Multi-label learning deals with the problem that each instance is associated with multiple labels simultaneously, and many methods have been proposed by modeling label correlations in a global way to improve the performance of multi-label learning. However, the local label correlations and the influence of feature correlations are not fully exploited for multi-label learning. In real applications, different examples may share different label correlations, and similarly, different feature correlations are also shared by different data subsets. In this paper, a method is proposed for multi-label learning by modeling local label correlations and local feature correlations. Specifically, the data set is first divided into several subsets by a clustering method. Then, the local label and feature correlations, and the multi-label classifiers are modeled based on each data subset respectively. In addition, a novel regularization is proposed to model the consistency between classifiers corresponding to different data subsets. Experimental results on twelve real-word multi-label data sets demonstrate the effectiveness of the proposed method.
Multi-label learning can deal with objects with various semantic meanings, and it has been widely used in various application fields [1], such as, text categorization [2, 3, 4], image annotation [5, 6, 7], music emotion categorization [8, 9] and clinical data analysis [10, 11]. The target of multi-label learning is to use the given data to learn an effective classifier, which can predict a set of relevant category labels for new data instances.
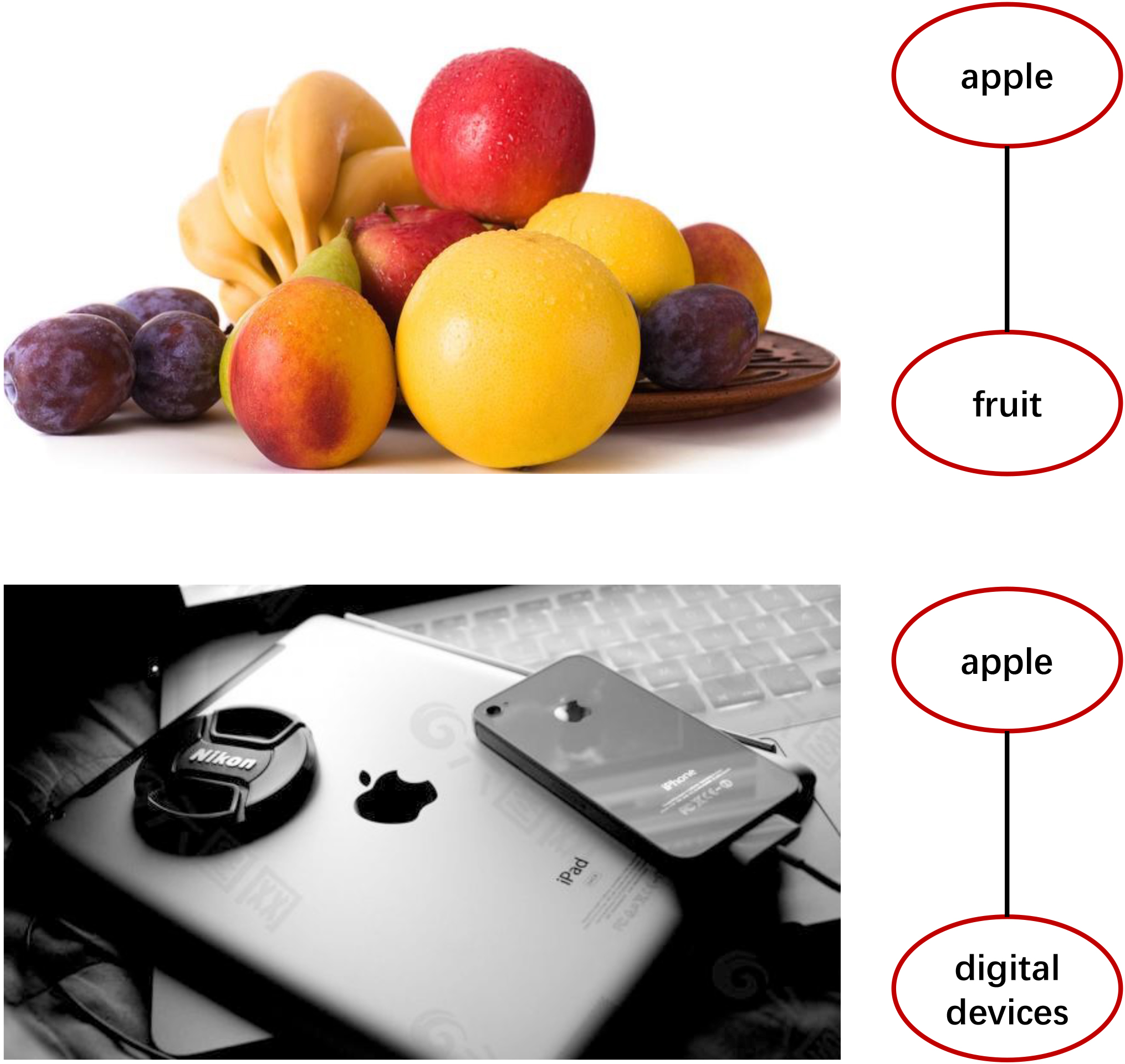
An example of local label correlation.
For multi-label learning, a simple and direct solution is to decompose the problem into a set of binary classification problems [12, 13], and each binary classification problem corresponds to a label. This approach may struggle to achieve good performance because it does not take into account the label correlations. Different to single-label learning, multi-label data involves complex correlations [1] between labels, i.e., the labels may correlated with each other. In other words, the information of a label can provide additional information for the labels related to it. To solve this problem, a large number of multi-label learning methods have been proposed to incorporate label correlations. However, most existing multi-label learning methods focus on global label correlations which are shared by all the instances [14, 15, 16, 17, 18, 19, 20, 21, 22]. In practical applications, label correlations may only be locally shared by different data subsets [23, 24, 25, 26, 27, 28]. For example, in Fig. 1, there is a picture of various fruits and a picture of digital devices. When only focusing on the pictures of fruit, label “apple” is related to “fruit”, and it is not related to “digital devices”. When only focusing on the pictures containing digital devices, label “apple” is related to “digital devices” not to “fruit”. This observation indicates that it is necessary to model label correlations for different data subsets respectively. Some methods [24, 25, 26] have been proposed to model local label correlations for multi-label learning, but they ignoring the relationship between features. On the other hand, in the environment of big data, the feature space of data sets becomes larger and larger, so feature redundancy may exist in the large feature space. Exploiting feature correlation can help to get rid of redundant features and obtain a more compact feature space, and further improve the performance of a model. Some methods [29, 30] introduce feature correlations into multi-label learning.Assuming that if two features are correlated, then their corresponding parameter vectors are also close. Similar to label correlation, feature correlation should also be modeled locally for different data subsets [31].
In this paper, a method is proposed to exploit Local Label and Feature Correlations for multi-label learning, namely LLFC. The local correlations of labels and features are integrated into a unified framework. Considering that the correlations corresponding to different data subsets are different, the classification models corresponding to each data subset are also different. Similar to CLMLC [32] and CBMLC [33], the data set is decomposed into several disjoint data groups, and then LLFC learns a classifier for each data group. But different from CLMLC and CBMLC, LLFC trains a classifier for each data group by modeling local label and feature correlations. The label correlations are used to constrain on the outputs of labels by assuming that if two labels are related then their corresponding outputs are similar. Besides, considering the relationship between different data clusters, if two data subsets are similar, their corresponding model parameters will be also similar, and then a new regularization term is proposed to control the similarity between different clusters by constraining the consistency of the models. In the testing stage, multiple classifiers are selected to predict the labels for the test data. The contributions of this paper are summarized as follows:
To the best of our knowledge, this paper is the first one to model the local correlation of labels and features into a unified framework for multi-label learning.
The consistency between different models corresponding to different data subsets is modeled.
Experimental results on twelve real-word multi-label data sets demonstrate the effectiveness of the proposed method.
The rest of this paper is organized as follows. Section 2 introduces some previous methods of multi-label learning, Section 3 describes the method LLFC in detail, Section 4 provides the experimental results and analyses. Finally, we conclude this paper in Section 5.
Related works
In multi-label learning, labels are usually correlated with each other, and modeling label correlations plays a crucial role in improvement of performance.
