
Abstract
Software maintainability is a significant contributor while choosing particular software. It is helpful in estimation of the efforts required after delivering the software to the customer. However, issues like imbalanced distribution of datasets, and redundant and irrelevant occurrence of various features degrade the performance of maintainability prediction models. Therefore, current study applies ImpS algorithm to handle imbalanced data and extensively investigates several Feature Selection (FS) techniques including Symmetrical Uncertainty (SU), RandomForest filter, and Correlation-based FS using one open-source, three proprietaries and two commercial datasets. Eight different machine learning algorithms are utilized for developing prediction models. The performance of models is evaluated using Accuracy, G-Mean, Balance, & Area under the ROC Curve. Two statistical tests, Friedman Test and Wilcoxon Signed Ranks Test are conducted for assessing different FS techniques. The results substantiate that FS techniques significantly improve the performance of various prediction models with an overall improvement of 18.58%, 129.73%, 80.00%, and 45.76% in the median values of Accuracy, G-Mean, Balance, & AUC, respectively for all the datasets taken together. Friedman test advocates the supremacy of SU FS technique. Wilcoxon Signed Ranks test showcases that SU FS technique is significantly superior to the CFS technique for three out of six datasets.
Keywords
Introduction
In the current scenario, developing such software that does not require any changes is not only impractical but also economically unviable since the needs and demands of the customers keep changing with time and environment. Any effort put to keep up with these changes after the delivery of the product to the customers is termed as software maintenance, and the ease to carry out these changes is referred to as software maintainability [86]. Over the years, the maintenance phase of any Software Development Life Cycle (SDLC) has become an indispensable part of any software product development. Resultantly, software maintainability has become crucial for the quality of any software. However, tracking this maintainability is complex. Not only this, maintenance is also the most costly phase of any SDLC, which consumes a vital portion of the resources in terms of effort, time, and money. The software industry is still striving hard to unveil effective ways and means to cope with the maintenance behavior of different software. This is done with a view such that the cost of maintenance is minimized, and the quality of the software is improved. Various metrics and models in respect of Software Maintainability Prediction (SMP) have already been proposed and implemented by different researchers over the years. These include the famous Chidamber and Kemerer (C&K) metrics suite [15], Li and Henry metrics suite [54], etc. Further, the proposed models include various Machine Learning (ML), meta-heuristic, ensemble, and other statistical models for predicting maintainability [3, 6, 59, 61].
However, the problem of imbalanced data still remains unsolved while predicting maintainability. Data is said to be imbalanced when data points in a particular dataset are distributed in an uneven manner, i.e., the number of occurrences of the instances for one particular class is much larger than that of the other class [32]. This imbalance often leads to inefficient learning and miscategorization of the minority class subjected to the lack of information related to the minority class. Specifically, as in our case, the Low Maintainability (L-M) class contains fewer instances as compared to the High Maintainability (H-M) class where L-M class refers to those data points that require more number of changes whereas the H-M class includes those data points that require only a few changes in the source. It is crucial to predict these classes correctly with high accuracy since the software maintenance team primarily needs to know about L-M classes as these classes essentially demand more attention and effort during the maintenance phase. Therefore, Importance Sampling (ImpS) algorithm for imbalanced classification problems has been applied in the current study to cater to the problem of the imbalanced data for a valid prediction, where L-M pertains to the minority class and H-M pertains to the majority class.
This study’s primary goal is to investigate different Feature Selection (FS) techniques and their effect in SMP. FS is a technique that chooses a subset of features from a larger set of all the available features while removing the unessential and irrelevant ones without any notable loss of information. FS elevates the performance of various prediction models by increasing the prediction accuracy since any inconsistency in terms of features is now removed. The main idea behind FS selection is to pick such a subgroup of features which is minimal in size and follows the criteria including, (1) there is no significant decrease in the classification accuracy and (2) the resulting distribution of the class, given the chosen features, is as much identical as possible to the original distribution of class, given the complete set of features [22]. It is required to choose a suitable set of features since any model’s predictive capability is majorly dependent on the set of input features used for the training of that model. Several Object-Oriented (OO) metrics belonging to the famous Li and Henry suite [54] have been used as an input to the various prediction models developed in this study. Since it is tough and tedious to decide on the best set of OO metrics to be fed into the prediction models manually; therefore, three different techniques, namely, Symmetrical Uncertainty (SU) (an Entropy-based filter), RandomForest Filter (RFI), and Correlation-based Feature Selection (CFS) have been used here for FS.
Subsequently, the effectiveness and the performance of these FS techniques have been compared and evaluated using eight different ML algorithms, viz., Support Vector Machines (SVM), Random Forest (RF), Decision Tree (Recursive Partitioning and Regression Trees) (DT (rpart)), k-Nearest Neighbor (kNN), Bagged CART, Gaussian Process with Radial Basis Function Kernel (GPRR), C4.5-like Trees, and Conditional Inference Random Forest (CIRF). All the techniques of handling imbalanced data, FS, and the ML algorithms mentioned above have been empirically evaluated using six datasets. These datasets include one open source, i.e., Drumkit, three proprietary, i.e., EASY Classes Online (EASY), File Letter Monitoring System (FLMS), and Inventory Management System (IMS) and two commercial, i.e., Quality Evaluation System (QUES) and the User Interface Management System (UIMS) datasets. Before using these datasets for carrying out the current work, the descriptive statistics for each of the datasets were calculated, followed by a normality test named the Shapiro-Wilk Test. This test is carried out to examine the hypothesis if the distribution of the various OO metrics being taken into account for the development of the prediction model is normal or not.
Furthermore, initially, the dependent variable in these datasets known as ‘Change’ was continuous representing the sum total of the count of lines that have been added (counted as 1), deleted (counted as 1), or modified (counted as 2) in the source code. However, for conducting this study, the continuous variable ‘Change’ has been converted into a binary variable known as ‘Maintainability’ consisting of two values or classes, i.e., L-M and H-M. The conversion of the continuous variable ‘Change’ to a binary variable has been done following the criteria given by Dallal [20] in his study, and the details for the same have been discussed in the subsequent sections. Outlier identification and removal have also been performed for all the datasets using the Inter Quartile Range (IQR) filter.
The prime objectives of the current work to investigate and assess the effectiveness of different FS techniques have been formulated as the following Research Questions (RQs):
Whether the performance of different ML algorithms used in this study improves markedly by using various FS techniques for predicting software maintainability? Which FS technique performs the best amongst the different FS techniques evaluated in this study? Does any significant difference exist between different pairs of FS techniques analyzed in this study?
Further, the performance of the prediction models so developed using different combinations of FS and ML techniques has been assessed and compared using one traditional metric, namely, Accuracy and the three stable metrics of performance, namely, G-Mean, Balance and Area under ROC Curve (AUC). 10-fold cross-validation has also been used while developing SMP models. Eventually, two statistically significant tests viz., the Friedman Test and the Wilcoxon Signed Ranks Test have also been performed for all the four metrics of performance as stated above to compare and evaluate the effectiveness of various FS techniques.
The remaining paper follows: – Section 2 furnishes the related work advancing towards the research background in Section 3, including data preprocessing (datasets, OO metrics, Shapiro-Wilk test analysis, conversion of datasets into binary, and removal of outliers) and handling of imbalanced datasets. Further, Section 4 extends the details of the research methodology, such as FS techniques, ML algorithms, cross-validation, performance metrics, Friedman Test, and the Wilcoxon Signed Ranks Test. Subsequently, Section 5 discusses the results, and Section 6 lays the threats to validity. Lastly, Section 7 concludes and closes with an insight into future directions.
