
Abstract
With the rapid development of social media and mobile Internet, short reviews, such as Weibo and Twitter, have exploded online. Discovering topics from short reviews is significant for many practical applications. It can effectively not only identify users’ attitudes and emotions but also enhance customer satisfaction and shopping experience. Because reviews are relatively short, the sparsity of reviews considerably restricts the quality of topic discovery. To improve the efficiency of topic discovery, we introduce the concept of data enhancement and strengthen the data in sentences and words in short reviews based on the weight of importance. We then propose a topic model for reviews to topic discovery based on data enhancement (shorted as DE-LDA). We verify the rationality and feasibility of DE-LDA on real datasets. Results show that the proposed method outperforms benchmarks in topic discovery and also has better clustering effects.
Introduction
With the rapid development of social media and mobile Internet, reviews play an increasingly important role in online social networks. Short reviews, such as Weibo and Twitter, have exploded online in recent years. According to Weibo’s 2020 fourth-quarter earnings report, Weibo’s monthly active users increased to 521 million and its daily active users rose to 225 million. In consideration of hundreds of millions of shorts reviews sent by users daily, topic discovery from reviews is crucial for practical applications. It can effectively help managers analyze stock price movements [1], study the evolution of public opinion [2], identify users’ emotions [3], and explore the impact of reviews on box office and sales [4, 5].
Topic models are effective and popular methods to discover topics and convert unstructured data into structured data in normal texts, such as long reviews. Topic models are widely used to uncover latent topics from texts through capturing document-level word co-occurrence patterns. Generally, documents are a probability distribution over topics, where a topic is modeled as a mixture of words. The effectiveness of leveraging traditional topic models, such as LDA [30] and pLSA [6], to long reviews for topic discovery has been proved, but applying them directly to short reviews does not work well. In reality, the small amount of words in short reviews makes rich context insufficient, which will result in the sparsity of reviews and minimal co-occurrence of feature words. Therefore, utilizing topic models to discovering topics from short reviews is a huge challenge.
To conduct topic models for short reviews effectively, some scholars conduct kinds of research. One common method to alleviate the sparsity problem is to aggregate short reviews into long documents or pseudo-documents before training a standard topic model [7
To some extent, these three methods can alleviate the sparsity problem of short reviews and effectively increase word co-occurrence. However, these ways not only destroy the integrity and coherence of documents but also have created strong assumptions for documents and sentences. They also are time-consuming and too weak in universality. Meantime, they do not distinguish the importance between different sentences or words. In a single document, the importance between sentences or words has considerable differences. To alleviate the sparsity of short reviews and increase word co-occurrence, we introduce the concept of data enhancement for short reviews, consider the importance of different sentences and words and then propose a topic model for short reviews based on data enhancement (referred to as DE-LDA). Data enhancement is a method for insufficient data, which can maximize limited data and produce a substantial amount of information. Using data enhancement in this study can effectively alleviate the sparsity of short reviews.
Compared with usual topic models for short reviews, the major advantages of DE-LDA are that 1) DE-LDA explicitly distinguishes the importance of different sentences and words; and 2) DE-LDA increases word co-occurrence through data enhancement. We first identify the importance of different sentences and words, determine the “stretching” operation based on different importance with the help of data enhancement, and enrich training data. Then, we utilize DE-LDA to model documents and obtain the final distributions of document-topic and topic-word after optimization. We verify the rationality and feasibility of our method in the Weibo and Yelp reviews datasets. The experimental results show that DE-LDA can effectively alleviate the sparsity of short reviews caused by the lack of rich context and word co-occurrence and improve the performance of topic discovery and clustering in practical application.
The rest of the study is organized as follows: related works are described in Section 2. Section 3 introduces the construction and inference of DE-LDA. Section 4 presents the experimental results of DE-LDA, and Section 5 discusses the clustering application. Finally, the last section concludes the study.
Related works
With the rapid development of social media, topic models have been applied to analyze content in a variety of tasks. In the absence of specific topic models for short reviews, some researchers use the traditional (or slightly modified) topic models directly for analysis [34, 35]. To conduct topic models for short reviews effectively, some scholars conduct kinds of research. One common method to alleviate the sparsity problem is to aggregate short reviews into long documents or pseudo-documents before training a standard topic model. Some scholars aggregate tweets posted by one user [7] or tweets with the same hashtag into one document [8]. Quan et al. and Zuo et al. assume that each short review is part of a pseudo-document and has the same proportion of topics as the pseudo-document [9, 10]. Although aggregating short reviews into long documents or pseudo-documents yields more realistic results than traditional topic models, aggregated documents compromise the integrity and coherence of original documents.
