
Abstract
The imbalanced data problem is widespread in the real world. In the process of training machine learning models, ignoring imbalanced data problems will cause the performance of the model to deteriorate. At present, researchers have proposed many methods to deal with the imbalanced data problems, but these methods mainly focus on the imbalanced data problems in two-class classification tasks. Learning from multi-class imbalanced data sets is still an open problem. In this paper, an ensemble method for classifying multi-class imbalanced data sets is put forward, called multi-class WHMBoost. It is an extension of WHMBoost that we proposed earlier. We do not use the algorithm used in WHMBoost to process the data, but use random balance based on average size so as to balance the data distribution. The weak classifiers we use in the boosting algorithm are support vector machine and decision tree classifier. In the process of training the model, they participate in training with given weights in order to complement each other’s advantages. On 18 multi-class imbalanced data sets, we compared the performance of multi-class WHMBoost with state of the art ensemble algorithms using MAUC, MG-mean and MMCC as evaluation criteria. The results demonstrate that it has obvious advantages compared with state of the art ensemble algorithms and can effectively deal with multi-class imbalanced data sets.
Introduction
If one class has more samples than other classes in the data sets, the data sets are imbalanced [1]. Because of internal or external reasons, the data sets used for machine learning or data mining are often imbalanced in the real world. Data collection and data storage can cause imbalanced data problems, which are external reasons. In some scenarios, the datasets are also imbalanced, such as datasets used for text classification [2], fraud detection [3], medical diagnosis [4] and fault prediction [5]. In machine learning applications, data sets are generally considered to be balanced. If these models are applied to the skewed data sets, the models will be biased towards the majority classes in the data sets and those minority classes will get very poor accuracy [6]. However, it is generally crucial for us to accurately classify minority classes.
Effectively learning from imbalanced data is becoming more and more essential because most real data sets are imbalanced. In recent years, a lot of researchers have devoted themselves to the research of imbalanced data problems and have put forward many algorithms so that these problems are solved. These methods can be roughly divided into hybrid methods, algorithm-level methods and data-level methods in the literature [7]. Data-level methods are mainly to deal with the imbalanced data problems through sampling methods. Its function is to make the class distribution more balanced and the classifier can treat all classes equally. In data-level methods, the number of samples of the minority class can be increased by using over-sampling and the number of samples of the majority class can be reduced by using under-sampling. Previous researchers have presented many data sampling algorithms, such as synthetic minority over-sampling technique (SMOTE) [8], random under-sampling, edited nearest neighbor (ENN) [9], AdaSyn [10], random over-sampling, condensed nearest neighbor (CNN) [11] and so on. The algorithm-level methods change the learning process or the discrimination method so that the algorithms are insensitive to class distribution and the resulting model can accurately classify minority classes [12]. The algorithm-level methods we frequently use include ensemble method, cost-sensitive learning, new loss function, threshold moving and so on. In [13], focal loss which is a new loss function was proposed so that the extreme class imbalance problems in target detection was solved. In [14], A novel adaptive k-NN classifier was proposed so that the imbalanced data problems in two-class and multi-class classification tasks were solved. The ensemble model is also often used to deal with the imbalanced data problems. It is composed of multiple weak classifiers and the final output result is jointly determined by these weak classifiers. In the training process, the ensemble model can be more focused on the minority class, which is conducive to improving the classification performance of the minority class. In hybrid methods, both algorithm-level methods and data-level methods are used and the advantages of the two are combined. It uses the sampling methods to rebalance the data sets and modifies the algorithm mechanism to make the algorithm insensitive to the data distribution, in order that the models are more focused on the minority class and can better distinguish all classes. In [15], ensemble method was combined with cost-sensitive learning and sampling approaches in order to accomplish admirable classification performance.
Usually, solving the multi-class imbalanced data problems is over and above complicated than solving the two-class imbalanced data problems. In multi-class imbalanced datasets, there may be numerous majority classes and numerous minority classes, which together lead to datasets skew. In this case, it becomes extremely difficult to find the connections between the classes. If only the classification performance of individual class is considered, the classification performance of other classes will be reduced, which poses a huge challenge to researchers. In addition, the evaluation criteria used in multi-classification tasks have always been controversial. Better evaluation criteria are desired.
