
Abstract
Multi-label text classification is a method for categorizing textual data based on features extracted from the original textual information. When it comes to modelling text structural properties, Graph Convolutional Network (GCN) has demonstrated outstanding performance. However, most existing graph-based models do not model the structure of a single text unit and do not consider the sequence information in each document (e.g., word order). To resolve these issues and fully utilize the text’s structural and sequential details, a text classification model called Sequential GCN with Multi-Head Attention (SGCN-MHA) is proposed in this paper. For each text, a separate text graph is constructed in which nodes are the words of the text, and the edges between nodes corresponding to the word relations. Then the GCN is used to extract the structural feature. To enable the word nodes in the document graph to hold contextual information, the BiLSTM is also applied to learn the sequential feature for each graph. Finally, the Multi-Head Attention mechanism is adopted to interact with these two features and then aggregate them to get access to critical information in the text. The efficiency of our approach has been tested on two standard datasets, including comparative and ablation experiments.
Introduction
In today’s society, people are creating and acquiring more and more content on the Internet, with significant news platforms generating large amounts of textual data every moment, such as chat posts, movie reviews, product evaluations, and news on a wide range of topics. Extracting relevant data from different types of textual data is a natural necessity in people’s daily lives. Text classification, as a common Natural Language Processing (NLP) technique, can play an important role in the processing and analysis of web text data. Text classification can be applied to many domains, such as sentiment classification [1, 2], question and answer [3, 4], recommend systems [5], literature organisation [6], disease diagnosis [7], topic annotation [8], etc.
Three stages of development can be used to categorize the history of text classification processing technology. The first stage was before 1980 and was stuck at the level of writing rules manually. The researchers tried to classify the text using the matching rules approaches and finally predicted the class of text data for these words. However, manual methods have many drawbacks. Firstly, analysing textual data and the subsequent maintenance of the rules is labour-intensive, time-consuming and money-consuming and can take several years of work by experts in the field. Secondly, the classification of texts applies only to one dataset and does not apply to other datasets. The second stage started after the 1980s when researchers began using machine learning algorithms to implement automatic classification. Boreham [9] initially represented the words in the text as vectors and used clustering to classify them. Torsten [10] was the first to use plain Bayesian classification and TF-IDF (Term Frequency – Inverse Document Frequency) to classify news text data. He also proposed SVM (Support Vector Machines) [11] later and proved that it is better than plain Bayesian, K-Nearest Neighbour (KNN) [12] in classification effect. The third stage is in the last two decades. Many neural network-based models appeared, including Convolutional Neural Network (CNN) [13] and Recurrent Neural Network (RNN) [14] and other neural networks, have been applied to text categorization challenges. These approaches focus on, for example, the sequential structure of the text and the flat form of pictures. Still, in real life, more data representations are not simply sequential or flat arrangements but are represented as more complex graph structures, such as social networks, regulatory networks, biomolecular structures, etc. This led to the emergence of an entirely new type of neural network: the Graph Neural Network (GNN) [15].
Since GNN has a natural advantage in preserving and modelling structural information, some researchers have started applying existing neural network models to graph structures for end-to-end graph modelling. Graph Convolutional Network (GCN) is one of the most popular neural networks. KipF et al. [16] first used GCN to do text classification tasks, outperforming the conventional CNN model. Afterward, Yao et al. [17] proposed TextGCN, which uses words and documents as nodes to create a large, coherent graph of the whole corpus. However, this model is challenged by a series of problems, such as a lot of graph-based methods failing to adequately account for local aspects of the text, like key phrases and word order information specific to each document.
In order to overcome the challenges mentioned above, a new model called Sequential GCN with Multi-Head Attention (SGCN-MHA) is proposed. After constructing a graph for each input document, GCN is used to extract the structural features, and BiLSTM is used to extract the contextual semantic relationships of the text in two directions. The Multi-Head Attention mechanism is employed to interact with the two features and assign weights to them in order to acquire the critical feature words while also maximizing the use of the two features in the classification process. Compared with other models, this approach overcomes the limitation of other models that may focus solely on one aspect (structural or sequential features) and provides a more holistic solution for document classification tasks that require considering both types of features simultaneously. Therefore, the problem of effectively leveraging both structural and sequential information in the classification process can be uniquely addressed by the SGCN-MHA model. In summary, this paper makes three important contributions:
The proposed model can learn different features from multiple aspects. It takes into account both semantic semantics from BiLSTM and structural semantics from GCN, thus enhancing the representation effect of the trained text. To avoid the separation of these two semantics in the prediction process and to look for essential terms that are more applicable to the assignment, a Multi-Head Attention mechanism is used, which can interact with the two representations to fully exploit them and give certain words varying amounts of weight for better classification results. Two popular datasets are used to test the effectiveness of SGCN-MHA. The comparative and ablation experiments are conducted to show the better performance of our model.