Making strong assumptions about short reviews is another common approach. Phelan et al. [11] assume that each short review is made up of a topic and Gruber et al. [12] suppose that words in each sentence come from the same topic. Cheng et al. [13] define the unordered word-pair co-occurred in short reviews as a biterm and assume that a biterm is generated from the same topic. However, in the reality, short reviews, sentences, and biterms may be drawn from multiple topics. Making strong assumptions can cause problems, such as losing the flexibility to capture different topic elements in one document and suffering from overfitting issues. Another way is to introduce external and domain knowledge for short reviews. Combining domain knowledge to evaluate words with high or low probability in each topic and then utilizing the Dirichlet Forest distribution to change prior is an effective method [14]. The method implicitly distinguishes the importance of words in documents. However, acquiring external knowledge is difficult, time-consuming, and not universal.
Based on the above, a topic modeling method based on data enhancement, shorted as DE-LDA, is proposed without introducing any external knowledge. The method distinguishes the importance of sentences and words in documents so that reducing the impact of text data sparsity problem and improving the effectiveness of short text-based topic modeling.
Construction and inference of DE-LDA
Data enhancement
Data enhancement is a method proposed when data is insufficient and missing, which is applied to the image field [15, 16] health care field [31], business field [32], and geophysics [33]. In image recognition, data enhancement easily obtains ideal results when utilizing a large amount of data to train models. To leverage data effectively under the condition of limited data, researchers usually use operations, such as scaling, rotating, cropping, and toning to enhance and enrich image training data. For example, cropping an image in different ways, making an object in an image appear in different proportions at different locations, or adjusting brightness, contrast, saturation, and hue, are universal and specific operations. Data enhancement, which generates equivalent data from limited data, can reduce the dependence of the model on attributes and improves the generalization ability. If useful information is extracted effectively from low-quality data, then the model can gain good results [17]. Data enhancement has been proved to be effective in image datasets [18, 19, 20].
In consideration of limitations in our study, user habits, and other factors, the text posted by users is relatively short. For example, Weibo requires the text posted by users to be less than 140 characters. The short and sparse content of short reviews makes the information expression inadequate and informal, hence, extracting effective information and topic discovery is difficult. To enrich data information, we introduce and apply data enhancement in the image field to short reviews, thus short reviews generate equivalent and effective data from limited datasets to train topic models. In reality, speakers often emphasize key sentences to highlight key points, and authors usually describe and write words, phrases, or sentences repeatedly, to highlight emotions and convey vital information. Emphasizing and repeating important sentences and words can highlight key information and facilitate users to extract effective information easily.
Given that the units of short reviews are usually sentences and words, we apply data enhancement to sentences and words in this study. It is an effective method in utilizing data enhancement to emphasize and repeat some sentences or words in short reviews. For example, a speaker’s point, when writing “let’s have lunch together”, is to emphasize having lunch together. After data enhancement, the short review can be regarded as “let’s have lunch together, having lunch together”. Introducing and applying data enhancement to short reviews not only adds data information but also does not change the original information and makes the extraction of data information easy. In this study, by distinguishing and repeating the importance of sentences and words, we propose a topic model for short reviews based on data enhancement (shorted as DE-LDA).
Figure 1 shows the flow chart of DE-LDA. The process of DE-LDA is organized as follows: 1) determining the importance weight of a sentence; 2) applying TextRank to calculate the importance weight of words; 3) utilizing data enhancement based on the importance weight of sentences and words, obtaining new importance sentences after the operation of DE-LDA, finally calculating the rate of change between two iterations; 4) according to the importance weights in step 3, carrying out iterative and update in step 2 until the rate of change is less than the value of the threshold and the iteration is stopped; 5) gaining the final document-topic distribution and topic-word distribution.
Basic flow chart of DE-LDA.
