
Abstract
In the application of Bayesian networks to solve practical problems, it is likely to encounter the situation that the data set is expensive and difficult to obtain in large quantities and the small data set is easy to cause the inaccuracy of Bayesian network (BN) scoring functions, which affects the BN optimization results. Therefore, how to better learn Bayesian network structures under a small data set is an important problem we need to pay attention to and solve. This paper introduces the idea of parallel ensemble learning and proposes a new hybrid Bayesian network structure learning algorithm. The algorithm adopts the elite-based structure learner using genetic algorithm (ESL-GA) as the base learner. Firstly, the adjacency matrices of the network structures learned by ESL-GA are weighted and averaged. Then, according to the preset threshold, the edges between variables with weak dependence are filtered to obtain a fusion matrix. Finally, the fusion matrix is modified as the adjacency matrix of the integrated Bayesian network so as to obtain the final Bayesian network structure. Comparative experiments on the standard Bayesian network data sets show that the accuracy and reliability of the proposed algorithm are significantly better than other algorithms.
Introduction
Learning and reasoning of uncertain knowledge is an important domain that needs to be solved urgently in the field of artificial intelligence. At present, most relevant machine learning methods only stay at the stage of pattern recognition and therefore are unable to reveal the internal relationship between variables in complex systems and mine the causal relationship between variables. As a kind of probabilistic graph model, Bayesian networks can effectively reveal the causal relationship between random variables by virtue of the organic combination of probability theory and graph theory and become an important theoretical tool to deal with uncertain problems [1].
The construction of Bayesian networks mainly includes structure learning, parameter learning and knowledge reasoning, among which Bayesian network structure learning is the top task to solve practical problems. Bayesian network structure learning aims to construct a network structure by using expert knowledge or observational data sets, so that the learned network structure can maximize the expression of the complex associations between random variables. Since the artificial construction of the Bayesian network structure by using expert knowledge is a time-consuming and subjective work, autonomous learning of the Bayesian network structure from observational data sets has become the mainstream. Learning BN structures from an observational data set aims to find a network structure that best fits the data set, which is a NP-hard problem [2]. So far, the existing algorithms for Bayesian network structure learning from the complete observational data sets can be roughly classified into three categories: the constraint-based method, the score-based search method and the hybrid learning method [3]. The constraint-based method usually adopts statistics or information theory to analyze the dependence between variables so as to determine the optimal Bayesian network structure. The score-based search method regards network structure learning as an optimization problem which searches for the Bayesian network structure with the best score by selecting an appropriate search algorithm under the specific scoring function. The hybrid learning method first uses the constraint-based method to reduce the search space and then uses the score-based search method to learn the optimal Bayesian network structure in the reduced search space. Thus it can be seen that the hybrid structure learning method combines the advantages of the constraint-based method and the score-based search method and it has always been the research hotspot of Bayesian network structure learning. For example, Tsamardinos et al. [4] proposed a classic hybrid structure learning strategy called Max-Min Hill-climbing (MMHC) in 2006. The algorithm first constructed the skeleton of Bayesian networks through a local discovery algorithm called Max-Min Parents and Children (MMPC), and then used the greedy search algorithm Hill-Climbing (HC) to search for the network structure with the optimal Bayesian scoring. Gasse et al. [5] proposed the Hybrid HPC (H2PC) in 2014. Different from MMHC algorithm, this algorithm adopted the Hybrid Parents and Children (HPC) algorithm to construct the skeleton of Bayesian networks and obtained a better superstructure than MMPC algorithm. Compared with MMHC algorithm, the network structure finally obtained was characterized not only with better quality but also with better generalization performance. Sun et al. [6] discretized the multi-group artificial bee colony algorithm based on cuckoo algorithm (CMABC) and applied it to Bayesian network structure learning, which was called CMABC-BNL algorithm.
