
Abstract
In recent years, various loss functions have been proposed to boost the performance of deep neural networks. Every loss function has its own specific theoretical motivation, and can easily learn its preference features of training data compared with other loss functions. Thus, combining multiple loss functions to capture more data features becomes an attractive idea for model performance improvement. In this paper, instead of using a single loss function or a linear weighted sum of multiple loss functions, we present the method named Multiple Independent Losses Scheduling (MILS), which allows multiple loss functions to independently participate in the training process according to their performance. Specifically, for all candidate loss functions, one loss function will be predefined as the primary loss function before training, and the other loss functions will play auxiliary roles for possible contributions to improve the model performance. In order to avoid auxiliary loss functions bringing a negative effect on the model performance in the training process, we developed a simple but effective performance-based scheduling algorithm to prevent auxiliary loss functions from dragging down the model performance. Extensive experiments using various deep architectures on various recognition benchmarks demonstrate our scheme is simple, robust, lightweight, and effective for typical classification tasks.
Keywords
Introduction
Deep convolutional neural networks [1, 2] have been widely used to achieve state-of-the-art performance in speech recognition [3, 4], visual object recognition [2, 5, 6], object detection [7, 8, 9], which allows computational models, composed of multiple processing layers, to learn feature representations of data with multiple levels. Since many practical applications can be regarded as parametric function approximation problems, deep learning approaches often define a mapping
An important aspect of the design of a deep model lies in the choice of the loss function, which can affect learning dynamics and final performance of the deep model. The loss function is just like a ruler for the training process, which is used to measure the model and guide the training procedure of the model. Therefore, the design of loss function is as important as the design of model architecture. Although early loss functions are very simple, they still achieve excellent performance and are widely used in various deep learning tasks. A typical example is the softmax cross-entropy loss (softmax loss for short) function for image classification tasks, which is used to measure the error between model outputs and data labels. In recent years, to further improve the performance of deep models, some researchers have tried to develop some specially designed loss functions [10, 11, 12, 13, 14, 15] for targeted tasks, and these loss functions are often formalized as a linear weighted sum of multiple loss functions. Essentially, the joint loss functions can still be considered as a single loss function, which has been used in the whole training process for weight parameters estimation.
Feature space of training data. (a). The features in the left cycle mean the features can be learned by loss A, and the features in the right cycle mean the features can be learned by loss B. (b). In an ideal situation, all features can be learned by combining loss A and loss B.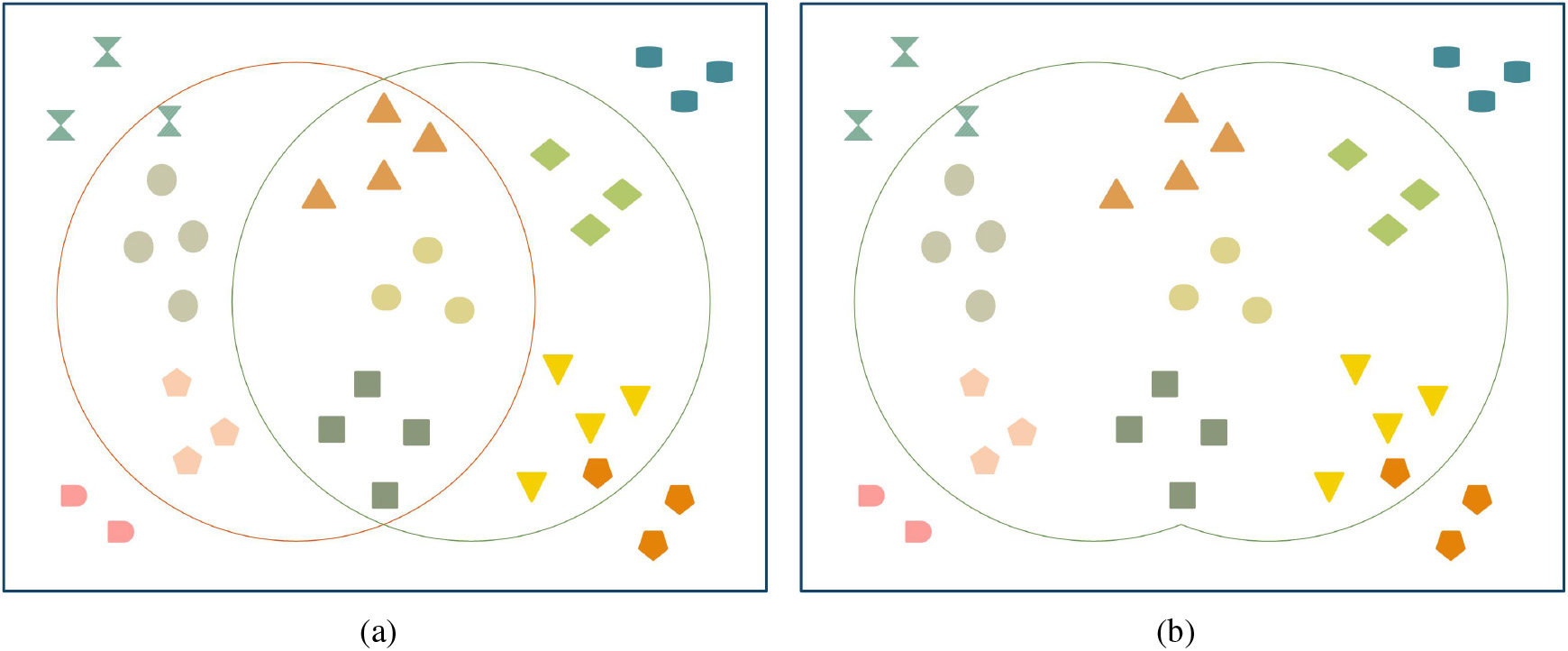
