
Abstract
Time series forecasting has many practical applications in a variety of domains such as commerce, finance, medicine, weather, environment, and transportation. There exist so many methods developed for time series forecasting. However, most of the forecasting methods do not pay attention to anomalies in time series even though time series are sensitive to anomalies. Anomaly patterns cause negative effects on the accuracy of time series forecasting. In this paper, we propose a novel anomaly repair-based approach to improve time series forecasting in the case of anomaly existence. In our approach, an effective time series forecasting framework, EPL_S_X, is proposed with anomaly smoothing as a pre-processing stage and any existing time series prediction algorithm X. In particular, our proposed approach consists of three steps including detecting anomalies, repairing anomalies by using our smoothing method, and forecasting time series using preprocessed time series. Experimental results on several time series datasets reveal that our proposed approach improves remarkably the accuracy of many existing time series forecasting methods. It also outperforms the two robust time series forecasting methods that are based on exponential and Holt-Winters smoothing. With such better prediction performance, our approach is not only more effective but also more useful when dealing with anomalies in time series forecasting.
Keywords
Introduction
In time series data mining, forecasting in time series is one of the most complex and challenging problems, as mentioned in the review by De Gooijer and Hyndman [6]. Indeed, time series prediction has attracted many researchers as shown in their proposed works [1, 2, 4, 9, 16, 17, 18, 19, 21, 24, 28, 33]. This is understandable due to the popularity of time series in a variety of application domains and the significance of the forecasting task in practice.
From the existing research works, time series forecasting methods can be categorized into two groups. The first group includes classical methods such as ARIMA model, regression, and exponential smoothing, while the second one consists of machine-learning based methods such as k-nearest-neighbors (k-NN), artificial neural networks (ANNs), and support vector machines (SVMs). Lago et al. [16] concluded that machine learning-based methods brought out higher prediction accuracy than statistical ones.
Some recent forecasting research works based on machine learning are listed as follows. In [21], Notton et al. proposed ANNs for solar radiation estimation and forecasting in energy applications. The work in [4] used ARIMA-ANN hybrid method and empirical mode decomposition to improve forecasting accuracy of time series. Lu et al. [18] proposed a hybrid model based on improved fruit fly optimization algorithm and support vector machines for short-term load forecasting of urban gas. Bao et al. [1] proposed a hybrid model using sequential ANN and Holt-Winters models for time series prediction. Besides, Bouktif et al. [2] proposed single and multi-sequence deep learning models for short and medium term electric load forecasting. Lago et al. [16] proposed deep learning approaches and empirical comparison with traditional algorithms to forecast spot electricity prices. In short, the features of these forecasting methods in common are: (1) they only applied forecasting for some specific time series data types and (2) they do not take into account anomalies explicitly.
In practice, one of the most recurrent problems in forecasting is the presence of anomalies (outliers, noises, anomalous patterns, discords). In addition, most of the forecasting methods are sensitive to anomalies. For example in [8], Gelper et al. mentioned that anomalies can affect the Holt-Winters exponential smoothing method in two ways. First, the predicted values are affected since they depend on the current and past values of the time series including the anomalies. The second impact of anomalies involves the selection of the parameters used in the updating technique. These influences might lead to incorrect forecasted results and decreasing the effectiveness of the forecasting methods.
To alleviate the negative effects of anomalies in time series forecasting, there have been some research works which apply anomaly detection and repair to improve data before forecasting [30, 5, 25]. However most of these works use statistical-based methods in anomaly detection which are workable in specific applications. Statistical-based methods fit the statistical model or distribution to the dataset and apply a statistical inference test to determine an observation is an anomaly or not. But the main drawback of statistical methods is that data often do not match a particular distribution.
Realizing that time series anomaly detection has many beneficial uses for data mining, including data cleaning and forecasting, in this work, we aim to devise a novel anomaly repair-based approach to improve time series forecasting in the presence of anomalies. This approach consists of three main steps: anomaly detection, anomaly repair, and prediction. These steps help handling anomalies in a general context where time series data of various kinds can be applied and any prediction method can be utilized after the time series is cleaned out of the anomalies. To realize this purpose of the work, we propose a time series forecasting framework, named EPL_S_
Compared to the existing methods for time series forecasting in the case of anomaly existence, our method is the first general framework that performs anomaly detection and repair in order to improve forecasting accuracy without requiring that the data fit any statistical model or distribution. In fact, our proposed approach is a data-driven method which does not require any domain knowledge from experts. Besides, an extensive empirical evaluation has been done on several datasets with different trend, and seasonal characteristics and from various application domains. The experimental results show that our method outperforms the existing time series forecasting methods and especially improves remarkably the prediction performance of many existing time series prediction methods. In short, our method is not only effective but also practical when reducing the influence of anomalies in time series forecasting.
