
Abstract
The development of graph neural networks (GCN) makes it possible to learn structural features from evolving complex networks. Even though a wide range of realistic networks are directed ones, few existing works investigated the properties of directed and temporal networks. In this paper, we address the problem of temporal link prediction in directed networks and propose a deep learning model based on GCN and self-attention mechanism, namely TSAM. The proposed model adopts an autoencoder architecture, which utilizes graph attentional layers to capture the structural feature of neighborhood nodes, as well as a set of graph convolutional layers to capture motif features. A graph recurrent unit layer with self-attention is utilized to learn temporal variations in the snapshot sequence. We run comparative experiments on four realistic networks to validate the effectiveness of TSAM. Experimental results show that TSAM outperforms most benchmarks under two evaluation metrics.
Keywords
Introduction
Complex systems in real world can be naturally described with complex networks, where nodes represent entities and links represent the interactions between them. Complex networks are highly dynamic objects whose topology evolves quick over time with the appearance of new interactions [17]. Predicting the dynamics of complex networks is a meaningful and promising problem. For example, in data center networks, the prediction of network topology can guide the design of routing protocols to improve the efficiency [19]. In online social networks such as Twitter and Sina Weibo, the prediction of people’s interactions can help infer the potential friends and recommend them to users, increasing their loyalty to the platform in return [22]. In most literatures, such task is referred to as temporal link prediction, the goal of which is to predict future topology of evolving networks based on historic network information. Generally, temporal link prediction is more challenging than link prediction in static networks, because it requires to capture not only the structural feature of but also the temporal evolution [30].
A number of methods have been proposed to solve the temporal link prediction problem in the last two decades. Most existing works compact the historic network structures into one single network, and use methods in static networks to predict future links. Similarity-based temporal link prediction methods are the simplest and most efficient ones, which assume nodes with higher similarity will form links in the future [21]. Such methods include Common Neighbors [16], Jaccard [10], Adamic-Adar [1], Resource allocation [37], Katz [13], etc. [22]. Even though these methods are efficient, they only take into account the structural feature of previous moment, regardless of informative temporal features such as the evolving pattern. Recently, the development of machine learning and graph neural network (GNN) makes it possible to build learning models for non-Euclidean data including complex networks [15]. Taking advantage of GNN, many works focus on solving temporal link prediction problem with machine learning models which learn both structural and temporal feature at the same time. These works mainly fall into two categories. The first kind of methods use dynamic graph representation learning to learn latent representations of nodes in temporal networks, and train a downstream logistic regression classifier for link prediction. Representative works of this kind of methods include DySAT [27], dyngraph2vec [6], DynamicTriad [36], etc. The other kind of methods reconstruct the predicted network through an autoencoder architecture, such as GCNGAN [19], GCLSTM [4], etc. Even though the latter one is more complicated with more parameters to train, it usually performs better in the task of temporal link prediction.
In reality, plenty of realist networks are directed in which link orientations have specified meanings. The prediction of link orientations are equally important with connectivity [28]. For example, in email networks, a directed link represents an outgoing email from one to another. If only the existence of a link is predicted, it would lead to ambiguity because one cannot decide the source and target of this email. Directed networks are quite different from undirected ones in topological properties, making temporal link prediction for directed networks a complicated and challenging problem. Since most existing works idealize their subjects into undirected networks, few works have investigated this problem thoroughly.
In this paper, we address the problem of predicting temporal links in directed networks. Our main contributions can be summarized as follows:
We design a model for link prediction in directed and temporal networks, namely TSAM. The model utilizes graph attentional layers to capture structural features of each snapshot. It also leverages matrix transformation to mine additional structural feature from local network structure. To capture the temporal features efficiently and overcome the long term dependency of evolving structure, we use graph recurrent units with self-attention mechanism to learn from a sequence of snapshots and predict future snapshots. Both node-level self-attention and time-level self-attention mechanisms are adopted in our model to accelerate the learning process and improve the prediction performance. We use comparative experiments on realistic networks to validate the effectiveness of our model.
The remainder of this paper is organized as follows: Section 2 introduces several related works. Section 3 describes the aiming problem of this paper. Section 4 presents the proposed method. Section 5 describes experimental setups and analyzes the results. Finally, Section 6 draws conclusion of the paper.
Temporal link prediction
Temporal networks are usually described in two ways: snapshot sequence which is a set of evolving snapshots at discrete time, and timestamped graph which is a graph with timestamped links. In this paper we adopt the first description.