When we apply data enhancement to topic modeling for short reviews, we first distinguish the importance of sentences and words and then identify the dataset that needs to be enhanced. We use topic models to measure the importance weight of sentences. Topic modeling assumes that each document consists of hidden topics
According to the topic-word distribution, we can acquire the top n words under different topics and the sentences in which the top n words are placed. The sentence s consists of
In this study, we utilize the length of interval
Although the importance weight of sentences, calculated by the topic model, can locate valid information, the importance of words in the identical sentence is different. TextRank is utilized to measure the importance weight of words in sentences. TextRank is a method that calculates word weights in a sentence to extract text keywords [22]. The process of TextRank in this study is divided into four steps:
Identifying units in sentence s and adding them to the graph model as nodes. Sentence s has S units because S words are found in sentence s. Confirming relationships between units and adding the relationships to the graph model as edges. The relationships between text units are based on co-occurrence between words. If two words occur in the same co-occurred window cw, that the number is often set from 2 to 10, then a relationship between words can be established. cw is an important adjustment parameter in TextRank and affects the accuracy of weighing the importance of words. Giving an initial value for each node. We set the initial value as 1 in this paper and run the algorithm until it converges. Ordering nodes based on weights and acquiring final scores. The results are defined as the vector
After measuring the importance weight of sentences and words in short reviews, we simultaneously use the importance weight to enhance data. To describe topics better through ordering words, we utilize the importance weight to determine the number of words appearing in a document. The higher the list of words that describe a topic effectively, the better the quality of the topic is. In this study, we introduce and define that the more important a sentence is, the more important words appear in the sentence; the more important the word is, the more frequently the word appears. We define the number of words in original sentence s as
We obtain enhanced short reviews after applying data enhancement to original reviews. The set of original words in document d is
We propose a topic model for short reviews based on data enhancement (referred to as DE-LDA). Our method explicitly distinguishes the importance of different sentences and words and eliminates the weakness of the traditional topic model for short reviews. It not only alleviates the sparsity in short reviews and increases the number of words that describe topics, but also has an improved and accurate effect on document-topic distribution
In this chapter, we assume that each document consists of multiple topics and that words are generated by each topic. Specifically, in DE-LDA, we set topics and words from two sources, original documents, and enhanced documents. Figure 2 shows the generation process.
Generative process of DE-LDA.
Probabilistic graphical model of DE-LDA.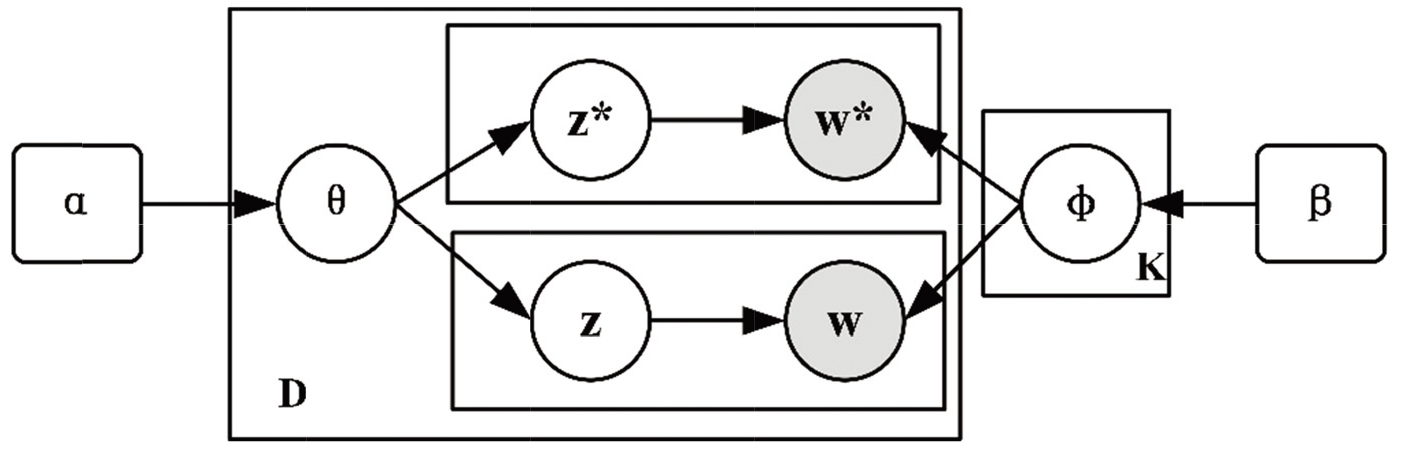
Figure 3 shows the probabilistic graphical model of DE-LDA. The joint probability distribution
We choose the Gibbs sampler to infer the joint probability distribution of DE-LDA. The Gibbs sampler is a simple and widely used Monte Carlo algorithm. Compared with other inference algorithms for topic models, such as variational inference, and maximum posterior estimation, the Gibbs sampler improves the accuracy of results by approximating the correct distribution asymptotically and is used to large datasets easily [23]. Figure 4 shows the process of Gibbs sampler for DE-LDA.
