
Abstract
Graph Neural Networks (GNNs) have achieved remarkable success in graph-related tasks by combining node features and graph topology elegantly. Most GNNs assume that the networks are homophilous, which is not always true in the real world, i.e., structure noise or disassortative graphs. Only a few works focus on generalizing graph neural networks to heterophilous or low homophilous networks, where connected nodes may have different labels. In this paper, we design a simple and effective Graph Structure Learning strategy based on Feature and Label consistency (GSLFL) to increase the homophilous level of networks for generalizing any existing GNNs to heterophilous networks. Specifically, we first introduce a method to learn graph structure based on node features and then modify the graph structure based on label consistency. Further, we combine the GSLFL with three existing GNNs to learn node representations and graph structure together. And we design a self-training method to iteratively train models and modify graph structure with pseudo-labels. Finally, our empirical results on 6 public networks with homophily or heterophily, and structure attacks show that our methods outperform the state-of-the-art methods in most cases.
Introduction
The graphs represent the relationships of objects, which are ubiquitous in the real world, such as social networks, traffic networks, bio-informatics networks. Graph neural networks (GNNs) have shown the advantages to learn the node or graph representations for graph-related tasks, for example, node classification [1, 2, 3, 4], graph classification [5, 6, 7]. Most GNNs integrate the node features and graph structure via aggregating the information from neighbors to update the node representations. One premise of this message propagation mechanism is the homophily assumption of networks that the connected nodes have the same labels or similar features. The homophily is a general principle in most real-world networks. But there are also some networks with heterophily, such as disassortative graphs, in where the connected nodes may have different labels and features. For example, the different amino acid types often connect in protein structures, most people prefer to communicate with people of opposite gender in dating networks [8]. Meanwhile, the networks may be noisy or incomplete due to the inevitable error during the data collection.
Most GNNs cannot generalize to networks with heterophily, in where the GNNs may gather large amounts of noise from neighbor nodes. At the same time, recent studies have shown that the small and less noticeable disturbances in graph structure can disastrously reduce the performance of the strongest and most popular GNNs [9]. In Fig. 1, we show the node classification results of different models on two real-world datasets under various structure noise ratios (see Definition 1 in 3 section). The x-axis represents different structure noise ratios, and the y-axis represents the classification accuracy of the model. We change the structure noise ratio of networks by attacking the graph structure and maintain the same number of nodes and edges (Algorithm 1 in 4.1 section). The higher graph structure noise means the lower homophily. The details of the experiments can be found in the empirical evaluation section. We can see that the classification accuracy of all models decreases rapidly as the structure noise increases (the level of homophily decreases) except for MLP that only uses node features. And the performance of simple MLP is even superior to many popular GNNs when the structure noise is high.
The node classification results of models with different structure noise ratios.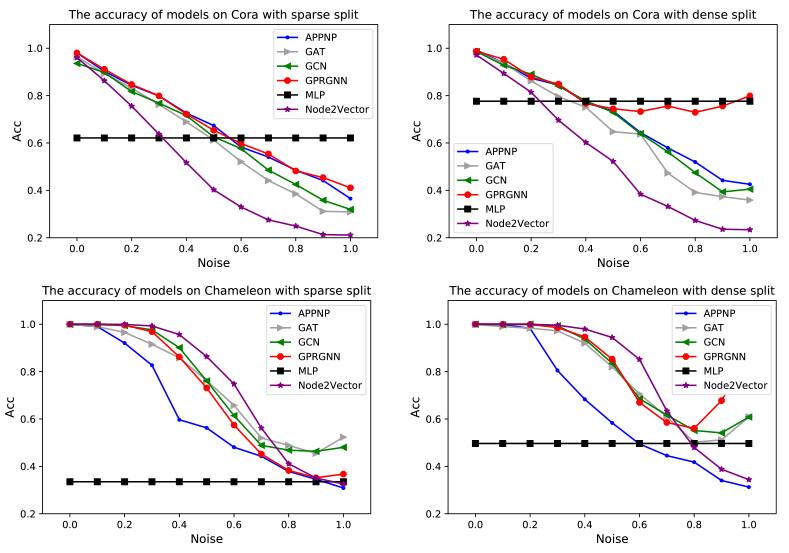
Recently, a few works have begun to generalize the GNNs to networks with different levels of homophily, such as GEOM-GCN [10], H2GCN [11], FAGCN [12], GPRGNN [13]. These GNN models are well-designed for networks with heterophily. Recently, Ma et al. [14] propose that homophily may not be a necessity for Graph Neural Networks and GCN can achieve good performance on heterophilous networks under the condition that nodes with the same label share similar neighborhood patterns. But the condition is not always true in real world. So it is also necessary to explore how to generalize the GNNs to networks with heterophily.