Zhou et al. [36] leverage the concept of triadic closure as guidance to capture the evolving pattern across different snapshots. Goyal et al. [7] proposed DynGEM based on depth autoencoder to incrementally update node embeddings through initialization from the previous step. These methods cannot capture the dynamics among a long period of time, which leads to limit on accuracy. Since recurrent neural network (RNN) and its variations are powerful tools to capture temporal dynamics of input sequences, they are adopted in many temporal link prediction methods. Chen et al. [4] proposed GC-LSTM which uses graph convolutional network (GCN) embedded long short term memory network (LSTM) to predict temporal links. Instead of learning structural and temporal feature separately, Pareja et al. [26] use the RNN to evolve the GNN so that the dynamic features are captured in the evolving network parameters. Nevertheless, these recurrent methods are inefficient in capturing the most relevant historical snapshots because they treat the effect of each snapshot equally. In our proposed TSAM model, we utilize self-attention mechanism to differentiate the influence of snapshots.
On the other hand, some works have studied the problem of link prediction in directed and temporal networks. Jawed et al. [11] addressed time frame based link prediction problem in directed citation networks and proposed time frame-based score. Bütün et al. [3] designed a measure by extending neighbor based measures as directional pattern based ones to consider the role of link directions.
Graph neural network
Graph convolution is a key technique to perform machine learning on non-Euclidean data structure such as complex networks. It generalizes the standard definition of convolution over a regular grid topology to graph structure. Graph aggregators are basic building blocks of graph convolution methods. Most existing works on graph aggregators are based on either pooling over neighborhoods or the weighted sum of neighboring features. Typically, graph convolutions can be categorized into two types: spectral domain convolution and spacial domain convolution. The classic GCN designed by Kipf et al. [15] employs spectral domain convolution by leveraging the decomposition of Laplace matrix. Since the Laplace matrix should be symmetric to perform decomposition, GCN cannot deal with directed networks whose adjacency matrices are asymmetric. Hamilton et al. [9] extended graph convolutional methods through trainable neighbor aggregation functions, and proposed a spacial domain convolution method named GraphSAGE. Since GraphSAGE does not use decomposition of Laplace matrix, it can deal with directed networks. Other efforts have also been done to learn representations of directed networks, such as motif2vec [5], DIAGRAM [14], ATP [29], MotifNet [23], etc.
Self-attention mechanism
Neural attention networks use a subnetwork to compute the correlation weight of the elements in a set. Among the family of attention models, the multi-head attention model proves to be effective for machine translation tasks. Later it has been adopted as a graph aggregator to solve the node classification problem [32] and static link prediction problem [8], referred to as graph attention network (GAT). Each attention head sums the elements that are similar to the query vector in one representation subspace, which provides more modeling power naturally. Zhang et al. [35] further proposed gated attention networks (GaAN) which treats the effect of different attention head unequally. Leveraging self-attention mechanism, Sankar et al. [27] proposed the DySAT to learn representation of temporal networks. Our work differs from theirs in two aspects: 1) On structural level, our TSAM model target directed networks and leverage additional structural features through matrix transformation and feature fusion, while DySAT aims at undirected networks. 2) On temporal level, TSAM adopts gated recurrent unit (GRU) layer and self-attention layer to capture temporal features, while DySAT only uses self-attention layer which cannot distinguish between different positions of the input.
Problem description
A directed and temporal network can be described with a sequence of network snapshots
Given the adjacency matrices during
The goal of our model is to learn function
We propose a temporal link prediction model based on self-attention mechanism, referred to as TSAM. The basic architecture of TSAM model is an autoencoder as shown in Fig. 1. First, the temporal encoder consisted of graph convolutional layers, graph attention layers and GRU layers draws both the structure-related and time-related features from the input snapshots, generating node embedding of the last time step. Then the decoder utilizes full-connected layers to interpret the embedding to the predicted adjacency matrix. Here we introduce the main parts of TSAM model separately.
Overall architecture of the proposed TSAM model. 