Obviously, every loss function has its own specific theoretical motivation [16] and can easily learn its preference features of training data compared with the other loss functions. Suppose we do not have any intuition or special knowledge about some specific applications and datasets, how can we find an adaptive and effective approach for learning more meaningful features in a general way? As shown in Fig. 1, a simple and straightforward idea is the utilizing of multiple independent loss functions, which combines two different loss functions and obtains more meaningful features than a single one. Thus, combining multiple independent loss functions to learn more data features becomes an attractive idea for deep network performance improvement. In this paper, instead of using a single loss function or a linear weighted sum of multiple loss functions (joint loss), we present the approach named Multiple Independently Losses Scheduling (MILS). MILS allows multiple loss functions to participate in the training process alternately and independently. Compared with continuous training using a single loss function, MILS only introduces a little overhead but brings an obvious performance improvement. Extensive experiments using various deep network architectures on various recognition benchmarks demonstrate our proposal is simple, robust, lightweight, and effective for typical classification tasks. The original contributions that we have made in this paper are highlighted as follows:
To the best of our knowledge, we are the first to consider the independent use of multiple loss functions in one training process, which aims to further utilize training datasets without modifying model architecture. We develop a simple but effective training approach with multiple independent loss functions. The key insight is allowing the multiple loss functions to introduce their preference features of training data to guarantee that the deep model can learn more meaningful features. Various deep network architectures trained with the proposed approach show nice performance boost on different object recognition benchmarks, and the source code is publicly available for exploitation.
The remainder of this paper is structured as follows. We make a brief overview of related works in Section 2 and illustrate the motivation of MILS in Section 3. Then, we describe the details of MILS in Section 4. Section 5 evaluates our proposal through extensive experiments. Finally, we summarize the paper in Section 6.
The loss function is a critical part of any machine learning or deep learning model, and loss functions define an objective against which the performance of your model is measured, and the setting of weight parameters learned by the model is determined by minimizing the chosen loss function. Some common loss functions have been widely used in various tasks, such as hinge loss, softmax cross-entropy loss, KL divergence loss, etc. Although these common loss functions achieve acceptable performance in various tasks, researchers still want to develop specially designed loss functions to improve model performance further.