According to the order of correlations that the learning techniques have considered, existing methods are usually divided into three categories: first-order, second-order and higher-order strategies [1, 34]. The first-order strategy takes no account of the interaction between the labels and divides a multi-label learning problem into several independent single-label learning problems, and such as the representative algorithms BR [12], LIFT [35] and MLKNN [36]. The first-order strategy is simple and efficient, but it doesn’t consider the correlation between labels, which may be difficult to achieve good performance in most cases. To solve this problem,researchers set out to explore pairwise label correlations, known as second-order strategy, such as [14, 23, 37, 38, 39]. In fact, a label may depend on multiple labels simultaneously. The high-order strategy considers the interaction between multiple labels, such as [18, 40, 41, 42, 43, 44]. This strategy mines strong label correlations, but it may lead to a high computational complexity.
Besides, according to the scope of application of label correlations, existing methods are mainly divided into global and local strategies. For the global strategy, the label correlation is learned and exploited globally for the whole data. For example, ML-LRC [18] applies a kernel regularization to capture label correlations, and successfully captures global label correlations by using low rank structure on label correlation matrix. LSLC-ML [45] uses a manifold regularization to model positive and negative label correlations to recover missing labels for multi-label learning. These two methods only consider global label correlations,while in practical application, label correlations may not be globally applicable. Global label correlations may introduce irrelevant labels into the model. For the local strategy, label correlations are learned and exploited locally for different subsets of a data set. For example, ML-LOC [24] extends the original features by adding a code vector for each instance to exploit local label correlations. It divides the training data into several groups by a clustering method, and then generates prototypes of label vectors for each set. The code vector is composed of the similarities between the label vector of each instance and these archetypes. CLFS [25] divides the training data into several subsets by clustering, then it models local label correlations on each subset and constrains the correlations on outputs. GLOCAL [26] integrates global and local label correlations by label manifold regularization and constrains label correlations on outputs, which achieves good results. While these methods only focus on the local correlation of labels and ignore the relationship between features.
The information in the feature space is also very important for constructing multi-label learning models [15, 46]. For example, ML-LSS [46] utilizes local sample similarity for multi-label learning. It assumes that if the data samples are similar in a feature subset, their corresponding labels will also be similar. Although this method utilizes the information in the feature space, it only considers the correlation between instances and does not directly model the correlation between features. Exploiting feature correlations can help to remove the redundancy between features and get a more compact feature space. For example, MSSL [30] combines feature manifold learning and sparse regularization into a joint framework to study the problem of multi-label feature selection, and makes use of global feature correlations through feature manifolds. Similar to label correlation, the feature correlation may also be locally shared by different subsets of data examples. FSLCLC [31] explores local feature correlations on different subsets of examples, and tries to learn the potential relationship between features and labels. However, this method only model local feature correlations and Learn the same classifier for different data subsets. Through the analyses of previous studies, most of the existing multi-label learning methods only model the label correlations or feature correlations separately. To further improve the classification performance of multi-label learning, DRMFS [29] uses feature graph regularization and label graph regularization to preserve the geometric structure of feature manifolds and label manifolds respectively, which is the first time to integrate global feature correlations and label correlations into a unified framework. However, as discussed above, different subsets of data correspond to different label correlations and feature correlations, and exploiting global correlation of labels and features may bring unnecessary or even misleading constraints to the model.
To solve the mentioned problems, in this paper, we propose to construct the model by exploring the local correlation of labels and features simultaneously.
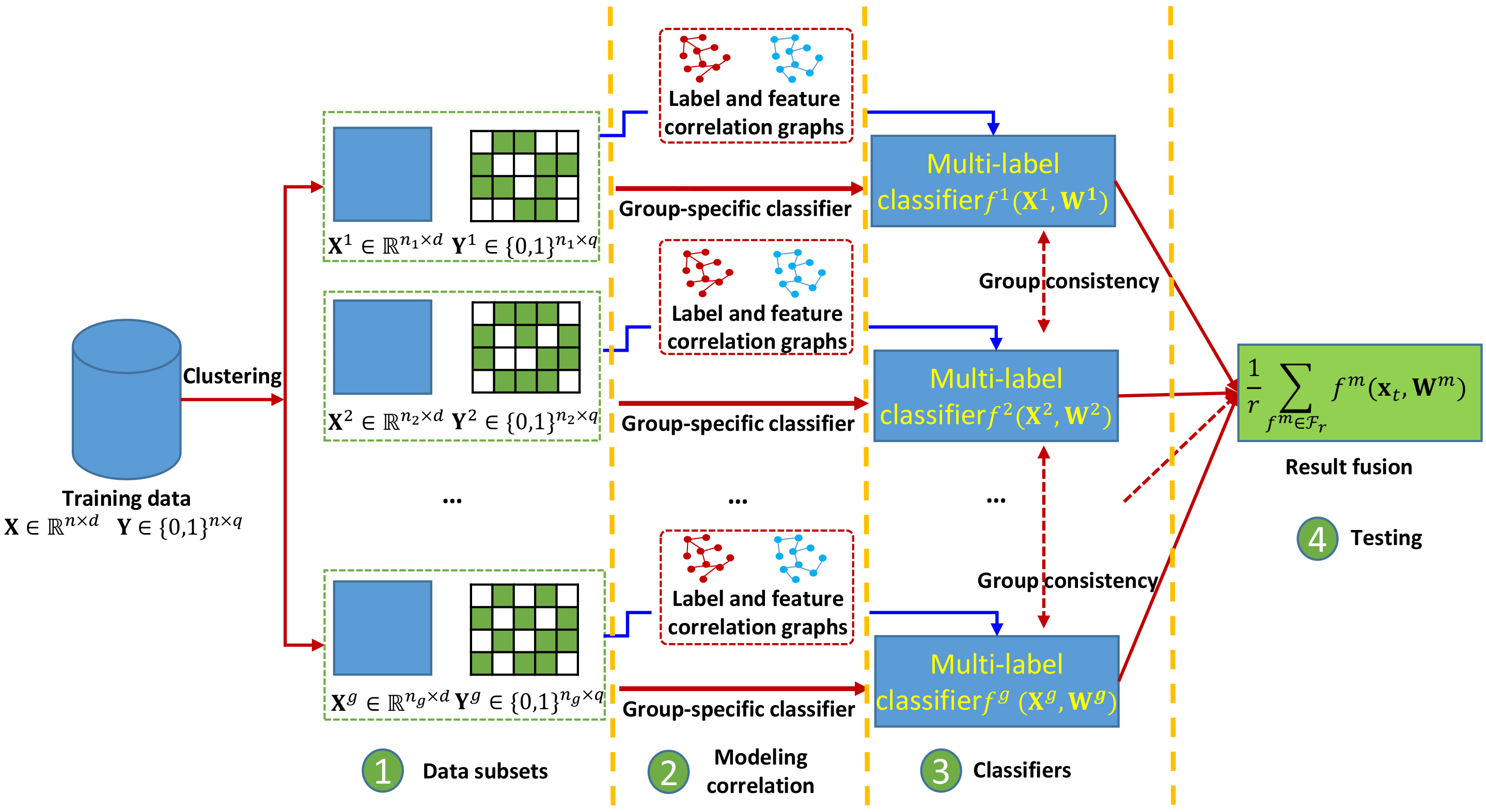
The framework of the proposed method.
The proposed method
In this section, details of the proposed method LLFC are introduced, and the framework of it is shown in Fig. 2. The framework diagram is mainly composed of four parts, which are divided by the orange dotted line in the figure. As shown in the figure, step 1 is to divide the train data into multiple disjoint data subsets by clustering. and are data subsets and label subsets respectively. The blue rectangles represent the data matrices corresponding to all the data subsets , and the rectangles with white and green color indicate the corresponding label matrices of . The white color indicates that the element value of the matrix is 0, that means the label is not included, and the green color indicates that the element value in the matrix is 1, which means that the label is included. In step 2, local label and feature correlations are modeled by manifold regularization to construct the group-specific multi-label classifiers for each data subset. In step 3, the consistency between different group-specific classifiers is modeled. Finally, step 4 is the test stage, and nearest classification models are selected to predict possible labels for the test data.
