
Abstract
We consider the problem of clustering a set of uncertain data, where each data consists of a point-set indicating its possible locations. The objective is to identify the representative for each uncertain data and group them into
Keywords
Introduction
Clustering is the problem of grouping a set of objects into (disjoint) clusters based on their similarities. It is a fundamental problem in computer science and finds applications in many fields such as information retrieval, computer vision, data mining, social network, bioinformatics, etc. And there are a lot of well developed clustering methods such as k-means, k-medians, k-centers, self organized maps and so on.s A frequently encountered challenge in clustering is how to deal with the uncertainty of data caused by various reasons, such as data noise/errors and partially observed data. For example, when segmenting a video sequence, some frames may be imprecise or incomplete due to the limitation of equipments [1, 2]. Thus the data points in these frames can only be vaguely determined. For another instance, the position of a moving animal at a certain time point may not be precisely known, and thus can only be modeled by a set of possible locations or a probability distribution in some area [3]. Modeling data points in such an uncertain way could be quite beneficial in many applications. For instance, it could significantly improve the reliability of the clustering results and enhance our understanding of the inherent relations of data [4].
The issue of data uncertainty has been investigated quite extensively in recent years. Most of the existing results assume that each uncertain data point is given by a probability density function (PDF) or a discrete probability mass function (PMF) over an uncertain region [5, 6, 7, 2]. The PDF (PMF) associated with the data point can be accessed using some sampling [5] or Monte-Carlo approach [4].
There are also scenarios where the probability distribution of an uncertain point is not known. One of such examples is given in [8, 9], where the authors aim to clustering chromosomes (based on their pairwise associations) in a population of cells. Due to the undistinguishable homologues of the same chromosome, the set of
An illustration of uncertain clustering problem. Point-sets 1, 2 and 5 are in the same cluster, colored by blue, and point-sets 3 and 4 are in another cluster, colored by green. The representative point of each point-set is colored by red.
Due to the lack of a probability distribution for each uncertain data point, it is in general much harder to find its representative point. To overcome this challenge, quite a number of techniques were developed (see Section 2 for details). But each of them has its own limitations. For example, Ding and Xu have proposed a quite accurate method for solving the median graph problem for this type of uncertain data. Later, the authors in [9] extended this method to a more general
To provide a better solution to the uncertain data clustering problem, we propose in this paper a Non-negative Matrix Factorization (NMF) based
To address this issue, our main idea is to first use NMF to decompose a point into a linear combination of non-negative features. Then, iteratively seek the common features shared by different point-sets and use them, instead of the pairwise distances, to cluster the point-sets. The identified common features are also used to update the centroid of each cluster. This allows us to always select points close to the centroids, and thus lead to a good clustering. To help resolving the uncertainty issue in the iterative procedure, a novel sparse constraint is introduced in our model to assign weight to each point.
The followings are the main contributions of our paper.
A novel diagonal
An effective
An effective initialization and efficient strategies for large scale data. A good-quality initialization is generated by a simple search on a small number of inputs. A peeling strategy is designed to reduce the redundant points, and hence improve the ability of processing large-scale data. An efficient gradient descent method is developed in which only selected points are used to update the centroids.
The rest of the paper is organized as the follows. In Section 2, we briefly describe the related works on uncertain data clustering and NMF models. In Section 3, the mathematical formulation and related poof are presented. In Section 4, we present the alternative minimization approach for solving our relaxed NMF model. In Section 5, some experimental results on benchmark datasets are provided to illustrate the effectiveness of our method.