Joint loss functions
Large-margin Gaussian Mixture loss [15] is proposed for classification, which intuitively makes the assumption that the deep features of the training dataset follow a Gaussian Mixture distribution. It is proved superior to the softmax cross-entropy loss function with a high classification performance. Similarly, focal loss [13] discovers the extreme foreground-background class imbalance in object detectors. With such knowledge, it reshapes the standard softmax cross-entropy loss to down-weight the loss assigned to well-classified examples, and trains a high-accuracy detector that significantly outperforms others. The approach of agreement learning [17] defines an objective function that incorporates both data likelihood and a measure of agreement between two models. Besides large-margin Gaussian Mixture loss and focal loss discussed in Section 1, center loss [11] is first proposed to learn a center for deep features of each class and penalize the distances between the deep features and their corresponding class centers. Center loss achieves state-of-the-art accuracy on several important face recognition benchmarks. Similarly, angular softmax loss [14] and later studies including large-margin softmax loss [10], quadruplet loss [12], large margin cosine loss [18], additive angular margin loss [19], also aim at obtaining the deep features with the two key learning objectives, inter-class dispersion and intra-class compactness as much as possible. Zhen et al. [20] investigated a nonlinear combination of multiple loss functions, which allows adaptively tuning the weights of different loss functions to guide the optimization. But it seems not easy to be tuned for every specific task or dataset.
Regularization methods
Also, there has been lots of work dealing with loss functions, in the form of
Generally, existing multiple loss functions have been used for various tasks and applications. Still, previous studies often combine multiple loss functions or penalties into a new loss function (a weighted sum of multiple loss functions), just like a single loss function, which means this function can only learn a single feature preference. Unlike the existing usage of multiple loss functions, we first proposed MILS which uses multiple loss functions independently and alternately in the training process. MILS lets the deep model learn different feature preferences according to the model performance of different loss functions.
Motivation
Suppose the deep network architecture, training dataset, and hyperparameters (such as learning rate and weight decay) are defined in advance; in that case, the choice of loss functions will decide the final performance of this model. In general, based on the knowledge of the training dataset and the past experience in related works, researchers will choose an appropriate existed loss function or develop a new loss function to enhance the model performance as much as possible. However, we believe that although a single loss function may significantly outperform other loss functions in the scenario mentioned before, deep models trained with this loss function cannot correctly classify all test samples that can be correctly classified by deep models trained with other loss functions. The basis of MILS lies in the assumption that various loss functions have various feature preferences, and these feature preferences can be learned stacked in one training process.
Experimental results for motivation. (a). Test error on the CIFAR-100 validation dataset (softmax loss vs. multi-margin loss). (b). We independently train the network ResNet-20 by softmax loss 10 runs, and 959 samples in the CIFAR-100 validation dataset always misclassified by any model trained before. (c). 92 samples in (b) have been correctly classified by the ResNet-20 model trained by multi-margin loss.
In order to verify this assumption, we empirically conduct a classification experiment on the CIFAR-100 dataset [27]. To evaluate the performance of softmax loss and multi-margin loss, we use softmax loss and multi-margin loss to train networks ResNet-20 [6] separately, except for the choice of loss functions, other hyperparameters are the same. Figure 2a shows that the model performance trained by softmax loss significantly outperforms the model trained by multi-margin loss and achieves the lowest error rate of 31.3%. We have two interesting and important observations in Fig. 2b and c. First, we have trained ResNet-20 (ResNet with a depth of 20) 10 runs independently with the softmax loss. Therefore we got 10 ResNet-20 models with different model parameters. We found 959 fixed samples (9.59% of the total number of the validation dataset in the CIFAR-100 dataset), which failed to be correctly classified by all ResNet-20 models trained before. On the other hand, there are 4116 fixed samples (41.16% of the total number of the validation dataset in the CIFAR-100 dataset) that can always be correctly classified by any ResNet-20 model. We have grounds to believe that the features related to the 959 fixed samples mentioned above are challenging to learn by the model trained with the softmax loss. Second, although the softmax loss significantly outperforms multi-margin loss in classification accuracy of ResNet-20, 92 in 959 fixed samples mentioned previously have been correctly classified by the ResNet-20 model trained by multi-margin loss. The phenomenon discussed above reflects that a specific loss function is sensitive to some features in the feature space of the training data but not sensitive to other features.
Based on the above observations, we try to find a general way to combine multiple loss functions independently to join the training process for learning more meaningful features. However, in the training process using multiple independent loss functions, some loss functions may inevitably degrade network performance. As a result, deploying multiple loss functions in training to efficiently optimize deep models is a challenging task in practice. How do different loss functions take effect separately in training? What changes need to be made to the training process? How to measure the effects of these loss functions? How to schedule them for achieving better performance? In the Section 4, we will present a detailed design based on MILS strategy.