In this paper, an ensemble algorithm is put forward in order to deal with the imbalanced data problems in multi-class classification tasks, called multi-class WHMBoost. It is an extension of the WHMBoost [12] that we proposed before and it has been modified in some steps. It combines the algorithm-level method and the data-level method in order to accomplish preferable classification performance. We use random balance based on average size to process the data sets so that the class distribution becomes more balanced. We use support vector machine and decision tree classifier as the weak classifiers of the ensemble model. In the process of training models, we assign weights to them so that they can participate in model training with the given weights, thereby obtaining complementary advantages. In the experimental part, we used MAUC, MG-mean and MMCC as the classification performance evaluation criteria, and compared our designed method with the previously presented algorithms (SAMME [16], SMOTEBoost [17], GradientBoost [18, 19], RUSBoost [20]) on 18 multi-class imbalanced data sets. Experimental results demonstrate that our designed algorithm is more advanced than other ensemble methods in classifying multi-class imbalanced data.
The main contributions of this paper are summarized as follows:
We extended WHMBoost, which solves binary imbalanced data problems, to multi-class WHMBoost, which solves multi-class imbalanced data problems, and made improvements in some algorithm steps. We used three performance evaluation criteria and compared our designed method with other algorithms like SAMME, RUSBoost, GradientBoost on 18 multi-class imbalanced data sets. By observing the experimental results and analyzing the experimental data, we can conclude that the presented algorithm is more advanced than the previously presented algorithms and can produce exceptional results.
The rest of the paper is organized as follows: in Section 2, related work is shown. The presented method is described in detail in Section 3. In Section 4, the results and analysis on 18 multi-class unbalanced data sets are introduced. Finally, Section 5 concludes the paper.
WHMBoost
In this paper, the multi-class WHMBoost we introduce is an extension and improvement of the WHMBoost that was previously presented to deal with the two-class imbalanced data problems. In this section, we first introduce WHMBoost. WHMBoost is a hybrid method that combines algorithm-level method and data-level method. The data-level method we use is the sampling algorithm that consist of adjustable random balance and random under-sampling. The sampling algorithm is used to balance the distribution of the data sets so that the number of samples in all classes tends to be the same. In order to make the adjustable random balance and random under-sampling better complement each other and adapt to different data sets, we assign weights to them. The algorithm-level method we use is the ensemble algorithm. In the ensemble method, the weak classifiers we use consist of support vector machine and decision tree classifier. The decision tree algorithm is unstable so that many different trees can be generated and more data space will be covered during the operation of the algorithm. Support vector machine has strong generalization capabilities and may also have satisfactory results on small data sets. Weights are assigned to support vector machine and decision tree classifier in order that they can better complement each other’s strengths in training and maximize their ability in order to accomplish the outstanding classification effect. Each iteration of the presented algorithm consists of two stages. In the first stage, the sampling algorithm is applied on the original data sets so that the size of all classes tend to be equal, in which adjustable random balance or random under-sampling is selected for training according to the given weight. In the second stage, the ensemble algorithm is executed on the generated data sets, in which a base classifier is selected for training according to the given weight.
[htb]
[htb]
The steps of the WHMBoost can be illustrated as follows. First, the weight
For multi-class imbalanced datasets, the current processing methods can be divided into two groups, one is to decompose multi-class imbalanced data problems into numerous two-class imbalanced data problems for processing [22], and the other is to directly carry out multi-class imbalanced datasets problems. The class decomposition methods are not discussed in this paper. In real data sets, most of them are imbalanced, which seriously affects the performance of machine learning models. Previous researchers have also put forward abounding ensemble algorithms in order to carry out the imbalanced data problems.
SAMME [16] was put forward in order to deal with the multi-class classification problems and it directly extends AdaBoost to multi-class situations, rather than reducing it to numerous binary-class situations. The algorithm process of SAMME is basically the same as that of AdaBoost. The only difference is the formula for calculating the weight of the weak classifier in the boosting algorithm, as shown in Eq. (4). The extra term
GradientBoost [18, 19] is a method based on Boosting, which can carry out both two-class classification tasks and multi-class classification tasks. It is suitable for various loss functions and is an additive model. In each iteration, the learner is obtained by fitting the negative gradient of the loss function of the previously established model. The learner in GradientBoost will be initialized with a constant value in order that the loss function of all samples is minimized [24]. When the learner is added to the ensemble model, it needs to be multiplied by a coefficient, which can be regarded as the learning rate.
