
Abstract
As a supervised learning algorithm, Support Vector Machine (SVM) is very popularly used for classification. However, the traditional SVM is error-prone because of easy to fall into local optimal solution. To overcome the problem, a new SVM algorithm based on Relief algorithm and particle swarm optimization-genetic algorithm (Relief-PGS) is proposed for feature selection and data classification, where the penalty factor and kernel function of SVM and the extracted feature of Relief algorithm are encoded as the particles of particle swarm optimization-genetic algorithm (PSO-GA) and optimized by iteratively searching for optimal subset of features. To evaluate the quality of features, Relief algorithm is used to screen the feature set to reduce the irrelevant features and effectively select the feature subset from multiple attributes. The advantage of Relief-PGS algorithm is that it can optimize both feature subset selection and SVM parameters including the penalty factor and the kernel parameter simultaneously. Numerical experimental results indicated that the classification accuracy and efficiency of Relief-PGS are superior to those of other algorithms including traditional SVM, PSO-GA-SVM, Relief-SVM, ACO-SVM, etc.
Keywords
Introduction
Data classification is crucial in data mining, cluster analysis and intelligent information processing. The target of classification is to establish a model based on the feature of the number dataset, which can predict unknown samples categories to one of the given categories [1]. As a fundamental supervised learning method, the support vector machines (SVM) is widely used in text recognition, image recognition etc [2, 3, 4]. The principle of SVM is to maximize the difference between different types of data by constructing a classification hyperplane as a decision surface [5], which is considered to be an effective method to avoid local optimum and has unique advantages in dealing with complex problems such as limited samples, high dimensional and nonlinear data.
As a popular machine learning method, the performance of SVM in convergence, speed, and accuracy of training and classification is is affected by the selection of the penalty factor
Due to the limitations of individual intelligent algorithms, the combination intelligent algorithms to accelerate the optimization process of SVM is presented in recent years, such as PSO-GA [21], GA-WOA [22], FA-PSO [23], NN-GA [24], etc. Among the nature-inspired algorithms, PSO-GA is popular algorithms. Liu et al. [25] proposed an SVM algorithm combining genetic algorithm and particle swarm algorithm to optimize the parameters of the five-parameter model. Huang et al. [26] introduced three algorithms including PSO, GA and grid-search algorithm to obtain the parameters of Radial Basis Function (RBF) kernels of SVM. Cui et al. [27] presented a novel method coupling a modified PSO algorithm with GA-SVM algorithm to optimize the kernel parameters of SVM. Bonah et al. [28] optimized SVM parameters based on genetic algorithms (GA), grid search (GS) algorithms and particle swarm optimization (PSO) to improve classification accuracy of spectral data. Optimizing the performance of the SVM can take into account optimizing subset of features, which can improve the robustness of the model and the speed of convergence.
Since the original feature contains a large amount of redundant information, it is necessary to reduce irrelevant features during training can accelerate classification process of SVM [29]. Relief algorithm is a multivariate filtering feature weighting and selection algorithm [30], which calculates the weight of the feature vector based on sample learning [31, 32]. The Relief-SVM consists of feature selection based on Relief algorithm and SVM classification method. The advantage of Relief-SVM method lies in that it can identify optimal features and construct optimal classifiers, which results in the increase of the classification accuracy and the decrease of the classification time [33]. However, it can not completely remove irrelevant and redundant features, which may not contribute to the performance for feature extraction problems.
To solve the problem that the existing methods are not suitable for optimizing feature subset selection and SVM parameters at the same time, a new SVM algorithm based on Relief algorithm and particle swarm optimization-genetic algorithm (Relief-PGS) is proposed to improve the classification potential of SVM. The main contributions of this paper include as follows. (1) A new effective hybrid method based on particle swarm optimization and genetic algorithm (PSO-GA) is proposed for feature selection and parameter optimization of SVM. (2) The feature subset screened by Relief algorithm and SVM parameters were encoded into the PGS algorithm for quadratic feature filtering to optimize the number of features and improve the classification accuracy of SVM. (3) The Relief-PGS algorithm can optimize both feature subset selection and SVM parameters simultaneously. (4) The efficiency and effectiveness of the proposed Relief-PGS are demonstrated by experimental results.