From Fig. 1, we also find an interesting phenomenon that all the popular GNNs can achieve nearly 100% classification accuracy when the structure noise decreases to zero, that is, all connected nodes belong to the same class. Therefore, we propose whether it is possible to reduce the structure noise of the networks for improving the homophily level of networks, and thus improve the performance of the existing GNNs. Inspired by this, we propose a simple and efficient framework of Graph Structure Learning based on node Features and Label consistency (GSLFL), which can reduce the structure noise and be used as a plug-in to combine with any existing GNNs.
Different from these well-designed GNN models for heterophilous networks, our method focuses on improving the robustness of existing GNN models from the perspective of graph structure learning, which can deal with networks with different homophily levels. To the best of our knowledge, it is the first work that uses graph structure learning to solve the problem of performance degradation of most GNNs when the strong homophily is not satisfied. And there are very few works to consider label consistency in graph structure learning.
Specifically, similar to most graph structure learning methods, we first propose to learn the graph structure based on node features or representations. The intuition is that similar nodes in feature space should be connected and belong to the same class, which may reduce the structure noise and improve the level of network homophily. However, there may be noise in node features, so the learned structure may bring new structure noise. To reduce the structure noise, we design a novel strategy to modify the learned graph structure based on label consistency that connected nodes should have the same labels. Further, we design a self-training method to iteratively train models and modify graph structure. The proposed GSLFL is simple and effective. A large number of experimental results on standard datasets show that our proposed GSLFL combined with the popular GNNs can achieve state-of-the-art performance under different homophilous levels of networks.
The main contributions of the paper are as follows:
We find an interesting phenomenon that any existing GNNs can achieve nearly 100% node classification accuracy on most standard datasets by modifying the graph structure based on the label consistency to improve the homophilous level of networks. We propose a novel graph structure learning framework based on node features and label consistency, which can be plugged into any existing GNNs. We design self-training method to iteratively train models and modify graph structure based on predicted pseudo-labels. We run a large number of experiments on various types of standard datasets with homophily and heterophily, and structure attacks, which proves our proposed method, GSLFL, can improve the performance of any existing GNNs and achieve state-of-the-art performance on the node classification task.
The organization of this paper is as follows. Section 2 introduces the notations and related works. Section 3 presents the Graph Structure Learning based on node Features and Label consistency, and a self-training method. The experimental results and analysis are shown in Section 4. In Section 5, we propose our conclusions and future works.
In line with the focus of our work, we briefly introduce related works on Graph Neural Networks. For more details of Graph Neural Networks, please refer to the surveys [15, 16, 17].
Preliminaries
In this section, we introduce some basic concepts and notations used in this paper. Let
Most Graph Neural Networks learn node representations via the following message propagation mechanism:
where
Where
Follow the recent research works [10, 11, 12], we focus on homophily in class labels. We first define the structure noise ratio (It is contrary to the edge homophily ratio defined in [11]).
