
Abstract
As an important task in business process management, remaining time prediction for business process instances has attracted extensive attentions. However, most of the traditional remaining time prediction approaches only take into account formal process models and cannot handle large-scale event logs in an effective manner. Although machine learning and deep learning have been recently applied to the remaining time prediction task, these approaches cannot incorporate domain knowledge naturally. To overcome these weaknesses of existing studies, we propose a remaining execution time prediction approach based on a novel auto-encoded transition system, which can enhance the complementarity of process modeling and deep learning techniques. Through auto-encoding the event-level and state-level features, the proposed approach can represent process instances in a comprehensive and compact form. Furthermore, a transfer learning strategy is proposed to train the remaining time prediction model so as to avoid overfitting and improve the accuracy of prediction. We conduct extensive experiments on four real-world datasets to verify the effectiveness of the proposed approach. The results show its superiority over several state-of-the-art approaches.
Introduction
Information systems have been successfully deployed in various scenarios, including enterprise resource management, workflow management, etc. These systems record a large scale of event logs and provide an opportunity for exploration of new business process management paradigms and applications. Predictive process monitoring [16], as a rising interest in the area of business process management, aims to perform predictive analysis of ongoing business process instances, such as predicting future activities to be executed, final execution results of the instance, and remaining execution time of the instance. Compared with traditional process monitoring methods based on the dashboard or statements, predictive process monitoring can not only monitor the execution status of business process instances in a real-time manner, but also predict their possible future execution results intelligently.
Predicting remaining execution time of a business process instance [17, 21] (for simplicity and clarity, we refer to the task as remaining time prediction hereafter), as an important predictive process monitoring task, is helpful in gaining insights on many business process management scenarios. For example, if the remaining execution time of ongoing business process instances can be accurately estimated, the business process manager can take necessary actions to avoid possible transgression of business deadlines, or improve the overall performance of the business system. In a word, remaining time prediction plays an important role in business process performance optimization.
Early work on remaining time prediction mainly relies on formal business process models such as transition systems [12], stochastic Petri net [10] and process tree [19]. One of the most representative work [17] is proposed by Van der Aalst et al., which predict remaining time using the state of an ongoing business process instance in transition system. In recent years, with the successful applications of deep learning in various fields, researchers have focused on predicting remaining time by using various deep learning techniques [18]. Existing results show that deep learning is more effective than traditional business process models in exploiting massive event logs to build accurate remaining time prediction models. However, as data-driven approaches, deep learning is hard to incorporate process knowledge that can be easily encoded in various business process models.
In order to take the advantages of deep learning and business process modeling technologies in handling massive event logs and modeling process knowledge, respectively, we propose a novel auto-encoded transition system (AETS) for the task of remaining time prediction. In particular, the traditional process model – transition system – is enhanced by auto-encoder, such that multi-view information about ongoing instances can be encoded in a compact way, further facilitating learning accurate remain time prediction model. The main contributions of our work are summarized as follows:
We propose a new remaining time prediction approach that incorporates auto-encoder and transition system. It is advantageous in handling massive event logs and modeling process knowledge, respectively. We propose a new encoding scheme for process instances that covers not only the information about an ongoing instance itself, but also its state information in transition system. An auto-encoder is then utilized to derived compact representation based on the raw high-dimensional features. When training the remaining time prediction model, we adopt a transfer learning mechanism to overcome the overfitting problem caused by insufficient training data in each state of the transition system, as well as retaining the correlation among different states in the transition system.
Extensive experiments on four real event log datasets demonstrate that the proposed AETS outperforms several state-of-the-art remaining time prediction approaches based on either deep learning and process model. The effectiveness of the proposed auto-encoded transition system and transfer learning mechanism is also experimentally verified.
The rest of this paper is structured as follows. Section 2 briefly reviews related work. Section 3 introduces key concepts of the remaining time prediction task, followed by the details of the proposed remaining time prediction approach given in Section 4. Section 5 presents the experiment results and Section 6 concludes this paper.
Existing remaining time prediction approaches can be roughly divided into three categories: (1) process-model-based approaches, (2) machine-learning-based approaches, and (3) deep-learning-based approaches.
Concepts
In this section, we introduce key concepts in the task of remaining time prediction.
Historical execution information of process instances is recorded in event logs. Simply put, an event log can be viewed as a set of traces, each of which is an execution sequence of activities. Related concepts are formally defined in what follows.
Note that both of the trace prefix and the trace are finite non-empty event sequences. In essence, a trace records execution information about a completed process instance, whereas a trace prefix can be used to represent an ongoing process instance that is a part of a completed process instance. For ease of presentation, subsequently we may use “trace” or “process instance” interchangeably, as well as “trace prefix” or “ongoing process instance” interchangeably.
Table 1 shows an example event log. Here only two traces are recorded, each containing 5 and 6 events, respectively. For example, the event 1015580001 is a running instance of the activity Urine Source that started on October 29th at 19:00 and ended at 19:14.
An example event log
An example event log
Transition system [17] is a classic business process model that formally represents the behavior of a process-aware information system. It is mainly composed of two parts: (1) state, which represents the running state of the system, and (2) transition, which represents the transitions between system states. What follows are related concepts in transition system.
In general, an event can be represented by its running activity or related attributes. Taking the event log in Table 1 as an example,
Commonly, there are three forms of state representations, i.e., SET, MULTISET, and SEQUENCE, in transition system. Formally, given a trace
SET: MULTISET: SEQUENCE:
Taking the trace 101558 in Table 1 as an example, its state representations are as follows if activity is used as the event representation:
According to the three different forms of state representations, transition system is usually categorized into three types, each of which uses the set state representation, the multiset state representation, and the sequence state representation, respectively. Figure 1 gives an example of the three types of transition system of an event log. Note that to simplify the representation here, the events are represented by the corresponding running activities.