The rest of the paper is organized as follows. Section 2 presents some related works on time series forecasting and anomaly detection. Section 3 describes the proposed anomaly-repair-based approach for time series forecasting. Section 4 reports the main experiments to check the effectiveness of our approach. Finally, Section 5 gives some conclusions and future works.
Related works
Time series forecasting
In time series mining, time series forecasting is a task that takes a time series
In practice, time series forecasting is a popular but non-trivial task because of the popularity and characteristics of time series in a variety of application domains. Indeed, time series are present in many applications where objects and their relationships are recorded over time. In addition, time series in each application may have their own characteristics. Some typical ones are trend, seasonality, periodicity, irregularity, randomness, etc. These characteristics challenge the time series forecasting task. The task is more challenging when noises, outliers, or anomalies exist in the input time series.
In the existing works, trend and seasonal time series have been considered in forecasting task with different proposed methods. As introduced in [32], a trend in a time series is the long-term change in the level of the data. In the case of time stretching, the series moves upward, it is said that the data show a positive trend. Otherwise, the series moves downward, it is said that the data show a negative trend. Trends in time series clearly violate the condition of stationary. A seasonal pattern occurs in a time series when there is a regular variation in the level of the data that repeats itself at the same time each year. The term “season” is used to represent a period of time before the behavior begins to repeat itself. A cyclical (periodic) pattern is represented by a wavelike upward and downward movement of the data around the long-term trend. Cyclical fluctuations are of longer durations and are less regular than seasonal fluctuations.
Among the existing forecasting methods, a few of them [8, 17] paid attention to handling anomalies. In the work [8], Gelper et al. proposed two Robust Forecasting versions for exponential smoothing, a well-known classical method for time series forecasting. Exponential smoothing is a simple technique used to forecast a time series without the necessity of fitting a parametric model. It is based on a recursive computing scheme, where the forecastings are updated for each new incoming observation. The Holt-Winters method, also called as double exponential smoothing, is an extension of exponential smoothing for trended and seasonal time series. In [8], two proposed versions for Holt-Winters method, called RHW and RHW’, can handle outliers in time series. These two robust versions perform outlier detection and smoothing before prediction. However, they can detect and smooth out only point anomalies while time series in real world areas usually contain subsequence anomalies. Gelper et al. perform outlier detection and smoothing by applying Kalman filter [20] to the state-space model associated with exponential and Holt-Winters smoothing. Experimental results on two datasets reveal that RHW and RHW’ bring out better prediction results than the original Holt-Winters method.
Loc and Anh [17] proposed a method of anomaly detection and repair to improve Holt-Winters forecasting. This method can detect and smooth out subsequence anomalies. However, one drawback in this method is that it detects anomalies by using BFDD (brute-force discord discovery) algorithm proposed by Keogh et al. [12] which is a simple and inefficient window-based method for anomaly detection in time series. Therefore, this method can be improved upon.
In short, both of the above-mentioned forecasting methods used simple methods in anomaly preprocessing for only exponential smoothing forecasting method. By contrast, we propose a forecasting approach that can handle anomaly detection and repair with a combination of more efficient techniques and can work for any forecasting method.
Anomalies in time series
A top anomaly pattern in a time series is a subsequence that is maximally different from other subsequences in that time series. This is the most commonly-used and intuitive definition for anomaly subsequence, given by Keogh et al. [12]. Notice that anomaly in this definition is subsequence anomaly, not point anomaly. That means the anomalies we consider in this paper are contextual and based on a local context [5]. Figure 1 illustrates a top anomaly in an electrocardiogram (ECG) time series [27].
