
Abstract
This research explores the potential of supervised machine learning models to support the decision-making process in demobilizing ex-combatants in the peace process in Colombia. Recent works apply machine learning in analyzing crime and national security; however, there are no previous studies in the specific contexts of demobilization in an armed conflict. Therefore, the present paper makes a significant contribution by training and evaluating four machine learning models, using a database composed of 52,139 individuals and 21 variables. From the obtained results, it was possible to conclude that the XGBoost algorithm is the most suitable for predicting the future status of an ex-combatant. The XGBoost presented an AUC score of 0.964 in the cross-validation stage and an AUC of 0.952 in the test stage, evidencing the high reliability of the model.
Introduction
Colombia has suffered an armed conflict for more than fifty years, bringing negative consequences on social and economic development. As an alternative to the use of weapons, since 1982 a demobilization process has been developed. The illegal combatant is motivated to leave the insurgent group for economic, social, and judicial benefits [1]. Official data show that between 2001 and 2020, seventy-five thousand seven hundred and thirty-one (75,731) people (85% men and 15% women) from armed groups outside the law embarked on the path of return to civilian life [2]. Demobilization as a peace strategy has been evidenced as a positive element in armed conflicts; for example, the research of Ribetti [3] illustrates how disengagement can be an effective strategy for security only under specific circumstances. Consequently, in the research of de Posada [4] identifies that six first-order factors explained demobilization: survival, physical-psychological safety, civilian safety, justice, self-determination, and belongingness. The article of Nussio and Howe [5] analyze Post-Demobilization Trajectories of Violence, exploring the causes that explain why rates of violence can rapidly increase in a post-demobilization context.
As a result, to the degree that the demobilization process is guided by an advanced decision-making framework based on objective evidence, it will foster public confidence in the existence of a sound strategy for consolidating the peace process. The goal will be achieved by reducing the drop-off percentage in the process and identifying the critical aspects to succeed in the demobilization, considering the characteristics of each combatant. The primary objective of this research is to investigate beyond the fitting of machine learning models. Thus, our proposal’s success is not contingent on accurately anticipating when an ex-combatant will exit the demobilization process. Rather than that, it aims to improve the decision-making on the acceptance and allocation of benefits received by a demobilized individual, thus maximizing success in reintegrating into civilian life.
The dataset comprises the statistics published by the Agency for Reincorporation and Normalization (ARN), shows data on demobilization, location, year of entry into the process, benefits of economic insertion, benefits of academic training and training for work, economic occupation, family census, social service actions, among others. The dataset has 55,600 participants in demobilization processes between 2001 and 2019.
In this paper, a supervised machine learning approach is proposed to predict ex-combatants status in the Colombian demobilization process. For the creation of the model, the Random Forest, GLMNET, KNN and XGboost algorithms will be implemented. In addition, a cross-validation procedure will evidence the algorithm with the best performance.
The remainder of the paper is organized as follows. In Section 2, a description of the demobilization process In Colombia is presented and a presentation about relevant related works. In Section 3, it describes the dataset and the machine learning approach to analyze data. Section 4 describes the machine learning models implemented and the performance metrics of the evaluation. Section 5 presents the discussion of the paper. The conclusions are in Section 6, and finally, in Section 7, the conclusions.
Background and context
The ARN defines the Disarmament, Demobilization and Reincorporation (DDR) process as one that contributes to security and stability in a territory after emerging from a situation of organized violence by disarming combatants and removing them from military structures. The DDR is the one who provides them with the necessary tools to reintegrate socially and economically into civil society.
The three components of the DDR process in Colombia are closely correlated since if disarmament and demobilization are carried out effectively, security conditions in the local and national context will improve, a scenario that facilitates the reintegration of ex-combatants. Consequently, Mouly et al. [6] consider that the disarmament and demobilization process, which usually occurs after a period in which combatants gather in safe areas waiting to return to civilian life, is when the time for reintegration arrives.
