
Abstract
The Bayesian network classifiers (BNCs) learned from labeled training data are expected to generalize to fit unlabeled testing data based on the independent and identically distributed (i.i.d.) assumption, whereas the asymmetric independence assertion demonstrates the uncertainty of significance of dependency or independency relationships mined from data. A highly scalable BNC should form a distinct decision boundary that can be especially tailored to specific testing instance for knowledge representation. To address the issue of asymmetric independence assertion, in this paper we propose to learn k-dependence Bayesian multinet classifiers in the framework of multistage classification. By partitioning training set and pseudo training set according to high-confidence class labels, the dependency or independency relationships can be fully mined and represented in the topologies of the committee members. Extensive experimental results indicate that the proposed algorithm achieves competitive classification performance compared to single-topology BNCs (e.g., CFWNB, AIWNB and SKDB) and ensemble BNCs (e.g., WATAN, SA2DE, ATODE and SLB) in terms of zero-one loss, root mean square error (RMSE), Friedman test and Nemenyi test.
Keywords
Introduction
Classification is one of the key issues in machine learning and data mining [1, 2, 3]. Researchers propose to learn Bayesian network classifiers (BNCs) [4, 5] for classification and knowledge representation under condition of uncertainty. According to multivariate data analysis across disciplines, the learning procedure of BNCs can be divided into two parts: structure learning that models data in the form of directed acyclic graph (DAG), and parameter learning that estimates the joint probability based on the learned DAG. However, learning an optimal DAG from existent data is NP-hard [6].
Most learning algorithms assume that the instances for training are independently and identically distributed (i.i.d.) [7, 8]. That is, if the statistical model learned from training data can achieve the right estimate of probability distributions, then it can also fit each unseen instance from the testing data. Obviously this assumption is too tight for many applications[9, 10], and that may result in negative influence on the generalization performance [11]. By combining multiple models, an ensemble learner (e.g., Random Forest [12], AODE [13, 14] and AdaBoost [15]) can compensate the errors produced by any one of its members [16], and it works especially when the probability distributions learned from labeled training set as input can generalize to the testing data. In contrast, instance learning mines significant dependency relationships among random variables implicated in each instance, and the learned probability distributions can hopefully fit each instance if the wrong class labels are not introduced into the learning procedure.
For specific unlabeled instance, sometimes it is hard to differentiate one class label from the others among the most possible high-confidence ones. By removing the class labels with low-confidence information to alleviate the conditional independence assumption, the estimates of information-theoretic metrics will be calibrated and that may help enhance the robustness of the learned network topology [17]. Furthermore, labeled training data and unlabeled testing data both contribute to the completeness of knowledge, and when they work jointly to learn the right probability distribution, the final BNC will achieve the bias/variance trade-off. In this paper we propose to filter out low-confidence class labels and then build a Bayesian multinet classifier (BMC), called class-specific Bayesian classifier (CSB), which consists of two sets of class-specific BNCs in the framework of multistage learning [18]. The main contributions are as follows:
Class-specific information-theoretic metrics, e.g., Class-CMI or Micro-CMI, are introduced to identify asymmetric (conditional) dependence between attributes or attribute values. To improve the generalization performance, the training set and pseudo training set are partitioned according to high-confidence class labels, then local BNCs can be learned from each subset and fully represent the dependency or independency relationships implicated. The resulting highly scalable BMC learns an ensemble of class-specific k-dependence Bayesian classifiers in the framework of multistage classification. We compare the performance of our BMC with single-topology BNCs (e.g., CFWNB, AIWNB and SKDB) and ensemble BNCs (e.g., WATAN, SA2DE, ATODE and SLB). The local BNCs learned from training subsets or pseudo training subsets demonstrate significant advantage over KDB when they work independently or jointly. The experimental results of Friedman test [49] and Nemenyi statistics [50] show that our algorithm achieves competitive generalization performance while dealing with 28 datasets from different research domains, ranging in size from 32 to 1,025,010 instances and 4 to 64 attributes.
The rest of this paper is organized as follows: Section 2 briefly introduces the i.i.d. assumption for learning BNC and the framework of multistage classification. The basic idea and detailed learning procedure of CSB are described in Section 3. The experimental results of CSB and the comparisons with a set of state-of-the-art BNCs are presented in Section 4. To finalize, Section 5 shows the main conclusions and outlines future work.
Table 1 lists all the symbols which are used in this paper.
List of symbols used in this paper
List of symbols used in this paper
In the DAG of BNC over predictive attributes
Suppose that each unlabeled instance
Learning unrestricted BNC is often very time consuming and the inference for unrestricted BNC has been shown to be NP-hard [6]. Learning a pre-fixed or constrained topology is a practical approach to handling the intractable complexity [19, 20]. One of the most popular and effective approaches to addressing this issue is to learn restricted BNC, for which the DAGs take class variable as the root node. Correspondingly the joint probability distribution
where
The simplest restricted BNC is the naive Bayes (NB) classifier [21, 22, 23, 24], which assumes that the attributes are conditionally independent of each other given the class. As Fig. 1(a) shows, each arc points from the class to the attribute in the DAG of NB. NB exhibits excellent generalization performance and classification accuracy, and researchers attribute its success to its simplicity and high-confidence estimates of conditional probabilities [5, 21]. The joint probability for NB is decomposed as follows,
The independence assumption makes the topology of NB always remain the same while dealing with different kinds of datasets, and correspondingly the joint probability will not fit data well. When handling datasets with complex attribute dependencies, that will result in classification bias. However, the insensitivity of NB to the changes in training data helps it achieve low variance and robust generalization performance. To relax NB’s independence assumption which is too strict to hold in practice, researchers propose to add augmented arcs to the DAG of NB.
Examples of network topologies with four attributes for the BNCs: (a) NB; (b) TAN; (c) KDB (with 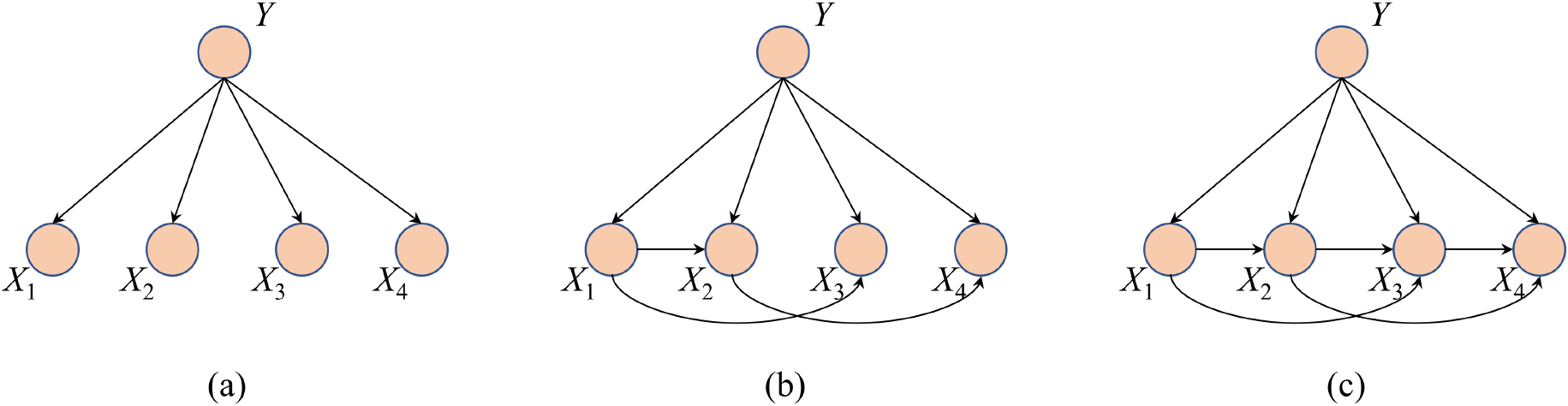
For learning BNCs from data, improving the topology of NB is an effective and efficient way to avoid the intractable complexity, and that has received great attention from researchers. An efficient machinery to manipulate and represent independence assertions is required in order to relax NB’s conditional independence assumption [5, 25]. To analyze qualitatively and measure quantitatively the mutual dependence and conditional dependence between random variables, the information-theoretic metrics, e.g., mutual information (MI) and conditional mutual information (CMI) [26], are widely applied in the learning procedure and provide a solid mathematical basis.
