evaluation metrics, Harvest Rate and Target Recall, to describe and compare the performance of different topical crawling methods. These metrics have been used by many researches [6, 9, 10, 11, 34].
Harvest rate
For
where
From the start of the process, the target recall
where
We believe that the harvest rate metric can reflect topical crawling performance better than the target recall metric. Because harvest rate computes the relevancy of each crawled web page by utilizing evaluator classifiers, but target recall is only concerned about pages that are in target set
Compared methods and their settings
The implemented LA is compared with four other methods. These methods are the Best First method, Text Window method, VIPS-based method, and Block Text Window method. Based on [6, 9, 10, 11, 18], Best First, Text Window, VIPS-based, and BTW methods have been lead to the state of the art results in many topical crawling experiments. Also, the reported results of [10, 9] show better performance for versions of Best First and Text Window methods, which utilize both link context and page text for computing link scores; the results of [11] shows this fact for the BTW method. Hence we implemented these versions of Best First, Text Window, and BTW methods, and we used Eq. (1) for combining relevancy scores. In Eq. (1), link_context is considered as link text, text of the window, and text of the window inside the corresponding block, for Best First, Text Window, and BTW methods, respectively. Also, we implemented and evaluated two versions of the methods which use the VIPS algorithm [13]. One version uses block text as the link context and computes the link score based on the context relevancy, and the other version combines the relevancy of link context with the relevancy of page text using Eq. (1). The
To study the influence of the learning process in the performance of implemented LA, which is done by the score combiner component, we implemented another version of LA, which computes the final score of the link by averaging the output of all of the analyzers. In other words, in this version of LA, the score combiner is replaced with a simple averaging function. We call this version, the Non-Leaning Agents.
We have utilized the described relevancy evaluator for determining the degree of relevancy of crawled pages by different compared methods in this paper. The implemented analyzer classifiers of LA are also used as the Relevancy function in Eq. (1) for compared methods. The settings of the VIPS algorithm, which is used in some compared methods, are the same as the parameters of this algorithm in implemented methods based on LA.
Selected topics
The number of target topics that are used for the evaluation of topical crawling methods is a number from 2 to 15 topics in previous researches [6, 10, 11, 15, 18, 28, 29]. Also, some works like [12, 9] evaluated topical crawling methods based on about 50 and 100 different topics, respectively. The crawlers of [10] download up to 100 KB of pages HTML, and the implemented LA downloads whole HTML of pages; But, the crawlers of [9, 12] downloads only the first 10 KB of pages HTML during the crawling process.
In a manner similar to [10, 11], eight distinct topics from different domains are selected to evaluate topical crawling methods. The selected topics are Algorithms, England Football, First Aid, Graph Theory, Java, Linux, Olympics, and Robotics. We chose these topics from DMOZ, like [15, 9]. The corresponding pages of each topic and the pages of a predefined depth of their sub-topics based on the hierarchical structure of DMOZ are extracted from the web. The extracted pages, forms the relevant set of each topic. The relevant pages of the topic itself, forms the relevant set with the depth of zero, the relevant pages of the topic itself in addition to its immediate sub-topics, forms the relevant set with the depth of one, and so on. This way is similar to the suggested method in [35] for extracting the representative vector of the topic from the DMOZ.
Table 1 describes the properties of selected topics. The Number of Pages column shows the number of pages of the relevant set of the topic, from the root to the determined depth based on the DMOZ structure. The URL of these pages is extracted from the dump of the DMOZ [40]. A one-third of the relevant set of the topic is considered as target set
Properties of selected topics
Properties of selected topics
Seed pages of selected topics
We used similar settings to [6, 11] for the relevancy evaluators. The relevancy evaluators for each topic are MLP classifiers. Also, the VSM [22] is used for the representation of the web pages. For representing the pages in this space, first, the text of the page is extracted using the HTML Parser [44]. Then the stop-words are removed from the text, and a stemming process is done on the remained words using the Porter algorithm [45]. The weights of the words are determined based on the TFIDF method [22]. Each stemmed word forms one dimension of the VSM. Each dimension of the vector space is considered as a feature for the classifier’s input. The vast number of features emerges the curse of dimensionality problem and makes the training of MLP classifiers practically impossible. One solution is using feature selection methods. Also, a good feature selection process can increase the efficiency of the classifiers [46]. We used Information Gain (IG) as the feature selection metric based on reported results in [46]. All of the classifiers are 3 layer MLPs (with one hidden layer). The training of the classifier is done using the whole relevant set of the topic as the positive instances, and double of this number from the relevant pages of the other topics as the negative instances. We have used some packages of Weka [47] for implementing the classifiers.