According to the Colombian Agency for Reintegration, there are two distinct methods of combatant demobilization, i) the collective one, which implies a prior negotiation with the national government and the group that intends to lay down its arms. This demobilization obeys the order given by the leaders of the respective structures and not necessarily the will of each combatant, ii) in a individual demobilization, the combatant makes the voluntary decision to leave the group to which he belongs.
The regulation of the DDR process is established in Decrees 128 of 2003 and 395 of 2007, indicating that persons demobilized under the framework of agreements with armed organizations outside the law or individually may benefit from the socioeconomic reintegration programs established by the National Government. Thus, providing demobilized individuals with procedures that enable them to create a life project in a secure and dignified manner. Figure 1 presents the route and steps followed in the reintegration process.
Demobilization route.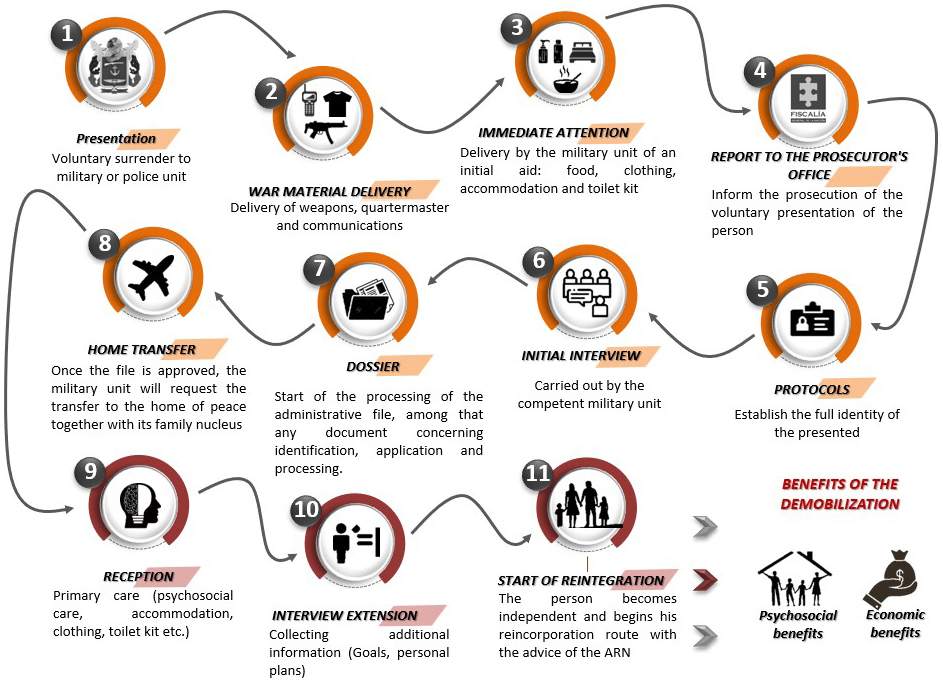
Beyond disarmament and demobilization, the reintegration process represents a challenge for society and is considered the most problematic stage of the peace process; Because reintegration is an ongoing process that takes place mostly on a local level and through which demobilized personnel obtain civilian status. Thus, reintegration is part of the overall development of a country and constitutes a national responsibility that can be complemented with international support. Therefore, Montoya and Herrera [7] state that an ex-combatant can comply with disarmament and demobilization. However, by not reaching the desired final state with reintegration into civilian life, he is prone to return to criminal activities.
Because reintegration reverses such importance as the final stage of the process, the accuracy of forecasts is of great importance to conclude the DDR effectively. Since the phenomenon’s complexity is given by many demobilized people and the absence of reliable historical information to implement differentiated actions to achieve a better adaptation of people to civilian life and therefore ensure the sustainability of the peace process in the future. The reintegration of ex-combatants into the law is one of the pillars of the peace process. It means the consolidation of a public policy to guarantee and promote demobilized people’s social and economic development, aiming to have no incentive to take up arms again. In this way, the primary purpose of the reintegration process is to provide a series of economic aids to generate a self-sustainable life through the creation of companies, education, and training in legal businesses. Thus, a predictive model provides the tools and techniques necessary to manage and process social data about demobilized people. So, handling the complexity of a process with no background and providing a support scheme for strategic and operational decision-making that positively affects people’s integration into civilian life.