The present section covers the related work in the concerned field of study and is further divided into two sub-sections. The first sub-section discusses the previous studies related to SMP, whereas the second sub-section reports the previous studies pertaining to FS techniques.
Background work related to SMP
According to the literature, various ML models and metrics have already been proposed and developed for SMP by different researchers as elaborated here in this section. A study about the validation of OO metrics with maintainability was conducted by Li and Henry [54] in 1993. In 2003, the significance of the OO metrics like inheritance and coupling for SMP was studied by Dagpinar and Jahnke [18] indicating that size and direct coupling are essential predictors of maintainability whereas indirect coupling, inheritance and cohesion are not. In 2005, Thwin and Quah [78] studied the role of Neural Networks (NN) in foreseeing software quality utilizing the OO metrics. In the next two years, i.e., Koten and Gray [48] in 2006, and Zhou and Leung [83] in 2007 applied the Bayesian network and the Multivariate Adaptive Regression Splines (MARS), respectively for SMP on UIMS and QUES datasets with promising results. Further, in 2006, Aggarwal et al. [1] examined the usefulness of Artificial NN (ANN) for SMP. A few years later, in 2009, Elish and Elish [26] proposed a novel and competitive TreeNet model for predicting maintainability. Next year, in 2010, Kaur et al. [45] applied several techniques in soft computing for SMP with Adaptive Neuro Fuzzy Inference System (ANFIS) being the most precise technique. In 2012, Malhotra and Chug [61] put forth three ML algorithms including Genetic Algorithms (GAs), the Group Method of Data Handling (GMDH), and Probabilistic NN (PNN) for SMP; proving the superiority of GMDH technique in predicting maintainability. Further, Dubey et al. [24] proposed Multi Layer Perceptron (MLP) model for SMP using QUES and UIMS datasets in the same year.
The very next year, i.e., in 2013, Jia et al. [42] and Ahmed and Al-Jamini [2] proposed the fuzzy-logic-based models for the prediction of maintainability. Also, Olatunji and Ajasin [63] presented the Sensitivity-based Linear Learning Method (SBLLM) and Extreme Learning machines (ELM) for SMP with promising results for already explored datasets, i.e., UIMS and QUES. Further, Malhotra and Chug [59, 60] successfully applied the GMDH technique and the Evolutionary Algorithms (EAs) for SMP in 2014. After that, in 2015, Elish et al. [25] introduced three effective empirical studies using ensemble methods for predicting maintainability and Kumar et al. [50] validated the efficacy of OO metrics for SMP. Next year, in 2016, Kumar and Rath [51] came up with the hybrid Functional Link ANN (FLANN) approach for SMP, which performs even better when combined with FS techniques like PCA. Again in 2016, Chug and Malhotra [16] gave a standard framework for the prediction of the maintainability value of open source system with genetic-based adaptive learning and GMDH techniques performing the best. In the same year, Datyal et al. [23] proposed a PCA-based MLP model for SMP using the datasets from a repository of NASA called Promise. In 2017, Kumar and Rath [52] used the hybrid NN and the fuzzy logic approach combined with parallel computing for an efficient and improved maintainability prediction. Further, in 2018, Baskar and Chandrasekar [6] recommended a neuro-PSO based SMP model, and Alsolai et al. [3], in the same year, proposed the utility of ensemble techniques in the prediction of maintainability. Recently, in 2019, Alsolai and Roper [4] described a plan to predict OO maintainability using ensemble techniques, and Jha et al. [41] put up a deep learning approach for SMP by affirming the usefulness of the proposed approach. Further, Wang et al. [80] brought forth a fuzzy network-based framework for SMP utilizing the metrics’ data of the system software as well as the subjective assessment of the experts. In 2020, Gupta and Chug [29, 31] proposed and assessed the cross-project technique and an enhanced random forest algorithm for SMP in two of their respective studies. Not only this, Gupta and Chug [30] also propounded the utility of Least Squares Support Vector Machines (LS-SVM) for SMP of open source datasets in the same year.
Background work related to FS techniques
FS techniques help to deal with the problems that arise due to a large in number group of the features such as the problem of redundant and irrelevant occurrence of features, over-fitting, dimensionality curse, etc. by producing precise results and in turn save time, effort and money when combined with different ML algorithms. In 1997, Jain and Zongker [39] proved the supremacy of sequential forward floating selection FS technique for the classification of land use, and Kohavi and John [47] discussed the wrapper methods for FS. In 2001, Das [21] examined the pros and cons of both, the wrapper and the filter methods of FS and proposed a competitive and novel hybrid algorithm for FS using boosting. Sometime later, i.e., in 2003, Gunnalan et al. [28] put forth a new FS method using TAR2 which assumes that a small number of features would be sufficient while selecting the preferred classes. In the same year, Dash and Liu [22] focussed on those FS techniques which were based on consistency. Further, in 2005, Liu and Yu [55] thoroughly examined, compared, and evaluated the existing FS methods and presented a unifying platform for FS. In the same year, Chen et al. [13] studied the wrapper methods of FS for SMP and the results improved remarkably on removing irrelevant features. A few years later, in 2014, Chandrashekar and Sahin [12] surveyed different FS methods, whereas Khalid et al. [46] carried out a survey on both the FS and the Feature Extraction (FE) techniques in ML. In 2016, Xue et al. [81] surveyed the evolutionary computational approaches to FS. Brezocnik et al. [10], in 2018, analyzed the mechanisms and usage of swarm intelligence based methods of FS in several application domains. In 2019, Sayed et al. [71] came up with a successful improvisation of the existent Crow Search Algorithm (CSA) know as the novel Chaotic CSA (CCSA) for FS. Further, Rao et al. [67] also introduced an efficient FS method using bee colony and gradient boosting DT in the same year. Recently, in 2020, Solorio-Fernández et al. [74] reviewed the unsupervised methods of FS by stating and comparing their pros and cons. Again, in the same year, Zheng et al. [82] put forth an unsupervised FS method based on the concept of self-placed learning for handling the outliers.
It is observable from the research work mentioned above that though a wide range of studies has been conducted both in the field of SMP and related to the FS techniques individually, none of the studies has carried out an extensive investigation and analysis to study the effect of different FS techniques in predicting maintainability. Although there have been some SMP studies that have made use of FS techniques [16, 23, 31, 52], the role of FS techniques has not been systematically explored for the SMP task. This happens in spite of the availability of a number of FS techniques and their effective implementation and seemingly noteworthy performance in improving the predictive performance in several fields of study. Therefore, in this paper, the authors have carried out a comparative analysis of how various FS techniques perform for the prediction of software maintainability in order to bridge the above identified research gap. Subsequently, bridging this gap with the help of the current study advocates for the novelty and creativity of this work while conducting an exclusive and comprehensive analysis of the effect of several FS techniques in improving SMP. Here, the authors analyze three different FS techniques for comparison and claim that the performance of the SMP models so developed improves on using FS techniques, which further adds to the creativity and worth of this study.
Research background
This section explains the datasets, the OO metrics, the descriptive statistics and their analysis, and the Shapiro-Wilk Test.
