
Abstract
Illness diagnosis is the essential step in designating a treatment. Nowadays, Technological advancements in medical equipment can produce many features to describe breast cancer disease with more comprehensive and discriminant data. Based on the patient’s medical data, several data-driven models are proposed for breast cancer diagnosis using learning techniques such as naive Bayes, neural networks, and SVM. However, the models generated are hardly understandable, so doctors cannot interpret them. This work aims to study breast cancer diagnosis using the associative classification technique. It generates interpretable diagnosis models. In this work, an associative classification approach for breast cancer diagnosis based on the Discrete Equilibrium Optimization Algorithm (DEOA) named Discrete Equilibrium Optimization Algorithm for Associative Classification (DEOA-AC) is proposed. DEOA-AC aims to generate accurate and interpretable diagnosis rules directly from datasets. Firstly, all features in the dataset that contains continuous values are discretized. Secondly, for each class, a new dataset is created from the original dataset and contains only the chosen class’s instances. Finally, the new proposed DEOA is called for each new dataset to generate an optimal rule set. The DEOA-AC approach is evaluated on five well-known and recently used breast cancer datasets and compared with two recently proposed and three classical breast cancer diagnosis algorithms. The comparison results show that the proposed approach can generate more accurate and interpretable diagnosis models for breast cancer than other algorithms.
Keywords
Introduction
Breast cancer results from specific breast cells that multiply and form a mass called a tumor. The tumor is benign if its cells are normal, whereas it is malignant when the cells overgrow (cancerous cells). Breast cancer is the most diagnosed cancer and is the principal cause of death from cancer among women worldwide. In Canada, for example, one in eight women will develop breast cancer in her life, and one in thirty women will die from breast cancer. However, chances of recovery depend on the type of cancer and when it is detected. Currently, the essential thing in the medical field is the early diagnosis and detection of breast cancer that helps to cure it in the early stage. In China, early cancer detection makes about 30% of cancerous persons survive a long time [1]. Hence, early detection, diagnosis, and monitoring the women’s health are significant issues that must be considered carefully.
Over the past years, with the development of biomedical and electronic equipment on the one hand and the evolution of information technology, many data related to breast cancer disease have been collected and saved in large medical databases. Hence, the doctor cannot manually process this enormous amount of data to diagnose the presence or absence of cancer in women’s breasts, requiring computer-aided diagnosis. Besides, in recent years, researchers in computer science and especially in the data mining field have developed advanced techniques for discovering knowledge from data. This advancement motivates many researchers to develop reliable data mining methods applied to medical data. Because the Breast Cancer Diagnosis (BCD) serves to classify the tumor type into benign or malignant, it is considered a classification problem in several research works [2]. In recent years, several classification approaches have been developed and successfully applied to BCD problems, including Support Vector Machine (SVM) [3] and Deep Learning (DL) [4]. These methods generate black-box models that are not understandable by users. These methods only maximize the model’s classification accuracy. However, they overlook the models’ understandability or interpretability, which is very important in diagnosis. Especially in medical diagnosis, the doctors need to interpret their decisions because it concerns about a human’s life. Hence, the Associative Classification (AC) answers this concern by generating interpretable models. Then, it is very important to develop accurate AC models for BCD. The main contribution of this work is to propose a novel AC approach for generating accurate and interpretable BCD models employing a recent efficient optimization algorithm called Equilibrium Optimization Algorithm (EOA) [5]. In the proposed approach, the main measures, including the diagnosis models’ accuracy and interpretability, are considered evaluation metrics.
The outline of this paper is structured as follows. In the second section, we describe the AC task in data mining. The third Section presents a literature review of the BCD problem. In the fourth Section, we present this work’s research motivation and contributions. Section 5 describes the details of our approach. The experimental results and discussion are presented in Section 6. Finally, Section 7 concludes our research work.
Related works
In the last decades, BCD has been an active research area and has attracted researchers’ attention. Several new diagnosis approaches and models are proposed in the literature for the diagnosis in general and especially for medical diagnosis. In the literature, various data-driven and Machine learning (ML) classification methods have been proposed to generate accurate BCD models based on recorded clinical data. In this section, we summarize and classify BCD approaches. The classification algorithms investigated in BCD are categorized into two main categories: black-box and white-box classification algorithms. The first category includes SVM, Neural Network (NN), and DL approaches. The second category includes the algorithms based on Decision Trees (DT) and AC or rule-based classifiers.