The rest of the paper is organized as follows. A synopsis of recent work on text classification methods is discussed in Section 2, along with the state of the art of GCN text classification research. The proposed text classification model SGCN-MHA is further explained in Section 3. The experiment’s datasets, assessment metrics, and outcomes are described in Section 4. The experimental results are then presented and discussed. In the end, Section 5 presents the conclusions of this paper.
Related work
Text classification
Text classification is an essential area of Natural Language Processing (NLP) [18] and is widely used in recommendation systems, question-and-answer systems, sentiment analysis, and other regions. The process of classifying texts into one or more groups based on predetermined labels and the characteristics of the texts is known as text classification. Depending on how many labels are provided, a single or multi-label text classification might be used to describe the text classification task. Single-label text classification classifies each text data into a single-label category. Multi-label text classification, as opposed to single-label text classification, separates each text’s data into several label categories that are more useful in practical contexts and correlate to objective objects’ characteristics and norms.
Text classification technology has evolved from manual annotation to machine learning algorithms and then to deep learning techniques. Traditional methods, such as plain Bayesian [19], K-Nearest Neighbor (KNN) [12], and Support Vector Machines (SVM) [20], have been studied using feature engineering to represent text, like Bag-of-words (BOW) [11], N-Gram [21], and Topic Model [22]. For researchers, it is necessary to obtain manually specified features and use machine learning algorithms to train and predict. The classic machine learning algorithms can no longer meet the performance requirements of algorithms used in actual applications due to the number of computer resources and the vast amount of data involved.
Due to deep learning’s rapid development, particularly in image and speech processing, artificial intelligence has made significant strides in recent years. Inspired by this, deep neural network-based techniques have been used extensively in text classification. Currently, the two most popular deep learning models are Convolutional Neural Network (CNN) [13] and Recurrent Neural Network (RNN) [14]. They are good at capturing local information and extracting a sequence’s most important information without changing the input sequence’s position. Kim et al. [23] introduced TextCNN in 2014, a text classification model with CNN as the processing framework, which includes convolutional, pooling, and output layers. The model achieved good classification results and became a new benchmark method for text classification at that time. Although CNN effectively extracts local information from the text, it does not perform well with long text. RNN has a set of memory cells, so RNN can be adapted to process the sequential data and is better than CNN in capturing sequence context. It produces an output depending on the memory cells and the current input as each data sequence is received. Although RNN is good at processing sequential data, it suffers from gradient instability when processing long sequences, which prevents it from capturing relationships between long words. The optimized RNN models, such as Long Short-Term Memory network (LSTM) [24] and Gated Recurrent Unit (GRU) [25], as well as BiLSTM and BiGRU, which are derived from them, improve the shortcomings of general RNN to some extent. Deng et al. [26] proposed the ABLG-CNN model, combining BiLSTM and CNN to obtain contextual and important topic information. Teng et al. [27] integrated two methods, using BiGRU to extract contextual information from the text and CNN to extract local information. In addition, pre-trained language models have attracted more attention, such as BERT [28]. It has been pre-trained on a sizable dataset and can be fine-tuned for use in NLP subtasks. Prabhu et al. [29] proposed a BERT-based active learning strategy for multi-label text classification. Liu et al. [30] used an improved BERT model ALBERT, combined with CNN for text classification. These models, however, frequently ignore the co-occurrence of single words and fail to fully use the text’s structural characteristics, focusing instead primarily on the order of the text.
Graph Convolutional Network
Recently, Graph Neural Network (GNN) has also become popular because it has proven to be a powerful tool for solving text classification problems by considering the correlation between words and preserving the global structural information of graphs. GNN captures the semantic relation between words by converting textual data into graphical data to discover more effective methods of expressing the nodes or the whole network and has succeeded in several text categorization tasks. Therefore, GNN can directly handle complex structural data by prioritizing global domain information. Several researchers use existing neural network models for graph structure to model graphs end-to-end, the most popular of which is the Graph Convolutional Network (GCN). Bruna et al. [31] proposed the first GCN model in 2013. They used the convolution theorem and graph theory to define graph convolution in spectral space. But the original GCN model has the disadvantage of high time-distance complexity. Kipf et al. [16] presented a simplified GCN model that can significantly reduce the time-distance complexity of parameterizing the convolution kernel using the spectral approach. They also did the text classification task, and the result outperformed the conventional CNN model.