In previous research, various methods have been proposed to determine the number of hidden layers and the number of neurons in these layers [48, 49, 50]. In most cases, it is appropriate to use only one hidden layer to achieve an efficient model [48]. To determine the number of hidden neurons, the rules of thumb presented in [50] and the method presented in [49] have been considered. According to one of the rules in [50], the number of hidden layer neurons is determined to be about two-thirds of the sum of the number of input and output neurons. Also, according to the equation presented in [49], the lower the ratio of the number of training samples to the number of input neurons, the less number of neurons in the hidden layer is needed. Considering that the average number of training samples is equal to about 730 samples, which is a small number compared to the number of input neurons, and also to facilitate the training of models, the number of hidden layer neurons is one-third of the number of input neurons. For other hyperparameters of MLP models, the default values of Weka are used.
Also, the appropriate number of features varies from one topic to another. Hence we have done a set of experiments for determining the number of features for the relevancy classifier of each topic. Table 3 shows the performance of the trained relevancy evaluator classifiers, based on well-known F-measure metric [51]. The metrics are computed based on 10-fold cross-validation. Using a number of 500 words as the input features of the classifiers results in appropriate performance for most topics. Nonetheless for First Aids and Graph Theory topics, using 700 features and for Algorithm topic using 300 features results in a notable increase in the performance of the classifiers.
Properties of relevancy evaluator classifiers
Properties of relevancy evaluator classifiers
To simplify the implementations, the learning agents are implemented homogeneously and use a set of the same crawler, analyzers, and score combiner components. We have done a multithread implementation of the agents by utilizing and modifying some Java libraries associated with [52]. This implementation makes the crawler component able to fetch many pages at the same time and efficiently uses the network bandwidth. In the following, we explain the settings of two intelligent components of the learning agents.
Settings of analyzers of the agents
Analyzers of the agents use the classifiers for determining the degree of relevancy of the given texts. This process is done after some pre-process, just like what described for the relevancy evaluator. Based on [9], using whole text of some relevant and irrelevant pages as the training set of analyzer classifiers of the agents will result in higher performance in comparison to using neighboring texts of links which lead to relevant and irrelevant pages, as the training set of the classifiers. Hence we used the whole text of relevant and irrelevant pages as the learning instances for training the topical content analyzers of the learning agents. The used classifiers for all of the analyzers of a specific topic are the same.
The type and the training process of analyzer classifiers are the same as the classifier of the relevancy evaluator, with one difference: the pages that are members of the target set of a topic are removed from the set of positive instances, and the number of negative instances relatively decreased; this ensures that the analyzer classifiers have not seen the target pages before. The number of input features for the analyzer classifiers of each topic is considered the same as the relevancy evaluator classifiers. Table 4 describes the properties of analyzer classifiers. All of the evaluation metrics are computed based on 10-fold cross-validation. The metrics describe the high performance of the implemented relevancy evaluators specifically based on precision and F-measure metrics. Thus the decisions made by the relevancy evaluators will be highly confident. Particularly if a page is classified as relevant by the classifier, with high confidence, this classification is correct.
Properties of analyzer classifiers
Properties of analyzer classifiers
We have used the VIPS algorithm [13] for the page segmentation and block extraction process in corresponding analyzers. The PDoC parameter of the VIPS algorithm is set to 0.6, according to [41]. The window sizes of the analyzers which use Text Window method are set to 10, 20, and 40 for small, medium, and large window size, same as [9]. The visually extracted page blocks by VIPS are more likely to lead to the correct position of the link context of a hyperlink, in comparison with the whole page [11]. Thus in the implemented LA, for extracting the link context of a hyperlink, we apply the Text Window method on the text of the block in which the hyperlink is inside.