Regarding the international experience in cases of reintegration processes, Sacristán [8] mentions those developed in Africa, Asia, and Central America. This author states that reintegration initiatives failed in South Africa and Burundi due to non-compliance with incentives or the lack of technical support to demobilized persons. In countries such as Indonesia, El Salvador, and Nicaragua, some initiatives such as access to land were adopted; however, the experience showed that land delivery requires access to a comprehensive financial aid package. For its part, El Salvador stands out with success in the reintegration process by involving non-ex-combatant communities, who contributed legitimacy to the process.
The criterion for access to the demobilization process relies on three requirements. i) having belonged to an armed organization outside the law, ii) To have the will to rejoin civilian life, and (iii) not having committed crimes against humanity. Due to the lack of theoretical references for contexts such as the Colombian case, the machine learning model does not pretend to be a biased factor for acceptance on the process; instead, it seeks to alert decision-makers about the probability of dropping out of an ex-combatant.
The information provided by the ARN refers to the 76,067 people who left the ranks of armed groups outside the law in Colombia between 2001 and 2021, of which 51,586 people voluntarily entered the reintegration process. That is to say that 68% of this population decided to return to civilian life, accessing the different benefits granted by the state. However, only 26,091 people have completed the reintegration process into civilian life, and 3,867 are currently completing their reintegration route, suggesting that 21,628 people (42%) are out of the process or absent. Therefore, the forecasting methods derived from machine learning will provide decision-makers in reintegration processes, more accurate, transparent, and good behavioural predictions that allow corrections to be made and help to conclude the DDR process effectively.
Machine learning models applied to the social sciences have become an exciting challenge for researchers, given that the particularities of social problems are somewhat different from those of industry [9]. While the industrial and technological sectors aim to boost productivity and competitiveness via the integration of information systems [10]. The social sciences are concerned with integrating data to generate decisions that positively influence people’s lives [11]. For example, forecasting the state of food security [12], predicting and improving the performance of athletes in competitions [13], predicting student attrition using administrative data [14], predicting future cases of malaria [15] and forecasting the final state of the spread of COVID-19 [16].
The use of data as an input to information systems in social contexts is widespread. Social agencies are increasingly implementing artificial intelligence methods in a wide range of applications. For example, to predict issues related to crime and public safety, such as the misconduct of subjects in prison for assigning appropriate security levels to inmates [17], killings committed by persons on probation to identify persons who pose a severe threat to public safety [18]. Similarly, threats to public safety, such as domestic violence, have been predicted [19], unemployment and marital status [20], future violence to help judges make sentencing decisions after conviction [21], and in controlling violence in prisons using assembly methods [22]. In the Colombian case, machine learning methods have been used to make COVID-19 forecasts [23], predict future dengue cases [24], predict insolvency in advance [25], and predict the outcome of missing persons [26].
Related works
During the disarmament process of ex-combatants, one of the most relevant issues is demobilization and social reintegration; however, there is not enough information that is useful to support the decisions made in these peacebuilding environments.
However, despite the scarce information, there are different approaches to the issue of demobilization of ex-combatants from armed conflicts from quantitative or qualitative approaches. Within the quantitative approach, specifically for the Colombian case, the study by Samii, et al. [27] estimates causal effects retrospectively from microdata with the help of a machine learning ensemble, illustrating an analysis of options to reduce recidivism of ex-combatants in Colombia. Consequently, in an approach to violence analysis, the work of Bazzi, et al. [28] research about How feasible is violence early-warning prediction? Attempting to predict violence one year ahead with a range of machine learning techniques using data from Colombia and Indonesia; Concluding that the developed models poorly predict new outbreaks or escalations of violence even with unusually rich data.
