
Abstract
Although achieving remarkable progress, it is very difficult to induce a supervised classifier without any labeled data. Unsupervised domain adaptation is able to overcome this challenge by transferring knowledge from a labeled source domain to an unlabeled target domain. Transferability and discriminability are two key criteria for characterizing the superiority of feature representations to enable successful domain adaptation. In this paper, a novel method called learning TransFerable and Discriminative Features for unsupervised domain adaptation (TFDF) is proposed to optimize these two objectives simultaneously. On the one hand, distribution alignment is performed to reduce domain discrepancy and learn more transferable representations. Instead of adopting Maximum Mean Discrepancy (MMD) which only captures the first-order statistical information to measure distribution discrepancy, we adopt a recently proposed statistic called Maximum Mean and Covariance Discrepancy (MMCD), which can not only capture the first-order statistical information but also capture the second-order statistical information in the reproducing kernel Hilbert space (RKHS). On the other hand, we propose to explore both local discriminative information via manifold regularization and global discriminative information via minimizing the proposed class confusion objective to learn more discriminative features, respectively. We integrate these two objectives into the Structural Risk Minimization (RSM) framework and learn a domain-invariant classifier. Comprehensive experiments are conducted on five real-world datasets and the results verify the effectiveness of the proposed method.
Introduction
Supervised learning has achieved remarkable progress in many fields with the help of a large number of labeled training samples [1]. However, when there are few and even no labeled samples, it is difficult to, if not impossible, induce a supervised classifier. Rather, there is a need for versatile algorithms that reduce the need for large labeled datasets across multiple domains. Unsupervised domain adaptation address this need by transferring knowledge from a different but related domain (source domain) with labeled samples to a target domain with unlabeled samples to improve the performance of the target domain [2]. For example, an object classification model trained on manually annotated images may not generalize well to new images obtained under substantial variations in pose, occlusion, or light. Domain adaptation aims to enable knowledge transfer from the labeled source domain to the unlabeled target domain by exploring domain-invariant features that bridge different domains [3].
The error matrix of different methods on tasks D 
Transferability and discriminability are two key criteria that characterize the superiority of feature representations to enable domain adaptation [5, 6, 3, 7, 4]. The transferability indicates the ability of feature representations to bridge the discrepancy across domains, and we can effectively transfer a learning model from the source domain to the target domain via the transferable feature representations [3, 7, 4]. Discriminability refers to the ability to separate different categories easily by a supervised classifier trained on the feature representations, and the model can achieve better classification performance via the discriminative feature representations [6, 5].
Since the source samples and target samples are drawn from different distributions, it is important to reduce the distribution discrepancy across domains to learn transferable features. The mostly used shallow domain adaptation approaches include instance reweighting [8, 9] and distribution alignment [3, 7, 4]. The former assumes that a certain portion of the samples in the source domain can be reused for learning in the target domain and the samples from the source domain can be reweighted according to the relevance to the target domain. While the latter assumes that there exists a common space where the distributions of two domains are similar and focus on finding a feature transformation that projects features of two domains into another common subspace with less distribution discrepancy [3, 7, 4]. Maximum Mean Discrepancy (MMD) [10] based methods are popular methods for distribution alignment, where the MMD distance is used to evaluate the distribution discrepancy across domains.
While achieving remarkable progress, the experiments in [5] indicate that previous domain adaptation methods tend to enhance the transferability at the expense of deteriorating the discriminability. Thus, some methods, including geometrical based methods [11] and manifold regularization based methods [12, 6], also aim to improve the discriminability of the feature representations. Geometrical based methods consider the geometric divergence between both domains or the variance information in the target domain. Manifold regularization based methods are inspired by manifold assumption [13], which can make the predicted label of a certain sample consistent with its neighbor samples.