Settings of score combiner of the agents
We have implemented the score combiner component of the learning agents as an MLP neural network with three layers (one hidden layer). The number of inputs of this neural network (i.e., the number of input neurons) is equivalent to the number of outputs of the analyzers of the agent. Since each analyzer has one output, the number of input neurons of the score combiner is eight. This MLP has a single output that provides the final score. According to the method presented in [49], to determine the number of neurons in the hidden layer, the higher the ratio of the number of training samples to the number of input neurons, the more neurons are needed in the hidden layer to allow learning more complex patterns. Given that there are eight neurons in the input layer of the implemented MLP model for the score combiner and there are several thousand training samples, according to the equation presented in [49], about 80 neurons in the hidden layer should be used. But according to [50] rules of thumb, it is better that the number of hidden layer neurons to be less than twice the number of input neurons. Given these two criteria, 40 neurons are used for the hidden layer of the implemented score combiner model. For other hyper parameters, the default values of Weka are used.
The learning process of the score combiner can be done online by fetching each new page. For facilitating the implementation procedure, we did not use an incremental learning algorithm in the score combiner, and the learning process is done periodically after fetching each 1000 new pages. Before the first period of training, the final score is computed based on the average of input scores to the score combiner. In other words, for the first 1000 crawled pages, the functionality of two implemented methods based on LA, i.e., the Learning Agents and Non-Learning Agents, are just the same.
In this section, we compare the discussed topical crawling methods based on the described metrics. To do this, we established a relatively long crawling process by fetching 30,000 pages for each pair of selected topics and methods, like [11]. It should be pointed that most previous researches have done topical crawling processes for 1000 to 20,000 pages [6, 9, 10, 12, 15, 28, 29] and some like [12, 9] have done some additional experiments respectively by fetching 50,000 and 100,000 pages for fewer number of topics with limitations mentioned before.
Figures 4 and 5 illustrate the comparison of two implementations of the proposed Learning Agents method with Best First method, three versions of Text Window method with different sizes of the windows, three versions of Block Text Window method with different sizes of the windows, and two versions of the method which uses VIPS algorithm, based on harvest rate and target recall metrics, respectively. Except for one version of the method based on VIPS, which only uses link context relevancy, all of the compared methods with LA implementations utilize a combination of page text relevancy and link context relevancy based on Eq. (1) for computing link scores.
As can be seen in Fig. 4, the average harvest rate of almost all non-learning methods (includes Non-Learning Agents method), changes with a relatively same flow. The average harvest rates of these methods, in the beginning, have ascending progress and continue during the crawling of the first 1000 pages. By getting far away from the seed pages, the average harvest rate of all of these methods falls into a descending flow, and this continues to the end of the experimented crawling period. In some of these methods, the speed of decrease in harvest rate, reduces as the methods crawl more pages.