Data clustering
In multi-label learning, assuming is a dimensional feature space and represents a label set with class labels. is a train data set with instances. is the label matrix, and is a binary label vector corresponding to , where represents belongs to , otherwise .
To model the local label and feature correlations, similar to previous work [25, 26, 31], the data set is firstly divided into subsets by clustering. Then, the feature matrices and label matrices for the subsets can be obtained, where has instances, and is the label subset of Y corresponding to . After clustering, the cluster centers for each data subset can be obtained, where is the -th row of C and represents the clustering center vector of the -th subset.
Model construction
For each data subset, a multi-label classifier can be constructed. Specifically, a classifier is learned for the -th subset based on and . In this paper, the linear classifier is adopted, and is defined as
where indicates the -th instance in the -th data subset, and is the model coefficient of the linear model . denotes the bias, and it can be absorbed into by adding the constant value 1 to each data instance as an additional feature.
In this paper, an independent model coefficient is learned for each subset through the least squares loss function with F-norm constraints. Consequently, the basic model of LLFC can be constructed as follows
where is the non-negative model parameter, are the model coefficients, is the weight coefficient matrix of the -th model constructed based the -th data subset .
Learning local label correlations
In multi-label learning, the correlation between different labels provides additional information for multi-label learning, which is very helpful to improve the performance of classifier. Previous approaches usually exploit label correlation in a global way, and assume that label correlations are shared by all instances [14, 15, 16, 17, 18, 19, 20, 21, 22]. However, in some real applications, label correlations are locally applicable. In this paper, explore local label correlation for each model by adding a manifold regularization to constrain the correlations on the outputs of labels in each data subset.
Motivated by previous work CLFS [25] and GLOCAL [26], the training data is divided into different subsets, the local label correlation matrices are calculated according to the corresponding label subset of each data subset. Let be label correlation matrix which corresponds to the -th label subset . is the element of in the -th row and -th column, and it represents the correlation between the -th and -th label of . By the cosine similarity, can be calculated as follows
where indicates element of in the -th row and -th column.
After obtaining the local label correlation matrices, it can be used to model local label correlations for the models . Specifically, for each data subset, assuming that if two labels are highly correlated, their corresponding output should be more similar, i.e. if and are highly correlated in the -th subset, the outputs of and should be similar, and vice versa. and are the i-th column and j-th column of , and . Consequently, the regularization term for modeling local label correlation for each model can be defined as
where is the Laplacian matrix of the label correlation matrix , is a diagonal matrix with diagonal elements , and and are the -th and -th columns of respectively. By combining the local label correlations, the objective Eq. (2) can be rewritten as follow
where is a non-negative weight coefficient.
Learning local feature correlations
In multi-label learning, there is not only correlation between labels, but also correlation between features, and exploiting feature correlations can help to remove redundant features and obtain a more compact feature space. Similar to local label correlations, different instances may correspond to different feature correlations. Therefore, in order to get improved coefficient matrices, this paper introduces the manifold regularization based on local feature correlations for multi-label learning. For each data subset, the cosine similarity is adopted to calculate the feature correlations. Let be the feature correlation matrix which corresponds to the m-th data subset , and element is defined as
where is the -th row and -th column element of and represents the similarity between the -th and -th features in . and represent the -th row and -th column element and the -th row and -th column element of respectively.
For each data subset, supposing that if two features in are similar, the model coefficients corresponding to these two features are similar too, i.e. if and are more similar, then their weight vectors and should be similar as well, where and are the -th and -th rows of respectively, and and are the -th and -th columns of respectively. Similar to the construction of local label correlation, the following regularization term is defined to model local feature correlation
where is the Laplacian matrix of , is a diagonal matrix with . By combing feature correlations, the objective Eq. (5) can be reformulated as follows
where is a non-negative weight parameter.
Exploring the consistency between models
In this paper, the data set is divided into groups, and construct a model for each each of them. Considering that the data subsets come from the same data distribution, the models for different subsets should be consistent to some extent. Therefore, we try to model the consistency between different models for the data groups. Specifically, if two data subsets are similar, their corresponding models will also be similar, i.e., if and are similar, and will be similar as well, where and are -th and -th data subsets, and are their corresponding model coefficients. Consequently, the following regularization term is defined to model the consistency between different models
where represents similarity between the -th and -th data subsets, and . It can be obtained by calculating the similarity between the clustering center vectors of data subsets according to the following formulation
where represents the -th row and -th column element and represents the -th row and -th column element of C.
Finally, the final objective function of our proposed method LLFC can be defined as follows
where is a non-negative model parameter.
Optimization
The objective Eq. (11) is convex and smooth, and the gradient descent method is used to optimize the solution. From the objective function, it need to solve the model coefficients and adopt the alternating optimization strategy.
When updating the model coefficient for the -th group, the other model coefficients are fixed, and the problem Eq. (11) is simplified as follows
As a result, the gradient w.r.t can be calculated as follows,
Then, can be updated by
where is a step size for , it is a small positive number. In this paper, we use an automatic step adjustment method [47] to set the value of .
[t]Optimization of LLFCTraining data:, label matrix:, and the weighting parameters , , , , , and ; Model Coefficients:;
Getting and through K-means clustering on X; Calculating A;
In Algorithm 3.6, the overall optimization steps of LLFC are summarized . After obtaining the model coefficients corresponding to each data subsets, the subsequent prediction can be made. Given a test instance , the prediction of the LLFC algorithm can be done in two steps:1) find the nearest data subsets for the test instance; 2) combine the predictions from the models corresponding to the nearest data subsets.
First, the Euclidean distances between the test instance and the center vectors of data subsets are calculated to find the nearest data subsets. Then, the corresponding models for the nearest data subsets are obtained. Finally, models are used to predict the labels for respectively, and then the average of the predicted results is taken as the final prediction result of .
where is the real label confidence vector of the test data , and a binary label vector corresponding to can be obtained based on a threshold value.
Time complexity
According to Algorithm 3.6, we can see that the time complexity of the algorithm is mainly controlled by the steps 6–10, where the model coefficients corresponding to each group-specific classifier should be calculated. For each group-specific classifier, the total time complexity is , where is the number of instances of the -th data subset. Therefore, the total time complexity is , where is the total number of instances, is the number of features, is the number of iterations, is the number of labels and is the number of groups.
Experiment
Experimental setup
Data sets
In this paper, we perform the experimental analysis on twelve commonly used real multi-label data sets to verify the effectiveness of the proposed method. These data sets can be downloaded from Mulan,1
and details are summarized in Table 1. For each data set, “ Instance” indicates the number of instances, “ Feature” denotes the number of features, “ Label” represents the number of labels, and “ Card” denotes the average number of labels per instance.
Characteristics of the experimental data sets
ID
Dataset
#Instance
#Feature
#Label
Card
1
yeast
2417
103
14
4.24
2
arts
5000
462
26
1.64
3
reference
5000
793
33
1.17
4
corel5k
5000
499
374
3.52
5
rcv1subset1
6000
944
101
2.88
6
rcv2subset2
6000
944
101
2.63
7
rcv2subset3
6000
944
101
2.63
8
Corel16k001
13766
500
153
2.86
9
Corel16k002
13761
500
164
2.88
10
Stackexcs
9270
635
274
2.65
11
Stackexcooking
10491
577
400
2.23
12
Stackexchess
1675
585
227
2.41
Comparing algorithms
In the experiment, we compared the proposed method with six existing multi-label learning methods. The optimal parameters for all of the algorithms are determined by a 5-fold cross validation. The detailed settings are summarized as follows:
MLKNN[36]: This method is a lazy multi-label learning method, and does not consider the correlation between labels. The value range of parameter is .
CLMLC[32]: This method is a local multi-label classification method based on Scalable clustering, and it learns a model for each subsets by low dimensional clustering. The value ranges of parameters and are , and .
ML-LSS[46]: It is a multi-label learning method with local similarity of samples. It assumes that if the feature subsets between samples are similar, the output of corresponding labels should also be similar. The value of parameters and are searched in .
LSF-CI[15]: It proposes to learn the label specific features of each label and takes into account the global label correlations in the label space and the instance correlations in the feature space. The value range of parameters , , is .