Definition table for the OO metrics [54]
Definition table for the OO metrics [54]
Various datasets used in the current study are described in this subsection as follows:
Open Source: A software whose code is open and freely available for the purpose of downloading, reusing or for modification is considered as open source. It can be easily accessed by the developers in no time, irrespective of their geographical location all over the globe. Open source software is free from the copyright issues and can be customized without any payment of fee.
Drumkit (91 classes): A game based on Java Mobile on the JAVA-JME platform in which a drum kit is created virtually. The users can play this drum just by tapping the screen.
Descriptive statistics
(Min.
Proprietary: The software whose code is closed and not available freely are known as the proprietary software. These software are owned by their publisher or some person who retains their copyright.
EASY (58 classes): A web portal for use by an educational institution that provides the material for study and an online system for evaluation. FLMS (34 classes): A customized, web-based file monitoring system that tracks the file movement among different departments of a particular organization by maintaining a log file. IMS (47 classes): An inventory management system for maintaining the stock of a company at various branch-offices located within different cities.
Commercial: The software developed for a commercial purpose with an objective of earning money fall under the category of commercial. These software also have proprietary license which allows their free use but does not allow any modification in the existing code.
QUES (71 classes): A system for quality evaluation; designed and developed in Classic-Ada. UIMS (39 classes): A system for the management of user interface; again developed using Classic-Ada.
Further, the current study uses ten OO software metrics as the independent variables, i.e., DAC, DIT, LCOM, MPC, NOC, NOM, RFC, SIZE1, SIZE2, and WMC, and one single metric as the dependent variable, i.e., Change [54]. The elucidation of all the variables is supplied in Table 1. Out of these, DIT, LCOM, NOC, RFC, and WMC are known to be the famous C&K [15] metrics as they have been originally proposed by C&K only. DAC, MPC, NOM, and SIZE2 have been put forward by Li and Henry [54]. The remaining OO metric, i.e., SIZE1, represents the traditional metric for size. These particular OO metrics have been selected as the independent variables of this study, since, over the years, all these metrics have come out as the most widely and effectively used metrics throughout the literature while predicting maintainability in studies pertaining to SMP. Moreover, all these metrics together represent several distinct and the most relevant class properties of the selected datasets, covering coupling, complexity, cohesion, inheritance and size.
The software metrics of the two commercial software used in this study, i.e., QUES and UIMS have been provided publicly by Li and Henry [54] in one of their studies. In contrast, for obtaining the metrics of the remaining four software, source codes of two different versions of each software have been used. The codes of each of these software systems were analyzed line by line to identify the ‘Changes’ in the code lines of the second version as compared to the first version utilizing the ‘Beyond Compare’ tool available at: (
The descriptive statistics of all the six datasets have been supplied in Table 2. Table 2 depicts that the distribution of all the OO metrics for Drumkit, EASY, and FLMS datasets is positively skewed. Further, it is also shown that for IMS dataset, the distribution of all the OO metrics except DIT and NOC is positively skewed. However, for QUES and UIMS datasets, Table 2 shows a positively skewed distribution for all the metrics except DIT. It is also observed from the descriptive statistics that the means and the respective medians of all the OO metrics for all the datasets differ from each other. Not only this, but another observation to be noted is that the distribution of all the metrics for each of the six datasets is either platykurtic (
The EASY dataset is found to be more cohesive due to the minimum value of mean and median for the LCOM metric, whereas FLMS is highly coupled due to the maximum mean and median values for DAC. The minimum value of the mean and median for the DIT metric in the Drumkit dataset indicates the limited use of inheritance, whereas a high value for the same in the FLMS dataset indicates more use of inheritance. Also, a higher value of mean and median for the NOC metric in the EASY dataset reveals more inheritance. The maximum mean and median values of MPC and RFC metrics in the QUES dataset exhibit higher coupling between the classes in this dataset as compared to any other dataset. Different values of mean and median for NOM and SIZE2 metrics for different datasets further indicate the different class-sizes at the design level, Drumkit being the largest of all. The EASY dataset has the minimum mean and median value for WMC.
All these observations draw the focus towards a hypothesis stating that the distribution of the OO metrics used in this study is not normal. The stated hypothesis has further been tested by conducting the Shapiro-Wilk Test for normality.
The descriptive statistics provided in the previous sub-section show that the OO metrics’ distribution is not normal for any of the datasets for carrying out the current study. This finding further leads to a hypothesis to be tested by performing some normality tests to corroborate the non-normal distribution of the OO metrics. In this study, the Shapiro-Wilk test of normality has been performed to test the above hypothesis.
Shapiro-Wilk test published by Shapiro and Wilk [72] is one of the most widely used tests to check for the normality of datasets. Initially, when this test was proposed, it had a restriction of less than 50 on the sample size. However, sometime later, i.e., in 1995, this restriction was removed, and the range of sample size
where
Table 3 depicts the results obtained on applying the Shapiro-Wilk test for all the six datasets being used in the current study. The results of this test are analyzed based on the value of significance obtained for different OO metrics at a confidence interval of 95% (i.e., Sig.
Shapiro-Wilk statistics
* NA – NOC is constant in QUES and FLMS. It has been omitted.
It is evident from Table 3 that none of the eleven OO metrics used in this study is distributed normally in each of the three datasets, namely, Drumkit, QUES, and UIMS. However, NOC and SIZE1, MPC, and LCOM are normally distributed in case of EASY, FLMS, and IMS datasets, respectively. Further, the rest of the metrics, apart from the ones mentioned above, are not normally distributed in the case of EASY, FLMS and, IMS also. Hence, it can be concluded that since the overall distribution of various OO metrics in all the six datasets is not normally distributed, therefore, no parametric test can be applied for comparing these datasets with each other.
The current section talks about the complete methodology adopted in this study. The study starts with the selection of datasets, followed by data preprocessing and the handling of imbalanced datasets and, lastly, the development of models using different ML algorithms in combination with various FS techniques and their evaluation. Figure 1 furnishes the block diagram of the overall experimental design. However, the detailed description of the datasets, the metrics including the descriptive statistics, and the Shapiro-Wilk test have already been provided in Section 3. Therefore, this section describes the preprocessing phase, including converting datasets into binary datasets, removing outliers, and handling the problem of imbalanced datasets. This phase is further followed by the description of different FS techniques, ML techniques, performance evaluation measures, and the two statistical and post-hoc analysis tests, i.e., the Friedman test and the Wilcoxon Signed Ranks test.
