
Abstract
Small object detection has a broad application prospect in image processing of unmanned aerial vehicles, autopilot and remote sensing. However, some difficulties exactly exist in small object detection, such as aggregation, occlusion and insufficient feature extraction, resulting in a great challenge for small object detection. In this paper, we propose an improved algorithm for small object detection to address these issues. By using the spatial pyramid to extract multi-scale spatial features and by applying the multi-scale channel attention to capture the global and local semantic features, the spatial pooling pyramid and multi-scale channel attention module (SPP-MSCAM) is constructed. More importantly, the fusion of the shallower layer with higher resolution and a deeper layer with more semantic information is introduced to the neck structure for improving the sensitivity of small object features. A large number of experiments on the VisDrone2019 dataset and the NWPU VHR-10 dataset show that the proposed method significantly improves the Precision, mAP and mAP50 compared to the YOLOv5 method. Meanwhile, it still preserves a considerable real-time performance. Undoubtedly, the improved network proposed in this paper can effectively alleviate the difficulties of aggregation, occlusion and insufficient feature extraction in small object detection, which would be helpful for its potential applications in the future.
Introduction
It is well-known that a small object is characterized by a bounding box with a ratio less than 0.1 [7] or a resolution less than 32
To address this issue, researchers start paying attention to obtaining more information through different methods from these classical networks. For instance, Liu et al. [24] considered that, for small object images captured by unmanned aerial vehicles (UAVs), the inadequate feature extraction is mainly caused by a small field of perception and less spatial information in traditional algorithms. Therefore, they applied two different ways to broaden the perceptual field and enrich spatial information. One way is to optimize the residual blocks in the darknet by concatenating two residual networks (ResNet) [16] units together with the same width and height. The second way is to enrich the entire darknet structure by adding convolution operations to earlier layers. In comparison to the methods proposed by Liu et al. [24], Ku et al. [4] argued that the key role in solving the problem of inadequate feature extraction is high-resolution features and feature fusion. By extracting the content and texture of the input image to capture local details of small objects, and using a combination of spatial pooling pyramid [17] (SPP) and path aggregation network [29] (PAN) in the neck network, an enhanced ability to utilize high-resolution features of small objects can be realized. Similar to [4], Oghaz et al. [25] also performed feature fusion on two feature layers with higher resolution. Moreover, the deconvolution operation played a key role in achieving better detection performance. It is because of the high-resolution features and their corresponding features fusion, as well as more spatial information and a larger perceptual field, an excellent performance for detecting small objects can be achieved in [4, 24, 25]. However, in practical use, especially in the use of complex scenes for detecting multiple small objects, high-resolution features, more spatial information become more and more difficult to obtain due to the aggregation and occlusion of small objects in complex scenes, resulting in more false detection and missed detection. Thus, researchers begin to study the solution of detecting aggregated and occlusive small objects in complex scenes. For example, Guo et al. [32] and Li et al. [42] both used a combination of the intersection over union (IOU) and non-maximum suppression (NMS) to decrease the ratio of false detection and missed detection. The difference is only that Li et al. [42] used the complete IOU, while Guo et al. [32] used the distance IOU. Different from the methods proposed by Guo et al. and Li et al., Guan et al. [19] enhanced the detection accuracy of partially occluded small objects by applying multiple pooling layers to mix contextual information into the feature map. It is worth noting that Guo et al. and Li et al. only focus on the solution of occlusion between small objects that should be detected. However, they cannot resolve the occlusion between the detected objects and other irrelevant objects. Though these methods [19, 32, 42] can be used to alleviate the problem of small objects occluded each other, the detecting performance including detecting accuracy and detecting speed would be somewhat reduced in complex scenes.
From the description of small object detection, it is found that the detecting performance of small objects in complex scenes is mainly determined by the extraction of small object features and feature fusion. If richer spatial, semantic information and a higher resolution feature information of small objects can be captured with a larger perceptual field and feature fusion, a relatively good performance would be achieved, which would be helpful for the solution of aggregation and occlusion for detecting small objects in complex scenes.
In this paper, we design a spatial-channel attention module composed of SPP module and multi-scale channel attention (MSCAM) module, named SPP-MSCAM. The SPP module is used to increase the perceptual field and obtain more spatial information. The MSCAM module is applied to capture enough semantic features on both global and local scales. By combining the SPP module and MSCAM module, the relation between the channel and spatial feature layers is strengthened and the richer features of small objects are obtained. Moreover, by fusing shallower feature information with higher resolution, and extending the feature pyramid network (FPN) and PAN parts to match the size of the shallower features, more features of small objects with different scales are fused, leading to a better detecting performance.
