
Abstract
Generative Adversarial Networks (GANs) has achieved great success in computer vision like Image Inpainting, Image Super-Resolution. Many researchers apply it to improve the effectiveness of recommendation system. However, GANs-based methods obtain users’ preferences using a single Neural Network framework in generative model, which may not be fully mined. Furthermore, most GANs-based algorithms adopt cross-entropy loss to get pair-wise bias, but these methods don’t reveal global data distribution loss when data are sparse. Those problems will influence the performance of the algorithm and result in poor accuracy. To address these problems, we introduce Wide & Deep Generative Adversarial Networks for Recommendation System (a.k.a W & DGAN) in this paper. On the one hand, we employ Wide & Deep Learning as a generative model capable of extracting both explicit and implicit information of user preferences. Furthermore, we combine Cross-Entropy loss in G with Wasserstein loss in D to get data distribution, then, the joint loss will be to receive the training information feedback from data distribution. Empirical results on three public benchmarks show that W&DGAN significantly outperforms state-of-the-art methods.
Introduction
As an important way of information filtering, Recommendation System (RS) plays a key role in our daily lives.The recommendation task is to produce a list of recommendations that a user may be interested in. Collaborative Filtering (CF) [27], as is a core algorithm of RS, provides information recommendations like music recommendation and movie recommendation. However, CF and its extended methods, such as Matrix Factorization [18], Probabilistic Matrix Factorization (PMF) [22], and Bayesian Probabilistic Matrix Factorization [26] doesn’t receive satisfactory results. In recent years, deep learning [20] has achieved great success in computer vision and natural language processing [5]. Thus, many researchers use Deep Neural Networks [19] to obtain better recommendation accuracy. For example, Deep Neural Networks (DNNs) is applied in rating prediction, the core idea of which acquired user and item vector representation from DNNs; Zhang et al. [43] use two parallel neural networks to learn the hidden features of users and items. However, when the data are sparse, these methods can not get satisfactory results.
Goodfellow et al. [9] propose Generative Adversarial Networks (GANs) that includes two parts: a Generator (G) and Discriminator (D), they play min-max games: G creates an image and sends it into D, and D discriminates whether the image generated by G is true or false, and the information will be feedback to G. Based on this, many GANs-based algorithms are proposed, such as Conditional Generative Adversarial Nets (CGAN) [21], Deep Convolutional Generative Adversarial Networks (DCGAN) [24], Wasserstein GAN (WGAN) [1], Large Scale GAN Training for High Fidelity Natural Image Synthesis [3], and so on [23]. All of them apply to computer vision, and good results are obtained. Then, many researchers manipulate GANs for RS and design GANs-based methods for recommendation system. For example: Unifying Generative and Discriminative Information Retrieval Models (IRGAN) [35], and Graph representation learning with generative adversarial nets (GraphGAN) [34] based on pair-wise theory, namely, given a user, to let G generate items sequences that the user might be interested in, and to use D to discriminate it with specific user’s ground truth. However, these methods rely on Reinforcement Learning (RL) [17] to guide the whole process. Cross-Entropy loss is used to receive feedback information, but it can not express global data distribution of the whole training process; However, the recommendation results of these methods is not satisfactory. The reason for this is that these approaches are ineffective in mining useful information. Therefore, GANs-based methods exist some disadvantages: (1) they employ neural nets of G and D to train a model, which receive a poor reseult since G fully mine users’ preferences; (2) Pair-wise loss is designed to as target function in GANs for RS, but it doesn’t acquire global data distribution and affects information feedback.
To solve those problems we have mentioned, Wide & Deep Generative Adversarial Networks for Recommendation System (W&DGAN) is proposed. First of all, Because of memorization and generalization capabilities of Wide & Deep Learning [7],we introduce it into GANs as generative model, it can fully mine the preferences of users. On the other hand, we take advantage of the Cross-Entropy loss in G and Wasserstein loss in D, then W&DGAN not only obtains the paired results, but also get the global data distribution, which improves recommendation accuracy and even data sparsity. The contributions of this paper can be summarized as follows:
We propose a new GANs recommendation framework called W&DGAN, as far as we know, this is the first time to combine the Wide & Deep Learning model with GANs for Top- The generator of W&DGAN, Wide & Deep Learning model can fully mine users’ preferences from the interaction records of user-item because of its memorization and generalization. Thus, W&DGAN receives useful preference information and recommends the sequence of items that users may like. The Cross-Entropy loss in G and Wasserstein loss in D are utilized to get data distribution, which means that the joint loss will get training information feedback and obtain better experimental results.