Performance comparison between two implemented versions of the proposed Learning Agents method, Best First method, three versions of Text Window method, three versions of Block Text Window method, and two versions of the method which uses VIPS, based on average harvest rate metric.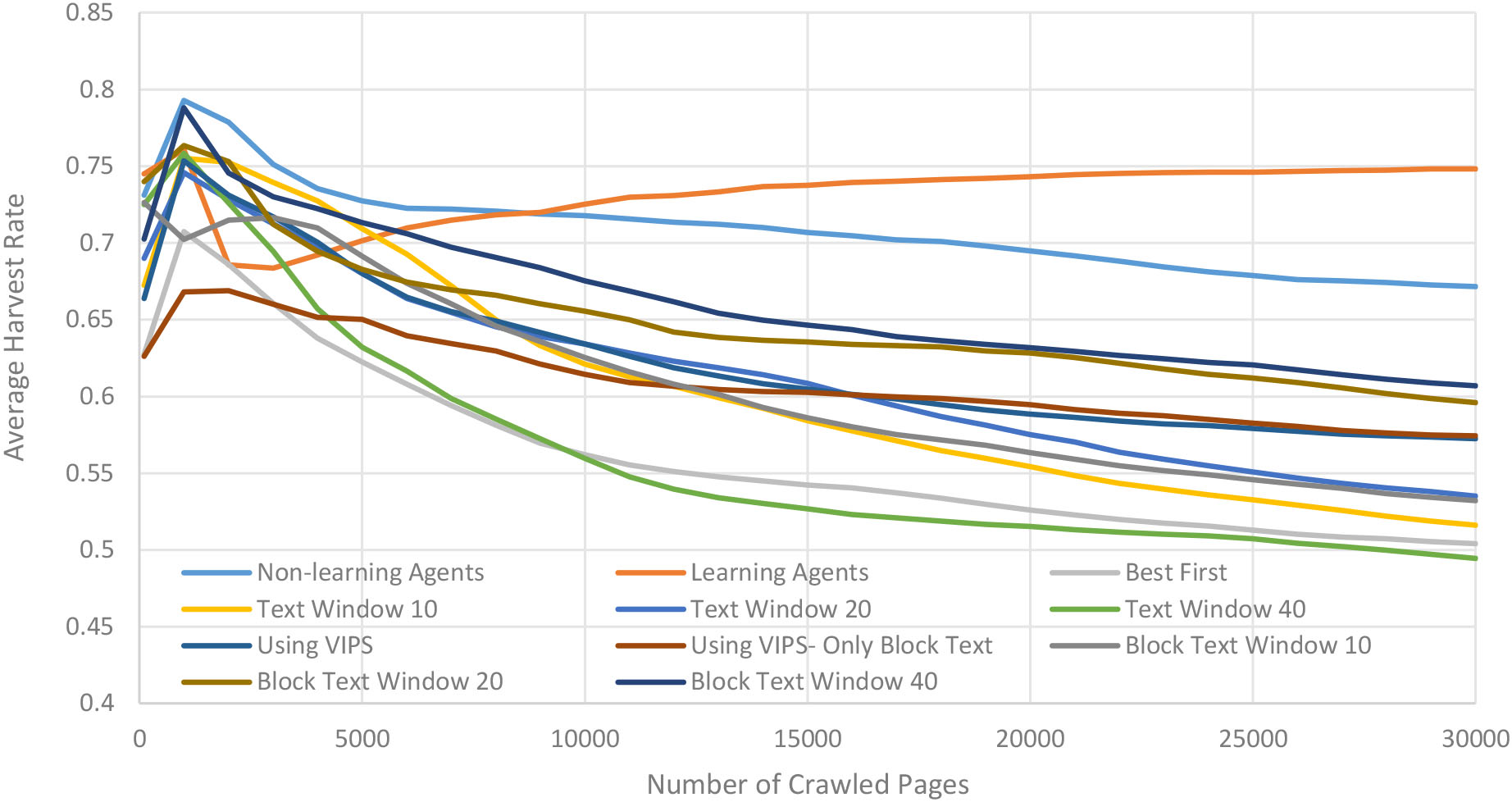
Performance comparison between two implemented versions of the proposed Learning Agents method, Best First method, three versions of Text Window method, three versions of Block Text Window method, and two versions of the method which uses VIPS, based on average target recall metric.