Process of Gibbs sampler for DE-LDA.
Joint probability distribution eliminates hidden unknown variables through integration and then samples the topic for each word. Once the topic of each word is determined, the parameters in Eq. (3.3) can be calculated after counting frequency. Thus, the purpose of utilizing the Gibbs sampler to infer parameters is to calculate the conditional probability of the topic sequence under the word sequence. After inferring the topic for the set of words
In the above formula,
After obtaining the document-topic distributions and topic-word distribution, we choose the coherence change rate as the threshold between two iterations. Although there are many metrics to evaluate, compared with other metrics, the coherence score corresponds well with human coherence judgments and makes it possible to identify specific semantic problems in topic models without human evaluations or external reference corpora. The Coherence is a performance metric to evaluate the quality of the topic [24]. This metric is based on the property that words under the same topic often co-occur in the same document. For the quality of topics, the experiments show that coherence has a high correlation with human judgment. For the given topic
In Eq. (9),
During the process of iterative update, we stop iterations until the change rate between two successive iterations is below the value of the threshold and then acquire final document-topic distribution and topic-word distribution. We set the threshold to 0.03.
Experimental setting
To validate the quality of topic discovery by using our method, we apply DE-LDA to several practical short review datasets. Firstly, we explore the best values of
Most topic models contain two hyperparameters
Dataset
We use two different practical datasets in our experiments, Weibo1
We choose four different traditional topic models as our compared methods in this study:
LDA is the most famous probabilistic topic model which uses a hierarchical Bayesian graphical model. It assumes that document-topic distribution and topic-word distribution have a prior distribution. We use jGibbLDA to implement LDA.4
Mix [25] assumes that each document is made up of a topic.
BTM [21] defines the unordered word-pair that co-occur in the same document as a biterm and assumes the biterm generated from the same topic. For a biterm
We use the program provided by the author to implement BTM.5
To evaluate the quality of topic discovery by topic models, we utilize coherence as the evaluation metric. To explore the influence of different
where
To confirm the best parameters of
When exploring the influence of different
defeat_ratio under different 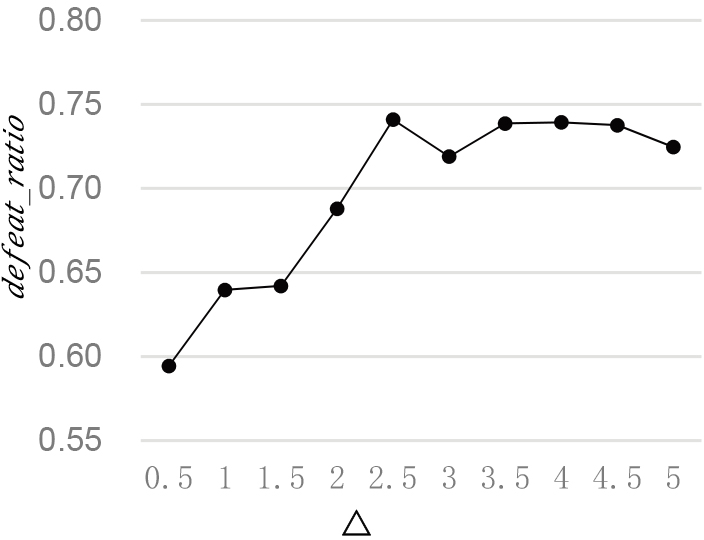
defeat_ratio under different cw settings.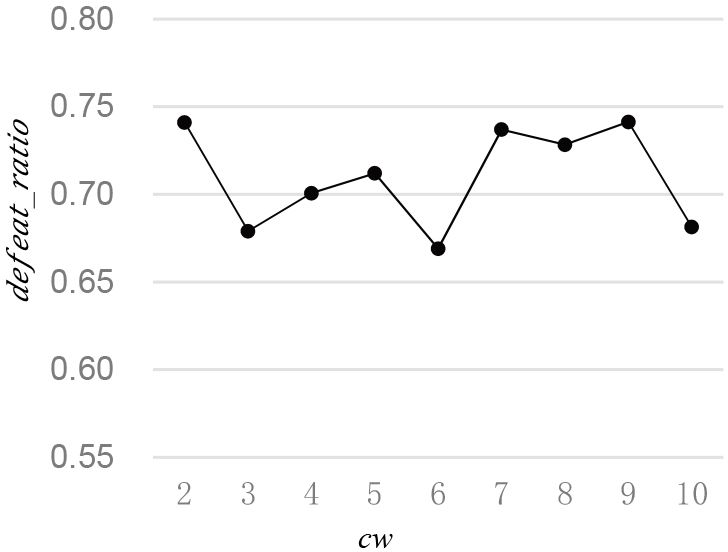
The co-occurred window cw influences the relationship between words. The value of cw often is set to range from 2 to 10. Under the setting of
To evaluate the quality of topic discovery calculated by using DE-LDA, we first assess the quality quantitatively of the reviews in the Weibo and Yelp datasets. We select coherence as a metric and set the number of topics to range from 10 to 50. Table 1 shows the results of average coherence.
Results of coherence
Results of coherence
Top 20 words under “health” and “movies”