For each snapshot at time step
where
The calculated attention coefficient
We follow [32] to perform the multi-head attention mechanism which can stabilize the learning process of self-attention.
where
In order to leverage more structural information of directed networks, we generate a set of transformed adjacency matrices using the simplest matrix operations. In detail, at each time step
There are multiple choices of mapping functions. Here we list four simplest forms as:
The meaning of these four transformed adjacency matrices can be interpreted with network motifs [2]. Take two simple networks shown in Fig. 2 as example. In Fig. 2a, operation
In Fig. 2b, operation
Obviously, operation
Example of matrix transformation in directed networks. 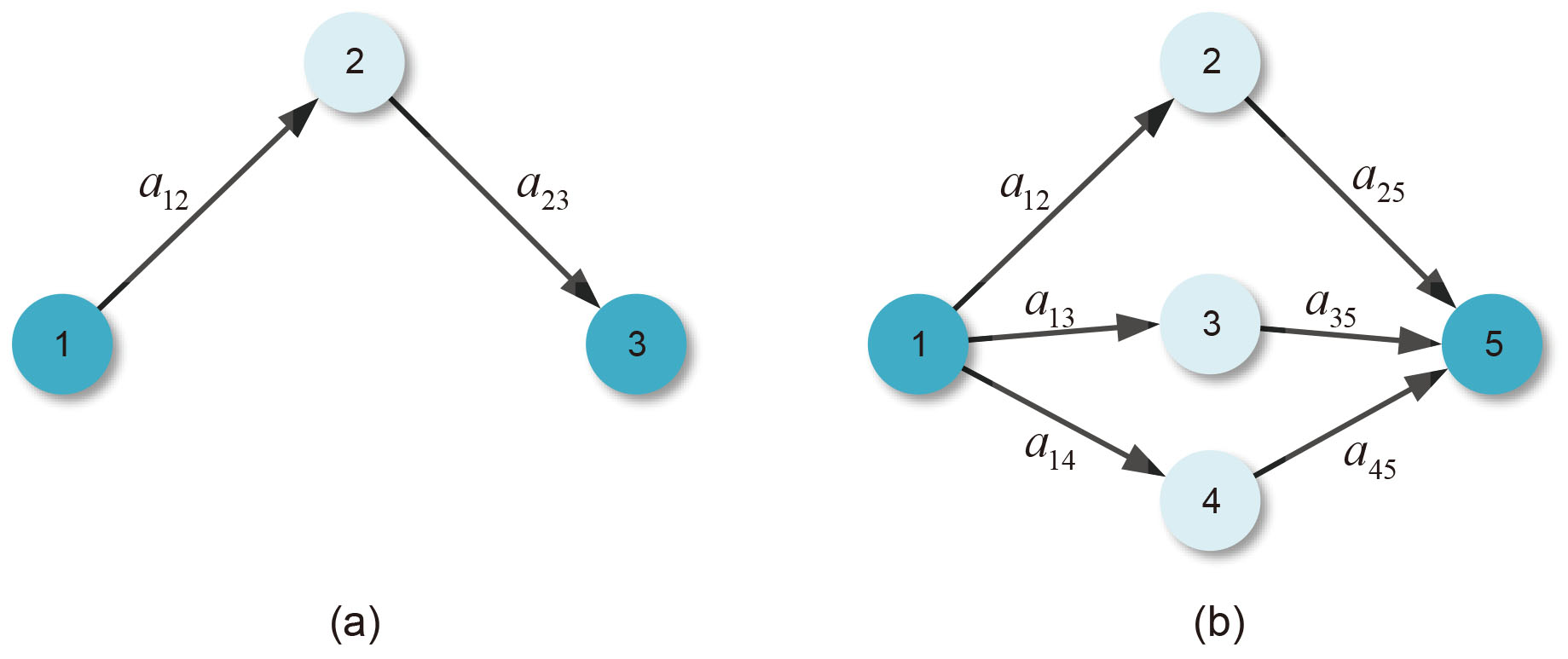
We use a set of graph convolutional layers (GCL) to exact structural features and generate corresponding embeddings from the transformed adjacency matrices. For each transformed adjacency matrix
where
The extracted features from GAT layer and the set of GCLs captures different structural properties of the input network
where
Diagram of feature generation in each snapshot. 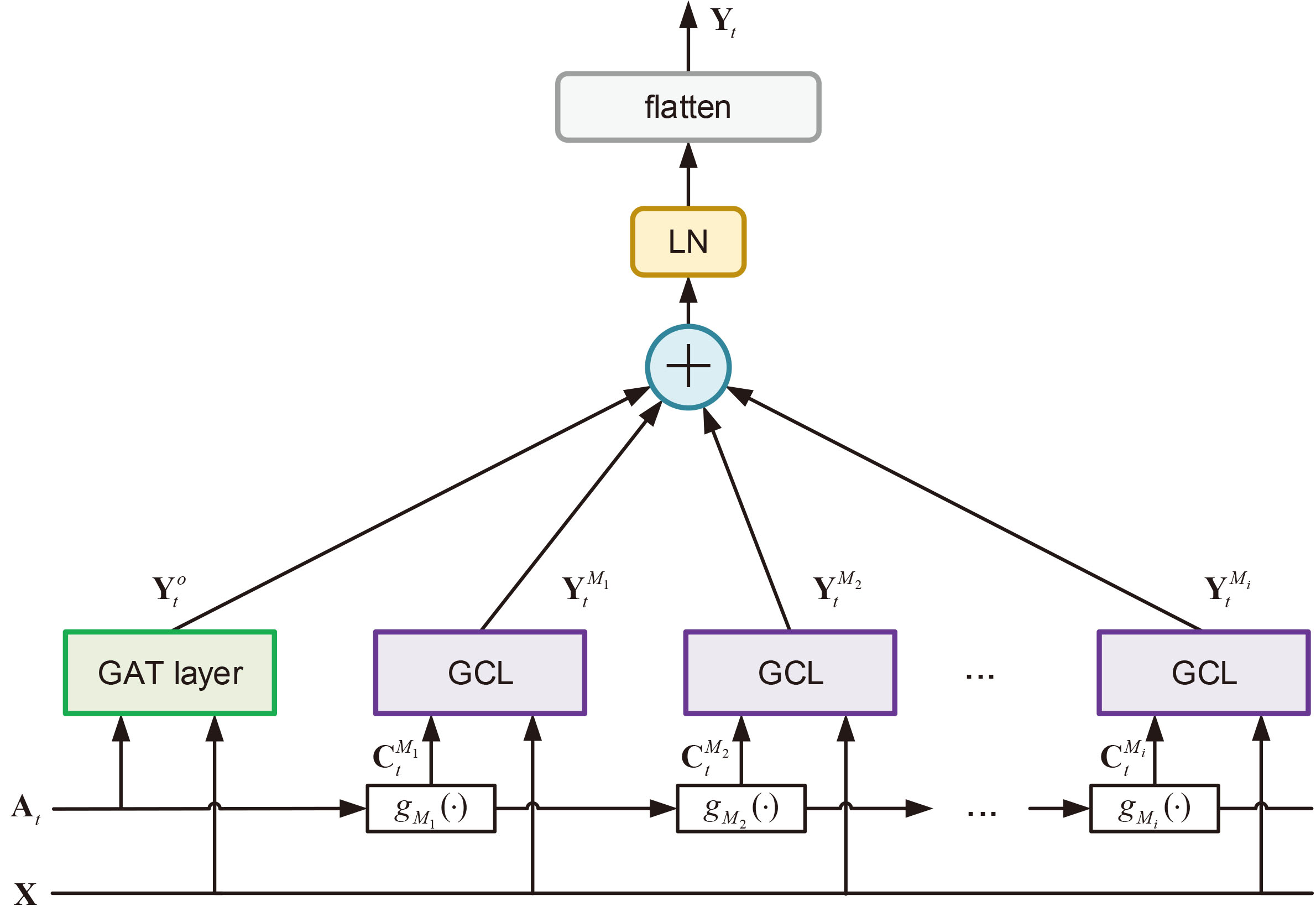
To capture the temporal variations of network structure through multiple time steps, we feed the sequence of row-wise vectors into a time-level attention block. The time-level attention block consists of two layers: a nonlinear RNN layer and a temporal self-attention layer.