An anomaly in ECG time series.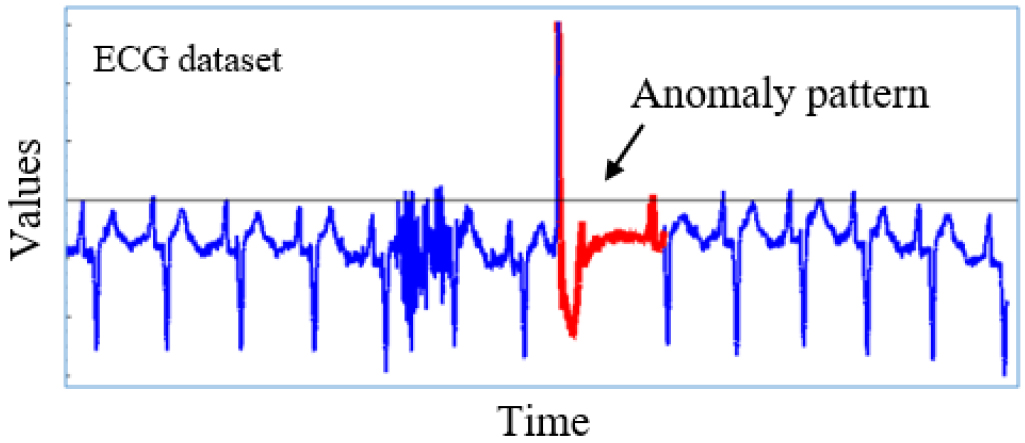
The anomalies might reduce the performance of a time series forecasting task because they introduce abnormal behaviours that are not common ones observed with the time series. They may mislead the process to incorrect forecast results. Therefore, anomalies in the input time series of the task should be detected and repaired to ensure the effectiveness of the forecasting results.
Outlier/noise/anomaly handling is a well-studied topic in knowledge discovery. However, surprisingly, this topic is still limited in time series forecasting as previously reviewed with only two research works [8, 17]. This situation motivates us to develop an approach to deal with time series forecasting with the presence of anomalies.
To handle this problem, we first need to detect where anomalies are located in time series. Up to now a lot of anomaly detection methods have been proposed for time series data. They are listed as Brute-Force and HOT SAX of Keogh et al. in 2005 [12], WAT of Bu et al. in 2007 [3], a method based on segmentation and Finite State Automata by Salvador and Chan in 2005 [23], a method based on segmentation and cluster-based outlier detection by Kha and Anh in 2015 [15] and EP-Leader-DTW proposed by Thuy et al. [27]. Among these anomaly detection methods, EP-Leader-DTW, in our previous work, is the most recent one that can detect anomalies accurately and efficiently with Dynamic Time Warping, the most effective distance measure for time series data. Therefore, in our proposed approach for time series forecasting, EP-Leader-DTW is used to detect anomalies in time series before forecasting. With high accuracy of anomaly detection, EP-Leader-DTW does not bring out false alarms in time series anomaly detection.
EP-Leader-DTW is the anomaly detection algorithm proposed by Thuy et al. [27] with four steps:
Step 1: Segmentation. This step uses the important extreme points method proposed by Fink and Gandhi [7] to segment time series into subsequences. Step 2: Transformation. A homothetic transformation is performed to transform subsequences of different lengths into subsequences of the same length by using the average length of all the extracted subsequences. Step 3: Clustering. The Leader algorithm proposed by Hartigan [10] is used to cluster similar subsequences into the same clusters. EP-Leader-DTW then calculates the anomaly scores of all the subsequences by using the formulas given by Thuy et al. [27]. Step 4: Anomaly Detection. EP-Leader-DTW finally determines the subsequence with the largest anomaly score as the top anomaly subsequence of the time series.
As compared to the other anomaly detection methods, EP-Leader-DTW does not require users to predetermine the length of the anomaly subsequence. Instead, EP-Leader-DTW uses two parameters, compression rate – R and clustering threshold –
The following is a brief comparison between Euclidean and DTW distance measures to clarify the effectiveness of EP-Leader-DTW when DTW is used.
Euclidean distance (ED) is the most commonly-used distance measure between two time series. ED measures the dissimilarity between two time series by aligning the point-to-point observations at the same time. Therefore, ED is very sensitive to distortions in the time axis. However, the advantage of ED is its linear execution time.