Related work
YOLOv5 has been widely used in small object detection [2, 37, 39] due to its high detection accuracy and fast detection speed simultaneously. Therefore, YOLOv5 is used as a typical benchmark network to study the effects of attention mechanism and enhanced network on its performance for detecting small objects.
YOLOv5
YOLOv5, a one-stage object detection model based on a convolutional neural network, has four structural components: Focus, CBS (composed of convolutional layer, batch normalization layer, and sigmoid-weighted linear unit, abbreviated as CBS), cross-stage partial (CSP) structures, and SPP module.
Focus, a component of the backbone network, uses four parallel slice operations to transfer the spatial information of the input image to the channel dimension without losing any of the finer details. CBS is a foundational module, including a convolutional layer, a batch normalization layer, and a sigmoid-weighted linear unit (SiLU) activation function. The CSP structure divides the original input into two branches for convolution and bottleneck operations. Moreover, both the backbone part and neck part all use CSP structures, but the difference is that the CSP structure in the backbone portion of the network has several residual units, while the CSP structure in the neck portion uses the CBS module to replace the residual unit. The SPP module consists of three maximum pooling operations. Then, the input feature map is converted into a fixed-size feature vector by the SPP module, which further enhances the expressiveness of small object features without slowing down inference.
Attention mechanism
Attention mechanisms in machine vision can be regarded as a dynamic weighting process based on input image information. Up to now, attention mechanism has been widely used to computer vision, such as image classification [15, 22] and image denoising [5]. Initially, it is used to imitate humans to quickly discover the desired attention region in complex images [21]. By concentrating on important areas of the input image, attention processes in small object detection can gather more crucial feature information. In addition, channel attention, spatial attention and their combination are often used to detect small objects. Squeeze-and-excitation networks (SE-Net) [10] and efficient channel attention (ECA) [26] are typical attention mechanisms for channels. Spatial transformer networks (STN) [23] are typical attention mechanisms for spaces. Convolutional block attention module (CBAM) [31] and bottleneck attention module (BAM) [11] are typically combined attention mechanisms for both channels and spaces.
The channel attention mechanism SE-Net was firstly proposed in [10], which has a squeeze and excitation block, as indicated by the dash box and dash box in Fig. 1a. This block can gather global information, capture the relationship between channels and enhance its representational capability. However, the global average pooling in the squeeze block is difficult to obtain complex global information. Moreover, the complexity of the model is increased due to the fully connected layer in the excitation block. To avoid channel degradation and reduce model complexity, ECA [26] was introduced. As illustrated in Fig. 1b, the convolutional layers are employed rather than fully connected layers in the excitation module of SE-Net. Though the channel attention mechanism can enhance the performance of a detection model, it often ignores the location information which is generated by the spatial attention feature layers. Woo et al. [31] proposed a convolutional block attention module, as depicted in Fig. 1c, which consists of the max-pooling operation, the average pooling, a multi-layer perceptron (MLP), a convolution operation, a sigmoid operation and batch normalization. It unites the channel attention module and the spatial attention module. Moreover, it also introduced two global pooling layers to generate global spatial information. However, the spatial sub-module may be impacted by the constrained perceptual field because it only uses convolution to handle the corresponding spatial attention information. Thus, in this paper, an improved attention mechanism by using pyramid pooling layer to expand the receptive field, and by combining multi-scale channel convolution to improve the ability of feature information extraction is proposed. The corresponding description is introduced in Section 3.1.