Recurrent neural networks has flexible nonlinear transformation ability on time-series inputs, while the attention mechanism has limited representational power for it uses weighted sum to generate output vectors. To increase the expressive power on time-level, the row-wise vector sequence
where
Afterwards, the hidden states of GRU layer are fed into a temporal self-attention layer to differentiate their influences on each other. In detail, we take the hidden state vector at time step
where
where
is the softmax function, and
is the attention coefficient matrix, with
where
Diagram of temporal self-attention layer. 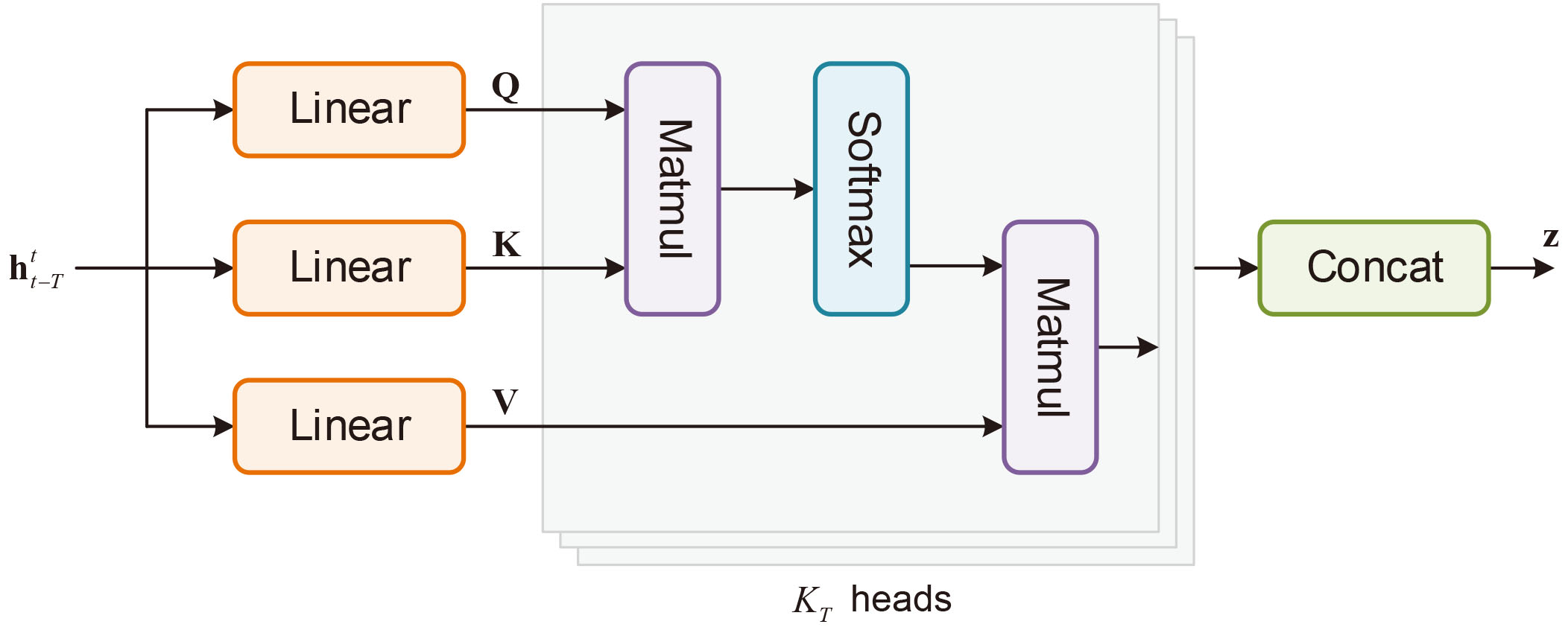
In this case, the shape of
In order to predict the network at time
where
Since our goal is to predict links in
where
Datasets
We use four temporal directed networks from real world to evaluate the performance of TSAM model, including two Email networks, a social network and an interaction network. Basic statistics of the four datasets are presented in Table 1, and a brief introduction of them is described as follows.
Summary statistics of four temporal networks
Summary statistics of four temporal networks
Manufacturing emails (MAN) [18]: An email network between employees of a mid-sized manufacturing company. The network is directed and nodes represent employees. The left node represents the sender and the right node represents the recipient. A directed link Email-Eu-core-temporal (EEC) [25]: An email network generated from the email data in a large European research institution. A directed link UC Irvine messages (UCI) [24]: A network consisted of private messages sent on an online social network at the University of California, Irvine. A directed link LevantMonths (LEM) [20]: An interaction network collected by the Kansas Event Data System based on folders containing WEIS-coded events within eight countries: Egypt, Israel, Jordan, Lebanon, Palestinians, Syria, USA, and Russia. The dataset contains interactions from April 1979 to June 2004. Each snapshot contains links occurred in 6 months, and 50 snapshots are constructed in total, as shown in Fig. 5d.