The remainder of the paper is organized as follow. Related works about the SVM algorithms are introduced in Section 2. In Section 3, some basic theories about Relief, PSO and GA algorithms are introduced. In Section 4, the proposed Relief-PGS algorithm is introduced. In Section 5, various kinds of experiments are conducted to evaluate the performance of the proposed algorithm under varying datasets. Finally, the conclusions are made in Section 6.
Related works
Support vector machine (SVM) is a classification method based on the principle of structural risk minimization [34, 35]. It is an effective method to avoid local optimum and has unique advantages in dealing with complex problems such as limited samples, high dimensional and nonlinear data. The performance of SVM is highly related to its kernel parameters and penalty factor, and the key to improve the classification accuracy is to select the appropriate parameters. SVM are sensitive to parameter conditioning and the choice of sum functions, and suitable for handling binary classification problems if left unmodified. Using intelligent algorithms to optimize the penalty factor C and kernel parameter
Most of the methods can only individually optimize either feature subset selection or SVM parameters, greatly limiting the classification potential of SVM. In recent years, many scholars have proposed new algorithms for simultaneous optimization of feature selection and data classification [42]. Mehdi et al. [43] introduced a new intrusion detection method, which uses genetic algorithm to optimize SVM and particle swarm optimization algorithm to select the most influential features to learn classification model. Dinesh et al. [44] proposed the KPCA-GA-SVM feature classification optimization model, which improved the classification accuracy based on the selected relevant features. Bi et al. [45] presented a novel hybrid genetic algorithm-particle swarm optimization (GA-PSO) method to optimize the SVM model. The optimization process and result demonstrated that the GA-PSO-SVM method was more accurate and time-saving than the classical GA and PSO method. Compared with the classical Grid-search SVM, the combined GA-PSO-SVM model appeared to be more applicable for the property prediction.
In general, redundant features complicate the operation and reduce the processing speed, which may lead to a reduction in classification accuracy. Thus, it is necessary to select features that have a greater role in classification recognition. In order to improve the accuracy of the classification, Wang [46] introduced a fast Relief algorithm to compute the training sample weight values for the optimization of SVM kernel function in content-based image retrieval systems. Zhang et al. [47] proposed to use denoising features of Relief algorithm combined with mixed kernel function to optimize SVM model. Choi et al. [48] presented a relieve-based de-noising feature to extract relevant features from rough tablet surfaces. Dou et al. [49] introduced a Relief-SVM method, which is used to recognize coal and gangue based on image analysis. The Relief-SVM method presented in the study is proven to be effective in the aforementioned types of complex situations.
Based on the existing research work, we propose an Relief-PGS algorithm to solve the feature selection and data classification problem in terms of both feature subset and parameter optimization, and shows its superiority over other algorithms.
Preliminaries
SVM model
SVM is a classification algorithm based on statistical learning theory. The principle of SVM is to construct an optimal hyperplane as a decision surface by a small set of vectors near boundary and divide the data points of different categories in the vector space. When the problem is the linearly separable, the optimal decision surface needs to satisfy the condition that the samples can be separated and the classification interval is maximized. When the problem is linear inseparable, it is need to search for a multi-dimensional hyperplane to separate the samples. Thus, SVM solves the problems of traditional learning methods, such as nonlinearity, over learning, high dimension, local minima, etc.
A theoretical assumption for SVM algorithm is that there are data set
where
For some data that cannot be separated in linear space, SVM maps the data into high-dimensional linear space through the nonlinear equation of the kernel function to make the data separable. The function
where
The selection of kernel parameters is very important for SVM classifiers because it has significant impact on the learning ability of the SVM methods. The kernel parameters commonly used in SVM include linear, ploy kernel function, RBF and sigmoid functions, etc. In this paper, the radial basis kernel parameters are selected as the kernel parameters of SVM. The RBF kernel parameters of SVM are given as
where
Particle swarm optimization (PSO) is an evolutionary computing technology inspired by the population behavior of birds, where each bird in the flocks is considered as one of the particles and each individual particle represents a possible potential optimal solution.