Related results on uncertain clustering
The problem of clustering uncertain data has been extensively studied in recent years. Most of the existing results are based on some heuristic ideas (a nice survey can be found in [10]), and are mainly for the type of uncertain data with known probability distributions. For example, the authors in [11, 5] extended Lloyd’s
Related results on NMF-based clustering
Non-negative Matrix Factorization (NMF) is a powerful technique for feature extraction and dimension reduction, and has been wildly used in pattern recognition [16], information retrieval [17], and bioinformatics [18]. Given a matrix
where
The authors in [20] proved the equivalence of the orthogonal NMF Eq. (2) and
Below we briefly overview how the orthogonality constraint leads to the equivalence of clustering. Let columns
where
Now, set the
where
Later, the theoretical analysis in [22, 23] extended the normal orthogonal NMF to the symmetric factorization, and proved its equivalence to Kernel
As we will show in Section 3.2, the non-negative k-means clustering problem for uncertain data is equivalent to the sparse orthogonal NMF problem. Therefore, these NMF techniques could be modified to solve our uncertain data clustering problem.
Problem definition
First, we define our problem formally. Let
.
(Uncertain
where
The point
In the above definition, we use Squared Euclidean distance for the distance function
Now, we present our NMF model for the problem Eq. (5). Let matrix
where
The diagonal entry
.
The sparse orthogonal NMF model Eq. (7) is equivalent to the non-negative
Proof..
Let
where
By simple calculation, we can have the clustering cost as
where
Taking the derivative of
based on the orthogonality constraint. This gives
which equals Eq. (14) after a proper permutation. ∎
We give a general error bound for our NMF model as the following.
.
Let
Before presenting the proof of Theorem 2, we first introduce a necessary lemma as below.
.
Let
where
Proof..
We define a random vector
Since
Now the proof of Theorem 2 can be presented as the below.
Proof..
By Eq. (17), we know that the total cost of clustering depends on the selection of
where
From Lemma 1, we know that
where
The NMF formulation presented in last section models our problem quite well, but has a non-convex
where
The relaxed model is the follows.
where
The benefit of this model is that a divide-and-conquer strategy can be applied in each iteration of the alternative minimization framework.
Furthermore, a much finer partition can be achieved by grouping points as sub-matrices in each point-set
During the execution of the above algorithm, it is possible that many points from one point-set are assigned to the same cluster. Since at most one of them is allowed to appear in the final solution, we need to determine which small set of points to be kept in each iteration. Our idea is to shrink the trace of
Illustration of selecting the extreme points. The blue dots and red diamonds represent points from two different point-sets. The ‘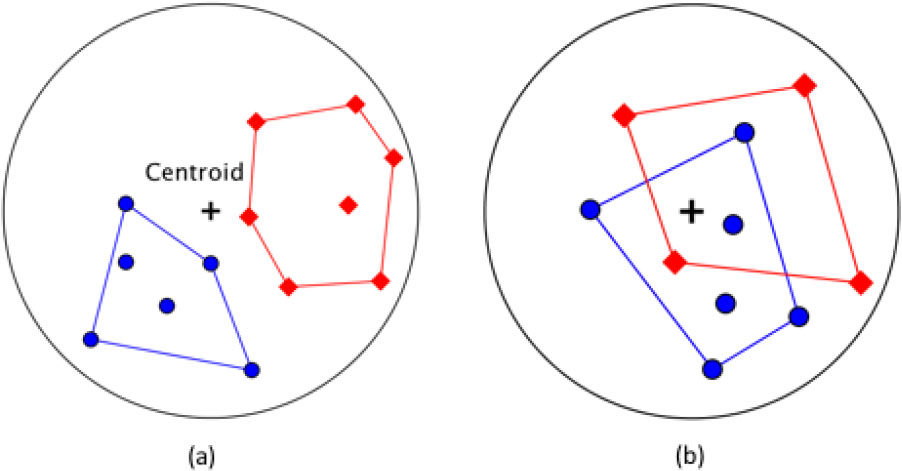
From a geometric point of view, trace minimization is equivalent to projecting the centroid to the convex cone formed by the extreme points. The projection is a non-negative linear combination (called features) of weighted extreme points. Hence an extreme point closer to the centroid tends to have a larger weight, meaning that it shares a larger portion of the common feature. There are two cases to consider based on the relative positions of a centroid with respect to the convex cone (see Fig. 3). The following theorems ensure the correctness.