The graphs have strong homophily when structure noise ratio is small
In the section, we first introduce a method to change the structure noise, then discuss the phenomenon that most GNN models can achieve almost 100% node classification accuracy when the structure noise ratio is zero, and give an intuitive explanation. Inspired by this, we propose a structure learning strategy to reduce the structure noise of networks and improve the homophilous level of networks. Then, we combine our method, Graph Structure Learning based on Feature and Label consistency (GSLFL), with three graph neural networks, GCN, GAT, and GPRGNN. Further, we propose a sel-training method to train models and modify graph structure. Finally, we give an analysis of our method by comparing it with similar works.
The method of changing structure noise
In this paper, we define the structural noise ratio as the fraction of connected nodes with different labels on a graph (see Definition 1 in 3 section). We introduce a scheme to change the structure noise ratio on real-world networks, as shown in Algorithm 1 that references [35] but is different. The input of Algorithm 1 is adjacency matrix
The node classification results of models on real-world networks with 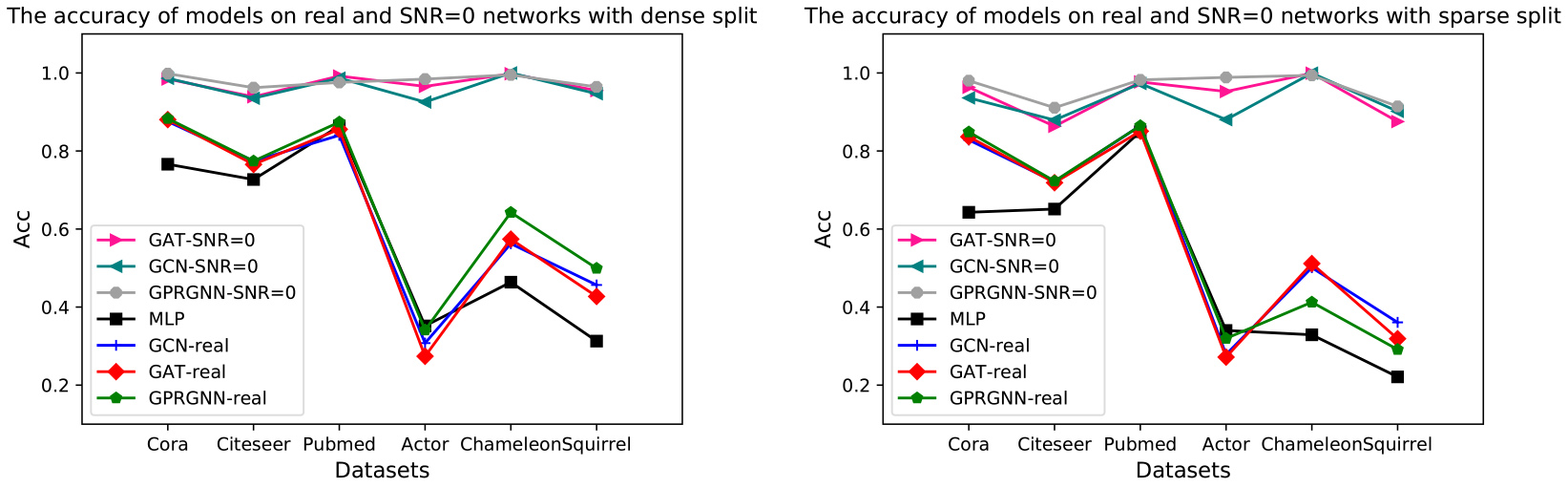
In the real world, the networks have different structure noise ratios, as shown in Table 1. The structure noise ratio of homophilous networks is low, and it is high on heterophilous networks. Based on Algorithm 1, we set different structure noise ratios, which can change the noise ratio of the real-world networks and affect the homophilous level of the networks. When the structure noise ratio is zero, all nodes in the network are only connected with the same labeled nodes. And there is no structure noise. So the network has the very strong homophily. We set the structure noise ratio of the real-world networks as zero, and then run the models to classify nodes on the original graph structure and the modified graph structure respectively. The experimental results are shown in Fig. 2. The x-axis represents different datasets, and the y-axis represents the classification accuracy of the model. We find that the node classification accuracy of all models in the modified graph structure is much higher than that of the original graph structure on all datasets (homophilous graphs and heterophilous graphs). Moreover, the node classification accuracy of all models on the modified graph is almost 100% on most datasets.
