
Abstract
Question Answering based on Tabular and Textual data is a novel task proposed in recent years in the field of QA. At present, most QA systems return answers from a single data form, such as knowledge graphs, tables, texts. However, hybrid data including structured and unstructured data is quite pervasive in real life instead of a single form. Recent research on TAT-QA mainly suffers from the higher error of extracting supporting evidences from both tabular and textual content. This paper aimed to address the problem of failure evidence extraction from more complex and realistic hybrid data. We first proposed two types of metrics to evaluate the performance of evidence extraction on hybrid data, i.e. wrong evidence ratio (WER) and missing evidence ratio (MER). Then we utilize a candidate extractor to obtain supporting evidence related to the question. Third, an origin selector is designed to determine from where the question’s answer comes. Finally, the loss of origin selector is fused to the final loss function, which can improve the evidence extraction performance. Experimental results on the TAT-QA dataset showed that our proposed model outperforms the best baseline in terms of F1, WER and MER, which proves the effectiveness of our model.
Keywords
Introduction
Question answering (QA) is to answer the corresponding questions giving a certain background information, and the information may be a sub-graph of knowledge graphs [1], a segment of text [2], or a table [3]. Unstructured text data contain implicit knowledge, while they can be easily accessed through the Internet; Structured tabular data emerges with small quantity and good quality. Structured knowledge graphs are more conducive to solve the task of multi-hop QA. Triples in the knowledge graph can be extracted from both structured and unstructured data, however, the knowledge graph is built at the cost of heavy manpower. In the real world, hybrid data including textual and tabular data is more pervasive in different scenarios such as weather forecast scripts, scientific literature, and financial report in which the textual data act as a complement for the tabular data. QA based on hybrid data has attracted great attention from academia and industry in recent years [4, 5].
An example of TAT-QA.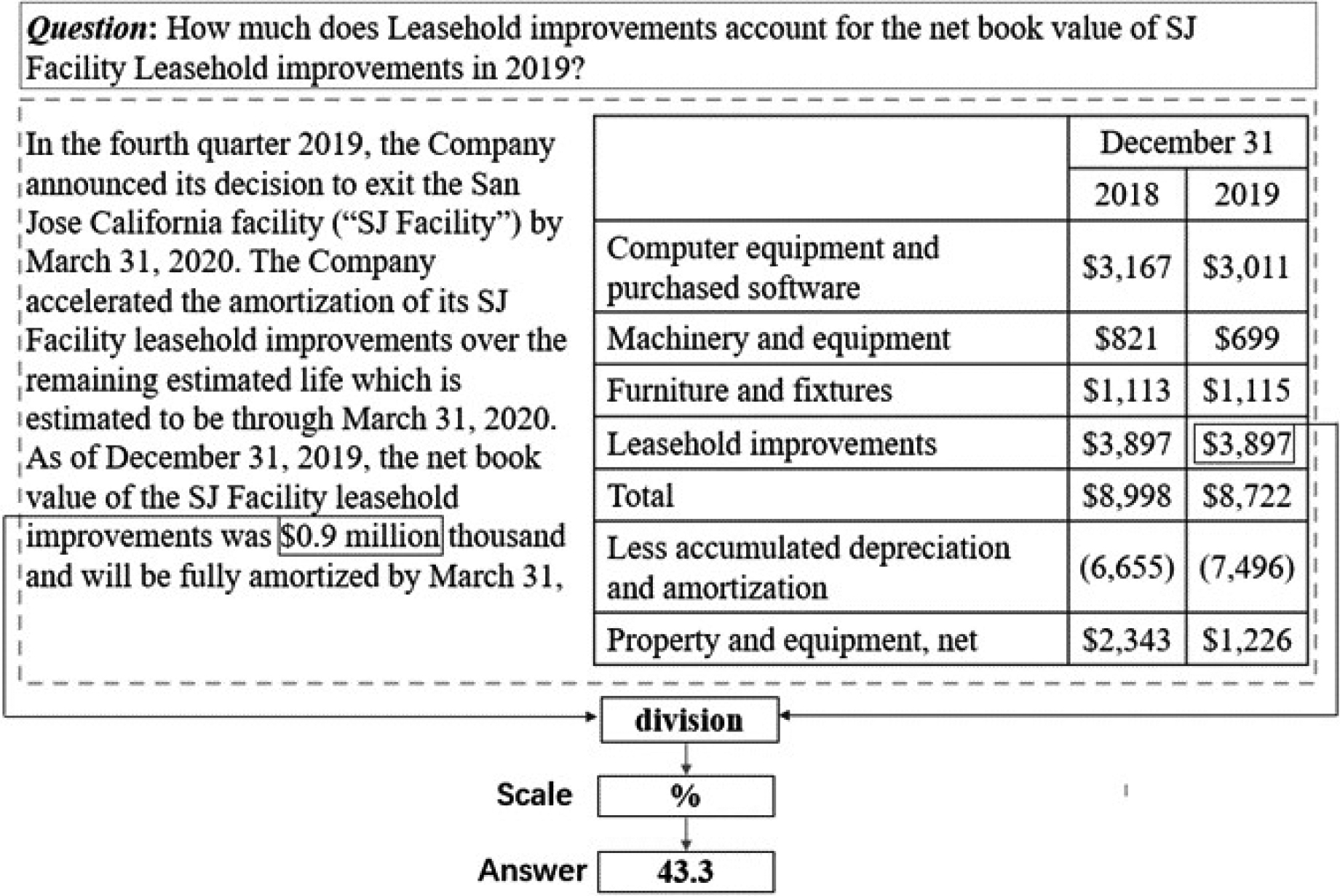