The algorithm flow charts of the SE-Net, ECA and CBAM.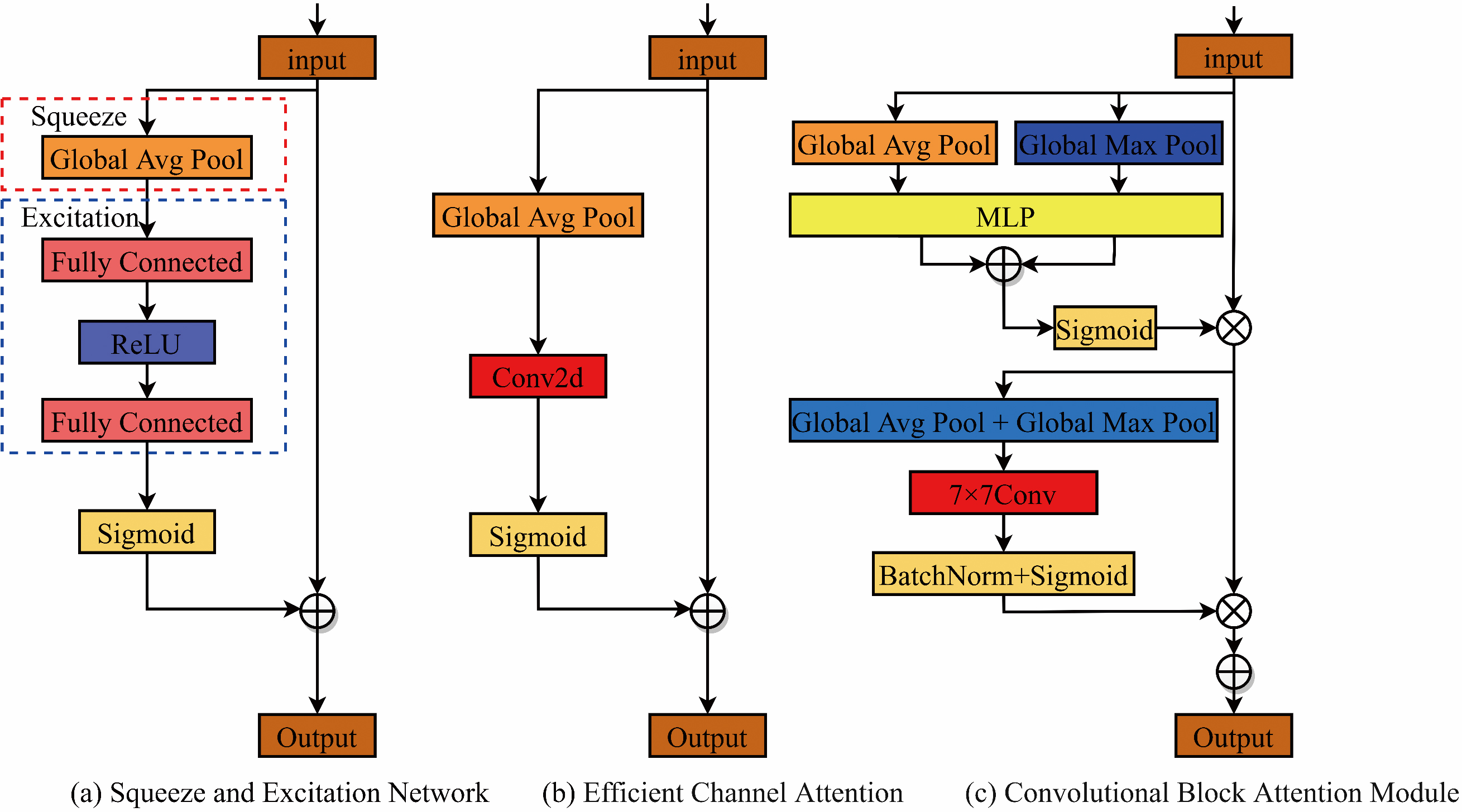
Enhancing the accuracy of detecting by feature fusion from different scales is an essential way to improve the performance of small object detection. As we know, abundant semantic information is difficult to be captured from shallow layers, while rich location information and detailed information always exist in shallow layers. With the processing of the down-sample, more semantic information would be extracted while less location information and detailed information would be captured. To detect small objects accurately, it needs to obtain enough semantic information, location information and detailed information simultaneously. Thus, a suitable fusion of enough semantic information, location information and detailed information with different scales should be used to achieve the goal. For instance, Lin et al. [35] proposed FPN to enhance detection accuracy by fusing the features from various feature layers in the backbone part. Moreover, Liu et al. [29] introduced PAN to strengthen the entire feature hierarchy by enhancing the bottom-up path for obtaining accurate location information in shallow layers. As a result, the path of information transition between shallow layer and deep layer features was shortened. The computational cost was decreased and the detection accuracy was improved. Furthermore, Liang et al. [40] constructed a structure composed of two feature pyramids for predicting. The two feature pyramids were produced by the deconvolution module and the feature fusion module. Further modified branches for features fusion were added to better learn more deep features. Therefore, an amount of feature information including semantic information, location information and detailed information can be obtained simultaneously. As a result, small object detection can perform better.