We give an intuitive explanation for this phenomenon from the perspective of label propagation. We assume that there is no structure noise in the network, that is, all connected nodes have the same labels. We run label propagation in the network, in where there are no unlabeled isolated nodes, and at least one node in each connected subgraph has labels. In this case, all unlabeled nodes can only get the label information from the nodes in the same category, and cannot receive the label information from the nodes in different categories. Finally, all nodes can get the correct label information, and the label propagation can achieve 100% node classification accuracy. Recently, as Dong et al. [35] have proved that the decoupled GCN(like APPNP) is essentially the same as the two-step label propagation. In the above experiments, we choose many training and validation samples. In this case, the unlabeled isolated nodes are very few and connected subgraphs without labeled nodes are also very few. So GCN, GAT, and APPNP can achieve almost 100% classification accuracy in the modified graph structure. Inspired by this, we explore to learn a clean graph structure for decreasing the structure noise ratio.
It is known that deep neural networks are prone to noise and error. Most GNN methods are highly sensitive to the quality of graph structure, and they require the perfect graph structure to learn node representations. But most of the real-world graph structures are noisy. And the performance of GNN models is significantly degraded when suffering the disturbance of graph structure, as shown in Fig. 1. This poses a great challenge to apply GNN to practical problems, especially in some risk-critical scenarios, such as medical analysis. Recently, many researchers have begun to focus on graph structure learning, and they are committed to jointly learning the optimal graph structure and GNN models. Most of the existing graph structure learning methods case the problem as metric learning based on distance between nodes or similarity of features. To the best of our knowledge, very little work is done to consider label consistency in graph structure learning. We are the first to study graph structure learning from the perspective of improving the homophilous level of networks, and jointly use the node features and label consistency.
The framework of graph structure learning based on feature and label consistency.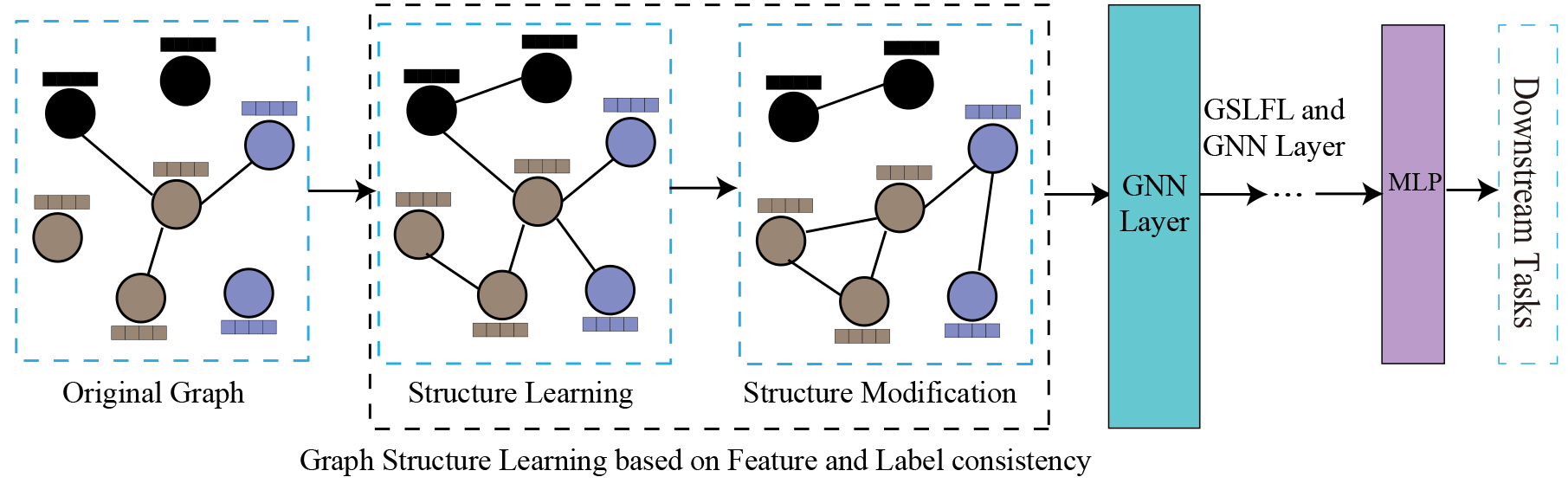
The existing methods of metric learning in graph structure learning usually include kernel function [28], attention mechanism [29] and cosine similarity [32]. These methods are learnable and based on the node features or representations in the hidden layer. The intuition behind this is that the nodes close to each other in the feature space should be connected in the graph structure. Inspired by this, we propose a simple and effective Graph Structure Learning framework based on Feature and Label consistency (GSLFL), as shown in Fig. 3. Our method includes three modules, structure learning module, structure modification module, and GNN learning module. We firstly propose to learn the similarity between nodes in the feature space and establish the sparse graph structure based on the threshold or KNN. Then let the learned graph structure combine with the original graph structure to form a new graph structure. However, both the learning graph structure and the original graph structure may have structure noise. Therefore, we further propose a graph structure modification scheme, which uses the labels of nodes in the training set and validation set to reduce the structure noise ratio of the network and improve the homophilous level of the network. Finally, our GSLFL can combine with any existing graph neural network methods for various graph-related downstream tasks.