Meanwhile, in a direct application of machine learning to DDR processes, the paper of Kobach, et al. [29] uses Random Forest to determine predictors for appetitive aggressive and trauma-related mental illness. By investigating the frequency of psychopathological symptoms for high- and low-intensity conflict demobilization settings. Similarly, in the work of Quintero-Zea et al. [30] designed a study to characterize the emotional processing of Colombian ex-combatants of illegal groups, using supervised learning techniques and developing a tool to support decision-making during interventions with ex-combatants in the process of reintegration into society.
From another approach, the work carried out by Garcia-Barrera et al. [31] particularly analyzed the empathy factor by means of confirmatory factor analysis. Within their results, it was found that the manifest variable “empathic concern” has a strong correlation with the latent factor “empathy”. This generates a guide on the variables of greater importance in the reintegration processes of ex-combatants.
Finally, the work of Therese [32] proposes a new measurement strategy for territorial control in asymmetric civil wars. Territorial control is conceptualized as an unobserved latent variable that can be estimated via observed variation in rebel tactics, modelling the latent variable, territorial control via a Hidden Markov Model (HMM).
On the other hand, from a qualitative point of view, the work of Rosenau, et al. [33] analyzes 15,000 surveys of men and women who have left the Revolutionary Armed Forces of Colombia (FARC) and other violent extremist organizations. Thus, identifying the main factors that contributed to the decisions to leave the armed struggle: ideological disenchantment, the relentless nature of the government’s counterinsurgency campaign, the physical abuse by commanders, and the wish to reconnect with the families and rebuild their personal lives.
The work presented by Kaplan and Nussio [34] analyze the justifications for recidivism related to the experiences of combatants, criminal motives and surveys of groups of ex-combatants in Colombia. This study concludes that antisocial personality factors, absence of family ties, lack of educational achievement and presence in criminal groups are strongly related to recidivism among ex-combatants.
However, the work of de Vries and Wiegink [35] analyze the context where the disarmament, demobilization and reintegration (DDR) process do not always account for the difficulties for understanding community dynamics. Therefore, arguing that communities are not singular entities but subject to change and consist of people with different ideas and viewpoints about returning fighters.
The research of Baez, Santamaría-García and Ibáñez [36] develops integrative approaches for ex-combatants, including social, cognitive and affective mental processes. By considering the situated nature of post-conflict scenarios and the urgent need for evidence-based interventions and suggesting a two-stage approach for addressing ex-combatants’ reintegration programs. Likewise, the work presented by Schmitt et al. [37] analyzes the adversities faced by a reintegration process. The authors study on a sample of the population of the Democratic Republic of Congo, the factors of exposure to trauma, perpetration, mental health problems and stigmatization associated with the process of reintegration into society. Their findings highlight the need to intervene jointly on aspects of individual mental health, aggression and collective discriminatory positions.
For the Colombian case, the study of Casas-Casas and Gúzman-Gómez [38], propose that the processes DDR involve learning new ways of solving shared problems (mental models) through nonviolent mechanisms and recommending that disciplines such as political science take care of the perspectives of the process to produce an iterative dynamics that will switch on alarms and reorient the process when needed, with the aim of building true and lasting peace.
Data and methods
For this research, we use the public database of people who have entered the reintegration process in the context of the peace process in Colombia [39]. The dataset is composed of 52,139 observations and 21 predictor variables.
Considering the variables, eleven are categorical, eight binary and two numerical as shown in Table 1. Consequently, a 10-fold cross-validation approach was used to eliminate bias. The Training and testing data sets were chosen at randomly; so, the training dataset contains the 70% of the data and test dataset the remaining 30%. The Colombian reintegration agency collected and published this dataset and is fully available for research, but it had missing values. These missing values seem to be at random, so that the model will use only complete cases. Table 1 shows the variable name, the attributes chosen for the analysis and the proportion of missing values by each variable.