The basic principle of the PSO algorithm is described as follows. First, it can be assumed that a population consists of m particles in an S-dimensional target search space, where the i-th particle represents an s-dimensional vector
The particles of PSO algorithm can be manipulated by
where
Genetic Algorithm (GA) is an intelligent computational method, which is designed by the laws of biological evolution and genetic mechanisms of organisms in nature. GA consists of selection, crossover and variation. GA does not need to derive the structural object and limit the continuity of the function. It can perform a series of operations directly on the structural object, so that the better global optimization ability can be obtained.
The core idea of GA is given as follows. First, a parent population is randomly obtained and the fitness value of individual in the parent population is calculated. Then,
Relief algorithm
Relief algorithm is a feature weight selection algorithm, which determines the retaining of the feature as the weight of each feature. Generally, it is suitable for big data samples. The Relief algorithm is a feature filtering method by calculating feature weights. Its principle is to assign different weights to each feature on the correlation between every feature and category and delete the feature when the weight of the feature is smaller than the threshold. The Hypothesis-Margin is used to judge the classification precision using feature dimensions. It refers to the distance that the classifier can move without changing the classification results of any sample points, which can be defined as
where
For the Relief algorithm, insufficient parameter features can lead to misclassification of sample categories and redundant parameters can lead to wasted computational effort. To solve this problem, the Relief algorithm associates data features with categories, and selects some features related for classification.
The calculation of the weight for Relief algorithm is
where
The procedure of Relief algorithm is given as follows.
Step 1: initialize all feature weights of the sample and set it to 0.
Step 2: randomly select a sample
Step 3: calculate the distance
Step 4: repeat step 2 for
Step 5: Sort the features according to the weights and select several dimensional features with larger weights.
PSO-GA optimization method
PSO and GA are swarm intelligence algorithms, which are widely used in various optimization problems. When PSO or GA individually optimize the parameters of SVM, it is found that the classification accuracy is not satisfactory and the classification accuracy is instability. For PSO algorithm, the flight speed and direction can be obtained by comparing the optimal position of the particle in the flight history. However, the lack of non-linear factor adjustment causes the problem that it is easy to fall into the local optimal solution in the latter part of the iteration and the global optimal solution cannot be obtained. For GA method, the global search and population diversity [51] is excellent. However, the coding and decoding process increases the complexity of calculation. Meanwhile, the GA needs to complete three operations in a loop, which results in the fact that the computational efficiency and convergence speed of GA algorithm are limited. Therefore, it is necessary to improve the efficiency of optimization process for GA algorithm.
To improve the classification accuracy of SVM, a hybrid PSO-GA optimization method is employed for the parameter selection of SVM. The PSO-GA algorithm uses the PSO algorithm to replace the GA algorithm’s selection operator, which accelerates the convergence speed of the PSO-GA algorithm and ensures the diversity of the GA [52]. The key step in the PSO-GA algorithm is that the process of selecting particles in GA is replaced by PSO, which means that appropriate individual particles have been searched in PSO and the GA employs the crossover and mutation to improve the ability of parameter optimization.
The procedure of PSO-GA algorithm is presented as follows.
Step 1: Initialize all parameters of PSO-GA algorithm, including acceleration factor, weights, number of iterations, etc.
Step 2: Update particle position and velocity in PSO.
Step 3: Calculate the fitness value of each particle and sort the individual as the fitness value.
Step 4: Select
Step 5: Cross and mutate individual particles to obtain the diversity of individual.
Step 6: Synthetic the new particle swarm. Update the optimal individual and group until the maximum number of iterations are reached.
The flowchart of PSO-GA algorithm is shown in Fig. 1.