.
Mutual information (MI) I(X;Y) [26] measures how much information X bears on Y, and is defined as:
.
Conditional mutual information (CMI)
The absence of any conditional dependencies makes NB achieve high bias and low variance, whereas the full representation of all dependency relationships makes full BNC achieve low bias and high variance. To achieve the bias/variance trade-off, researchers propose to mine only the most significant dependency relationships implicated in data. The final probabilistic topology can be regarded as a spectrum of allowable dependence standing between NB and full BNC. Friedman [5] proposes tree-augmented naive Bayes (TAN) which learns one-dependence relationships by building a maximal weighted spanning tree [27]. By assuming that each predictive attribute can have at most
The vast majority of learning algorithms in statistics and machine learning assume that random variables or attributes follow the i.i.d. assumption [8]. The independence assumption of the i.i.d. assumption assumes that the samples are independent from the rest of them. Similarly, the identical distribution assumption posits the underlying distribution of each random variable or attribute is the same for all samples. The i.i.d. assumption is considered to be the foundation of model selection techniques such as cross-validation and bootstrapping in statistics and machine learning. Whereas, the i.i.d. assumption is too tight for many applications [9].
BNCs represent the dependency relationships among a set of domain attributes in the form of DAG, and ideally the conditional probability distributions encoded in the DAG can fit data well. However, the real-world data generating mechanisms mostly involve various heterogeneous entities with complex relationships. To guarantee high-confidence estimates of probability distributions, commonly the DAG only describes the most significant dependency relationships implicated in the relational data while the number of instances for training is limited. Different kinds of conditional independence assertions are proposed to simplify the topology of DAG, and that may bias the estimates of conditional probability distributions. Thus the identically distributed assumption is not appropriate for precisely learning BNC from data. Take dataset segment from the UCI machine learning repository [30] as an example. Suppose that segment consists of
The values of joint probability distribution on dataset segment for (a) NB and (b) KDB.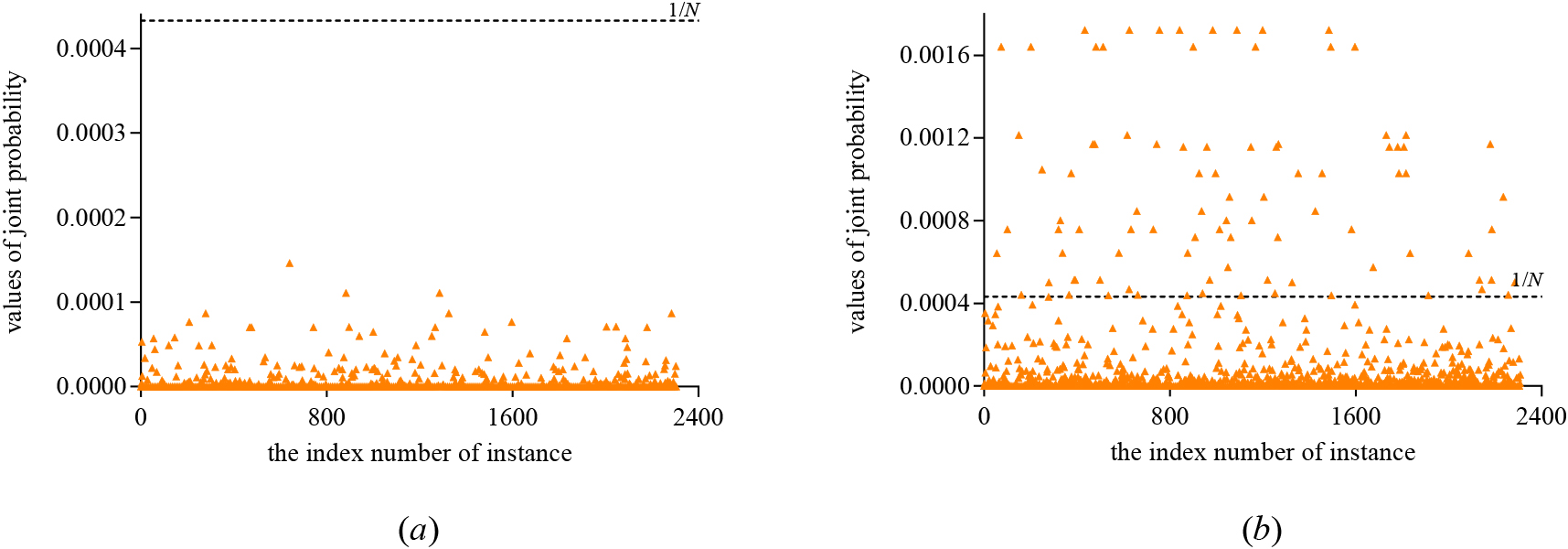
To address this issue, instance learning takes specific unlabeled instance or selected instances as the objective and learns the dependency relationships among attribute values [31]. Among instance-based learners, nearest neighbour algorithms [32] are supposed to be the simplest one. By applying domain specific distance function to learn the similarity among instances from training data, they assign the class label of the retrieved instance to the new instance.
One single BNC can represent limited number of dependency relationships and the estimate of joint probability may be biased. In contrast if the BNCs are combined as multistage classifier or ensemble, the dependency relationships may be fully represented and that will help calibrate the estimate of joint probability [37, 38]. Multistage classifier means a sequence of binary classifiers, guiding from the rough information about examined object at the early stages to the more detailed classification at the end. Silla and Freitas [39] empirically prove that adopting multistage or hierarchical classification methods to different application domains can decrease the misclassification rate. Multistage classification has been widely adopted in numerous pattern recognition fields, e.g., face recognition [40], age estimation [41], character recognition [42], and emotion recognition [43]. To overcome the weakness of Euclidean norm-based measure and improve the global recognition rates while dealing with noisy images, Grossi et al. [40] build up a cascading three-stage voting system based on the sparsity promotion worked out on the multi-feature dictionaries. For human age estimation, Liu et al. [41] also propose a three-stage learning, including age grouping, age estimation within age groups and decision fusion for final age estimation. Basu et al. [42] present a two-stage classifier which performs a coarse classification on the input pattern and then refines its earlier decision by selecting the true class from the group of candidate classes selected before. Poorna et al. [43] adopt multistage classification methodology to develop a speech emotion recognition algorithm based on Arabic speaking community.
Single-topology BNC, e.g., NB, TAN and KDB, represents the attribute dependencies over the entire dataset with one network topology. In contrast, Bayesian multinets (BMs), which are introduced in [44] and then studied in [5], compose of a series of local networks. Similar to the basic idea of clustering, an algorithm can assemble observations into groups which prior misconceptions and ignorance would otherwise preclude. To represent an asymmetric set of dependency relations between attributes, the whole dataset is partitioned into subsets according to the class labels, then each local network of BM is built on different subset. Alternatively, arbitrary partitions can be obtained, in which each partition has consistent dependency relations between attributes given the data subset which is in the partition. Therefore, more effective local BNCs can be built according to each data subset.