Data Pre-processing
A cross-validation scheme such as the one presented in Fig. 2 is used. Consequently, ten new folds are randomly created with the training dataset that will serve as training and cross-validation instruments. The K-Fold cross-validation scheme gives insight into how well it will fit an unknown dataset, avoiding common problems such as overfitting and selection bias. Therefore, each of the k datasets is used as the test set, while the remaining K-1 datasets are modelled in their respective training datasets. In cross-validation processes, the larger the value of K, a better generalization of the results would be expected, but in turn, this generates a greater computational time. Schaffer [40] gives a detailed description of the cross-validation process and its different modalities.
As can be seen in Fig. 1, the demobilization route is composed of several stages, including in-depth interviews with military and psychological professionals. It is vital to notice that the domain expert plays a crucial role in correctly developing the decision-making process in this problem. Thus, the proposed machine learning model is created to support those activities, not to replace the domain expert of the professionals.
Summary of model’s variables
Summary of model’s variables
This section summarizes the significant methodologies and approaches used in the literature to forecast social phenomena. No machine learning study has been conducted to predict armed group demobilization processes to the authors’ knowledge. However, the demobilization problem is structured similarly to other social challenges.
The main idea of supervised data learning models is to classify or forecast a future event based on known predictor variables. Thus, an advantage of implementing a data-driven solution is related to the generation of objective information for complex decision-making. In the case of this research, the decision of continuity, separation, and support to the reintegration is an essential aspect for the consolidation of the peace process in Colombia, given that the reintegration into civilian life uses the resources provided by the government to generate an autonomous and sustainable life.
Table 2 summarizes the most frequently utilized algorithms in the literature., showing selected references of applications in different social sectors. Consequently, each algorithm is briefly explained. The operational detail of ML algorithms will not be explained in detail. Instead, a summary description and reference will be presented where the algorithm is explained in depth.
Most used classifiers on social sciences
Most used classifiers on social sciences
K-fold cross validation process.
In this section, a variety of algorithms used for the modeling of social problems have been evidenced. However, due to the internal adjustment structures of the different models, it becomes challenging to identify the algorithm that best suits a situation. Thus, we’ll use a cross-validation process to generate a fair evaluation of the algorithm’s performance.
Random Forest models are methods articulated between machine learning algorithms; it entails the repeated and growing building of many decision trees using an aggregation method called bootstrapping [50]. Thus, generating several decision trees with varied variable compositions such that each tree provides an independent outcome, followed by a democratic approach in which the category with the most votes is chosen as the final output. Thus, the ability to generate different responses for each decision tree and then combine them into general forecast results in robust models that are less susceptible to extreme values than a basic decision tree, boosting the model’s prediction and classification capabilities.
The RF model incorporates a variable selection strategy, enabling it to handle many variables’ data sets if preceding processes are used to minimize dimensions. Additionally, the model allows for determining the importance of each variable for correctly classifying observations using a permutation test.
K-nearest neighbor
The KNN is one of the most popular neighbourhood-based classifiers in machine learning [51], given its simplicity and high efficiency to detect and classify elements into categories. The parameter k in KNN refers to the number of neighbours based on which a category is defined; this parameter is usually determined empirically. Depending on the problem, it is tested with different values of K, choosing the parameter with the best performance in precision. The algorithm’s operation relies on calculating a distance matrix between all the points of the training dataset.
XGBoost
The XGBoost is a robust and solid structure to enhance the results of machine learning models, especially tree-based models, parameterizing the iteration that depends on the calculation of the tree of choice, and that is used for positioning, characterization of observations according to the problem either classification or regression.
GLMNET
GLMNET’s machine learning technique is an assembly algorithm that builds a linear model by articulating lasso regression [52] and [53]. The assembly method is performed by penalizing the magnitude and number of final coefficients of the regression model, thus avoiding the problem of overfitting. This model form was evaluated in datasets with multiple predictor variables and few individual observations as accurate. Therefore, in the limit case, when the linking parameter takes a value of zero, the model operates strictly as a Ridge regression, and when it takes a value of 1, it works as a pure Lasso regression. In another scenario, for example, a Lambda value
Performance metrics
The classification process’s success is set by the difference between the anticipated and actual values. The True Positive (VP), True Negative (VN), False Positive (FP), and False Negative (FN) metrics all describe this relationship.