An overview of the proposed method. (a) Before adaptation, the source classifier can not perform well in the target domain. (b)–(c) After learning transferable and discriminative features, the domain discrepancy can be reduced and the samples can be classified correctly.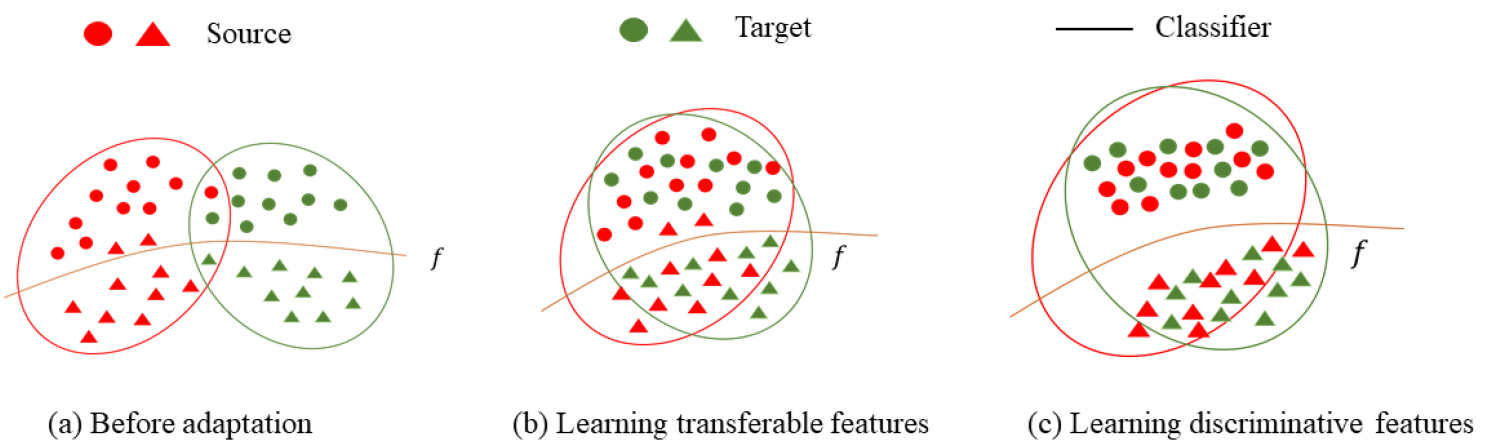
However, there are two issues with the existing methods. (1) To learn transferable features, MMD distance is a widely used statistic to measure the distribution discrepancy by kernel mean embedding of distributions. However, MMD distance only measures the first-order statistic of different distributions in reproducing kernel Hilbert space (RKHS). Some recent experiments have revealed that the second-order statistic (such as CORAL [14]) is also important to capture useful information for evaluating distribution discrepancy, which is ignored by many methods. (2) To learn discriminative features, previous methods mainly focus on local discriminative information (i.e., sample-level discriminative information), but ignore the global discriminative information (i.e., class-level discriminative information). For example, the classifier trained in the source domain may confuse to distinguish the correct class from a similar class [15], such as backpack and video-projector. As shown in Fig. 1a and b, the probability that a source-only model (only trained with labeled source data) misclassifies backpacks as video-projectors in the target domain is over 28%. This phenomenon is named class confusion and it reminds us that the global discriminative information should also be considered.