An example of transition system.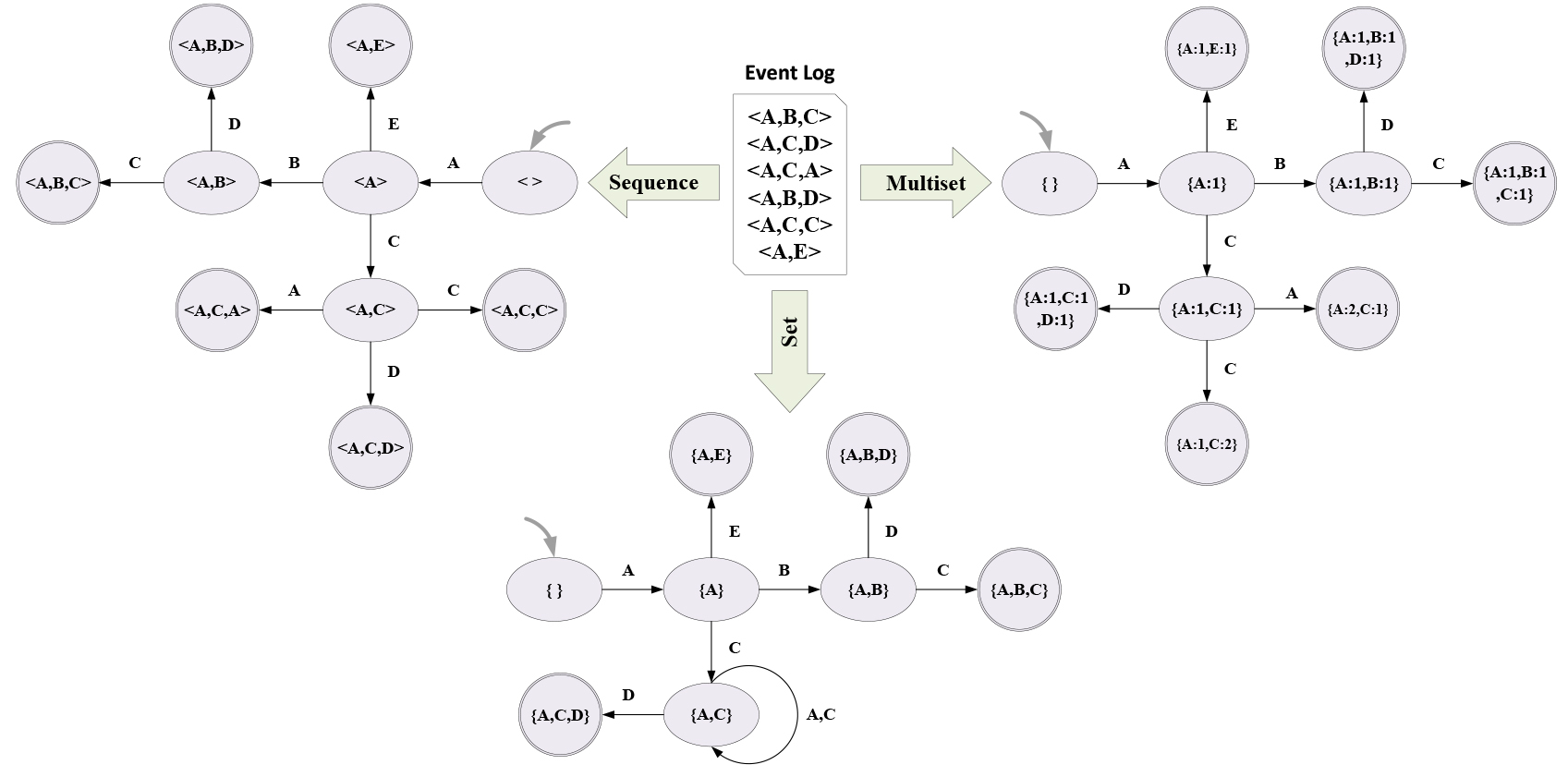
The overall framework of the proposed approach is depicted in Fig. 2. In the training stage, the given event log on one hand is used to mine a transition system, which abstracts the inherent global process information, on the other hand is used to generate the training data for constructing the remaining time prediction model. More specifically, a variety of features of historical traces recorded in the event log are extracted by taking into account both the global process information abstracted in the transition system and single instances’ own execution information. Then the raw sparse feature vectors are fed into a sparse auto-encoder to derive a more compact representation. Taking the historical traces with the compact representation as training data, a multi-layer perceptron (MLP) is trained for each state in the transition system for remaining time prediction. In the predicting stage, a given ongoing process instance is mapped to a state of the transition system, and the corresponding MLP model is applied to yield its remaining time. More details will be given in the following sections.