In the
Where
Where
Where
Then the
Finally, we can run any existing GNN models on the modified graph structure to learn the representations of nodes or graphs and solve the downstream tasks. For example, we use GCN for node classification.
where
However, in real world, the labeled samples are rare, and the number of training set and validation set are few, which means that we can only delete few inter-class edges and add few intra-class edges based on the labeled nodes. To solve the problem, we propose a self-training method to enhance the training set based on the prediction of models. Specifically, we obtain the pseudo-labels of test set based on threshold
where
We iteratively train model and modify graph structure with pseudo-labels in several stages until the performance of the model is not improved.
An intuitive explanation for the effectiveness of the structure modification module is as follows. We first denote the graph structure as:
where
In this section, we show the results of node classification on 6 standard datasets and prove the effectiveness of our GSLFL method. First of all, we introduce the datasets and experimental setup, and then integrate our method into the three existing methods, GCN, GAT, GPRGNN to get the improved models, GCN
Datasets and experimental setup
Statistics of the datasets
We use the source codes of models including Node2Vector, ChebNet, GCN, GAT, APPNP, which are from the website.2
For all comparative methods, we follow the original setup from the authors. And for the three improved models, GCN
In the section, we first show the accuracy of node classification on the standard datasets that are usually used to evaluate the performance of models in the community. The results of dense split and sparse split are shown in Tables 2 and 3, respectively.
Accuracy of node classification under dense split
Accuracy of node classification under dense split
Accuracy of node classification under sparse split
From Table 2, we find that our models achieve the best performance on all datasets, for example, GPRGNN
From Table 2, we also find that simple MLP, which only uses the node features and ignores the graph structure, is better than some popular GNN models on heterophilous networks. But the GNN models, such as GCN, GAT, can achieve better performance than MLP when running on the corrective graph (GCN
In this section, we show the robustness of the models under structure attacks. The details of attack strategies are shown in Algorithm 1. It should be noted that we assume that we know the labels of all nodes and the graph structure during the structure attacks. We randomly delete the intra-class edges and add the inter-class edges. Then we run all models on the networks with different structure noise ratios. We show the results of the models on three datasets. Figures 4 and 5 show the results of node classification under dense split and sparse split respectively.