Existing QA system mainly predicts the answer of questions from a single format of data source, e.g. [6, 7, 8] only utilized unstructured text to answer questions, and [9, 10, 11, 12] utilized semi-structured tables. Since hybrid data is quite common, QA on hybrid data are proposed recently. [13, 14] obtain knowledge from incomplete knowledge graphs and related texts to answer questions, where incomplete knowledge graphs are obtained by randomly hiding knowledge graph triples. However, existing large-scale question answering datasets were originally designed to use either structured or unstructured knowledge during annotation, which greatly hindered the development of QA on hybrid data. Hybrid QA dataset is constructed to develop and evaluate QA systems, which contains about 1700 questions [15]. [2] proposed a large-scale questions answering dataset called HybridQA, in which the supporting information is acquired from hybrid data and the answer is obtained by reasoning. [4] proposed a new dataset containing both Tabular and Textual data, named TAT-QA, where numerical reasoning is usually required to infer the answer, such as addition, subtraction, multiplication, division, counting, comparison/sorting, and their compositions, and the corresponding baseline model TAGOP is proposed, which utilizes sequence tagging to extract relevant information from hybrid data, and uses a series of symbolic operations to infer on relevant information to get the answer to the question. However, the performance of TAGOP, which achieved 51% and 58% in terms of EM and F1 respectively, lags far behind the performance of both human and state-of-the-art KBQA system. In order to demonstrate the difficulty of QA based on hybrid data, an example is shown in Fig. 1, in which as for How much does Leasehold improvements account for the net book value of SJ Facility Leasehold improvements in 2019?, one needs to get Leasehold improvements in 2019, i.e. 3,897 thousand from the table and the net book value of SJ Facility leasehold improvements, i.e. 0.9 million, from the text. Error analysis experiment result from [4] showed that 55% error type comes from Wrong Evidence, which means that the model obtained the wrong supporting evidence, and 29% from Missing Evidence, which means that key evidences are incomplete. These two error types of real examples [4] are shown in Table 1.
Examples from TAGOP
From above one can conclude that the low performance of current QA models based on Hybrid data attributed to: (1) answer candidate segments are scattered across heterogeneous data, and one should determine whether candidate come from structured data or unstructured data or both; (2) Even model knows where candidates come from, single sequence tagging model such as RNN is not enough to extract supporting evidence from different data source, and it is obvious that different submodule should be used to tackle different types of data format. Both pose challenges in candidate segment extraction. Thus, the key factor to improve the performance of QA on hybrid data is to enhance the ability of candidate segment extraction.