Euclidean distance (left) and DTW distance (right) [13].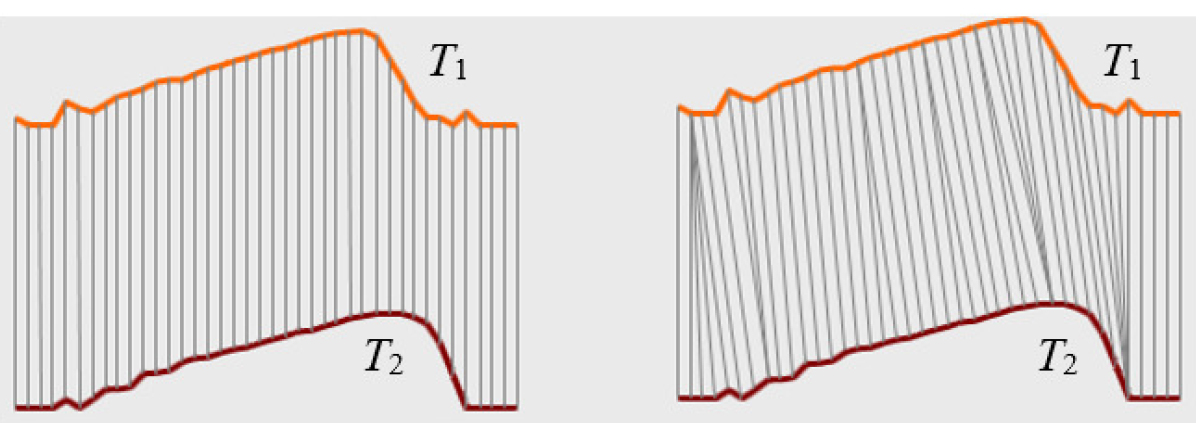
By contrast, DTW is suitable for calculating a distance between two time series that do not need to be aligned point-to-point at the same time (see Fig. 2) [22]. In addition, DTW can compute the distance between two time series with different lengths. Moreover, as mentioned in the work of Wang et al. [29], DTW is significantly more accurate than ED for time series classification on small datasets while converged to ED on larger datasets. Nevertheless, the disadvantage of DTW is high time complexity. In order to use DTW efficiently, methods based on DTW need to use some techniques to speed-up DTW calculation. A well-known speed-up technique is lower-bounding. One of the popular lower-bounding techniques is LB_Keogh proposed by Keogh and Ratanamahatana in 2005 [13].
To handle the time series forecasting task in presence of anomaly patterns, we devise an anomaly repair-based framework, called EPL_S_
Anomaly repair-based approach to time series forecasting
Anomaly handling is normally handled in the data preprocessing phase of a knowledge discovery process. Similarly, we define an anomaly repair stage as a data preprocessing phase before time series forecasting by any existing time series prediction method. Our approach consists of the three following main steps.
Step 1: Anomaly detection. In this step, the input time series is processed for finding anomalies if any. These anomalies are explicitly identified as abnormal subsequences in the input time series. Step 2: Anomaly repair. The resulting anomalies in Step 1 are processed to become normal subsequences in the input time series. In other words, those anomalies are smoothed out of the time series. The input time series after this step is considered clean with no anomaly patterns. Step 3: Prediction. The clean time series produced from Step 2 is then used for forecasting. Any time series forecasting method can be applied on this clean time series. Its output, which includes forecast data points, is also the output of our time series forecasting approach.
In our forecasting approach, no restriction on the data characteristics of time series is counted on. This implies that our approach is not bound with any specific kind of time series data or their application domains. Besides, in Step 2, our proposed approach tries only to clean anomalies and preserves all other information in the time series data.
EPL_S_
The pseudo code of EPL_S_
1. Anomaly detection with EP-Leader-DTW
A
2. Anomaly adjustment with Anomaly-Repair
3. Prediction with an existing time series prediction method
4. Return
The pseudo code of our smoothing method, Anomaly-Repair(), is presented as follows.
1. Group formation.
Unusual_Group, Normal_Group
2. Unusual subsequence adjustment.
real_s
Unusual_Group
3. Return
After detecting the positions of anomaly subsequences, a smoothing technique is defined to clean these anomaly subsequences. There have been some smoothing techniques to clean outliers or noises out of a time series, such as, moving average, exponential smoothing and regression methods. However, due to the specific properties of our EP-Leader-DTW algorithm, in this work, we devise a new technique to perform anomaly smoothing. This technique is performed by our Anomaly-Repair module. The target of this module is to decrease unusually great values or increase unusually small values of data points toward the values which are considered normal. The question is how to determine which values are unusually large and which values are unusually small and then how to adjust their values so that no anomaly exists under any form in the preprocessed time series for prediction. The details of Anomaly-Repair method are described as follows.
Based on anomaly scores computed by EP-Leader-DTW, we divide subsequences into two groups by using Split() function. The first group, Unusual_Group, contains the subsequences whose anomaly scores are approximately similar to that of the most unusual subsequence. The second group, Normal_Group, contains the rest of subsequences extracted from the time series. In this function, at first, the most anomaly subsequence is put into the Unusual_Group group. After that, all the subsequences whose anomaly scores are almost the same as that of the most anomaly subsequence are put into this unusual group. We can measure their score differences by means of an approximated score ratio, e.g. 10%. The remaining subsequences of the time series are put into the normal group.