The node classification results of models on different structure noise ratios under dense split.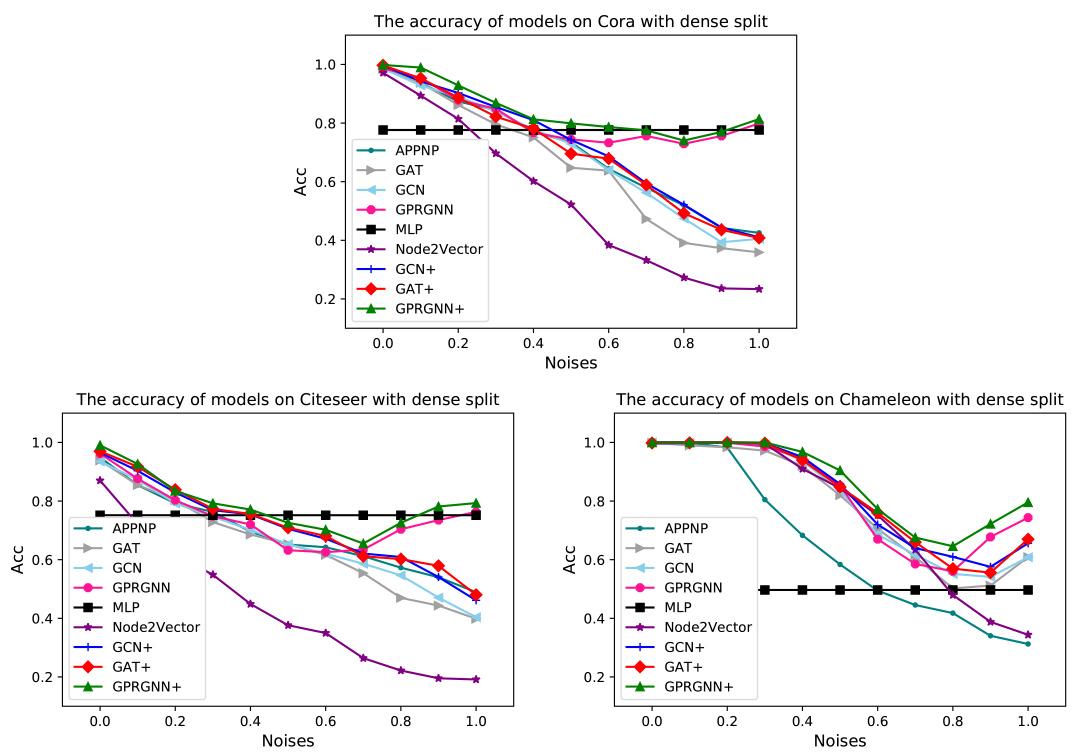
The node classification results of models with different structure noise ratios under sparse split.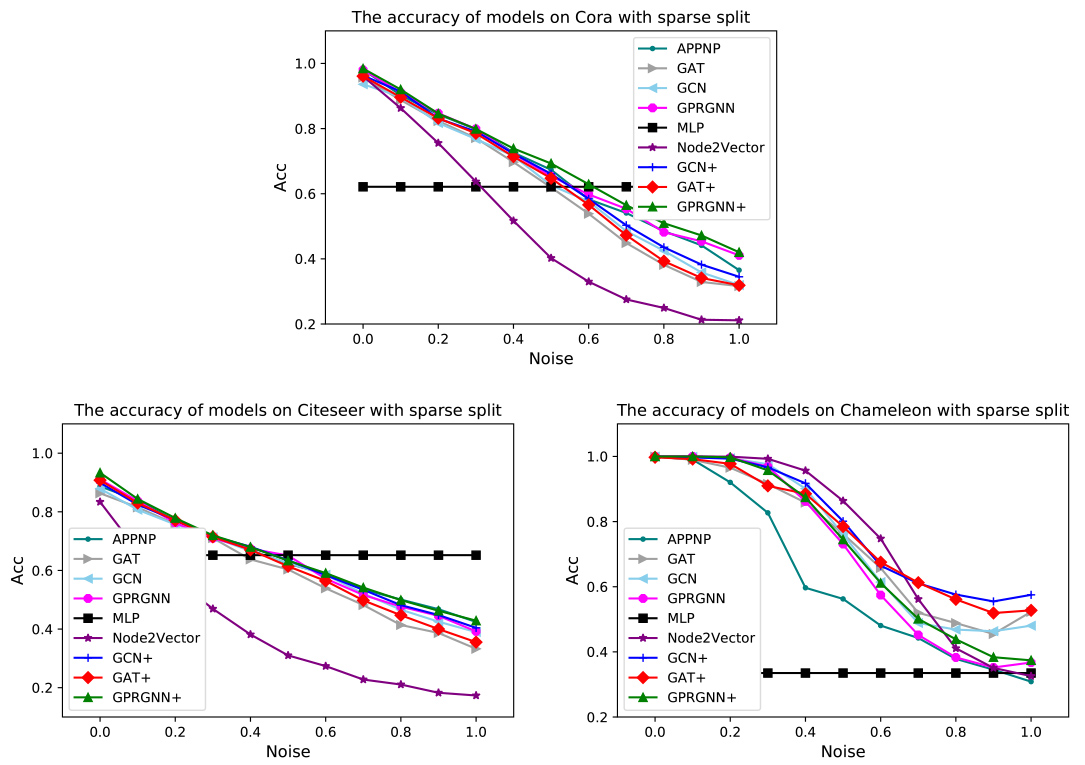
From Fig. 4, we find that the node classification accuracy of almost all models decreases with the increase of structure noise ratio (the level of the network homophily decreases), indicating the effectiveness of structure attacks. Meanwhile, we find that the performance of popular GNN models, such as GCN, GAT, and APPNP, decreases significantly with the increase of structure noise ratio. However, GRPGNN shows the robustness to structure attacks, which indicates that it is useful to generalize GNN models to networks with different homophilous levels. Node2vector achieves the worst performance under structure attacks because it completely depends on the network structure for representation learning. But MLP only uses node features and is stable under different structure noise ratios. The most important thing is that our models are better than the original models under different structure noise ratios, which proves the robustness of our model against structure attacks. Finally, on Chameleon, we observe that as noise increases, the classification performance first decreases, it eventually begins to increase, showing a V-shape pattern, which is similer to [14]. The reason may be that as we keep adding more noises, the neighborhood pattern gradually approaches the same for nodes with the same label.
From Fig. 5, we can also find similar conclusions as in Fig. 4. For example, our improved models are always better than the original models. However, the difference is that almost all models are worse than simple MLP under sparse split when the structure noise ratio is high, which shows that the existing GNN models still have a huge space to improve the robustness for structure attacks.