GLOCAL[26]: In this method, the global and local label correlations is obtained by the label manifolds to learn the full label and missing label. In this experiment, we use the full label method as the comparison method. The value of parameter is , the value range of parameters to is and parameters and are searched in among and respectively.
JFSC[19]: The method is based on global label correlations for feature selection and multi-label learning. The value range of parameters , and is and the value range of is .
LLFC: The proposed method. The value range of parameters and is and parameters , , , and are searched in , , , and respectively.
Evaluation metrics
In the experiment, we used seven commonly used evaluation metrics [1] to evaluate the performance of each algorithm. Given a test set , where represents a set of ground truth labels. represents a predictive label set of the instance . The output value of represents the degree to which instance is labeled with .
Hamming Loss:
The Hamming Loss evaluates the number of times an instance-label pair is misclassified, where indicates the symmetric difference between two sets.
MicroF1 measure:
It evaluates the prediction performance of the learned classifier on the label set.
Average Precision:
It evaluates the average fraction of relevant labels ranked higher than a particular label . Where .
One Error:
It evaluates the proportion of instances whose top-ranked label is not in the relevant label set, and is an indication function.
Ranking Loss:
It evaluates the average ratio of incorrectly sorted label pairs, and
Coverage:
It evaluates the average number of steps is needed to move the sorted label list of an instance down to overwrite all its related labels.
AUC:
It takes the average of the proportion of positive instances sorted higher than negative instances on all labels and represent the instance set with the label .
The above evaluation metrics are widely used in the multi-label learning, including the label-based evaluation criteria and the instance-based evaluation criteria. The larger the value of MicroF1 measure, Average Precision and AUC, the better the performance of a multi-label classification model is. For other evaluation metrics, the smaller the value, the better the performance of a multi-label classification model is.
Experimental results
In order to evaluate the performance, a 5 5-fold cross-validation is carried out for each data set, 80% of the data of each data set are randomly selected as the training data and the rest 20% are selected as the test data in the experiment, and the average value and standard deviation in terms of each evaluation metric are recorded. The experimental results (mean std) are shown in Table 2 to Table 8. The experimental data of all comparison methods on each evaluation metric are counted in these tables, and the name of the corresponding evaluation metric has been given in each table. In each row of the tables, font in boldface represents the best performance.
Experimental results (mean std) of each comparison algorithm on 12 data sets in terms of Hamming Loss. indicates the smaller the value, the better the performance is. The boldface in each row indicates the best performance
Datasets
Hamming Loss
LSF-CI
ML-LSS
GLOCAL
CLMLC
MLKNN
JFSC
LLFC
yeast
0.313 0.011
0.216 0.006
0.314 0.007
0.224 0.006
0.211 0.003
0.220 0.006
0.213 0.006
arts
0.066 0.003
0.066 0.001
0.068 0.003
0.084 0.002
0.081 0.002
0.066 0.001
0.065 0.001
reference
0.030 0.001
0.030 0.001
0.032 0.001
0.034 0.001
0.034 0.001
0.030 0.001
0.029 0.000
corel5k
0.015 0.000
0.015 0.001
0.014 0.001
0.017 0.000
0.017 0.000
0.014 0.000
0.015 0.001
rcv1subset1
0.034 0.001
0.031 0.000
0.032 0.001
0.033 0.000
0.037 0.000
0.030 0.001
0.029 0.001
rcv1subset2
0.029 0.000
0.027 0.001
0.028 0.001
0.029 0.001
0.032 0.001
0.027 0.001
0.026 0.001
rcv1subset3
0.028 0.000
0.027 0.001
0.028 0.001
0.029 0.000
0.032 0.001
0.027 0.001
0.027 0.001
Corel16k001
0.030 0.001
0.029 0.001
0.031 0.001
0.031 0.001
0.036 0.000
0.029 0.001
0.030 0.001
Corel16k002
0.028 0.002
0.028 0.001
0.029 0.001
0.030 0.001
0.035 0.000
0.028 0.001
0.028 0.001
Stackexcs
0.012 0.001
0.012 0.000
0.013 0.000
0.011 0.000
0.012 0.000
0.011 0.000
0.011 0.001
Stackexcooking
0.008 0.000
0.006 0.000
0.007 0.001
0.006 0.000
0.006 0.000
0.007 0.000
0.006 0.000
Stackexchess
0.012 0.001
0.012 0.000
0.014 0.001
0.014 0.001
0.013 0.001
0.013 0.000
0.013 0.000
Experimental results (mean std) of each comparison algorithm on 12 data sets in terms of MicroF1 measure. indicates the bigger the value, the better the performance is. The boldface in each row indicates the best performance
Datasets
MicroF1 measure
LSF-CI
ML-LSS
GLOCAL
CLMLC
MLKNN
JFSC
LLFC
yeast
0.514 0.013
0.661 0.009
0.499 0.015
0.636 0.008
0.668 0.003
0.658 0.005
0.670 0.008
arts
0.452 0.014
0.454 0.006
0.451 0.011
0.387 0.006
0.328 0.005
0.456 0.004
0.466 0.007
reference
0.560 0.014
0.575 0.004
0.573 0.012
0.537 0.006
0.503 0.007
0.578 0.004
0.582 0.006
corel5k
0.277 0.011
0.272 0.007
0.274 0.006
0.190 0.003
0.237 0.003
0.271 0.008
0.289 0.003
rcv1subset1
0.495 0.001
0.501 0.002
0.493 0.005
0.411 0.006
0.417 0.002
0.483 0.004
0.532 0.005
rcv1subset2
0.481 0.006
0.492 0.008
0.479 0.006
0.429 0.009
0.389 0.005
0.485 0.007
0.510 0.009
rcv1subset3
0.487 0.007
0.497 0.006
0.482 0.007
0.423 0.009
0.387 0.004
0.479 0.010
0.514 0.013
Corel16k001
0.287 0.003
0.285 0.004
0.282 0.003
0.226 0.002
0.252 0.001
0.284 0.003
0.291 0.004
Corel16k002
0.287 0.004
0.289 0.005
0.283 0.004
0.223 0.002
0.253 0.001
0.287 0.005
0.294 0.002
Stackexcs
0.407 0.006
0.419 0.002
0.400 0.007
0.364 0.005
0.354 0.001
0.424 0.006
0.456 0.005
Stackexcooking
0.400 0.004
0.418 0.005
0.405 0.004
0.299 0.011
0.343 0.002
0.417 0.007
0.451 0.006
Stackexchess
0.423 0.010
0.385 0.019
0.355 0.017
0.321 0.019
0.308 0.016
0.390 0.022
0.421 0.015
Experimental results (mean std) of each comparison algorithm on 12 data sets in terms of Average precision. indicates the bigger the value, the better the performance is. The boldface in each row indicates the best performance
Datasets
Average precision
LSF-CI
ML-LSS
GLOCAL
CLMLC
MLKNN
JFSC
LLFC
yeast
0.620 0.012
0.762 0.010
0.611 0.014
0.714 0.005
0.762 0.006
0.760 0.004
0.766 0.008
arts
0.623 0.011
0.629 0.003
0.628 0.008
0.554 0.004
0.525 0.004
0.625 0.002
0.639 0.007
reference
0.699 0.014
0.710 0.003
0.712 0.009
0.671 0.003
0.637 0.005
0.706 0.004
0.720 0.009
corel5k
0.300 0.012
0.301 0.005
0.297 0.004
0.215 0.004
0.249 0.002
0.300 0.006
0.313 0.004
rcv1subset1
0.605 0.005
0.601 0.005
0.604 0.007
0.514 0.005
0.495 0.002
0.594 0.006
0.625 0.004
rcv1subset2
0.628 0.004
0.628 0.002
0.631 0.008
0.551 0.008
0.502 0.003
0.625 0.007
0.634 0.009
