Abstract
Co-training is a popular semi-supervised learning method. The learners exchange pseudo-labels obtained from different views to reduce the accumulation of errors. One of the key issues is how to ensure the quality of pseudo-labels. However, the pseudo-labels obtained during the co-training process may be inaccurate. In this paper, we propose a safe co-training (SaCo) algorithm for regression with two new characteristics. First, the safe labeling technique obtains pseudo-labels that are certified by both views to ensure their reliability. It differs from popular techniques of using two views to assign pseudo-labels to each other. Second, the label dynamic adjustment strategy updates the previous pseudo-labels to keep them up-to-date. These pseudo-labels are predicted using the augmented training data. Experiments are conducted on twelve datasets commonly used for regression testing. Results show that SaCo is superior to other co-training style regression algorithms and state-of-the-art semi-supervised regression algorithms.
Introduction
Co-training [1] is a simple and effective disagreement-based semi-supervised learning (SSL) method. Two learners trained in different views independently select high-confidence unlabeled instances. Then these instances are assigned pseudo-labels and added to the training pool of the other learner to update the model parameters. Since the two views are compatible and independent [2], co-training can reduce the accumulation of errors in the learner by exchanging pseudo-labels. This method has been applied to many fields, such as image retrieval [3, 4], sentiment analysis [5, 6], and medical diagnosis [7, 8, 9].
Currently, there are a number of key issues of co-training. First, the assumption of sufficient and redundant views [10] has strict requirements on the data. However, some studies have proved that this is unnecessary [11, 12, 13]. The data-driven methods split the dataset into different subsets as views. The split methods include random splitting [14, 15], splitting according to set mechanisms [16] or conditions [17], splitting based on view sufficiency and independence [18, 19, 20], and splitting based on relevant domain knowledge [21, 22]. The learner-driven methods utilize the learners to achieve view difference. One is to use learners with different learning mechanisms to obtain more comprehensive data information [23, 24]. The other is to use learners with the same type however different parameters to achieve view difference [10, 25, 26]. Second, co-trainers trust the pseudo-labels assigned at each iteration, so they will not be updated in the subsequent training process. However, the pseudo-labels assigned in training may not reach the expected confidence level [27]. This problem may be more serious in the early stage of training. The errors caused by inappropriate instances will always exist or even accumulate.
The illustration of the SaCo algorithm at the 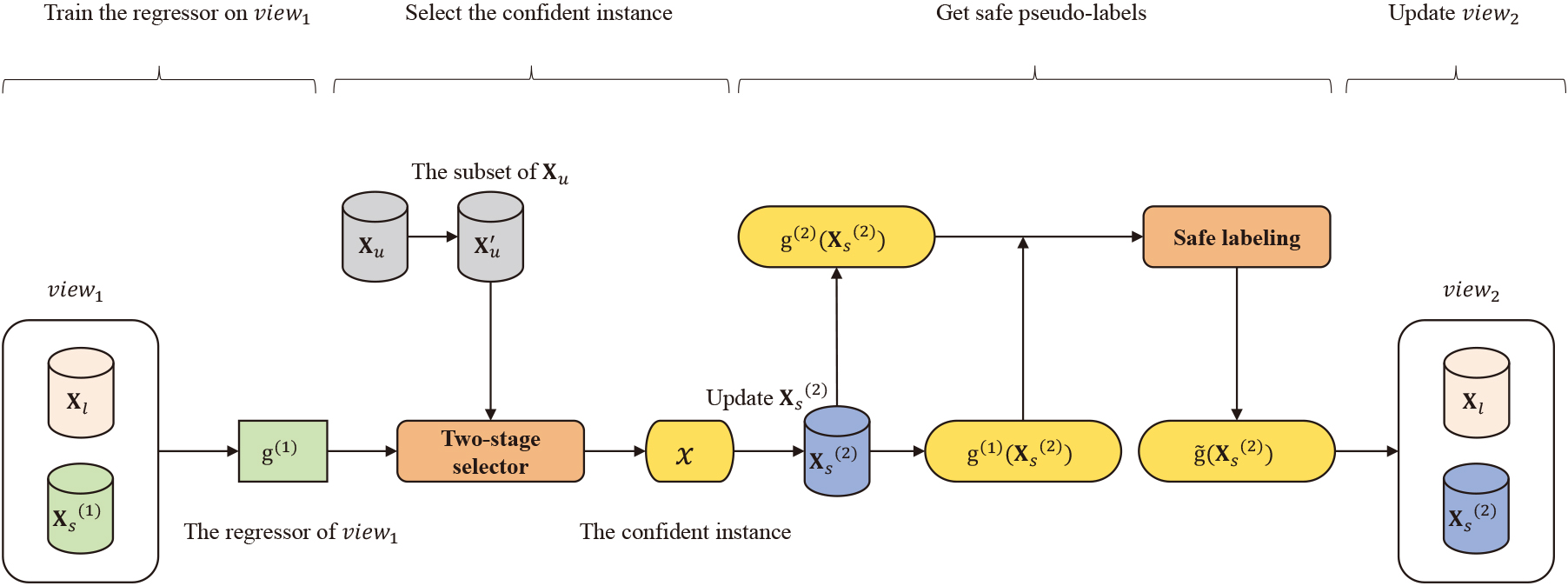
This paper proposes a safe co-training algorithm (SaCo) for semi-supervised regression (SSR). It mainly reduces the impact of the second disadvantage by guaranteeing and improving the quality of pseudo-labels. Figure 1 shows the framework of SaCo. The contributions of SaCo are as follows:
A two-stage selection approach that selects easy-to-learn instances. In the first stage, A safe labeling technique that assigns reliable pseudo-label to the selected unlabeled instance. For the unlabeled instance selected in current round, a more reliable prediction than the baseline is integrated by the predictions of different views. Unlike many algorithms that directly assign pseudo-labels without guaranteeing their quality, this technique can guarantee and improve the quality of pseudo-labels to reduce the risk in model learning. A label dynamic adjustment strategy that ensures the performance of pseudo-labels will not degrade as training progresses. Different from the general co-training framework, our algorithm dynamically updates the pseudo-labels. At each iteration, the model not only assigns safe pseudo-label to the currently selected unlabeled instance, but also updates the previous ones. This strategy guarantees that the quality of pseudo-labels will not be out of date.
Experiments are conducted on 12 datasets that are commonly used to test regression algorithms. We test the reliability of safe pseudo-labels and compare SaCo with other state-of-the-art semi-supervised regression algorithms. The results show that SaCo can significantly outperform the counter-parts. Statistics test shows that SaCo is significantly different from other algorithms. The source code of SaCo can be found at
The rest of the paper is organized as follows. Section 2 briefly introduces related works of co-training. Section 3 presents the proposed safe co-training framework. Section 4 presents the of experimental setting and some results, as well as a brief discussion. Finally, the necessary conclusions and the improvements for future work are recorded in Section 5.
This section reviews the related work of SaCo, including co-training and safe learning.
Co-training
Co-training [1] has attracted widespread attention due to its wide range of applications, and many variants have been gradually extended. For classification tasks, a co-training style algorithm [28] uses different algorithms instead of data features to divide views. The Co-EM algorithm [29] extends the standard co-training framework by assigning pseudo-labels to all unlabeled data at each iteration. The co-labeling algorithm [30] models the learning problem on each view as a weakly labeled learning problem, and then uses a set of pseudo-label vectors generated from classifiers of other views to learn the best classifier. DCT [26] employs two neural networks as regressors for views. It employs adversarial examples to achieve view difference, thereby avoiding network collapse. The SPamCo algorithm [31] incorporates self-paced learning and co-regularization into the co-training framework to remove inappropriate unlabeled instances, and it is also suitable for multi-view cases.
For regression tasks, a kernel regression algorithm coRLSR [32] designed a semi-parametric variant that greatly reduces the runtime for handling numerous unlabeled data. COREG [10] is the most representative single-view regression algorithm. It uses two
Safe learning
Since the use of unlabeled instances in semi-supervised learning may degrade model performance [35, 36, 37, 38], it is necessary to develop a safe prediction framework. Safe learning is a semi-supervised learning strategy that aims to assign more reliable pseudo-labels to unlabeled instances. These pseudo-labels should be able to often improve or at least not reduce the performance of the learner after participating in training.
