
Abstract
With the increase of online businesses, recommendation algorithms are being researched a lot to facilitate the process of using the existing information. Such multi-criteria recommendation (MCRS) helps a lot the end-users to attain the required results of interest having different selective criteria – such as combinations of implicit and explicit interest indicators in the form of ranking or rankings on different matched dimensions. Current approaches typically use label correlation, by assuming that the label correlations are shared by all objects. In real-world tasks, however, different sources of information have different features. Recommendation systems are more effective if being used for making a recommendation using multiple criteria of decisions by using the correlation between the features and items content (content-based approach) or finding a similar user rating to get targeted results (Collaborative filtering). To combine these two filterings in the multicriteria model, we proposed a features-based fb-knn multi-criteria hybrid recommendation algorithm approach for getting the recommendation of the items by using multicriteria features of items and integrating those with the correlated items found in similar datasets. Ranks were assigned to each decision and then weights were computed for each decision by using the standard deviation of items to get the nearest result. For evaluation, we tested the proposed algorithm on different datasets having multiple features of information. The results demonstrate that proposed fb-knn is efficient in different types of datasets.
Introduction
Decision making in life is much important, but most important is making the right decision after gaining some particular information about that item. Recommendation system’s in these days are playing a vital role in changing the decision ability of users by giving them appropriate correct information by utilizing the historical or correlated data. The latest technologies are making as more powerful in making a good decision in less time. For example, if anyone visits a particular place, there are so many choices for selection but those are not according to the taste of that user, thus it wastes a lot of time to have a correct decision. On the other side, having too much information about different places also affects decision-making criteria. To overcome this problem, modern recommendation systems are playing a vital role in improving decision making by giving the decision according to the taste of users. Different online product websites are now online and providing a recommendation to users according to their tastes [9]. Recommendation systems are of basically three types namely Content, Collaborative and Hybrid. But this paper is far behind the concepts of those recommendation ideas as these approaches are using the single criteria decision-making methods and it’s not a simple combination of algorithms to make it multicriteria. A lot of the methods are already developed for improving the recommendation system as artificial intelligence research is growing, such as the neural networks, SVM, knn, kmeans, and logistic regression methods, which resolves these classification issues very satisfying level. Researchers have tried to extend the machine learning algorithm kNN theory to deal with the multi-criteria classification issue. To improve multi-criteria recommendation performance deep learning and AI can help together to improve using feature-based data extraction [13, 30]. AI enables specialists and other restorative experts to perform a more exact and speedier analysis. For drugs, AI utilizes scientific calculations and information science from the human body to influence analyses, which are superior to anything specialists can do. This enables experts to take prompt activities for maladies that may end up being very serious [2].
Recommender systems (RSs) are tools that are generally being used to foresee user needs and suggest helpful things that may attract them [29]. As the rate of online buying services is increasing day by day the size of a dataset of online services is also increasing thus, it demands auto recommendation of user preferences from the already existing record. These kind of RSs are usually helpful for the user as they can provide the user decisions of their choice based on historical records, this may be helpful in reducing the time for selection of the item.
Content based vs collaborative filtering.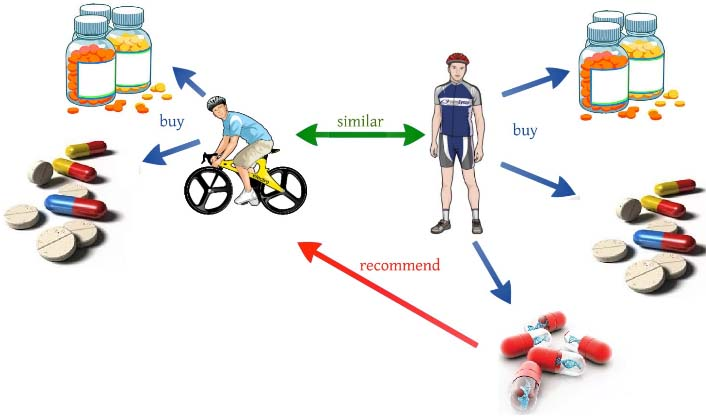
Recommendation systems (as shown in Fig. 1) are the best effective tools that help in decision making with more relevant data. So, based on the choices of the user’s different types of recommendation techniques have been proposed that can improve this decision making. Therefore, to get better use of the proposal approach different recommendation methods have been developed with the goal that patients can get the most important data to the greatest degree. Recommendation systems approaches have been extensively isolated into three classifications to be content-based, collaborative filtering and hybrid filtering based approach.