In order to build graphs for complicated corpora, there are two main approaches to do. Making a vast, unified corpus text graph based on the word relationships of the words and documents in the entire corpus is one approach. The TextGCN algorithm developed by Yao et al. [17] created a corpus-level graph of words and documents as nodes, which achieved good performance in the text classification task. SGC [32] and S2GC [33] used the same approach as TextGCN to construct a graph but proposed a different method of information transmission. TensorGCN [34] and TextGTL [35] built a semantic-based graph, a syntactic-based graph, and a sequence-based graph in three different methods. Each of these three graphs was whole-corpus based and used the same approach to communication used in the GCN. Because these models build a large graph based on the whole corpus, it will lead to significant memory consumption. If there are new documents, it needs to modify the entire graph structure. In addition, it is unable to take into consideration the structural features of individual documents. The other method builds small individual graphs for each document in the dataset, including semantic and syntactic correlations graphs. Huang et al. [36] proposed a new graph-based model in which the graphs of each input text are constructed using much smaller text windows rather than a single graph of the whole corpus. This approach drastically decreases the number of edges and the memory overhead while extracting additional local characteristics. Zhang et al. [37] proposed TextING, a graph-based text classification model that shows how each document’s words relate to one another in context and enables the inductive learning of new words. Although GCN can learn the graphic structure information of the text, such as syntax and semantic parse tree, they need to pay more attention to the order of the text.
Now, due to the popularity of the pre-training model, researchers have begun to combine the pre-training language model with the GCN. TG-Transformer proposed by Zhang et al. [38] combined Transformer and GCN. Jeong et al. [39] made use of GCN and BERT to produce a document encoding and a context encoding for the recommendation task. However, this method cannot take into account interactions between features, which reduces the mapping possibilities. Lu et al. [40] propose the VGCN-BERT model (VGCN) by combining BERT capabilities with a vocabulary GCN. Lin et al. [41] proposed BertGCN, which embedded BERT into TextGCN. She et al. [42] processed the event text using GCN and BERT to get the relevant representation vectors, respectively. However, these models, which use pre-trained models, are computationally expensive and require external resources that are not always accessible.
Proposed SGCN-MHA model
System overview
This section describes the architecture of the SGCN-MHA comprehensively. In Fig. 1, the model architecture is shown, which consists of four components: graph construction, GCN layer, BiLSTM layer, and attention layer. There are four stages in our model. Concretely, the raw data is pre-processed in the graph construction stage, and then different graphs are constructed for each input document by the words’ relationship. The text’s nodes stand in for the individual words, while the edges show how those words are related. After the graph construction stage, GCN extracts the structural feature so that the neighbourhood features of every word node can be collected to study the word representations from their neighbourhood structures. Moreover, in the BiLSTM-based feature extraction stage, BiLSTM takes complete account of the contextual information of each word in the document, aiming at upgrading the two-way representation of the word nodes in each document graph frontward and backwards. The second stage considers the text’s structural elements, while the third stage represents the documents’ semantic content. Finally, in the attention stage, before aggregating the contextual data, these two features are interacted with and combined on each graph using the Multi-Head Attention technique to solve the feature interaction problem and concentrate on the text’s main ideas. The final text representation through the attention layer is calculated based on this score using the output of GCN and BiLSTM as the input. Then the text’s label can be predicted based on learned representations. Further details are given below.
Table 1 summarizes significant notations for convenience of reference.