PSO-GA algorithm.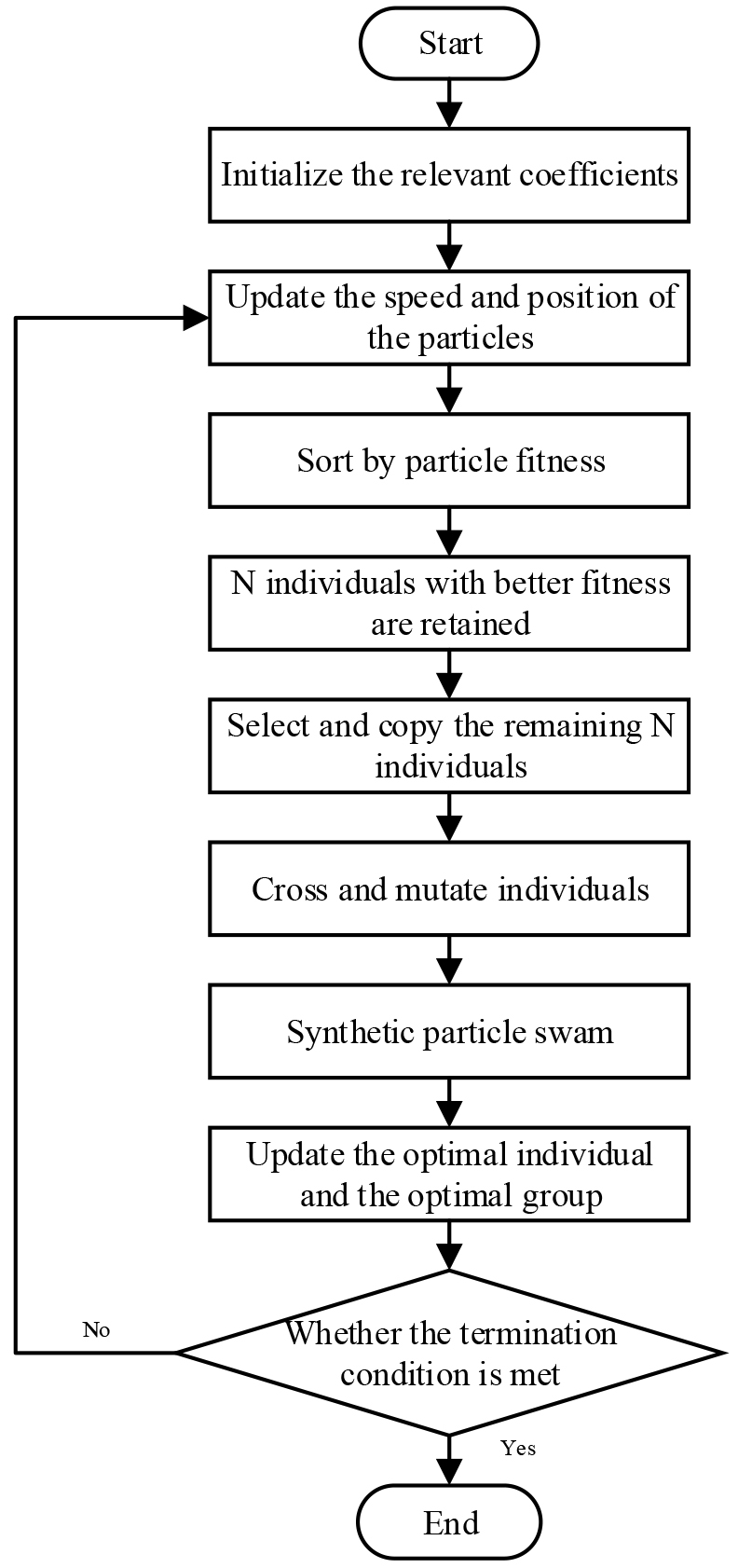
Relief-PGS algorithm.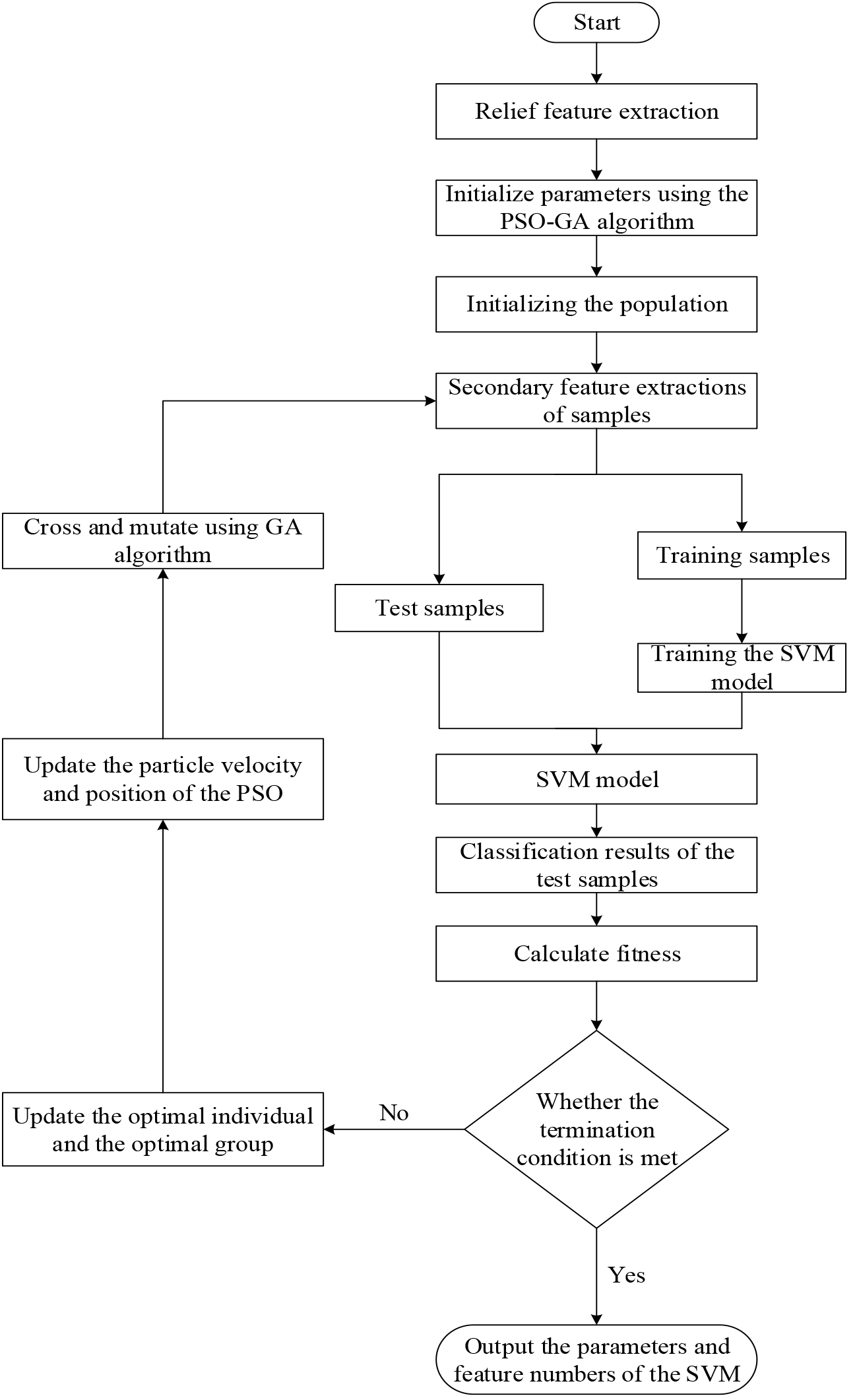
The efficiency and effectiveness of SVM are determined by the selected feature numbers and the parameter of SVM including penalty factor and kernel parameters. The increase of related features can accelerate the classification speed, and appropriate kernel function can improve the ability of SVM to process nonlinear characteristic data of high-dimensional feature space in classification problems. Since the penalty factor and the kernel function are crucial for the classification accuracy and generalization ability of the SVM algorithm the radial basis function (RBF) kernel is selected as kernel function the generalization ability of SVM.