To overcome these issues, in this paper, we propose a novel method called learning TransFerable and Discriminative Features for unsupervised domain adaptation (TFDF), which learns a domain-invariant classifier under the principle of Structural Risk Minimization (SRM) to solve the above two issues simultaneously. An overview of the proposed method is shown in Fig. 2. For the first issue, we adopt the recently proposed statistic called Maximum Mean and Covariance Discrepancy (MMCD) [16] to measure and decrease the distribution discrepancy across domains. MMCD is comprised of MMD and Maximum Covariance Discrepancy (MCD). MCD evaluates the Hilbert–Schmidt norm of the difference between covariance operators and can measure the second-order statistic in the RKHS. Therefore, MMCD can consider the first-order and the second-order statistics simultaneously in the RKHS and can capture more distribution information than MMD. For the second issue, we aim to learn more discriminative features at both local and global levels. At the local level, we use the manifold regularization to further exploit the similar geometrical property of the nearest points. At the global level, instead of focusing on the feature space, we concentrate on the label space. We consider the confusion relationship between different classes which is revealed by the inner product of the classifier predictions between different classes (shown in Fig. 1). The goal is that no examples are ambiguously classified into two classes at the same time. Thus we force the inner product of the same class close to 1 while the different classes close to 0, which encourages the samples in the same class to be more compact while the samples in the different classes to be more dispersed. Thus, TFDF can extract discriminative features.
To sum up, besides minimizing the empirical error in the source domain, TFDF also concentrates on minimizing the distribution discrepancy across domains to learn transferable features and exploring both global and local discriminative information to learn discriminative features. However, TFDF is a non-convex problem that is difficult to be solved directly, so we firstly propose a variant of TFDF named TFDF-V, which is a convex optimization problem that is easy to be solved with a closed-form solution. Then, taking the solution of TFDF-V as the initial value of TFDF, we use the Adam algorithm [17] (a variant of stochastic gradient descent) to solve the TFDF optimization problem. Comprehensive experiments on five different real-world cross-domain visual recognition datasets are conducted, and the results verify the effectiveness of the proposed algorithm.
Transferability in domain adaptation
Shallow domain adaptation
Shallow domain adaptation methods include instance reweighting and distribution alignment. Instance reweighting based methods assume that the data from the source domain can be reused in the target domain by reweighting samples. Tradaboost [8] is the most representative method which is inspired by Adaboost [18]. The strategy of adjusting the weights of the source and target data is just the opposite, where the source data more conducive to the target data have greater weight in the source domain. LDML [19] also evaluates each sample, and takes full advantage of the pivotal samples, and filters out outliers. DMM [9] learns a transfer support vector machine by extracting invariant feature representations and estimating unbiased instance weights, to jointly minimize the cross-domain distribution discrepancy. However, the performance by instace reweighting is not satisfying.
Distribution alignment based methods focus on finding a feature transformation that projects features of two domains into another common subspace with less distribution discrepancy. The distribution discrepancy across domains includes marginal distribution discrepancy and conditional distribution discrepancy. TCA [3] tries to align marginal distribution across domains, which learns a domain-invariant representation during feature mapping. Based on TCA, JDA [7] tries to align both marginal distribution and conditional distribution simultaneously. Moreover, BDA [20] proposes a balance factor to leverage the importance of different distributions. MEDA [4] can dynamically evaluate the balance factor and has achieved promising performance. The above methods are all based on MMD, which only captures the first-order statistical information across domains. CORAL [14] explores the second-order statistic covariance of the target distribution. Many previous methods only adopt the first-order statitic information while ingore the second-order statistic information. Our method adopts MMCD [16] to evaluate the distribution discrepancy across domains and can capture more useful information for domain adaptation.
Deep domain adaptation
Most deep domain adaptation methods are based on statistical discrepancy minimization. DDC [21] embeds a domain adaptation layer into the Alexnet [22] and minimizes Maximum Mean Discrepancy (MMD) distance between features of this layer. DAN [23] minimizes the feature discrepancy between the last three layers of Alexnet [22] and the multiple-kernel MMD is used to measure the discrepancy. Other measures are also adopted such as Kullback-Leibler (KL) divergence, Correlation Alignment (CORAL) [24] which measures the second-order statistical information and Central Moment Discrepancy (CMD) [25] which measures the high-order statistical information. These methods can utilize the deep neural network to extract more transferable features and also have achieved remarkable performance.