Block diagram of the experimental design.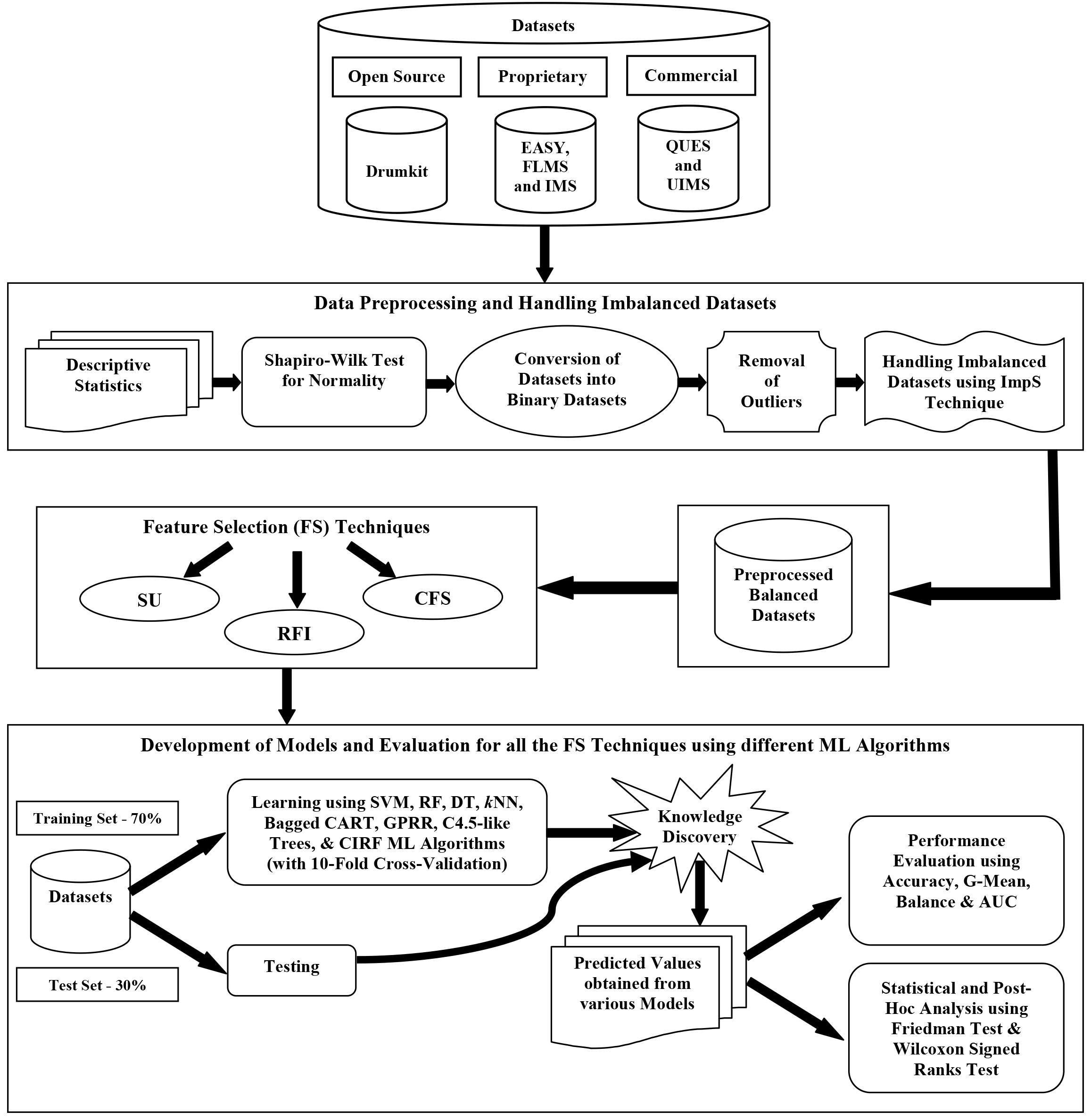
Initially, as described in Section 3.2, and from Table 1, it is known that the dependent variable is Change. This variable calculates the total count of the source code lines for each data point or class that has been added, deleted, or modified in the subsequent version of the software compared to the prior version. Each addition in the source code or deletion from the code is counted as a single change whilst any modification in the existing code is counted as two changes. However, while conducting the current study, the dependent variable Change has been converted into a binary variable, known as ‘Maintainability.’ The new binary variable can take one of the two possible values of classes, i.e., L-M (1 – Low Maintainability) and H-M (0 – High Maintainability), where L-M classes require more maintenance efforts due to more number of changes in comparison to H-M classes. This conversion is done based on the criteria proposed by Dallal [20] in one of his studies attributed to the prediction of OO class maintainability using internal quality attributes. According to this criterion, for those classes where the value of Change was greater than or equal to the mean/average value of Change for all the classes taken together, the Maintainability value was set to L-M (1). On the other hand, those classes whose value of Change was less than the average value of Change were labeled as H-M (0) classes. This conversion has been done due to various reasons discussed by Morasca [62] for the unsuitability of the idea of measure for quantifying the external attributes like maintainability as described in the measurement theory. These reasons include:
Quantifying external attributes not only depends on the entity under consideration but on various additional factors as well, e.g., it would be wrong to say that the maintainability of any software product is only a function of that product itself. Logical problems may arise when attributes are defined as per their measures due to the prior existence of attributes irrespective of how and when they have been measured. Further, the logical definition of any specific measure that intends to measure a particular attribute follows the definition of that attribute; else inconsistencies may enter while classifying attributes. Since external attributes are affected by a number of variables apart from a particular entity, hence, they do not have any deterministic measure, which is the basic prerequisite for applying the measurement theory.
Table 4 presents the details of all the six datasets being used in this study, including the total number of data points, the number of L-M and H-M data points, the Imbalance Ratio (I-R), number of outliers, and the number of data points after outlier removal. I-R is calculated using the formula which divides the number of H-M data points by the number of L-M data points
Details of the datasets
Identification and removal of outliers from different datasets is one of the most crucial preprocessing steps for developing a useful prediction model. This is done so that the performance of the model is in no way influenced by any variability in the data points due to specific extreme values. These extreme values significantly differ from other observations in the datasets. Here, Interquartile Range (IQR) [75] filter has been used to identify and remove the outliers. IQR is a measurement of the statistical dispersion, that is equivalent to the difference in the values of the 75
Handling the imbalanced datasets
It is noticeable from Table 4 that all the six datasets being used in the current study are imbalanced in nature. Hence, it is vital to handle these imbalanced datasets for bringing about a balance between the minority and the majority classes to do away with any bias for an improved prediction. In this study, a very effective algorithm, namely, ImpS [88], has been used for handling the imbalanced datasets. This algorithm makes use of the relevance that has been provided for re-sampling the datasets to handle the imbalanced classification problem. This relevance then helps in the introduction of the copies of the most relevant examples and the removal of the least relevant ones. The ImpS algorithm applies a combination of random over-sampling and random under-sampling techniques [7] to the problematic classes as per the corresponding importance. Thus, this makes ImpS one of the best sampling techniques to handle the imbalanced datasets since it retains the best possible out of the combination of the two individual techniques.
Feature Selection (FS) techniques
While developing any prediction model, the selection of relevant features out of all the available ones becomes an essential task in enhancing the overall performance and efficiency of that model. FS reduces the initial information being fed to the model for learning while training, thereby, decreasing the execution time also. This happens since all the redundant and irrelevant features have been eliminated from the original set of features. This sub-section describes the three different FS techniques that have been used for selecting the relevant features from each dataset on an experimental basis. However, it is important to note that it is difficult to mention a single FS technique that can be considered as the best technique for FS [27, 34].