The overall framework.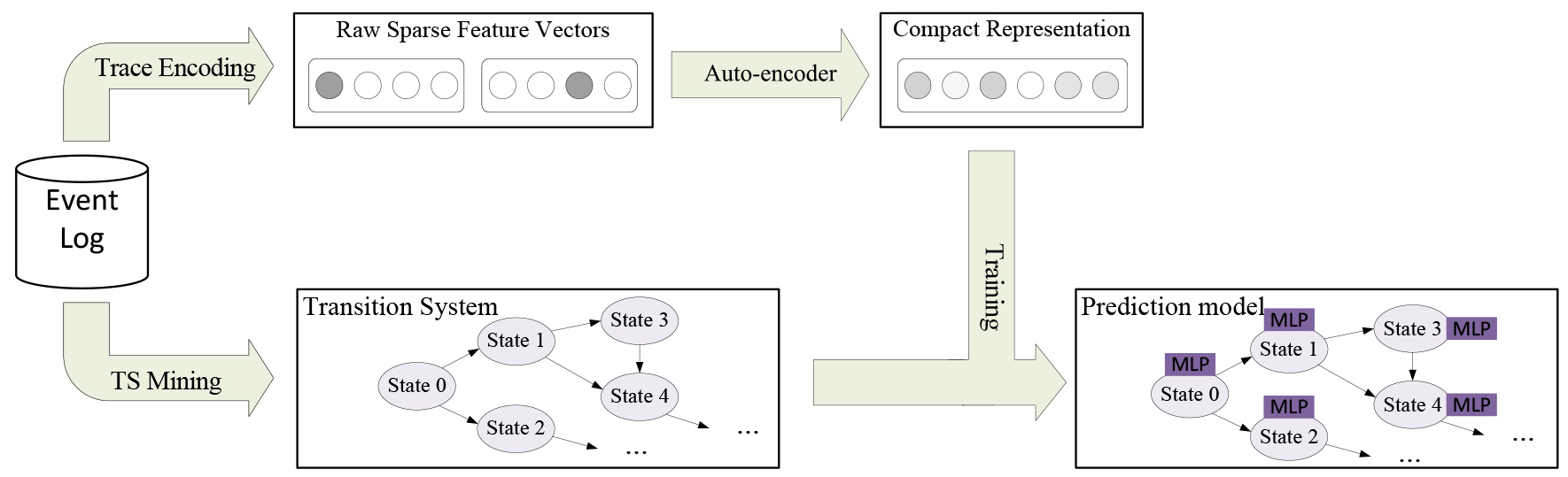
Inspired by [17], we design the transition system mining algorithm, of which the details are given in Algorithm 4.1. The procedure of transition system mining involves two-round traversals of the input event log. In the first-round traversal (lines 2–8), the state of each trace prefix is calculated, based on which the state set
[h] : TSMining[1] The event logs
With the proposed process mining algorithm, a transition system is automatically discovered from the given event log, free of laborious efforts of domain experts. This would be desirable especially in case of large-volume event logs or lack of prior domain knowledge. We nevertheless note that our proposed remaining time prediction framework in Fig. 2 takes transition system as a module for trace encoding, thus offering the flexibility of incorporating transition systems either mined from event log or available as a prior.
Trace encoding
In order to take account into various factors affecting the remaining time of process instances, we propose to use a new form of trace encoding, including trace event features and trace state features, which encode the execution information of single trace, and related global process information, respectively.
Trace event encoding
Trace event encoding mainly considers the events and the associated attributes in a trace. Due to the heterogeneity of event attributes, we design different encoding schemes for three types of attributes, i.e., discrete attributes, continuous attributes, and datetime-type attributes.
Discrete attributes
We use one-hot encoding for discrete attributes, e.g., activity name, practitioner. Specifically, let a discrete attribute takes values from
Continuous attributes
We use discretization-based encoding for continuous attributes, e.g., execution time and cost. Specifically, let a continuous attribute takes values from
Datetime-type attributes
Datetime is an indispensable field recorded in event logs because process instances are essentially time-sensitive event sequences. Thus we particularly design encoding scheme for datetime-type attributes. To be more specific, we treat every fields of a datetime value, i.e., year, month, week, day and hour, as discrete attributes, and concatenate the encodings of each fields. Taking a datetime-type value “2012/4/10 5:13” as an example, the field values “2012”, “4”, “10” and “5” are encoded as discrete values separately.
As the number of events in different traces is not always the same, we only consider the
where
where
Note that the vector of a trace prefix with length less than
The states of transition system essentially represent running states of the overall business system. Each ongoing process instance (i.e., trace prefix) can be mapped to a state of transition system, which reflects the state of the business system at the time when the process instance is running. For each of the three forms of state representations, we design the corresponding state encoding scheme, respectively.
Formally, let the set of all events in an event log
SET: Given a set state
MULTISET: Given a multiset state
SEQUENCE: Given a sequence state
We give an example for the above encoding scheme for ease of understanding. Suppose the set of event representation is
After obtaining the event encoding vector and the state encoding vector, the trace vectors are formed by concatenating these two types of encoding vectors. Commonly, each events have a number of discrete attributes, and the one-hot encoding adopted above easily lead to high-dimensional and sparse feature vectors, which can hinder training effective machine learning models. To tackle the sparsity issue, we use sparse auto-encoder to reduce the dimension of raw trace encoding vectors and derive more compact feature vectors for traces.
Auto-encoder [20] is an unsupervised neural network model, which consists of an input layer, one or several hidden layers and an output layer. The task of auto-encoder is to reconstruct the input data from the low-dimensional representation generated by the hidden layers. Figure 3 illustrates the architecture of an auto-encoder, in which the part from the input layer and hidden layers is called as encoder, and that from hidden layers to the output layer called as decoder.