Generally, there is a coupling relationship between the number of input feature subsets and the optimal parameters of SVM. If the number of the input feature subset is changed, it will affect the optimization of the parameters of SVM. If the parameters of SVM is changed, it will also affect the number of the input feature subset. A Relief-PGS algorithm is proposed to reduce the input feature subset and optimize the kernel parameter. In order to speed up training process, the Relief algorithm is used to delete the irrelated features and reduce feature dimension. Meanwhile, the penalty factor and kernel parameters of SVM and the selected feature subsets are encoded into the chromosome of PSO-GA. Since the penalty coefficient C and the kernel parameter
The fitness function is uniformly defined as follow:
where
The procedure of Relief-PGS algorithm is presented as follows.
Step 1: Perform a feature extraction on the data features using the Relief algorithm to obtain a feature matrix.
Step 2: Initialize the parameters of PSO-GA algorithm including the size of the population and the number of iterations. Set the termination condition of Relief-PGS algorithm as follows:
where
Step 3: Generate the first-generation population. The penalty coefficient C and the kernel parameter
where
Step 4: Run Step 5 to Step 11 until the termination condition is satisfied, and output the parameters and feature numbers of SVM.
Step 5: Add the first N digits of the individual into the sample for secondary screening of features.
Step 6: Add the last two digits of the individual into the SVM model and determine the SVM classification model considering the training samples of the secondary screening.
Step 7: Add the second screened testing samples into the SVM classification model to obtain the classification result.
Step 8: Calculate the fitness value of the first-generation population.
Step 9: Update the optimal individual and the optimal group.
Step 10: Update the speed and position of the individual according to the fitness of the first-generation population. Add a constraint factor
Step 11: Add the population updated by the PSO algorithm into GA algorithm Obtain a new population after a crossover and a mutation of GA algorithm, then go to Step 5. The crossover probability of GA algorithm can be defined as
where
where
The flowchart of Relief-PGS algorithm is presented in Fig. 2.
The pseudo code is is illustrated in the following steps.
Experimental environment and parameter settings
In order to verify the validity of the algorithm, a common UCI database was used in the experiments [54]. The basic information of the experimental data set is illustrated in Table 1. All the classifiers are implemented in MATLAB R2015a on a PC with Inter (R) Core (TM) CPU and 4GB RAM.
The setup of the experimental data set
The setup of the experimental data set
To improve the classification accuracy of SVM, the selected data samples were required to be normalized, and then the data were subdivided into training sample sets and test sample sets. In order to compare the classification results of SVM parameters, the initial condition of GA, PSO and PSO-GA are given as: the population size is 30, the length of the population is 2, the iterative times is 50. The crossover probability and mutation probability of GA are adjusted according to the fitness.
For PSO-SVM and GA-SVM algorithm, the population size is 30, the length of the population is 2 and the iterative number is 500. The crossover probability and mutation probability of GA are adjusted by the fitness. The weight parameter
The experimental results of PSO-SVM, GA-SVM and PSO-GA-SVM
The experimental results of PSO-SVM, GA-SVM and PSO-GA-SVM
Table 2 illustrates that the classification accuracy of PGS algorithm is higher than that of GA-SVM and PSO-SVM. It is because PSO-GA algorithm combines fast convergence speed of PSO and strong global research ability of GA to optimize the penalty factor and kernel coefficient of the SVM.
To verify the validity of the Relief-PGS algorithm, the classification results of the Relief-PGS, SVM, PSO-GA-SVM (PGS), Relief-SVM and ant colony optimization-SVM (ACO-SVM) algorithms are compared. The sample size and the number of feature subsets are shown in Table 3. The iteration number is set to be 500. For PGS-SVM, the PSO-GA algorithm is operated to obtain SVM hyperparameters to improve classification accuracy. The Relief algorithm is used to reduce features with small impact factors to improve the classification. In the ACO-SVM algorithm, the ACO algorithm is used to optimize SVM hyperparameters to improve classification accuracy.