Therefore, the chosen FS techniques have been employed after a careful trial and experimentation of several FS techniques to provide the best possible results. Another reason behind choosing the below mentioned FS techniques for conducting the current study is a successful implementation of these techniques for selecting features in numerous studies in literature. For example, according to literature, SU FS technique has been applied in several different fields resulting in an effective FS for improving the predictive performance of various ML models. Jiang et al. [43] used SU FS technique to develop a hybrid FS algorithm, Kannan and Ramaraj [44] proved an effective utilization of SU technique in removing the redundant features for improving the accuracy of the classifiers, Potharaju and Sreedevi [66] proposed a novel SU-based FS technique to enhance the classification accuracy for several medical datasets, and Piao et al. [65] conducted the SU-based feature subset selection for a noteworthy classification of electricity customers. Similarly, RFI FS technique has also been successfully implemented in several prior studies. Saeys et al. [69] showed that RFI FS technique clearly outperformed other FS techniques in terms of robustness. Pan and Shen [64] revealed the importance of RFI FS in having a deep insight into the actual contribution of different features for an effective development of various predictive tools for a robust B-factor prediction. Sylvester et al. [76] effectively applied RFI FS technique for the assignment of genetic population. In one of their studies on intrusion detection, Hasan et al. [35] showcased that the RFI technique of FS is highly capable of selecting the most relevant and important features for classification. This in turn reduces the number of features and time along with an improvement in the classification accuracy. Further, if we talk about CFS FS technique, Hall and Holmes [34] assessed six different FS techniques using 15 datasets confirming the effectiveness of CFS technique over other techniques showing good results. Malhotra [58] reviewed 64 fault prediction studies (for the period 1991 to 2013) and resultantly unveiled CFS to be the most widely used FS techniques. Other studies that applied CFS technique for FS to develop effective predictive models employing various ML techniques include Hall [33], Arisholm et al. [5], and Carvalho et al. [11]. In a nutshell, the above description and studies strengthen the claim about the successful implementation of the three most effective FS techniques in the development of different prediction models employing various ML algorithms. Thus, the above three particular FS techniques, i.e., SU, RFI, and CFS have been utilized to carry out the current study.
Symmetrical Uncertainty (SU)
SU is an entropy-based filter [40, 85], which is derived by normalizing the mutual information to the entropies of either the feature values, or the feature values and the target classes. Mutual information here refers to the measure of the difference between the distribution of the feature values and the target classes from statistical independence. This estimates the correlation between the feature values, or the feature values and the target classes in a non-linear manner. SU has prominently been used for evaluating the relevance of features for classification. SU is measured as follows:
where,
RFI [85] uses the RF algorithm to find the weights of various features. RF consists of a number of decision trees that are built from a random extraction of different observations in a dataset, along with a random extraction of various features. Each and every tree is not necessarily exposed to all the observations or features at the same time, which ensures that the trees are sufficiently de-correlated and, hence, less susceptible to the problem of over-fitting. Here, every tree is a series of questions (each question represents a node) in yes-no form, formed on the basis of an individual or a blend of various features. The tree is further divided into two branches at every subsequent node, where each branch consists of all those observations that are similar to each other but not so similar to the ones hosted by the other branch. Thus, the relevance of each and every feature is decided based on the purity of the corresponding branch. Generally, in RF, the features selected by the tree at the top are considered to be more important than that of those selected by the end nodes.
Correlation-based Feature Selection (CFS)
CFS [40, 85] algorithm uses the measures of correlation and entropy to find a subset of the relevant features. CFS selects the features in a way such that the selected features are highly correlated to the dependent variable and have the least possible correlation amongst each other. Further, CFS uses a heuristic-based evaluation function based on the values of correlations for the ranking of features. Different subsets of feature vectors that are in correlation with the dependent variable, but independent of each other are evaluated using this function. According to the CFS algorithm, features showing a low correlation with the dependent variable are irrelevant, and hence, they should be ignored. Typically, CFS sometimes even eliminates over half of the total features. A subset
where
Once the relevant features are selected from all the datasets using each of the FS techniques, these datasets are divided into a
SVM is a supervised ML algorithm put forth by Vapnik [14] along with his colleagues at At&T Bell Laboratories. It can be used for the analysis of both classification and regression problems. The principal objective of SVM is to identify a hyperplane in an
RF is another supervised ML ensemble for classification and regression problems [9] consisting of multiple DTs. In RF, every individual tree generates a class prediction where the class having the majority of votes becomes the final prediction. The strength of RF lies in the fact that a number of uncorrelated trees operate collectively to outperform several individual trees and protect one another from the individual errors. One of the prerequisites of RF for better performance is that there should be a low correlation among the prediction of individual trees. Therefore, RF tries to build a forest of trees that is uncorrelated in nature using feature randomness and bagging (bootstrap aggregation) while creating individual trees such that the collective prediction is always more accurate as compared to individual trees. Finally, RF results in ensemble predictions by integrating the decisions of each DT, which are indeed more accurate than any of the individual predictions.
DT(rpart) [77] method is a popular, exploratory and widely used statistical tool for solving many classification and regression problems whose primary objective is to bring down the dissimilarity existing in the terminal nodes of the DT to a minimum. It is generally used for dichotomous outcomes such that the assumption of linearity can be avoided. In this method, a DT is built by repeated division/splitting of a dataset, i.e., the whole population into various subsets based on some rules or descriptors that differentiate between different types of data points. This method is recursive since each subset may further be split for an unspecified number of times until it reaches a stopping criterion to terminate the splitting process and receive the final predicted class or value. The predictions made using DT(rpart) can be more accurate as it ensures varying prioritization of the misclassifications for creating a decision rule having more specificity or sensitivity.
Bagged CART combines bagging with the CART algorithm to develop an integrated algorithm for classification since the CART algorithm lacks stability in training and prediction when used individually. Bagged CART not only includes the simplicity of the CART algorithm but, in turn, enhances the reliability and accuracy of the classification. Breiman [19] proposed the CART, i.e., the Classification and Regression Trees classification algorithm in 1984. In CART, non-parametric methods are used to determine the relationship between the multiple layers of data and to meet the classification goals through the construction of binary graphics. However, CART is an unstable algorithm.
Further, a few years later, it was pointed out by Breiman [8] that bagging can improvise the predictive performance of the weak and unstable learning algorithms significantly by iterating over several different versions of a particular predictor to obtain an aggregated predictor. This aggregation then averages out or makes a plurality vote over all the versions during prediction. Hence, the bagging algorithm has been used with the CART algorithm for an increased optimizing ability of the CART algorithm.
GPRR model was developed by O’Hagan and others [57] in the seventies. Gaussian Process (GP) is again a non-parametric, generic and supervised method of classification, which is based on Bayesian methodology. It is based on a prior assumption of distribution on the underlying density of the probabilities guaranteeing the smoothness property. The classification providing a good fit for the observed values is considered to be the final classification. GP is a distribution of probability over possible functions. It is advantageous as the observations are interpolated by the prediction. The prediction is Gaussian or probabilistic in nature, such that the empirical confidence intervals may be computed for deciding if the prediction should be refit in the region of interest and is versatile in terms of the kernels used. Kernels or the covariance functions play a crucial role in ascertaining the prior and posterior shape of the GP. They do so by encoding the assumptions of the learning function by combining the defined similarity of the two data points with an assumption that two similar data points are supposed to have similar targets. Here, Radial-Basis Function (RBF) kernel, otherwise known to be the squared exponential kernel has been used. RBF is a stationary kernel.
C4.5-like trees is an algorithm propounded by Ross Quinlan [70], which is applied for generating a DT. It is an enhancement to Quinlan’s ID3 algorithm. C4.5 is otherwise known as a statistical classifier since the DTs generated by C4.5 are used for classification. It uses an information entropy concept for building the DTs from a given set of already classified training data. At each tree node, C4.5 works by selecting such attributes of the dataset that split the whole set of observations into various subsets in the most effective manner enriched in one or the other class. The splitting is done based on the criterion of normalized Information Gain (IG), i.e., the difference in entropy and the attribute having the highest IG is chosen for making the decision. After this, the C4.5 algorithm recurrently iterates over the partitioned subsets.