The input of auto-encoder is the trace encoding vector
Then the decoder obtains the reconstruction of the trace encoding vector
Here,
The aim of auto-encoder, i.e., reconstructing the trace encoding vectors, can be formalized as minimizing the following loss:
In this work, the stacked auto-encoder, as shown in Fig. 4, is used to derive the hidden features of input traces. The stacked auto-encoder is composed of several cascaded auto-encoders. The hidden feature vector extracted from the
The architecture of auto-encoder.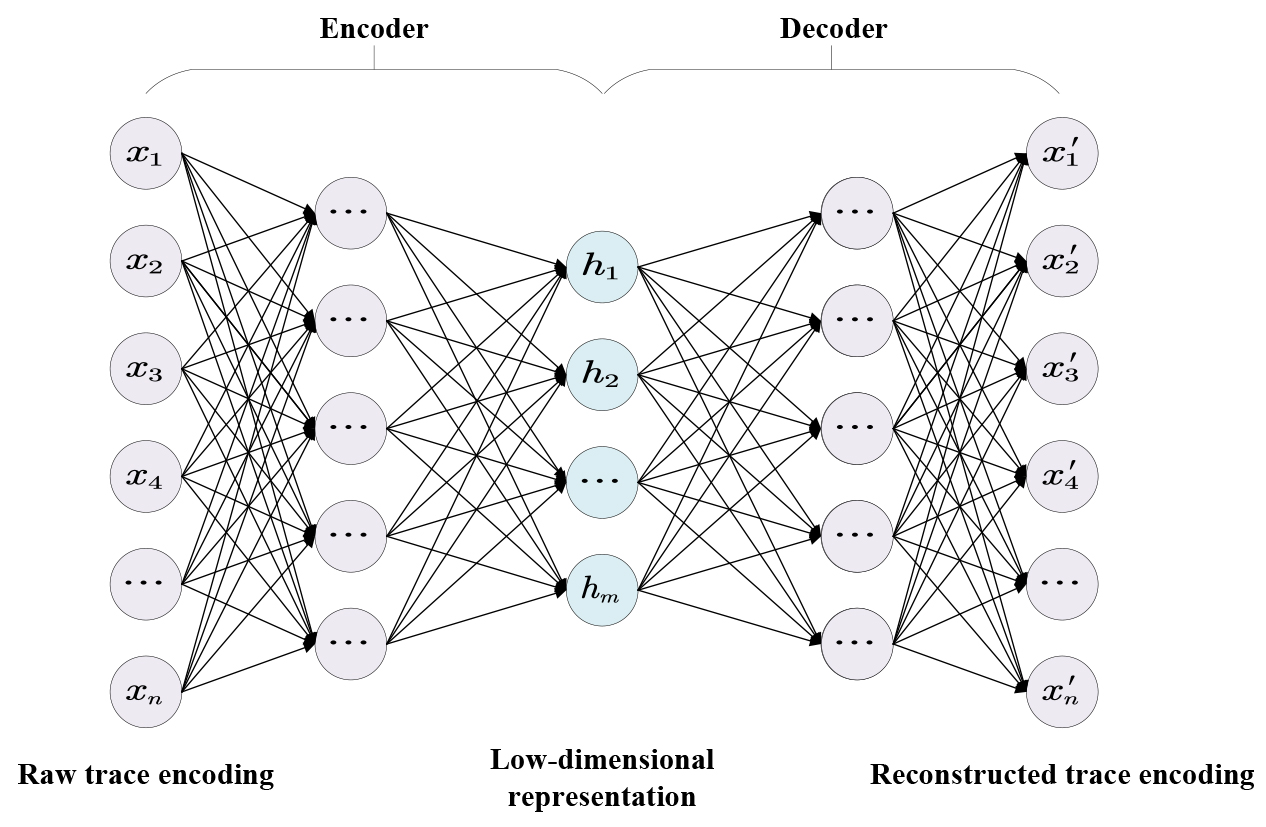
The structure of stacked auto-encoders.
The remaining time prediction model is constructed by using the condensed representation of traces. In particular, we first generate a training set from a given query log, then train multi-layer perceptrons in a transfer learning manner as the remaining time prediction model.
Generating training set
Given an event log
The trace prefix set is then divided by the states of the transition system
Finally, the training set is generated by the condensed low-dimensional feature vector of each trace prefix in
We train a three-layer perceptron (as shown in Fig. 5) for each state in the transition system as the remaining time prediction model. The input to each model is a trace feature vector
where
The following L1 loss is used for training the three-layer perceptron:
where
The architecture of three-layer perceptron.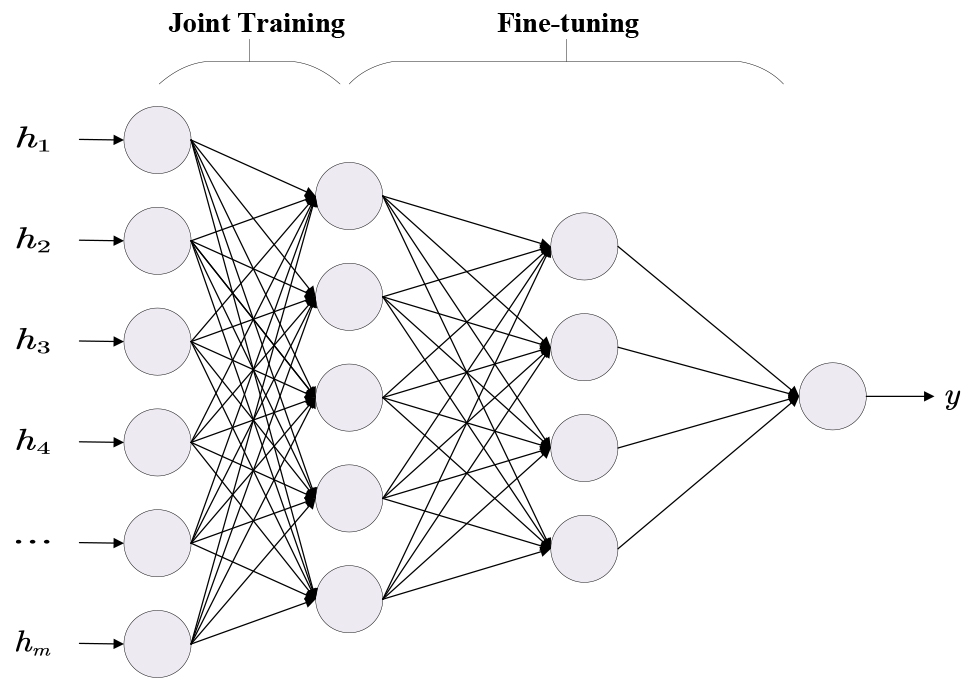
It should note that due to the potentially large amount of states in a transition system, the training set after divided by states tends to be much smaller; however, it is well recognized that limited training data easily leads to overfitting of neural networks. Inspired by recent developments in transfer learning [2], we propose to jointly train the multi-layer perceptrons for each states to tackle the overfitting problem. First, the multi-layer perceptrons for each states in the transition system are jointly trained using all the training set generated from the given event log. This stage can be viewed as pre-training for the remaining time prediction models. Then, for each state in the transition system, the parameters of the first layer in the three-layer perceptrons (i.e.
Actually, states in a transition system are not necessarily independently with each other as longer states are formed by a series of transitions from shorter states, making the remaining time prediction models for each states also interrelated. The proposed joint training strategy is also advantageous in accounting for the correlation among the states in addition to tackling the overfitting problem.