For classification task, S4VMs [37] is a safe semi-supervised support vector machine algorithm. This method employs multiple low-density separators to approximate the decision boundary and maximize the SVMs performance of candidate separators. A general safe framework WILLSVM [39] is suitable for various performance testing methods. The ICLS classifier [40] minimizes the squared loss of a set of parameters implied by the labeled data under all possible labels of the unlabeled data. It can guarantee that the performance of the model is better than that of supervised ones. Balsubramani and Freund [41] proposed a method to learn a highly accurate prediction by limiting the allocation of real labels to a specific candidate set. LEAD [42] is a safe large-margin separation method for graph-based semi-supervised learning. Its strategy is that high-quality graphs should have a large margin of separation from predictions on unlabeled data. The UMVP method [38] integrates multiple semi-supervised learners and obtains the final prediction by maximizing the worst-case performance gain. When the performance metric is top-
In regression, coRLSR [32] trains the model under multiple views, and enforces the consistency of predictions from multiple views through co-regularization. SAFER [43] regards the problem of safe prediction as a geometric projection issue. It learns safe predictions that are not worse than supervised model from multiple semi-supervised regressors. SAFEW [44] further extends the framework of SAFER to weakly supervised learning.
The proposed method
In this section, we present the details of the SaCo algorithm. These include general optimization problem of the model, selection strategy for confident instances, safe labeling technique used in training, and algorithm description. Table 1 lists notations used throughout the paper.
Notations
Notations
Let
where
Let
More specifically, the selection of high-confidence unlabeled instance in SaCo is divided into two stages:
Use the
Use the supervised and semi-supervised regressors of the current view to select the most confident instance. For the unlabeled instance
where
Denote the baseline prediction and the
However,
In the absence of more information, our goal is to optimize the worst-case performance gains [37]. As long as good performance is achieved in the worst case, the quality of pseudo-label can be guaranteed. So the objective function becomes:
By taking the derivative of Eq. (7) w.r.t.
Then substituting Eq. (8) into Eq. (7), the equivalent form only related to
which is a simple convex quadratic program. After expanding its quadratic form, it becomes:
where
[b] : SaCo
Algorithm 3.3 present the details of SaCo.
The inputs of our model includes the labeled dataset
The first step is to initialize the parameters in our model. Semi-supervised regressor
The second step is to update
The third step is to update the safe pseudo-labels
The last step is to update the parameters of the
The training will end when there is no unlabeled data available or the iteration round reaches the maximum. It is easy to see that the flow of SaCo is very similar to that of the standard co-training. It exchanges confident instances in different views and trains the learners in an iterative manner. The most significant improvement of our algorithm is the use of the safe labeling technique to improve the quality of the pseudo-labels, especially in the early stages of training.
[htb] : Safe labeling
Experiments
In this section, we analyze the effectiveness of the SaCo algorithm through experimental results. From these experiments, we answer the following questions:
Does safe labeling technique improve the quality of pseudo-labels? Is the SaCo algorithm more accurate than other popular semi-supervised regression algorithm? Is the SaCo algorithm more robust and interpretable than other algorithms?
Experimental setting
Table 2 lists 12 publicly available datasets used in our experiments. Among them, 7 datasets [Abalone, Electrical, Elevators, Parkinsons, Puma8NH, SeoulBikeData, Wine_quality] are from the UCI machine learning data repository, 3 datasets Bank8FM, Cpu_small and Kin8nm are from the Delve repository, the other 2 datasets Space_ga and Wind are from the StatLib data repository. These datasets cover different domains including physical (Electrical), biomedical (Parkinsons), business (Wine_quality), etc. The number of instances in the datasets ranges from 3107 (Space_ga) to 10000 (Electrical). The number of features ranges from 6 (Space_ga) to 21 (Parkinsons).
Datasets
Datasets
Each dataset randomly selects 2000 instances as the training set, and the rest as the testing set. The instances in the training set are further split into labeled and unlabeled parts. The number of labeled data is set to 50, 100, 200, and 400, while the rest of the data is used as unlabeled part.