Intuition
In common, only one single loss function is involved in the training process for typical classification tasks. Sometimes, this single loss function can be formalized as a linear weighted sum of multiple loss functions. It means that there is only one same loss function that will be used for training deep neural networks in all training iterations. Why not use different loss functions to train the deep model in different training iterations separately?
Inspired by this assumption, we try to search for a general scheme to combine multiple independent loss functions during the training process. It is easy to find that the fundamental issue of this assumption is how to ensure that multiple loss functions do not degrade the model performance during the training process. Thus, we need an evaluation criterion to measure the impact of one loss function on the model performance in a training iteration. In order to identify the impact of loss function on model performance, we first introduce a conception of an observation dataset and evaluate the impact of the current loss function on the model based on the model’s classification accuracy on the observation dataset. In general, creating a new dataset is very difficult, so randomly copying some samples from the training dataset is a reasonable way to build an observation dataset. Suppose one loss function gives a negative effect on the model performance, which is evaluated by the classification accuracy on the observation dataset using deep models updated by this loss function. In that case, we need to reload the last model parameters and use other loss functions to train the model again. Consequently, if one loss function fails to improve the model performance, it will bring twice parameter updating and one parameter reloading operations in this training iteration. That means more overheads are generated to reduce the negative effect of this loss.
As mentioned above, training deep models using multiple independent loss functions may inevitably bring high computational costs. Thus, we need a scalable framework that schedules the participation of multiple loss functions in one training process and alleviates the related computation costs to an acceptable level.
Framework
The illustration of MILS. If the 
As shown in Fig. 3, we develop a framework that can combine multiple different loss functions for training deep neural networks. Specifically, for all candidate loss functions, one loss function will be chosen as the primary loss function (for example, we select softmax loss as primary loss function) before the training start, and the other loss functions (such as multi-margin loss, center loss, focal loss, and L-GM loss) will play auxiliary roles for the possible contribution to improve the model performance. For example, if we use softmax loss and center loss as primary loss and auxiliary loss, respectively. This MILS version loss can be formulated as:
For the MILS strategy, we define a participation ratio as
MILS can be regarded as a scheduling algorithm that schedules the use of loss functions in the training process based on their performance on the observation dataset. The pseudocode of MILS is shown in Algorithm 4.3. MILS has two main hyperparameters, i.e., participation rate
The pseudo code of MILS scheduling algorithmThe model and optimizer parameters after
In MILS, we initialize a probability
As shown in Algorithm 4.3, in every training iteration, we will randomly pick
Experiments
We conduct extensive experiments to test the effectiveness of our proposal on the prevalent SVHN [28], CIFAR10/100 [27], and Tiny-Imagenet datasets1
In the training process, only one loss will be chosen as an auxiliary loss. All experiments are carried out using the PyTorch framework2
SVHN
SVHN is a real-world image dataset for developing machine learning and object recognition algorithms with minimal requirement on data pre-processing and formatting. The SVHN dataset contains 73,257 training samples and 26,032 testing samples.