Statistics of datasets w.r.t. execution time.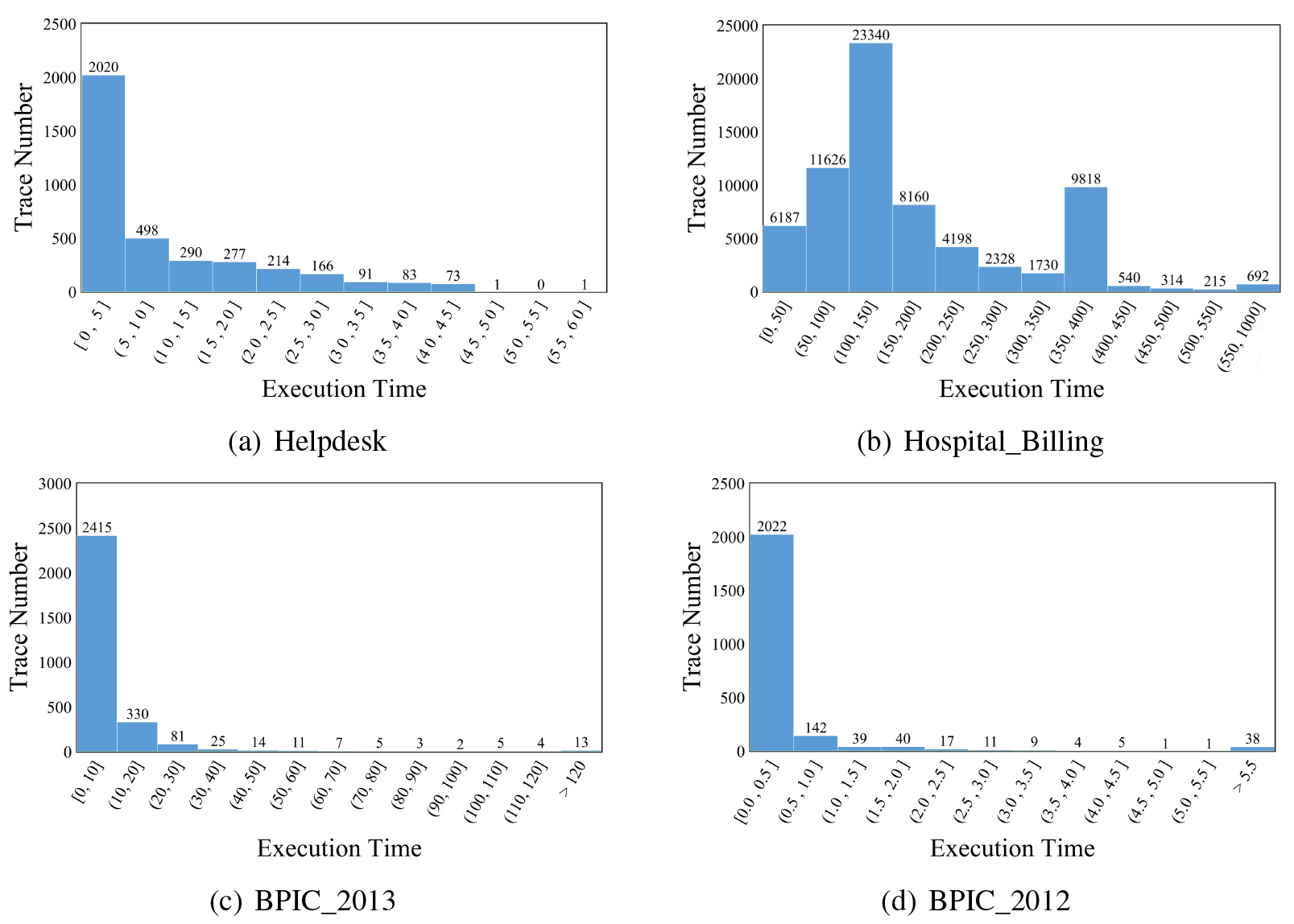
Datasets
To evaluate the effectiveness of the proposed remaining time prediction approach, we use the following four real event logs from different domains:
Basic statistics of the four datasets are shown in Table 2. Figure 6 illustrates the statistics of traces w.r.t. execution time for each of the four datasets. Before used for the experiments, these datasets are preprocessed by filtering out traces with concurrent events and noises. The traces with lengths less than 3 are also filtered out.
Basic statistics of datasets
Baselines
The following three types of remaining time prediction approaches are used as baselines in the experiments:
As for the proposed remaining time prediction approach, we also use the three different state representations, denoted as AETS-set, AETS-multiset and AETS-sequence, respectively. The main parameters of the proposed approach are tuned using a development set over the following ranges:1
The codes are available at
The dimension of condensed feature vectors of traces: The number of neurons in the layers of multi-layer perceptron: Learning rate: The number of training epoch: Optimization algorithm: Adam.