The topologies learned from a) dataset iris, b) subset with class label 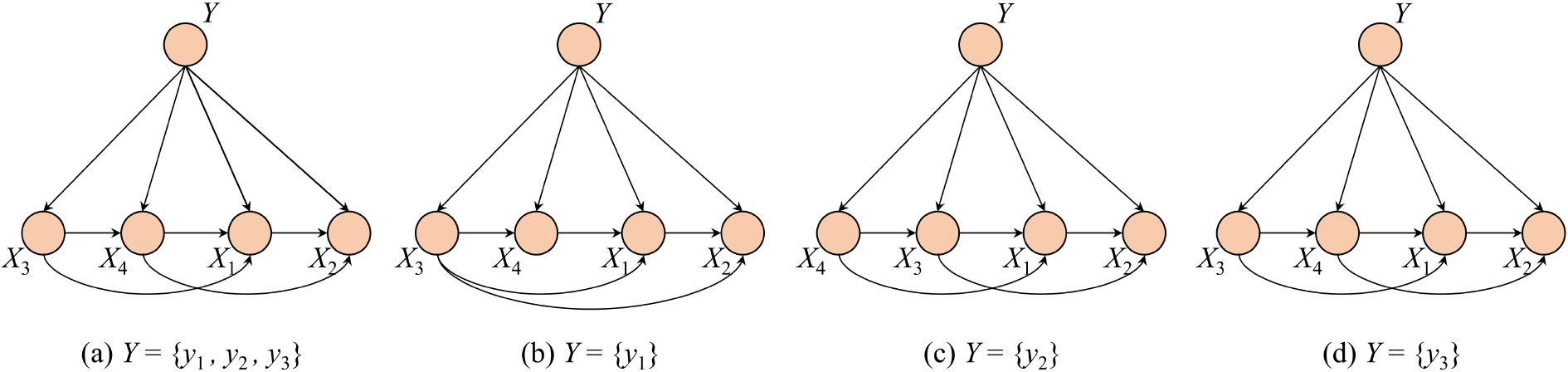
A BMC (Bayesian multinet classifier) consists of a prior probability distribution about the class and a series of local BNCs. Each local BNC corresponds to a label that the class variable can take. Figure 3 shows the topologies of BNCs respectively learned from dataset iris and partitioned subset
where
Different from the single-topology BNCs which have fixed dependency relations between attributes over all class labels, BMC allows diverse dependency relationships between the attributes for different class labels. A BMC can simulate single-topology BNC if there exists the same topology for all the local networks. The class variable in a BMC can be considered as a parent of all the attributes, and takes only one label in each local network. For example, the Bayesian Chow-Liu tree multinet classifier [45] builds each local BNC by adopting the Chow-Liu tree.
Asymmetric independence and symmetric independence
The independence assertions encoded in BNCs are likely to speed up knowledge acquisition or facilitate inference, whereas the significance of independence may vary from instance to instance.
.
[
44
]
.
[
44
] If
Asymmetric independence corresponds to asymmetries within decision trees, and asymmetric independence assertion is adapted from literatures over decision analysis [44]. Although researchers propose to extend traditional approaches considerably and make the topology of BNCs more expressive, the asymmetric independence assertions cannot be naturally represented. The formulas of traditional information-theoretic metrics (e.g., MI and CMI) consider all the possible combinations of attribute values and when applied to identify significant dependence or independence, the topology of learned BNC will remain the same while dealing with different instances.
BMCs provide an effective and feasible solution to address this issue. If the dataset
The probability that KDB can assign the right class label with different values of 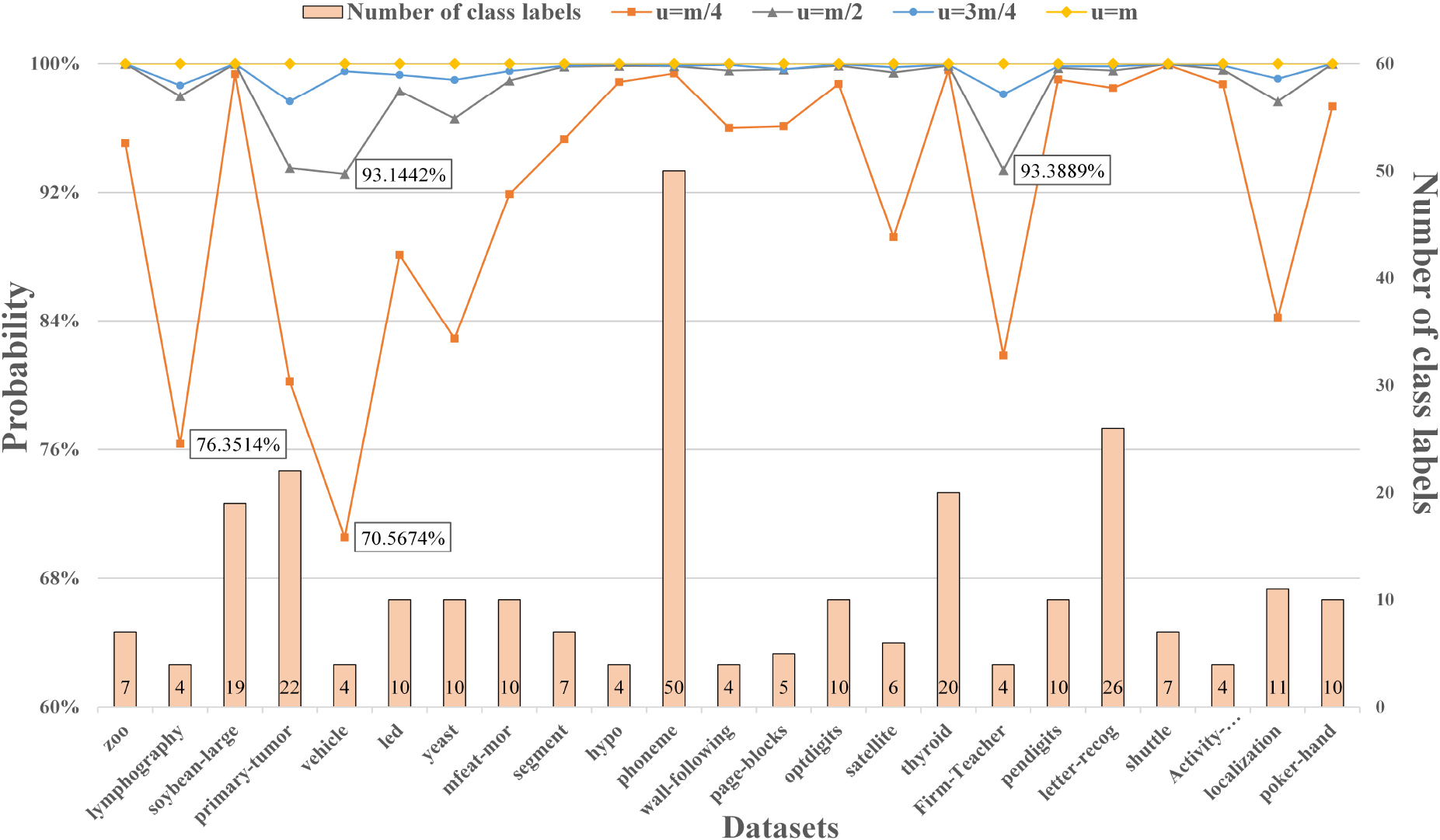
The confidence levels of different local BNCs will not be the same especially when dealing with unbalanced datasets. If these BNCs are treated equally then the estimate of joint probability conditioned on true class label may be overwhelmed by those conditioned on wrong class labels. As the number of class labels increases, the BNC needs to satisfy more independence assertions. Then it is possible to learn a sub-optimal BNC, and that may result in poorer classification performance. If we assign class label to testing instance
One class label corresponds to two local BNCs, one BNC learned from
Single-topology BNC roughly describes the dependency relationships between attributes due to the asymmetric independence assertions. One feasible solution is to precisely identify the (conditional) independence conditioned on specific class label. Suppose that for testing instance
The training data
Similarly, to measure the mutual dependence between attribute value and class label
where
Some state-of-the-art algorithms, e.g., TAN and KDB, learn from training dataset
KDB controls the bias/variance trade-off by allowing each attribute to have at most
[htbp] LearnStructure-
Similarly, to learn the conditional dependency relationships implicated in
where BNC
Restricted BNCs take the class variable as the common parent of the predictive attributes, and the asymmetric independence assertions also take the class variable as a distinguished variable. The final BMC comprises several BNCs, the topology of each of them describes the joint probability for data subset where the distinguished variable (e.g.,
[htbp] Learning process of CSBTraining dataset
In this section, to evaluate the efficacy of multistage learning, we compare the performance of our proposed algorithm CSB with state-of-the-art semi-naive BNCs based on attribute selection, attribute weighting, topology extension and model selection. The
CFWNB [51], correlation-based attribute weighting filter for NB.