Black-box classification approaches
Many researchers for BCD have introduced NN methods. The authors in [9] used a multilayer perception with retro-propagation to classify breast cancer, and the model generated has an accuracy of 96.21%. In 2009, Murat [10] proposed a BCD system based on association rules and NN. It proposed a NN architecture for the classification, which contains only one hidden layer in addition to input and output layers. However, the ARs are used to reduce the dimensionality of the datasets. The proposed system obtains an accuracy of 95%. Alkim et al. [11] proposed a fast and adaptive BCD system called learning vector quantization artificial NNs, which considerably reduces the diagnosis decision time. In 2016, Zribi and Boujelbene [12] used the NN with an incremental learning algorithm for BCD. This approach was compared with previous algorithms. It obtains a model with an accuracy of 99.95% over the Wisconsin breast cancer dataset
As another data-driven classification technique, SVM has been widely used for medical diagnosis because of its capability to handle high-dimensional data. In recent years, SVM has attracted the most attention from researchers in the BCD field [13]. Liu et al. [14] applied SVM for clinic BCD in 2003. The SVM method is compared with the NN method and several other machine learning techniques, and the experimental results show that SVM had the best performance. There are generally many irrelevant features in the datasets that increase the computational complexity of the SVM training phase [15]. However, to improve the computational result of SVM, many feature selection techniques are applied in several works with SVM before constructing the classifier. F-score feature selection algorithm with SVM for breast cancer prediction was proposed by Akay [16]. Chen et al. [17] applied a rough set technique for feature selection and SVM for classification in another work. The number of features was halved in the Wisconsin original breast cancer dataset. In 2004, Genetic Algorithms (GA) were used with SVM for feature selection for BCD [18]. The authors use the Wisconsin breast cancer dataset to validate this approach. The experimental results show that the performance of the generated SVM diagnosis models is considerably improved. Recently, in 2018 an SVM-based weighted ensemble learning method called WAUCE [4] with six kernel functions was proposed for BCD. The WAUCE model achieves a higher accuracy with significantly lower variance than other methods.
DL methods have dominated the literature for the past few years and have been effective in classification accuracy, taking advantage of increasing hardware computational power [5]. The DL approaches, including Convolutional Neural Networks (CNNs), Deep Autoencoders (DANs), Deep Belief Networks (DBNs), Stacked Autoencoders (SAE) and Recurrent Neural Network (RNN), has been recently applied for BCD with great success. The CNNs method is used for image analysis [19], for breast cancer classification [20], and mammographic BCD [21]. Although the CNN approaches obtain good results on big-size datasets, it fails to achieve significant results on small-sized datasets [22].
To accelerate the training time of CNNs, transfer learning has been combined with CNNs in some works [22, 23]. On another side, several works have been realized to improve the performance of DL approaches for BCD. Feng et al. [24] have successfully applied a deep manifold preserving autoencoder for classifying breast cancer images. Abdel-Zaher et al. [25] proposed a DBN for breast cancer classification. The RNN system is proposed in [26] for the breast lesion classification.
White-box classification approaches
To overcome the drawback of black-box classification methods, interpretable models have been introduced to allow the decision-makers and doctors in BCD to explain their decisions.
DTs and random forest are commonly used as white-box classification methods in several domains, especially for BCD, because of their easy conversion into a set of classification rules understandable by decision-makers. The C4.5, CART, and ID3 are the most well-known decision tree methods. However, in DTs, the training’s simple change may produce a more significant change in the generated model [27].
Many AC algorithms have been developed based on classification rules. The classifiers are based on classification rules generated from dependencies between the class feature and other features. AC algorithms are implemented based on two principal stages: the rule generation stage and the prediction stage. Based on the techniques used in the rule generation stage, we distinguish two groups of algorithms: the first group contains the association rule-based algorithms, which first generate the association rule set and select from them the classification rules used. The latter group contains the Classification Rule-based Algorithms (CRA). Contrary to the first group, these CRA generate the classification rules directly from the dataset. In [7], the authors proposed a new algorithm that generated an associative classifier from the association rule set. It used the Apriori algorithm[28] to generate the association rules, and after that, the classification rules were extracted from the association rule set.