The swarm intelligence optimization algorithm is a kind of probability-based random searchable evolutionary algorithm which is abstracted mainly by simulating the group behavior of biological foraging and has received extensive attention and research in solving optimization problems [7]. Compared with the single-solution search algorithm, the swarm intelligence optimization algorithm can explore the search space better and thus has a higher probability of capturing the global optimal solution. Genetic algorithm (GA) [8] which searches for the optimal solution of the problem by simulating the process of natural selection, crossover and mutation in genetic mechanism is a typical swarm intelligence optimization algorithm and has been widely used in Bayesian network structure learning optimization problems. In 1996, Larranaga et al. [9] combined the genetic algorithm with the K2 algorithm and proposed the K2GA algorithm which took the order of variables obtained by the genetic algorithm as the input of the K2 algorithm and finally learned the network structure that made the score of the K2 algorithm optimal. Later, Larranaga and others proposed the conventional genetic algorithm (CGA) [10]. The algorithm learned the structures of Bayesian networks based on the traditional genetic algorithm, which had two typical problems. First, in the case of unordered variables, the BN structure was encoded as a chromosome chain formed by its adjacency matrix, which resulted in the problem that genetic operators might cause illegal BN structures, that is to say, the genetic operators were not closed to the BN structures. Second, under the assumption that the variables were ordered, the BN structure was encoded as a chromosome chain formed by the elements of the upper triangle of its adjacency matrix. Although the problem of unclosed genetic operators was overcome, the search space of BN structure was severely limited. Once the variables were sorted incorrectly, only suboptimal solutions could be searched for. In 2008, Lee et al. [11] proposed the dual genetic algorithm (DGA) which effectively solved the shortcomings of the CGA. The DGA coded the BN structure into pairs of chromosomes, of which, one that represented the topological order of variables consisted of the indexes of variables and the other that represented the conditional dependence between BN nodes in the specific topological order consisted of the elements of the upper triangle of the BN adjacency matrix. However, after the crossover operation of the DGA, the node order of the offspring and their parents was different, which led to a tremendous difference of the offspring and their parents so that the good characteristics of the parents could not be well transmitted to the offspring and therefore resulted in a large number of iterations and slow convergence of the algorithm. In order to solve this problem, In 2010, Lee et al. [12] proposed the matrix genetic algorithm (MGA). The algorithm encoded the network structure as a chromosomal chain linked by the upper and lower triangular matrices elements of the adjacency matrix and developed the new closed genetic operators. Experiments showed that the algorithm had fast convergence speed and more robust results. In addition, Guo et al. [13] proposed an approach of epistasis mining based on genetic tabu algorithm and Bayesian network named Epi-GTBN in 2019. This method used the tabu search strategy with memory to improve the crossover operator and mutation operator of the genetic algorithm, which improved the diversity of population, helped to obtain a more effective global optimal solution and accelerated the convergence speed of the algorithm. Literatures [9, 10, 11, 12, 13] are all score-based Bayesian network structure learning methods. With the increase of the number of nodes, the search space also increases exponentially, and it is easy to fall into local optimal solutions. Later, many GA-based hybrid BN structure learning methods had been proposed. For example, In order to quickly and accurately obtain the Bayesian network structure with the highest matching degree with the data set from the vast search space, in 2020, Dai et al. [14] proposed a hybrid algorithm in the dynamic constrained search space based on the improved genetic algorithm. The algorithm designed a new coding scheme and developed the new genetic operators and had good results in terms of the quality of final solution, convergence speed and running time. Jose et al. [15] also proposed a hybrid Bayesian network structure learning method, which used a single-node local discovery function to determine the superstructure in the constraint-based stage. Then Case-injected Genetic Algorithms (CIGAR) was used to search for the Bayesian network structure with highest score. Compared with a randomly initialized genetic algorithm and MMHC algorithm, this method was obviously better in the quality, convergence speed and accuracy of the final solution.
However, the existing BN structure learning methods based on genetic algorithms generally have the problem that the structure randomness of the learned Bayesian network is large, which leads to the difficulty of application. Moreover, when the size of the data set to be modeled is small, it is easy to lead to an inaccurate Bayesian network scoring function. Therefore, how to better learn Bayesian network structures in a small data set is a problem of more importance. Literature [16] proposed a hybrid BN structure learning method, that was ESL-GA. The ESL-GA limited the maximum number of parent nodes of network structures through the knowledge-driven strategy, which further reduced the search space in the process of evolution and improved the feasibility of calculation. It also solved the problem of data fragmentation to a certain extent and provided a feasible method for learning Bayesian networks of different scale with small training data. However, the accuracy and reliability of this method need to be further improved. Based on the idea of ensemble learning, this paper proposes a new Bayesian network hybrid structure learning strategy based on ESL-GA algorithm integration, named EN-ESL-GA, and carries out performance analyses through simulation experiments of the proposed algorithm.
The main contributions of this paper are as follows:
This paper introduces the idea of ensemble learning to improve the ESL-GA algorithm, and proposes a hybrid BN structure learning method EN-ESL-GA which not only improves the applicability of BN structure learning algorithm to learn small sample data sets, but also improves the accuracy and stability of the learned BN structure, and solves the problem of low generalization to a certain extent. The performance of the EN-ESL-GA algorithm is compared with two traditional BN structure learning methods (K2 [17], Maximum Weight Spanning Tree named MWST [18]) and several BN structure learning methods based on genetic algorithm. It is found that the final BN structure learned by the EN-ESL-GA algorithm has higher accuracy and reliability. However, due to the parallel integration of the ESL-GA algorithm, the time complexity of the EN-ESL-GA algorithm is high, so that the EN-ESL-GA algorithm is only suitable for BN structure learning of small and medium-sized networks under the condition of limited hardware conditions.
The remainder of this article is organized as follows. Section 2 introduces the relevant basic theoretical knowledge. Section 3 gives a detailed description of the ESL-GA algorithm and the proposed EN-ESL-GA algorithm. In Section 4, the simulation study is carried out, including the performance comparison of the EN-ESL-GA algorithm and the existing GA-based BN structure learning algorithm in learning standard BN networks of different sizes and the advantages and disadvantages analysis of the EN-ESL-GA algorithm itself. The fifth section summarizes and looks forward to the full text.