Notations
Notations
The architecture of SGCN-MHA. (a) The input document where 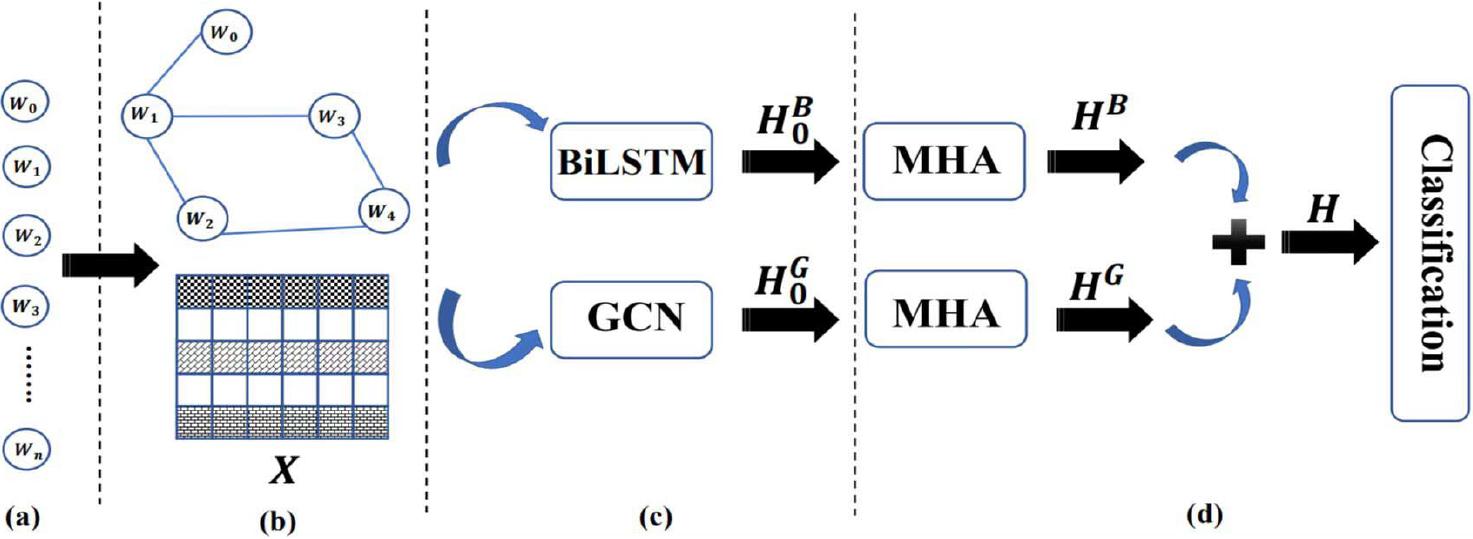
Independent graphs are created for every input document, with all words in the text represented as nodes and the relationships between words as edges. The text’s words can be represented as
In this equation,
First, the raw data must be pre-processed using standard methods, like word cleaning. Unprocessed data may contain many useless data, such as website link data, punctuation marks, etc. This data is of no practical relevance for many classification tasks and is usually discarded as noisy data. Moreover, the stop words and the words appearing less than five times in the document need to be removed. Stop words such as conjunctions, exclamation marks, or end-of-sentence intonation, which are present in a large number in the text, do not contribute to text classification and may even severely interfere with the classification task. So stop words should be efficiently filtered away to enhance both the model’s and classification task’s performance.
After data preprocessing, the joint recurrence information needs to be extracted in order to model the correlation between words in the document. To achieve this, a sliding window approach is employed by selecting a fixed-size window of four words and iterating over the text corpus. For each window, an edge is created between the four words in the window and added to the graph. This process is repeated for each window in the corpus, resulting in a graph where each node represents a unique word and each edge represents the co-occurrence of two words within a fixed distance of each other. The graph has three important matrices, as shown in Fig. 2. The first graph is an adjacency matrix
An illustration of the constructed graph, adjacency matrix 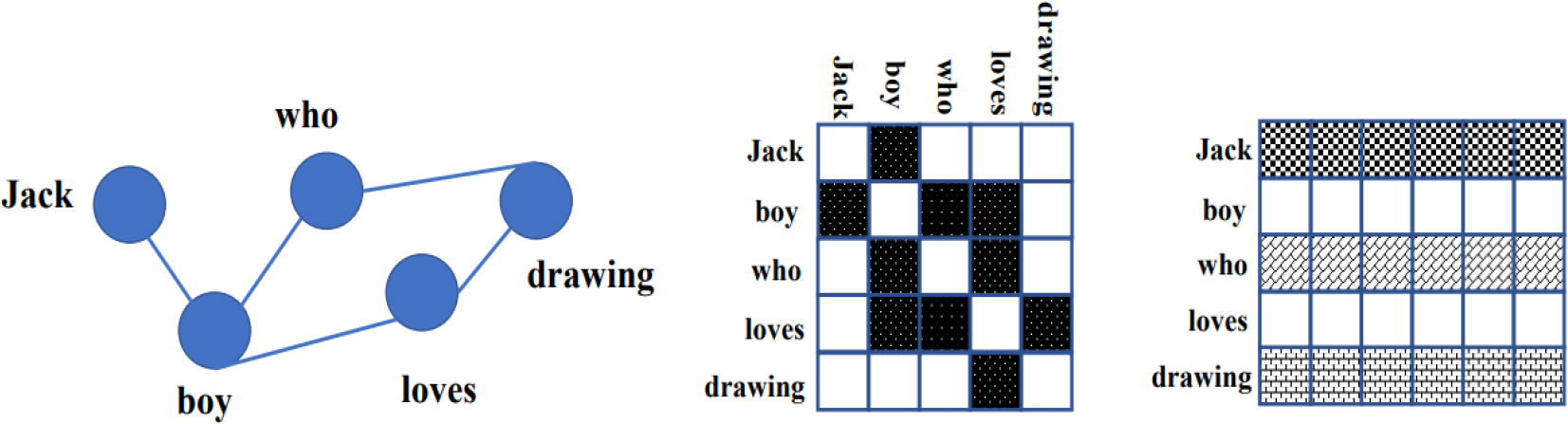
After constructing the graphs, the text co-occurrence graph
The formulas for GCN are shown in Eqs (3)–(5). GCN has two inputs, one is the adjacency matrix