Li et al. [29] proposed an algorithm called Classification Based on Multiple Association Rules (CMAR), in which they implemented the CR-Tree and FP-Tree as algorithms for the rule generation. CMAR was tested and compared with CBA and other classical classification algorithms using UCI datasets.
To resolve the multi-scanning problem of CBA, Thabtah et al. [30] proposed an algorithm called Multi-class Classification Based on Association Rules (MCAR), in which the Tid-list method is used during the rule generation stage. Hadi [31] developed the Enhancement Class Association Rules (ECAR) and also a new Fast Associative Classification Algorithm (FACA) [31]. In FACA, to enhance the training stage’s speed, the Diffset method is used as an algorithm for the rule generation from the dataset. FACA is evaluated and compared with CBA, CMAR, MCAR, and ECAR and obtains the best results.
The weighted Classification Based on Association Rules (WCBA) is proposed by Alwidian et al. [32] for resolving the estimation measures used in the rule generation process.
Recently, in another way, Wang et al. [33] proposed a method called Improved Random Forest-based Rule Extraction (IRFRE) for rules extraction from DTs. This method aims to derive classification rules for BCD from a set of decision trees generated by the classical classification algorithm Random Forest Algorithm (RFA). It employed a multi-objective evolutionary algorithm for optimizing the CR set extracted.
However, one of the main challenges in the classification rule generation from association rules is that it tends to produce many association rules. The number of rules grows exponentially with the number of features in the datasets. Simultaneously, the associative classifier’s performance highly depends on the classifier size (number of rules) and the rule size (number of conditions in the rule). The direct CR generation approach from the dataset can build classifiers whose size is independent of the dataset’s features.
Several recent approaches have been proposed in the meta-heuristic optimization field and showed promising results in several optimization problems, such as EOA proposed in 2020 [5]. More recently, González-Patiño et al. [34] proposed a new AC method for BCD using an old algorithm called Artificial Immune System (AIS) [35] (which was proposed in 2001) as a meta-heuristic optimizer for the generation of classification rules directly from the dataset. The classification model generated achieves higher accuracy than association rule-based AC but is still worse than the results from recent deep learning methods. According to this limitation, we aimed in this paper to propose a discrete version of EOA and use it for CR mining. Our approach presents the advantages of both direct CR generation from the dataset and the efficiency of the recent meta-heuristic EOA.
Associative classification overview
Data mining is a set of tasks and approaches to extracting knowledge from datasets for decision support purposes in several domains, including engineering, economic, biological, and medical. Data classification is among the interesting and widely used tasks among data mining tasks [6]. In 1998, Liu et al. [7] introduced a new type of classification called AC or rule-based classification. AC aims to generate classification models in the form of a Classification Rule (CR) set, which is easily comprehensible by decision-makers to interpret their decisions [8]. The AC is the hybridization of the two data mining tasks: Association Rule (AR) mining and data classification using a set of CRs. Each CR is a particular case of the AR. The CR has the form
The associative classifier is defined as a set of classification rules
Motivation and contributions
The main aim of the recently proposed algorithms for classification is usually to improve the accuracy of classifiers. However, in the BCD case, the diagnosis decision directly affects the patient’s safety. Then, it requires high classification accuracy and high interpretability of the diagnosis models, allowing the doctors to make safe decisions. That is another challenge for researchers. AC methods generate interpretable models composed of classification rules which are easily readable and interpretable [36]. Rule generation is an essential task in AC, which needs intelligent approaches. In the literature, all proposed approaches generate rules indirectly, i.e., generate the association rules and extract the classification rules from them. However, these approaches generate many rules that complicate the interpretability of the classifier. Based on a recent and efficient meta-heuristic, this study proposes an intelligent CR generation algorithm for an efficient AC approach. Our approach generates the classification rules directly from data. Our work has three main contributions:
First, our study designs an effective AC method that generates interpretable classification models for BCD. Second, the proposed approach uses the recent meta-heuristic algorithm EOA to generate classification rules directly from the dataset, improving the models’ accuracy and interpretability. EOA obtained the best results in several optimization problems [5]. Third is proposing a new discrete version of the EOA called DEOA to solve the CR generation problem. The proposal of new discrete operators can improve the performance of the discrete algorithm.