Basic conceptions
Bayesian networks
Definition and representation of Bayesian networks
Bayesian networks, also known as belief networks, are graphical networks based on probabilistic reasoning. Bayesian networks not only have a solid theoretical basis of probability but also can well depict the complex dependence between variables involved in practical problems. It is a very effective analysis tool for uncertain knowledge expression and reasoning.
Assuming that the research object involves
Bayesian networks satisfy the assumption of conditional independence, that is, given the parent node set of a node, the node is independent of its non-descendant nodes [19]. Therefore, the joint probability distribution of the Bayesian network can be expressed as:
where
Learning BN structures from an observational data set aims to find the network structure that can best reveal the dependence relationships between the variables of the data set. In the existing studies, learning the structures of Bayesian networks from observation datasets can be divided into structure learning under complete datasets and structure learning under incomplete datasets. The algorithms for structure learning under complete datasets can be roughly divided into three categories: the constraint-based method, the score-based search method and the hybrid learning method.
(1) The constraint-based method
The constraint-based method usually uses statistics or information theory to measure the conditional independence or dependence between variables, so as to determine the optimal Bayesian network structure. At present, there are two ways to limit the relationships between variables: one is the missing constraint of the connecting edge which judges the conditional independence relationship between two variables by performing the conditional independence tests. If the two variables are conditionally independent in a certain constraint set, it is considered that there is no connecting edge between the two variables. The other is the existence constraint of the connecting edge which uses the methods of information theory to measure the dependence between variables. If the correlation between two variables is strong, it is considered that the connecting edge between the two variables must be in the BN structure we are going to study.
The advantages of the constraint-based method lie in the fact that it has relatively high learning efficiency and can obtain the global optimal network structure. However, this kind of algorithm also has many disadvantages: the number of conditional independence tests required to judge the dependency between variables may increase exponentially with the increase of the number of nodes, which greatly increases the computational complexity, and thus affects the reliability and accuracy, especially for the high-order conditional independence tests.
(2) The score-based search method
The score-based search method can be regarded as an optimization problem which searches for the Bayesian network structure with the best score under a specific scoring function by selecting the appropriate search algorithm and scoring function.
Scoring functions which are related to the computational complexity and accuracy of BN structure learning algorithms are measures to evaluate the matching degree between the learned network and the actual network. Scoring functions include the scoring functions based on information theory (such as Minimum Description Length (MDL) [20]) and the scoring functions based on Bayesian statistics (such as Bayesian Dirichlet with likelihood Equivalence (BDe) [21]). The BDe and a uniform joint distribution (BDeu) scoring function will be adopted in this paper.
The BDeu scoring function is a kind of Bayesian scoring function, whose core idea is to learn the network structure with the maximum posteriori probability based on the prior knowledge and the data set. When it comes to learning the structure of a Bayesian network, the structure
To maximize the above equation, for convenience, defining
is the Bayesian scoring function of the network structure
Suppose that
then the corresponding BDe scoring function can be obtained:
where
When
After the scoring function is determined, the problem of Bayesian network structure learning becomes the problem of choosing which search strategy to search for the optimal scoring network structure. The performance of the selected search algorithm directly determines the search efficiency of the BN structure learning strategy.
Although the score-based search method can find a better network structure, it is difficult to find the global optimal network structure because of the huge search space.
(3) The hybrid learning method
The hybrid learning method combines the constraint-based method with the score-based search method. The former is used to reduce the search space and then the latter is used to learn the optimal Bayesian network structure in the reduced search space.
When solving practical problems, our goal is to find a model with good and stable performance in all aspects. However, No-Free-Lunch theorem [23] shows that the models we find have their own preferences and it is difficult and impossible to cover all the bases. The core idea of ensemble learning is to combine multiple weak learners to obtain a better and more comprehensive strong learner, which provides an idea for finding a better model to solve complex problems [24].
Ensemble learning methods can be divided into sequence ensemble methods and parallel ensemble methods according to whether there is strong dependence between individual learners. The sequence ensemble methods make use of the dependence between individual learners and adjust the distribution of training samples through the performance of previous individual learner so that the samples that are not correctly learned by the previous individual learner can receive more attention in the follow-up individual learner, and finally the results of each learner are combined. The representative algorithm for this class of methods is Boosting. The parallel ensemble approaches represented by Bagging utilize the independence between individual learners to optimize the final learner. The basic process of Bagging is to use the Bootstrap method to sample several sample sets with the same capacity as the training sample size, then learn each sample set on the base learner, and finally combine all the results of the base learner to obtain a more stable and reliable learner.