Collaborative recommendation system (CF): is the most successful way in the current recommendation system; for example: If the user’s ratings for some products are similar, then the nearest product having high similar rating is recommended. The traditional collaborative filtering recommendation technology is mainly through finding and target users which are interested in similar users, and according to their favorite products, favorite to targeted users list of products are predicted and recommendations are generated. For example, for a user of a movie website recommend a movie, first look for the user group that loves the same movie as the target user, ie the most Near-neighbor set; then, the movie that the neighbor user likes and the target user is unknown.
The advantages of the collaborative filtering algorithm are:
No need to consider new content for the recommendation, by use of existing features can provide an appropriate decision; the ability to recommend new content, you can find that the content is not the same similar tasks of potential interest in the preferences of users; technically easy to implement.
Based on this, collaborative filtering technology is currently the most popular recommendation technology. However, the user feedback information matrix is sparse, that is, most user tags are very few in each search of user selection, resulting in inaccurate traditional similarity calculation methods, difficult to obtain a better effect.
The recommended method is recommended to the target user, uses the historical data of the same users, and provides the decision based on the past selection of the same user and had an assumption that users’ taste of selection remain the same. So for example, if patient X and patient Y have a medication history that overlaps strongly and patient X has recently bought an item that Y has not yet been, the basic rationale is to propose this item also to Y. Let
Content recommendation system (CB): focus on the content of the data which were rated by similar patients. Those items that are most similar to the positively rated ones and the one which is positively rated by the patients are recommended to the patients. Let U and I be a set of patients and items and RatedItem
Hybrid based recommendation system: when we combine both the approaches i.e, content-based as well as collaborative approach an improved recommendation system can be utilized in making the decision more accurate. Hybrid recommendation helps in solving the problems like Cold start and delay the inaccurate decision.
If we focus on mono criteria ranking, as shown in Fig. 2, total ranking from users can be shown in the form of a matrix having rows and columns. It elaborates the classification of the ranking of user’s selection u based on items p have been ranked or null if not ranked.
The classical CF technique is using the technique of the mono criteria basically as it considers only the one featured of the user’s choice and based on that features in provides the decision. Table 1 more clearly explains the idea of the mono criteria ranking in which user preferences with a ranking are shown for each item.
Example of mono-criteria ratings
Matrix showing users and items (
RSs have established a case of machine learning applications. However, these techniques are yet to be used in the different business sectors like healthcare, medicine, pharmaceutical industries, etc. One of the main reasons for not utilizing these systems in those businesses is because of privacy and the security of information – secondly the complexity of the diseases in terms of availability of required information of data of that disease. To resolve that approach similarity-based approach is applicable after keeping the doctor in the loop for evaluation of the results and verification of health records between the suggested as well as the predicted value.
Weighted cosine similarity as mentioned in (Eq. (3)) is used in our paper for getting the similarity because by using the similarity approach we can get preferences of our required items by used category – and will remain focused on category of dataset characteristics (e.g., as its most important if working for health domain).
Where
The next step is the creating of the list of items with the weighted ranked items of similar patients, the created ordered list of those selected items is Usimilar. Items having more weight are on the top of the list while items having less weighted ranked are in the last of the queue of the list by Eq. (4).
Where the set of
Transformed item scores (both collaborative and content) used in the calculation are based on the item’s position in the patient’s lists, as shown in Eq. (6):
The final output of the hybrid recommendation is a list of recommended users ordered by calculated hybrid score (list contains all collaborative candidates, ordered by their importance in the CB method). Finally, top-N items with the highest scores are recommended. The N has to be chosen with respect to the specific domain. This research work is focused on building a multi-criteria recommendation system with risk factor prediction for assisting in feature analysis of datasets more effectively and efficiently.
Predictive modeling is a standout among the most prominent and critical strategies that are utilized in clinical and medicinal services today and has been effectively connected to various causes, including the early identification of illness and, of greater note, individualization of care [27]. A virtual study of several global, local and personalized modeling approaches applied to several bioinformatics classification tasks is presented in [6, 25, 26].