The results of models under dense split
The results of models under dense split
We conduct the ablation study to verify the effect of the structure learning module, structure modification module, and self-training method. The results of models for node classification under dense split are shown in Table 4. The “
In this paper, we explore to generalize the GNN models to networks with different homophilous levels and improve the robustness of GNN models. Firstly, we find that most popular GNN models can achieve nearly 100% accuracy for node classification when the structure noise ratio of the networks is zero, which means the networks have strong homophily. So we propose a simple and effective Graph Structure Learning framework based on Feature and Label consistency (GSLFL) for reducing the structure noise and increasing the homophily level of networks. Our method includes three modules, structure learning module, structure modification module, and GNN module. We conduct a large number of experiments on 6 standard datasets that include homophilous networks and heterophilous networks, which demonstrates that our method can significantly improve the performance of existing GNN models on networks with different homophily levels. And the experiments under structure attacks further prove that our method can enhance the robustness of GNN models. In the future, we will aim to improve the generalization performance of our method, and further extend our method to other tasks, for example, graph classification.
Footnotes
Acknowledgments
This paper is supported by the National Key Research and Development Program of China (Grant No. 2018YFB1403400), the National Natural Science Foundation of China (Grant No. 61876080), the Key Research and Development Program of Jiangsu(Grant No. BE2019105), the Collaborative Innovation Center of Novel Software Technology and Industrialization at Nanjing University.