
Abstract
This paper focuses on the influence maximization problem in social networks, which aims to find some influence nodes that maximize the spread of information. Most existing achievements usually adopt a uniform propagation probability, without considering the topic information. Moreover, the classic Independent Cascade Model and its approximations have suffered from much running time. To overcome this limitation, this paper proposed a Topic based Shortest Path Set algorithm (TSPS). Additionally, a comprehensive set of experiments are conducted on large real-world networks, showing that our proposal provides more impressive results in the aspects of influence spread and running time.
Introduction
As the paper all feel now, the social media cloud [1, 2, 3, 4] has gradually become a data storage platform for various social networks, such as Facebook, Bright Cloud, and Twitter. There is little doubt that the number of people publishing ideas or opinions on social networks is overtly increasing. Thus a large amount of information can propagate by “word-of-mouth” in social networks, such as ideas and topics [5].
Let us suppose the following examples in product marketing. To advertise a new product, viral marketing wants to select some initial users that will potentially recommend the product to a large number of other users, which could maximize the influence mostly in the form of “word-of-mouth”. Some other examples include rumor blocking and analyzing people’s behavior, which can be analyzed similarly. In the above examples, it is a natural issue to find a relatively superior way to sort out influential users from whom to maximize their influence over others. The context problem, named influence maximization [6], is meant to design the solution to single out top-K influential nodes that could maximize the total number of affected nodes from a social network. In the literature, the paper emphasizes addressing the maximization of influence that runs through large-scale networks [7, 8].
Over the last several years, the influence maximization analysis has attracted considerable research interests. There are some models which simulate information dissemination in networks, among which Independent Cascade Model (IC) [6, 9] is widely used. The IC model is a well-known probabilistic model of the connections. More concretely, each node is associated with the same influence probability to activate its neighboring nodes, and the probability indicates the power of one node influencing its neighbors. Note that the probability needs to be predefined without taking some important information into accounts, such as topics and user interest in different topics. However, the existence of the topic-sensitive phenomenon has been observed in many social networks [10, 11, 12, 13], i.e., a user usually follows his friends since they share the same topics, and his friends also probably follow back because of the same reason. In other words, the propagation process of different topics is different in real networks. Therefore, how to define the probability is worthy of consideration to obtain more realistic results. Moreover, both the IC model and its approximate approaches such as the greedy algorithm [6] have a serious drawback-suffering from much running time, which is not scaled to large networks successfully as the paper will point out in Section 2.
Since social networks are usually topic-sensitive and large-scale in reality, it is necessary to improve a novel algorithm by considering the topic and running time. To account for the above problems, the paper proposes the heuristic algorithm TSPS by modeling topic-level influence maximization on large-scale networks. Expressly, the proposed TSPS takes (1) the results of a predefined topic distillation based on Latent Dirichlet Allocation (LDA) [14, 15, 16]; (2) the extended IC Model to accommodate user interest in different topics; (3) the heuristic strategy based on the shortest path set [17, 18]. Extensive experiments illustrate that the TSPS algorithm achieves significantly better results in terms of impact propagation and running time for specific topics, which is in contrast with other methods (including the original greedy method and several existing heuristic algorithms).
In a word, the main contribution of this paper is to propose and evaluate a topic-based heuristic method that addresses the influence maximization problem in social networks. The contribution details are summarized below.
Based on putting forward to the topic-level influence maximization problem formally, we present a generative EIC model that is able to capture the topic link information in social networks. Different from the original IC model which simply sets to propagate uniformly in influence diffusion process [9], the paper emphasizes measuring the strength of topic-level influence quantitatively. In particular, the paper takes the results of topic distillation based on the LDA, and then adapt to user preferences source from the calculation results of topic distillation by extending the traditional IC model. The paper proposes a novel heuristic strategy based on the shortest path set to select the most influential users that maximize the influence. Especially, the paper firstly computes the maximum propagation probability paths that nodes pairs occupy and then selects the maximum one to construct the shortest path set, which can maximize the number of nodes activated by a set of selected designated seeds. The proposal provides significantly better results owing to incorporating topic and heuristic strategy by conducting adequate contrast experiments with other related algorithms on large real-world networks.