In order to solve challenges mentioned above, in this paper multi-head attention mechanism is proposed to obtain rich semantic information related to the question from hybrid data, and a two-layer FFN is used to determine from where the answer to the question comes, and the loss of answer origination in FFN classifier is fused to the final loss function. In addition, Mean Reciprocal Rank (MRR) and Mean Average Precision (MAP) are used to evaluate the performance of candidate sentence selection model in textual data, however textual span, tabular cell or their compositions are extracted instead of candidate sentence in hybrid data. In order to acquire quantitative evaluation of comprehensive extraction performance, we propose two types of metrics to evaluate the performance of candidate segment extraction on hybrid data, i.e. WER and MER. The main contributions of this paper are as follows:
We propose to use candidate extractor, which is composed of two multi-head attention modules, to obtain supporting evidence related to the question from tabular and textual data respectively. Each module can obtain information from different representation sub-spaces. Each head focuses on different positions of the input sequence, which can learn multi-view relevant information from both tabular and textual data; We use origin selector to predict where the answer comes, which narrow the candidate selection scope and thus reduce the computational cost in subsequent steps, and the origin selector can be trained by minimizing the loss of origin selector; Two types of metrics, i.e. WER and MER, are proposed, both of which are used to evaluate the comprehensive performance of candidate segment extraction on hybrid data. Experiment results show that our model outperforms TAGOP in terms of F1, WER and MER on TAT-QA.
Some work in the QA system focused merely on text data, such as machine reading comprehension (MRC), e.g. BiDAF [16], Gated Attention Reader [17], QANet [18]; some work in QA research is based on tabular data, and related datasets includes SPIDER [10], TabFact [19], while other work in QA take the Knowledge Graph as input data for question answering [14]. Structured information based on tables or knowledge graphs has the disadvantage of low knowledge coverage, although data quality can be guaranteed. Textual data has the advantage of large amount and availability while noisy data existed in most cases and knowledge is hard to acquire. QA on hybrid data has just started in recent years. [5] proposed a large-scale QA hybrid dataset named HybridQA, in which the answer to a question needs to be obtained by simply reasoning in knowledge from heterogeneous information. [4] proposes a hybrid dataset TAT-QA related to financial field, which contains a large number of questions that require numerical reasoning, such as addition, subtraction, multiplication, division, counting, comparison, and sorting.
Supporting evidence extraction is a key sub-task in QA, which is to select sentences or critical evidences that contain or verify the right answers given a question. Most researchers proposed to use deep neural network to solve supporting evidence extraction: [20] considers semantic relationship between each question and answer using distributed representations; Since attention mechanism allows the model to selectively focus on critical parts of textual data, it is widely applied in evidence extraction. [21] proposes a model combining convolutional neural network with basic architecture and adding to attention mechanism. Unlike [21] aiming at representation of answers and questions, attention-based CNN is proposed in [22] to model a pair of sentences for answer selection. Sequential attention mechanism [23] is used to obtain the representation of candidate sentences, which is achieved by multiple steps of attention. Aiming at problems of missing clue annotation and multi-hop reasoning in multiple choice reading comprehension task, [24] proposes an evidence sentence extraction model based on multi-module combination. As far as we know, supporting evidence extraction in QA based on hybrid data largely ignored in existing research.
Model
Task description
The concerned task of QA over hybrid data is to answer the question given both tabular and textual data related to a given question. In this paper, we pay more attention to supporting evidence extraction over hybrid data. The goal of the task is to extract supporting evidence related to the question precisely and completely. Specifically, given a table
Model overview
The mainframe of our model is shown in Fig. 2. The model consists of two parts: Encoder with candidate extractor (3.3) and Reasoning layer with origin selection mechanism (3.4). Our supporting evidence extraction module is composed of origin selector and candidate extractor, in which origin selector is to predict which type of data source candidate segment located in, and candidate extractor executes specific extraction task on specific type of data source. Candidate extractor is the key part of encoder, and origin selector is incorporated into the reasoning layer.