Histogram of link numbers for each snapshot in four networks. 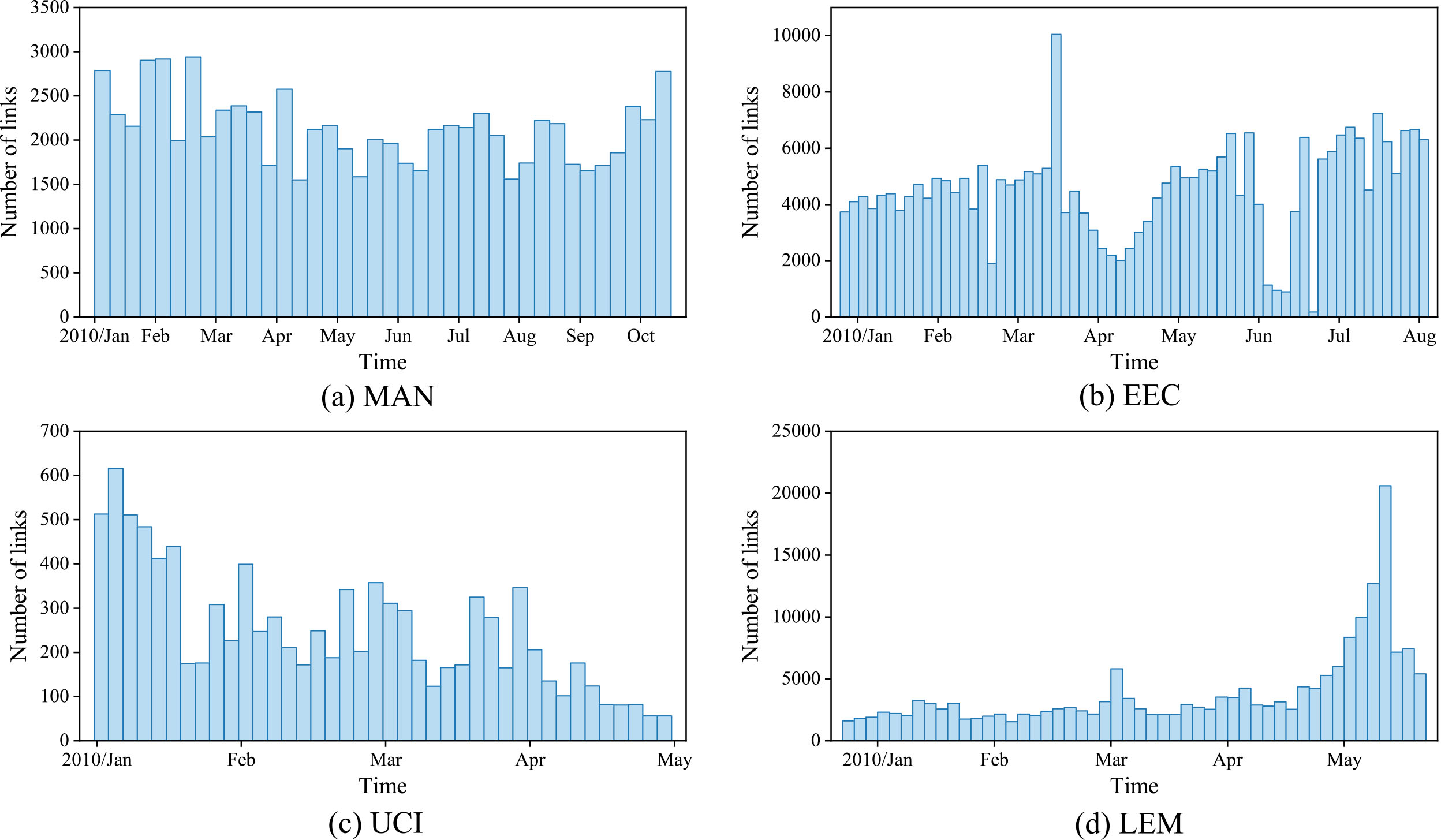
We use two standard evaluation metrics to evaluate the performance of temporal link prediction models. The area under the receiver characteristic operator curve (AUC) is a widely adopted evaluation metric for classification models, which considers both the sensitivity and specificity of the model. In link prediction problems, if there are
A larger AUC score indicates a better prediction performance for a given model. Similar with AUC, the area under the precision-recall curve (PRAUC) is designed to evaluate the sparsity of networks. However, both AUC and PRAUC cannot evaluate the added and removed links at the same time. Therefore, in addition we adopt the geometric mean of AUC and PRAUC (GMAUC) [12] to evaluate both added and removed links, defined as:
where
Experiments are performed on a Ubuntu 16.04 LTS system with 48 cores, 128 GB RAM and 2.20 GHz clock frequency. We implement the model in Tensorflow 1.15.0, and train it on a NVIDIA Titan Xp GPU. We use a sliding window with size
Parameter settings of TSAM in four networks
Parameter settings of TSAM in four networks
We compare the performance of TSAM and five state-of-the-art models on temporal link prediction in directed networks, including:
TNE [38]: It models the temporal network with Markov process and uses matrix factorization to learn node embeddings. GC-LSTM [4]: It is an end-to-end temporal link prediction model which uses GCN to extract structural features and LSTM to extract temporal features. We set the order of GCN EvolveGCN [26]: It is a graph embedding model which adapts GCN model along the temporal dimension without resorting to node embeddings. It captures the dynamism of graph sequences using an RNN to evolve the GCN parameters. dyngraph2vec [6]: It uses multiple non-linear layers to learn structural patterns of each snapshot, and then uses recurrent layers to learn temporal transitions in the network. We choose one of its variations namely dyngraph2vetAERNN, which uses LSTM in the encoder to extract node embeddings and full-connected network in the decoder to generate predictions. The hyperparamerter DySAT [27]: It is a graph embedding model based on joint self-attention along the two dimensions of structural neighborhood and temporal dynamics.