Once these two groups are formed, anomaly repair is carried out to reduce the abnormal level of the anomalies in the unusual group. In this step, we examine each homothetic transformed subsequence which is anomaly and refer back to its corresponding real subsequences so that all the unusual subsequences of the input time series can be adjusted accordingly. To extract the real subsequence of a homothetic transformed subsequence
After the unusual group is updated, each of its members is considered for adjustment in a point-by-point manner. For each data point
Finally, all the smoothed subsequences in the Unusual_Group group and those in the Normal_Group group are merged by means of Merge() function to produce the preprocessed time series
Characteristics of EPL_S_X
According to the design of EPL_S_
The main characteristics of EPL_S_
EPL_S_ EPL_S_ EPL_S_
In this section, we evaluate the proposed forecasting approach EPL_S_
Research questions
Question 1: Does our proposed approach EPL_S_ Question 2: Can our anomaly-repair strategy improve some typical prediction methods in terms of prediction accuracy?
Notice that, Gelper et al. [8] proposed Robust Holt-Winters method (RHW) and a variant of RHW (RHW’) for forecasting time series in presence of outliers. These two methods were evaluated on the Thermostat Sales time series (with trend) and the Resex time series (with trend and seasonality). Different from RHW and RHW’, our approach is more general. Therefore, we will use a version of our proposed approach which uses a particular forecasting method to compare with the two Robust Smoothing methods.
As for the second question, the generality of EPL_S_
For empirical evaluation, we implemented the comparative forecasting methods in Visual C#. All the experiments were conducted on an HP Intel
In our experiments, 14 datasets are used as described in Table 1. The first four time series datasets are downloaded from the webpage [26]. The next five time series datasets are from the webpage [11]. The tenth and eleventh datasets are downloaded from the UCR Time series Classification/Clustering [14]. The last three datasets are downloaded from the UCI webpage [31]. Shown in Table 1, these datasets come from various application domains such as transportation, environment, commerce, medicine, finance, economy, production, and energy. Their lengths are also varying. In addition, most of them have trends together with seasonal variations although the patterns are quite different from dataset to dataset. Besides these datasets, we also used the Thermostat Sales time series in [8] for the experimented related to Question 1.
To ensure the presence of anomalies in tested time series, anomaly embedding was made at random positions in all the 14 above-mentioned datasets as well as Thermostat Sales dataset. Each dataset was divided into two parts. The first part includes 2/3 data points of time series and the second one includes the rest data points. The first part is used for training and the second one for testing. Finally, only one-step-ahead forecasting was considered in all of the experiments.
Datasets used in the experiments
Datasets used in the experiments
Regarding to the comparative prediction methods for the experiment related to Question 2, we used some well-known prediction methods such as linear regression (abbreviated as LR), k-nearest neighbors (k-NN), artificial neural networks (ANN), and the hybrid method proposed in [1] (Hybrid). Their parameter settings were made in the trial-and-error scheme. These prediction methods have been used for time series forecasting in the context of no concern about anomalies. In this experiment these methods are improved with our anomaly-repair strategy to become EPL_S_LR, EPL_S_kNN, EPL_S_ANN, and EPL_S_Hybrid, respectively. Among these comparative methods, for the experiment related to Question 1, we use EPL_S_kNN to compare with the two Robust Holt-Winters methods (RHW and RHW’) in [8].
For measuring the accuracy of the forecast results, we used the mean squared error (MSE), the mean absolute error (MAE), and the mean absolute percentage error (MAPE (%)) as follows.
In these equations, n is the length of time series,
In this subsection, we present the experimental results in Table 2 for the experiment related to Question 1 and those in Tables 3–8 for the experiment related to Question 2. In these tables, the best results are presented in bold.