Accuracy
It is the number of correct predictions made divided by the total number of predictions made.
Precision
It is the number of positive predictions divided by the total number of positive class values.
Recall
It is the number of positive predictions divided by the number of positive class values in the test data.
AUC
The AUC represents the area under the ROC curve, between 0.5 and 1. For a perfect classifier, the value of AUC should be 1. AUC as a numerical value to visually evaluate the quality of the classifier. The larger the AUC value, the better the classification effect. If the AUC value is larger, the classification effect will be better.
Kappa
Kappa indicates how much better your classifier performs than a classifier that merely predicts randomly based on the frequency of each class.
F1
It is the number of positive predictions divided by the number of positive class values in the test data.
Results
Table 3 summarizes the cross-validation hyperparameters for each classification algorithm. The AUC Cross-validation results for each of the implemented algorithms are shown in Fig. 3. The XGBT algorithm presents the best performance among the algorithms evaluated with a mean value of AUC
The Random Forest and the XGB are algorithms that recurrently assemble trees to generate a prediction that shows results higher than AUC
Consequently, the data used to train the models is about individuals who entered the reintegration process, so these models suffer from a selection bias due to the absence of data on individuals who requested admittance to the reintegration process at some time but did not receive acceptance for a variety of reasons. This bias is essential to mention given the recommendation-based approach given to the model of this research, focused on generating objective support for decision-making on admission to the reintegration process into civilian life.
Main hyperparameters used in the classifiers
Main hyperparameters used in the classifiers
The cross-validation procedure evaluated the performance of each of the algorithms, yielding forty different models (four algorithms and ten folds). Table 4 presents the results of each algorithm for the AUC, F1, and Kappa metrics. It is essential to mention that, although the XGB is the one that presents the best performance according to all metrics, the GLMNET yields competitive results for the Kappa and F1 metrics. In the case of GLMNET the value of the Alpha parameter was equal to 1, representing a pure Ridge regression, which allows estimating the impact of the variables on the result, which is not possible for XGB because of its Black Box algorithm characteristic.