Recently, Inspired by the generative adversarial network [26], adversarial learning is widely used in domain adaptation. DANN [27] adopts a domain discriminator to distinguish the source domain from the target domain, while the feature extractor is trained to learn domain-invariant features to confuse the discriminator. ADDA [28] designs a symmetrical structure where two feature extractors are adopted. Different from DANN, MCD [29] proposes a method to minimize the
Discriminability in domain adaptation
Learning transferable features may harm the discriminability of the features. Therefore, learning discriminative features is another objective for domain adaptation methods. Inspired by Linear discriminant analysis (LDA) [30], some methods take the geometrical information into consideration. For instance, the goal of JGSA [31] is to minimize the geometrical divergence across domains to enhance the discriminability in shallow domain adaptation. JJDA [32] extends this idea to deep domain adaptation and considers the instance-level discriminative information. Besides, LPJT [12] considers the manifold regularization via fisher criterion. ARTL [6] and MEDA also use the manifold regularization via local samples. These methods mainly focus on local discriminative information while the global discriminative information is ignored. TFDF can learn both local and global discriminative information, thus making the features more discriminative.
Method
Problem definition
In this paper, we focus on unsupervised domain adaptation. There are a source domain
Overall objective
Transferability and discriminability are two key criteria that characterize the superiority of feature representations to enable domain adaptation [5, 6, 3, 7, 4]. Thus, TFDF aims to learn a domain-invariant classifier
Minimizing the source empirical error of the labeled data in the source domain. Minimizing the distribution discrepancy across domains to learn transferable features. Minimizing the manifold regularization to learn local discriminative features. Minimizing the proposed class confusion loss to learn global discriminative features.
The learning framework of TFDF is then formulated as:
where
In the next subsections, we introduce each objective separately and give the learning method finally.
The first objective of TFDF is to learn an adaptive classifier that can classify source samples correctly. To begin with, we can induce a standard classifier
where
and the Eq. (2) can be represented as:
where
The distribution discrepancy across domains will result in performance degradation when directly applying the classifier trained in the source domain to the target domain. Thus, TFDF aims to learn transferable features to reduce the distribution discrepancy, which includes marginal distribution discrepancy and conditional distribution discrepancy.
Maximum Mean Discrepancy (MMD) is a widely used statistic to measure distribution distance, which compares different distributions
However, MMD only measures the first-order statistic of different distributions. Some experiments have revealed that the second-order statistic (such as CORAL [14]) is also necessary to capture useful information for evaluating distribution discrepancy, which is ignored by existing methods. Recently, a new distribution metric termed Maximum Mean and Covariance Discrepancy (MMCD) is proposed in [16]. MMCD considers both the first-order and the second-order statistical information in the RKHS, which is defined as,
where
where
Based on MMCD, the distribution discrepancy across domains can be written as
where
where
where
.
Given the constraint that
where
where
In domain adaptation, we except to learn discriminative features for better classification and adaptation. In this work, local discriminative information refers to the sample-level discriminative information. Manifold regularization is a widely used method to extract local discriminative features. According to the manifold assumption [13], if two points are close in the intrinsic geometry, then the corresponding labels are similar. Under this assumption, the manifold regularization is computed as
where
where
Maximizing manifold regularization can only learn local discriminative information from the nearest neighbors while the global discriminative information (i.e., class-level discriminative information) is ignored. As shown in Fig. 1a and b, there exists class confusion in domain adaptation methods, which means that the classifier trained in the source domain may confuse to distinguish the correct class from a similar class, such as backpack and video-projector. In order to solve this problem, instead of focusing on the feature space, we concentrate on the label space, where the prediction outputs are able to reveal the class relationships. we use the prediction outputs of the samples in both domains to minimize the class confusion. The prediction of the classifier
where
Note that
Recall that
Note that previous methods only learn discriminative features at the instance level (local level). However, by enforcing different classes to seperate from each other, the proposed method can learn discriminative features at the class level (global level).