In encoder with candidate extractor, we first apply RoBERTa [25] to encoder the question, tabular and textual data, and the context representation of question with background information, as well as representations of each sub-token are obtained. Then, we utilize two multi-head attention modules to extract supporting evidence related to question from textual and tabular data respectively in candidate extractor, since multi-head attention [26] can obtain information from different sub-spaces. Finally, tag predictor is to predict the label of each sub-token. In reasoning layer with origin selection mechanism, we have three classifiers and one origin selector, in which classifiers include operator classifier, number order classifier, scale predictor. Number order classifier and scale predictor are designed according to [4], while in this paper an origin selector is designed as a gate function that predict whether supporting evidence comes from textual or tabular data, and operator classifier to predict the correct operator obtained the answer to question, which includes eight aggregation operations instead of ten. The scale predictor is to predict the scale corresponding to the answer, and the number order classifier is to predict the order of two input numbers matters in the final result. In one word, Encoder with candidate extractor extract supporting evidence related to the question and Reasoning layer with origin selection mechanism reason over evidence segment to return the final answer.
The structure of our model.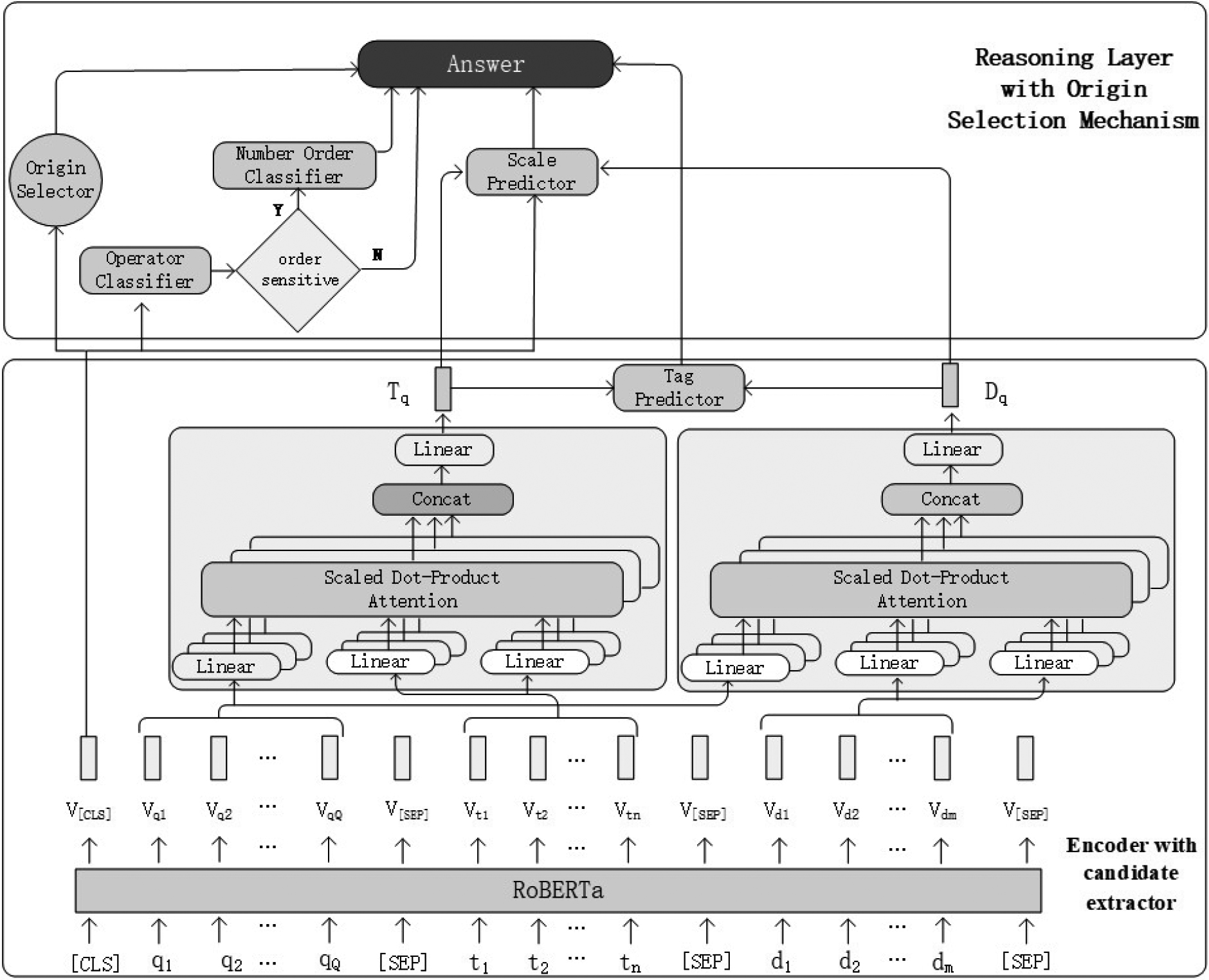
In this section, we first construct a sequence with length of
where the number of tokens in question, sub-tokens in the tabular data and textual fragment are
Then we use candidate extractor to extract candidate segments related to question from hybrid data, in which two multi-head attention modules are applied to textual and tabular data respectively:
where
Specifically, the vectorization of table
where
where
Finally, the representation of each sub-token is input into the tag predictor, which predicts labels of each sub-token. Specifically, the sub-token that can provide supporting evidence for the answer is marked as
where
Once supporting evidences are extracted from data, it is natural to compose these segments to get the final answer, during which the composition needs further reasoning. We concluded from the question answer pair samples that there are generally eight aggregation operations: None, Sum, Count, Average, Multiplication, Division, Difference, Change ratio. Unlike [4], we put the Span-in-text, Cell-in-table, Spans in a single origin selector, since the composition mode of these three extractions mode is quite different from that of the eight aggregation operators, and we argue that the separation of composition mode is helpful to improve the supporting evidence extraction’s performance since the selection of extraction mode and the aggregation operation are independent of each other. Experimental results in Section 4 also verify this argument.
In order to predict whether supporting evidence comes from textual or tabular data or both, we take the representation of [CLS] as the input of origin selector. The origin selector probability is calculated as follows:
where
In order to get the correct answer to the question, an operator classifier is used to predict right aggregation operator that help reasoning over the candidate segments. Specifically, we take the vector representation of [CLS] obtained from Roberta as input, and the operator classifier is calculated as follows:
where
Similar to [4], the scale predictor and the number order classifier is used to predict the scale of the answer and the number order in the situation of Difference, Division, and Change ratio. Each probability are formulated as:
where
According to origin selector, we can predict data source of the answer in hybrid data; the operator classifier can predict which operation to perform on the dataset. For operators that require the order of the operands, such as Division, Difference, Change ratio, we further use the number order classifier to predict the order of the input two numbers; the scale is obtained by the scale predictor, with which the numerical or string prediction is multiplied or concatenated as the final prediction to compare with the ground-truth answer.
Supporting evidence is obtained from Encoder with candidate extractor (3.3). The operator mode, the number order, the scale are obtained from Reasoning layer with origin selection mechanism (3.4), the final answer related to the question can be easily composited according to the operator mode, the number order, the scale for supporting evidences.
Considering the loss caused by origin selector, we redesign the loss function for our model:
where
Dataset and metrics
We use TAT-QA [4] dataset to evaluate the effectiveness of our model, which is a large-scale QA dataset containing tabular and textual data. Numerical reasoning is usually required to obtain the correct answer related to given questions, such as Counting, Summing, Multiplication, Subtraction, Division, Comparison/Sorting, and their compositions, since samples are extracted from the financial reports in which there are many numerical arithmetic operations. There are totally 16,552 question samples in TAT-QA, in which 7,431 samples of answers are from table data, 3,902 from text data, and 5,219 from both table and text, and TAT-QA is randomly divided into training set, test set and verification set according to 8:1:1.
Traditional evaluation metrics for candidate extraction are Mean Reciprocal Rank (MRR) and Mean Average Precision (MAP), which can be appropriate for candidate sentence selection model in textual data. However textual span, tabular cell or their compositions are quite complex, we propose two novel metrics to evaluate the performance of candidate segment extraction on hybrid data, i.e. Wrong Evidence Ratio (WER) and Missing Evidence Ratio (MER). Besides we use the popular numeracy-focused F1 [6] and Exact Match (EM) to evaluate the performance of our model. WER and MER are proposed in this paper to evaluate the comprehensive performance of supporting evidence extraction from hybrid data. Specifically, for sample i, the
Therefore,
where
Unlike precision and recall in F1, WER and MER is a soft evaluation metric, and can measure one single sample or a sample set, while precision and recall is unable to evaluate over one sample. The value of WER and MER can take in [0, 1].