MSE values of RHW, RHW’ (Gelper et al. [8]), and EPL_S_
NN on Thermostat sales time series
MSE values of RHW, RHW’ (Gelper et al. [8]), and EPL_S_
MSE values for time series forecasting with LR, EPL_S_LR, k-NN, EPL_S_kNN without and with anomaly repair strategy
MSE values for time series forecasting with ANN, EPL_S_ANN, Hybrid, EPL_S_Hybrid without and with anomaly repair strategy
In this experiment, we compare the prediction performance of EPL_S_
To be unbiased, we used the experimental results reported in Gelper et al. [8] to compare to those of our EPL_S_
In Fig. 3, we used the Thermostat Sales time series in two cases. Since there is no outlier in Thermostat Sales dataset, we embedded outliers (noises, anomalies) into this dataset at different positions. For the first case (3a), we create an outlier at position 35 and in the second case (3b), another outlier at position 7. We used these two different outlier positions to test the degree of influence of the outlier position on the outcome of the forecasting method. On Thermostat Sales time series, we also examined both EPL_S_
Thermostat Sales time series forecasted by EPL_S_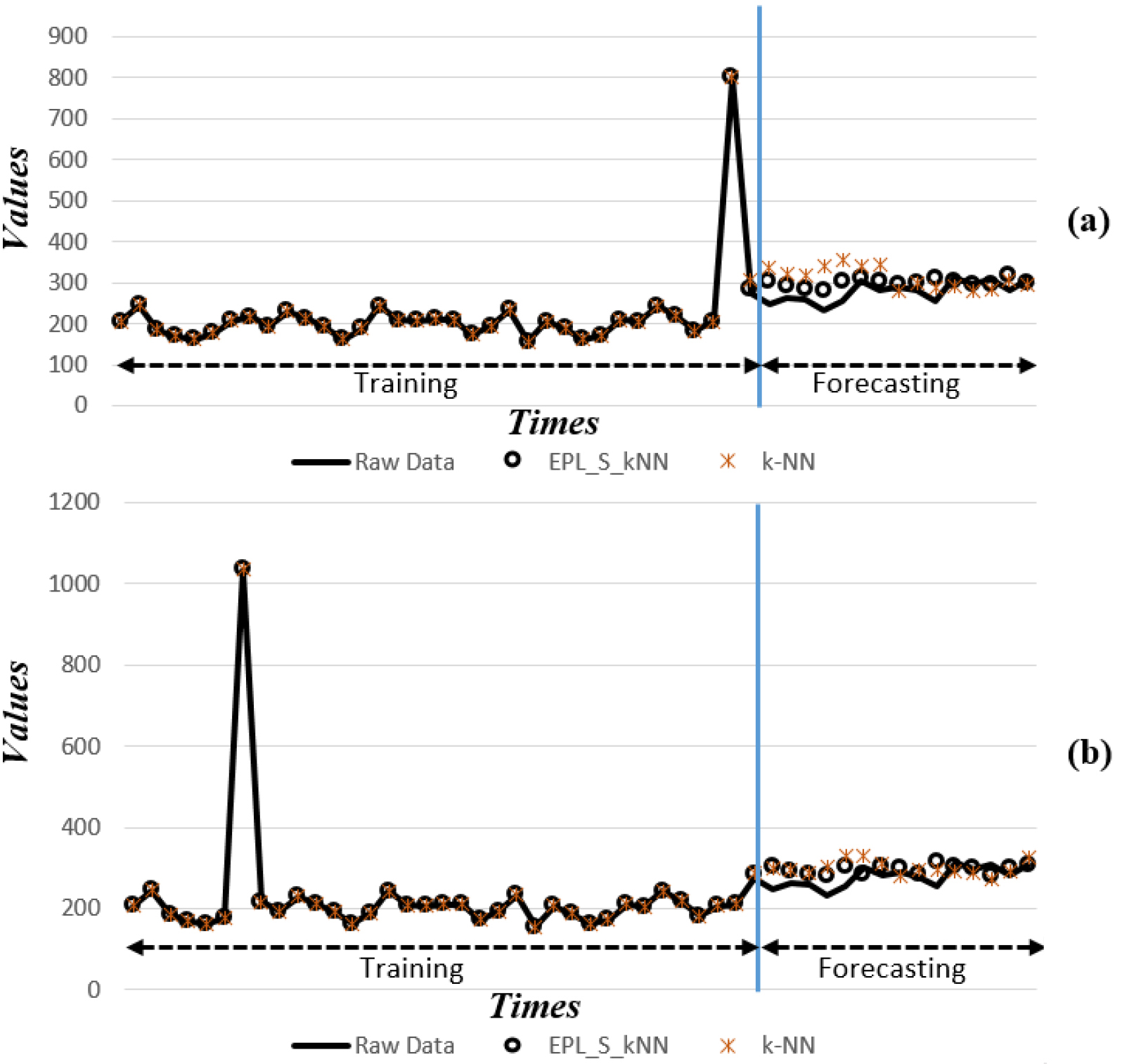
For the experiments, we prepared training and test datasets for forecasting Thermostat Sales time series. Displayed in Fig. 3, the left part of the blue line shows a part of data used for training, the right part of the blue line shows the data forecasted by the two methods EPL_S_
MAE values for time series forecasting with LR, EPL_S_LR, k-NN, EPL_S_kNN without and with anomaly repair strategy
MAE values for time series forecasting with ANN, EPL_S_ANN, Hybrid, EPL_S_Hybrid without and with anomaly repair strategy
Shown in Table 2, we compared the MSE values obtained from [8] to those from our experiments using EPL_S_
From the results in Table 2, the MSE values of RHW and RHW’ methods are larger than those of EPL_S_
In Tables 3–8, we report the experimental results for three evaluation criteria collected from various comparative prediction methods over different datasets. In Tables 9 and 10, the improvement rates of EPL_S_
MAPE values for time series forecasting with LR, EPL_S_LR, k-NN, EPL_S_kNN without and with anomaly repair strategy
MAPE values for time series forecasting with LR, EPL_S_LR, k-NN, EPL_S_kNN without and with anomaly repair strategy
MAPE values for time series forecasting with ANN, EPL_S_ANN, Hybrid, EPL_S_Hybrid without and with anomaly repair strategy
As for the simple forecasting method LR (linear regression), the MSE values from EPL_S_LR are smaller than those obtained from the pure LR for all of the 14 datasets. The MSE improvement rate of EPL_S_LR over LR is about 87.9 times on average. Similarly, MAE and MAPE values from EPL_S_LR are also smaller than those from the pure LR for all 14 datasets. In addition, the MAE improvement rate of EPL_S_LR over LR is about 6.3 times and the MAPE improvement rate is about 5.7 times on average. In sum, the prediction performance of LR using our anomaly repair strategy is remarkably better than that of LR without using our anomaly-repair strategy.