SMOTEBoost [17] was proposed by Chawla et al. in order to deal with both the two-class imbalanced data problems and the multi-class imbalanced data problems. The process of this method is divided into two steps: SMOTE and boosting method. In each iteration, SMOTE will synthesize new data based on the initial data, and the weak classifier in boosting is trained based on the initial data and the synthesized data. At the end of each iteration, the weights of the initial data will be updated, and the weights of correctly classified samples become smaller and the weights of incorrectly classified samples become larger. By updating the weights of samples, the model will be more focused on misclassified samples after one iteration, so as to advance the classification effect of the model. The disadvantage of SMOTEBoost is that it generates a large amount of data, which leads to longer training time.
RUSBoost [20], which can handle multi-class imbalanced data problems and two-class imbalanced data problems, was proposed by Seifert et al. It can overcome the shortcomings of longer training time for SMOTEBoost. RUSBoost consists of random under-sampling and AdaBoost, and each iteration process is divided into two stages. In the first stage, random under-sampling, randomly removing samples from the majority class, is used to adjust the data distribution so that all classes have the same size. In the second stage, the weak classifier is trained using the data generated in the first stage. After the classifier is trained, the weights of misclassified samples will also be updated. Although it overcomes the shortcomings of SMOTEBoost, random under-sampling may discard the more important data in the data sets, resulting in reduced classification performance.
MEBoost [25] integrates two weak classifiers under the framework of boosting, but it can only deal with the imbalanced data problems in the binary classifications. In each iteration, either the extra tree classifier or the decision tree classifier is chose for training. This method can combine the advantages of the two classifiers so that the classification effect is better. AUC is used to choose the best ensemble model in the training process. RB-Boost [21] was proposed by Díez-Pastor, combining random balance and AdaBoost. It can only carry out the two-class imbalanced data problems. In random balance, the temporary data sets are obtained by randomly under-sampling one class and using SMOTE to over-sample another. Random balance increases the diversity of the data sets. In addition, RHSBoost [26], AdaCost [27], etc. have also been presented in order to deal with the two-class imbalanced data problems.
In this paper, we used MAUC, MG-mean and MMCC as the evaluation criteria, and compared our proposed algorithm with the previously presented algorithm. AUC is considered to be a more robust evaluation standard and it is often used to evaluate imbalanced data problems. The AUC for evaluating multi-class imbalanced data is shown in Eq. (5), which is called MAUC [28]. In Eq. (5),
Matthews correlation coefcient (MCC) is also often used as the two-class and multi-class performance evaluation standard. Its value is between
Geometric-mean (G-mean) [29] is the third method used to evaluate imbalanced data in our paper, and it can be extended to multi-classification problems. In this paper, we used the geometric mean of the recall values of all classes to represent the G-mean in a multi-classification tasks, as shown in Eq. (8).
The process of multi-class WHMBoost.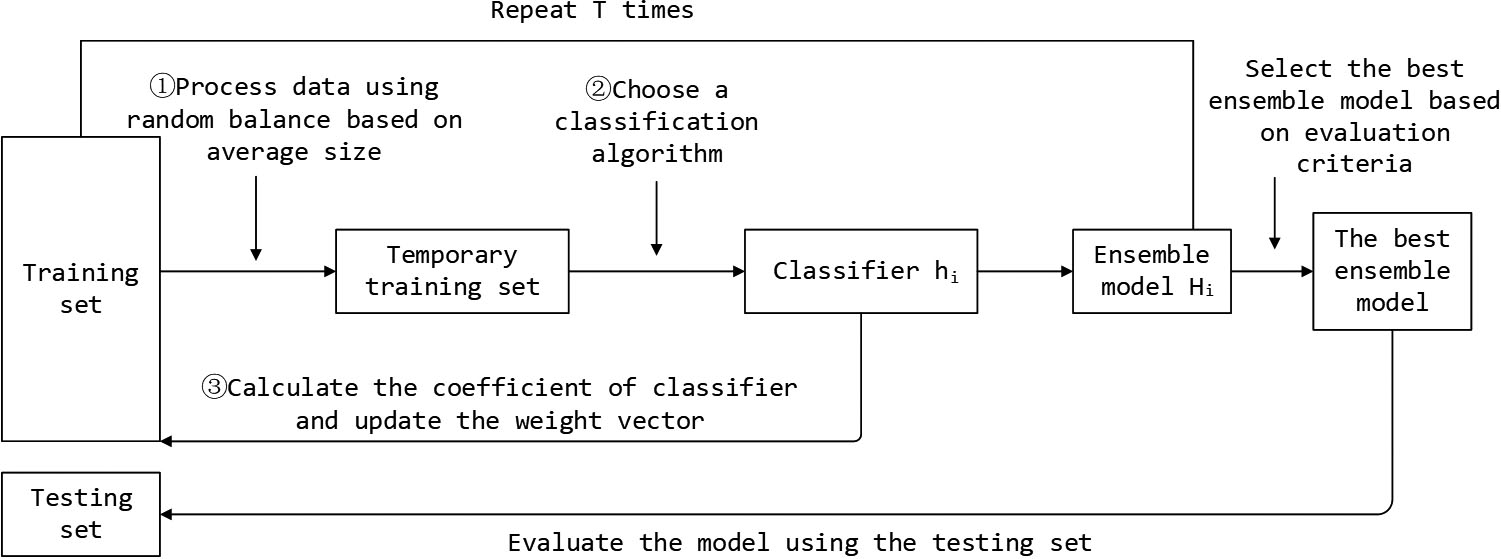