We choose the root mean square error (RMSE) and the coefficient of determination (
where
where
Four state-of-the-art algorithms are included in the experiment for comparison. (1) A popular co-training style semi-supervised regression algorithm COREG (TKDE 2005) [10]. In COREG, two Self-3NN methods are used as base regressors with Euclidean and Mahalanobis distance metrics. (2) A safe semi-supervised regression algorithm SAFER (AAAI 2017) [43]. It takes a supervised prediction as a baseline to ensemble safe predictions using multiple semi-supervised regressors. In SAFER, the model parameters are set to the recommended one in the package. It consists of a Self-LS and two Self-3NNs using Euclidean and cosine distance metrics, respectively. (3) A Multi-scheme Semi-supervised regression approach MSSRA (PRL 2019) [46]. It selects high-confidence instances by minimizing the difference in the predictions of multiple regressors. In MSSRA, the setting of based regressors is the default according to the implementation of the WEKA tool. Random Forest, SMOReg, and M5 are used as semi-supervised regressors for different views. (4) A novel graph-based semi-supervised regression algorithm BHD (Applied Soft Computing 2021) [47]. In BHD, heat diffusion with boundary-condition is employed to guarantee a closed-form solution. In SaCo, two basic networks with 3 hidden layers (
The average RMSE score of safe pseudo-labels and original pseudo-labels obtained by 20 tests on the twelve datasets. The best results in each series are highlighted in bold
Two fully connected networks are used as weak learners. To encourage view difference, we adopted the following settings: 1) 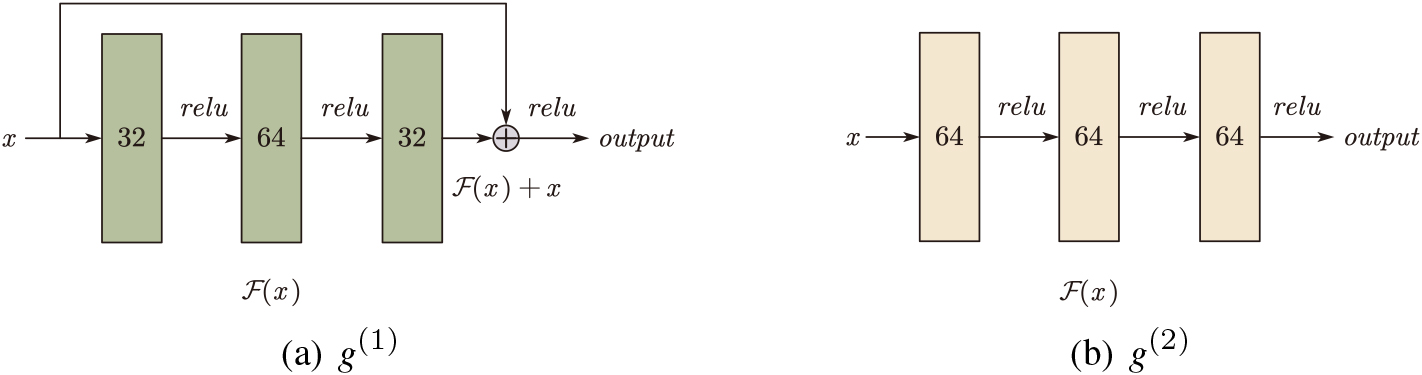
All comparison algorithms are derived from the source code provided by the authors and use the same optimal settings as in the reference. For COREG and MSSRA, the code runs on the Weka platform. For SAFER, the code runs on the Matlab platform. For BHD and SaCo, the code runs on the Python platform.
We validate the effectiveness of the safe labeling technique by comparing the difference in the RMSE of the safe pseudo-labels and the original pseudo-labels. Table 3 lists the RMSEs of the two types of labels for different datasets. Each dataset was run 20 times with different labeled data size settings. From the results, it can be observed:
The safe pseudo-labels are more reliable than the original pseudo-labels. Under four different labeled data size settings of 50, 100, 200 and 400, the RMSE of learner trained with the safe pseudo-labels was always smaller than that trained with the original pseudo-labels. For Kin8nm, the performance of learner trained with the safe pseudo-labels at 200 labels was comparable to the performance of the original pseudo-labels at 400 labels. In particular, the learner with safe pseudo-labels performed better at 100 labels than it with original pseudo-labels at 200 labels in Puma8NH. The quality of these two types of labels maintains a consistent trend of change. As the number of labeled data increased, the performance of both the original pseudo-labels and the safe pseudo-labels gradually improved. This is because the safe pseudo-labels are generated on the basis of the original pseudo-labels.