Method
SPP-MSCAM
The attention mechanism can focus on the key regions of the input image by assigning certain weights to the channels and spaces. Based on these settings, the important spatial information and location information of different channels can be obtained. By collecting these fine-grained features, the attention mechanism can alleviate the issues of aggregation and occlusion for small objects in complex scenes. Meanwhile, it is also helpful for improving detection accuracy. Motivated by the spatial pooling pyramid and the multi-scale channel attention [43], the SPP-MSCAM is proposed, as shown in Fig. 2. Benefitting from the advantages of a larger perceptual field, rich spatial information and multiple-scale channel information in SPP-MSCAM, not only the accuracy of small objects detection in complex scenes is enhanced, but also the aggregation and occlusion of small objects in complex scenes can be also resolved effectively.
The detailed structure of SPP-MSCAM. H, W and C represent the height, the width and the number of channels for the feature maps. The scale of input feature 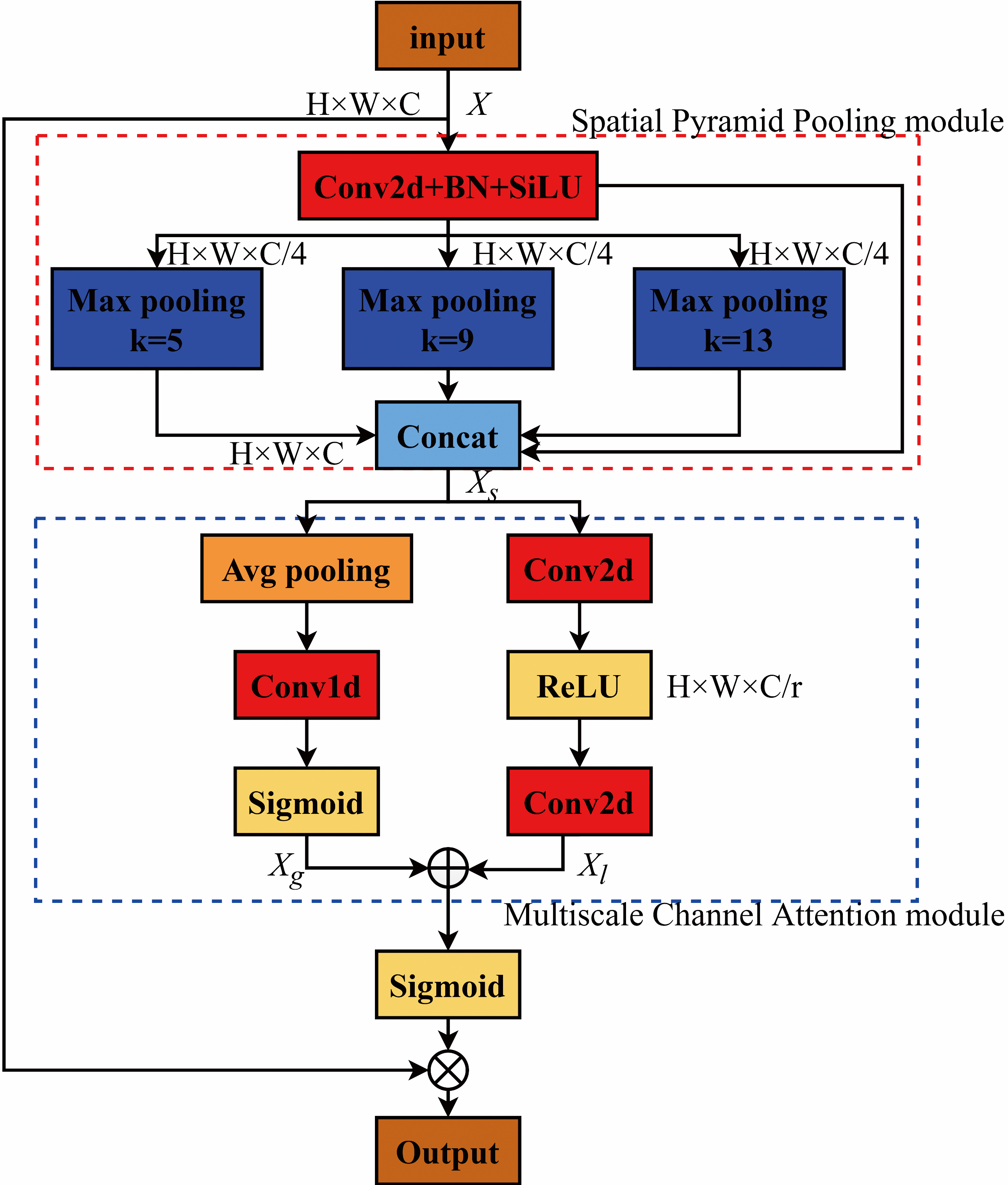
As shown in Fig. 2, the SPP module is indicated by the dash box. Firstly, the input image is operated by a 1
In Fig. 2, the MSCAM module is composed of two parallel channel attention units, as indicated by the dash box. On the left of the dash box is the global channel attention module, which employs one-dimensional convolution to realize a local cross-channel interaction without dimensionality reduction. Moreover, the kernel size of one-dimensional convolution could be chosen adaptively. The formula of convolution kernel adaptive function [26] is followed as below:
Where
Where
Where Conv1d represents the one-dimensional convolution,
As we know, the shallow layers contain a large number of small objects features and location information while the deep layers contain more semantic features. The fusion of shallow features and deep features can make the deep layers obtain richer location information and semantic features, which helps improve the accuracy of small object detection. To obtain more semantic features and location information of small objects, we design another enhanced sub-network, named the efficient small object detection (ESOD), as indicated by the dash box in Fig. 3. As the input of the ESOD, P2 is the output of the CSP1_1 with less down-sample operation in the backbone network. It possesses a relatively higher resolution of 160
The architecture of enhanced network. P2 is the output of the CSP1_1. The dash boxes indicate the FPN, the enhanced network (ESOD) and the PAN, respectively.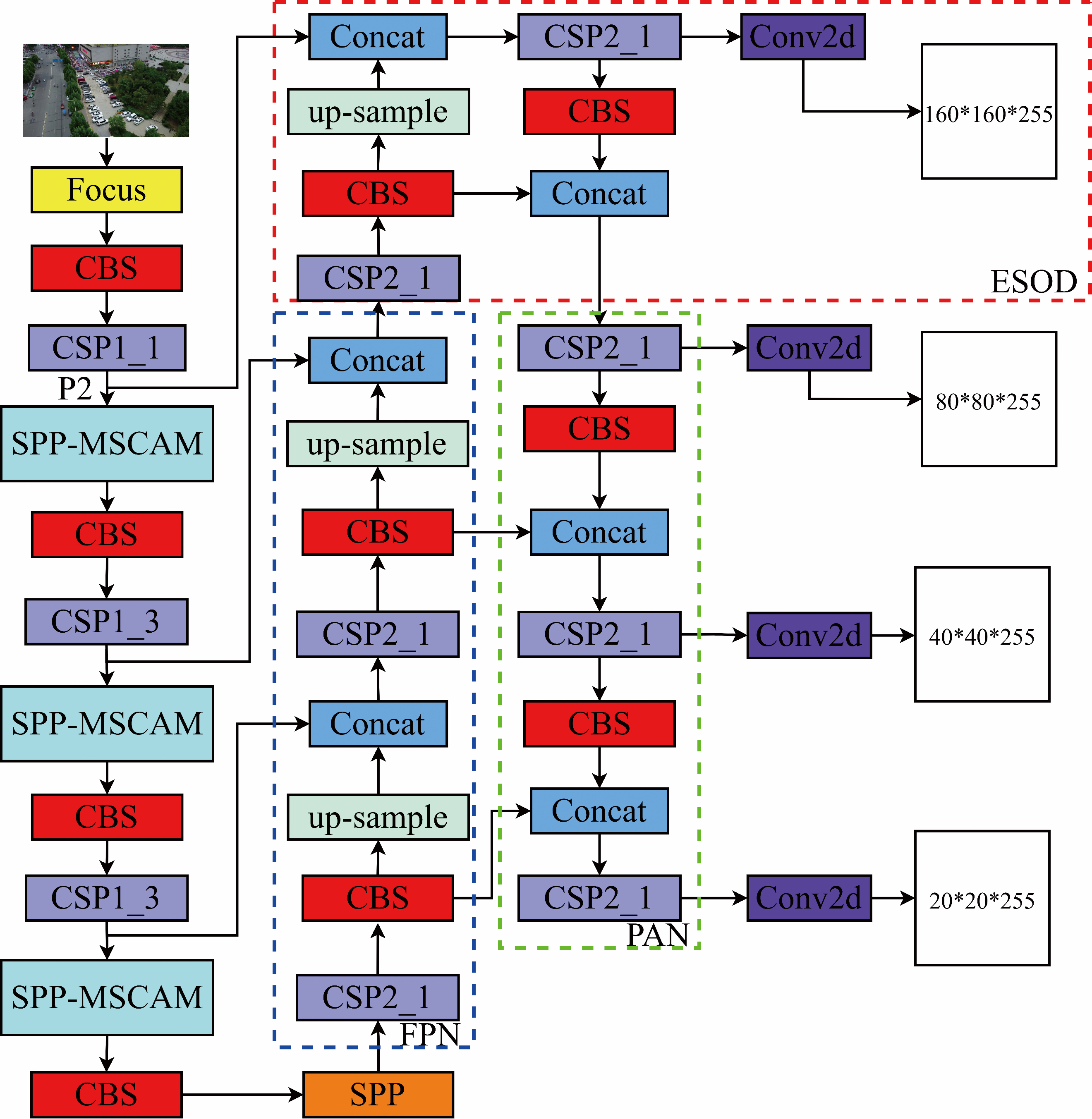