rcv1subset3
0.627 0.006
0.624 0.007
0.623 0.006
0.543 0.009
0.502 0.003
0.617 0.008
0.636 0.011
Corel16k001
0.345 0.005
0.344 0.004
0.336 0.002
0.281 0.002
0.290 0.002
0.345 0.003
0.349 0.003
Corel16k002
0.340 0.004
0.341 0.005
0.332 0.004
0.271 0.003
0.286 0.001
0.341 0.005
0.345 0.003
Stackexcs
0.517 0.007
0.494 0.005
0.512 0.003
0.398 0.007
0.392 0.001
0.496 0.006
0.530 0.009
Stackexcooking
0.515 0.004
0.504 0.008
0.507 0.004
0.319 0.010
0.378 0.002
0.504 0.007
0.519 0.008
Stackexchess
0.517 0.014
0.477 0.026
0.474 0.017
0.376 0.019
0.373 0.021
0.475 0.021
0.512 0.015
Experimental results (mean std) of each comparison algorithm on 12 data sets in terms of One Error. indicates the smaller the value, the better the performance is. The boldface in each column indicates the best performance
Datasets
One Error
LSF-CI
ML-LSS
GLOCAL
CLMLC
MLKNN
JFSC
LLFC
yeast
0.341 0.021
0.226 0.012
0.366 0.031
0.275 0.006
0.234 0.009
0.233 0.013
0.222 0.017
arts
0.453 0.016
0.457 0.004
0.451 0.008
0.546 0.005
0.611 0.008
0.455 0.002
0.444 0.010
reference
0.377 0.016
0.373 0.004
0.367 0.007
0.405 0.004
0.455 0.007
0.378 0.005
0.360 0.006
corel5k
0.641 0.017
0.643 0.008
0.643 0.010
0.787 0.009
0.732 0.004
0.639 0.008
0.632 0.015
rcv1subset1
0.423 0.006
0.428 0.009
0.424 0.015
0.524 0.004
0.534 0.003
0.434 0.002
0.415 0.017
rcv1subset2
0.413 0.004
0.412 0.006
0.409 0.012
0.475 0.008
0.558 0.004
0.408 0.013
0.416 0.015
rcv1subset3
0.414 0.010
0.415 0.016
0.418 0.007
0.485 0.013
0.558 0.003
0.411 0.010
0.422 0.018
Corel16k001
0.639 0.013
0.639 0.005
0.643 0.007
0.735 0.002
0.733 0.003
0.639 0.008
0.640 0.007
Corel16k002
0.638 0.007
0.634 0.011
0.638 0.010
0.744 0.004
0.732 0.002
0.638 0.008
0.636 0.008
Stackexcs
0.448 0.013
0.481 0.014
0.448 0.010
0.545 0.015
0.568 0.002
0.473 0.014
0.439 0.014
Stackexcooking
0.416 0.006
0.425 0.013
0.418 0.006
0.562 0.013
0.536 0.003
0.422 0.006
0.415 0.009
Stackexchess
0.398 0.022
0.457 0.048
0.453 0.029
0.523 0.029
0.554 0.026
0.463 0.019
0.424 0.020
Experimental results (mean std) of each comparison algorithm on 12 data sets in terms of Ranking Loss. indicates the smaller the value, the better the performance is. The boldface in each row indicates the best performance
Datasets
Ranking Loss
LSF-CI
ML-LSS
GLOCAL
CLMLC
MLKNN
JFSC
LLFC
yeast
0.340 0.007
0.170 0.006
0.349 0.014
0.210 0.006
0.169 0.004
0.175 0.004
0.166 0.006
arts
0.135 0.004
0.120 0.002
0.131 0.003
0.179 0.002
0.148 0.002
0.141 0.001
0.119 0.005
reference
0.095 0.009
0.082 0.002
0.083 0.003
0.150 0.003
0.087 0.002
0.088 0.002
0.076 0.009
corel5k
0.240 0.010
0.158 0.003
0.185 0.007
0.368 0.003
0.132 0.002
0.148 0.005
0.132 0.010
rcv1subset1
0.050 0.001
0.053 0.001
0.059 0.002
0.194 0.003
0.091 0.001
0.062 0.002
0.044 0.001
rcv1subset2
0.051 0.001
0.051 0.001
0.056 0.003
0.191 0.004
0.089 0.001
0.057 0.001
0.047 0.003
rcv1subset3
0.052 0.003
0.051 0.003
0.060 0.005
0.195 0.007
0.091 0.001
0.057 0.002
0.043 0.002
Corel16k001
0.164 0.001
0.150 0.002
0.182 0.008
0.221 0.001
0.169 0.001
0.158 0.003
0.149 0.004
Corel16k002
0.162 0.005
0.145 0.003
0.178 0.002
0.226 0.001
0.162 0.001
0.152 0.002
0.144 0.002
Stackexcs
0.084 0.003
0.072 0.002
0.086 0.002
0.200 0.011
0.119 0.001
0.075 0.002
0.059 0.004
Stackexcooking
0.117 0.003
0.090 0.004
0.101 0.005
0.275 0.005
0.148 0.002
0.090 0.002
0.077 0.003
Stackexchess
0.101 0.008
0.120 0.007
0.145 0.007
0.398 0.026
0.135 0.007
0.138 0.016
0.090 0.006
Experimental results (mean std) of each comparison algorithm on 12 data sets in terms of Coverage. indicates the smaller the value, the better the performance is. The boldface in each row indicates the best performance
Datasets
Coverage
LSF-CI
ML-LSS
GLOCAL
CLMLC
MLKNN
JFSC
LLFC
yeast
0.624 0.003
0.455 0.008
0.624 0.016
0.519 0.011
0.450 0.005
0.470 0.009
0.450 0.010
arts
0.202 0.006
0.187 0.004
0.197 0.003
0.241 0.003
0.206 0.001
0.216 0.002
0.187 0.004
reference
0.111 0.011
0.104 0.003
0.099 0.006
0.115 0.002
0.101 0.003
0.113 0.003
0.097 0.009
corel5k
0.421 0.013
0.364 0.004
0.400 0.012
0.427 0.005
0.303 0.004
0.339 0.008
0.318 0.020
rcv1subset1
0.125 0.003
0.134 0.003
0.146 0.004
0.297 0.005
0.196 0.002
0.150 0.008
0.114 0.003
rcv1subset2
0.126 0.003
0.126 0.003
0.137 0.005
0.267 0.005
0.185 0.002
0.138 0.005
0.115 0.005
rcv1subset3
0.125 0.008
0.124 0.006
0.144 0.011
0.268 0.010
0.187 0.002
0.135 0.004
0.107 0.005
Corel16k001
0.312 0.003
0.299 0.005
0.351 0.013
0.381 0.001
0.329 0.002
0.316 0.005
0.297 0.008
Corel16k002
0.307 0.008
0.290 0.003
0.344 0.004
0.383 0.001
0.320 0.002
0.306 0.005
0.288 0.007
Stackexcs
0.177 0.004
0.153 0.004
0.182 0.004
0.292 0.011
0.233 0.003
0.154 0.005
0.127 0.005
Stackexcooking
0.183 0.004
0.177 0.007
0.193 0.009
0.352 0.005
0.269 0.002
0.177 0.004
0.150 0.003
Stackexchess
0.212 0.019
0.249 0.014
0.278 0.011
0.420 0.017
0.267 0.012
0.232 0.022
0.184 0.013
Experimental results (mean std) of each comparison algorithm on 12 data sets in terms of AUC. indicates the bigger the value, the better the performance is. The boldface in each row indicates the best performance
Datasets
AUC
LSF-CI
ML-LSS
GLOCAL
CLMLC
MLKNN
JFSC
LLFC
yeast
0.644 0.008
0.817 0.007
0.636 0.012
0.777 0.006
0.818 0.003
0.810 0.002
0.821 0.005
arts
0.830 0.007
0.842 0.003
0.833 0.004
0.794 0.003
0.822 0.002
0.814 0.002
0.840 0.006
reference
0.898 0.009
0.896 0.003
0.901 0.005
0.888 0.002
0.900 0.003
0.888 0.002
0.902 0.010
corel5k
0.855 0.007
0.848 0.003
0.816 0.007
0.799 0.002
0.869 0.002
0.857 0.005
0.868 0.010
rcv1subset1
0.934 0.001
0.930 0.002
0.923 0.003
0.824 0.002
0.890 0.002
0.920 0.004
0.940 0.002
rcv1subset2
0.928 0.002
0.928 0.001
0.920 0.003
0.822 0.003
0.885 0.002
0.919 0.003
0.933 0.003
rcv1subset3
0.928 0.004
0.930 0.002
0.916 0.006
0.822 0.006
0.884 0.001
0.921 0.003
0.938 0.002
Corel16k001
0.842 0.001
0.848 0.002
0.816 0.006
0.797 0.001
0.827 0.001
0.839 0.002
0.848 0.004
Corel16k002
0.848 0.004
0.856 0.003
0.824 0.002
0.800 0.001
0.836 0.001
0.847 0.002
0.857 0.003
Stackexcs
0.911 0.002
0.923 0.002
0.908 0.001
0.841 0.007
0.877 0.002
0.923 0.002
0.935 0.003
Stackexcooking
0.890 0.005
0.893 0.005
0.883 0.005
0.779 0.005
0.835 0.002
0.893 0.001
0.907 0.003
Stackexchess
0.890 0.009
0.869 0.008
0.847 0.009
0.751 0.016
0.852 0.008
0.877 0.013
0.903 0.008
In order to compare the relative performance of each algorithm, Friedman Test [48] is used to analyze the performance of multiple compare algorithms on twelve data sets. The Friedman statistic and the corresponding critical value of each evaluation metric are recorded in Table 9. According to the results in Table 9, at significance level 0.05, the null hypothesis that all the comparing algorithms perform equivalently is clearly rejected in terms of all the evaluation metrics.