Comparison with other methods
To validate the performance of SaCo, we compared it with four other state-of-the-art SSR algorithms. Each dataset was run 20 times at different labeled data size settings. Figure 3 shows the RMSE results of different algorithms under four label sizes. It can be observed that SaCo has superior performance compared to other algorithms, as follows:
When the number of labeled data is 50, SaCo achieves the best performance on 9 of the 12 datasets. In Abalone, Cpu_samll, Electrical, Kin8nm, Parkinsons, SeoulBikeData, and Wine_quality, SaCo has achieved significant improvement compared to other algorithms. In Bank8FM, Puma8NH and Space_ga, SaCo achieved the second-best performance. For these datasets, SaCo does not perform as well as MSSRA, but the gap is not obvious. It suggests that the selection of confident instances by the consistency principle may be applicable to these datasets. In Elevators and Wind, SaCo had a marginal improvement over MSSRA. One of the reasons for this might be that SaCo has adopted safe labeling technique to improve the quality of pseudo-labels. As the label size increases, SaCo achieves more performance gains than other algorithms. SaCo achieved the best performance on at least 9 of the 12 datasets and the second-best in 2 datasets under all label size settings. In Cpu_samll, Electrical, Parkinsons, SeoulBikeData and Wine_quality, the performance of SaCo at 100 labels approached or exceeded that of other algorithms at 200 labels. In Bank8FM and Puma8NH, SaCo and MSSRA had similar performance. Both of them significantly outperformed the other three algorithms. In Space_ga, the performance of COREG was ahead of other algorithms, only SaCo outperformed it at 400 labels. The reason for this may be that the
RMSE comparison of different methods on 12 datasets.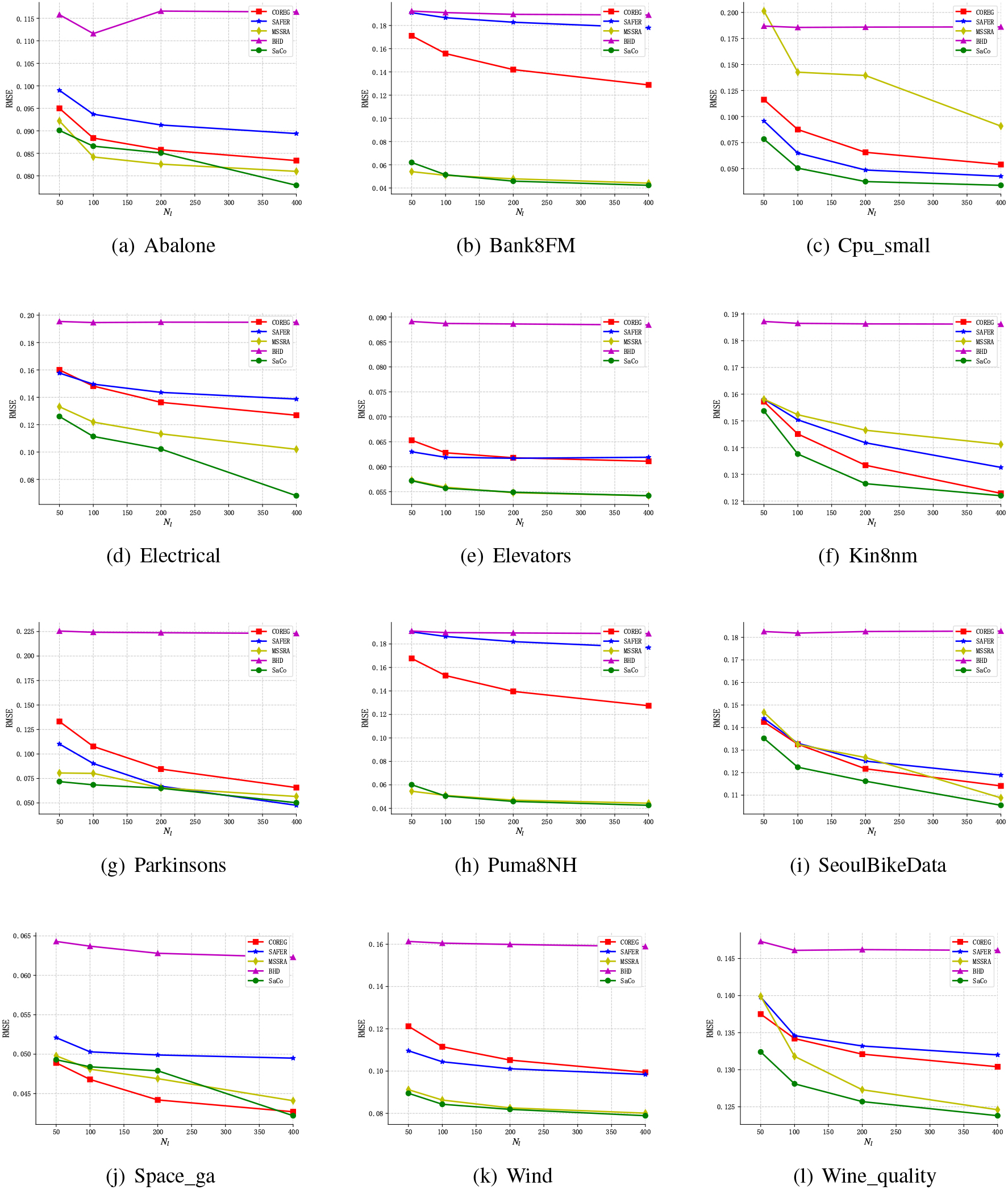
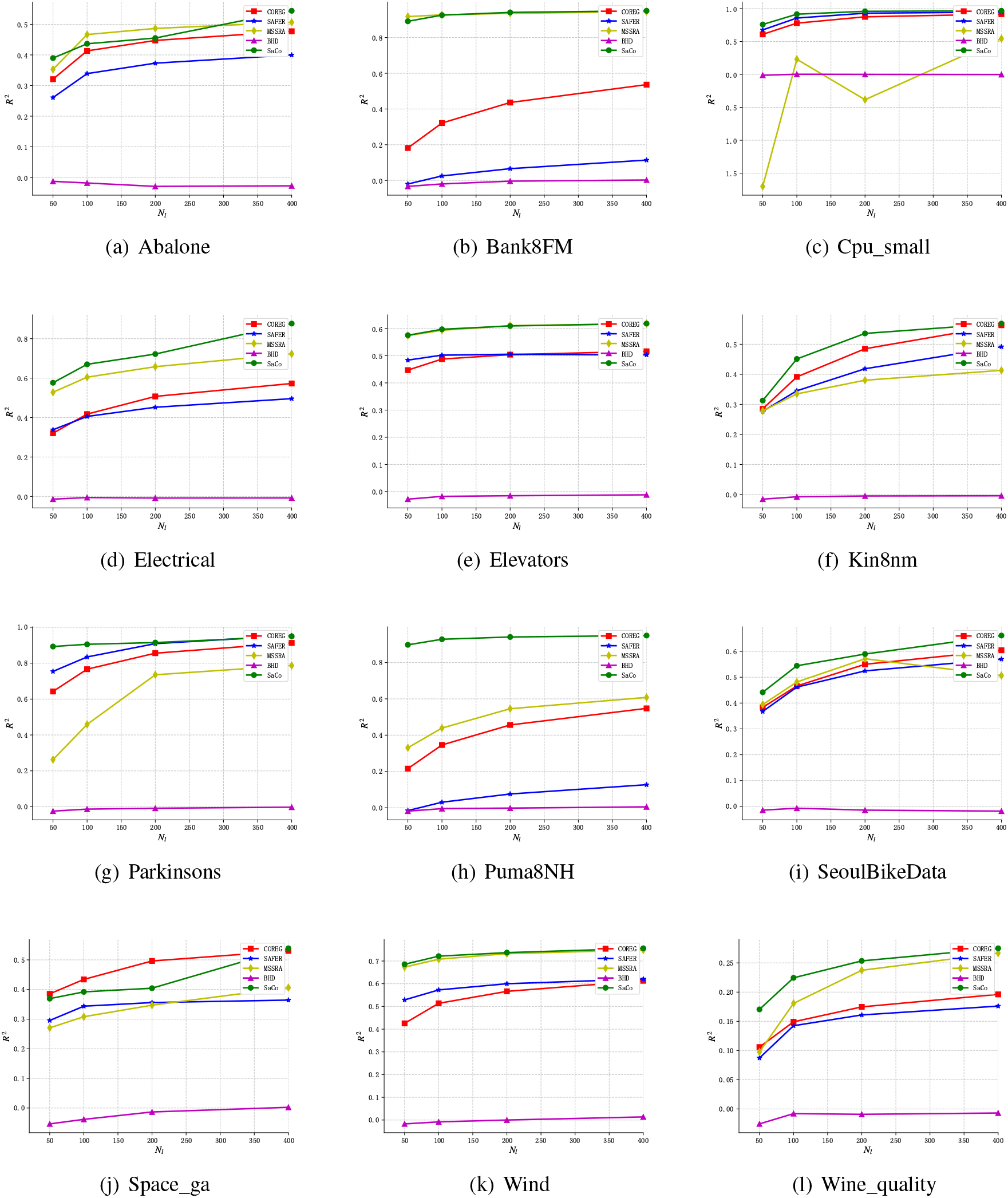
Figure 4 shows the
Since different algorithms share the same random trials, we further performed statistical tests. The pairwise
The
Figure 5 shows the results of the Bonferroni-Dunn post-hoc test for
Performance comparison of SaCo algorithm against the others by the Bonferroni-Dunn test with 
Now we can answer the questions proposed at the beginning of this section.