The learning framework of the CSB algorithm. AIWNB [36], attribute and instance weighted NB. SKDB [27], selective WATAN [25], weighted averaged tree augmented NB. SA2DE [52], selective A2DE. ATODE [31], averaged tree-augmented one-dependence estimators. SLB [11], semi-lazy Bayesian network classifier.
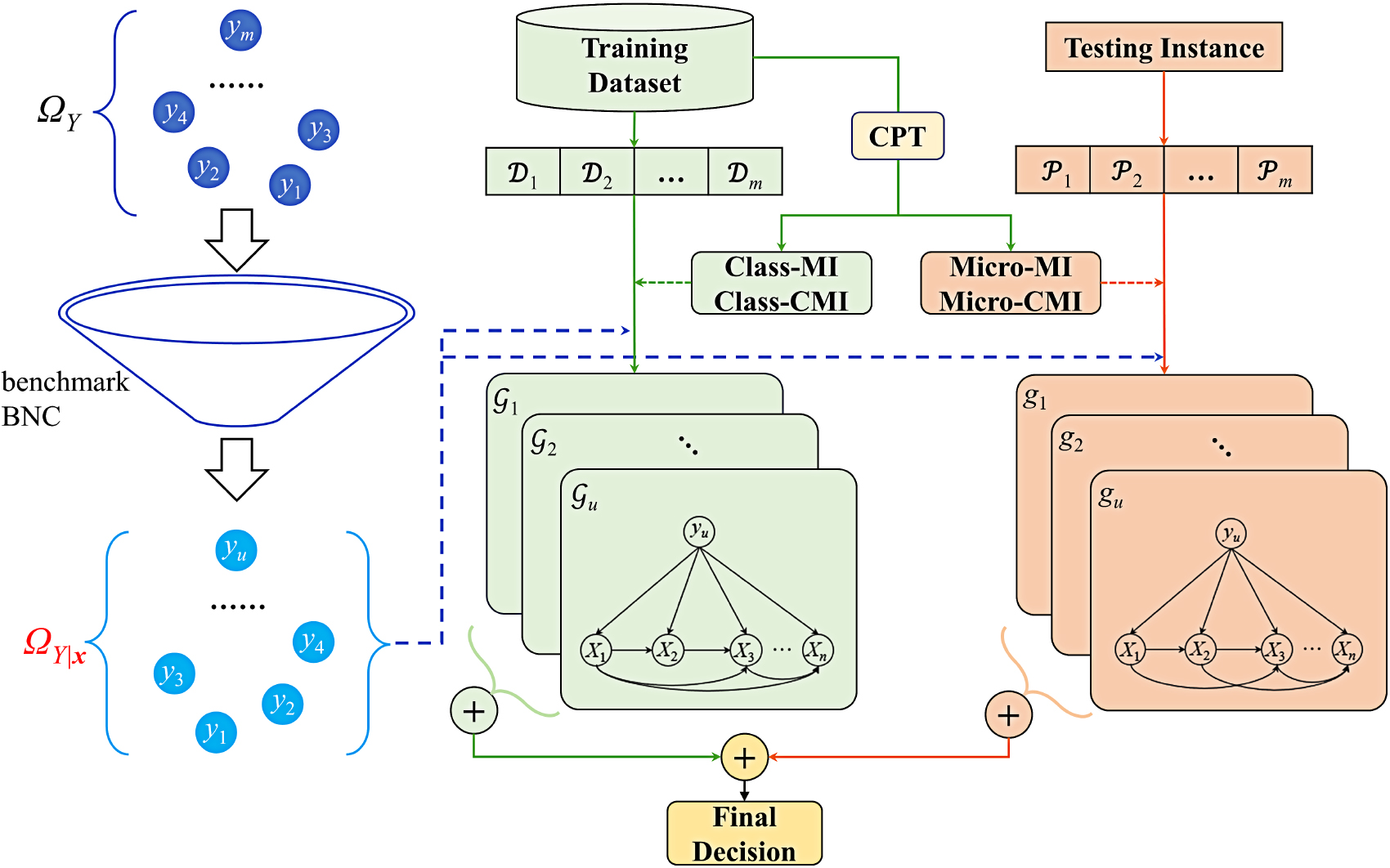
The performance is analyzed in terms of zero-one loss, root mean square error (RMSE), Friedman test and Nemenyi test on 28 datasets from the UCI repository of machine learning [30]. Table 2 describes the characteristics of each dataset, including the number of instances, attributes and class labels. Table 3 presents the detailed description about the statistics we employed to interpret the results. For qualitative and quantitative attributes, the missing values are respectively replaced by modes that mostly appear or means from the training data. The minimum description length discretization method is adopted to discretize numeric attributes for each benchmark dataset [53]. 10 runs of 10-fold cross validation is used to test each algorithm on each dataset. Tables A1 and A2 in Appendix respectively present the detailed results of zero-one loss and RMSE.
Descriptions of the UCI datasets for experimental study. Symbol “*” denotes the dataset with no less than 4 class labels
A summary table of the statistics employed
By alleviating the asymmetric independence assumption, the topologies learned from training set or testing instance can fit data well. To prove the effectiveness of the class-specific learning mechanism, two versions of class-specific BNCs, called CSB
The comparison results of relative zero-one loss. The X-axis presents the index number of datasets, Y-axis presents 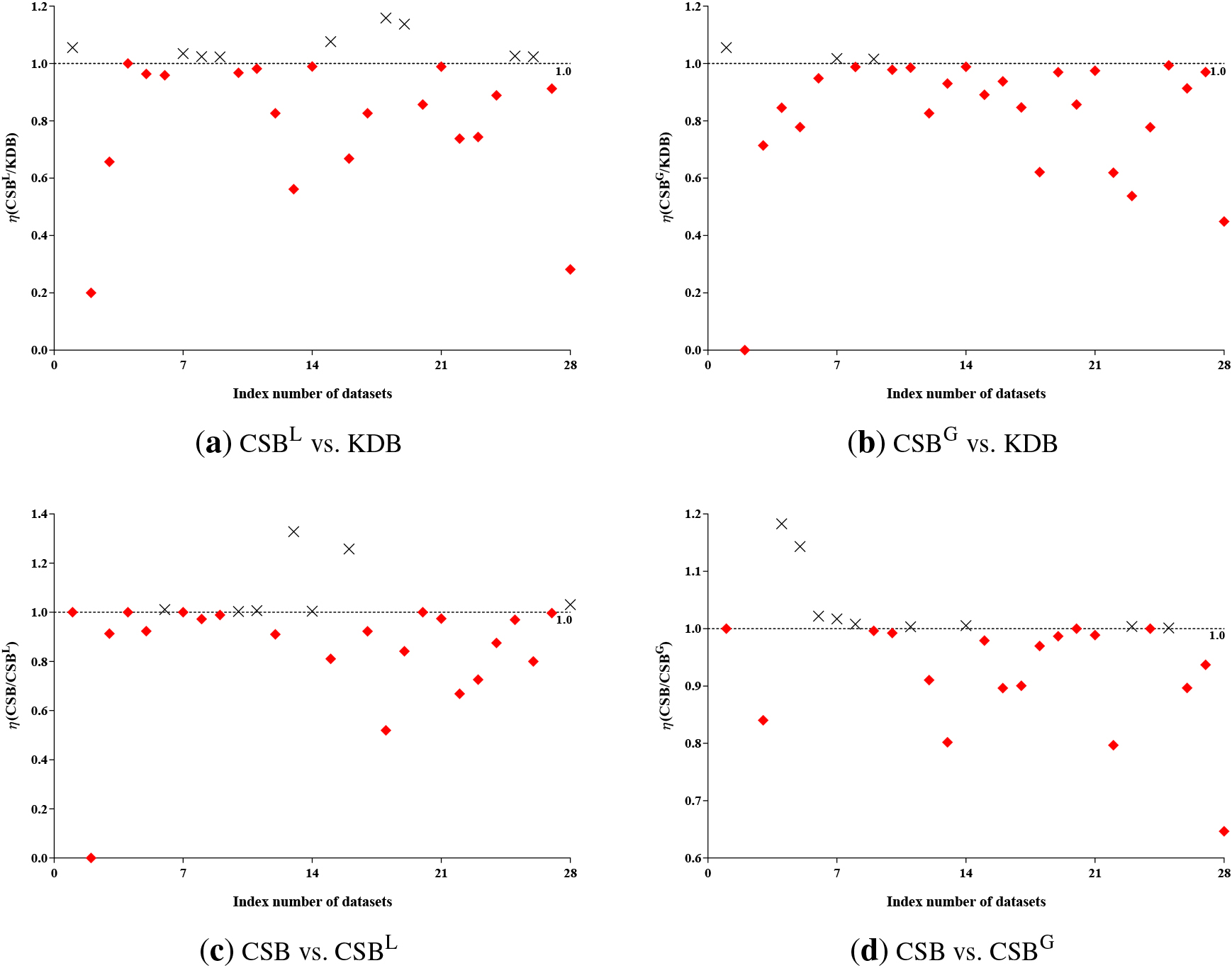
To prove the effectiveness of CSB, the BNCs for comparison study are divided into two groups: single-topology BNCs (including CFWNB, AIWNB and SKDB) and ensemble BNCs (including WATAN, SA2DE, ATODE and SLB). One-tailed
The compared results of the corrected paired one-tailed
-test (
) on zero-one loss
The compared results of the corrected paired one-tailed
The comparison results of the corrected paired one-tailed
From Table 4 we can see that, for single-topology BNCs structure extension is more effective compared to attribute weighting. For CFWNB, each attribute weight is a sigmoid transformation of the difference between the average attribute-attribute intercorrelation (average mutual redundancy) and the attribute-class correlation (mutual relevance). AIWNB utilizes a lazy approach to learning instance weights and a correlation-based attribute weighting approach to learning attribute weights, in which instance weighting and attribute weighting are combined into one uniform framework. SKDB, which relaxes NB’s independence assumption by adding augmented edges, selects appropriate parameter