Results of prediction performance in MAN and EEC
Results of prediction performance in UCI and LEM
Notice that since we are dealing with directed networks, spectral domain convolution cannot perform on the asymmetric adjacency matrices because the asymmetric laplace matrices are not decomposable. Therefore, we replace all GCN units with GraphSAGE in GC-LSTM and EvolveGCN to perform spacial domain convolution on directed networks. The mean aggregator function is utilized in GraphSAGE to aggregate neighborhood features. Moreover, since TNE, EvolveGCN and DySAT are graph embedding models which learn node embedding
Average AUC of TSAM and baselines in four networks at each time step. Each value is the average of 20 independent experiments. 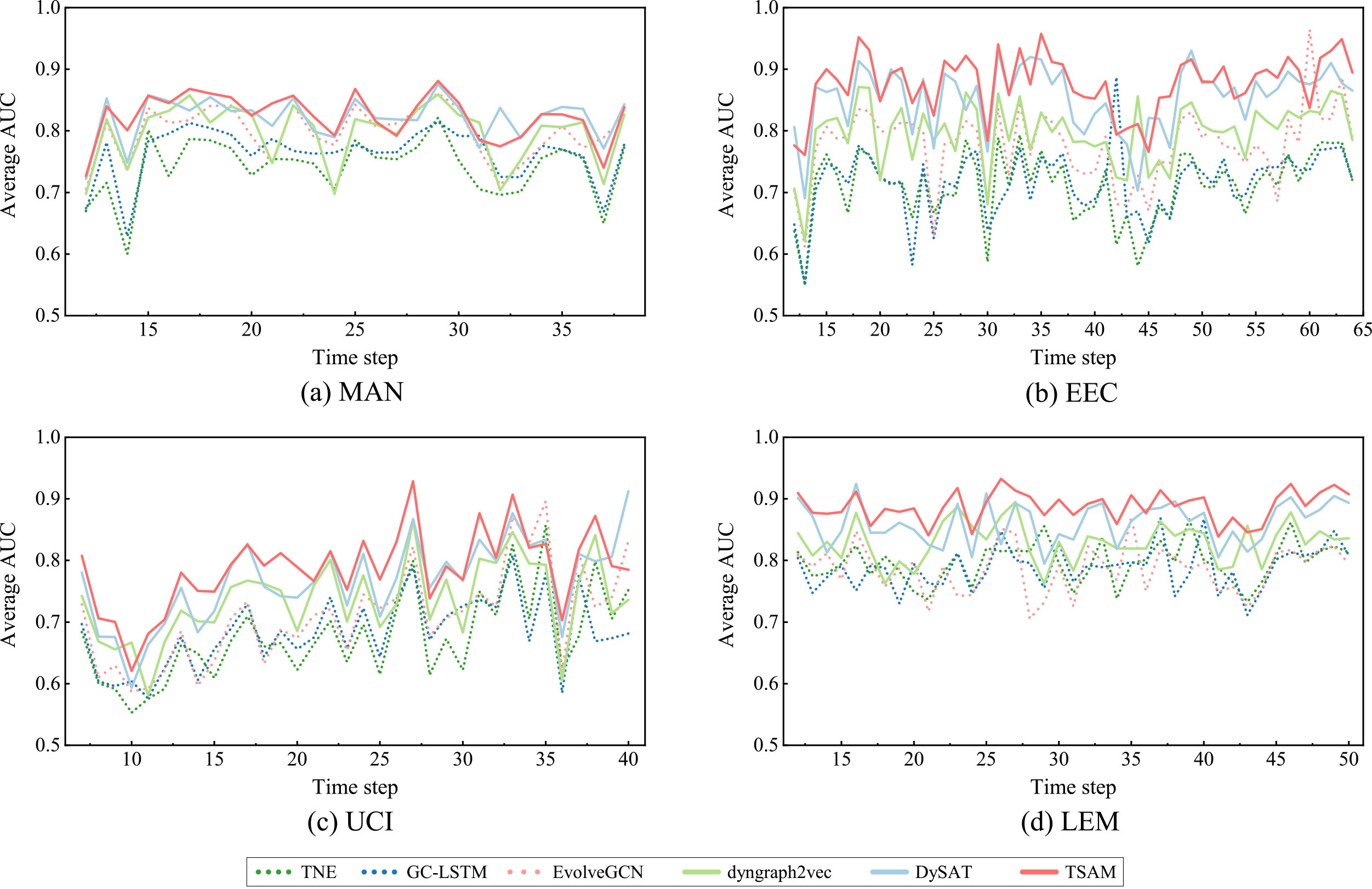
Tables 3 and 4 presents the prediction performance of TSAM and baselines in four networks. From the results we can observe consistent gains of 1–2% AUC in comparison to the best baseline in EEC, UCI and LEM. In MAN, the AUC of TSAM is slightly lower than DySAT, but TSAM get higher GMAUC than DySAT, which indicates a better performance of predicting both added and removed links. It is also clear that the performance of TSAM is more stable in four networks reflected by the smaller standard deviation. We also notice that compared with dyngraph2vec and GC-LSTM, our TSAM model and DySAT are able to achieve obvious improvements on both AUC and GMAUC, which indicates the effectiveness of self-attention mechanism on temporal link prediction task.
Figure 6 presents the average AUC at each time step in four networks. We find that the performance of TSAM is relatively better and more stable than baselines. The superiority of TSAM is obvious in comparison with TNE and GC-LSTM, whose AUC curves show rapid drops at certain time steps.
An important improvement in TSAM compared with other baselines is the feature fusion block, which uses matrix transformation to capture motif features in directed networks. Here we analyze the influence of feature fusion block with different choices of additional feature. Tables 5 and 6 present the performance of TSAM under three circumstances: 1) use only the output of GAT without additional features as the input of GRU, 2) use