Word order is important for text classification, so it is necessary to learn both front-to-back and back-to-back information at the same time. For each text graph, a BiLSTM network is used to extract the sequence information, and the text word vectors are encoded into hidden vectors with contextual semantic information. BiLSTM is composed of forward LSTM and backward LSTM, so it is often used to model contextual information in the field of NLP.
The LSTM model owns an adaptive locking mechanism to ensure that the LSTM neural unit maintains its previous state and remembers the feature extraction of the current input neural unit. The LSTM block consists of a forgetting gate, an input gate, and an output gate, denoted as
Although the LSTM model is a unidirectional distribution model and cannot extract text context information, in a text classification task, the outcome of the current instant is frequently linked to both the words that came before it and the words that came after it. Whereas in the BiLSTM model, each sequence of text is distributed in a back-and-forth and forth-and-back two directions, and then extract the contextual information of the sequence is. Therefore, the sequence representation obtained by the BiLSTM model takes contextual semantic information into account, and its feature-rich representation is more suitable for text classification.
For each document-level graph, BiLSTM is used to obtain contextual information between words in order to learn each document’s word representation and then modify the document’s corresponding feature matrix. For example, in order to encode “We love singing”,
After each graph has had its structural and time series features extracted using the GCN and BiLSTM, respectively, the Multi-Head Attention mechanism is applied to each graph. The Multi-Head Attention mechanism makes it possible to represent a node that is affected by several dependencies, allowing it to incorporate multiple behaviors, such as capturing various dependencies in a sequence and learning different behaviors based on the same attention mechanism. Because of this, even though it is a polysemous word, its precise definition can be determined through various dependencies.