We compare the softmax loss, the center loss, and their MILS versions (softmax loss as the primary loss, center loss as the auxiliary loss respectively with the participation rate of
The baselines and experimental results of the ResNet-20 trained with various loss functions and MILS loss on the SVHN dataset
The baselines and experimental results of the ResNet-20 trained with various loss functions and MILS loss on the SVHN dataset
Two-dimensional feature embedding on the SVHN training set. (a) Softmax loss. (b) The joint supervision of softmax loss and center loss [11]. (c) MILS schedule with center loss as auxiliary loss function with participation rate of 
We select the softmax loss as the primary loss and choose one of multi-margin loss, center loss, and L-GM loss as the auxiliary loss to train the network ResNet-20. We set participation rate
The classification accuracies on the test dataset of the SVHN dataset are present in Table 1. We can see that the multi-margin loss is a little weak compared with the four other loss functions in model performance. As shown in Table 1, if we use MILS to schedule softmax loss and multi-margin loss, the model performance (test error) has achieved 4.13%. Compared with 4.29% and 5.25%, the baselines of softmax loss and multi-margin loss, MILS significantly improves the model performance with very little overhead. Center loss (the joint supervision of softmax loss and center loss to train the deep models) has a very excellent performance on the SVHN dataset, but if we use MILS to combine softmax loss and center loss (only center loss involved) (
CIFAR-10 and CIFAR-100
CIFAR-10 and CIFAR-100 each consists of 32
The baselines and experimental results of the PreResNet-20 and VGG11-bn models trained by various loss functions and MILS losses on the CIFAR-10 dataset
For the CIFAR-10 dataset, we trained the VGG11-bn and PreResNet-20 (PreResNet with a depth of 20). If not specified, the networks are trained with a batchsize of 128 for 300 epochs. The learning rate is initially set to 0.1 and then divided by 10 at the 150th and 225th epoch. The weight decay is set to
The baselines and experimental results of deep models trained by various loss functions and MILS losses on the CIFAR-100 dataset