The rest paper is structured as follows. The second of the paper outlines the related works. Then, the next section depicts the TSPS algorithm we developed. Section 4 introduces experimental results and validates the computational efficiency derived from our method. At last, our conclusion of this paper is given in the fifth one.
Our breakthrough is the intersection of maximizing influence and topic targeting. Here the paper gives an overview of the related literature on these topics.
Much effort has been made for influence maximization, and there is a large number of pioneering work. Usually, users can be mathematically modeled as nodes and the connections among them can be represented by edges, so that the graph composed of nodes and edges maps perfectly a social network. The influence can propagate under a stochastic cascade model [9] with the specific rules in the network, and the paper just takes the following IC Model as an example. Considering a directed graph
Note that the probability in the IC model is a predefined uniform parameter without taking some important information into account. As a result, the model neglects some important information among users, such as the information of user interest in different topics. The propagation process of different topics is different in the networks. Especially, the more interested a node and its neighbors are in the certain topic they share, the more likely the influence will happen. Therefore, without considering topic information, the results of influence maximization may be inaccurate. Consequently, the paper focus on measuring the strength of topic-level influence maximization quantitatively by using the LDA algorithm. The most similar work with ours is LeaderRank [20] and TwitterRank [10]. The LeaderRank algorithm is designed to detect opinion leaders in BBS, which involves finding the interest user group based on topic analysis. TwitterRank algorithm measures the topic-sensitive influence on Twitter by using the LDA. The experimental results show that both of their work (LeaderRank and TwitterRank) outperform the original PageRank [21] and other related algorithms. Meanwhile, their work concludes that the approaches can address the shortcomings of the PageRank algorithm by taking into account topical similarity. However, LeaderRank and TwitterRank are both PageRank-based methods to detect the opinion leaders in the networks, which are not suitable for the problem of influence maximization.
In pioneering work, the influence maximization has proved to an NP-hard [7, 22] problem. Consequently, a greedy approximation is proposed to address the problem, which is visibly superior to the classic methods such as the heuristic using degree centrality. However, the greedy approach may be time-consuming for large-scale social networks, which has testified that this is a daunting mission. Therefore, later studies try to improve the algorithm’s efficiency, scaling to large social networks. Even after these improvements, the greedy algorithm and other speeds ups such as NewGreedy [22], MixGreedy [23] and TLGA [24] still take much running time on large social networks, while these methods become completely infeasible for real networks. Consequently, several recent studies try to address the efficiency issue by proposing effective heuristic algorithms using their great efficiency and speed, such as Degree Discount Heuristic [23] and TLPA [24]. Their results give us a new light in addressing the influence maximization problem. Rather than paying more attention to improving the time efficiency of the original greedy algorithm, perhaps it cannot do better than proposing new heuristic methods.
Following the above discussion, for the sake of solving the efficiency limitation of existing algorithms, the paper observes that it is necessary to look for alternative ways, such as incorporating the topic and heuristic strategy efficiently. Along this line of consideration, the paper develops a topic-based heuristic influence maximization algorithm TSPS, taking the influence of the topics into account. Additionally, the paper adopts the heuristic strategy based on the shortest path set, preventing it from much time-consuming.
Topic-based influence maximization
Overview of our method
The paper draws into first the topic-based heuristic algorithm TSPS, which combines topic and heuristic strategy efficiently and is affirmed in Section 4. The general structure of our method is illustrated in Fig. 1. The TSPS algorithm works in three stages. Firstly, for recognizing voluntarily the topics of interest to the users, the paper conducts topic distillation based on the LDA. Based on the topics distilled, the paper extends the original IC model to incorporate user interest obtained from the first stage, providing conditions for the subsequent process. At last, considering concurrently the link structure as well as the topic similarity between users, the paper applies a novel heuristic strategy based on the shortest path set for evaluating the influence of the user.