The higher harvest rate of the Non-Learning Agents method, in comparison with other non-learning ways, has two main reasons. The first reason is the combinatorial nature of this method; this method combines the output of eight distinct analyzers by averaging the outputs. The influence of this combinatorial method is similar to the excellent experience of combining the computed score based on page text and link context in previous researches such as [9, 10], with one difference: Non-Learning Agents method uses a series of link contexts rather than using just a single one. Also, since most of the implemented LA analyzers use link context, the weight of the whole text of the page will be lower than the weight of link context in the averaging process, similar to assigning a lower value than 0.5 to
Since the implemented Learning Agents use just the same method as Non-Learning Agents during the crawl of the first 1000 pages, the flow of changes in the average harvest rate of Learning Agents is the same as other non-learning methods in this period of crawling. But during the crawling of page 1000 to page 2000, the harvest rate of Learning Agents sharply decreases and places this method almost lower than all other compared methods. After that, the harvest rate of Learning Agents, unlike other compared methods, first gets stable and then starts an ascending flow. This ascending flow continues until the end of the experimented crawling period. Although the speed of increase in harvest rate of Learning Agents slows down as this method crawls more number of pages, but the ascending flow of harvest rate of Learning Agents and the descending flow of all of the non-learning methods, places Learning Agents in a much higher position.
As we can see in Fig. 5, the Learning Agents outperform the other compared methods based on the target recall metric. The target recall of the way, which uses the VIPS algorithm and the Non-Learning Agents method are very close to each other and stand below Learning Agents at the end of the experimented crawling period.
Also, we can see the influence of the learning process by comparing the flow of harvest rate and target recall of Learning Agents and Non-Learning Agents methods in Figs 4 and 5. As it is expected, we see in Fig. 4 that the harvest rates of Learning Agents and Non-Learning Agents methods are close to each other for the first 1000 crawled pages. After fetching 1000 pages, the first training period of the score combiner is done based on the produced learning instances; afterward, until the end of the crawling process, the scores of the links are computed using the score combiner. Figure 4 shows that approximately between fetching page 1000 and page 2000, the Learning Agents method faces a significant decrease in harvest rate and places much lower than its non-learning version. The reason is that the 1000 and even 2000 learning instances were not sufficient for training the score combiner; as a result, the score combiner was not able to appropriately determine the scores of the links. The very lower decrease in harvest rate of the Non-Learning Agents method, in comparison with the Learning Agents method, is a witness for the mentioned reason. After fetching 2000 pages and retraining of score combiner, not only the sharp decrease in average harvest rate of Learning Agents disappears, but also the harvest rate of this method almost gets stable between fetching pages 2000 to 3000. In this period, the harvest rate of the Non-Learning Agents method decreases at a higher rate. Approximately from fetching page 3000 to the end of the crawling process, the Learning Agents method gets into an increasing flow of harvest rate. This flow can be considered as the mirror of the harvest rate flow of Non-Learning Agents, and all other non-learning compared methods. As Fig. 5 illustrates, at the beginning of the crawling process, the target recall of the Learning Agents method is lower than its non-learning version. But after fetching about 3000 pages, the growth rate of target recall of the Non-Learning Agents method gets very low, and from that point, there is no significant change in target recall of this non-learning method to the end of the crawling period. On the other side, approximately between crawling page 6000 to page 8000, the target recall of Learning Agents dramatically increase and makes this method superior to Non-Learning Agents. The supremacy of Learning Agents over its non-learning version based on the target recall metric is kept until the end of the experimented crawling period.