Dataset
The performance of the enhanced small object detection network is assessed by the VisDrone2019 dataset. The VisDrone2019 dataset is collected by the AISKYEYE team at the Lab of Machine Learning and Data Mining, Tianjin University, China. There are 10209 static images, consisting of 6471 images for training, 548 images for verifying, and 3190 images for testing. Ten kinds of items exist in the dataset, including pedestrian, people, bicycle, vehicle, van, truck, tricycle, awning-tricycle, bus and motor. In particular, the images in the dataset are more comprehensive and complex than the other classical datasets, which contain a large number of small objects. Moreover, the labels of these small objects are very strict and fractionalized. For example, people who are only walking or standing can be identified as pedestrian objects, while others (such as squatters or bikers) are identified as people objects. However, due to the problems of complex environments, different weather, light intensity and shooting angle, it is relatively difficult to detect these small objects accurately and rapidly from this dataset.
To further prove the effectiveness of the method proposed in this paper, the NWPU VHR-10 dataset [8, 9] is selected to evaluate the performance of the network because the NWPU VHR-10 dataset is also a publicly available 10-class geospatial object detection dataset with 650 high-resolution images. Ten typical categories of objects in NWPU VHR-10 dataset corresponds to airplane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, and vehicle. In this paper, the training set and verification set in NWPU VHR-10 dataset are randomly allocated according to the typical ratio of 8:2, which include 520 training set images and 130 verification set images, respectively.
Evaluating metrics
The network is evaluated by these metrics:
True positive (TP) represents the number of predictions of the positive sample with a correct prediction. False positive (FP) represents the number of predictions of the positive sample with a wrong prediction. False negative (FN) represents the number of predictions of a negative sample with a wrong prediction. Precision refers to the percentage of positive samples with a correct prediction among all the positive samples, while Recall refers to the percentage of positive samples with a correct prediction among all the positive samples the network predicted. Moreover, the area of the Precision-Recall curve is defined as the average precision (AP) for describing the performance of accuracy, which can be denoted as follows by Eqs (6) and (7):
where