The remainder of this paper is organized as follows: Related Work is introduced in Section 2. In Section 3, it includes problem definition, and Wide&Deep Learning. W&DGAN algorithm will be described in Section 4. Section 5 contains a description of the datasets, measurement metrics, experimental results and analysis. Conclusion and future work will be introduced in Section 6.
In recent years, deep learning [20] has achieved great success in computer vision and natural language processing [5]. Thus, many researchers use Deep Neural Networks to obtain better recommendation accuracy. He et al. [12] create Neural Collaborative Filtering (NCF) for the recommendation, which gets input information representation from Multi-Layer Perceptron [13]. Deep Matrix Factorization [40] adopts user-item matrix as the input, and deep structure learning architecture is to learn a common low dimensional space for the representations of users and items. In addition, many researchers employed GANs to receive better accuracy in Recommendation System. A Generic Collaborative Filtering Framework based on Generative Adversarial Networks (CFGAN) [4] is proposed. The framework redefines GANs for recommendation with CF, and abandons RL mechanism, but does not fully mine users’ preferences for interactive information; Recurrent Generative Adversarial Networks for Recommendation Systems (RecGAN) [2] is based on Recurrent Neural Networks [28], which also doesn’t obtain satisfactory recommendation based on Cross-Entropy loss; In addition, some researchers have designed adversarial networks methods for RS, such as: an Adversarial collaborative neural network for the robust recommendation (FG-ACAE) [41], Prioritize Long And Short-Term Information in Top-
Preliminaries
In this section, we introduce some background knowledge about problem definition and Wide & Deep Learning, which are important perspectives for understanding our proposed method.
Problem definition
Given user
Therefore, the Top-
Cheng et al. [11] analyzed the users’ data and found that there are not only implicit representations but also correlations (user preference). They called it memorization and generalization capability. By combining the generalization ability of deep neural networks with the memory ability of a linear model, the user’s preference can be obtained.
The Wide model consists of a linear structure. Part of the information is input to construct the feature engineering. The following equations describe the details.
where the parameter
Deep model is a deep neural network. The information input is processed by the embedding layer, and then transferred into vector representation, which makes deep model has the ability to extract features. Then the vector representation is sent to the hidden layer, and the implicit information representations of the final prediction is obtained through training. The following equation shows the process of calculating:
where the parameter
Wide & Deep Learning includes two previous models, and outputs values after joint training is finished. The equation gives the details.
where
Typically, methods which are based on GANs (e.g. CFGAN) exist the same train way in recommendation system as shown as in Fig. 1. It demonstrates that G generates items for specific-user each time under the guidance of D, and that D can distinguish input from the results of G. However, it will cause some problems: (1) D distinguishes user-item pair but doesn’t consider global data distribution; (2) GANs-based models can not utilize some potential interactive information. Thus, we propose the W&DGAN algorithm to solve these problems and give a detailed introduction.