The Safe labeling technique can effectively improve the quality of pseudo-labels. Table 3 shows that the performance of the learner is enhanced with safe pseudo-labels on all 12 datasets. For different number of labeled data, the safe pseudo-labels consistently have a better quality than the original pseudo-labels. In some datasets, safe pseudo-labels at low labels are of similar or even higher quality than the original pseudo-labels at high labels. All this shows that the quality improvement of pseudo-labels brought by safe labeling technology is comprehensive and stable. SaCo is more accurate than state-of-the-art SSR algorithms, including COREG, SAFER, MSSRA and BHD. This is validated by Fig. 3, Fig. 5 and Table 4. Unfortunately, the performance of SaCo is weaker than other algorithms on some datasets when the number of labels is small. This may be due to the poor performance of our instance selection strategy on these datasets. SaCo is more robust and has better interpretability than other algorithms. Figure 4 proves that the fitting performance of the regression model obtained by SaCo is better than other algorithms. Furthermore, the performance of SaCo maintains a steady improvement as the label size increases on all datasets. Although MSSRA does not have a significant gap with SaCo in performance, it is unstable on some datasets such as Cpu_small and SeoulBikeData, which is also the difference between these two algorithms.
The datasets used in the experiment does not contain missing values. Although there are outliers and noise, we do not handle them explicitly. Instead, our instance selection strategy and safe labeling technique handle them implicitly. On the one hand, the two-stage selection strategy evaluates the performance gain that each unlabeled data can bring to the current regressor in each iteration. Outliers tend to have low gains and are therefore difficult to be selected as confident instances. On the other hand, The safe labeling technique can reduce noise by improving the quality of pseudo-labels.
Conclusion and further work
In this paper, we proposed the SaCo algorithm to improve the quality of pseudo-labels selected during co-training. A safe labeling technique was designed for co-training framework to learn safe pseudo-labels. A label dynamic adjustment strategy was used to maintain the timeliness of safe pseudo-labels. Results not only validated the effectiveness of safe pseudo-labels, but also demonstrated the advantages of SaCo over state-of-the-art SSR methods.
The following research topics deserve further investigation:
Make use of prior knowledge. In some domains, it is more beneficial to achieve the view difference by splitting the dataset with prior knowledge. However, SaCo as a single view style algorithm ignores this. In further work, the use of relevant domain knowledge to split views will be considered. More efficient evaluation measures to select reliable instances. SaCo evaluates the quality of selected instances by computing the performance gains on labeled data in two stages. This method helps to select unlabeled instances that are easy to learn, however it can be further improved in time cost. The evaluation measure should be fine-tuned or modified to improve the efficiency of selecting high-confidence instances. A new strategy based on minimizing the prediction gap between different views might be a good option. Better safe pseudo-labels for selected instances. The performance of safe pseudo-labels is jointly determined by the original pseudo-labels and a linear convex set constructed from the predictions of the two views. Different convex sets can be constructed in other ways instead of linear combinations, possibly resulting in safe pseudo-labels with better quality. SaCo is implemented in the two-view cases, but it is supposed to be extended to the multi-view scenario. The multi-view case could provide more choices for baseline labels, and the constructed candidate convex set is also richer.
In summary, SaCo is a general algorithmic framework that can be enriched in the future.