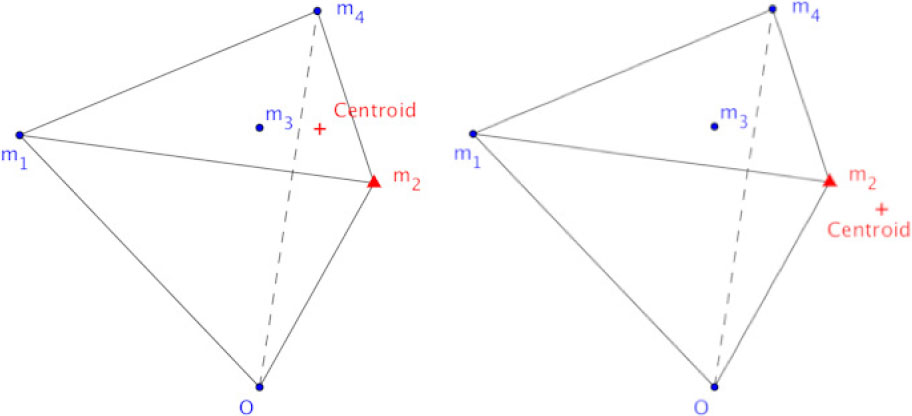
.
Let
Let
Proof..
Given the point
Since
Then we can have
Therefore
From the above theorem, we immediately have the following.
.
Let the convex cone of
Proof..
Define the projection point of
where
We have
We then obtain the result by Theorem 3. ∎
We solve the model Eq. (24) using an alternative minimization framework, which is presented in Algorithm 4. In each iteration, our algorithm first clusters all weighted points based on the current centroids. Then it calculates the weights of each point-set by the divide-and-conquer method discussed in the previous section. For each point-set, we try to shrink the number of points falling in (or assigned to) the same cluster, which is achieved by the peeling step. At the end of each iteration, we update the centroids by selecting the most likely points from each cluster, instead of directly using the entire set of points. All these steps will be described in details in the following subsections.
[h]
Update
i = i+1
t = 1 : n
Peeling
A good initialization can effectively improve the quality of our clustering result. We first extract
Finally, we initialize
To obtain
[h]
Non-negative least square methods for
We use the non-negative coordinate descent (NCD) method to solve Eq. (28). Coordinate descent method [30, 31] is a popular and efficient gradient method for solving NMF and NLS problems, which updates one variable of the unknown vector at a time.
In fact, when fixing all variables but a single entry
Then NCD updates
Finally, we need to project
The numerical operations will be computationally expensive if we directly use the entire
To preserve the possibilities that a point-set may be clustered into different clusters, our algorithm allows each point-set to have multiple points assigned to different clusters during its execution (one for each at the end). In the final solution, it decides for each point-set its cluster by using the cluster label of the largest-weighted point.
Update the centroids
We present an efficient and novel gradient descent method for updating the centroids. In the alternative minimization framework,
with
Now let
Then the gradient of Eq. (44) can be written as
Directly using this gradient will lead to a large computation burden, especially when
where
In this section, we present the experimental results of our method on several benchmark clustering datasets.
The CBCL face database
The CBCL database [32] contains 2429 19
We firstly apply a normal NMF method to decompose each image into a combination of 20 features. Then we select 3 specific features as the centroids of 3 clusters, as shown in Fig. 4.
To construct the cluster of each selected feature, we randomly sample 60 images which are mainly represented by this feature. Following this, we manually vary the weights of this feature in these images, such that 10 of them have relatively larger weights. The distances of the images to its centroids are proportional to these weights. This is illustrated in Fig. 5.
Accuracy results on synthetic CBCL face data
Accuracy results on synthetic CBCL face data
The selected 3 features (b) from a total 20 features (a) obtained by NMF on CBCL data.
An example of two clusters consist of images with different weights.
Now we construct 6 point-sets, each of which contains 30 images. A point-set is constructed by randomly mixing the large-weight images with the small-weight ones having different features. The cluster label of this point set is decided by the largest-weighted feature of its images. In this way, we can design the optimal solution by distributing the large-weight images of each cluster into different point-sets. We call them the representative images (points). An example is illustrated in Fig. 6. Therefore the quality of our clustering method can be measured by the representative images detected, since only one point is allowed to be kept in each point-set in the final solution.