CIRF is an implementation of RF [9] and the bagging ensemble models which use Conditional Inference (CI) trees [38] in the form of base learners. Unlike RF, where predictions are averaged out directly; in CIRF, aggregation is done by finding out the average of the weights of the observations extracted from each and every tree. Generally, CI trees grow in a usual manner on the bootstrap samples or the sub-samples having only a subset of attributes being available for the split at each node. After this, a suitable and weighted average of the responses that have been observed is constructed for the predictions [37]. Further, the CI trees apply the significance tests to determine the split attributes and the split points.
Performance evaluation measures
This section talks about various performance measures that have been used to estimate the performance of different prediction models being developed in the current study. Precisely, one traditional evaluation measure, i.e., Accuracy along with three other robust measures, viz., G-Mean, Balance, and AUC have been used in this study to measure the performance. The use of all the above three robust measures in determining the performance of the predictive models has already been advocated in various prior studies [36, 49, 53, 73].
All the above evaluation measures have been derived in accordance with the confusion matrix [56]. A confusion matrix for the concerned study has been provided in Table 5 representing two different classes, i.e., H-M (0), the majority class, and L-M (1), the minority class. Here, H-M is relative to the positive class, whereas L-M symbolizes the negative class.
Confusion matrix
Confusion matrix
Based on the confusion matrix, various performance measures are described as follows:
Accuracy computes the percentage of the correctly predicted classes, including both the positive and the negative classes using the following formula:
G-Mean symbolizes the geometric mean of the sensitivity (
Balance measure computes the Euclidean distance between a particular pair, i.e., (Recall or TPR, FPR or False Positive Rate) to a pair having the optimum value of (Recall, FPR). The optimum value of Recall
AUC is another significant measure to evaluate the performance of the predictive models. It represents the area under the ROC (Receiver Operating Characteristic) curve between FPR (1-specificity or
Once the results have been obtained for various prediction models, it is essential to perform some statistical tests such that these results get support for strengthening the conclusions of the current study through statistical analysis. In this study, two non-parametric tests, namely, the Friedman Test followed by the Wilcoxon Signed Ranks Test for post-hoc analysis have been used.
Table for Feature Selection (FS)
Table for Feature Selection (FS)
Friedman Test [84] has been used to advocate for any significant difference among the performances of the different prediction models that have been developed in this study using different FS techniques for each dataset employing Accuracy, G-Mean, Balance and AUC performance measures (RQ2). Further, a mean rank is assigned to different FS techniques for each and every dataset depending on the four different performance measures mentioned above. The lower the rank of the FS technique, the better is that technique.
Friedman test distributes the test statistic as per the Chi-Square distribution having ‘
Once it is known that the results on performing the Friedman test are significant, then the Wilcoxon Signed Ranks test should also be performed to ascertain pair-wise differences among different FS techniques.
Wilcoxon Signed Ranks Test [84] finds the differences amongst the various possible pairs of different FS techniques for comparison for each dataset. Further, according to the absolute values of the calculated differences, ranks are allocated to them. In this study, the Wilcoxon test has been performed with Bonferroni correction for handling the family-wise error and compensating for the inflation of Type I error. Here also, the level of significance is taken to be 0.05, i.e.,
Results for Accuracy using different FS techniques
Results for G-Mean using different FS techniques
Results for Balance using different FS techniques
Results for AUC using different FS techniques
The current section presents the results of this study, along with extensive analysis. The study has been performed on six different datasets after their preprocessing, including converting these datasets into binary, removing outliers, and balancing the imbalanced datasets using the ImpS technique. The preprocessing has been followed by FS with the help of three FS techniques, namely, SU, RFI and CFS. Afterward, the resultant datasets have been used for developing the prediction models by dividing them into a
Feature Selection (FS) results
This study implements three different FS techniques, described in Section 4.4, for choosing the relevant features from each of the six datasets. Table 6 provides a complete list of features or the OO metrics that have been selected using SU, RFI and CFS techniques of FS for developing the prediction models for all the datasets using different ML algorithms.
It is observable from Table 6 that each FS technique selects an entirely different set of OO metrics both in terms of names and numbers depending on the dataset and the ML technique being used at a particular instance. However, the effect of all these FS techniques on the performance of various prediction models has been stated and explained in the subsequent sections with the help of different performance measures.
Evaluation and discussion of results using different FS techniques and ML algorithms with 10-fold cross-validation
This sub-section answers the first RQ formulated in this study, i.e., RQ1: Whether the performance of different ML algorithms used in this study improves markedly by using various FS techniques for predicting software maintainability?
Several prediction models have been developed for six different datasets using three FS techniques and eight ML algorithms for answering the above RQ. All the ML algorithms have been implemented using the 10-fold cross-validation while training. Since, for each of the 6 datasets, a total of 4 FS techniques (3 FS techniques
As per Table 7, for all the datasets, the values of Accuracy in some cases are better when no FS technique has been used as compared to the cases where some or the other FS has been applied, especially in case of IMS, QUES, and UIMS datasets. Further, the SMP models that have been built with FLMS, Drumkit and EASY datasets still performed well with FS in terms of Accuracy since the values of Accuracy using FS techniques are better than the case when no FS has been done in majority cases.