We evaluate the performance of the proposed approaches and baselines using Mean Absolute Error (MAE) and Mean Squared Error (MSE), which have been widely used in regression tasks. Given an evaluation set
where
Overall results
The results of all the compared approaches are summarized in Table 3. In this experiment, we randomly split each dataset into three 70%-15%-15% parts, each taken as the training set, testing set and evaluation set, respectively. The partition is repeated 5 times and the average MAE/MSE values are reported. It can be seen that the proposed approach achieves the best performance in most cases, which directly verifies the effectiveness of the proposed auto-encoded transition system for the remaining time prediction task. By comparing the proposed approach with baselines, we can make the following further observations:
Compared to the traditional transition-system-based approaches (i.e., TS-set, TS-multiset and TS-sequence), the approaches fusing machine learning or deep learning techniques with transition system (i.e., DATS-set, DATS-multiset and DATS-sequence, as well as the proposed AETS-set, AETS-multiset and AETS-sequence) perform better in most cases (except in terms of MSE on BPIC_2012). This indicates the advantages of the combination of heterogeneous models over single ones in the remaining time prediction task. Among the two types of approaches based on extended transition systems, the proposed AETS performs much better than DATS. Note that the main difference between them is that AETS uses deep learning (i.e., auto-encoder and multi-layer perceptron), whereas DATS uses traditional machine learning (i.e., support vector regression machine and decision tree). This result verifies the advantages of deep learning techniques in leveraging large-scale and noisy event logs for remaining time prediction. Furthermore, this advantage would be more significant in the case of even bigger event logs, as shown in Table 2 where the improvements of AETS are more significant on bigger event logs, e.g., Hospital_Billing and BPIC_2013. Among the three types of state representations, the sequence representation (i.e., TS/DATS/AETS-sequence) performs slightly better than the multiset representation (i.e., TS/DATS/AETS-sequence), while both superior to the set representation (i.e., TS/DATS/AETS-set). This is mainly because the transition system constructed with sequence and multiset state representation tends to have more states, leading to finer-granular division of the event log and more targeted remaining time prediction models trained on each states. The proposed AETS outperforms all the baselines with an exception on the BPIC_2012 dataset in terms of MSE. One reason is that the multi-layer perceptron for remaining time prediction is trained with L1 loss, which is essentially the same to the evaluation measure MAE, making AETS tends to perform better in terms of MAE than MSE. We also checked the BPIC_2012 dataset in more detail, and find that many traces did not end normally, which will be assigned with a large remaining time in the training set. This can be seen in Fig. 6d where the distribution of traces of the BPIC_2012 dataset exhibits a long yet heavy tail. The prediction errors on these traces tend to be large and have a greater impact on the evaluation results when measured by MSE.
Remaining time prediction results of all compared approaches
Remaining time prediction results before and after removing abnormal traces.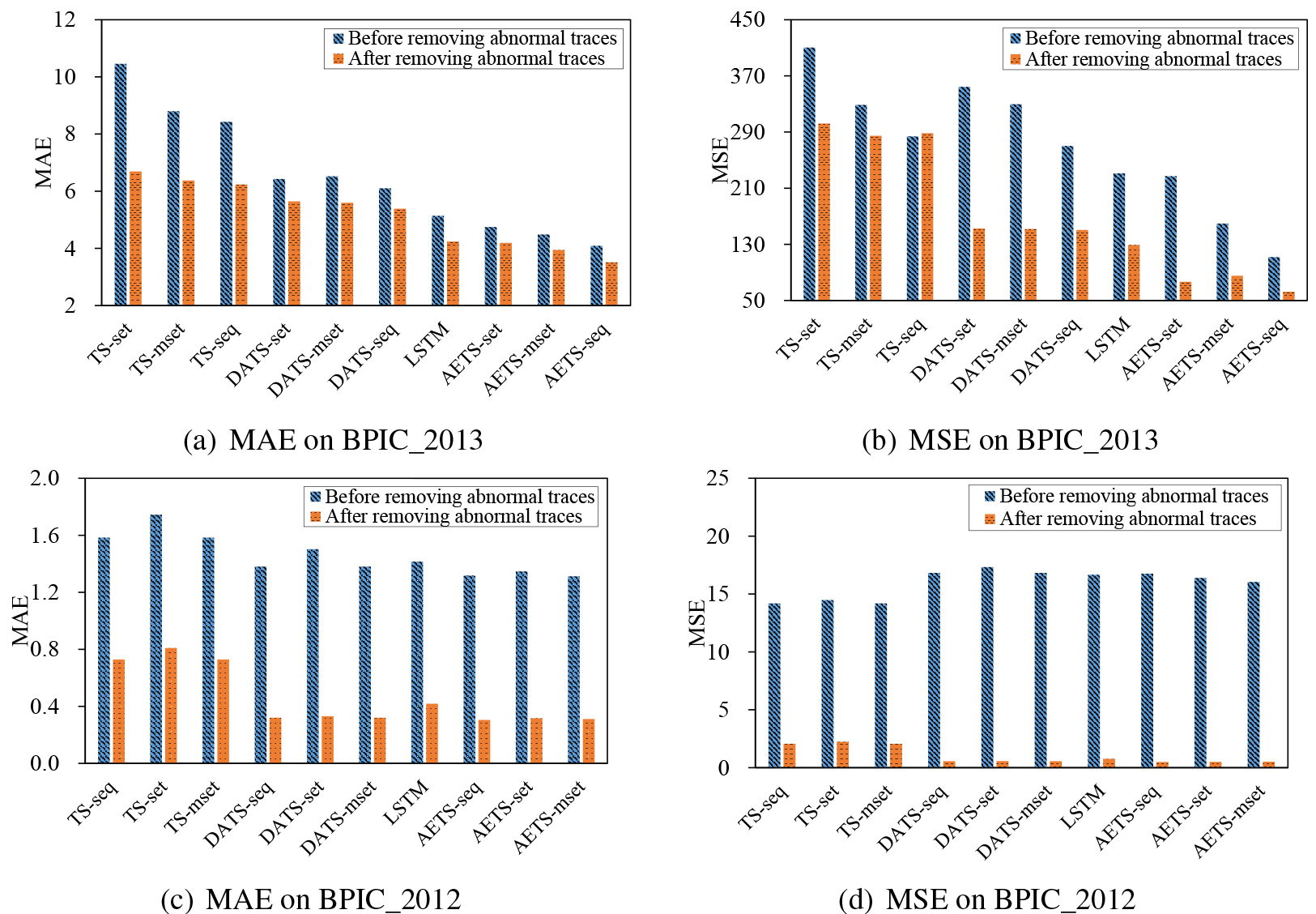
As a matter of fact, as shown Fig. 6, the four datasets used in the experiment exhibit two types of trace distributions w.r.t. execution time. That is, traces in the Helpdesk, BPIC_2013 and BPIC_2012 datasets roughly follow exponential distributions, whereas the distribution of traces in the Hospital_Billing dataset is more of a Gaussian mixture with three peaks at (100, 150], (350, 400] and (550, 1000], respectively. If we look in more detail, we see heavier tails in the BPIC_2013 and BPIC_2012 datasets, which imply a number of abnormal traces existing in the two datasets. To further evaluate the impact of abnormal traces on time prediction approaches, we remove the traces with very large execution time (i.e., larger than 120 and 5.5 in the BPIC_2013 and BPIC_2012 datasets, respectively) and compare the performance of each time prediction approaches which is shown in Fig. 7.