An example of 4 point-sets consisting of mixing images. Set 
We construct the ground truth of our experiment as follows. Point-set 1 and 2 are labeled by representative images from cluster 1; point-set 3 and 4 are labeled by representative images from cluster 2; point-set 5 and
The result of our method on synthetic data. An optimal solution is obtained in this experiment. The representative point in each point-set is showed in this figure and matches the corresponding features.
We compare the accuracy of our method with different methods: orthogonal NMF (ONMF) [21], Kmeans
We compare the running time of our method and that of the SDP model in Fig. 8, which clearly shows an outperforming advantage of our method in efficiency. The experiment is performed using the similar construction of point-sets and clusters, but with varying sizes. We choose 3 different sizes for each point-set: 15, 25 and 35. The corresponding total number of images is respectively 90, 150 and 210.
We also provide the comparison result on the USPS handwritten digit database [33], which contains 9298 16
We also construct the optimal representative images as in last experiment. But we do not manually affect each image. Every data point is an original image. In the experiment, we randomly select the images of the number 3, 2, 4 as the representative numbers to label the point-sets. Each point-set contains 30 images, constructed by mixing images of one representative number and images randomly selected from other different numbers. We have 6 point-sets and 3 clusters. An example is shown in Fig. 9.
Accuracy comparison on real handwritten data
Accuracy comparison on real handwritten data
The efficiency comparison of UKmeans and SDP model.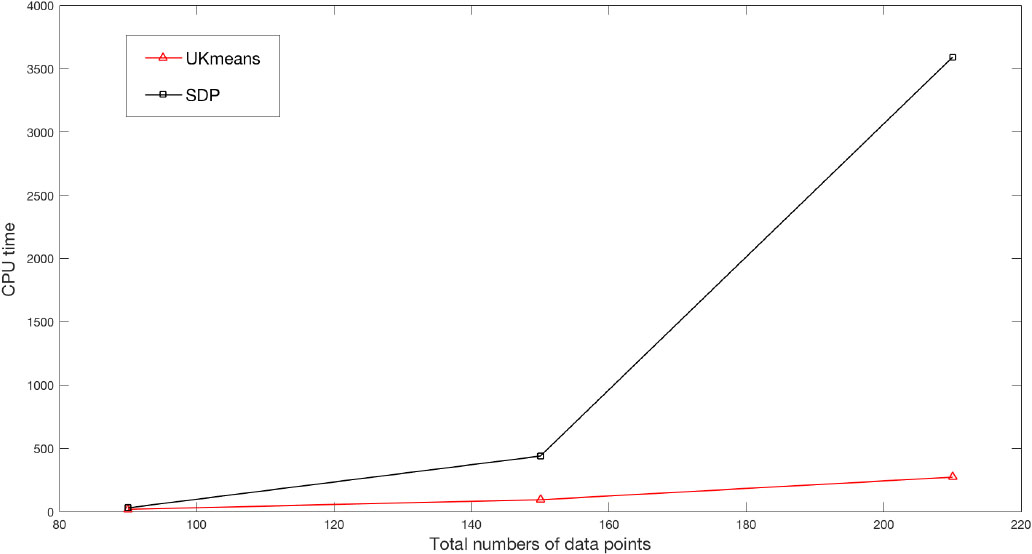
An example of 2 point-sets consisting of mixing number images. Set 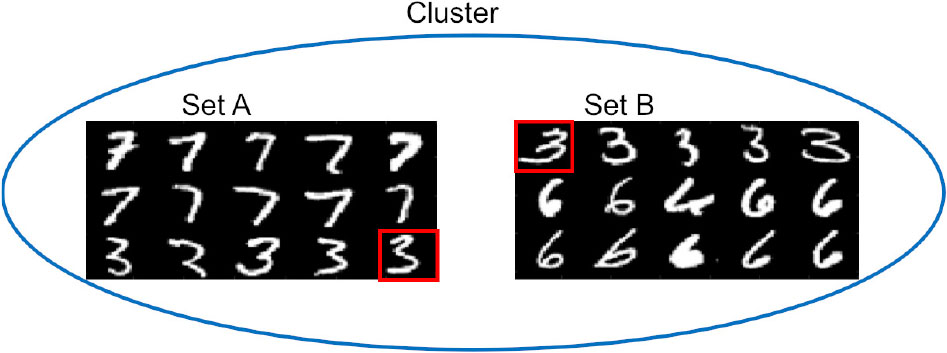
The accuracy comparisons are provided in Table 2, which are conducted in the same manner as for the face data. The real handwritten data is much easier to be confused with each other. This is because no fixed handwritten type exists for each number. For instance, 2 may be written similarly as 7, and 4 could be close to 6 and 9. Also Euclidean distance is not very suitable for measuring the similarity, since the
The D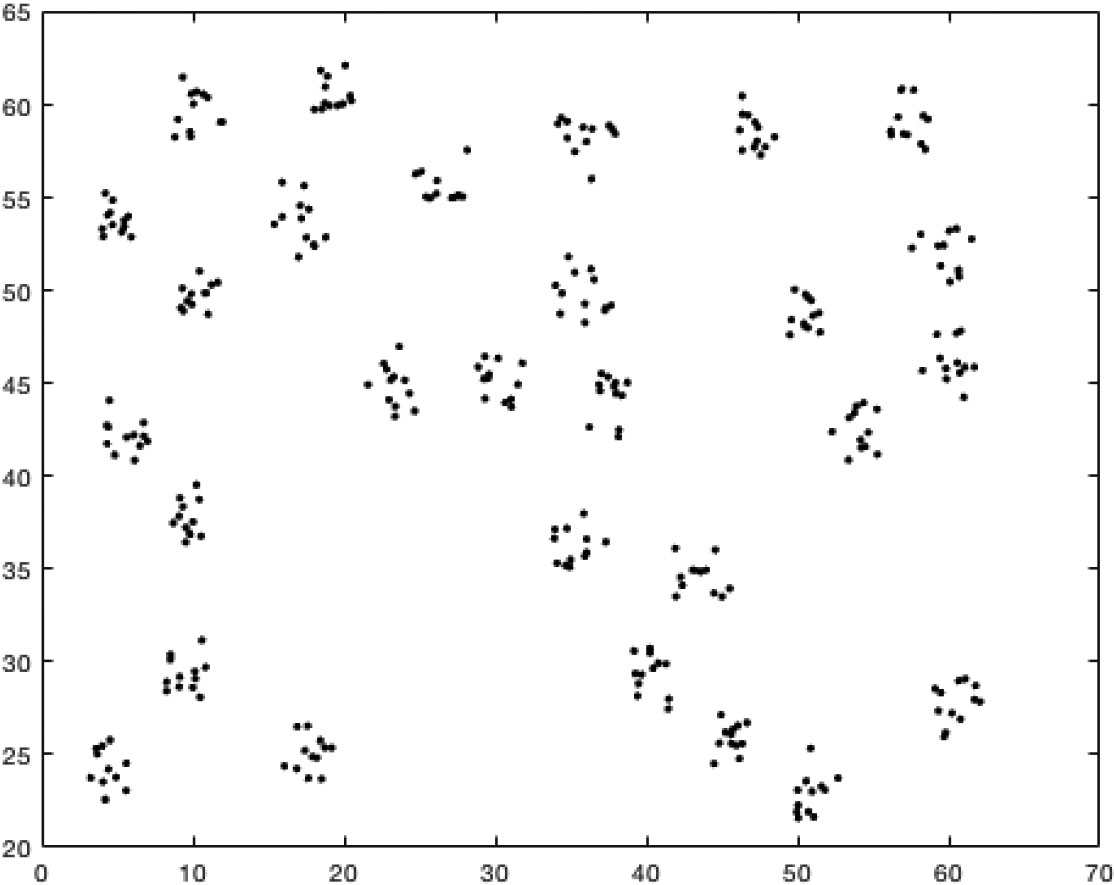
In this subsection, we demonstrate the effectiveness of our method by providing the comparison results on the random D28 data set [4], which consisting of 28 similar 2-D Gaussian distributions as in Fig. 10. In this data set, there are total 336 points, with each Gaussian distribution contains 12 points.