The primary process of the Multi-Head Attention mechanism can be divided into three stages. The first step is to identify the different subspaces of the queries, the key, and the value mappings. The second step is to transform the query matrix
The text representation obtained from GCN is defined as
Attention layer.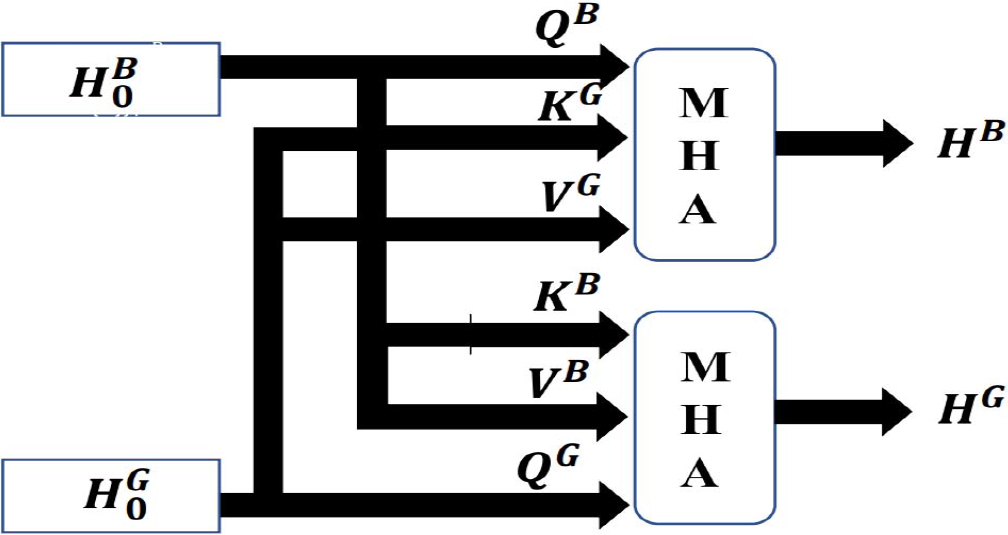
The extracted features
After feature aggregation, a Softmax function is employed to predict the document’s label. As shown in Eq. (16),
Moreover, to train the model, the cross-entropy loss is used between the actual label
This section contains a detailed description of experiment datasets, evaluation indicators, comparative experimental results, and ablation experimental result. Firstly, comparative experiments are conducted on two datasets with SGCN-MHA and several benchmark models and compare the results of the experiments for text classification. Afterwards, ablation experiments on SGCN-MHA are performed to explore whether several parts of the model can improve the model’s effectiveness.
Datasets
Two publicly accessible datasets are chosen to test the SGCN-MHA in order to validate its effectiveness. The specific information on these two datasets is as follows:
RCV1-V2 [43]: RCV1-V2 (Reuters Corpus Volume I) is a Reuters dataset provided by Lewis et al. This dataset has more than 800000 Reuters English news texts and corresponding news categories. The dataset also contains 103 news topics, which may have multiple topics. The experiments need to predict topics according to the news content. AAPD [44]: AAPD (Arxiv Academic Paper Dataset) is a dataset of Arxiv academic papers provided by Yang et al., which collects 54840 papers in the field of computer science, including abstracts and corresponding keywords. Each paper abstract will correspond to multiple keywords. The dataset contains 54 keywords in total. The experiments need to predict the keywords corresponding to the paper according to the abstract of the paper.
The original text needs to be pre-processed because it contains a lot of noisy data, such as punctuation and stop words. Stop words mean the data of pronouns, prepositions, and adverbs, which have no practical meaning and have no impact on the classification. Removing these words can improve the density of keywords so that the text features can be extracted more accurately. Then the words need to be standardized. All words should be converted to lowercase and checked for misspellings, as well as the original lexical form of the word should be checked, and the word should be converted to its standard form. Each dataset in this experiment is divided into a training set, a test set, and a validation set. Table 2 displays the datasets’ statistical information. When conducting experiments with the RCV1-V2 dataset, a total of 804,414 individual graphs are constructed. When conducting experiments with the AAPD dataset, a total of 55,840 individual graphs are constructed.
Statistics of datasets
Statistics of datasets
This research uses four evaluation indicators to evaluate the SGCN-MHA’s performance: precision, recall, f1-score, and hamming loss. The precision represents the proportion of text classification models whose positive predictions are correct accounts for all positive predictions. The recall represents the proportion of text classification models with correct positive predictions compared to all actual positive predictions. The f1-score is a total precision and recall score that measures how well the classification model performed overall. Equations (18)–(20) are used to display the calculation formula for precision, recall, and f1-score.
In these equations, positive samples are referred to as positive class by the model, negative samples as a negative class by the model, negative samples anticipated as a positive class by the model, and positive samples as a negative class by the model are referred to as
The hamming loss is used to examine the misclassification of samples on individual tokens, such as relevant tokens not appearing in the predicted set of tokens or irrelevant tokens appearing in the predicted set of tokens. The smaller the value of this metric, the better the model performance. If
Various methods are used as baselines, including LEAM, LSAM, SGM, and Seq2Set. Following that, we contrast them with the findings of our own model SGCN-MHA.
LEAM [45] embeds labels to produce a more discriminating representation of the content when classifying text. LSAN [46] implements label information and uses an attention mechanism to capture semantic information between documents and different labels. SGM [44] is a sequence generation model that employs an LSTM-based Seq2Seq model combined with an attention mechanism, while the decoding phase uses global embedding to obtain inter-tag dependencies. Seq2Set [47] adds a set decoder to SGM to take advantage of the unordered nature of the set to reduce the impact of incorrect label ordering. Not only does it capture the relationship between labels, but it also reduces the dependence on label sequences.