Influence of attention heads
Another important hyperparameter of TSAM is the number of attention heads in self-attention layers. Here we respectively analyze the influence of attention heads on the performance of TSAM. Figure 7 presents the performance of TSAM when we independently vary the number of attention heads in node-level and time-level self-attention blocks within range
Comparison on the influence of feature fusion in MAN and EEC
Comparison on the influence of feature fusion in MAN and EEC
Comparison on the influence of feature fusion in UCI and LEM
Performance comparison on the number of attention heads in node-level and time-level self-attention blocks (in percentage).
Predicting the connectivity and direction of links in temporal networks is both meaningful and challenging. In this paper we propose a temporal link prediction model for directed networks based on graph neural networks and self-attention mechanism. The basic architecture of our model is an autoencoder. In the encoder, local structural features of each snapshot are drawn by the GAT layer and several GCLs. A GRU hidden layer then captures the temporal variations of the snapshot sequence. We use a time-level self-attention layer to differentiate the effect of each snapshot. In the decoder, a full-connected layer transforms the learned embedding into predicted adjacency matrix. Experimental results on realistic networks prove the effectiveness of our model in comparison with baselines.
In our future works, we will focus on the prediction of weighted links in directed networks. A possible direction of extending TSAM to solve weight prediction problems is leveraging the structure of generative adversarial network to refine the prediction accuracy.
Footnotes
Acknowledgments
This research was funded by the Foundation for Innovative Research Groups of the National Natural Science Foundation of China (Grant No. 61521003), and National Natural Science Foundation of China (Grant No. 61803384).