Performance comparison between Best First method, three versions of Text Window method, three versions of Block Text Window method, the method which uses VIPS, and the proposed Learning Agents method based on harvest rate metric for a) Algorithms b) England Football c) First Aid d) Graph Theory e) Java f) Linux g) Olympics h) Robotics topics.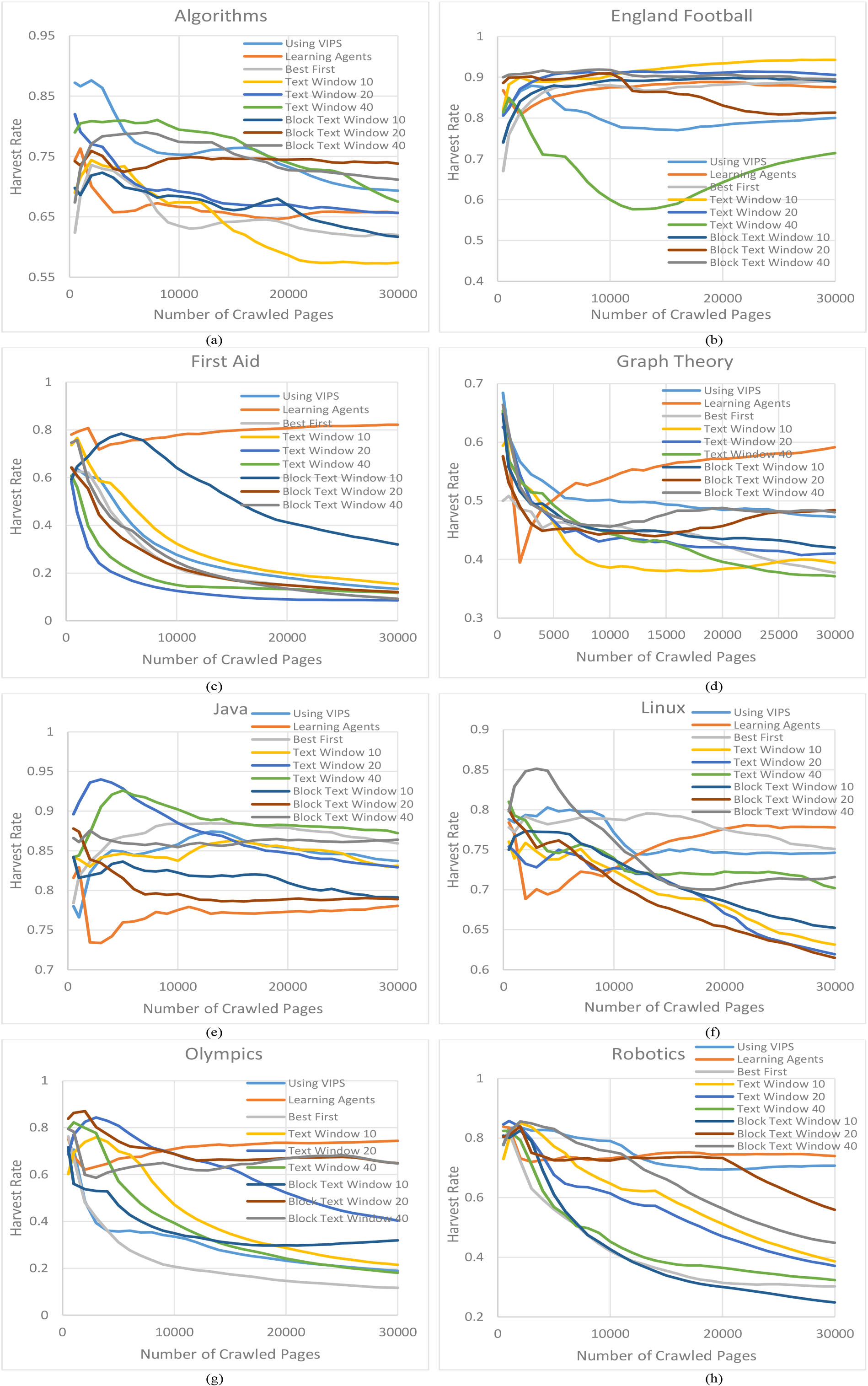
The methods may have various behaviors for different selected topics. Thus, to better illustrate the efficiency of the methods, in Fig. 6, eight methods including Best First method, three versions of Text Window method with different sizes of the windows, the block-based method which uses VIPS algorithm, and three versions of Block Text Window method with different sizes of the windows, are compared with the proposed Learning Agents method, based on the harvest rates metric for eight selected topics. Figure 6 shows that the performance of almost all of the non-learning methods has descending flow, and in contrast, the harvest rate of the proposed Learning Agents method gets ascending after crawling less than 3000 pages for the selected topics. The growing harvest rate of the Text Window 40 method, after crawling 13000 pages for the England Football topic in Fig. 6b, is an exception in the performance flow of non-learning methods; the reason may be finding rich sources of relevant URLs after this long period of crawling. This late ascending flow is different from the early growth in the efficiency of the Learning Agents method.