The main contributions of our paper are:
It provides improved performance of MCRS based on the selection of weights obtained from content-based and collaborative approaches. It can be used in any type of industry like the movie, medical, travel, etc. Our proposed model incorporates the user features data, demographics, and users’ N-dimensional information. In multidimensional feature space and subspace weight-based clustering methodology produces satisfactory results of clusters as compared to simple-means used in many RSs.
We chose eye hospital dataset with diseases cataract and pseudophakia surgeries as a model in this paper because of the high number of cases for this disease, and we aimed to test our results on a larger and more accurate dataset [7, 8]. Beside eye hospital dataset we have used more different types of the dataset to validate results on different industries.
Multi-criteria recommendation system (MCRS) for selecting a particular recommendation.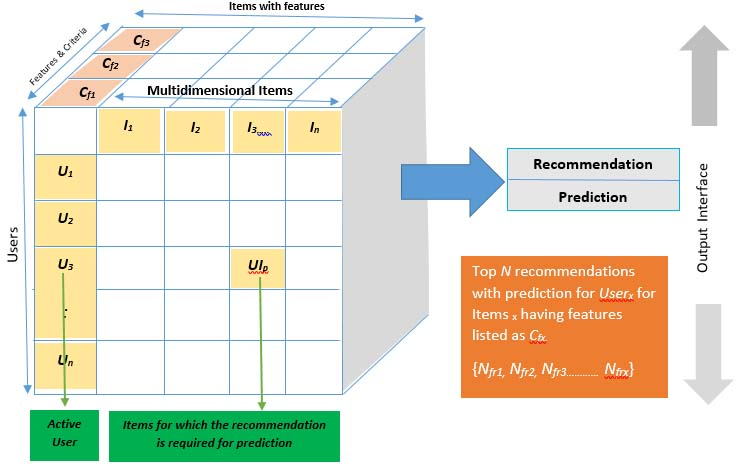
Collaborative filtering often corresponds with the use of the rating functions R and elaborates the relation with different users and items as;
This section mainly focuses on elaborating in detail the different multi-criteria recommendation methodologies, starting with the Multi-Criteria Decision Analysis field, followed by multi-criteria RSs, and then presenting the detailed implementation of our strategy.
Called also Multi-Criteria Decision Analysis (MCDA) [21] is a discipline, refers to decisions that require consideration of two or more goals simultaneously. If an enterprise wants to choose one of several products for production, it must consider the profitability, and consider whether the existing equipment can be produced and whether the raw material supply is sufficient, etc., and only choose one of them. The best coordination, coordination, and satisfaction of the factors that are mutually constrained are the optimal decisions. Decision making is mainly based on the weights of the choices (attributes) which play a very significant role [18, 19]. So, answering the question “How to determine the weights of attributes?” is very crucial in this field of research”.
To improve the process of multi-criteria recommendation, many methods exist in the MCDA literature for the determination of attributes’ weights (Fig. 3). The method, on which this research is focused, is an objective weight determination method, which is referred to as Correlation Coefficient (CC) and Standard Deviation (SD) integrated approach for determining the weights of attributes, to provide decision supports to MADM problems. The weighted summation method quantifies each index, determines the relative importance of each index, assigns weights, and then weights and sums the quantized values of all indicators to determine the optimal solution. If the indicator is not properly selected, the use of a weighted summation method can also lead to decision bias. For example, in terms of solving the problem of parking space allocation in high-rise apartment parking lots, it seems that a weighted analysis method can be adapted according to the idealized decision-making method so that the walking distance of each apartment occupant to the own parking space is minimized as a decision target.
In real terms is the use of multi-attribute decision has some decision-making information a certain way for a group of (finite) alternatives into line ordering or merit. It consists mainly of two parts:
Obtain decision information: Which includes two aspects: weights of attribute and values of the attribute (property values There are three main forms: a real number, interval number, and language). The decision information is aggregated in a certain way and the scheme is sorted and selected.
Thus, we selected the decision of working with multi-criteria recommender frameworks. In the next part, we explain the rules and settings of working with these systems.
The most commonly used technique in the modern recommendation system is utilizing the
where
For example, in the hospital doctor recommendation, instead of ranking the doctor by giving a single global rating, its more beneficial to give the ranking based on the selection of different features of a doctor like a specialty, experience, qualification, etc. In mono criteria ranking the user, function R is calculated based on just a single attribute feature. While in the multi-criteria ranking, the datasets usually contain the detailed matrix of all the features related to the particular user items.