By substituting Eqs (4), (14), (15), (19) into Eq. (1), we can get the optimization problem as follows,
where
Equation (3.7) is an optimization problem with constraints, which is difficult to be solved directly. We relax the problem as an unconstrained optimization problem, namely
[tp] :
[tp] :
Since the fifth term of Eq. (21) is a non-convex fourth-order term, the optimization problem doesn’t have the closed-form solution. Therefore, we adopt the adaptive moment estimation (
We experimentally found that it is important to set a proper initial value. Thus, we propose a variant of optimization Eq. (21) which is named as
Note that
In this section, we evaluate the performance of TFDF by extensive experiments on five widely-used common datasets. Codes will be available online upon publication.
Data preparation
We adopt five public image datasets: Office
The
Baselines
We compare the performance of TFDF with traditional machine learning approaches, several state-of-the-art traditional approaches, and deep domain adaptation approaches:
traditional machine learning approaches: 1-Nearest Neighbor ( traditional domain adaptation approaches: Transfer Component Analysis ( deep domain adaptation approaches:
For fair comparison and following [3, 35], 1NN, SVM and PCA are trained on the labeled source data, and tested on the unlabeled target data; Other traditional domain adaptation methods (e.g. TCA, JDA) are performed on both the source data and the target data and tested to classify the unlabeled target data. All the baselines except MEDA are performed in original feature space. While MEDA [4] and TFDF firstly perform manifold feature learning to project the original feature to a new feature space with
where
Under our experimental setup, it is impossible to tune the optimal parameters using cross validation, since labeled and unlabeled samples are from different distributions. Thus following previous methods [7], we evaluate all methods by empirically searching the parameter space for the optimal parameter settings, and report the best results of each method. We set number of nearest numbers by searching
In the comparative study of TFDF, we set 1)
The results on five real-world cross-domain (object, digit and object) datasets are shown in Tables 1–3. From these results, we can draw several observations:
Accuracy (%) on Office-Caltech datasets using SURF features
Accuracy (%) on Office-Caltech datasets using SURF features
Firstly, TFDF achieves the best performance in most tasks (7/12 tasks) on the Office-Caltech dataset (SURF features). The average accuracy of TFDF on the Office-Caltech dataset (SURF features) is 54.1%, while the best baseline is MEDA with 52.7%. Compared with MEDA, the average performance Accuracy (%) on Office-Caltech datasets using DeCaf6 features
Accuracy (%) on USPS
Ablation study
We conduct an ablation study to analyze how different components of our work contribute to the final performance. When learning the final classifier, TFDF involves four components: Structural Risk Minimization (SRM), Distribution Alignment (DA), Local Discriminative information (LD), and Global Discriminative information (GD). We empirically evaluate the importance of each component. To this end, we investigate different combinations of four components and report average classification accuracy on five datasets in Table 4. The first setting where only SRM is used is actually the source-only method where no adaptation is performed and this setting performs the worst. It can be observed that the accuracy is further improved after performing Distribution Alignment (DA). And the use of both global and local discriminative information improves the performance significantly on all datasets. Finally, a combination of all components can achieve the best results.