Proposed approach methodology
This work aims to design an AC approach for generating interpretable BCD models. The proposed approach comprises two main components: associative classifier for BCD and discrete EOA for classification rule generation. Based on the proposed discrete EOA, the associative classifier is generated for BCD. The proposed approach is presented in detail in the rest of this Section. We further evaluate and compare the proposed approach performance with other AC approaches.
Associative classification-based BCD framework
We describe, in general, the proposed DEOA-AC in this Section. In Fig. 1, the workflow of the proposed approach is presented. It consists of two main parts: the diagnosis module generation and breast cancer diagnosis.
Flowchart of the AC based BCD framework.
The first part is involved two stages (1) data discretization and (2) diagnosis module generation. In the second part, the user exploits the generated diagnosis module for breast cancer diagnosis of each patient using an intermediate interface. The user can also input new data with its diagnosis result in the training dataset for a possible enrichment of the training dataset.
Stage 1: Data discretization
We used several benchmark datasets from the UCI dataset repository. Generally, these datasets contain discrete-valued (nominal) and real-valued features, while our approach works only with nominal data. Then, all real features were converted to nominal (discrete) features. This process is called data discretization, which isdetailed in sub-Section 6.1.2.
Stage 2: Associative classifier generation
The diagnosis module (associative classifier) generation method used in this work aims to generate the diagnosis module from a Training Set (TS). The rules that compose the associative classifier are mined through an iterative process. In each iteration, one rule is generated using the proposed DEOA. A rule is generated for each class, starting with the highest number of instances class in the TS. Our method operates in four phases, as presented in Algorithm 1:
The Rule Set (RS) is initialized as empty. While the TS is not empty, a class C with the highest number of non-covered instances in TS is chosen, and a New Training Set (NTS) is created from the instances of class C. After that, all these instances are removed from the TS. While the NTS is not empty, the proposed DEOA is called for generating one CR from the NTS at each iteration until all NTS instances are covered.
The generated CR is added to RS, and all instances correctly classified by the CR are removed from the NTS. This process continues until all instances are covered. Finally, the RS is considered an associative classifier once the TS is empty.
Stage 3: Breast cancer diagnosis
For any new patient, the user inputs its data to the diagnosis module through an interface and receives the diagnosis result. The associative classifier checks the classification rules in order one by one. Once it has found a rule that matches the new data, i.e., the new data corresponds to the rule’s antecedent, it classifies it according to the class label of the rule. If no rule matches the new data, it is considered as cannot be classified by the classifier.
Original Equilibrium Optimizer Algorithm (EOA)
The original EOA is a physical-based meta-heuristic algorithm proposed recently by Faramarzi et al. [5] for solving continuous optimization problems. Like other population-based algorithms, in this algorithm, the search agents are represented by the particles of the solution, and their concentration represents the positions (solutions of the problem). The particles update their concentrations using the physical mass balance equation and the best-so-far solutions, namely equilibrium pool [5] and seek to find the equilibrium state, which is considered the optimal solution.
Because EOA is a population-based algorithm, the particles start with random initial positions (concentration) in the search space. Then, the particle’s position is updated with the physical mass balance equations as in Eq. (1):
Where
The exponential term
Where
Where iter and Max_iter are the current and maximum iterations time, respectively,
Where
Where GCP is calculated as in Eq. (8).
Where
The original EOA is proposed for solving continuous optimization problems, while our optimization problem (CR mining) is modeled as a combinatorial optimization problem, which is by nature a discrete problem. According to the advantages of the original EOA, investigating its performance on discrete problems is indispensable. So, the original EOA has to be discretized for solving discrete problems. In this sub-section, the discrete equilibrium optimization algorithm version is designed and adapted to solve CR mining problems in AC for BCD. In the following, the steps for building our DEOA are shown.