Median values obtained for (a) Accuracy; (b) G-Mean; (c) Balance; and (d) AUC for all the six datasets before and after using FS techniques.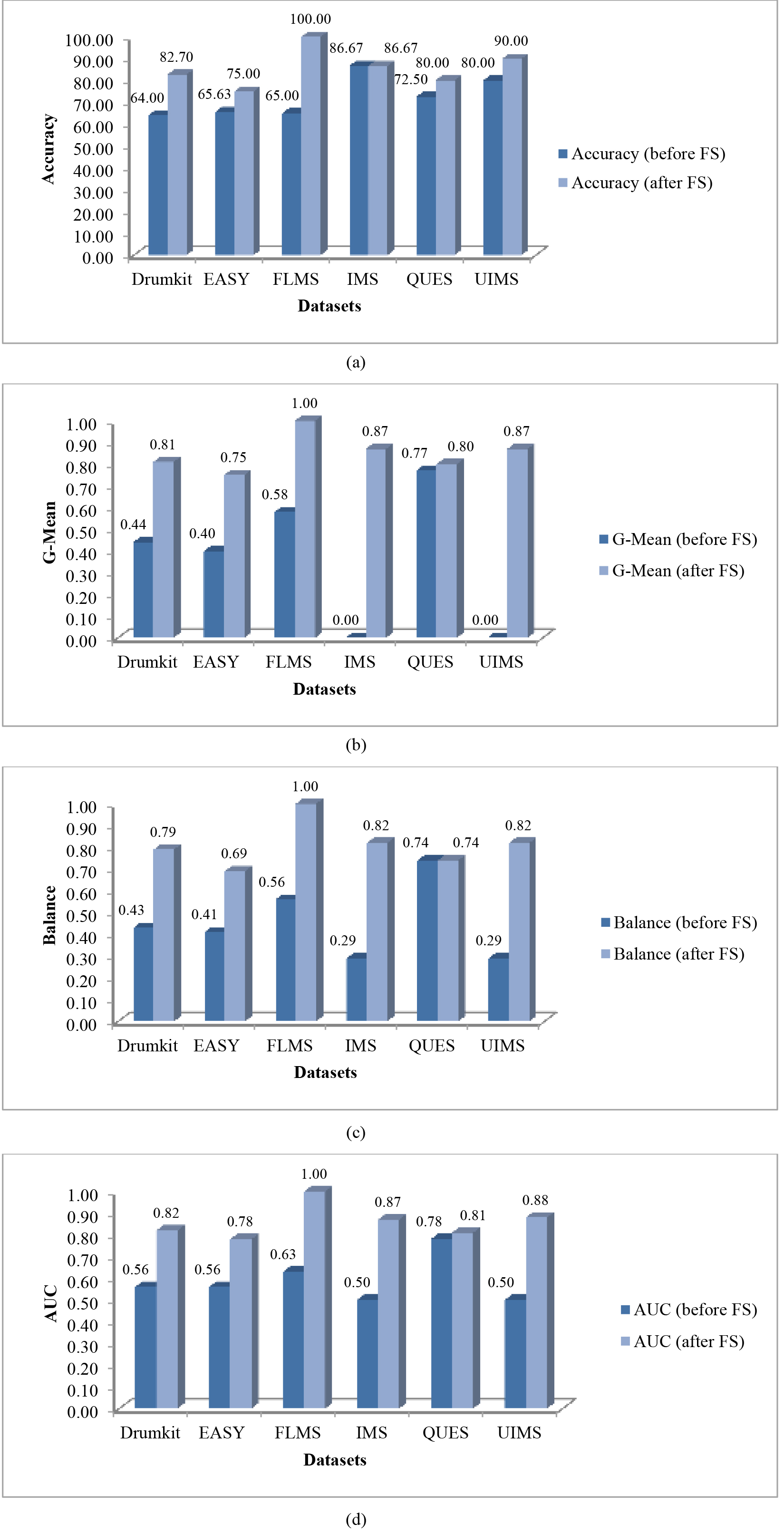
Further, on analyzing Tables 8–10, it has been observed that the values of G-Mean, Balance and AUC measures for all the datasets improved on applying various FS techniques for most of the cases as compared to the case where no FS has been used. Following this, Fig. 2a–d depict the median values obtained, before and after using FS techniques for each of the four accuracy measures, i.e., Accuracy, G-Mean, Balance, and AUC, respectively.
It is observed from Fig. 2a that the median values derived for Accuracy before using FS techniques are not so competitive. The highest median Accuracy value is attained by IMS dataset which is equal to 86.67%, whereas, this value is as low as 64% in case of Drumkit. Following this, from Fig. 2b it is clear that the median G-Mean values obtained for most of the datasets except QUES are extremely low without using FS. In fact, for IMS and UIMS datasets, this value is as low as 0.00, and the median G-Mean value for the FLMS dataset is close to 50%, i.e., 0.58. Likewise, as per Fig. 2c, the median Balance values obtained for almost all the datasets before using FS are also very low, except QUES having a median Balance value equal to 0.74.
On the other hand, IMS and UIMS datasets have the lowest median values for Balance equal to 0.29. Further, Fig. 2d again indicates lower median AUC values without using FS techniques for most of the datasets, except QUES and FLMS. However, the median AUC values for IMS and UIMS datasets are precisely equal to 0.50. This poor performance may be attributed to the presence of the redundant, irrelevant and noisy data, which degrades the learning of the prediction model being developed. That is why different FS techniques have been used in this study for removing insignificant features from the datasets and to investigate their effect in improving the performance of various prediction models so developed.
The median values of Accuracy, G-Mean, Balance, and AUC in Fig. 2 (after using FS) when compared with the corresponding values in Fig. 2 (before using FS) show that the use of various FS techniques indeed brought about a remarkable improvement in the performance of the different predictive models for all the datasets. Precisely, on the basis of median Accuracy values in Fig. 2a (before and after using FS techniques), an improvement of 29.22%, 14.28%, 53.85%, 10.34%, and 12.50% has been attained for Drumkit, EASY, FLMS, QUES, and UIMS datasets respectively by using FS; whereas in this case, no improvement has been observed for IMS dataset. In terms of median G-Mean values provided in Fig. 2b, the use of FS techniques resulted in an improvement equal to 84.09% for the Drumkit dataset, 87.50% for the EASY dataset, 72.41% for FLMS dataset, 87.00% for both IMS and UIMS datasets, and 3.90% for QUES dataset. Further, based on the median Balance values given in Fig. 2c, an improvement equal to 83.72% for Drumkit dataset, 68.29% for the EASY dataset, 78.57% for FLMS dataset, and 182.76% for IMS and UIMS datasets has been achieved after FS with no improvement in case of QUES dataset as the median Balance values for QUES are same in both the cases, i.e., before and after applying FS. Lastly, as shown in Fig. 2 (d), an improvement of 46.43%, 39.29%, 58.73%, 74.00%, 3.85%, and 76.00% has been observed for Drumkit, EASY, FLMS, IMS, QUES, and UIMS datasets respectively concerning the median AUC values on applying various FS techniques.
On an average, an overall improvement equal to 18.58%, 129.73%, 80.00%, and 45.76% in the median values of Accuracy, G-Mean, Balance, and AUC respectively has been attained on employing FS techniques for all the datasets taken together. Therefore, by virtue of the above results, it is concluded that the performance of different ML algorithms used in this study improves markedly by utilizing various FS techniques to predict software maintainability. Hence, this answers the first RQ (RQ1) raised in the current study.
This sub-section attempts to answer RQ2 for carrying out a comparison between different FS techniques. RQ2 has been stated as RQ2: Which FS technique performs the best amongst the different FS techniques evaluated in this study?