EN-ESL-GA algorithm construction
ESL-GA algorithm
Establishment of superstructure
The superstructure of a Bayesian network refers to the initial undirected graph structure generated in the analysis stage of the dependence between variables. Since both the initial population and the final BN structure are composed of the directed acyclic subgraphs of the superstructure, it is necessary to keep the false negative rate as low as possible to avoid deleting the optimal solution by mistake when determining the superstructure. The measures used to estimate the statistical independence between variables in Conditional independence (CI) tests include the Pearson’s chi-square test and the
Population initialization
Based on the superstructure, the edges in the superstructure are randomly oriented or deleted to obtain some directed subgraphs of the superstructure, and then the method of minimum feedback arc set is used to remove the loops of the illegal graph structures in these directed subgraphs to obtain the directed acyclic graphs. In order to enhance the computational feasibility and reduce the search space at the same time, according to the naive limit operation of maximum number of parent nodes, the maximum number of parents of all nodes for all the directed acyclic graphs is set to MP, that is, when the number of a node’s parent nodes is more than MP, a parent node of the node is removed randomly at a time, until the number of the node’s parent nodes is to MP. In this way, we have our initial population.
An adaptive genetic algorithm
ESL-GA algorithm is a kind of hybrid method of Bayesian network structure learning. The algorithm considers that the elite set has good gene structures and excellent characteristics, and a deep study of the information model that the elite set contains is more advantageous to search for the optimal solution, and in view of this, an adaptive genetic algorithm guided by a diversity elite set under the restriction of the maximum number of parent nodes is proposed. Firstly, the position weight matrix is constructed based on the elite set and is regarded as the information pattern matrix contained in the elite set. Secondly, an adaptive mutation strategy is proposed, and the adaptive mutation probability of each locus of each individual in the population is derived from the position weight matrix, which keeps the balance between exploration and exploitation ability in the process of evolution. In addition, in order to further reduce the search space in the whole evolution process and improve the computational feasibility, the maximum number of parent nodes in the network is limited based on the knowledge-driven strategy. The adaptive genetic algorithm mainly includes the following basic steps.
(1) Select the elite set
Suppose that
In order to keep the balance between exploration and exploitation in the process of evolution, the diversity of the elite set should be maintained to a certain extent.
Let
(2) Construct the position weight matrix
Construct the information pattern matrix contained in the elite set, namely the position weight matrix (PWM), as shown in Eq. (8),
(3) An adaptive mutation strategy
The adaptive mutation probability of individuals at each location is derived from the position weight matrix. The basic idea is to generate high mutation probability for sites whose state does not propagate in the elite set, and conversely, to reduce mutation probability for the ‘good’ sites.
Flow chart of ESL-GA algorithm.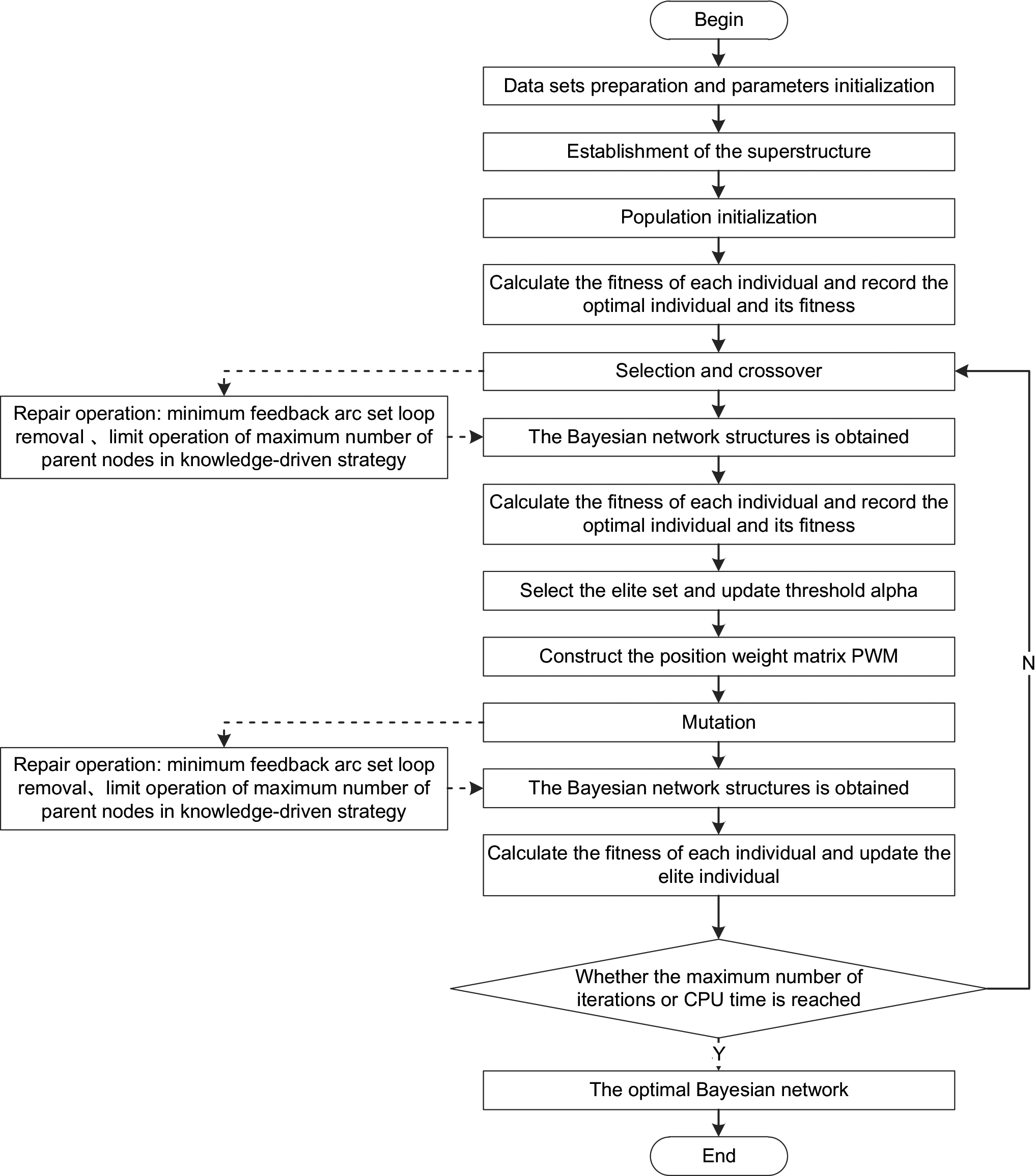
Compare
(4) Limit operation of maximum number of parent nodes in the knowledge-driven strategy