Multi-criteria ratings with Users * Items
Multi-criteria ratings with Users * Items
If we compare Table 2 with Table 1, we notice that the only difference is the users have more choice of selection in Table 2. Thus the decision is evaluated by the selection of all choices of each item. All the items are valued according to four ranking criteria, and the results of the recommendation are obtained by taking the average of all decisions [12]. But in mono criteria rating, the decision is not as accurate as other useful information is hidden in other features which can help improve the recommendation accuracy. On the contrary of multi-criteria RSs, utilizing all the features of the information helps identify the correct ranked item (in this case doctor). Thus multi-criteria recommendation helps find the accurate connection between the users and the items.
In [3] author proposed the combination of a similarity-based approach with the aggregation function. In the first approach, the likeness among the user’s choices is resolved by finding dependent variables on their historical rating conduct, for example, the Pearson relationship coefficient. The distinctive possible nearest matching technique was used to quantify the actual likeness between users dependent on their itemized appraisals. Thus, the basic difference in monocriteria versus similarity-based multi-criteria ranking is the impact of using different comparability matric use. In composite methods of recommendation system, there are different methods of exploring the weights with the ranks of each item and give priority to the items having more weights and ranks. But that technique is still lack of making an efficient recommendation as its needs to compare features and assign each features a different number of ranks and weights so that each item in the recommendation have ranks and weights with the highest number of matched features ranks and weights. Technically, the overall rating
Overall, we are focused on two things in this paper the first one is weighted ranking and the second is the deviation of features from the standard recommendations. Most of the cases the recommendation results are not accurate as per prediction because of the sparsity of datasets and which requires time to be intelligent. The reason for selecting those criteria in the multidimensional recommendation is to avoid sparse dataset problems by utilizing more information in a few samples of datasets. Multi-objective decision refers to the need to consider the decision of two or more goals. If you want to choose one of several items for evaluation, you should consider the profitability, and consider whether the existing equipment can be produced and whether the raw data is sufficient. The best coordination, coordination, and satisfaction of the factors that are mutually constrained are the optimal decisions.
We have utilized the same above approach [8] in our paper but used the deviation approach to improve selection and recommendation more appropriate with results. Lets m decision alternatives
The overall assessed value of each item is computed as follows
The bigger the overall assessment value, the better the decision alternative. The best item is the one with the biggest overall assessed value. By removing criteria
The coefficient correlation (CC) among different values of the
By using the above similarity rating the weights can be calculated as
Where the SD is calculated by:
Detail description of different datasets
Steps of proposed algorithms are mentioned with using Knn for feature selection.
We train a ranking model to figure out which neighbor’s list of features in the dataset will be in general nearer to the genuine list of features. The workflow of the training the modules is shown in Fig. 4, and the above algorithm provides the pseudocode of the complete process. The set of
Algorithm implementation workflow.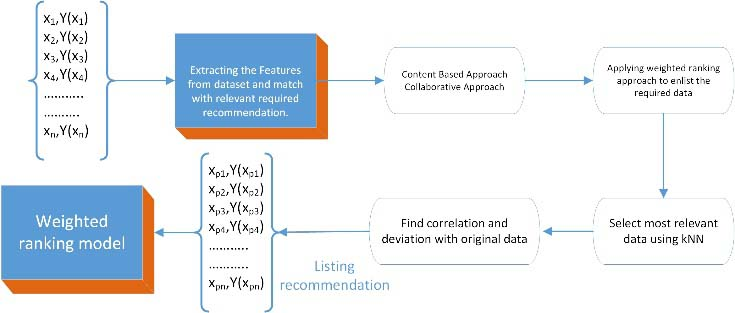
For the accuracy and integrity of the results of our multi-dimensional methodology, we used datasets of different business sectors and validation steps of results are also mentioned in the next section of this paper. A short description of features of each dataset is as follow:
TripAdvisor dataset [14]: The dataset contains around 180,609 ratings of different hotels provide by many users. The dataset has been taken from the www.tripadvisor.com. The sparsity of the dataset is 99.9432%. There are 7 criteria for ranking the hotel: Value rating, Room rating, Location rating, Hygiene ranking, Check-in/front desk ranking, Facility ranking, Commercial service ranking, and an Overall ranking. The scale of the ranking is set from 1 to 5 while a value of Yahoo! Movies Dataset [4]: It contains the movies, ranking, and the viewers of the movie ranking. However, some of the rankings are missing in the dataset. Missing records of data are removed to get a more accurate decision. The multidimensional dataset contains movie all features which make it specific according to the selection of the users. Hospital Dataset: This dataset is from the hospital of Pakistan working in the urban area and providing services to patients from around 10 years. The name of the hospital is JA Hospital from Punjab province, having computerized health records of 176,084 unique patients from different cities with demographic details, therapeutic prescription historical data, drug, and laboratory test examinations results, diagnosis, and surgical treatment records, follow-up visits of hospitals and biological results. Total records are from 6 years i.e, from 2012 to 2017. The dataset includes patients having different diseases of the eye in different categories (error of refraction (30372), cataract (11506), allergic conjunctivitis (6581), pseudophakia (PCL) (5194), blepharitis (2226), pterygium (2202), glaucoma (2058), allergy (1562), etc.). We mainly focused on cataract and pseudophakia because they are common, because the total number of patients with these particular diseases is higher than that of other diseases, and because a larger number of cases will lead to better analysis, as shown in Fig. 5.