Performance metrics summary for the Cross-validation
Cross-validation results.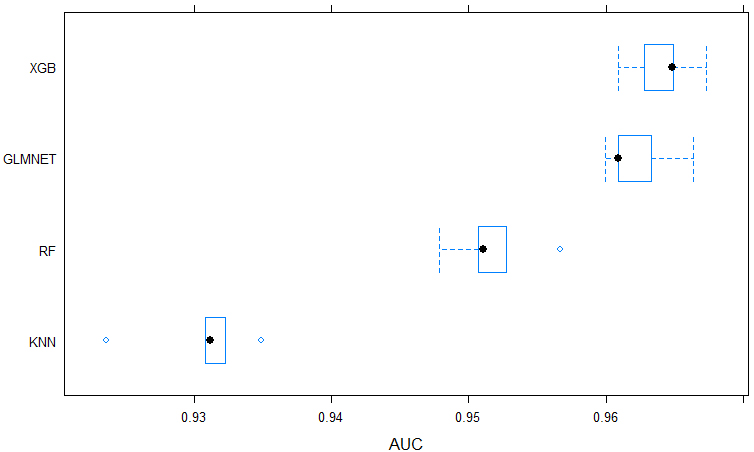
Finally, the model’s performance during the test is on confusion matrices in Fig. 4, where the number indicates the classified individuals per category. When evaluated on the test data, the XGB reached a mean accuracy of 89.6% (89.19%, 90.15%) in a confidence interval of 95%. The XGB model has a no-information rate (NIR) of 49.9% with the unseen data, even though the p-value for (Acc
Confusion Matrices for the models evaluating the test set.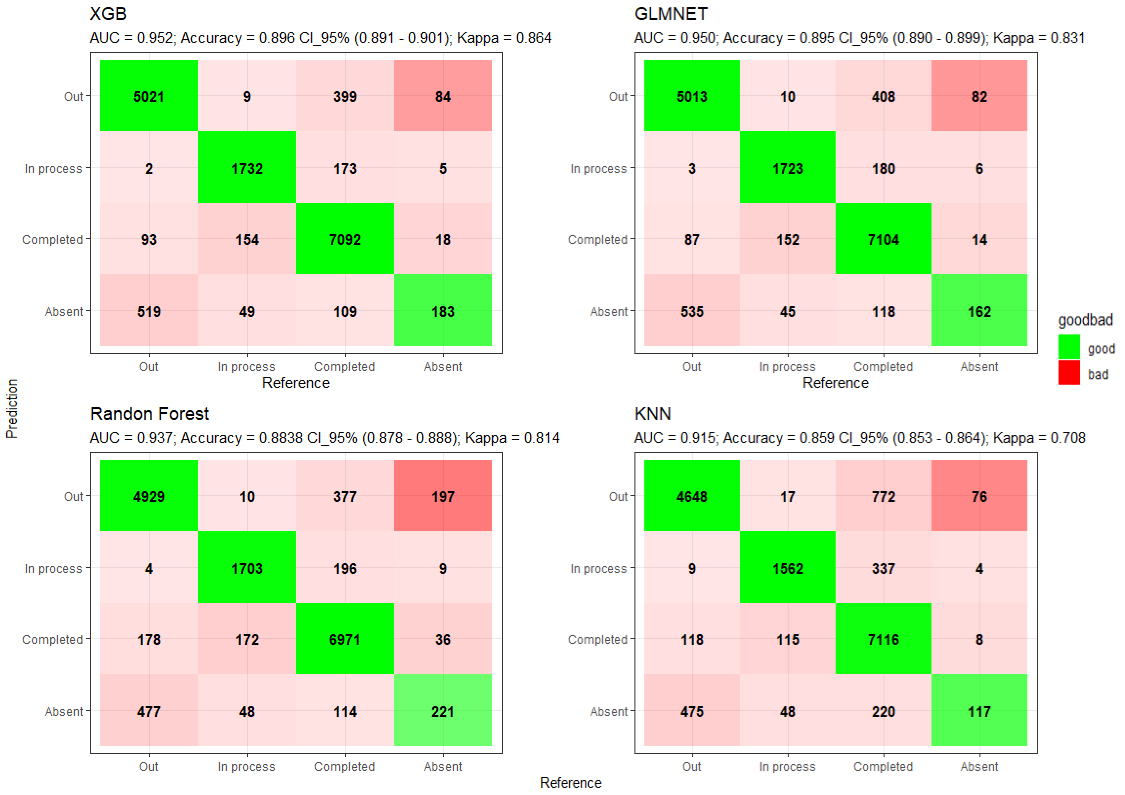
The research uses forecasting methods derived from machine learning to predict a future event based on known predictive variables; so, the main contribution is to propose to decision-makers more accurate behavioural predictions that allow corrections to be made and help effectively conclude the reintegration process. The results do not seek to be a bias factor for acceptance or expulsion of an ex-combatant; on the contrary, to alert decision-makers about possible abandonment of the process. Therefore, fostering to take the necessary measures and successfully promote the continuity of ex-combatants to civilian life.
We find that the three algorithms with the best performance are the ensemble algorithms. Thus, it shows the superior capacity of joint algorithms to predict the future state of a demobilized in the framework of a peace process. Consequently, reliability is crucial for supervised algorithms because it demonstrates how results obtained from the training can be extrapolated for real-life applications. In the present research, the four algorithms implemented shows high reliability, evidencing the model’s capacity for effectively predicting ex-combatant future status. The classifiers represent a deviation of 0.0012, 0.0012, 0.0004, and 0.01 deviation for the XGB, GLMNET, RF and KNN.
As mentioned in the background section, the classification problem of ex-combatant in a demobilization process is similar to other social issues. Thus, the machine learning approach used in this research could be replicated to other social phenomena. For example, in the study of [22] developed a machine learning model to predict prison violence, obtaining that the best AUC value was 0.789 for the Random Forest algorithm. Thus, in the present research, the best model scored an AUC value of 0.952, suggesting that the ensemble models applied to predicting prison violence could outperform the current results.