The GAN-based algorithms item generation processing.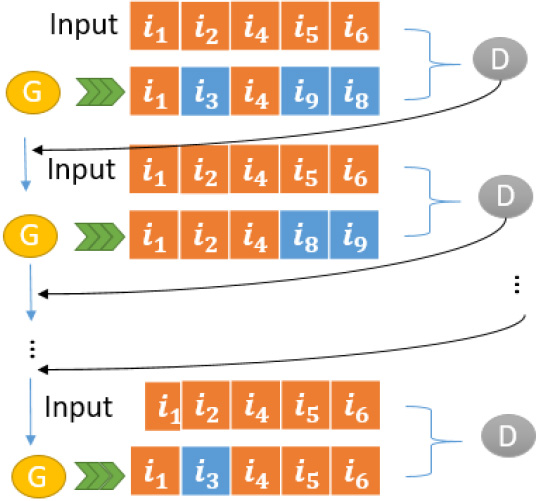
W&DGAN framework. 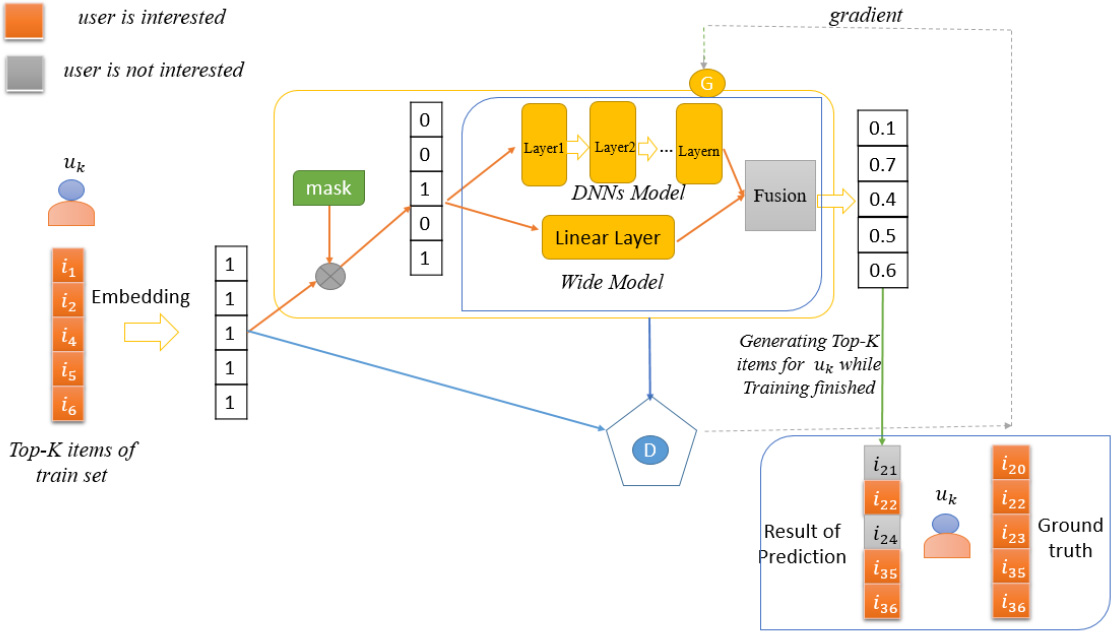
In this section, we mainly introduce the W&DGAN method, and the framework is as shown as in Fig. 2. Before we start introducing the model, there are something need to explain the preprocessing of the input information, which makes it easier to understand the algorithm we proposed.
Here
Based on GANs theory, we have a masking operation before data enters the model. The masking operation can be represented by the following formula:
Here, mask means the random noise sequence of input information,
Wide & Deep Learning mines user’s preferences through memorization and generalization capability. Therefore, we employ Wide & Deep Learning to generate item sequences for specific users. The whole process can be shown as:
Where
We fuse two models, then it outputs recommendation results, which can be written by:
Where
As the target function of G,
Where
In this part, we will describe Discriminator, shortly D. Here, D is designed by deep neural networks. The reason is that deep neural networks encode the input sequences, and pay attention to distinguish differences between G and D. Therefore, D can provide feedback information for G to update parameters. Traditionally, GANs-based methods employ Cross-Entropy loss for D in Top-
However, Cross-Entropy loss doesn’t receive global distribution because of insufficient capacity [1]. Therefore, we use Wasserstein loss as the loss function of D to receive global distribution. The expression can be shown by:
Here,
W&DGAN combines G and D to achieve better results, so the training process can be expressed by:
We also adopt ZR loss and OR loss [4] to construct triplet loss, it can constrain the generated vectors not to be loose or dense. This means the vectors do not contain many negative or positive samples. The target function of triplet loss can be expressed by the following formula:
Here
Therefore, the W&DGAN target function of training process can be shown as:
: W&DGAN
Sample user-item pair (
Generate items of user may like
G not converged
In summary, the W&DGAN algorithm can be described as: the input is operated by embedding and mask, then it will be sent into the G of W&DGAN. After that, G uses Wide & Deep model to generate sequences of item for specific user. D will discriminate item sequence of G generated whether is true or not based on the ground truth value, and feedback result information to guide G. The whole algorithm of W&DGAN is shown in Algorithm 1.
In this section, we will introduce the datasets, the experimental environment and analyze the experimental results. In order to evaluate our proposed model correctly, we conduct experiments to answer the following research questions:
How does the performance of W&DGAN compared with state-of-art algorithms for Top- Is it useful components in W&DGAN (i.e., Joint loss, Wide& Deep Learning) for improving recommendation results? How does the stability of W&DGAN in epoch?
The Datasets include Ciao, MovieLens 100K, and MovieLens 1M,1
Ciao
It is 18,648 interactive records of 996 users in 1,927 items. the less interactive records, the more sparseness of the data increases synchronously.
MovieLens 100K
It contains 100,000 interactive reco-rds of 943 users in 1,682 items.