Step 1: Solution encoding and particle representation
In a CR mining problem, a solution is a generated CR for a given class from the training dataset. Each particle in the DEOA represents a CR, as presented in Section 2. The CR is composed of a subset of features. At each feature, a value from their predefined possible values is assigned. Therefore, we must represent, on the one hand, the selection of a subset of features in the CR (first sub-problem) and, on the other hand, the selection of one feature’s value from their possible predefined values (second sub-problem). Each sub-problem is represented by a d-dimensions vector, where
Particle’s position encoding.
Step 2: Initialization
In the initialization step, a population of
Each element of the matrix has two values that represent the feature selection in the CR and the feature’s value in the CR, and are generated using Eqs (10) and (11), respectively.
Where
Step 3: Fitness function definition
To evaluate the quality of each particle’s position (Rule), we use the coverage fitness [37] defined in Eq. (12):
Where
Step 4: Concentration (particle’s position) update
The positions of the particles are updated using Eq. (1) in the original EOA. However, in the discrete EOA, Eq. (1) is modified using discrete operators and replaced by Eqs (13) and (14).
Where
The multiplication operator “*” in Eq. (14) is redefined as in Eq. (15).
Where
Where
Where
The vectors,
The generation rate parameter calculation (G)
In the original EOA, the parameter
Where
Where
Based on the modifications introduced above, the details of the proposed DEOA are presented in Algorithm 1.
Experimental design
The experimental setup is presented in terms of (1) The benchmark breast cancer datasets used in this study. We have chosen datasets from the UCI repository as presented in Table 1. (2) All numerical attributes of the chosen datasets have been discretized as explained in sub-section 6.1.2. (3) The measure metrics used for evaluating the experimented algorithms. (4) The parameter setting and evaluation of the proposed DEOA-AC, (5) the DEOA-AC comparison with benchmark algorithms.
Our proposed algorithm was developed and implemented in the Java programming language. All experiments of this study were run on a personal computer equipped with a processor, Intel Core i5 3.2 GHz, and a memory RAM of 8 GB.
Datasets
To test and evaluate the performance of the proposed DEOA-AC, we selected various well-known and recently used benchmark breast cancer datasets from the UCI repository [38] for our analysis, which includes Breast Cancer Dataset (BCDS), Wisconsin Original Breast Cancer Dataset (WOBC), Wisconsin Diagnostic Breast Cancer Dataset (WDBC), Wisconsin Prognostic Breast Cancer Dataset (WPBC), and Mammographic Mass Data Set (MMDS).
The WDBC and WOBC datasets are collected from the University of Wisconsin Hospitals, Madison. The samples in the WDBC dataset comprised of visually measured atomic features taken from the patient’s breast. Each instance represents FNA test measurements. WDBC does not contain missing values; the instances are divided into 212 malignant and 357 benign. The WOBC dataset includes 65,52% benign instances and 34.48% malignant instances. Sixteen instances include missing values in the feature “bare nuclei”.
The WPBC dataset was also extracted as digitized image of a fine needle aspirate (FNA) from the breast of 198 people and contains 151 benign instances and 47 malignant instances, in which four instances include missing data. It was collected from digital mammograms of patients between 2003 and 2006 at the Institute of Radiology of the University Erlangen-Nuremberg. MMDS contains 961 instances divided into 516 benign and 445 malignant. Seventy-six instances have missing values.
The instances containing missing values in all datasets were removed before the experiments since their number was very low, as presented in Table 1.
The dataset’s informations are presented in Table 1, including the number of attributes, number of instances, number of missing values, and number of classes for each dataset.