Results of ablation study (accuracy (%))
Results of ablation study (accuracy (%))
We run JDA, MEDA, and TFDF on task
MMD distance, classification accuracy on the task 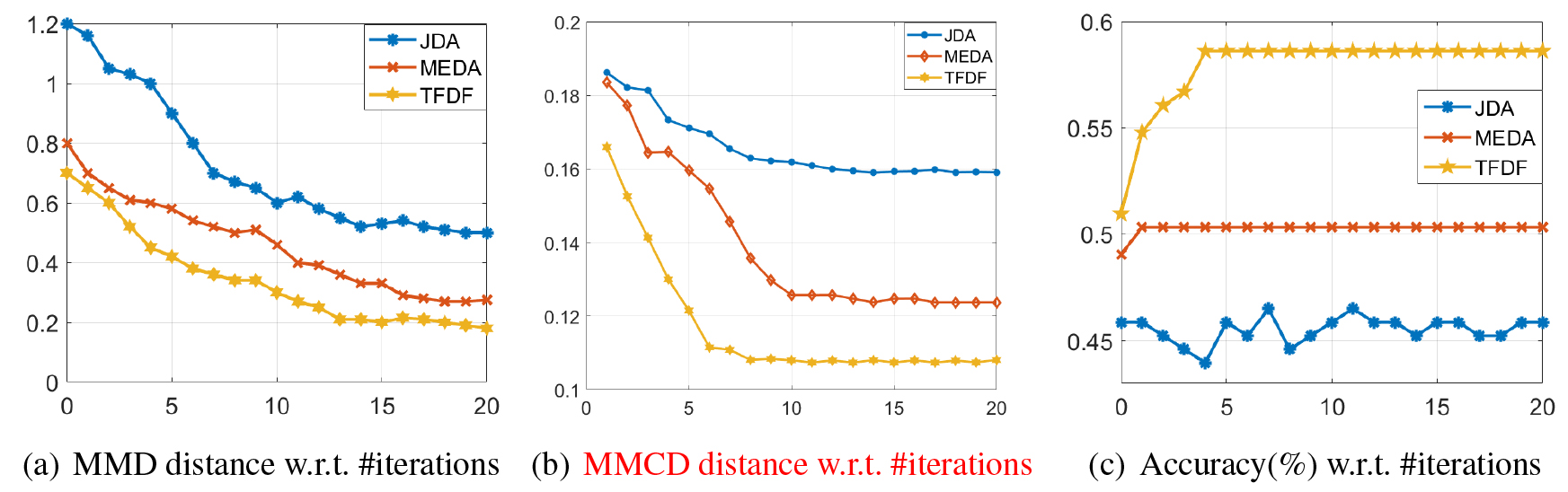
Figure 3a and b show the MMD distance and MMCD distance computed for each method and Fig. 3c shows the prediction accuracy for each method. As we can see, MEDA and JDA can reduce the domain discrepancy which can be measured by either MMD distance or MMCD distance and achieve good performance in the target domain while TFDF achieves better results. JDA only considers the first-order statistic, while TFDF adapts both the first-order and the second-order statistics. Besides, by minimizing class confusion, TFDF can learn more discriminative features and improve performance.
In Fig. 4, we visualize the feature representations of task USPS
Time complexity
We run JDA, MEDA, and TFDF on datasets Office-Caltech, COIL, and USPS
Runing time on different tasks
Runing time on different tasks
Feature visualization on task 
Parameter sensitivity on three tasks.
In this section, we evaluate TFDF with a wide range of values for regularization parameters
Conclusion
In this paper, we propose a method called learning TransFerable and Discriminative Features for unsupervised domain adaptation (TFDF), which could learn both transferable and discriminative features simultaneously. On the one hand, we adopt a recently proposed statistic called MMCD to measure domain discrepancy, which can capture both the first-order and the second-order statistical information simultaneously, thus more statistical information can be explored than MMD-based methods. On the other hand, we propose to learn both local and global discriminative features through manifold regularization and proposed class confusion loss respectively. With the principle of empirical risk minimization, TFDF also integrates the source classification error with the above objectives into a uniform optimization problem. Comprehensive experiments are conducted and the results verified the effectiveness of the proposed method.
Footnotes
Acknowledgments
This paper is supported by the National Key Research and Development Program of China (Grant No. 2018YFB1403400), the National Natural Science Foundation of China (Grant No. 61876080, No. 62002137), the Key Research and Development Program of Jiangsu (Grant No. BE2019105), the Collaborative Innovation Center of Novel Software Technology and Industrialization at Nanjing University.
Appendix A. Proof of theorem 1
According to [16], we can approximate the convex upper bound of the second
The first equation holds because