Not only LR but also all the other well-known forecasting methods like k-NN and ANN provide better prediction results when applying our anomaly-repair strategy over all the 14 datasets. For example, the MSE values obtained from EPL_S_kNN are smaller than those from the pure k-NN for all the 14 datasets. This is also reflected through the fact that the MSE improvement rate of EPL_S_kNN over k-NN is about 2.2 times. Similarly, for all the datasets, the MAE and MAPE errors produced by EPL_S_kNN are smaller than those by the pure k-NN. On average, the MAE improvement rate of EPL_S_kNN over k-NN is about 1.4 times and the MAPE improvement rate is about 1.5 times.
As for artificial neural network (ANN), EPL_S_ANN improves ANN in terms of prediction accuracy remarkably over all of the 14 datasets. The MSE, MAE, and MAPE improvement rates of EPL_S_ANN over ANN shown in Table 6 are about 142.5, 7.3, and 6.7 times, respectively. For example, for the very short time series dataset S&P, EPL_S_ANN can provide MSE value 23.81 times better than the one yielded by the pure ANN without anomaly detection and repair.
Improvement rates of EPL_S_X over X where X is LR, k-NN
Improvement rates of EPL_S_X over X where X is ANN, or Hybrid
In addition to the single prediction methods as discussed above, our anomaly repair-based approach can improve a hybrid prediction method proposed in [1], denoted as Hybrid. This Hybrid method combines Holt-Winters’ exponential smoothing and artificial neural networks in order that it can take advantage of the benefits of the two methods. This is because the ANN model can capture nonlinear features hidden in the time series and the Holt-Winters’ exponential smoothing can capture some trend and seasonal features in the time series. The experimental results show that EPL_S_Hybrid can dramatically reduce MSE, MAE and MAPE errors over all the 14 datasets. The MSE, MAE, and MAPE improvement rates of EPL_S_Hybrid over the pure Hybrid are about 4.8, 1.8, and 1.7 times, respectively.
Original time series (solid line), the predicted time series by EPL_S_kNN (circle line), and by the pure k-NN ( star line) on Expenditure dataset.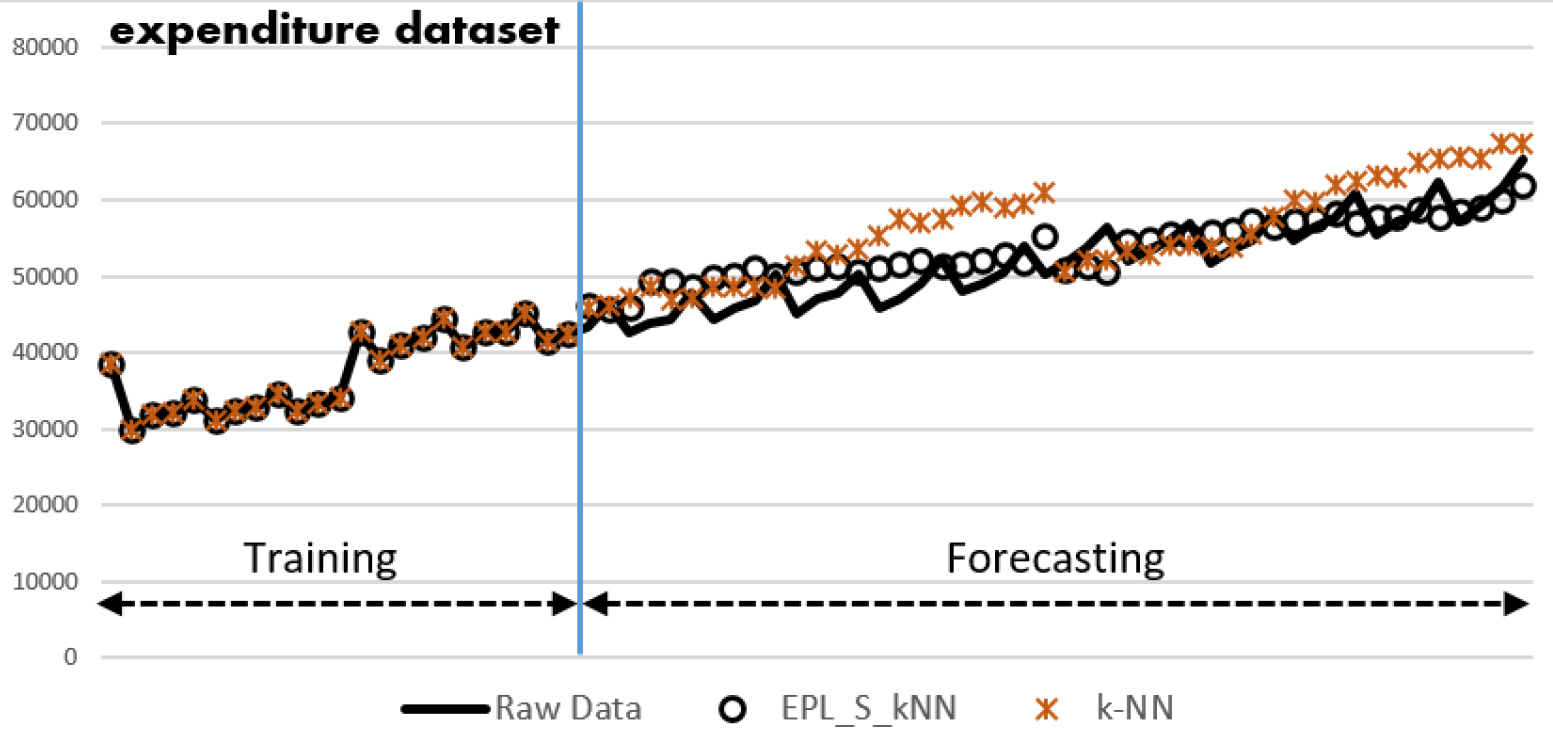