In the Weibo dataset, the value of coherence computed by DE-LDA has a better result than all baselines. This result means that DE-LDA generates high-quality topics and extracts topic features better. Compared with the average coherence between all baselines, BTM outperforms Mix, Mix is better than LDA and LDA performs better than pLSA. Thus, topic models that are proposed to deal with short reviews are better than topic models designed for normal reviews in the Weibo dataset. In the Yelp dataset, DE-LDA also has a better result than all baselines. With increasing the number of topics, pLSA always outperforms LDA. This result indicates that considering prior in the model has no advantages when dealing with short reviews in the Yelp dataset. For the average coherence, BTM and Mix have a poor effect. Thus, in the Weibo and Yelp datasets, DE-LDA could obtain the best results and generate a better quality of topic discovery.
To evaluate the quality of topic discovery qualitatively discovered by all models, we sample some topics for visualization. Table 1 shows that as the number of topics increases, the coherence value also increases. We randomly sample two topics for visualization in the Chinese dataset, when the number of topics is set to 50. We first collect the top 5 words in each topic and recognize the meaning of topics based on the top 5 words. Then, we randomly choose two topics (i.e., health and movies) from the same meaning of topics between all methods. For each topic, we list the top 20 words that are most representative of a topic. Table 2 presents the top 20 words under the topic “health” and the topic “movies” for the Chinese dataset. The second and third rows are Chinese words for selected topics and the fourth and fifth rows are English words translated from the Chinese words.
Table 2 shows that the top 20 words under “health” generated by DE-LDA highly relate to the topic “health”. The top 20 words generated by benchmarks contain irrelevant words. For example, LDA has words like “fire” and “times”; pLSA contains the words “fight” and “reading”; BTM includes “times”, “fire” and “rub”; and Mix has the words “fight” and “reading”. The top 5 words generated by DE-LDA are similar to those generated by Mix. The top 5 words in pLSA do not include “health” and BTM includes the insignificant word “times”. For the topic “movie”, all words in Table 2 generated by DE-LDA and BTM are related to the topic “movie”. In the remaining methods, LDA has an irrelevant word “link”, pLSA contains the unrelated words “image” and “do”, and Mix also has irrelevant words “link” and “game”. Although DE-LDA is the same as BTM, words computed by DE-LDA have more relevant to the topic “movie” than BTM. For the visualization of topics, we conclude that DE-LDA generates a better quality of topic discovery based on qualitative evaluation.
The quantitative and qualitative methods are direct ways to evaluate the quality of topic discovery. Based on the former works of literature for topic models, clustering application is a widely used and indirect method to evaluate the quality of topic discovery. In mining short reviews, clustering is one of the most important applications. Before clustering, turning short reviews into a vector is essential. Utilizing topic models to text vectorization is a popular and common way. To evaluate the quality of topic discovery indirectly and apply methods to the practical dataset for clustering, we verify the clustering performance based on different topic models.