Another point is the variable efficiency of the eight non-learning compared methods for various topics. The position of curves of these methods dramatically varies from one topic to another. The BTW method with window size 40 has better performance than the other non-learning methods. Mainly, for the Text Window method, the best harvest rate is produced from different window sizes for various topics; this shows the strong influence of the window size in the efficiency of the Text Window method, and the challenge of using the same window size for different topics. This problem also exists in the BTW method, but in a milder form. In contrast, the proposed LA method has a higher harvest rate for five of eight selected topics (Fig. 6c, d, f, g and h), and its performance is not far from the best results for the other three topics (Fig. 6a, b and e).
Also, the curves of Fig. 6c shows, for the First Aid topic, the harvest rate of the LA is much higher than the other methods. This demonstrates the ability of the proposed LA method for the efficient crawling of challenging topics, where other methods are unsuccessful. In Fig. 6d, f, g and h for Graph Theory, Linux, Olympics, and Robotics, respectively, the curve of the LA crosses the curves of the other non-learning methods and reaches a higher position. In Fig. 6a and g, for the Algorithms and Java topics, respectively, the descending flow of non-learning methods and the ascending flow of the LA did not cross each other during the evaluated crawling period of 30,000 pages; but as the flows show, the LA curves are getting close to the higher curves, and it is possible to reach the a higher position after more extended crawling periods. In Fig. 6b for the England Football topic, the harvest rate of the LA is lower, still competitive with the other compared methods. The higher harvest rate of the Text Window 10 for the England Football, maybe because of the specificity of this topic in comparison with the other topics; large windows and long link contexts may contain noisy words when the crawlers are searching for narrow topics.
To investigate the influence of the learning process in more detail, we compared the Learning Agents with Non-Learning Agents methods for different topics based on the harvest rate metric in Fig. 7. As we see, the harvest rate of Learning Agents and Non-Learning Agents for various topics almost have the same characteristics as their average harvest rate curves. Non-Learning Agents curves have descending behavior, and Learning Agents curves at first go down and then start ascending or stable responses. For five topics, including First Aid, Graph Theory, Linux, Olympics, and Robotics (Fig. 7c, d, f, g and h), the Learning Agents method has a better harvest rate than Non-Learning Agents after crawling 30,000 pages. For the other three topics (Fig. 7a, b, and e), the Non-Learning Agents way has a higher harvest rate. Still, especially for Algorithms and England Football topics in Fig. 7a and b, the descending flow of Non-Learning Agents and the ascending flow of Learning Agents bring their curves closer and closer. In Fig. 7, the effect of learning in the Learning Agents method is quite evident compared to the behavior of the Non-Learning Agents method.
Table 5 shows the harvest rate of topical crawling methods after fetching 30,000 pages for eight selected topics. The Learning Agents method has the best results for five topics. The Block Text Window 20, Text Window 10, and Text Window 40 produced the highest harvest rates for the other three topics.
Performance comparison between Learning Agents method and its non-learning version based on harvest rate metric for a) Algorithms b) England Football c) First Aid d) Graph Theory e) Java f) Linux g) Olympics h) Robotics topics.
The harvest rate of topical crawling methods after fetching 30,000 pages for eight selected topics
Performance of topical crawling methods after fetching 30,000 pages
For an overall comparison, average harvest rate and target recall, and their standard deviations after crawling 30,000 pages are reported in Table 6 for different methods. This table shows that the Learning Agents method has better performance than the other compared methods based on average harvest rate and average target recall metrics. Also, the standard deviation of the harvest rate of this method is lower than the other ones, and the standard deviation of its target recall is acceptable in comparison with the others. The standard deviations in Table 6 are consistent with the reported standard errors in [9, 34].
The Non-Learning Agents method, BTW method, VIPS-based method, Text Window Method, and Best First method are ranked second to sixth, respectively, based on the harvest rate metric. The target recall metric also shows almost the same for the position of the methods. These results are almost consistent with what is reported in [6, 11].