MovieLens 1M
It has 1,000,209 interactive records from 6,040 users on 3,883 items, the scale of the dataset increases, and the sparseness of the data increases synchronously.
All information of datasets are as shown in Table 1. In addition, we need to preprocess the datasets: the value is 1 if an item is rated by an user, else value is 0. The input of W&DGAN is (user, item, rating) and the output is (user, item1, item2, …, itemN).
Statistics of the experimental datasets
Metrics
We use four popular accuracy metrics to evaluate W&DGAN in Top-
Here value of N is 5 and 20, TP is numbers of the true prediction, FP represents numbers of the false prediction, FN is numbers of false negative samples. TP
We employ the deep learning framework which is TensorFlow-1.13 to implement our model and deployed it on a NVIDIA Tesla P100 GPU with 16 GB of memory. The OS is Ubuntu 16.04.5LTS server, and memory is 128 GB.
Comparison algorithms
To better answer RQ1, The experimental settings are based on IRGAN [4] algorithm, and 5 cross-validation experiments are performed for comparison, and then the average value is taken. Comparison algorithms with the following:
Table 2 shows the experimental results of the Ciao dataset (Bold indicates the best result on different datasets). We can see that W&DGAN receives better results with an average improvement of 0.3%. According to the dataset description by Table 1 and metrics definition, we find that Ciao dataset size of user-item interactive information is less, but W&DGAN obtains a better recommendation effect. It proves that W&DGAN can mine useful information from user-item interactive matrix even in the case of sparse data.
Table 3 shows the experimental performance of MovieLens 100K dataset. It has a similar situation with Table 2, W&DGAN is better than the other baselines. Compared with the other algorithms, W&DGAN improves by 0.3% on average regardless of the top-5 or top-20 recommendation. It demonstrates that the W&DGAN can efficiently mine potential interactive information of user and item and receive good recommendation effects.
Experimental performance of W&DGAN and baselines on the Ciao dataset
Experimental performance of W&DGAN and baselines on the Ciao dataset
Experimental performance of W&DGAN and baselines on the MovieLens 100K dataset
Experimental performance of W&DGAN and baselines on the MovieLens 1M dataset
Experimental performance of W&DGAN in NDCG@10 on the MovieLens 100K dataset
MovieLens 1M dataset experimental results are shown in Table 4. It is similar to Table 3, W&DGAN’s performance higher than the baselines with is 0.4% improvement on average. Therefore, it illustrates that W&DGAN obtains the potential interactive information between users and items on large dataset.
Recently, Graph Neural Networks (GNNs) [38] has an advantage in network representation of the social network, so many researchers adopt it into RS [36, 32, 14]. The experimental performance is measured by NDCG@10 of MovieLens 100K because of the sparsity of data. And the results of NDCG@10 are shown in Table 5. We can find that some GNNs-based algorithms like NGCF can obtain better recommendation effects. Nevertheless, W&DGAN also achieved the best recommendation accuracy. Other MF-based methods (BMF, NMF, etc. [45]) can not get satisfactory recommendation results because of the sparsity of data. It also proves that W&DGAN is efficient in mining social network data.