Friedman Statistics ( 7, 12) in terms of each evaluation measure and the Critical Value. ( indicates the number of compare algorithms and indicates the number of data sets)
Metric
Critical Value ( 0.05)
Hamming Loss
7.6157
2.239
MicroF1 measure
34.0046
Average Precision
27.5837
One Error
16.1343
Ranking Loss
28.9748
Coverage
22.3725
AUC
21.5639
Then we continue to conduct a post-hoc Nemenyi test [48] to further verify whether our method LLFC achieves superior performance against other comparison algorithms. LLFC is regraded as the control algorithm, if the average ordering values of two methods differ by at least one CD value, there is a significant difference between the two methods. denotes critical value, at significance level 0.05, and thus we calculate the value of 2.5999 (7, 12), where is the number of compare algorithms and is the number of data sets. Figure 3 shows the CD diagrams of the LLFC method and all the comparison methods on each evaluation metric. In each sub-figure, if the difference between the average rank of any compared algorithm is within a CD, they will be connected by a red bold line. According to above experimental results, the following conclusions can be drawn:
Comparison of LLFC (control algorithm) against six compared algorithms with the Nemenyi test. Unconnected to LLFC(at 0.05) in CD graphs are thought to differ significantly from control algorithms.
As can be seen from the results in the Table 2 to Table 8, the proposed method LLFC ranks first in terms of MicroF1 measure and Average Precision except on the Stackex_chess data set. And it also ranks first in terms of Ranking Loss and Coverage except on the corel5k data set. In addition, the result of LLFC in terms of MicroF1 measure is 1%–2% higher than other comparison algorithms over the rcv1subset1 to rcv1subset3 three data sets.
According to the Fig. 3, the proposed method LLFC is significantly better than CLMLC, MLKNN and GLOCAL, and statistically better than other comparing algorithms in terms of all evaluation metrics. The excellent performance of LLFC against MLKNN and JFSC shows that modeling label correlations is helpful to improve the performance of multi-label learning, especially on modeling local label correlations.
GLOCAL exploits local and global label correlations for multi-label learning. LSF-CI models both the label correlations in the label space and the instance correlations in the feature space, which considers the global information in the label and feature space. ML-LSS is a multi-label learning method with local instance similarity, which takes into account the local similarity in the feature space. The better performance of LLFC against them demonstrates that modeling local feature and label correlations and learning different classifiers for different subsets can improve the performance of multi-label learning.
CLMLC learns a multi-label classifier for each data group, but it does not model the consistency between different classifiers and only selects the nearest classifier to predict test instances. The better performance of LLFC against CLMLC validates the effectiveness of modeling the consistency among classifiers corresponding to different groups and selecting multiple classifiers for label prediction of test data.
Parameter sensitivity analysis
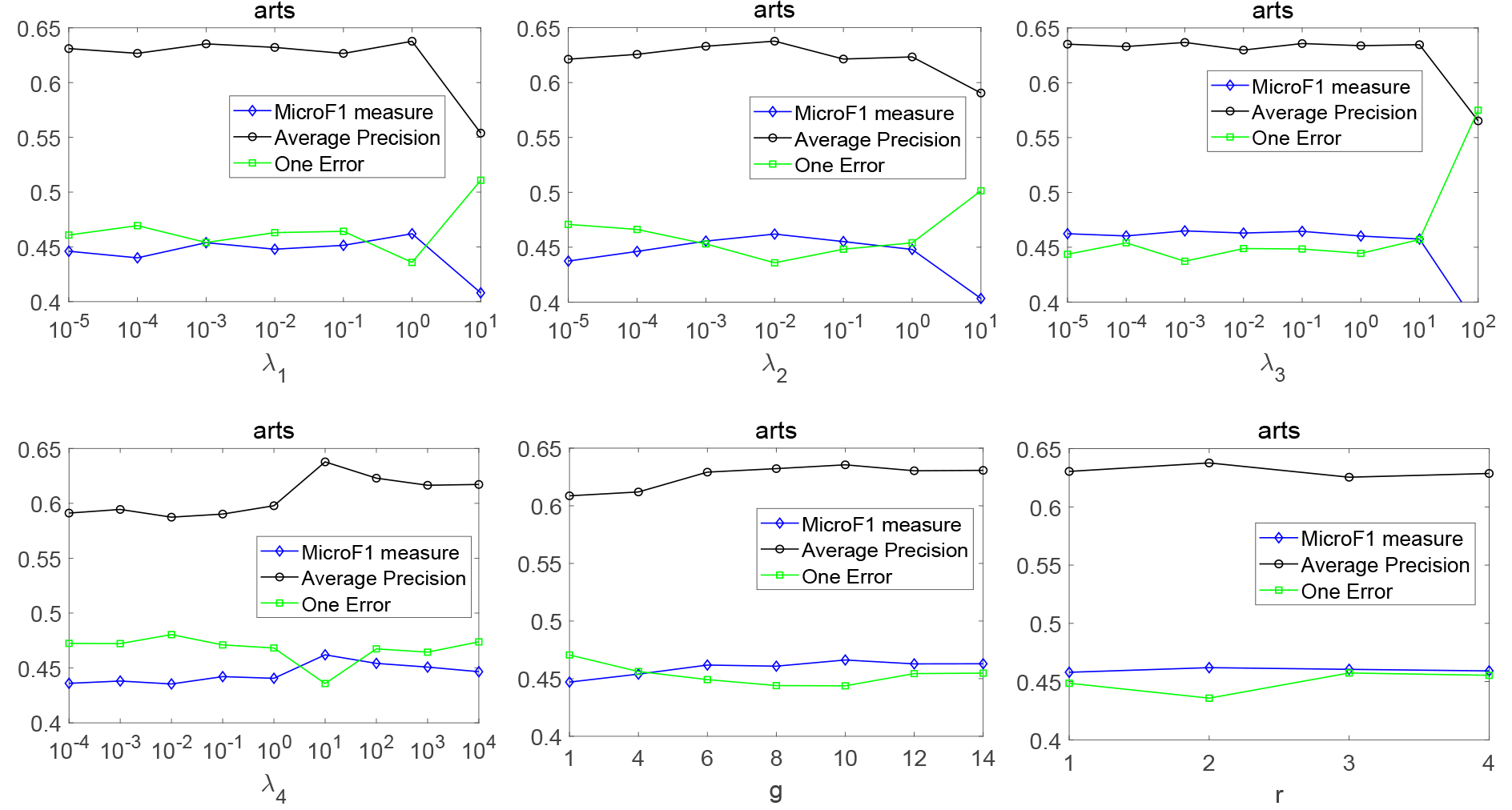
In this section, we study the sensitiveness of parameters and on LLFC, in which parameter is used to control local label correlations, is used to control local feature correlations, is used to control the model complexity, is used to control the number of groups and is used to control the number of classifiers selected for model prediction. In this experiment, three evaluation metrics Average Precision, MicroF1 measure and One Error are selected to study parameter sensitivity on the arts data set. All parameters are analyzed according to the parameter settings in Section 4.1.2. Figure 4 shows the results of LLFC with different parameter settings.