Table 4 and and Fig. 3 compare classification accuracy of different algorithms. It can be observed that the classification accuracy of Relief-PGS is the highest for various experimental datasets, which displays the feasibility and effectiveness of the proposed algorithm. This is because the weights of relevant features are selected by Relief algorithm in the initial stage and the hyperparameters of SVM as particles are encoded into the PSO-GA algorithm for simultaneous optimization of the feature subsets and the parameters of the traditional SVM.
The number of optimized feature subsets
The number of optimized feature subsets
Classification accuracy of different algorithms
The training time of different algorithms for different datasets is compared in Table 5. As can be seen from Table 4, the average classification accuracy of parameters optimization based on the traditional SVM is 72.7987%. The average classification accuracy using the PGS optimization algorithm is 13.08% better than that of traditional SVM. The average classification accuracy using Relief-SVM optimization algorithm is 7.65% higher than that of traditional SVM. The highest classification accuracy is 88.5873%, which is obtained by the Relief-PGS algorithm. Compared with traditional SVM, the training time of Relief-SVM is reduced due to the selection of relevant feature subset by Relief algorithm. Compared with PGS and ACO-SVM, the Relief-PGS algorithm shortens the training time and speed up iteration. The training time of traditional SVM and Relief-SVM is superior to that of Relief-PGS, which owes to the multiple optimization of PSO-GA algorithm.
The training time of different algorithms (unit: second)
Classification accuracy of different algorithms.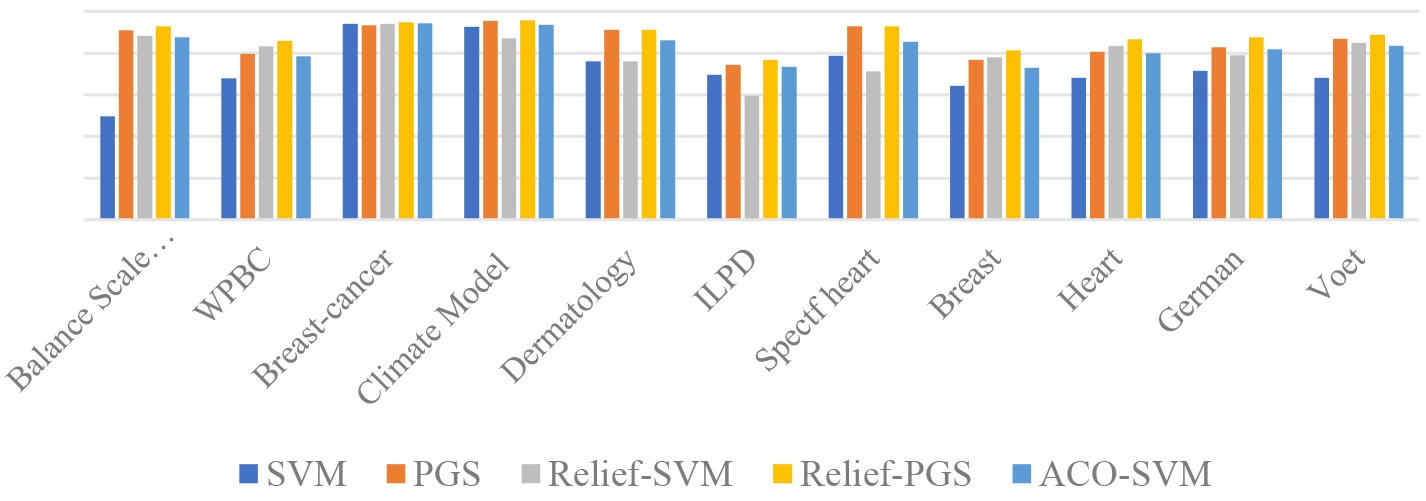
Optimal individual fitness of different algorithms in training process.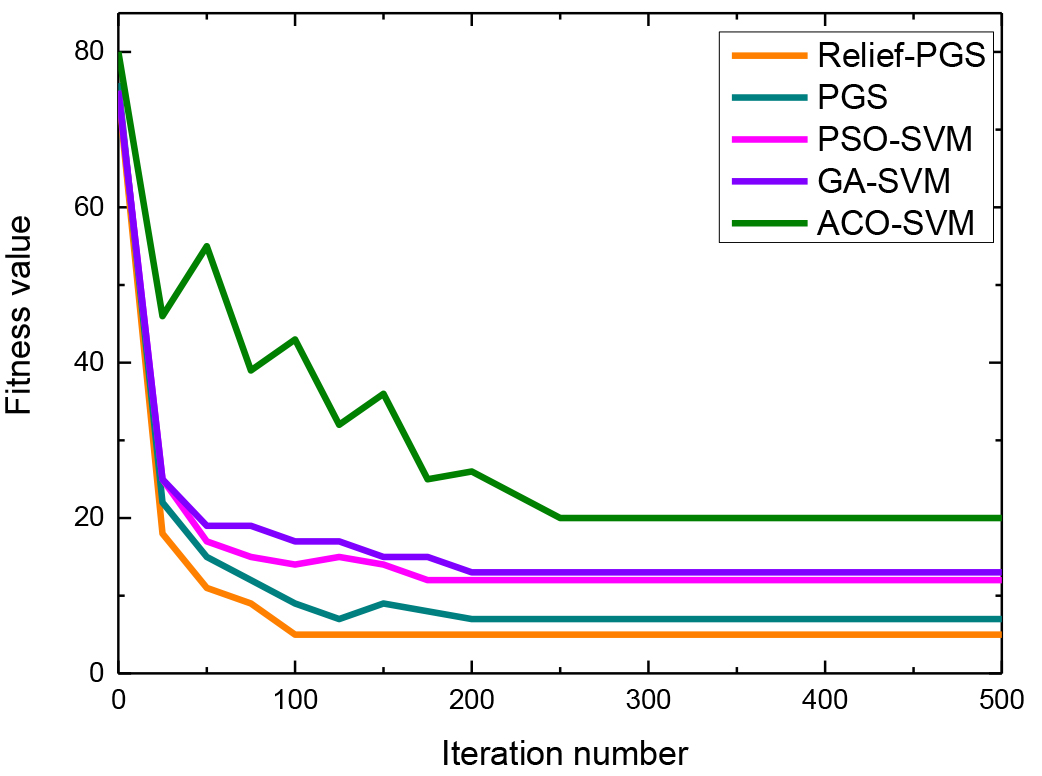