Benchmark datasets used in the study
Benchmark datasets used in the study
Most breast cancer datasets contain many continuous attributes that take real values, whereas the AC works only with discrete values. Then, the discretization of continuous values is necessary. In this work, the unsupervised discretization [39] called Entropy Minimization Heuristic (EMH) [40] is performed on all continuous attributes. The EMH is offered by the Weka tool [41], in which the range of a real-valued attribute is partitioned into
Classification accuracy of the proposed approach obtained by varying the number of intervals of the discretization algorithm
Classification accuracy of the proposed approach obtained by varying the number of intervals of the discretization algorithm
It is clear that the accuracy changes with the discretization interval number in almost all datasets. However, it proves that the interval number plays an essential role in the discretization algorithm. Table 2 shows that the value 4 of the parameter bins in the discretization algorithm gets the highest classification accuracy on almost all datasets. Then, in all the following experiments, we fixed the value of the parameter bins at 4.
In this Section, several experiments are conducted to evaluate the proposed DEOA-AC approach’s effectiveness; the experimental results are presented in detail and discussed.
In order to evaluate and compare the performance of our approach with the compared algorithms, we consider not only the classification accuracy (CA) but also the interpretability (or simplicity) of the obtained classification model [42]. In our work, the model’s interpretability is measured by two metrics [43]. First, the Classifier Size (CS) is evaluated by the number of rules in the obtained classification model. Second, the Average Rules Size (ARS) is evaluated by the average number of terms in all rules’ antecedent of the classification model.
The calculation formulas of the three metrics and the statistical standard deviation metric (Std) are presented in Eqs (21)–(24).
Where CCI is the number of correctly classified instances,
Where
Where ARS measures the average number of terms in the antecedent of all classification rules.
In addition to the three previous metrics, to compare the reliability of the generated models by different runs of the algorithms, statistical standard deviation (Std) is measured using the formula presented in the Eq. (24). It highlights that when Std is smaller, the algorithm always converges to the same solution.
Where
Where
In this Section, several experiments are conducted to evaluate the effectiveness of the proposed DEOA-AC approach.
DEOA-AC parameter setting
Like all meta-heuristic algorithms, DEOA-AC has four tuned parameters that must be set, including particle number (
Figure 3 shows that DEOA-AC finds maximum performance in almost all datasets when the number of particle
DEOA-AC’s performance effects of varying population size and maximum number of iterations parameters.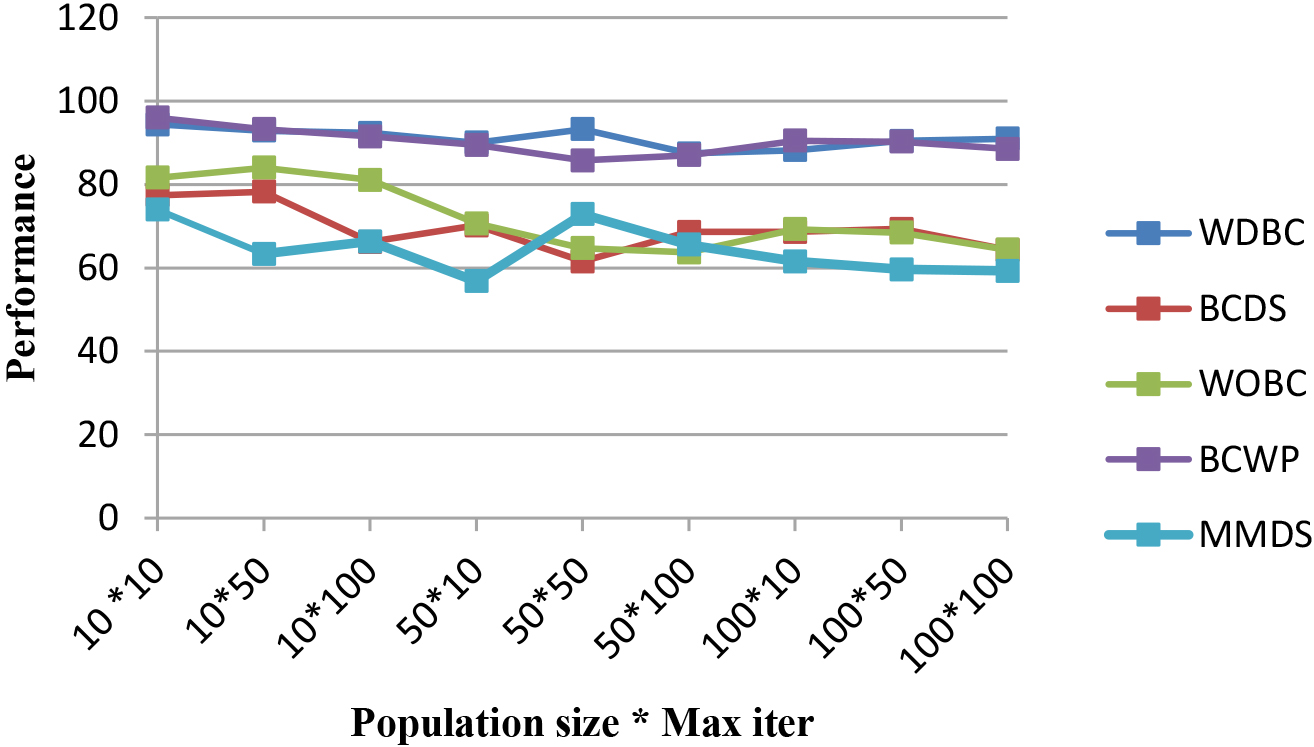