For the CIFAR-100 dataset, we trained the AlexNet, VGG19-bn, ResNet-50 (ResNet with a depth of 50), and DenseNet-100 (DenseNet with a depth of 100, DesNet-100 is trained with a batch size of 64 for 300 epochs). The softmax loss has been predefined as the primary loss function, one of the multi-margin loss, focal loss, center loss, and L-GM loss has been regarded as an auxiliary loss function. The auxiliary loss is participating in the training process according to the participation rate
Tiny-ImageNet
The Tiny-ImageNet dataset is a subset of the ImageNet dataset with 200 classes. It has images with 64
Pale colour lines denote the counts of total parameters updated by auxiliary loss in an epoch, and deep colour lines denote the counts of successful parameter updates by auxiliary loss in an epoch. Point-fold line denotes the test error(%) of deep models trained by MILS version loss(softmax loss as primary loss, multi-margin loss as auxiliary loss).
The baselines and experimental results of Resnet-50 model trained by various loss functions and MILS losses on the Tiny-imagenet dataset
We train the network ResNet-50 to evaluate the effectiveness of MILS on the Tiny-ImageNet dataset. The size of input images (training samples or testing samples) has been resized from 64
We also investigate the successful updating ratio of the auxiliary loss function to develop a deep understanding of the training process based on MILS. When we only use the multi-margin loss to train the ResNet-50 on the Tiny-Imagenet dataset, it fails to train this network, and the final best training and test errors are 99.44% and 99.76% respectively. However, if we combine the softmax loss with multi-margin loss (
How the batch training time changes associated with 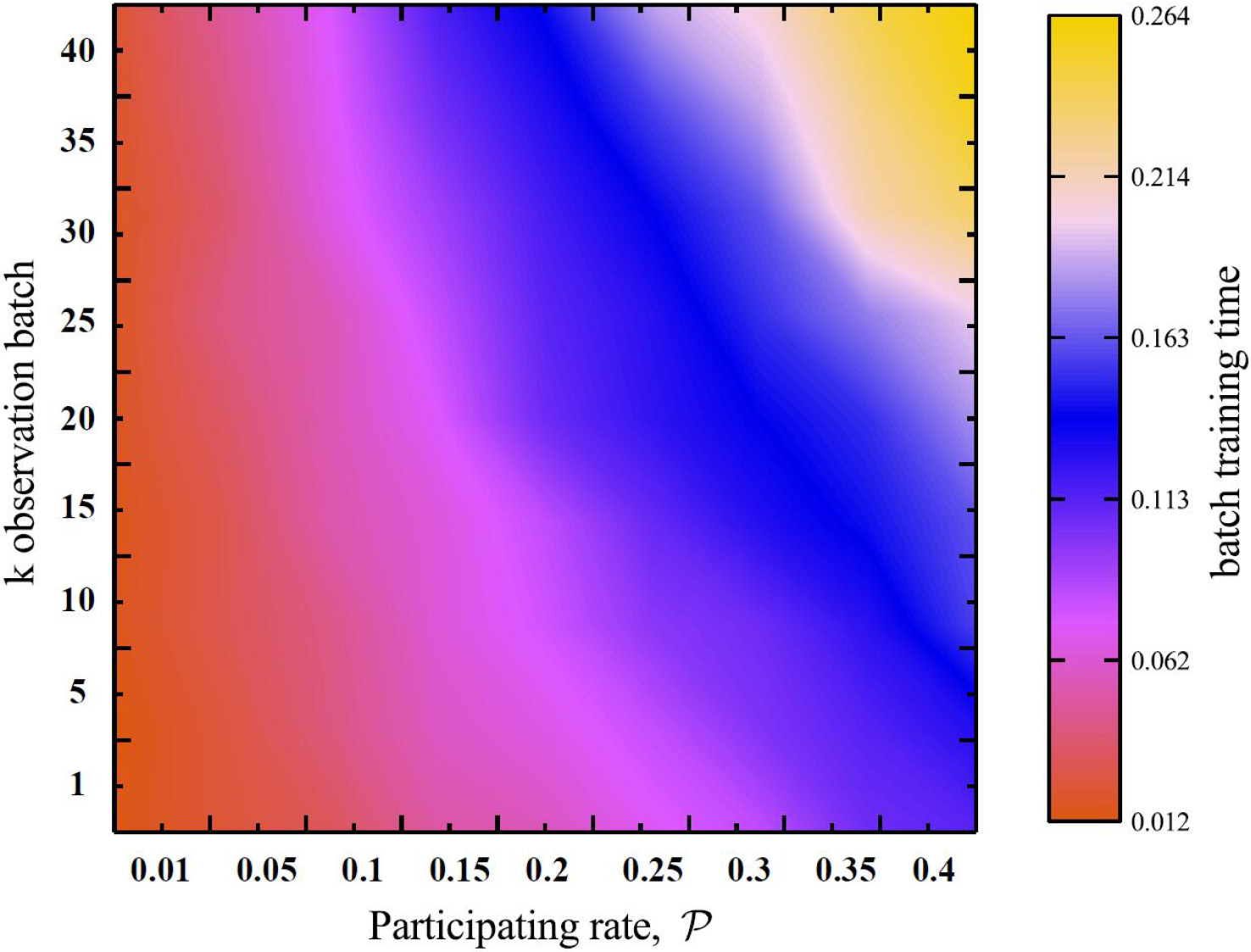
The deep colour point-fold line denotes the test error of ResNet-50 model trained by multi-margin loss, and the pale colour point-fold line denotes the test error of ResNet-50 model by MILS loss (softmax loss 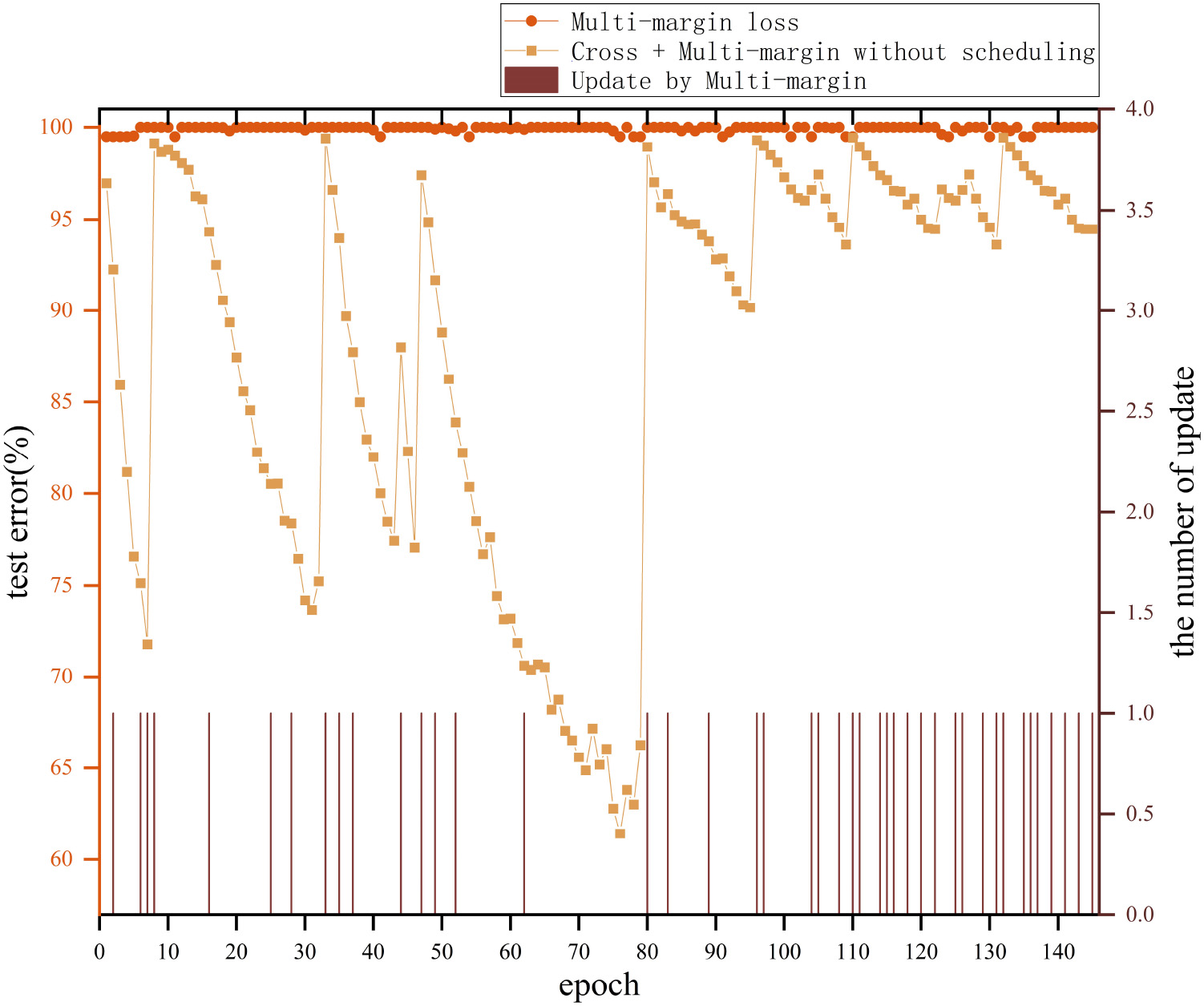
This section will explore the extra computational cost associated with MILS. In every iteration,
In fact, high computational or cache costs does not denote that the model can always raise its performance. We have two simple observations. First, if the high computational cost is mainly caused by high