Parameter sensitivity analysis of LLFC over arts data set.
As can be seen from Fig. 4, the performance gradually increases and then decreases with the increasing of and . Therefore, the local label correlations and local feature correlations can improve the performance of the model. With the increasing of , the performance of the model is improved to a certain extent. When is too large, it may pay too much attention to the control of model complexity and ignore the training of the model, so the performance of the model is greatly reduced. The optimal performance is obtained when is the intermediate value, which means that it is helpful to consider the consistency between different models for the data groups. The performance of LLFC is improved with the increasing of . When 1, it means that there is no grouping and the global label and feature correlations are considered. However, when is too large, the number of instances and labels in the data subset may be too small to obtain reliable correlations, resulting in performance degradation. With the increase of , the performance is improved, which shows that the performance can be improved by integrating the prediction results of different models.
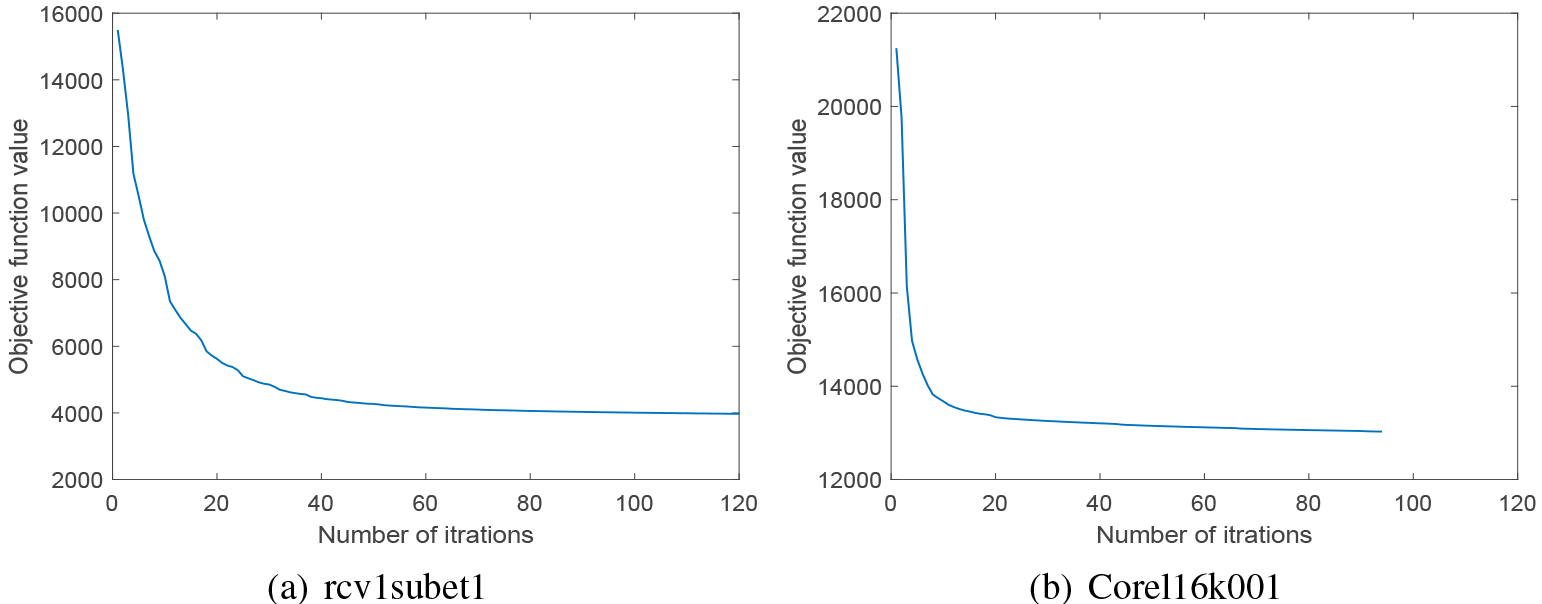
Convergence analysis
The convergence curves of our proposed method LLFC over the Corel6k001 and rcv1subset1 two data sets are shown in Fig. 5. It can be seen that the value of the objective function drops quickly and then is non-increasing.
The running time (Sec.) costs of different algorithms,which include training and testing time
Dataset
LSF-CI
ML-LSS
GLOCAL
CLMLC
MLKNN
JFSC
LLFC
yeast
1.204
1.924
1.415
0.322
3.978
0.466
0.631
arts
11.752
21.132
9.396
0.927
18.638
20.261
11.584
corel5k
23.509
292.430
63.591
4.186
4.711
37.954
40.389
rcv1subset1
34.760
356.157
70.644
1.960
3.738
58.225
20.699
Corel16k001
93.196
713.302
70.782
7.012
14.610
155.948
64.033
Corel16k002
93.629
738.478
79.594
7.628
15.059
157.004
91.827
Stackexcs
71.449
736.370
94.520
9.669
9.729
105.948
77.116
Average time(rank)
47.071(4)
408.542(7)
55.706(5)
4.529(1)
10.066(2)
76.544(6)
43.754(3)
Convergence curves of the objective function value on two data sets.
Running time analysis
In this paper, the running time (including training and testing) of each algorithm on seven data sets is reported to show the efficiency of LLFC. All the algorithms are run under the same experimental environment, and the results are shown in Table 10. According to the results, LLFC ranks the third place, achieves comparable results with LSF-CI and GLOCAL, is slower than CLMLC and MLKNN, and significantly faster than ML-LSS and JFSC algorithms. That because CLMLC does not directly calculate the correlation of labels and features, and MLKNN does not consider any correlation and does not need any iterative process during the training model. ML-LSS takes a lot of time to calculate local sample correlations based on the feature of maximum label dependence. Although LLFC ranks the third place, and it achieves the best performance in multi-label classification.
Conclusion
In this paper, a new multi-label learning algorithm which models local label correlations and local feature correlations is proposed. The training data is divided into disjoint groups by a clustering method, and then the multi-label classifiers, the local label and feature correlations are modeled based on each data subset respectively. In addition, we model the consistency between different classifier for the data subsets. During the testing phase, prediction results of multiple classifiers are integrated together as the final prediction result. A large number of experimental results show that the proposed method is superior to many existing multi-label classification methods.
Footnotes
Acknowledgments
This work is supported by NSFC: 61806005, the University Synergy Innovation Program of Anhui Province: GXXT-2022-052, the Outstanding Young Talents Support project of Anhui Province: gxyqZD2022032, and the Natural Science Foundation of the Educational Commission of Anhui Province of China: KJ2021A0373.
References
1.
ZhangM. and ZhouZ., A Review On Multi-Label Learning Algorithms, IEEE Trans. Knowl. Data Eng.26(8) (2014), 1819–1837.
2.
HeZ.WuJ. and LvP., Multi-label text classification based on the label correlation mixture model, Intelligent Data Analysis21(6) (2017), 1371–1392.
3.
AlmeidaA.M.G.CerriR.ParaisoE.C.MantovaniR.G. and JuniorS.B., Applying multi-label techniques in emotion identification of short texts, Neurocomputing320 (2018), 35–46. doi: 10.1016/j.neucom.2018.08.053.
4.
ZhaD. and LiC., Multi-label dataless text classification with topic modeling, Knowledge and Information Systems61(1) (2019), 137–160.
5.
LiY.SongY. and LuoJ., Improving pairwise ranking for multilabel image classification, in: CVPR, 2017, pp. 1837–1845.
6.
TanM.ShiQ.van den HengelA.ShenC.GaoJ.HuF. and ZhangZ., Learning Graph Structure for Multi-Label Image Classification via Clique Generation, in: CVPR, 2015, pp. 4100–4109.
7.
SunF.TangJ.LiH.QiG.-J. and HuangT.S., Multi-Label Image Categorization With Sparse Factor Representation, IEEE Transactions on Image Processing23(3) (2014), 1028–1037. doi: 10.1109/TIP.2014.2298978.
8.