Ensemble learning can represent more dependency relationships than single-topology BNCs and the topology of each committee member can be relatively simpler. The experimental results indicate that all the ensemble classifiers can achieve better performance than single-topology BNCs (e.g., CFWNB, AIWNB and SKDB). The TAN members of WATAN share the same topology skeleton but have different directed edges, the weighting metrics can tune the estimates of joint probabilities for different TAN members. SA2DE can represent high-dependence relationships and only high-confidence members are selected for prediction. ATODE conducts topology augmentation by applying log likelihood function to identify significant dependency relations. SLB learns class-specific BNCs to mine the dependency relations hidden in attribute values of testing instance with a supposed class label. Experimental results show that our multistage classification strategy provides low zero-one loss or high classification accuracy. As shown in Table 4, CSB performs significantly better than WATAN, SA2DE, ATODE and SLB on 18, 18, 15, 11 datasets, respectively. According to the experimental results, we can argue that CSB provides a more effective ensemble of class-specific BNCs with respect to zero-one loss.
Table 5 presents the experimental results in terms of RMSE. Compared with lower-dependence BNCs, higher-dependence BNCs can provide more reliable estimate of conditional probability. Table 5 shows that SKDB enjoys significant advantages over CFWNB (15 wins and 6 losses) and AIWNB (12 wins and 7 losses) in terms of RMSE. Among ensemble models, CSB still performs the best. For example, CSB performs much better than WATAN (16 wins and 1 loss), SA2DE (15 wins and 1 loss) and ATODE (12 wins and 1 loss). Meanwhile, CSB also outperforms SLB (8 wins and 3 losses). The experimental results from the perspective of RMSE show that the multistage classification strategy helps CSB fit data better.
Training and classification time comparisons for 8 BNCs on 28 datasets.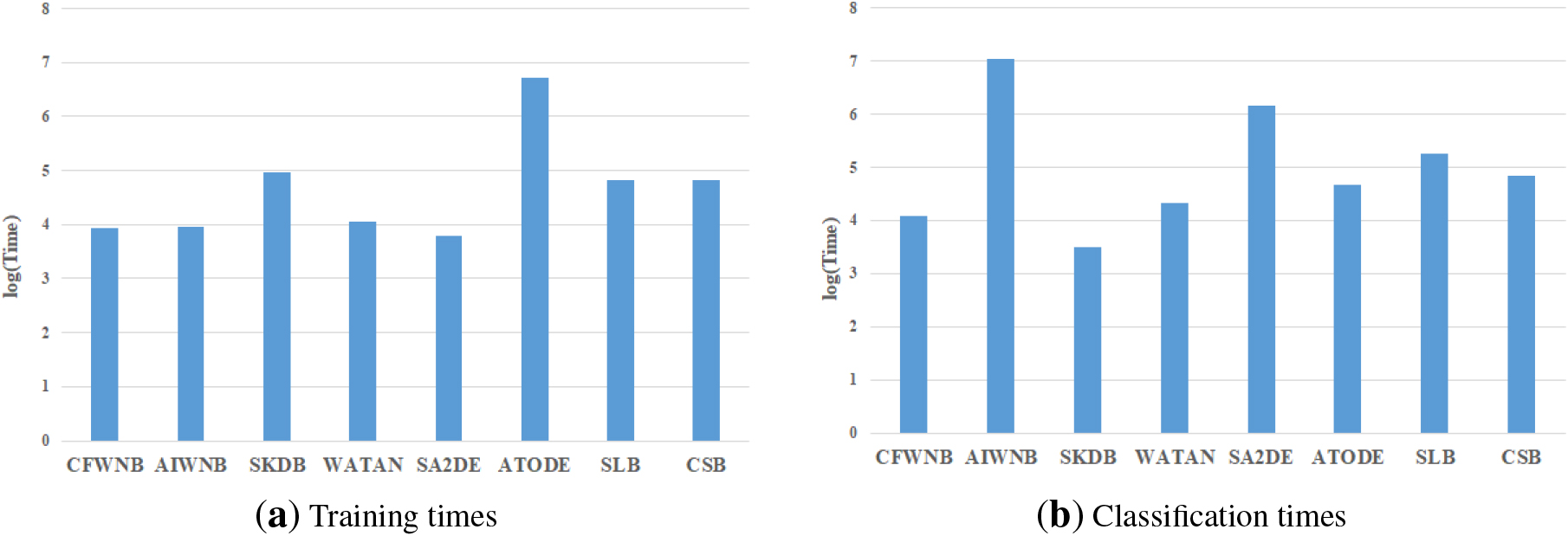
We compare the training and classification time for all the BNCs considered. The comparison results are shown in Fig. 7 and each bar denotes the averaged time on 28 datasets in a 10 runs of 10-fold cross-validation experiment. These experiments have been conducted on a desktop computer with an AMD(R) Ryzen(TM) 4600-H CPU @ 3.0 GHz, 64 bits and 16,384 MB of memory. As shown in Fig. 7(a), during the classification phase, SA2DE takes the least time and it performs attribute selection on superparents. AIWNB and CFWNB need to perform attribute weighting based on different information-theoretic metrics. WATAN needs to build a set of maximum weighted spanning trees (MWSTs) and to learn the weights for them. CSB, SLB and SKDB need more time for building high-dependence DAGs. ATODE consumes the most time because it uses log likelihood function to build high-dependence MWSTs.