The general structure of the proposed approach TSPS.
Topic distillation is primarily intended for quantitative topic-level analysis based on the input network and topic distribution on each node. For this purpose, knowing that the LDA algorithm is a hierarchical Bayes model utilizing Dirichlet priors, which can recognize potential topic information that comes out of a large document corpus, the paper applies the algorithm for further research. The LDA involves analyzing a corpus to produce words and topics distribution for each topic and document, respectively.
In particular, a corpus of
Formally, given the hyper-parameters
Where
Finally, the marginal probabilities of a single document are multiplied to gain corpus probability:
From the generative algorithm, the LDA model can be illustrated as a probabilistic graphical model shown in Fig. 2. It is obvious that the model has three levels including corpus level, document level, and word level. At the corpus level, the parameters
Graphical representation of LDA model.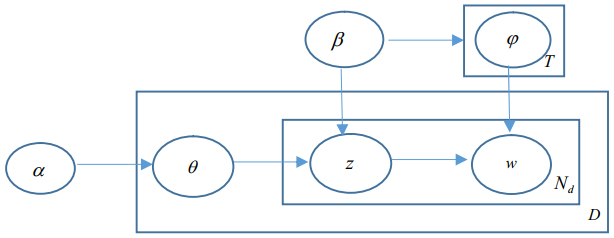
In order to use the LDA for distilling the topics users prefer, documents naturally correspond to the published posts, with each post being a document. In addition, the paper applies the Gibbs sampling algorithm for estimating model parameters
Based on the results of predefined topic distillation on the networks, the paper obtains the topic distribution which is mainly the probability distribution of users’ interest in different topics. Formally, given a directed network
Where
Obviously, the topical similarity describes the cosine distance between two nodes, and its range is from 0 to 1. The value 1 implies that users are closely related based on topics, while the value 0 implies that users are quite different.
From the approach in definition 1, the paper is able to gain topical similarity vectors set that mainly depicts the users’ influence on each topic. The vectors set can evaluate the rounded influence of users on their neighbors likewise. As the paper has discussed in Section 2, a uniform probability such as the traditional IC model can not capture the users’ interest in different topics. Therefore, the paper considers that the probability is related to user preference: the more interested the users
Depending on the applications, the traditional IC model is extended by considering topic information, called Extended Independent Cascade (EIC) model, and different probabilities can be assigned to describe the topical influence between
Similar to the original IC model, the NP-hard property also exists in the EIC model the paper proposed to find the nodes that meet the required influence, but the nice thing is that it can be approximated with a heuristic algorithm. Consequently, the paper proposes a novel heuristic strategy based on the shortest path set considering link structure as well as the similarity in users’ topics when weighing the influence of the user.
Supposing that
Since all nodes need to be activated along the path, the probability of
Where
For
Obviously, the influence of node
Thus, the paper can measure user influence by proposing TSPS algorithm, as indicated by following algorithm 1.
: TSPS algorithm: the topic-based heuristic algorithm for finding top-
The TSPS algorithm proposed runs
During the topic distillation stage, detecting community requires
Extensive experiments are carried out with our proposed TSPS algorithm and some other baseline algorithms on enough types of real-world networks. This section will illustrate the impressive performance of our proposed algorithm, generally from three perspectives: (a) the topic distillation, (b) the influence spread comparing to other algorithms, and (c) time costs comparison with others.
Experiment setup
CSDN. The dataset is crawled from the “CSDN Forum” in the period November 2016 to August 2017 (10 months), which is the largest IT technology exchange platform in China. Twitter. This is a much larger network, which is part of the most renowned micro-blogging services, provided by Kwak [25] and Yang [26] et al. The dataset includes user ID, link information and tweets. Sina Sport Forum. It gathers all the posts and comments in “Sina Sport Forum” from November 2016 to November 2017. Sina Microblog. It is inclusive of microblog content, forwarding relations and friend relations, which is chalked up in May 2014.
Table 1 depicts the concrete attributes of the above datasets.