Experimental results: Hamming loss
Showing eye diseases datase.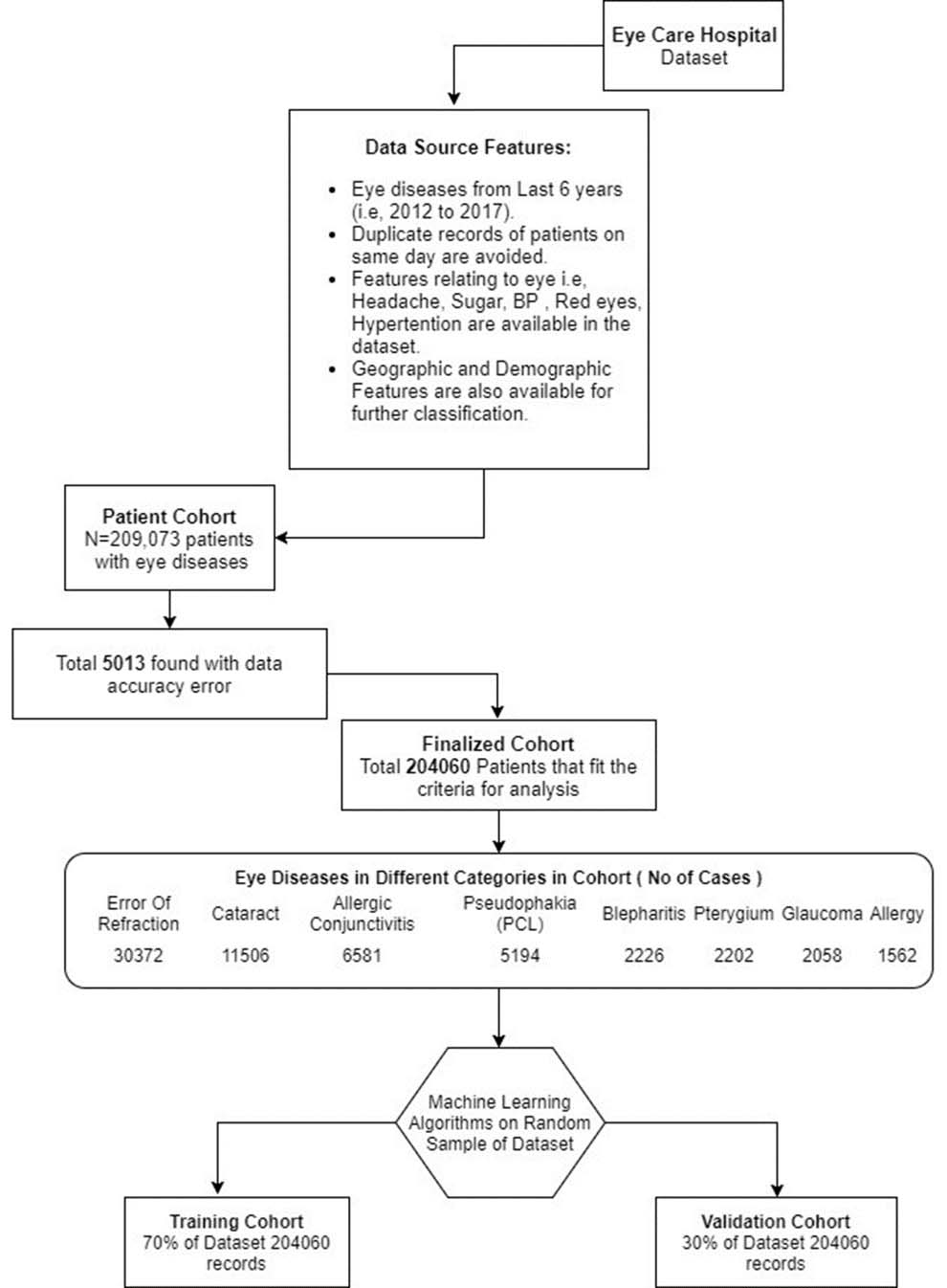
Experimental results: Average precision
Experimental results: One error
The yeast data set is used to predict the functional gene classes of the Yeast Saccharomyces cerevisiae [1, 28]. The features of the data set corresponding to the microarray expression data and phylogenetic profiles of the genes. The scene informational index is utilized to predict the semantics of the scenes in the photos [22]. MajorMinor’s system [17] of music labeling was used to get the data of music audio records of different beats and scenarios of the data.