During the classification phase, single BNCs, e.g., SKDB and CFWNB, consume the least time for estimating the joint probability. In contrast, ensemble BNCs, e.g., WATAN, ATODE, CSB and SLB, require more time to estimate the individual joint probability learned from each member. WATN and ATODE take different attribute as the root node of the topology in turn. CSB performs multistage classification and builds u local BNCs for high-confidence class labels. Instance learning makes the BNCs take the most time for extracting knowledge from testing instance. SLB calculates local information-theoretic metrics for different instances, SA2DE estimates the joint probability distributions through the instance with the selected attribute values, and AIWNB performs instance weighting for each instance. Although the advantages of CSB on training time and classification time are not significant, CSB can obtain significant improvement on the classification performance. Therefore, the consumption in terms of training time and classification time is perfectly acceptable.
The results of average rank in terms of zero-one loss and RMSE for alternative algorithms.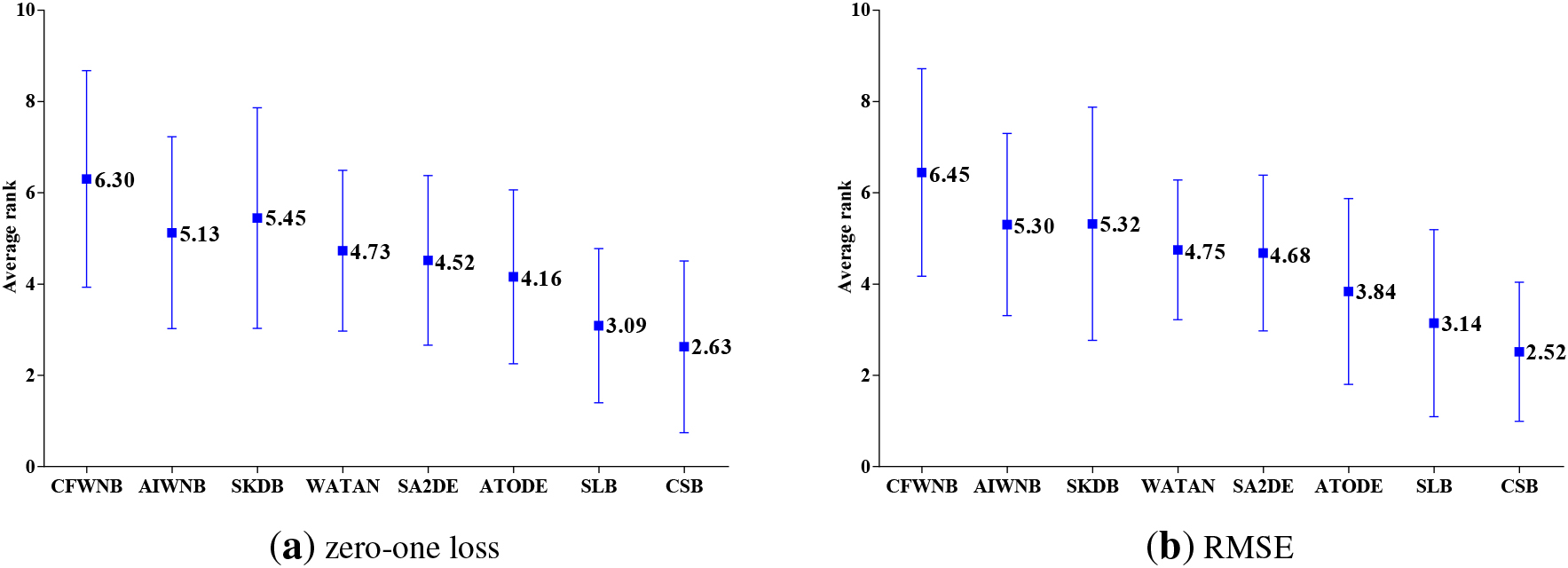
The results of Nemenyi tests in terms of zero-one loss and RMSE for alternative algorithms.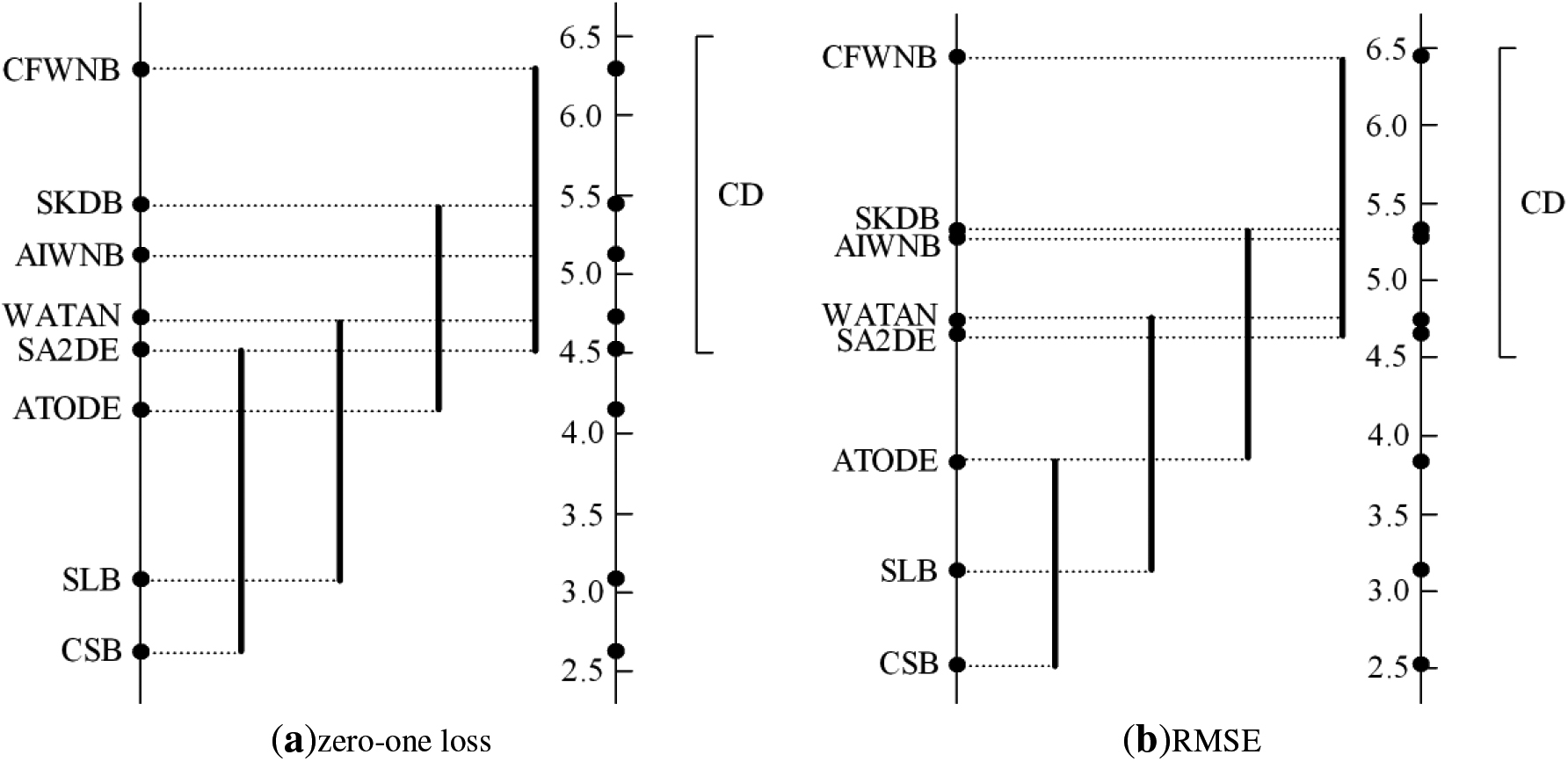
To illustrate the statistical significance of different metrics, we perform a non-parametric Friedman test followed by Nemenyi post test to statistically compare multiple algorithms on multiple datasets in terms of zero-one loss and RMSE. The Friedman test needs to rank the algorithms on each dataset, the null hypothesis of which is that all algorithms are equivalent. The detailed results of rank are presented in Tables A3 and A4 in Appendix respectively. The Friedman statistic is distributed according to
The average ranks for all of the classifiers are depicted in Fig. 8, and lower rank corresponds to better classification performance. As shown in Fig. 8(a), CSB obtains the lowest average zero-one loss rank (2.63), followed by SLB (3.09), ATODE(4.16), SA2DE(4.52), WATAN(4.73), AIWNB(5.13), SKDB(5.45) and CFWNB(6.30). Obviously, our proposed CSB significantly improves upon the zero-one loss and enjoys a significant advantage relative to the other algorithms. When RMSE is compared, as shown in Fig. 8(b), CSB still gets the first position (2.52) and achieves the lowest average RMSE rank than all the other algorithms. The experimental results illustrate that our proposed multistage strategy has the greatest positive effect on reducing the RMSE.