Every time after completing the operation of removing loops for illegal graph structures, the limit operation of maximum number of parent nodes based on the knowledge-driven strategy is carried out. Specifically, the parent node weight vector (PWV) which defines key-value pairs for each node is built in accordance with the PWM. The keys of each node are given by indexes of nodes other than that node and the value for each key is the weighted probability of the edge (the node corresponding to each key points to that node) that appears in the elite set with fitness of the individual as the weight. If the number of parent nodes of a node is greater than the maximum number of parent nodes (MP), leave MP values with relatively large values in the key-value pairs corresponding to the node, and the nodes corresponding to the keys of these MP values are the parent nodes of the node.
(5) Design of other operators
In the design process of ESL-GA algorithm, the selection operator adopts the improved fitness proportion selection method with elite reservation strategy, which improves the global convergence of the genetic algorithm. The crossover operator randomly selects a mate for each individual in the population, and the state of alleles at each locus of the combined individual is determined by the random selection of the states of alleles at the corresponding loci of the two parents.
The specific flow chart of ESL-GA algorithm is shown in Fig. 1.
EN-ESL-GA algorithm
In order to further improve the accuracy and reliability of ESL-GA algorithm learning Bayesian network structures, and make ESL-GA algorithm better applied to practical problems, this paper introduces the parallel integration idea into ESL-GA algorithm and proposes a new hybrid Bayesian network structure learning algorithm named EN-ESL-GA.
EN-ESL-GA performs an ensemble learning on the Bayesian network structures learned 20 times based on ESL-GA. Firstly, 20 sample data sets are randomly sampled from the original data set, and ESL-GA algorithm is used to learn the Bayesian network structure on each sample data set, and the adjacency matrix and BDeu score of the Bayesian network obtained from each learning are recorded. Secondly, the BDeu score of each network is normalized and used as the weight of the corresponding adjacency matrix of each network, and the transition matrix representing the strength of causality between variables is obtained by weighted average of all adjacency matrices, and the weak edges of the transition matrix are filtered out according to a preset threshold, and a fusion matrix is obtained. Finally, the operations of loop removal and the limit of maximum number of parent nodes are performed on the fusion matrix to obtain the adjacency matrix of the integrated Bayesian network, so as to obtain the final Bayesian network structure. The pseudocode of EN-ESL-GA is shown in Algorithm 1 (Table 1).
The pseudocode of EN-ESL-GA
The pseudocode of EN-ESL-GA
Preparation for experiments
Based on the Bayesian network toolbox BNT in MATLAB, this paper uses MATLAB programming to learn Bayesian network structures. The operating system is Windows10 (64bit), CPU is 2.4GHz and memory is 16GB.
In the experiments, two standard networks of different sizes are selected from Bayesian Network Repository (
Evaluation indicators
In order to evaluate the performance of Bayesian network structure learning algorithms, three indicators of F1 value, sensitivity and specificity are used to evaluate the learned Bayesian networks. The related formulas are shown in Eqs (10)–(13). Among them, F1 value balances precision rate and recall rate. Sensitivity, namely the true positive rate, represents the ratio of the number of correct edges learned in the current network to the number of existing edges in the standard network. Specificity refers to the ratio of the number of edges that do not exist in both the current network and the standard network to the number of edges that do not exist in the standard network, namely the true negative rate. The closer these three indicators are to 1, the more accurate the Bayesian network we have learned.