The characteristics of each feature in our data labels were captioned as dynamics, beat, resonance, pitch, and tone.
Remote experiments of data, as well as feature extraction of different datasets, were done by using the R software. The reason for using the R software is flexibility in terms of development as well as the availability of libraries to include in datasets easily. It has different packages that we utilized to improve our performance and were downloaded from https://cran.r-project.org/, including machine learning algorithms libraries like gbm and caret for other operations. We also used the library H2O for neural network result fetching in machine learning. A
Experimental results: RMSE
(weight rank):
implies the larger(smaller), the better
Experimental results: RMSE
Recommendation system accuracy can be measured with different validation criteria but in our research use commonly used validation methods to test our proposed algorithm, which is as follows:
Rating prediction accuracy: This paper uses Mean Absolute Error (MAE) as the evaluation criteria for the quality of the recommendation system. MAE intuitively predicts measuring quality and it’s the most common method. MAE calculates the predicted accuracy of the prediction between the user score and the actual score; the more MAE small, the higher the prediction quality. Mean absolute error (MAE) in Eqs (11) and (12) as well as Eq. (8) were used to measure rating prediction accuracy, where
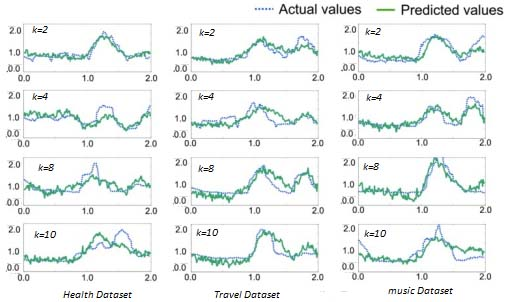
Actual vs predicted value comparison of fb-knn. Usage prediction: A Precision helps measure the closeness of the different rankings of the data with each sample. A Recall, which is defined in a standard way by [11] as a “percentage of the relevant items selected out of the corresponding item in the dataset (Eqs (13) and (14)). F-measure, which served as a harmonic mean of the precision and recall (Eq. (15)), which are the most useful measures of interest for some number of recommendations were used in measuring usage predictions”. In Equations (13) and (14), the #tp shows the total true positive values from all the data, thus indicates the total essential recommendations. The #fn stands for the number of valuable likelihoods that are not among the top-N recommendation list, and #fp represents the false positive values means the recommendations which are not useful in the decision making the process.
Multi-Label K-Nearest Neighbors algorithm (MLKNN)
Identifies its KNNs (Crocco et al.) using Euclidean metric is used to measure distances between instances.
Instance-Based Logistic Regression (IBLR)
Classification algorithm for multi-labels dataset [31] which are instance-based learning.
Slope one
A collaborative filtering algorithm [5, 16] useful for the comparison with the similarity algorithms and have better performance.
RAndom k-labELsets (RAKEL)
RAKEL [10, 24] has the ability to select random subsets of datasets and have good results in audio and medical datasets, however, results in other datasets are not satisfactory. Item-Based Collaborative Filtering (IBCF):
A collaborative filtering algorithm that was considered to provide a high prediction accuracy than other similarity-based recommendation techniques.