Clustering based on DE-LDA
We demonstrate how to apply DE-LDA to a short review clustering task. In clustering short reviews, choosing words as features, such as all words or part of words in the documents, clustering is a common way. However, defining words as features causes not only missing semantic information, but also the problems of polysemy and synonymy. In this study, we choose topics as features. This setting can alleviate the problems of polysemy and synonym, and decrease the dimensionality of reviews. We utilize DE-LDA to vectorize short reviews and leverage the clustering algorithm to clustering. The vector of document d is represented as follows:
where
Clustering performance for K-Means
The topic distribution of each document can be regarded as a k-dimensional vector and these vectors also are expressed by the vectors of Euclidean space. For most clustering, to compute distance and similarity between reviews, feature vectors are required from Euclidean space. Thus, the results of DE-LDA can be combined with many clustering algorithms. To evaluate the effectiveness of clustering based on DE-LDA for short reviews, we choose K-Means [27] and Gaussian Mixture Model (GMM) [28] as clustering algorithms. In consideration of the tags for each document, we select the RI index [29] as the evaluation index to evaluate the effectiveness of clustering. RI is a means of evaluating clustering with permutation and combination. The equation is shown as follows:
where a correct (R) decision assigns two similar documents to the same cluster, and a wrong (W) decision assigns two dissimilar documents to different clusters. D represents assigning two dissimilar documents to the same cluster, and W is defined as that assigning two dissimilar documents to the same cluster. The value of RI ranges from 0 to 1, in which a high value indicates better clustering performance.
To verify the clustering performance based on DE-LDA, we compare with the clustering algorithm based on different topic models in the Chinese and English datasets. The document can be approximated by document-topic distribution in the topic models, thus, the document is defined as a vector. We combine two clustering algorithms (K-means and GMM), with different topic models, thereby forming clustering algorithms based on different topic models. We then verify the effectiveness of clustering methods based on DE-LDA. To keep the same number of true categories as the dataset, we set the number of categories in the Chinese dataset as 28 and set 834 in the English dataset. We choose clustering algorithms that are based on LDA, pLSA, Mix, and BTM, as comparison methods, and set RI as evaluation metrics. Under the varying number of topics, such as 10, 20, 30, 40, and 50, we take the average mean and standard deviation in 10 experiments as the experimental results and utilize the
Table 3 provides the performance of clustering algorithms based on different topic models for K-Means. The clustering algorithm based on DE-LDA generates optimal effects compared with other clustering algorithms based on baselines in all datasets. The clustering algorithm based on DE-LDA is better than other clustering algorithms based on baselines and produces a stable result.
Table 4 provides the performance of clustering algorithms based on different topic models for GMM. The clustering algorithm based on DE-LDA creates optimal effects compared with other clustering algorithms based on baselines in all datasets.
Clustering performance for GMM
Clustering performance for GMM
With the rapid development of social media and mobile Internet, the volume of short reviews that are created has exploded. Mining short reviews and discovering topics can help managers analyze stock price movements, study the evolution of public opinion and effectively identify users’ emotions. Aiming to address the problems of sparsity and few co-occurrences of words, we introduce data enhancement from the image field, and we propose a topic model for short reviews based on data enhancement (DE-LDA). We evaluate quantitatively and assess qualitatively the quality of topic discovery in the Chinese Weibo and English Yelp datasets and verify rationality and validity. The clustering algorithm based on DE-LDA not only improves the performance of traditional clustering algorithms that utilize words as features but also strengthens the cluster effects for short reviews. DE-LDA can be applied to general short reviews on the Internet, provide method support to model and cluster short reviews, and has theoretical and practical significance.
Although DE-LDA improves performance for topic discovery from short reviews, the problems of fragmentation and diversification have not been solved. In the future, exploring new methods will be necessary to reduce the sparsity of short reviews and improve the accuracy of topic modeling.
Footnotes
Acknowledgments
This work is supported by the Major Program of the National Natural Science Foundation of China (91846201), the National Natural Science Foundation of China (71872060, 72071069, 71801069, 71802068). The National Key Research and Development Program of China (2017YFB0803303).