Comparison of w/o auto-encoder.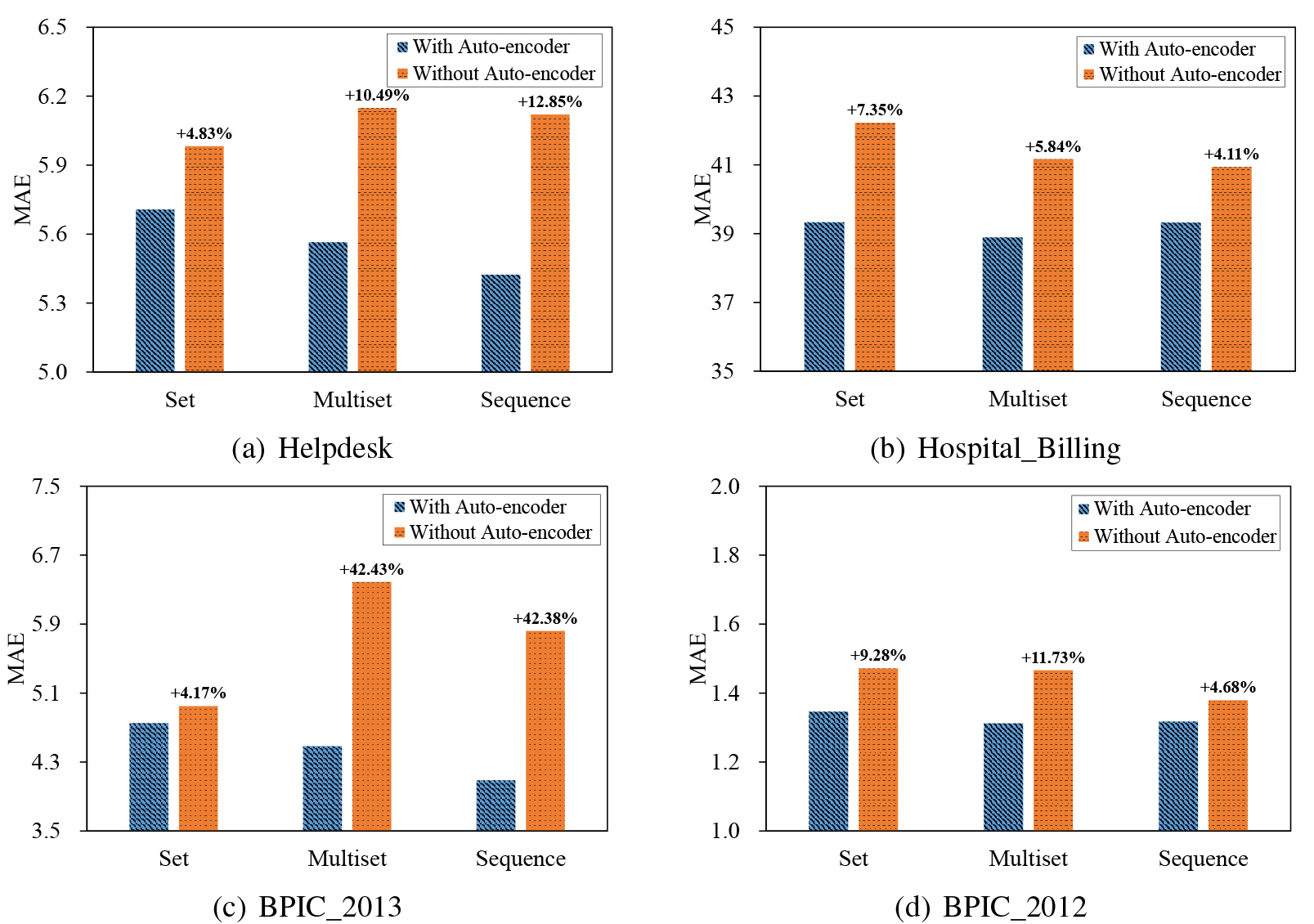
Comparison of w/o transfer learning.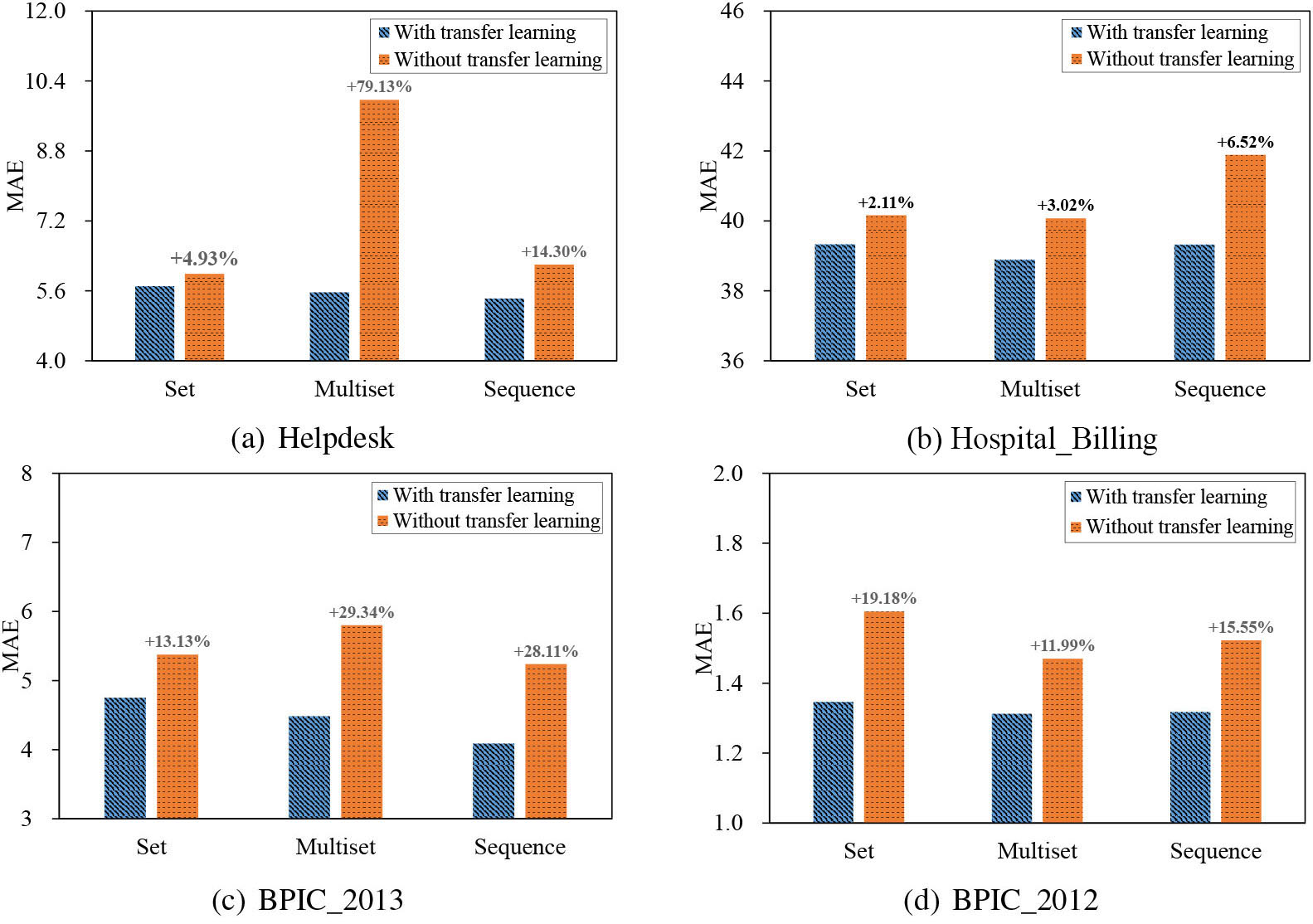
Comparison of w/o transfer learning on different states.
Not surprisingly, it can be seen that after removing abnormal traces, the performance of every time prediction approach is significantly improved. The improvements are much more notable when evaluated with MSE. This is mainly attributed to the fact that the traces with large execution time actually dominate the MSE evaluation results. It also should be noted that the proposed AETS exhibits more significantly improved performance compared to baselines in terms of both evaluation measures on the datasets with abnormal traces removed, which verifies the superiority of our proposed time prediction approach. From this experiment, lessons we can learn is that it can be beneficial to remove abnormal traces (e.g., that with relatively large execution time) before applying remaining time prediction approaches.
The impact of dimension reduction by auto-encoder
In this section, we analyze the impact of auto-encoder on dimension reduction experimentally. We specifically train remaining time prediction models with the following two strategies:
With Auto-encoder: The raw encoding vectors of traces are condensed by auto-encoder before used as the input of multi-layer perceptrons as described in Section 4.3. Without Auto-encoder: The raw encoding vectors of traces are directly used as the input of multi-layer perceptrons.
Both the above remaining time prediction models use the same transition systems that are built with the sequence, set and multiset state representations, respectively.
The performance of the two remaining time prediction models in terms of MAE is shown in Fig. 8. It can be seen that the remaining time prediction models with auto-encoder consistently and significantly outperform the ones without auto-encoder, regardless of datasets and state representations. More specifically, the advantage of auto-encoder is more significant with multiset and sequence state representation, mainly due to the fact that the raw trace encoding vectors are sparser when states in transition systems are represented as multiset and sequence. This result demonstrates that dimensionality reduction of trace encoding is vital for the success of the proposed approach.
In this section, we experimentally analyze the impact of the remaining time prediction model training strategy based on transfer learning. We specifically train remaining time prediction models with the following two strategies:
With transfer learning: The remaining time prediction models for each states in transition system are trained jointly as described in Section 4.4.2. Without transfer learning: The remaining time prediction models for each states in transition system are trained separately.
Figure 9 shows the results of the above two training strategies in terms of MAE. It can be seen that transfer learning is consistently superior to separate training. It is worth noting that up to a 70% improvement is achieved on the Helpdesk dataset. This verifies the importance of transfer learning for training high-quality remaining time prediction models.
In order to further explore the advantage of the proposed model training strategy, we conduct a more detailed analysis of the remaining time prediction results. Figure 10 shows the remaining time prediction results w.r.t. each state of the transition system, where the horizontal axis corresponds to each state and the vertical axis shows the corresponding MAE value. Here, the states are sorted according to the number of trace prefixes mapped to the state (i.e.,
In this paper, we have studied the task of predicting the remaining execution time of business process instances through fusing process modeling and deep learning techniques. Specifically, we have proposed an extension of transition system, i.e., Auto-Encoded Transition System (AETS) for remaining time prediction. Business process instances are first encoded by taking into account the execution information of each business process instance itself and the global state information of the information system. Then, stacked auto-encoder is used to tackle the high sparsity issue of raw trace encoding, and multi-layer perceptron is trained with a transfer learning strategy to construct the remaining time prediction models for each state of the transition system. Extensive experiments on four real event log datasets demonstrate that the proposed AETS can significantly reduce the MAE and MSE values of the remaining execution time prediction results compared with state-of-the-art baselines.
As future work, we plan to explore more advanced transfer learning strategy that can leverage the correlation among the states in transition system, such that the remaining time prediction models for different states can be jointly trained in a more effective manner. Furthermore, how to improve the interpretability of deep-learning-based remaining time prediction model is worth further exploration.
Footnotes
Acknowledgments
This work is partially supported by Natural Science Foundation of China (Grant No. 61602278, 71704096, and U1931207), the Taishan Scholars Program of Shandong Province (Grant No. TS20190936), and the Science and Technology Support Plan of Youth Innovation Team of Shandong Higher School (Grant No. 2019KJN024).