The optimal individual fitness of ACO-SVM, GA-SVM, PSO-SVM, PGS and Relief-PGS algorithms in the training process are shown in Fig. 4. The iteration number is 250, the ACO converges. The iteration number is 200, the GA converges. The number of iterations is 175, the PSO converges. It can be seen that the convergence rate of PSO is faster than GA and ACO in the early stage of algorithm iteration. The number of iterations is 100, the Relief-PGS algorithm converges. It can be concluded that the convergence rate of Relief-PGS algorithm is faster and the searched optimal solution is better than the other four algorithms.
Relief algorithm shortens the time of data selection process by decreasing the quantity of irrelevant features. The time complexity of the Relief algorithm to select features is
Conclusions
A Relief-PGS algorithm is put forword based on the feature selection of Relief algorithm and parameter optimization of SVM to select the input feature subset and kernel parameter, which encodes the feature subsets and the parameters of SVM into the PSO-GA as chromosome. The feature subset and the parameters of the SVM are optimized synchronously. Relief-PGS algorithm combines Relief algorithm, PSO-GA algorithm and SVM for feature selection and classification of datasets. The proposed algorithm of feature selection and parameter optimization can select the optimal feature subset and improve the classification accuracy by obtaining the optimal parameters and achieving better classification performance. Numerical experiments indicates that Relief-PGS algorithm obtains the better classification precision than other algorithms including traditional SVM, PSO-GA-SVM, ACO-SVM and Relief-SVM. It is promising that the proposed Relief-PGS algorithm can deal with the problem of complicated data classification, such as image detection, signal identification, etc.
Footnotes
Acknowledgments
This paper is supported by National Natural Science Foundation of China (Grant No. 51875457, 52105274), the Key Research and Development Program of Shaanxi Province of China (2022SF-259), and Xi’an science and technology plan project (22GXFW0128).