The core difference between the Gaussian data and the previous face data is that the Gaussian data set purely contains geometric information. In this scenario, the clustering result depends more on the relative geometric locations than the features of data points, since the features (extreme points) of each Gaussian distribution are not unique.
Now we partition this data set into 12 uncertain point sets such that each point set has 28 points. The uncertain clustering will group different point sets into one cluster based on the smallest
An example of 3 point-sets falling into one cluster. Set 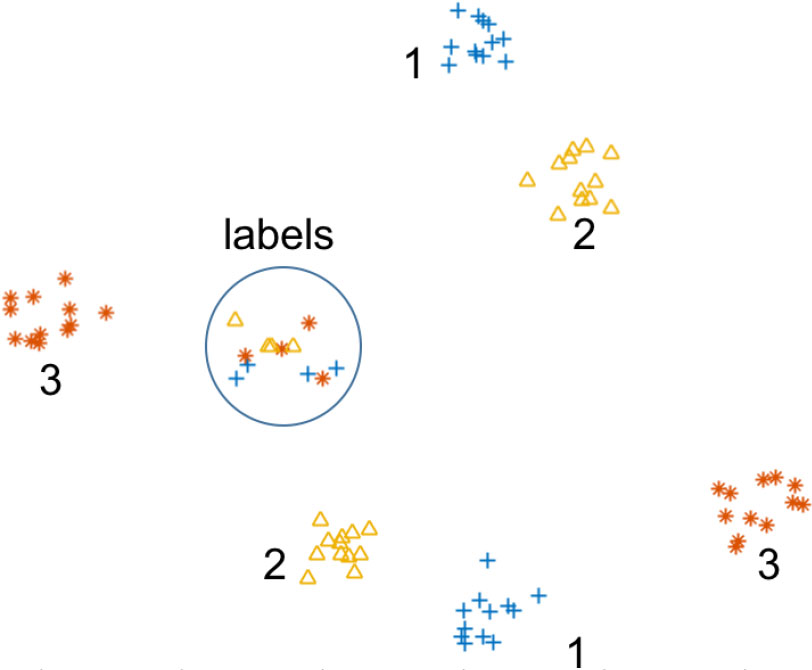
ARI comparisons on Gaussian dataset.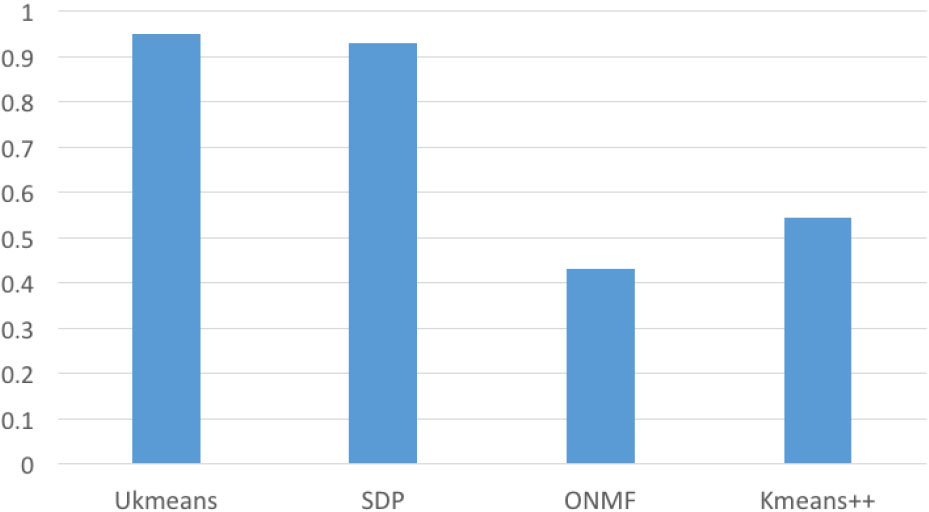
72 cities forms 9 clusters with 8 points in one cluster. And ‘
The accuracy of clustering is displayed by the Adjusted Rand Index (ARI) [34]. The comparisons are provided in Fig. 12, which are conducted in the same manner as for the face data. This result demonstrates our method is effective for the data with less feature information. The accuracy of our method is better than the state-of-art SDP method. The reason is that each Gaussian distribution in the original data set is tight and separated from other distributions. The extreme points of each point set can be easily calculated and precisely matched the boundary of the point set. Hence it is desirable for our method to locate the label points.