To further explore the significant difference among these algorithms, Nemenyi test is performed and the critical value
With 8 algorithms (
From Fig. 9(a) we can see that, with respect to zero-one loss, CSB performs better than SLB, ATODE and SA2DE, and its advantage over WATAN, SKDB, AIWNB and CFWNB is significant. As shown in Fig. 9(b), CSB ranks first in terms of RMSE and is followed by SLB and ATODE, in contrast its advantage over SA2DE, WATAN, AIWNB, SKDB and CFWNB is significant.
The i.i.d. assumption simplifies the computational complexity while learning BNCs from datasets with complex dependencies. However, different classes of datasets may demonstrate significantly different probability distributions and thus it is hard to fully represent the dependency relationships implicated. According to the asymmetric independence assertion, in this paper we propose to partition the datasets into several subsets according to the high-confidence class labels. The BMC with two sets of class-specific BNCs can be learned from training data and testing data based on multi-stage learning, and its advantage over other single-topology BNCs and ensemble BNCs is obvious from the experimental results in terms of zero-one loss and RMSE. The Friedman test and Nemenyi test illustrate that CSB also performs the best generally. Generalized BNCs learned from labeled training data and specialized BNCs learned from unlabeled testing data contribute to the completeness of domain knowledge. In this paper we propose to apply multistage classification to build BMC, whereas these two kinds of BNCs are treated equally. The study of model weighting or model selection is needed to be introduced into the learning procedure to make these BNCs work as a whole, and we leave it to future research work.
Footnotes
Acknowledgments
This work is supported by the National Key Research and Development Program of China (No.2019YFC1804804), Open Research Project of The Hubei Key Laboratory of Intelligent Geo-Information Processing (No.KLIGIP-2021A04), and the Scientific and Technological Developing Scheme of Jilin Province (No.20200201281JC) and High Performance Computing Center of Jilin University, China.
Conflict of interest
The authors declare that they have no conflict of interest.
Appendix A
Experimental results of zero-one loss The value in boldface indicates the classifier with the best performance.
Dataset
CFWNB
AIWNB
SKDB
WATAN
SA2DE
ATODE
SLB
CSB
Lung-cancer
0.5000
0.5000
0.6250
0.6563
0.5313
0.6250
0.5938
Zoo
0.0396
0.0396
0.0396
0.0198
0.0297
0.0198
0.0297
Lymphography
0.1486
0.1689
0.2770
0.1689
0.2635
0.1554
0.1554
Iris
0.0867
0.0800
0.0800
0.0867
0.0800
0.0867
Soybean-large
0.0977
0.1140
0.1010
0.1173
0.0782
0.0912
0.0782
Primary-tumor
0.5634
0.5634
0.5841
0.5575
0.5782
0.5457
0.5546
Balance-scale
0.2544
0.2912
0.2736
0.2800
0.2832
0.2544
0.2880
Vehicle
0.3711
0.3227
0.2920
0.2943
0.2790
0.2896
0.2931
Led
0.2630
0.2730
0.2660
0.2690
0.2650
0.2650
Yeast
0.4319
0.4212
0.4461
0.4245
0.4218
0.4239
0.4259
Mfeat-mor
0.3060
0.3050
0.3140
0.3005
0.3105
0.2990
0.3025
Segment
0.0640
0.0472
0.0615
0.0394
0.0571
0.0364
0.0355
Splice-c4.5
0.0374
0.0346
0.0818
0.0466
0.0362
0.2524
0.0796
Hypo
0.0121
0.0101
0.0175
0.0130
0.0119
0.0103
0.0085
Abalone
0.4754
0.4654
0.4680
0.4582
0.4594
0.4503
0.4534
Phoneme
0.2407
0.2139
0.1909
0.2345
0.1824
0.2427
0.2464
Wall-following
0.0720
0.0378
0.0550
0.0442
0.0361
0.0480
0.0337
Page-blocks
0.0416
0.0353
0.0331
0.0418
0.0358
0.0327
0.0312
Optdigits
0.0676
0.0628
0.0641
0.0406
0.0404
0.0290
0.0246
Satellite
0.1726
0.1434
0.1206
0.1207
0.1276
0.1147
0.1086
Thyroid
0.0817
0.1030
0.0784
0.0723
0.0605
0.0629
0.0605
Firm-Teacher
0.2359
0.2324
0.1779
0.1934
0.1985
0.2125
0.1749
Pendigits
0.1129
0.0635
0.0794
0.0328
0.0491
0.0200
0.0189
Letter-recog
0.2479
0.2041
0.1177
0.1300
0.0769
0.0838
0.0625
Shuttle
0.0020
0.0016
0.0009
0.0014
0.0017
0.0008
0.0007
Connect-4
0.2847
0.2827
0.2354
0.2397
0.2374
0.2343
0.2271
Activity-recognition-with
0.0429
0.0384
0.0183
0.0179
0.0168
0.0174
0.0132
Waveform
0.0198
0.0196
0.0285
0.0202
0.1662
0.1720
0.1688
Localization
0.4936
0.4643
0.3013
0.3575
0.3078
0.3544
0.2708
Poker-hand
0.4988
0.4988
0.3295
0.1967
0.3453
0.0792
0.0569
Experimental results of RMSE The value in boldface indicates the classifier with the best performance.