Simulation experiments of performance comparison between the EN-ESL-GA algorithm and other algorithms
In order to explore the Bayesian network structure learning performance of the EN-ESL-GA, there are six algorithms, namely K2, MWST, HSL-GA standing for Hybrid Structure Learner using Genetic Algorithm [26], a Diversity-Guided Site-specific Rate Genetic algorithm (DigSiR-GA) [25], DiGSiR-GA using the Parent Set Crossover operator (DiGSiR-GA-PSX) [27] and ESL-GA [16], used as comparison algorithms. Considering the randomness of the data set and the algorithm itself, all algorithms are run on 20 different random samples of the same size, and the average performance indexes of each algorithm are recorded. In addition, since K2 algorithm and MWST algorithm are both deterministic algorithms, in order to ensure fairness, the node order is randomly determined as the input of K2 algorithm in each experiment without prior knowledge. Similarly, since MWST algorithm requires a predetermined root node, a randomly generated root node is used for each structure learning. Parameter Settings of other methods based on genetic algorithm remain consistent, and specific Settings are shown in Table 2.
Parameter settings
Parameter settings
Performance comparison between EN-ESL-GA algorithm and other algorithms in different data sets
Table 3 shows the structure learning performance comparison results of the EN-ESL-GA algorithm and other algorithms under the data sets of 100, 500 and 1000 samples sampled for 20 times on the small network ASIA and the medium network ALARM respectively. Among them, Bayes score records the average BDeu score of the networks learned by each algorithm. The EN-ESL-GA algorithm integrates the 20 times running results of the ESL-GA algorithm. The running time is mainly spent on calculating the BDeu score for many times, which is almost the same as the time spent on the 20 runs of the ESL-GA algorithm. It should be noted that the performance of the EN-ESL-GA algorithm in Table 3 records the final results rather than the average.
In order to make a much clearer comparison of the structure learning performance of various algorithms under different data sets, bar graphs of structure learning performance are drawn according to Table 3, as shown in Fig. 2. Combined with Table 3 and Fig. 2, it can be seen that:
Bar graphs of structure learning performance of various algorithms in different data sets.
Apart from the fact that EN-ESL-GA algorithm is comparable to the MWST algorithm in ALARM500 and ALARM1000 data sets, EN-ESL-GA is significantly better than other algorithms in F1 score, sensitivity and specificity. Compared with learning the medium network structures, the five evolutionary algorithms (HSL-GA, DigSiR-GA, DiGSiR-GA-PSX, ESL-GA and EN-ESL-GA) have higher accuracy in learning the small network structures and significantly less algorithm execution time.