The experiments were performed under Ubuntu 18.04.6LTS, CUDA version 11.2 and NVIDIA GeForce RTX3080 GPU using the python-compiled version of PyTorch 1.8.0 deep learning framework. Meanwhile, the YOLOv5 was employed as the benchmark model for comparison with our improved method. To avoid overfitting, the initial learning rate and weight decay rate were adjusted to 0.01 and 0.0005, respectively. Additionally, due to the high resolution of every image in the VisDrone2019 dataset and NWPU VHR-10 dataset, the training batch size was adjusted to 4. After repeated experiments, the training epochs and the momentum on the VisDrone2019 dataset and NWPU VHR-10 dataset were set to 300 and 0.937. Moreover, other parameters were consistent with the parameter settings of YOLOv5.
Results and discussions
Comparative research on the mechanisms of attention
To verify the SPP-MSCAM module, a series of contrastive experiments with various attention mechanisms were performed on VisDrone2019 dataset, including ECA [26], MSCAM and SPP-MSCAM. The corresponding results are shown in Table 1. The networks labeled with bottleneck and backbone subscripts indicate the corresponding location of the attention mechanism. Moreover, the bolded number in each column indicates the best result in contrastive experiments.
Comparison of the detecting networks with different attention mechanisms
Comparison of the detecting networks with different attention mechanisms
Compared with the results under YOLOv5, the Precision and mAP50 under YOLOv5
When MSCAM is applied in the backbone network, the mAP and mAP50 can be increased up to 22.3% and 39.1%, respectively. The number of calculation parameters and FPS are almost maintained. It means that extracting the small object features from global and local scales can obtain more feature information than that only from a global scale. Importantly, these attention mechanisms only focus on the channel information to capture the features of small objects. Further considering the spatial information, MSCAM can be replaced by SPP-MSCAM in the backbone network. It is found that the Precision, mAP and mAP50 with SPP-MSCAM are further increased up to 50.6%, 22.5% and 39.4%, respectively, which are superior to the case of MSCAM. The amount of calculation parameters is higher than that of YOLOv5 because the pooling pyramid and global average pooling are all used in our SPP-MSCAM, resulting in the enhancement of calculation in the whole which would lead to the reduced FPS. Though the FPS is decreased by 16 compared with the case of YOLOv5, the comprehensive performance of the detection network with SPP-MSCAM is still improved.