Footnotes
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China under Grant No. 62136002 and 61876027, the Central Government Funds of Guiding Local Scientific and Technological Development under Grant No. 2021ZYD0003.
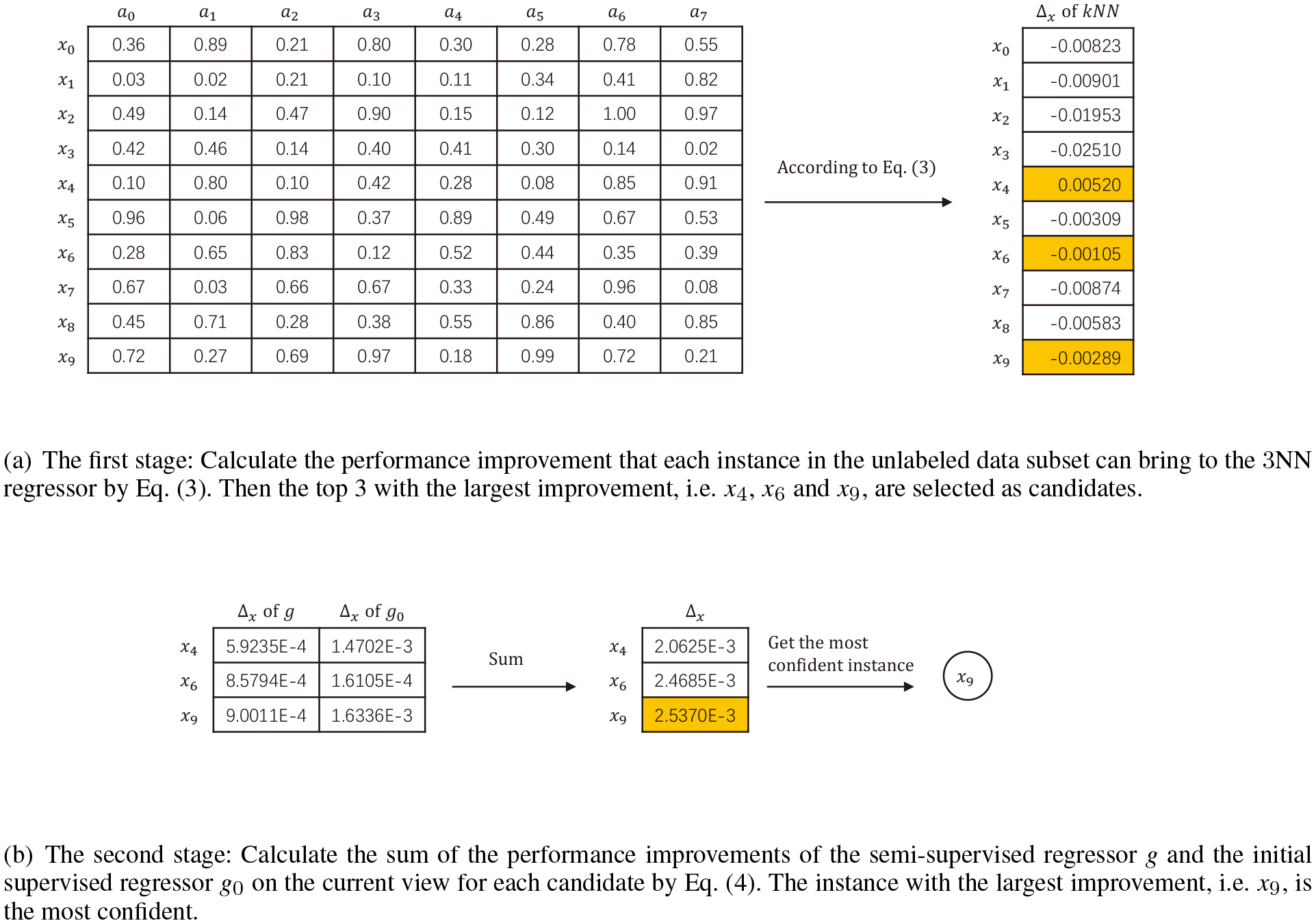
Appendix A. Two-stage instance selection
A running example of the two-stage instance selection with the following settings: 1) the data are from the kin8nm dataset; 2) the value of the conditional attribute is rounded to two decimal places; and 3) 3NN is used for the first stage.