W&DGAN different components results on Ciao dataset.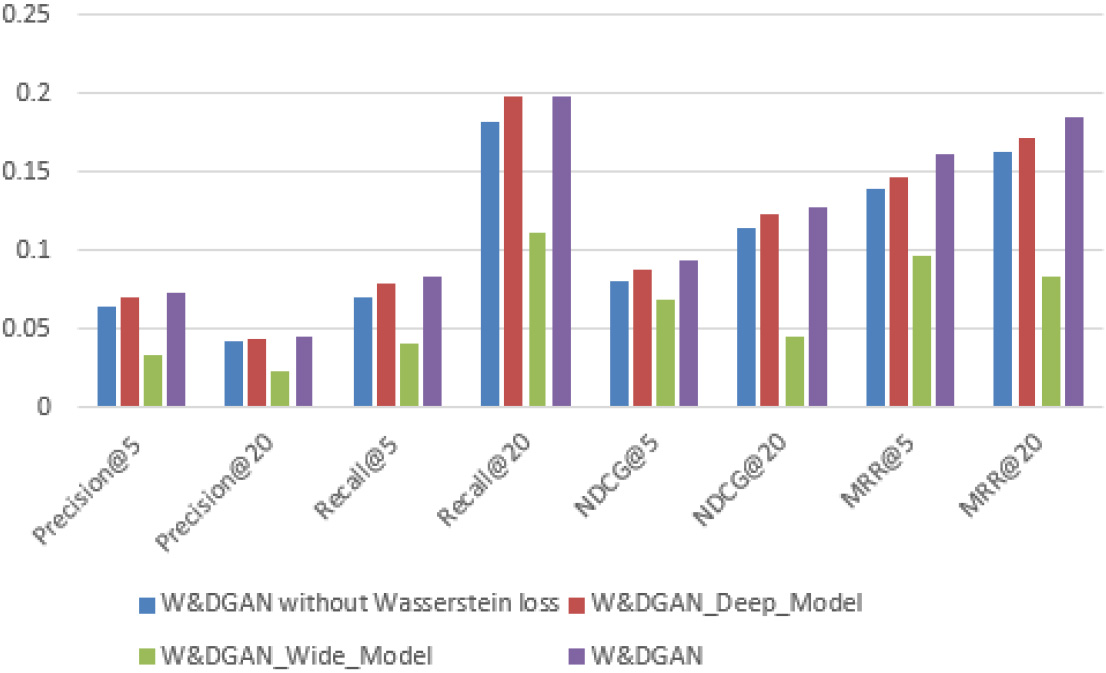
W&DGAN different components results on MovieLens 100K dataset.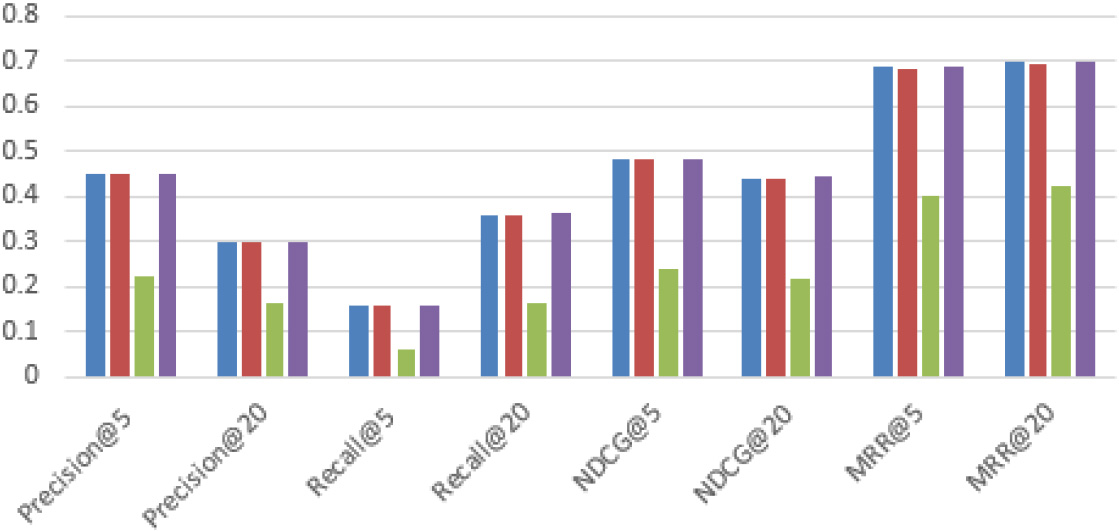
W&DGAN different components results on MovieLens 1M dataset.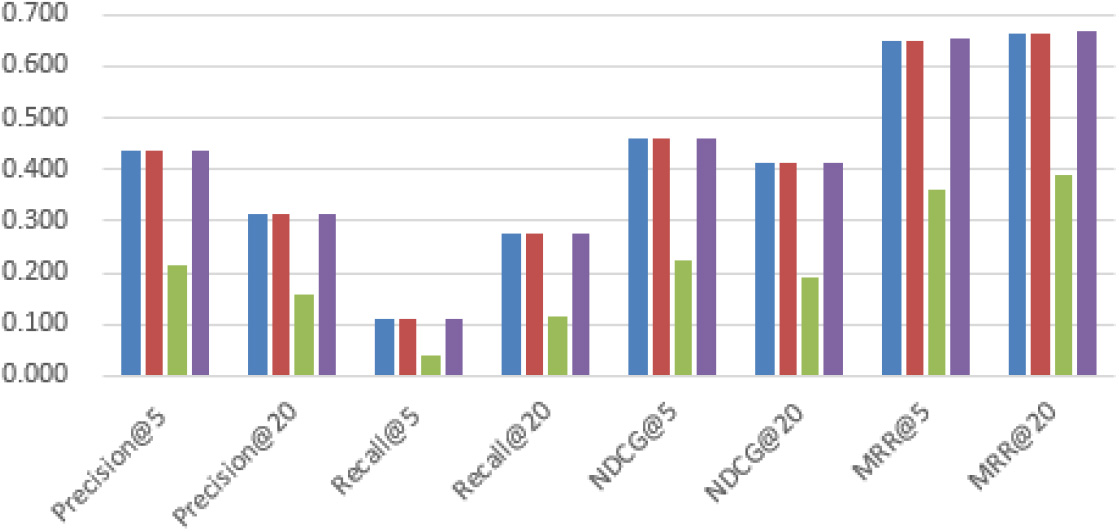
The results of different components in W&DGAN on different datasets are as shown in Figs 3–5, respectively. The W&DGAN_Wide_Model and W&DGAN_Deep_Model mean that W&DGAN uses Wide Model or Deep Model. Next, we will introduce it in detail.