In this sub-section, our goal was to compare the performance of DEOA-AC with other well-known classification algorithms that generate rule-based classifiers. These algorithms adopt different rule mining mechanisms. The three classical and well-known algorithms, including C4.5 (Algorithm J48 in Weka) [45], OneR [46], and PART [47] provided by the Weka tool, have been chosen and run with the default values of their parameters. We also chose the two recently proposed rule-based classifier algorithms Artificial Immune System for Associative Classification (AISAC) [34] and Improved Random Forest-based Rule Extraction (IRFRE) [33]. The parameters setting for DEOA-AC, AISAC, and IRFRE are shown in Table 3. Our DEOA-AC algorithm was implemented in Java programming language, while the Weka data mining tool is used to run C4.5, OneR, and PART algorithms. Ten-fold cross-validation [48] has been used for all experiments, where a dataset is divided into ten partitions. Nine partitions are used for training, while the tenth partition is used for testing. Since DEOA-AC is a stochastic algorithm, it was run 20 independent executions, and the average results are considered. The results of the algorithms AISAC and IRFRE are inspired by his studies.
The comparison was carried out using the criteria presented in sub-section 6.1.3. Tables 4–7 summarize the obtained results.
Parameter setting for DEOA-AC and tested algorithms
Parameter setting for DEOA-AC and tested algorithms
Average accuracy and standard deviation of the rule-based classifier obtained when applying DEOA-AC and other algorithms
To evaluate the predictive ability of the proposed algorithm, 20 independent runs of DEOA-AC are performed for each dataset. The average accuracy (A_Ac) and the best accuracy (B_Ac) of 20 runs for the tested datasets are evaluated and presented in Table 4. The best values are highlighted in bold. The standard deviation (Sdt) is also evaluated and provided in the third column for each dataset to compare the reliability of the results obtained by the tested algorithms. The symbol ‘
For the two first datasets, WDBC and WOBC, the comparison results in our algorithm’s average accuracy show that the proposed DEOA-AC outperforms the two recent algorithms, AISAC and IRFRE, and the old algorithms C4.5, OneR, and PART. The best accuracy achieved by the proposed DEOA-AC is 100% on the two datasets.
For the three last datasets, BCDS, BCWP, and MMDS, the proposed DEOA-AC algorithm obtains the highest average accuracies and considerably outperforms the AISAC algorithm. For example, in the BCWP dataset, DEOA-AC obtains an accuracy of 97.5%, while AISAC obtains only 79.29%, which is an 18.21% improvement. In other words, the best accuracies obtained by DEOA-AC for all datasets are 100%.
We further evaluate the model interpretability and complexity using the classifier size and the rules’ average length in addition to predictive power evaluation.
We report in Table 5 the average number of rules generated by each algorithm over each dataset. Note that the column (A_Nr) refers to the average number of rules from 20 runs of the DEOA-AC algorithm, and (B_Nr) refers to the number of rules of the best solution in terms of A_Ac from 20 runs of the DEOA-AC algorithm. However, the results of the other algorithms are inspired by his study. The symbol “
According to Table 5, the proposed DEOA-AC algorithm generates a lower number of rules than IRFRE for the WDBC dataset and significantly better for the WOBC dataset.