In [12], we presented a weighted hybrid ensemble method, called WHMBoost, in order to carry out the binary-class imbalanced data problems encountered in the field of machine learning and data mining. In this paper, we put forward multi-class WHMBoost for classifying multi-class imbalanced data, which directly extends WHMBoost, which can only solve the imbalanced data problems in two-class classification tasks, to an algorithm that can solve the multi-class imbalanced data problems. We have made some improvements to the algorithm so as to make the presented algorithm better deal with multi-class classification tasks. Multi-class WHMBoost is a hybrid method that combines algorithm-level method and data-level method. The data-level method we use is random balance based on average size. This method is inspired by random balance [21]. In our algorithm, random balance based on average size is used to balance the data sets while increasing the diversity of the data sets. It can make the size of each class randomly tend to the average size of all classes, that is, classes with a size smaller than the average size will be added samples and classes with a size larger than the average size will be reduced samples. The algorithm-level method we use is boosting algorithm. We use two base classifiers which are support vector machine and decision tree classifier in the boosting algorithm. In order to make support vector machine and decision tree classifier complement each other, we assign weights to them in order that they participate in training with given weight. Each iteration of the algorithm consists of two stages. In the first stage, random balance based on average size is applied on the original data sets so that the size of all classes tend to be equal. In the second stage of the method, boosting is executed on the generated data sets, in which a base classifier is selected for training according to the given weight. The algorithm process of multi-class WHMBoost is shown in Fig. 1.
In random balance based on average size, we use random under-sampling and SMOTE (synthetic minority over-sampling technique) to adjust the class distribution. In this method, we first obtain the average size of all classes in the data sets, then use random under-sampling to randomly remove samples from those classes whose size is larger than the average size, and use SMOTE to generate new samples and add them to those classes whose size is smaller than the average size. We do not directly change the size of each class to the average size, but use a coefficient to randomly tend the size of each class to the average size so as to increase the diversity of the training sets. After the random balance based on average size processing, the size of each class is changed as shown in Eq. (9). When the size of a certain class is equal to the average size of all classes, its size is not changed. If the size of a certain class is greater than the average size of all classes, its size becomes
In the presented multi-class WHMBoost, the base classifier set is
The pseudo code of our presented multi-class WHMBoost is shown in Algorithm 3. Its steps are basically the same as those of WHMBoost. The different steps are described below. During each iteration, the presented algorithm needs to use random balance based on average size to generate a temporary data set
[htb]
Imbalance data sets used in the experiments
Imbalance data sets used in the experiments
A total of 18 imbalanced data sets were collected to evaluate our presented multi-class WHMBoost and the previously proposed ensemble algorithms. Among them, 9 data sets are from KEEL [30] and the remaining data sets are from OpenML. The imbalance rate of these data sets ranges from 1.03 to 39.18. In the multi-class imbalanced data sets, the imbalance rate is defined as the maximum number of samples in the class divided by the minimum number of samples in the class [31].