We use a scheduling algorithm to avoid that auxiliary loss function introducing a negative effect on model performance. In order to verify that whether our scheduling mechanism plays a key role in MILS or not, we conducted the following experiments. Figure 7 shows that multi-margin loss fails to train ResNet-50 on the Tiny-Imagenet dataset. We also combine softmax and multi-margin loss to train this network without evaluating operation. Each epoch has a 20% chance to randomly select a batch to use the multi-margin loss to update the model parameters. Experiment results reveal that the model performance will be seriously affected by the auxiliary loss function, even if the model only updated by multi-margin loss several times without using a scheduling mechanism. We also trained ResNet-50 by MILS (softmax and multi-margin loss with scheduling strategy,
Conclusion and discussion
In this work, we introduce MILS to combine multiple different loss functions for the purpose of model performance improvement. As far as we know, we are the first to consider the idea that schedules the multiple loss functions independently and alternately in the training process according to their performance. We demonstrate that MILS is a new kind and more effective version of multiple loss function compared with joint loss functions on various deep models and datasets. Traditional multiple loss (joint loss) can be regarded as forming a new single loss through fixed linear weighting in space, while MILS makes multiple independent losses interacting in training time series. Compared with traditional joint loss functions, their MILS version has better flexibility and performance with very little extra overhead.
Our experiments show that with only 1% participation rate of the auxiliary loss function and 1 training batchsize image as the observation dataset, MILS still can achieve good performance for accuracy improvement. Extensive experiments using various deep models on various recognition benchmarks demonstrate our scheme is simple, robust, lightweight, and effective for typical classification tasks.
However, there’s still some limitations in this work. This paper only evaluates the practicality of MILS on typical object recognition benchmarks. In the future, we will test the effectiveness of MILS on object recognition benchmarks with factors such as noise and imbalance.
Footnotes
Acknowledgments
This work was supported by the Medico-Engineering Cooperation Funds from University of Electronic Science and Technology of China (No. ZYGX2021YGLH213, No. ZYGX2022YGRH016), the Municipal Government of Quzhou (Grant 2021D007, Grant 2021D008, Grant 2021D015, Grant 2021D018, Grant 2022D018, Grant 2022D029), as well as the Zhejiang Provincial Natural Science Foundation of China under Grant No. LGF22G010009.