From metrics described above, we know that WER can effectively evaluate the ability that the model recognizes wrong evidences, and it is obvious that the lower the WER is, the better the model can recognize the right evidences. MER can effectively evaluate the ability that the model completely recognizes all right evidences, and it is clear that the lower the WER is, the more supporting evidences the model can extract.
Note that BERT-RC and NumNet
We apply RoBERTa-Large to initialize the representations of questions, the row-flattened table data and text data, where the max length of a question is set to 46, and the max length of a row-flattened table and text is set to 463. The output dimension of RoBERTa-Large is 1024. Our model gets the best results when we set the number of heads to 3 and 2 respectively for both multi-head attention module over table and text. We set the max number of epochs to 50, and apply Adam optimizer to minimize the overall loss function with learning rate of 0.0005.
Experimental results
We compared our model with other baselines in terms of F1, EM, WER and MER on TAT-QA dataset. Experimental results are shown in Table 2.
Experimental results on TAT-QA
Experimental results on TAT-QA
Experimental results show that our model achieves the best performance on TAT-QA dataset, marked in bold, which proves that the candidate extractor can effectively extract supporting evidence related to questions from tabular and textual data. Specifically, two multi-head attention modules in candidate extractor can provide multi-level semantic information related to the question from hybrid data. Origin selector in reasoning layer can correctly locate candidate segments in hybrid data. WER and MER are used to evaluate the performance of extracting evidence from hybrid data. The ability of BERT-RC and NumNet
Besides, we further investigate the performance of our model and TAGOP in terms of different selection of operator, as shown in Table 3.
The performance of our model and TAGOP in terms of different selection of operator
Specifically, Table 3 shows the accuracy of the operator classifier and origin selector in the proposed model and TAGOP on the validation set and test set. It can be seen that our model is almost superior to TAGOP in span-in-text, cell-in-table and spans, which benefits from the ability of origin selector and reveals the difference of extraction mode and aggregation operation. Our model is consistent with of TAGOP in terms of the performance of eight aggregation operators, which indicates that our model has excellent classification ability. The performance of our model and TAGOP in multiplication operator is worse than that of other operators and this is because the number of samples that obtain the answer of question through the multiplication operation only accounts for 0.3% of the total number of samples in TAT-QA dataset [4].
Effect of multi-attention module
Candidate extractor can obtain supporting evidence related to the question from hybrid data, in which two multi-head attention modules is used to obtain the multi-level semantic information from the table and the text respectively. In order to evaluate the effectiveness of each part of the model, we conducted a series of ablation experiments on the TAT-QA dataset. Ablation experiment results are shown in Table 4. Specifically, we define three variant models:
Experimental results of model analysis
The second row in Table 4 demonstrates that multi-head attention module over table brings 1, 2.5 and 2.4 improvement of F1, WER and MER; the third row in Table 4 shows that multi-head attention module over text brings 0.5, 1.8 and 1.5 improvement of F1, MER and WER, which implies that these two components are effective for supporting evidence extraction, especially multi-head attention module over table. It can also be seen from the fourth row that full model outperforms model without both two components in terms of F1, WER and MER, brings 1.6, 3.4 and 2.7 improvement respectively.
Table 5 shows the impact of head number of multi-head attention when applying two multi-attention modules to extract supporting evidence in candidate extractor (3.3). We set the number of heads to around 3, since large number of head is empirically proved to decrease the final F1. We conduct a series of ablation experiments on head number selection with configuration of
Effect of the head number of multi-head attention
Effect of the head number of multi-head attention
To demonstrate the capability of extracting complete and correct evidence from hybrid data, we sample a typical case from experiment results, as shown in Fig. 3. We found that TAGOP can extract supporting evidence related to question from hybrid data, i.e. Belgium, France, Germany, Russia, but the information is incomplete, leading to a wrong answer 4. Our model can obtain the correct information related to question. Moreover, the information is complete, i.e. Belgium, France, Germany, Russia, South Korea, which proves our candidate extractor can capture complete and correct evidence related to the question, thus the correct answer 5 is naturally acquired.