The characteristics of the data sets are shown in Table 1. The name of the data sets is displayed in the first column. The number of classes in the data sets is shown in the second column. The number of features in the data sets is shown in the third column. The types of features include real, integer and nominal value. The number of instances and the number of instances of each class are displayed in the fourth column and the imbalance rate (IR) is shown in the fifth column. The origin of the data sets, either OpenML or KEEL, is shown in the last column.
Experimental results and analysis
The data set is randomly divided into training set and testing set in each experiment. the training set accounts for 80% of the entire data set. The proportion of the number of samples of the same class in the training set and the test set to the total number of samples is equal so as to preserve the original imbalance rate. The algorithm is trained using the training set and the effectiveness of the algorithm is evaluated using the testing set. As in [12], this process is repeated 50 times and the experimental result is the average of 50 experiments. In all experiments, the number of iterations of the ensemble model is the same. If the pseudo loss
On 18 multi-class imbalanced data sets, we compared the performance of multi-class WHMBoost (WHMBoostM, WHMBoostA) with state of the art ensemble algorithms like SAMME, SMOTEBoost, GradientBoost and RUSBoost using MAUC, MG-mean and MMCC as evaluation criteria. The best ensemble model in the WHMBoostM algorithm is selected based on MMCC and the best ensemble model in the WHMBoostA algorithm is selected based on MAUC. The range of
Score obtained using MAUC as the evaluation criterion
Score obtained using MAUC as the evaluation criterion
Hochberg test results using MAUC as the evaluation criterion
Average ranks from Friedman test using MAUC as the evaluation criterion.
Table 2 shows the scores obtained by multi-class WHMBoost and other ensemble algorithms based on MAUC. WHMBoostA gets the best score on 14 data sets, accounting for 77.78% of the total data sets. WHMBoostM gets the best score on 4 data sets, accounting for 22.22% of the total data sets. In the data sets “optdigits”, “analcatdata_authorship” and “cardiotocography”, WHMBoostM and WHMBoostA get equal scores and both get the highest scores. Figure 2 shows the average ranks of various methods. From the figure, we can find that the average rank of WHMBoostA is the smallest. The methods for ranking in the second and third positions are WHMBoostM and GradientBoost, respectively. SMOTEBoost has the largest average rank. The results of the hochberg test based on MAUC are shown in Table 3. According to the adjusted
Score obtained using MMCC as the evaluation criterion
Average ranks from Friedman test using MMCC as the evaluation criterion.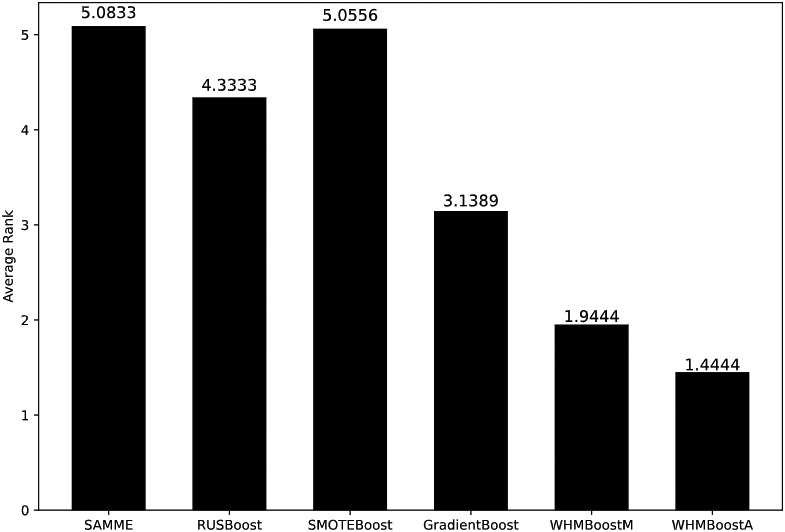
By using MMCC as the evaluation criteria, the scores obtained by the presented method and other algorithms are demonstrated in Table 4. WHMBoostA gets the best score on 14 data sets, accounting for 77.78% of the total data sets. WHMBoostM gets the best score on 3 data sets, accounting for 16.67% of the total data sets. From the table, we find that the scores obtained by WHMBoostA and WHMBoostM are not much different on most data sets. In Fig. 3, the average ranks of WHMBoostA is 1.2778 and is the smallest. The average rank of WHMBoostM is 1.9444 and the average rank of GradientBoost is 3.0. These two methods rank behind WHMBoostA. In Table 5, the adjusted
Hochberg test results using MMCC as the evaluation criterion
Score obtained using MG-mean as the evaluation criterion