Figure 3 shows the different results of the Ciao dataset. We can see that W&DGAN gains advantage instead of W&DGAN without Wasserstein loss. In addition, compared to other different components, W&DGAN keeps good results. It is clearly shown that different components will affect the recommendation accuracy of Ciao dataset.
MovieLens 100K results of different components are shown in Fig. 4. The W&DGAN obtains an average improvement of 0.1%, which is similar to the Ciao dataset. We think that MovieLens 100K is denser than Ciao, so interactive information will be received more. The results also explain that Wasserstein loss can receive user preferences from global distribution of data.
Figure 5 shows the experimental results of W&DGAN with different components in MovieLens 1M. It shows that the average improvement of W&DGAN is less than 0.1%. According to Table 1, we think that MovieLens 1M is larger than the other two datasets. Therefore, the potential preference information can be easily mined by recommendation algorithms. That’s why most of the methods in MovieLens 1M can get better results.
It should be noted that the performace of W&DGAN_Wide_Model is not satisfactory, we think that the interaction matrix is the linear representation, and W&DGAN_Wide_Model can not directly obtain a better representation from
Stability of W&DGAN (RQ (3))
Figures 6–11 reveal the stability of W&GAN in training epochs at three datasets, as we can see that W&DGAN has better stable results, not under unstable conditions. Firstly, the Precision, NDCG, Recall, and MRR of Ciao dataset have achieved the best results in 300 epochs; MovieLens 100K has obtained the best recommendation accuracy of Precision, NDCG, Recall, and MRR in about 100 epochs; the best results of MovieLens 1M of Precision, NDCG, Recall, and MRR meet in 150 epochs. Secondly, the W&DGAN method not only obtains a good recommendation effect, but also possesses better stability. When the model trains processing period on the best effect epoch, the MovieLens 100K and MovieLens 1M keep good results, but the Ciao dataset is not good. We think the reason is that the dataset is small and it is easy to get overfitting.
Ciao dataset MRR and NDCG measure results of epochs.
Ciao dataset Recall and Precision measure results of epochs.
MovieLens 100K dataset MRR and NDCG measure results of epochs.
MovieLens 100K dataset Recall and Precision measure results of epochs.
MovieLens 1M dataset MRR and NDCG measure results of epochs.
MovieLens 1M dataset Recall and Precision measure results of epochs.
In this paper, we propose a new framework for recommendation system: Wide&Deep Generative Adversarial Networks for recommendation system (W&DGAN), it is to obtain implicit preference information and improve recommendation accuracy. W&DGAN takes Wide&Deep Learning to learn users’ preferences from interactive information of user-item. Cross-Entropy loss in generator (G) and Wasserstein loss in discriminator (D) of W&DGAN is to obtain information feedback from distribution loss of data. The experimental results prove that W&DGAN possesses better recommendation accuracy in several datasets
Many GANs (BigGANs, WGAN-GP [10] etc.) have greatly improved in convergence properties and optimization stability, and attention mechnism [30] has been applied in recommendation. In the next work, we will apply these methods to W&DGAN, and get better recommendation accuracy.
Footnotes
Acknowledgments
This work was partially supported by the University-level key projects of Anhui University of Science and Technology (Grants #xjzd2020-15), Collaborative Innovation Project of Anhui Province (Grants #GXXT-2019-018), and the Provincial Artificial Intelligence and Robot Experimental Training Center Project (Grants # 2020sxzx08). The authors also would like to thank the anonymous reviewers for their valuable comments.