Figure 4 displays point-to-point comparison between actual values (in solid) and predicted values (by EPL_S_kNN in circle, or by k-NN in star) on Expenditure dataset. In Fig. 4, by using EPL_S_kNN, predicted data points are closer to actual data points than predicted data points by using k-NN. Due to space limitation, just only the experiment results on Expenditure dataset is illustrated graphically in Fig. 4. For the Expenditure dataset, we forecast 49 data points at the end of the training part of the time series.
Generally speaking, experimental results in Tables 3–10, and Fig. 4 indicate that the forecasting framework EPL_S_X brings out remarkably better forecast results than any comparative prediction method, X where X is LR, k-NN, ANN, or Hybrid on all the 14 datasets with different lengths and different periodic, trend, and/or seasonal characteristics from various application domains. From this experiment, it is recommended that in the presence of anomalies, an anomaly-repair based approach should be used before applying an existing prediction method in order to improve the prediction performance.
Our explanation to why the preprocessing with anomaly repair can improve forecasting accuracy is that the anomaly patterns in a time series may account for the dominance of its total variance. Models that ignore these anomaly patterns will result in a high variance thus poor forecasting accuracy.
Improving prediction accuracy is a very important problem in time series forecasting. So far, most of the time series forecasting methods do not take anomalies into account before forecasting although anomalies always appear in time series. Anomalies usually have a strong impact on the accuracy of the forecasting results. Handling them through a process of anomaly detection and repair before forecasting is thus necessary for several prediction applications.
In this paper, we propose a novel time series forecasting framework, EPL_S_
Many experiments have been conducted on 14 datasets in many different application domains to confirm the effectiveness of our EPL_S_
In the future, we intend to extend our method for online time series forecasting in many application domains that need on-line forecasting. Moreover, we will consider a new version of our framework by utilizing a deep neural network-based forecasting method.
Footnotes
Acknowledgments
This research is funded by Ho Chi Minh City University of Technology (HCMUT), VNU-HCM, under grant number BK-SDH-2022-8141217.