Concrete attributes of the datasets
TSPS: Our proposed algorithm 1 discussed in Section 4. Greedy [6]: The classic greedy algorithm on influence expectation with lazy-forward optimization. We set the activation probability of a node is 1/indegree. PMIA [27]: A heuristic algorithm based on the maximum influence arborescence. When simulating the algorithm, we set CELF [28]: An optimization for greedy algorithm which gets higher effectiveness. We set the activation probability of a node is 1/indegree. Degree Discount [19]: The heuristic method with a propagation probability of PageRank [21]: The ranking algorithm popularly is applied to search engine. We set the restart probability to 0.15. Degree [6]: The degree centrality selecting nodes in order to decrease their degrees. It is a normative means to consider high-degree nodes of social networks. Random: The baseline algorithm choosing random nodes in the networks.
From the earlier experiments, there is no outstanding difference between the approximation mass for 10000 iterations and that of after 10000 even more iterations. Accordingly, for each targeted set, the paper takes the average of the simulation results processing 10000 times.
The distribution of topics for the datasets is shown in Table 2. Each topic is associated with 5 keywords that can mostly represent the content in the comments, which provide a meaningful description of the topic. Each keyword is associated with its LDA value in the back bracket.
The five topics extracted from the datasets
The five topics extracted from the datasets
As the table makes clear, the LDA can obtain meaningful clusters consistent with reality, except for the Twitter network. Perhaps it is because of the unique features of the Twitter on which the number of characters published by its users is limited, and short text language processing is quite different from traditional natural language processing.
Figure 3 compare various algorithms in influence spread for the four datasets respectively. The comparison illustrates that under all circumstances, considering the topic information can gain relatively better results. As the baseline algorithm, the Random performs very badly, which means it is necessary to select the initial nodes carefully. Because the TSPS algorithm does take the topic