The introduction of the attention module SPP-MSCAM enables the network to extract richer spatial and channel features. However, due to the continuously down-sample operations, these richer features and high-resolution information generated by shallow layers would be gradually lost. Moreover, once the high-resolution information is lost, some important features cannot be underutilized anymore. This may be the reason that only using an attention module such as SPP-MSCAM cannot improve the detecting performance dramatically.
To address the issue, one way is to capture the richer channel and spatial features with high-resolution from shallower layers and then fuse these features with more semantics features from deeper layers. Thus, by up-sampling the features including more semantics information from the deeper layer and matching the size of the features including more channels information with high-resolution from the shallower layer, the features from the deeper layer and shallower layer could be fused, and then the corresponding prediction branch can be established successfully. The corresponding structure can be called ESOD, as indicated in Fig. 3.
To demonstrate the effectiveness of ESOD, comparative experiments are also performed on the VisDrone2019 dataset. The experimental results can be seen in Table 2. The YOLOv5
Contrastive experimental results in different enhanced network
Contrastive experimental results in different enhanced network
Compared with the YOLOv5
For the detection performance of small objects, mAP50 and mAP are the two most important target aims. To comprehensively compare these two properties, the mAP50 and the mAP under different models are shown in Fig. 4. Similar to the description of different models only with attention mechanisms, the network with SPP-MSCAM somewhat outperformers other networks. When ESOD and ESOD512 are applied, the network performance can be improved apparently. In a word, the SPP-MSCAM and the ESOD512 are very helpful for detecting small objects in complex scenes.
Quantitative results of mAP50 and mAP curves under different models.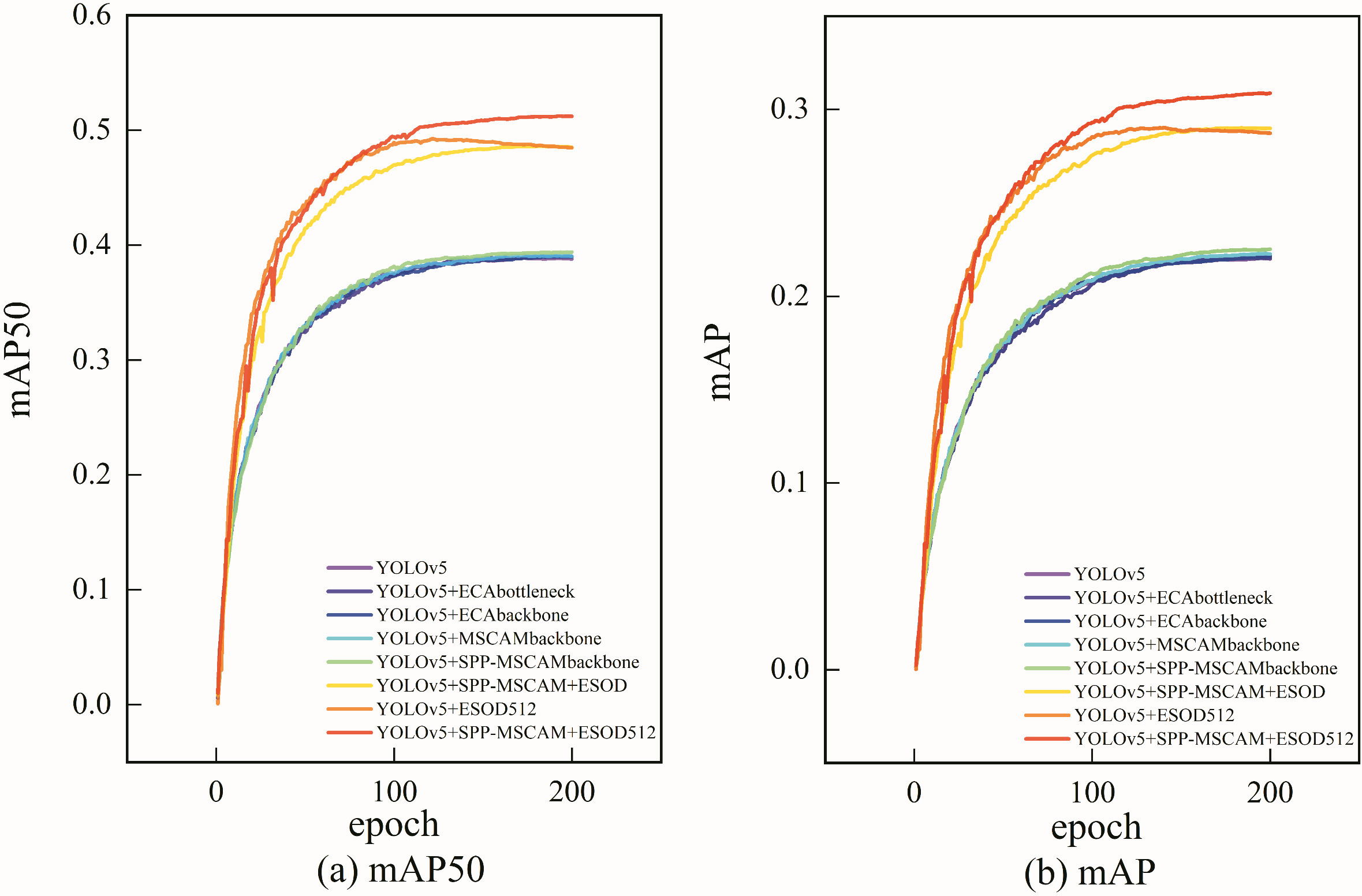
In addition, a series of ablation experiments were carried out on the NWPU VHR-10 dataset to demonstrate the effectiveness of the proposed method. As shown in Table 3, compared with YOLOv5, mAP of YOLOv5
The ablation experiments result in different models on the NWPU VHR-10 dataset
The ablation experiments result in different models on the NWPU VHR-10 dataset