WuB.ZhongE.HornerA. and YangQ., Music Emotion Recognition by Multi-Label Multi-Layer Multi-Instance Multi-View Learning, in: ACM, 2014, pp. 117–126.
9.
Alzu’biS.BadarnehO.HawashinB.Al-AyyoubM.AlhindawiN. and JararwehY., Multi-label emotion classification for arabic tweets, in: SNAMS, 2019, pp. 499–504. doi: 10.1109/SNAMS.2019.8931715.
10.
ZuffereyD.HoferT.HennebertJ.SchumacherM.IngoldR. and BromuriS., Performance comparison of multi-label learning algorithms on clinical data for chronic diseases, Computers in Biology and Medicine65 (2015), 34–43.
11.
HuangM.HanH.WangH.LiL.ZhangY. and BhattiU.A., A Clinical Decision Support Framework for Heterogeneous Data Sources, IEEE Journal of Biomedical and Health Informatics22(6) (2018), 1824–1833. doi: 10.1109/JBHI.2018.2846626.
12.
BoutellM.R.LuoJ.ShenX. and BrownC.M., Learning multi-label scene classification, Pattern Recognit.37(9) (2004), 1757–1771.
13.
TsoumakasG.KatakisI. and VlahavasI., Mining Multi-label Data, in: Data Mining and Knowledge Discovery Handbook, Springer US, 2010, pp. 667–685.
14.
HuangJ.LiG.HuangQ. and WuX., Learning Label Specific Features for Multi-Label Classification, in: ICDM, 2015, pp. 181–190.
15.
HanH.HuangM.ZhangY.YangX. and FengW., Multi-Label Learning With Label Specific Features Using Correlation Information, IEEE Access7 (2019), 11474–11484. doi: 10.1109/ACCESS.2019.2891611.
16.
ZhangJ.LiC.CaoD.LinY.SuS.DaiL. and LiS., Multi-label learning with label-specific features by resolving label correlations, Knowledge-Based Systems159 (2018), 148–157.
17.
WuG.TianY. and LiuD., Cost-sensitive multi-label learning with positive and negative label pairwise correlations, Neural Networks108 (2018), 411–423. doi: 10.1016/j.neunet.2018.09.003.
18.
XuL.WangZ.ShenZ.WangY. and ChenE., Learning Low-Rank Label Correlations for Multi-label Classification with Missing Labels, in: IEEE International Conference on Data Mining (ICDM), 2014, pp. 1067–1072. doi: 10.1109/ICDM.2014.125.
19.
HuangJ.LiG.HuangQ. and WuX., Joint Feature Selection and Classification for Multilabel Learning, IEEE Trans. Cybern.48(3) (2018), 876–889.
20.
ZhangJ.LinY.JiangM.LiS.TangY. and TanK.C., Multi-label feature selection via global relevance and redundancy optimization, in: IJCAIBessiereC., ed., 2020, pp. 2512–2518.
21.
WangY.ZhengW.ChengY. and ZhaoD., Joint label completion and label-specific features for multi-label learning algorithm, Soft Computing24(9) (2020), 6553–6569.
22.
JiaX.-Y.ZhuS.-S. and LiW.-W., Joint label-specific features and correlation information for multi-label learning, Computer Science and Technology35(2) (2020), 247–258.
23.
HuangJ.LiG.WangS.XueZ. and HuangQ., Multi-label classification by exploiting local positive and negative pairwise label correlation, Neurocomputing257 (2017), 164–174.
24.
HuangS.-J. and ZhouZ.-H., Multi-Label Learning by Exploiting Label Correlations Locally, in: Proc. AAAI Conf. Artif. Intell, 2012, pp. 949–955.
25.
LingY.WangY.WangX. and LingY., Exploring Common and Label-Specific Features for Multi-Label Learning With Local Label Correlations, IEEE Access8 (2020), 50969–50982. doi: 10.1109/ACCESS.2020.2980219.
26.
ZhuY.KwokJ.T. and ZhouZ., Multi-Label Learning with Global and Local Label Correlation, IEEE Trans. Knowl. Data Eng.30(6) (2018), 1081–1094.
27.
WengW.LinY.WuS.LiY. and KangY., Multi-label learning based on label-specific features and local pairwise label correlation, Neurocomputing273 (2018), 385–394. doi: 10.1016/j.neucom.2017.07.044.
28.
ZhangJ.LuoZ.LiC.ZhouC. and LiS., Manifold regularized discriminative feature selection for multi-label learning, Pattern Recognition95 (2019), 136–150. doi: 10.1016/j.patcog.2019.06.003.
29.
HuJ.LiY.GaoW. and ZhangP., Robust multi-label feature selection with dual-graph regularization, Knowledge-Based Systems203 (2020), 106126. doi: 10.1016/j.knosys.2020.106126.
30.
CaiZ. and ZhuW., Multi-label feature selection via feature manifold learning and sparsity regularization, Int. J. Mach. Learn. Cybern.9 (2018), 1321–1334.
31.
JiangL.YuG.GuoM. and WangJ., Feature selection with missing labels based on label compression and local feature correlation, Neurocomputing395 (2020), 95–106.
32.
SunL.KudoM. and KimuraK., A scalable clustering-based local multi-label classification method, in: Proceedings of the Twenty-Second European Conference on Artificial Intelligence(ECAI), 2016, pp. 261–268.
33.
NasierdingG.TsoumakasG. and KouzaniA.Z., Clustering based multi-label classification for image annotation and retrieval, in: 2009 IEEE International Conference on Systems, Man and Cybernetics, 2009, pp. 4514–4519. doi: 10.1109/ICSMC.2009.5346902.
34.
ZhouZ.-H. and ZhangM.-L., Multi-label Learning, in: Encyclopedia of Machine Learning and Data Mining, Springer US, 2017, pp. 875–881.
35.
ZhangM.-L. and WuL., Lift: Multi-Label Learning with Label-Specific Features, IEEE Transactions on Pattern Analysis and Machine Intelligence37(1) (2015), 107–120. doi: 10.1109/TPAMI.2014.2339815.
36.
ZhangM. and ZhouZ., ML-kNN: A Lazy Learning Approach to Multi-Label Learning, Pattern Recognit.40(7) (2007), 2038–2048.
37.
ElisseeffA. and JasonW., A kernel method for multi-labelled classification, in: NIPS, 2001, pp. 681–687.
38.
FürnkranzJ.HüllermeierE.Loza menciaE. and BrinkerK., Multi-label classification via calibrated label ranking, Machine Learning73(2) (2008), 133–153.
39.
GongC.TaoD.YangJ. and LiuW., Teaching-to-Learn and Learning-to-Teach for Multi-label Propagation, in: AAAI, 2016, pp. 1610–1616.
40.
HuangJ.LiG.HuangQ. and WuX., Learning Label-Specific Features and Class-Dependent Labels for Multi-Label Classification, IEEE Trans. Knowl. Data Eng.28(12) (2016), 3309–3323.
41.
ZhangM. and ZhangK., Multi-label Learning by Exploiting Label Dependency, in: KDD, 2010, pp. 999–1008.
42.
FengL.AnB. and HeS., Collaboration based multi-label learning, in: AAAI, 2019, pp. 3550–3557.
43.
TsoumakasG.KatakisI. and VlahavasL., Random k-Labelsets for Multilabel Classification, IEEE Trans. Knowl. Data Eng.23(7) (2011), 1079–1089.
44.
ReadJ.PfahringerB.HolmesG. and FrankE., Classifier Chains for Multi-label Classification, in: ECML, 2009, pp. 254–269.
45.
ChengZ. and ZengZ., Joint label-specific features and label correlation for multi-label learning with missing label, Applied Intelligence50 (2020), 4029–4049.
46.
ZhuW.LiW. and JiaX., Multi-Label Learning with Local Similarity of Samples, in: 2020 International Joint Conference on Neural Networks (IJCNN), 2020, pp. 1–8. doi: 10.1109/IJCNN48605.2020.9207692.
47.
BertsekasD.P., Nonlinear Programming, Journal of the Operational Research Society48(3) (1997), 334–334. doi: 10.1057/palgrave.jors.2600425.
48.
DemšarJ., Statistical Comparisons of Classifiers over Multiple Data Sets, JMLR7 (2006), 1–30.