According to the principle of EN-ESL-GA algorithm, to a certain degree, the performance of EN-ESL-GA algorithm depends on whether the BN structure learned by ESL-GA algorithm can converge to better results. Fig. 3 shows the curve of the average BDeu score of BN structures learned by HSL-GA, DiGSiR-GA, DiGSiR-GA-PSX and ESL-GA under different data sets with the number of iterations. As can be seen from Fig. 3:
Variation curves of average BDeu score of BN structures of various algorithms under different data sets.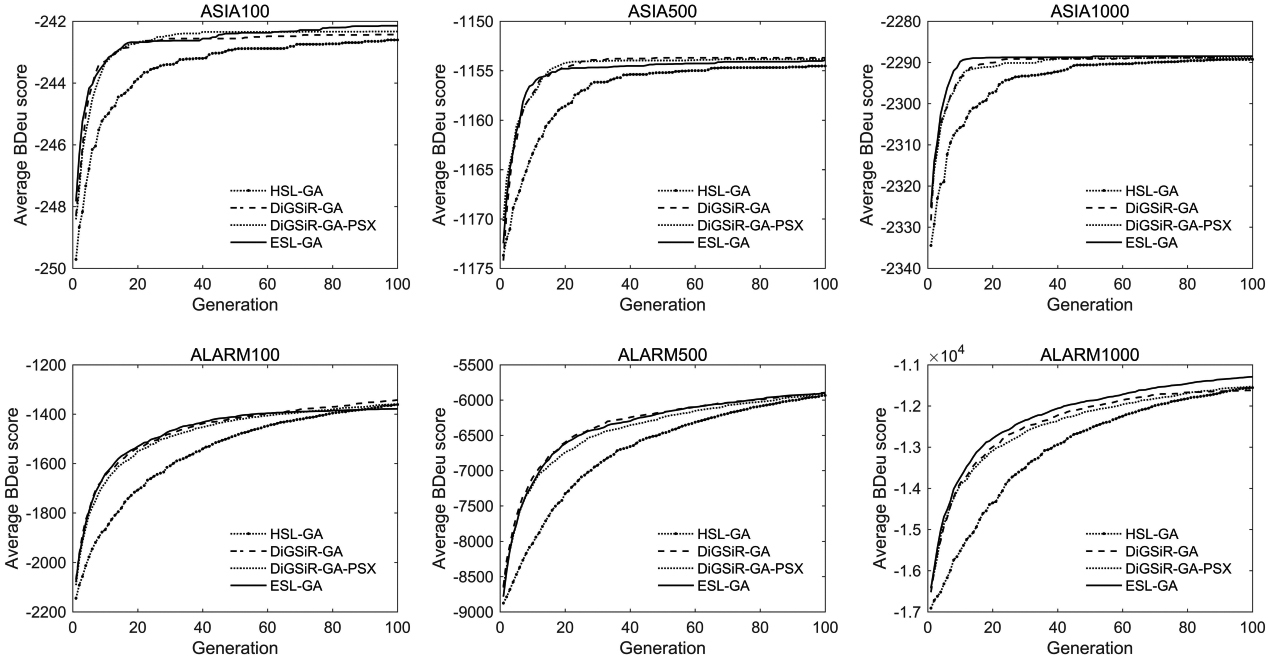
In the case of 100 and 1000 samples when learning the ASIA network, the average BDeu score of the optimal structure in the initial population of ESL-GA algorithm is higher than that of other algorithms, and ESL-GA algorithm finally converges to the BN structures with a higher average BDeu score; although the average BDeu score of BN structures learned by ESL-GA algorithm on ASIA500 is better than that of HSL-GA algorithm, it is still slightly worse than that of DigSiR-GA algorithm and DigSiR-GA-PSX algorithm, which is probably affected by the structural performance of the initial population networks. It can be seen from the learning results of the ASIA network that the convergence speed of ESL-GA algorithm is relatively fast, but when the sample size is small, the BN result may fall into the local optimal structure if the number of iterations is small. In practice, the maximum number of iterations can be adjusted appropriately according to the size of the observational data set. When the sample size is sufficient, the maximum number of iterations can be reduced properly to save the running time of the algorithm. When the sample size is small, the number of iterations should be large enough to avoid local convergence of the algorithm. When learning the ALARM network, with the increase of sample size, the ability of ESL-GA algorithm to learn better BN structures becomes stronger. On the data set ALARM1000, the average BDeu score of BN structures learned by ESL-GA algorithm is basically always greater than that of the other three algorithms in the whole iterative process. However, due to the insufficient number of iterations, none of the four evolutionary algorithms has yet converged. It is suggested that we set a larger number of iterations when learning a larger network, so as to obtain a network with better performance and ultimately improve the performance of EN-ESL-GA algorithm.
(1) Applicability analysis of EN-ESL-GA
Although the EN-ESL-GA algorithm solves the problem that the accuracy and reliability of learning Bayesian network structure are not high when the training dataset is small, its time complexity which is mainly spent on calculating multiple times BDeu scores increases greatly with the increase of network scale. Therefore, the algorithm is only suitable for learning BN structure of small-sized and medium-sized networks under the condition of limited hardware conditions.
(2) Reliability analysis of EN-ESL-GA and the model average of EN-ESL-GA (MA-EN-ESL-GA)
Performance changes of EN-ESL-GA algorithm and MA-EN-ESL-GA algorithm on the ASIA dataset.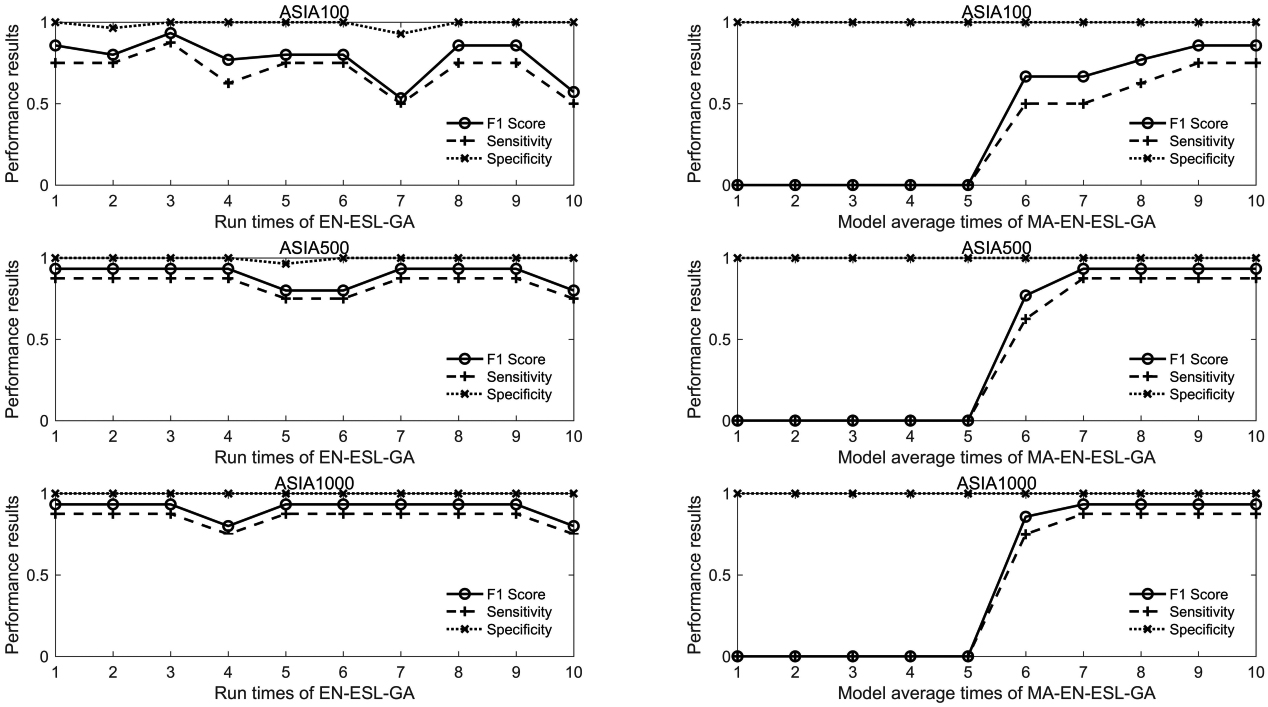
Performance changes of EN-ESL-GA algorithm and MA-EN-ESL-GA algorithm on the ALARM dataset.