Consequently, social reintegration refers to the ability of ex-combatants to become part of the social life again, participating in the collective decisions of the communities where they are established without returning to the violent and illegal actions of the past [54, 55, 56, 6]. Thus, the machine learning approach becomes a tool that supports the reintegration process with the contribution of objective information to maximize the results of the process in social terms.
Recently machine learning models have been applied in areas of the social sciences in order to help make decisions that positively impact people’s lives [11]; within these themes is the armed conflict and people outside the law, to whom society is willing to offer to abandon their criminal life to have a civilian life, in exchange for certain benefits and aids. Studies similar to this have been carried out by [17, 18, 19], whose objective is to help predict problems related to crime and threats to public safety as a solution to this social problem. The results obtained by these authors are coincident with those obtained in this research since the forecasting methods derived from machine learning, when applied in real situations, are similar, so these can be replicated.
Thus, the main objective of this research does not depend on accurately anticipating when an ex-combatant will emerge from the demobilization process but on providing the decision-makers involved with a guiding criterion on the acceptance and subsequent allocation of benefits received. So, ex-combatant who fails to reach the desired reintegration into civilian life will be prone to re-offending from the crime.
In this way, if reducing the percentage of abandonment in the process and identifying the critical aspects of succeeding in demobilization, to this same extent, the process will adopt an advanced decision-making scheme based on objective evidence, generating confidence in society about the Colombian peace process.
Finally, the results demonstrate that a predictive model can provide the tools and techniques needed to manage and process social data on ex-combatants. According to the literature review, supervised data learning models have not been used to estimate decisions about the acceptance and allocation of benefits received by an individual ex-combatant to maximize success in reintegration into civilian life. In this way, this study can be helpful in social issues related to armed conflict and national security by managing the complexity of a process of which there is not much background and providing a support scheme for strategic and operational decision-making.
One of the limitations of this study is associated with the bias of the database, considering that some combatants were not admitted to the demobilization process. Therefore, there is no information on these people who are somehow actors in the conflict and whose social profiles would feed the algorithms in order to improve the forecast of the future status of the ex-combatants.
The research approach has been of predicting the future status of an ex-combatant to help in the decision-making of the DDR process. If the DDR process is not successful, the entire society, the peace process, and the ex-combatants themselves may be jeopardized. As a result, failing to demobilize and reintegrate an ex-combatant successfully can be costly. It can result in numerous disadvantages in civilian life, increasing the possibility of the ex-combatant taking up arms again. Therefore, the model’s accuracy is paramount, and machine learning offers superior forecasting accuracy, at least compared to the domain expert’s traditional forecasting methods and judgments.
The machine learning models developed in this research are fully compatible with current empirical systems of the decision on the admission of a person to the DDR process. However, predictions of completion or abandonment of the process can avoid biases in accessing the DDR. Providing a sophisticated approach to the management of resources in the framework of a peace process would improve the perception by the actors of the process by avoiding factors of subjectivity.
Conclusion
This research demonstrated how a machine learning approach is effective in predicting the future status of a former combatant in the demobilization process in Colombia. The results obtained showed that the XGBoost method is the most suitable for predicting the future status since it combines high performance with a reasonable computational cost. It is worth mentioning the GLMNET algorithms since their results are competitive in all performance metrics.
At best, an AUC of 0.964 was obtained in the training phase and an AUC of 0.952 by simulating real cases in the test dataset. The deviation between the average values of the train’s AUC and the test was only 0.012, indicating that the model has high reliability. Therefore, this study provides a significant contribution to state of the art in machine learning applications in the social sciences, as it established a reproducible and replicable methodology to complex social contexts.
The social systems cannot be far from the advantages of applied machine learning models. Thus, based on a strategic decision, those models could save money, and when applied to a DDR process, machine learning can provide a more precise image.