As already concluded in Section 5.2, the use of FS techniques notably improved the performance of various predictive models developed using different ML techniques for all the six datasets with reference to Accuracy, G-Mean, Balance and AUC. However, the question that still remains unanswered is which of the three FS techniques used in the current work comparatively performed better. So, to carry this work further, the statistical Friedman test has been performed to answer the above question. This test has been applied for comparing four FS techniques in all, including SU, RFI, and CFS techniques, along with the scenario when no FS has been done. Therefore, the degree of freedom here is ‘
Results of the Friedman test using different FS techniques with reference to Accuracy
The hypothesis of the Friedman test with reference to Accuracy measure has been stated as follows:
Null Hypothesis (
Alternate Hypothesis (
Table 11 depicts the Friedman test results in respect of Accuracy, showing the mean ranks assigned to all the three FS techniques, including no FS case for each of the six datasets with corresponding
Results of the Friedman test using Accuracy measure
Results of the Friedman test using Accuracy measure
Results of the Friedman test using G-Mean measure
The hypothesis of the Friedman test with reference to G-Mean measure has been stated as follows:
Null Hypothesis (
Alternate Hypothesis (
Table 12 presents the results of the Friedman test in respect of the G-Mean measure for all the six datasets with mean ranks assigned to each of the three FS techniques along with the case when no FS has been done, and the corresponding
Results of the Friedman test using different FS techniques with reference to Balance
The hypothesis of the Friedman test with respect to Balance measure has been stated as follows:
Null Hypothesis (
Alternate Hypothesis (
Table 13 presents the Friedman statistics, including the mean ranks assigned to each of the three FS techniques plus the case when no FS has been done and the corresponding
Results of the Friedman test using Balance measure
Results of the Friedman test using Balance measure
The hypothesis of the Friedman test with respect to AUC measure has been stated as follows:
Null Hypothesis (
Alternate Hypothesis (
Table 14 presents the results of the Friedman Test with regard to AUC measure. This table provides the mean ranks assigned to each of the three FS techniques along with the case when no FS has been done for all the six datasets and the corresponding
Results of the Friedman test using AUC measure
Results of the Friedman test using AUC measure
Results of the Wilcoxon Signed Ranks test using Accuracy measure (based on positive ranks)
Overall, it is evident from Friedman test results that the SU FS technique has surpassed all the other FS techniques irrespective of the dataset and the performance measure being used. This exceptional performance of the SU technique may be attributed to the benefits which this technique provides. The values in SU technique are normalized in the range [0,1] and it compensates for the bias of mutual information towards the multi-valued features. As the name suggests, SU has symmetric nature and results in the reduced number of comparisons for a pair of features, say, ‘
As stated in the previous section, the results of the Friedman test have already proved that a noteworthy difference exists between the performance of different FS techniques with SU technique performing the best for various performance measures including Accuracy, G-Mean, Balance, and AUC for all the datasets. However, to know about the differences between various related pairs of different FS techniques, post-hoc analysis using the Wilcoxon Signed Ranks test with Bonferroni correction has been performed. The results of this test further answer the third RQ, i.e., RQ3: Does any significant difference exist between different pairs of FS techniques analyzed in this study?
The Wilcoxon test has been used to compare the SU FS technique that has been ranked to be the most accurate technique for all the datasets by the Friedman test with the other two FS techniques (RFI and CFS) at the level of significance,
Results of the Wilcoxon Signed Ranks test using G-Mean measure (based on positive ranks)
Results of the Wilcoxon Signed Ranks test using G-Mean measure (based on positive ranks)
Results of the Wilcoxon Signed Ranks test using Balance measure (based on positive ranks)
Results of the Wilcoxon Signed Ranks test using AUC measure (based on positive ranks)
Though it is known from the results of the Friedman test that the SU FS technique has been ranked the best for all the six datasets; from Tables 15–18 it is evident that SU technique is not significantly different from the RFI technique at
This section elucidates various threats to validity that have been encountered while conducting the current study.
Construct validity pertains to the correct selection and measurement of both the independent and the dependent variables while developing various prediction models. However, all the OO metrics used as the variables in this study have been selected from the most popular metric suites available in the literature that have already been used in developing several maintainability prediction models. Even the dependent variable used here, i.e., maintainability, measured in respect of the number of changes in the code lines, has also been used previously in several literature studies. The selection of OO metrics in this manner minimizes the construct validity threat for the variables. Further, the threat to construct validity can also arise while making a selection of various ML techniques for building the models, but an attempt has been made to reduce this threat to the minimum by selecting several ML techniques.
Internal validity is related to the effect that the independent variables put on the dependent variable, also known as the ‘causal effect.’ In this study, due to the imbalance existent in the classes of the original datasets, an attempt was made to handle these imbalanced datasets using a re-sampling technique. However, this brought about a change in the ratio of the data points of the minority and the majority classes, which might alter the initial causal effect and possibly let the threat to internal validity peep in. However, the performance of the predictive models being developed has been estimated using one traditional measure, i.e., Accuracy and the three most stable and robust accuracy measures; namely, G-Mean, Balance, and AUC, to minimize this threat.
Conclusion validity is associated with particular possibilities that may hinder the correct and precise analysis of the results from reaching a conclusion. Utmost care has been taken to avoid this threat by taking various steps. 10-fold cross-validation has been used while training the models to reduce any bias in the validation. Cross-validation also helped in mitigating any potential threat due to small size of the datasets. Further, multiple robust accuracy measures have been used for evaluating the performance. Lastly, two non-parametric tests, namely, the Friedman test and the Wilcoxon Signed Ranks test, have been performed for the statistical and post-hoc analysis of the predicted results to substantiate the conclusions further.
External validity is related to the expanse to which the results of a particular study could be generalized. In the current study, six different datasets from three different domains built under particular environments have been used for building the SMP models. Therefore, the results may generalize to other software built in similar environments whereas this may pose a threat while validating the results using software that has been developed under differing scenarios. Another threat to external validity could be the small size of the datasets used in the current study which might not be that relevant for today’s large software systems.
Conclusion and future direction
The current study initiated with the purpose of investigating the effect of various FS techniques in SMP since the early and timely prediction of classes with low maintainability can come as a boon to the software developers. This investigation is necessary to bring down the overall cost of development, especially the cost incurred in the maintenance phase in respect to time, money and even the human effort. To begin with, this study started with six different datasets, including one open source, three proprietaries, and two commercial datasets. Initially, these datasets were analyzed through their respective descriptive statistics and the Shapiro-Wilk test of normality. This was followed by the preprocessing step, which included the conversion of datasets into binary, removal of outliers, and handling of imbalanced datasets using the ImpS technique.
Further, the foremost step of this study, i.e., the selection of relevant features from all the datasets using various FS techniques (SU, RFI, and CFS), was carried out. FS was done to make the predictive task more efficient due to the elimination of redundant and noisy data. After this, the final preprocessed datasets were used to build different prediction models using eight different ML techniques with 10-fold cross-validation. The performance of these models was estimated using one traditional measure, namely, Accuracy and three other robust performance measures, namely, G-Mean, Balance and AUC, to study and analyze the effect of different FS techniques on the predictive ability of the SMP models. Lastly, a statistical and post-hoc analysis using the Friedman test and the Wilcoxon Signed Ranks test was also conducted to further support the conclusions of this study. The major conclusions drawn are stated as follows:
The performance of the SMP models that have been developed using various ML algorithms improved remarkably on using different FS techniques for all the six datasets. Of all the three FS techniques used here, the SU technique performed the best in predicting maintainability with respect to all the four performance measures, viz., Accuracy, G-Mean, Balance and AUC. However, the other two FS techniques, i.e., RFI and CFS, also provided competitive results compared to the case when no FS was done. On comparing the best FS technique, i.e., SU with the other two FS techniques, it was found that the SU technique is superior to the CFS technique with reference to the EASY, FLMS and QUES datasets in respect of all the four measures of performance as mentioned above.
Thus, the current study would help the research community determine the low maintainability classes well in advance by developing efficient prediction models using various FS techniques. This would lead to judicious use of the resources concerning the developer’s time, money and effort by removing the unnecessary data through FS. As a future extension, the authors plan to implement the current work on a wide range of datasets that have been built using different languages under varying environments. Furthermore, the authors plan to utilize, analyze, and compare several other re-sampling methods and FS techniques apart from those used in this study for efficient model development. Last but not least, the authors plan to replace the ML techniques with various evolutionary, meta-heuristic, or hybridized techniques.
Footnotes
Acknowledgments
This research work has been supported by the O/o Director (Research and Consultancy), GGSIPU under the FRGS scheme through the project entitled, “Determination of Optimum Refactoring Sequence after Prioritization of Classes on the basis of their bad smell,” dt. 03.05.2019, Ref. No. GGSIPU/DRC/FRGS/ 2019/1553/62.