The superiority of the Non-Learning Agents method over the BTW method indicates that it can yield better results if the method is able to combine more link context extraction methods, effectively. We can now make a clear comparison between the capability of the BTW method and the LA method. We consider the VIPS-based method as the primary method in this comparison. The VIPS-based method is one of the successful topical crawling methods [6] and has been used by both LA and BTW methods, but with two completely different approaches. According to the harvest rate criterion, the LA method is about 0.18 better than the VIPS-based method, which is about five times higher than the improvement that the BTW method does over the VIPS-based way. This is because the proposed LA method offers an entirely new approach for topical crawling, which is the ability to adapt to properties of web pages during the crawling process of the target topic, and online learning of an effective combination of many link scoring methods for that topic. The implemented version of LA in this paper, learns to combine eight link scoring criteria. The LA approach is entirely different from the procedures with predefined sensitive parameters and non-adaptive strategies, which are used by the BTW method, VIPS-based method, and any other non-learning approaches.
Results of [10] illustrate the superiority of the Best First method based on the average harvest rate over other compared methods such as semantic methods [23] (using synonym and hyponym words) and HMM methods [10, 28]. But for additional experiments, we compared the results of the topical crawlers implemented by [10] for two versions of the semantic methods and three versions of HMM methods after crawling 10,000 pages, with the results of the proposed LA method. To make a fair comparison, the pages fetched by [10] crawlers are evaluated by our implemented relevancy evaluators, and the harvest rates are re-calculated. First Aide and Robotics topics, which are shared between the LA method and [10] methods evaluation, are used for comparison.
The results are presented in Table 7. As can be seen, the average harvest rate of the LA method is higher than the other methods and its standard deviation is acceptable compared to the other methods. The harvest rate of the LA for the First Aide topic is higher than all other methods, but for the Robotics topic, the semantic method which uses synonym and hyponym similarity is at the forefront. Two issues need to be considered about these results. First, according to our experiments in the previous part, the LA has a 0.02 increase and non-learning methods have a 0.07 decrease in average harvest rate between crawling 10,000 to 30,000 pages. Since implanted methods in [10] which are compared to the LA method also do not have the capability of online learning, it is possible that in longer crawling periods, the LA may be in a higher position than the other methods. Second, the LA method has the capability to apply semantic and HMM analyzers in combination with other analyzers that it uses in its current implementation to increase its efficiency; we leave it to future research.
The harvest rate of topical crawling methods after fetching 10,000 pages for two selected topics
The harvest rate of topical crawling methods after fetching 10,000 pages for two selected topics
The cost of accessing web data is a real issue that must be considered in data mining and machine learning processes. We introduced and used online learning topical crawlers for the effective use of available bandwidth to reduce the cost of data acquisition from the web. The empirical results based on standard metrics proved the dominance of the implemented LA over the best-proposed methods in previous researches and show that the LA method has achieved the state of the art performance for topical crawling.
The Superiority of LA is due to its online learning capability that makes it able to adapt to the properties of web pages during the crawling process. So, the LA learns a model that combines a variety of scoring methods in an effective way and overcome the challenge in the combining mechanism in the previous researches. Also, the score combiner component of the learning agents by determining the degree of influence of each computed score by various analyzers and with different sizes of text windows, become able to implicitly determine the appropriate size of the window for pages of a given topic and resolved the challenge of the unclear size of the text window.
The results of this paper show, as in other areas of machine learning such as deep learning, the more distant the method is from the manual selection of features and left them to the learning algorithm, the more successful it is. The implementation of some other version of the LA method can be considered as future work. These implementations can utilize a set of different techniques as the analyzers of the agents, so we will be able to study the effectiveness of the proposed LA in combining different kinds of methods and to evaluate the influence of each of these methods in the topical crawling performance. Also, these methods can use a set of online learning analyzers. Similar to what has been done to determine the number of input layer neurons in relevancy evaluator models, a series of experiments can be performed to determine the optimal number of neurons in the hidden layer and to determine other hyperparameters of the MLP models used. Other machine learning methods can also be used to implement text analyzers and score combiner, and the impact of these methods on the performance of the topical crawlers can be evaluated.