Even though IRFRE is slightly better in terms of accuracy for the WOBC dataset, the number of rules generated by the proposed algorithm is considerably better than IRFRE. The DEOA-AC algorithm obtained an average of 6.05 rules by the classifier. In comparison, IRFRE generates a classifier with 12.5 rules, confirming our initial objective to improve BCD accuracy while reducing the diagnosis interpretability.
For the length of rule antecedent, our algorithm is compared with the IRFRE algorithm, and Table 6 shows the results. IRFRE outperforms our algorithm slightly for the WDBC dataset, while our algorithm outperforms the IRFRE for the WOBC dataset.
This result proves that the proposed algorithm can generate accurate and interpretable classification models with modest complexity, which is very important in BCD.
Average number of generated rules when applying DEOA-AC and other methods
Antecedent average length for each rule obtained when applying DEOA-AC and other methods
Based on Eq. (24), the three first performance measures’ variance are calculated and provided by the column “Sdt” in Tables 4–6. DEOA-AC is better than IRFRE for WDBC and WOBC datasets, whether for the average accuracy variance or the interpretability variance in terms of the average rule number in the classifier and the average rule length.
In conclusion, DEOA-AC has extracted a few and short rules because of the rule representation and the equilibrium optimization algorithm’s power search. Besides, the proposed discrete operators can guide the DEOA-AC to find straightforward rules.
In AC, the classifier comprises effective rules that are interpretable and comprehensible by users (doctors in the medical area). In our study, among 20 runs on tested datasets, WDBC, WOBC, BCDS, and BCWP, the run’s generated rules give the best performance (accuracy equal to 100%) are listed in Tables 7–10. Each rule is represented by the rank of the rule in the classifier (column 1), the antecedent of the rule (column 2), the class in the consequent of the rule (column 3), and the complexity of the rule evaluated by the number of nodes or terms in the rule (column 4).
All generated diagnosis models in Tables 7–10 diagnose all instances of the tenth-fold in the dataset that matches the table. As shown in Tables 7–10, the diagnosis models for the WDBC, WOBC, BCDS, and BCWP are composed of 10, 5, 4, and 11 rules, respectively. The average rule number is also around 2.7, 1.4, 1.5, and 1.8, respectively, easily readable and explainable by the doctors.
The results indicate that the accuracy is good, but the length of generated rules is short, and there are a small number of rules for each dataset, so the rules are easily comprehensible.
Extracted rules of dataset WDBC
Extracted rules of dataset WDBC
Extracted rules of dataset WOBC
Extracted rules of dataset BCDS
Extracted rules of dataset BCWP
BCD is an essential way for early detection, helping doctors cure it in the early stage. Several BCD methods are proposed in the literature and generate accurate models. However, the model’s performance is usually evaluated only in accuracy, whereas the doctors need to interpret their decisions. This paper proposes a new approach for generating accurate and interpretable classifiers directly from breast cancer datasets based on a recent and efficient optimization algorithm. We propose a discrete version of the EOA called DEOAfor the classification rules mining in the Associative classifier construction process to address the two aforementioned evaluation criteria. The proposed DEOA is an important part of our approach because it directly affects the generated rules’ interpretability.
To evaluate the performance of our proposed approach, we have tested it against two recent AC algorithms and three classical rule-based classification algorithms running on five well-known breast cancer datasets taken from UCI.
The experimental results show that the proposed DEOA-AC algorithm outperforms all other compared algorithms and can significantly increase BCD performance in terms of accuracy and interpretability. The rules discovered by our algorithm are generally with higher accuracy and comprehensibility.
This new approach contributes to the AC for the disease diagnosis problem. It opens a way for future research in disease diagnosis based on new intelligent optimization algorithms. So, in the future, the proposed approach can be used for many other diseases’ interpretable diagnosis systems, such as Heart diseases, Diabetes, Parkinson’s disease, and Alzheimer’s disease. We will also integrate new optimization algorithms to improve the diagnosis models’ performance by increasing their accuracy and interpretability.