Case analysis on TAT-QA.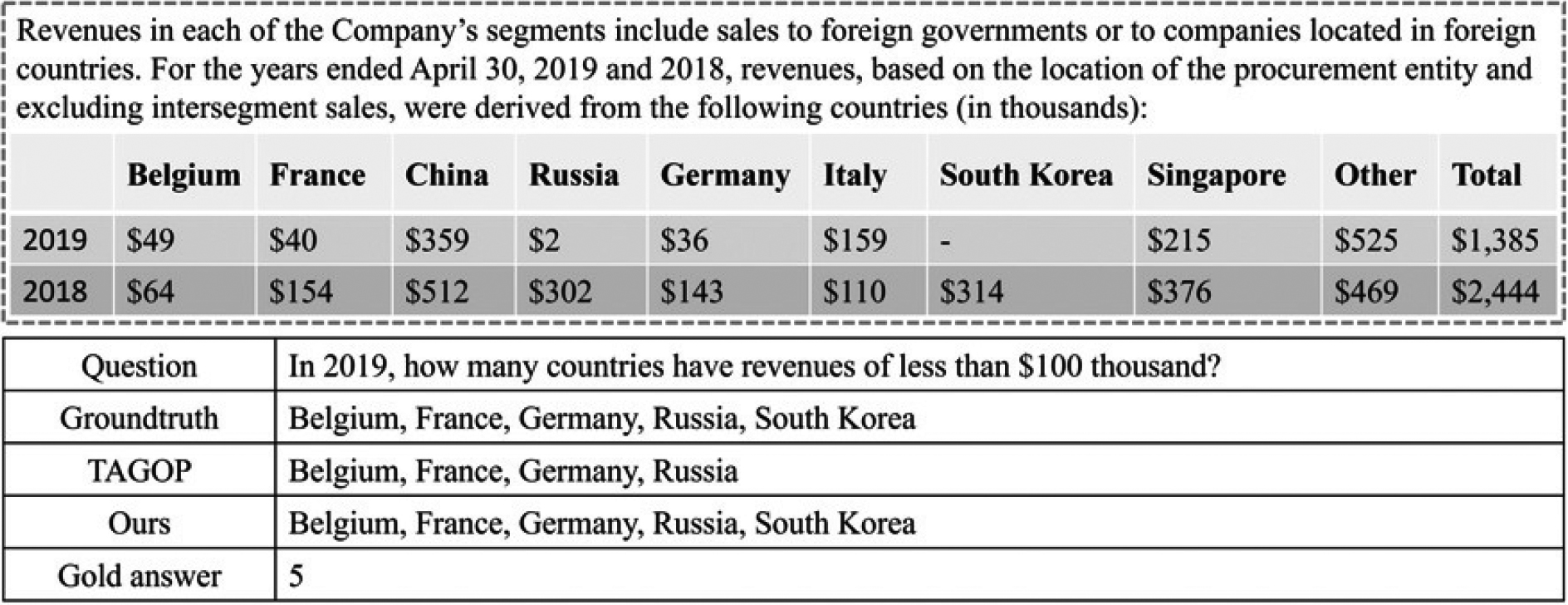
We proposed a new QA model over hybrid data, in which candidate extractor is proposed to obtain rich semantic information related to a given question, origin selector is proposed to determine from where the question’s answer comes and candidate extractor is realized by two multi-head attention mechanisms for tabular and textual data respectively. In order to evaluate the failure evidence extracting performance from more complex and realistic hybrid data, we proposed two types of metrics, i.e. WER and MER. Experiment show that our model outperforms TAGOP by 2.2 and 2.8 in terms of WER and MER respectively in TAT-QA dataset, which proved that our model can capture more supporting evidence instead of wrong evidence from hybrid data, and extract more comprehensive information.
In this paper, we mainly focus on supporting evidence extraction from hybrid data. In the future, we will do further research over numerical reasoning, both of which are two indispensable components in QA in the field of financial reports. Besides, existing work focus on single-layer reasoning, while reasoning in multi-loop is more common in most of the case. We will consider multi-loop numerical reasoning in QA over hybrid data as our future work.
Footnotes
Acknowledgments
This work was supported by National Key Research and Development Program (Grand NO. 2022QY0300-01), Natural Science Foundation of Shanxi Province (Grand NO. 202203021221021, 20210302123468, 202203021221001).