information into account, it outperforms other algorithms, including Greedy, PMIA, CELF, Degree Discount, Degree, PageRank, and Random, which obtains remarkably margins as the paper have expected. More concretely, the TSPS algorithm is at least 89%, 82.9%, 67.6%, and 37.9% better than other algorithms on the datasets respectively. It is worth noticing that the performance of the TSPS on Sina Microblog is not as good as on the other datasets. In addition, the changing trend of its curve is close to horizontal, which leads to about 2816 activated nodes, but makes no further progress as
The comparison of influence spread on the four datasets.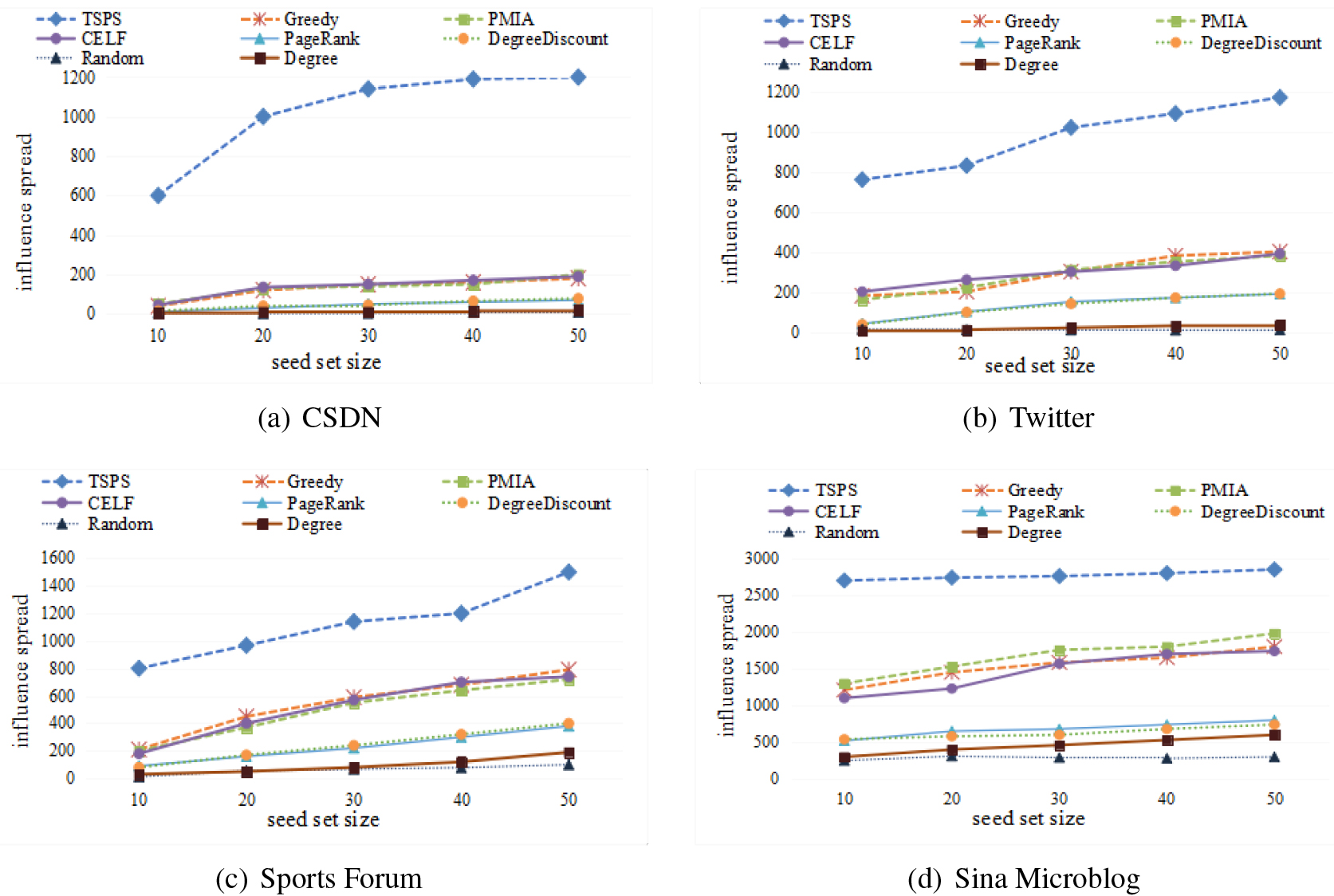
A comparison of running time on different datasets respectively.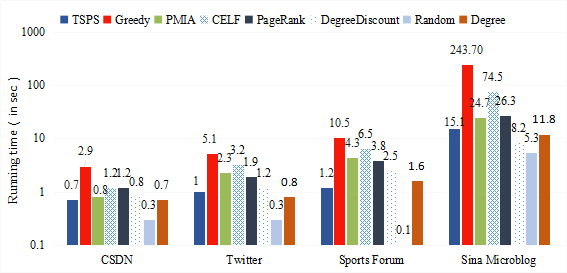
The paper put forward a topic-based heuristic algorithm TSPS, which is specifically applied to maximize the spread of the influence in the social network. Existed work only sets a uniform probability for influence propagation, which does not take topic information into account. In addition, both the IC model and its approximate approaches have suffered from a large amount of running time. Firstly, the paper conducts topic distillation based on the LDA, with the purpose of recognizing voluntarily the appealing topics to users. Secondly, the paper extends the original IC model to incorporate user preferences obtained from the first stage. At last, the paper applies a novel heuristic strategy based on the shortest path set considering link structure as well as the similarity in users’ topics when weighing the influence of the user. Our experiments on four datasets attest that our TSPS algorithm provides more impressive results in aspects whether influence spread or running time.
In the future, the paper set out to further probe into more advantages of our TSPS algorithm. As an example, the paper will try to apply the proposal to other models, including Linear Threshold (LT) [6] Model, Weighted Cascade Model, and some others. Another future work is to design an adaptive strategy to suit the dynamic social networks, since they are many aspects of uncertainness in information propagation.
Footnotes
Acknowledgments
This paper is supported by the Nature Science Foundation of China (No. 61502281, 71772107).