Item Based Collaborative Filtering (IBCF)
It is used to find the target user in the class to which the user belongs. Neighbor items provide the best weights to combine the results to produce recommendations. The algorithm overcomes the sparsity problem by utilizing the potential relationship between users and commodities while retaining the advantages of off-line modeling and scalability.
User Based Collaborative Filtering (UBCF)
It helps in finding the user’s choice of selection based on the nearest same user preferences.
Perceptron with Margins (PM)
The algorithm is used for recommendation after learning the weights of the data source.
We also compared our proposed algorithm with the popular instance-based learning approaches: MLKNN and IBLR, which are the well-known algorithms for label classification.
The K value is set to different levels between 2 and 10 on different datasets and uses the Euclidean metric as the distance function as shown in Fig. 6. On different datasets, the performance of the prediction of results is almost the same as the actual values. Both actual and predicted lines are overlapping each other to show the accuracy of our desired results. We used single criteria but item based as well as user-based algorithm i.e., IBCF and UBCF to elaborate on the effectiveness of the MCRS with them. While Fig. 7 gives a comparison of the performance of different algorithms with the proposed methodology.
We have used the algorithm, RAKEL, which is usually used to solve the multi-label problem when multiple labels are assigned to each instance. Although RAKEL is not an object-based multiple label learning method which solves the classification problem of the labels for instances. In our proposed framework, we have tried several ranking algorithms: Passive-Aggressive Perceptron (PA). We have performed the multiple data repetition to get the more accuracy of the relevant data, but, we selected randomly 20% data of the training set each time and use them for optimizing the result using the above algorithms. To have more accuracy in results the same datasets were used for the training and testing sets, hence all the methods have the same neighbors in kNN.
Comparison with existing methods
Comparison with existing methods
Comparison of the proposed algorithm on a different sample size of data.
So the accuracy of results is more validated by using the same dataset with the same no of neighbors and it’s easy to trace out which algorithm is performing better after using the KNN-based method approach. The experiment results are shown in Tables 3–6. The numbers in parentheses represent the rank of the algorithms among the compared algorithms. The number in the parenthesis shows the weighted level obtained after the execution of the results. Results show that the proposed algorithm fbknn performed better on different instances of the data. However, ML knn is also the second-best algorithm executing better in a different dataset. One possible reason for the poor results of IBCF and UBCF may be due to the simple criteria function realized by this method.
Table 8 elaborates on the comparison of existing approaches proposed by different papers and proofs that our proposed method is a way step forward as compared to other approaches because of its combination with content as well as collaborative approach.
A novel algorithm is proposed which is best for all business areas and useful for enterprises to adopt for making accurate recommendations by using weighted recommendation with KNN. We also compared the results with different single criteria, MCDM, Multi-label, and machine learning algorithm. Our results showed that features based weighted extraction of proposed recommendation algorithms perform better in different datasets. First, we observe an interesting feature from the data, then combine existing approaches to a hybrid weighted algorithm using k nearest neighbors. It is also possible to use another ranked based learner or search technique based on the characteristics of the dataset. Our primary focus in this was to predict the factor having more or less impact on data by doing that the mistakes of data analysis can also be reduced thus the performance of the hospital will increase.
Footnotes
Author contributions
Data curation, Zeeshan Zeeshan, Qurat ul Ain, Uzair Aslam Bhatti, Waqar Hussain Memon, Sajid Ali and Saqib Ali Nawaz; Formal analysis, Mir Muhammad Nizamani, Anum Mehmood, Mughair Aslam Bhatti, Muhammad Usman Shoukat; Investigation, Zeeshan Zeeshan, Qurat ul Ain, Uzair Aslam Bhatti, Waqar Hussain Memon, Sajid Ali, Saqib Ali Nawaz; Project administration, Zeeshan Zeeshan, Qurat ul Ain, Uzair Aslam Bhatti, Waqar Hussain Memon, Sajid Ali, Saqib Ali Nawaz, Mir Muhammad Nizamani, Anum Mehmood; Writing – original draft, Waqar Hussain Memon, Sajid Ali, Saqib Ali Nawaz, Mir Muhammad Nizamani, Anum Mehmood, Mughair Aslam Bhatti, Muhammad Usman Shoukat.