We also used MG-mean to evaluate the presented algorithm and other algorithms and the scores are demonstrated in Table 6. From the table, we can see that WHMBoostA obtains the highest score on 12 data sets, accounting for 66.67% of the total data sets, while WHMBoostM obtains the highest score on 4 data sets, accounting for 22.22% of the total data sets. In the table, SAMME, RUSBoost and SMOTEBoost have scores of 0 on some data sets. This may be related to keeping four decimal places. In Fig. 4, the average rank of WHMBoostA is still the smallest, followed by WHMBoostM. At the same time SAMME obtains the largest average rank. Based on MG-mean, the adjusted
Based on the above experimental results and analysis, we can conclude that there are significant differences between the presented algorithm and other ensemble algorithms. In the multi-class imbalanced data sets, the performance of the proposed method is excellent and it can produce more effects than other ensemble methods. Although there are no significant differences between WHMBoostA and WHMBoostM, WHMBoostA seems to be able to obtain better results. In future experiments, we can use MAUC as an evaluation criterion in our algorithm to select the best-performing ensemble model. In the experiment, we also found that on most data sets, assigning a larger weight to the support vector machine seems to get better performance. On only a few data sets, the best scores were obtained when a larger weight were assigned to the decision tree classifier.
Hochberg test results using MG-mean as the evaluation criterion
Average ranks from Friedman test using MG-mean as the evaluation criterion.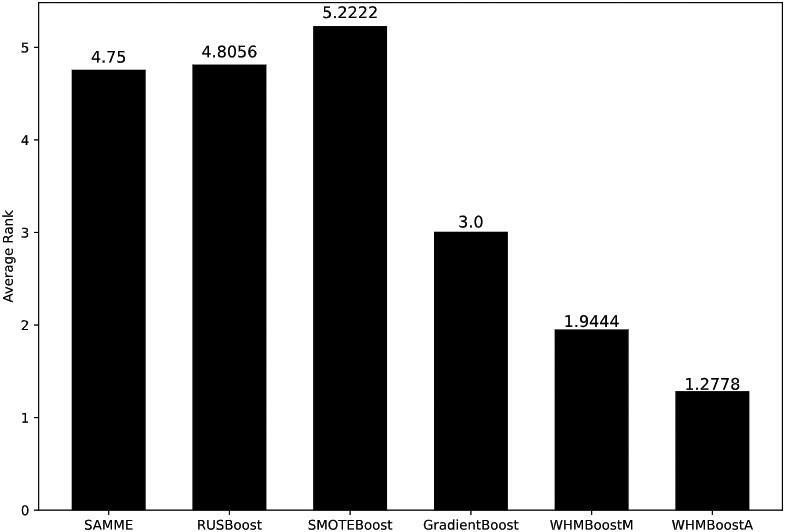
Due to internal and external reasons, most data sets in real scenarios are imbalanced. A model trained on the imbalanced data sets will be more focused on the majority class and ignore the minority class that we are interested in. This is determined by the inherent characteristics of the imbalanced data sets. The classification tasks of the multi-classification problems are much more complicated than the classification tasks of the two-classification problems. In the classification tasks of the multi-classification problems, there may be numerous minority classes and numerous majority classes, which makes it difficult to judge the connection between different classes in the data sets. Previous researchers have put forward many algorithms in order to deal with the imbalanced data problems in two-class classification tasks and multi-class classification tasks. These methods focus on solving the imbalanced data problems in binary classification tasks. The imbalanced data problems in multi-class classification tasks are still worthy of extensive research. In this paper, multi-class WHMBoost is put forward so as to carry out the imbalanced data problems in multi-class classification tasks. It directly expands the hybrid weighted ensemble model we previously put forward to deal with the imbalanced data problems in two-class classification tasks into a method to carry out the imbalanced data problems in multi-class classification tasks. In our proposed algorithm, two base classifiers are used and weights are assigned to them in order that they can give full play to their advantages. Like SAMME, when we calculate the weight of the base classifier in the ensemble model, the formula used is shown in Eq. (4), in which there is the extra term
Footnotes
Acknowledgments
We would like to thank the Natural Science Foundation of China (NSFC) under Grant 11972275 for funding our work. We used datasets from OpenML and KEEL in our work and we also express our gratitude to them.