On the RCV1-V2 and AAPD datasets, SGCN-MHA is compared with other models for text categorization. Tables 3 and 4 display each model’s precision, recall, f1-score, and hamming loss. A better model with a higher value is denoted by a “
Table 3 demonstrates that Seq2Set, which takes label correlation modeling into account, essentially achieves the best results of these benchmark methods on the RCV1-V2 dataset. However, the model proposed in this paper produces better results than the Seq2Set, with significant improvements in some evaluation metrics. It is possible that Seq2Set’s basic architecture for sequence-to-set transformation, which may not successfully capture the complicated features and sequential information available in text data, is the cause of its a little insufficient performance in comparison to SGCN-MHA in text classification tasks. In contrast, SGCN-MHA is better suited for capturing text associations and structure since it can effectively catch semantic details and context-related information. Table 4 demonstrates that the label embedding method LSAN on the AAPD dataset shows promise, however compared to SGCN-MHA, LSAN might struggle due to its possible shortcomings in capturing complex semantic links. The SGCN-MHA allows for better handling of complex relationships while LSAN concentrates on label-specific document representations using semantics and self-attention. The complete method used by SGCN-MHA contributes to its high performance, excels at capturing complicated meanings.
Experimental results of comparative experiments on RCV1-V2 dataset
Experimental results of comparative experiments on RCV1-V2 dataset
Experimental results of comparative experiments on AAPD dataset
In order to verify whether GCN, BiLSTM, and the Multi-Head Attention mechanism contribute to the text classification task, three models are designed and compared with the original model on the RCV1-V2 and AAPD datasets, respectively.
GCN is imported to extract the text’s structural features. The original model and the no-GCN model are contrasted in order to demonstrate if GCN may enhance the classification performance of SGCN-MHA. The results from Tables 5 and 6 show that the performance of the no-GCN degrades when the GCN is removed. It is clear that the GCN plays a crucial role because of its ability to accurately record intricate relationships between data elements. Additionally, by supplying vital contextual information, it improves the model’s comprehension, thus enhancing its capacity to make wise selections during classifying tasks. Therefore, its absence might deprive the model of these vital skills, which would greatly impair its classification ability. BiLSTM is used to preserve the text’s sequence information. The original model is contrasted with the no-BiLSTM model to see if BiLSTM may enhance the classification effect of the model. It is evident from Tables 5 and 6 that the model with no-BiLSTM is less effective than the original model. The no-BiLSTM model’s efficiency suffered noticeably as a result of the absence of BiLSTM because of BiLSTM’s contributions. Since BiLSTM is adept at capturing sequential features, the model may pick up on tiny details in the data, which is crucial for tasks that depend on sequential information for improved classification accuracy. Additionally, the model’s ability to distinguish significant information from the input is improved by its skill at extracting features, which helps the model make better classification decisions. To figure out whether applying the Multi-Head Attention mechanism improves the model’s classification performance, the original model is compared to a model with the Multi-Head Attention mechanism removed, known as no-MHA. It is evident from Tables 5 and 6 that the original model performs better than the model without MHA. Due to the various contributions of the Multi-Head Attention mechanism, the original model is more effective to the no-MHA model. MHA improves the model by enabling dynamic feature interaction, building a thorough comprehension of contextual details, making it simpler to extract abstract features that capture complex patterns and improving the creation of demonstrating data representations.
Experimental results of ablation experiments on RCV1-V2 dataset
Experimental results of ablation experiments on RCV1-V2 dataset
Experimental results of ablation experiments on AAPD dataset
In this work, a text classification model named SGCN-MHA based on BiLSTM-GCN and the Multi-Head Attention mechanism is proposed, which can better analyze the textual features. Each document is trained as an individual graph, and GCN extracts the structural characteristics of the text. Additionally, BiLSTM is imported to extract the sequential feature in both the front and back directions in order to preserve the word order information in each document. Also, to extract the important information from the text and avoid the separation of these features, on each graph, the Multi-Head Attention mechanism works on each graph to interact with and aggregate the structural and sequential features. The model is compared with other benchmark methods on two standard datasets to evaluate the model’s effectiveness, and the experiment results prove the effectiveness of our model. The ablation experiments are also performed to demonstrate the usefulness of each component of the proposed model.