To verify good performance of the improved network for detecting small objects, some typical algorithms are tested on VisDrone2019 dataset. The results can be shown in Table 4 and the bolded number indicates the best results. Resnet50 [16] are used in Faster R-CNN [30] and Retina-Net [36] as backbone network while VGG16 [18] is selected as the backbone network in SSD300 [38]. Apparently, the detection accuracy of the method proposed in this paper is better than other algorithms while the FPS is relatively well. Undoubtedly, the model and its corresponding algorithm proposed in this paper can effectively improve the detection accuracy of small objects and preserve a good real-time performance simultaneously.
Comparison of the mAP50, mAP and FPS under different models on the VisDrone2019 dataset
Comparison of the mAP50, mAP and FPS under different models on the VisDrone2019 dataset
To further demonstrate the effectiveness of the method proposed in this paper on different datasets, the NWPU VHR-10 dataset is selected as a candidate. The experimental results can be seen in Table 5 and the bolded number indicates the best results. It clearly indicates that the method proposed in this paper can both exhibit good performance on different datasets.
Comparison of the mAP50, mAP and FPS under different models on the NWPU VHR-10 dataset
To further compare the proposed way in this paper and the YOLOv5 network for detecting small objects in complex scenes, three images with many small objects including tiny objects, aggregated objects with low light and occlusive objects are selected to visually describe the difference. The visualization results under can be seen in Fig. 5a, c and e, respectively. In Fig. 5a, it is found that many tiny objects are undetected, which can be seen in the region denoted by the frame. Compared with the result of the YOLOv5 network in Fig. 5a, the YOLOv5
The visualization results of small object detection on the VisDrone2019 dataset. (a), (c) and (e) represent the detection results of YOLOv5 network, respectively. (b), (d) and (f) represent the detection results of YOLOv5
In summary, we propose an enhanced network for detecting small objects in complex scenes in this paper. Due to the aggregation and occlusion of small objects in complex scenes, we design the SPP-MSCAM module to obtain a larger receptive field, rich spatial information and multiscale channel information for effectively capturing more features of small objects. More importantly, the feature information can be adequately fused by ESOD512 with higher resolution from the shallower layer. The experimental results on the VisDrone2019 dataset and NWPU VHR-10 dataset demonstrate the effectiveness of the improved network. Moreover, compared with other classical algorithms, the enhanced network achieves a considerable performance for detecting small objects, which would be helpful for potential applications in various fields.
Footnotes
Acknowledgments
Jiangxi Provincial Natural Science Foundation (Grant No. 20224ACB201010). This work was supported by the Doctoral Start-up Fund of Jiangxi Normal University (No.9569).