Here we present our comparison results on a real data set, which contains the 2-D coordinates of 72 cities in North America [35]. The construction of uncertain data sets is similar as the processing of the Gaussian data. To construct the ground truth, we firstly apply Kmeans on the 72 cities to obtain 9 clusters, which can be shown in Fig. 13.
We partition this data set into 6 uncertain point sets such that each point set contains 12 points (one city cluster and 4 label points). These uncertain point sets are designed to form 3 clusters. Each cluster is labeled by one randomly chosen city cluster, as in Fig. 14.
The illustration of 3 clusters formed by 6 uncertain point sets. Each point set is colored by a unique color.
We present the ARI results of clustering in Fig. 15. Our method achieves a slightly lower accuracy than the SDP method. This is because the real city data points spreads more randomly in the space. And the city clusters are not tight as the previous Gaussian clusters. However, the speed of our method largely outperforms the state-of-art SDP method, which has been demonstrated in the previous example. And the results of real data strongly confirms the ability of our method in practical area.
ARI comparisons on city distance dataset.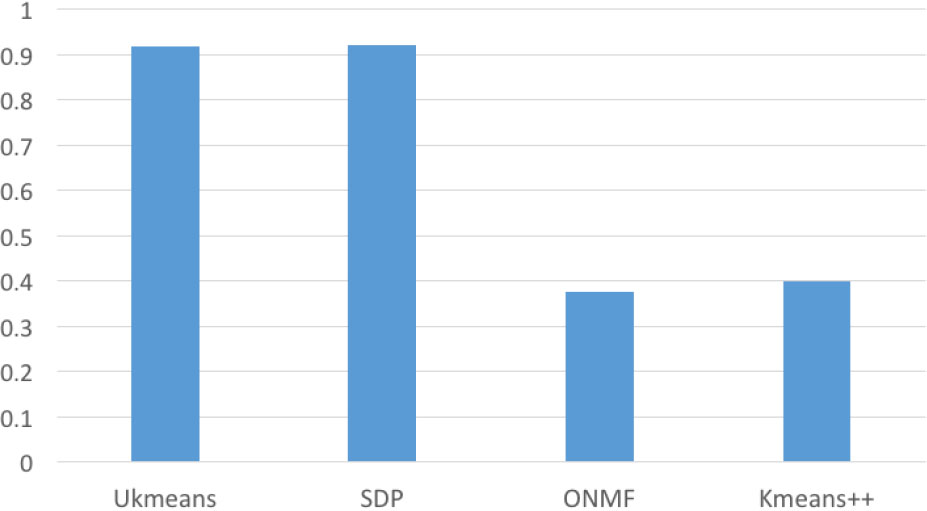
In this paper, we considered the problem of clustering uncertain data, and designed a new feature-based strategy to locate the representative point among a set of possible points. By introducing a novel NMF model, we can successfully avoid the expensive SDP computation on the whole dataset. The correctness of our model is proved by the provided theoretical analysis, and efficient computation strategies are designed in our algorithm. Experiments on benchmark datasets strongly support the effectiveness and efficiency of our method.
Footnotes
Acknowledgments
This work is supported in part by the National Natural Science Foundation of China under Grant No. 5187492 and Guangxi University’s High-level Talents Start-up Found under Grant No. A3070051002.