Dataset
CFWNB
AIWNB
SKDB
WATAN
SA2DE
ATODE
SLB
CSB
Lung-cancer
0.5287
0.5121
0.6218
0.5892
0.5692
0.6241
0.5005
Zoo
0.0933
0.0883
0.0884
0.0614
0.0746
0.0686
0.0640
Lymphography
0.2591
0.3156
0.2705
0.3027
0.2501
0.2645
0.2528
Iris
0.1500
0.1970
0.1958
0.2063
0.2077
0.1999
0.1948
Soybean-large
0.0886
0.0809
0.0978
0.0902
0.0962
0.0856
0.0833
Primary-tumor
0.1790
0.1782
0.1917
0.1812
0.1823
0.1864
0.1772
Balance-scale
0.3589
0.3507
0.3203
0.3206
0.3198
0.3153
0.3252
Vehicle
0.3611
0.3288
0.3233
0.3103
0.3116
0.3083
0.3101
Led
0.2163
0.2130
0.2023
0.1991
0.1986
0.1990
0.1986
Yeast
0.2423
0.2404
0.2440
0.2376
0.2377
0.2372
Mfeat-mor
0.1943
0.2003
0.1941
0.1966
0.1980
0.1966
0.1950
Segment
0.1195
0.1029
0.1210
0.0968
0.1081
0.0881
0.0917
Splice-c4.5
0.1388
0.2149
0.1541
0.1366
0.3681
0.2534
Hypo
0.0739
0.0661
0.0840
0.0723
0.0596
0.0685
0.0685
Abalone
0.4433
0.4337
0.4449
0.4250
0.4220
0.4243
0.4358
Phoneme
0.0806
0.0776
0.0756
0.0844
0.0737
0.0891
0.0848
Wall-following
0.1744
0.1295
0.1570
0.1368
0.1298
0.1483
0.1159
Page-blocks
0.1117
0.1044
0.1064
0.1187
0.1040
0.1013
0.0998
Optdigits
0.1075
0.1019
0.1035
0.0835
0.0829
0.0727
0.0984
Satellite
0.2316
0.2061
0.1917
0.1849
0.1862
0.1799
0.1752
Thyroid
0.0789
0.0905
0.0813
0.0742
0.1815
0.0706
0.0677
Firm-Teacher
0.3177
0.3138
0.2706
0.2711
0.2809
0.2895
0.2712
Pendigits
0.1318
0.0979
0.1128
0.0725
0.0899
0.0565
0.0593
Letter-recog
0.1139
0.1036
0.0823
0.0859
0.0670
0.0691
0.0645
Shuttle
0.0270
0.0220
0.0143
0.0177
0.0181
0.0129
Connect-4
0.3632
0.3620
0.3315
0.3349
0.3339
0.3299
0.3337
Activity-recognition-with
0.1246
0.1188
0.0835
0.0845
0.0822
0.0832
0.0720
Waveform
0.1116
0.1079
0.1087
0.0951
0.2778
0.0974
0.0900
Localization
0.2402
0.2351
0.2010
0.2095
0.2000
0.2081
0.1848
Poker-hand
0.2382
0.2382
0.2124
0.1770
0.2153
0.1566
0.1574
Experimental results of rank in terms of zero-one loss
Dataset
CFWNB
AIWNB
SKDB
WATAN
SA2DE
ATODE
SLB
CSB
Lung-cancer
1.0
2.5
2.5
6.5
8.0
4.0
6.5
5.0
Zoo
7.0
7.0
7.0
2.5
4.5
2.5
4.5
1.0
lymphography
2.0
5.5
8.0
5.5
7.0
3.5
3.5
1.0
Iris
1.5
1.5
7.0
4.0
4.0
7.0
4.0
7.0
soybean-large
5.0
1.0
7.0
6.0
8.0
2.5
4.0
2.5
Primary-tumor
5.5
5.5
8.0
1.0
4.0
7.0
2.0
3.0
Balance-scale
1.0
2.5
8.0
4.0
5.0
6.0
2.5
7.0
Vehicle
8.0
7.0
4.0
6.0
2.0
1.0
3.0
5.0
Led
3.0
1.5
8.0
6.0
1.5
7.0
4.5
4.5
Yeast
7.0
2.0
8.0
1.0
5.0
3.0
4.0
6.0
Mfeat-mor
6.0
5.0
8.0
1.0
3.0
7.0
2.0
4.0
Segment
8.0
5.0
7.0
4.0
6.0
1.0
3.0
2.0
Splice-c4.5
4.0
2.0
7.0
5.0
1.0
3.0
8.0
6.0
Hypo
6.0
3.0
8.0
7.0
1.0
5.0
4.0
2.0
Abalone
8.0
6.0
7.0
4.0
5.0
1.0
2.0
3.0
Phoneme
6.0
4.0
3.0
5.0
2.0
7.0
8.0
1.0
Wall-following
8.0
4.0
1.0
7.0
5.0
3.0
6.0
2.0
Page-blocks
7.0
5.0
4.0
8.0
6.0
3.0
2.0
1.0
Optdigits
8.0
6.0
7.0
5.0
4.0
3.0
2.0
1.0
Satellite
8.0
7.0
4.0
5.0
6.0
3.0
2.0
1.0
Thyroid
7.0
8.0
6.0
5.0
2.5
4.0
1.0
2.5
Firm-Teacher
8.0
7.0
3.0
4.0
5.0
6.0
1.0
2.0
Pendigits
8.0
6.0
7.0
4.0
5.0
3.0
2.0
1.0
Letter-recog
8.0
7.0
5.0
6.0
3.0
4.0
2.0
1.0
Shuttle
8.0
6.0
4.0
5.0
7.0
3.0
1.0
2.0
Connect-4
8.0
7.0
1.0
4.0
6.0
5.0
3.0
2.0
Activity-recognition-with
8.0
7.0
6.0
5.0
3.0
4.0
2.0
1.0
Waveform
3.0
2.0
5.0
4.0
6.0
1.0
8.0
7.0
Localization
8.0
7.0
3.0
6.0
4.0
5.0
2.0
1.0
Poker-hand
7.5
7.5
1.0
5.0
4.0
6.0
3.0
2.0
6.1167
4.9167
5.4833
4.7167
4.4500
4.0167
3.4167
2.8833
Experimental results of rank in terms of RMSE
Dataset
CFWNB
AIWNB
SKDB
WATAN
SA2DE
ATODE
SLB
CSB
Lung-cancer
1.0
4.0
3.0
7.0
6.0
5.0
8.0
2.0
Zoo
8.0
6.0
7.0
2.0
5.0
4.0
3.0
1.0
Lymphography
1.0
4.0
8.0
6.0
7.0
2.0
5.0
3.0
Iris
2.0
1.0
5.0
4.0
7.0
8.0
6.0
3.0
Soybean-large
5.0
2.0
8.0
6.0
7.0
4.0
3.0
1.0
Primary-tumor
4.0
3.0
8.0
5.0
6.0
7.0
1.0
2.0
Balance-scale
8.0
7.0
1.0
4.0
5.0
3.0
2.0
6.0
Vehicle
8.0
7.0
6.0
4.0
5.0
2.0
1.0
3.0
Led
8.0
7.0
6.0
5.0
2.5
1.0
4.0
2.5
Yeast
7.0
6.0
8.0
4.0
5.0
1.5
1.5
3.0
Mfeat-mor
3.0
1.0
8.0
2.0
5.5
7.0
5.5
4.0
Segment
7.0
5.0
8.0
4.0
6.0
2.0
3.0
1.0
Splice-c4.5
4.0
1.5
6.0
5.0
1.5
3.0
8.0
7.0
Hypo
7.0
3.0
8.0
6.0
2.0
4.5
4.5
1.0
Abalone
7.0
5.0
8.0
4.0
2.0
1.0
3.0
6.0
Phoneme
5.0
4.0
3.0
6.0
2.0
8.0
7.0
1.0
Wall-following
8.0
3.0
1.0
7.0
5.0
4.0
6.0
2.0
Page-blocks
7.0
5.0
6.0
8.0
4.0
3.0
2.0
1.0
Optdigits
8.0
6.0
7.0
4.0
3.0
2.0
1.0
5.0
Satellite
8.0
7.0
6.0
4.0
5.0
3.0
2.0
1.0
Thyroid
5.0
7.0
6.0
4.0
8.0
3.0
2.0
1.0
Firm-Teacher
8.0
7.0
1.0
2.0
3.0
5.0
6.0
4.0
Pendigits
8.0
6.0
7.0
4.0
5.0
2.0
1.0
3.0
Letter-recog
8.0
7.0
5.0
6.0
3.0
4.0
1.0
2.0
Shuttle
8.0
7.0
4.0
5.0
6.0
1.5
1.5
3.0
Connect-4
8.0
7.0
1.0
3.0
6.0
5.0
2.0
4.0
Activity-recognition-with
8.0
7.0
5.0
6.0
3.0
4.0
2.0
1.0
Waveform
7.0
5.0
6.0
3.0
8.0
1.0
4.0
2.0
Localization
8.0
7.0
4.0
6.0
3.0
5.0
2.0
1.0
Poker-hand
7.5
7.5
1.0
5.0
4.0
6.0
2.0
3.0
6.3833
5.1667
5.3667
4.7000
4.6833
3.7167
3.3333
2.6500