The EN-ESL-GA is performed 10 times on different scale data sets to explore its stability. The left part of Figs 4 and 5 respectively presents the performance results of each EN-ESL-GA structure learning in ASIA and ALARM networks with different data set sizes. As can be seen from Fig. 4, as far as ASIA network is concerned, the running results of EN-ESL-GA algorithm on the datasets ASIA100 are unstable. However, with the increasing size of datasets, the results of EN-ESL-GA algorithm running for 10 times are relatively stable. As can be seen from Fig. 5, EN-ESL-GA algorithm has fluctuations when learning the structures of the ALARM network, but it is generally stable.
In practical problems, when constructing the Bayesian network structure, the network structure is not known in advance. We cannot select a better network through the three performance indicators of F1 score, sensitivity and specificity, and we can only rely on the BDeu score of the network. In this case, the reliability of the model becomes particularly important. In view of this, aiming at the unstable situations of the EN-ESL-GA mentioned above, the MA-EN-ESL-GA is proposed by averaging the results of 10 times of EN-ESL-GA learning to improve the reliability of the model. The MA-EN-ESL-GA simply averages the adjacency matrices of the Bayesian networks obtained from 10 times results of EN-ESL-GA, filters the invalid edges according to a predetermined threshold and repairs the obtained matrix, thereby obtaining the final Bayesian network structure.
The right parts of Figs 4 and 5 describe the performance changes of MA-EN-ESL-GA with the average running times of the model. Experiments show that the MA-EN-ESL-GA algorithm has good convergence and it achieves good results in learning the small network ASIA, especially in the data set ASIA100. The F1 score, sensitivity and specificity of the network are 0.857, 0.750 and 1.000, respectively; by contrast, the F1 score, sensitivity and specificity of EN-ESL-GA are 0.667, 0.625 and 0.964, respectively, which suggests that MA-EN-ESL-GA overcomes the instability caused by data sampling and the algorithm itself and can be well applied in practice. However, MA-EN-ESL-GA algorithm is not better than EN-ESL-GA algorithm in learning the medium-sized network ALARM, and the running time of single ESL-GA algorithm on the medium-sized networks is much longer than that on the small-sized networks. Therefore, MA-EN-ESL-GA algorithm is only suitable for learning the small network structures.
(3) Effect of alpha1 on EN-ESL-GA
The sample_bnet() function is used to sample the data sets of size 1000 20 times from the ASIA network as the data input of the EN-ESL-GA algorithm, and the sensitivity test of alpha1 on the performance of the EN-ESL-GA algorithm is carried out. The results are shown in Table 4, and it can be seen that the value of alpha1 is not sensitive to the performance of the final result of the execution the algorithm EN-ESL-GA.
Effects of different alpha1 on evaluation indicators
To solve the problem that the accuracy and reliability of learning Bayesian network structures are not high when the training data set is small, this paper introduces the idea of ensemble learning and proposes a new hybrid Bayesian network structure learning algorithm based on ESL-GA algorithm, namely EN-ESL-GA algorithm. EN-ESL-GA algorithm is Bagging integration based on the Bayesian network structures learned by ESL-GA algorithms. EN-ESL-GA algorithm takes the BDeu score (normalized) of the network structure learned each time as the weight, carries out weighted average of the adjacency matrices, and filters out the network structure that extremely corresponds to the correlation between variables. EN-ESL-GA algorithm not only inherits the advantages of ESL-GA algorithm but also improves the accuracy and stability to a large extent. Experiments on the small network ASIA and the medium network ALARM show that EN-ESL-GA has better structure learning performance than other algorithms. However, with the increase of network size, the time complexity of the algorithm increases greatly. In addition, aiming to solve the problem that the reliability of EN-ESL-GA algorithm for learning network structures is not high when the data scale of the small network ASIA is small, this paper proposes MA-EN-ESL-GA algorithm. The algorithm is only suitable for learning small BN structures, but it can improve the reliability and accuracy of BN results to a certain extent.
The effect of initial population network structure performance and parameter settings on the algorithm will be further studied. In particular, in view of the problem of large time complexity of EN-ESL-GA algorithm and MA-EN-ESL-GA algorithm, it is worth further discussion to break through the limitation of hardware conditions and use parallel computing.
Footnotes
Acknowledgments
We sincerely thank all those who contributed valuable comments to this article.