
Abstract
In the digital era, the rapid advancement of artificial intelligence has put a spotlight on target detection, especially in traffic settings. This area of study is pivotal for crucial projects like autonomous vehicles, road monitoring, and traffic sign recognition. However, existing Chinese traffic datasets lack comprehensive benchmarks for traffic signs and signals, and foreign datasets do not match Chinese traffic conditions. Manually annotating a large-scale dataset tailored for Chinese traffic conditions presents a significant challenge. This study addresses this gap by proposing a cross-augmentation method for image datasets. We utilized YOLOX for target detection and trained models on the BDD100K dataset, achieving an impressive mAP of 60.25%, surpassing most algorithms. Leveraging transfer learning, we enhanced the CCTSDB dataset, creating the ACCTSDB dataset, which includes annotations for common traffic objects and Chinese traffic signs. Using YOLOX, we trained a traffic detector tailored for Chinese traffic scenarios, achieving an mAP of 75.79%. To further validate our approach, we conducted experiments on the TT100K dataset and successfully introduced the ATT100K dataset. Our methodology is poised to alleviate the limitations of manually annotating image datasets. The proposed ACCTSDB dataset and ATT100K dataset are expected to compensate for the lack of large-scale, multi-class traffic datasets in China.
Keywords
Introduction
The advancement in computer hardware and the widespread use of Convolutional Neural Networks (CNN) in computer vision have led to the emergence of numerous target detection algorithms. These approaches generally fall into two categories. The first category relies on candidate regions, exemplified by the R-CNN series [1, 2, 3, 4]. Initially, candidate frames are extracted using the selective search method, followed by classification and modification by CNN. While this method achieves high accuracy, its computational demands and long detection times limit its real-time applicability in traffic management. The second category treats the detection problem as a regression task, as seen in the YOLO series [5, 6, 7, 8, 9, 10]. These algorithms predict the location and category of targets directly using CNN for one-stage feature extraction. While their accuracy is slightly lower than the first category, they offer faster detection and lower hardware requirements, making them more suitable for real-time urban traffic vehicle detection. The latest visual algorithms are based on Transformer [11], marking a departure from traditional CNN and R-CNN. Instead, they rely solely on self-attention and Feed Forward Neural Networks. Notably, in 2022, the Vision Transformer [12] successfully integrates insights from both computer vision and natural language processing and applies Transformer-based techniques to target detection. It is worth noting that these algorithms often demand substantial computational power to achieve outstanding performance.
With the proliferation of autonomous driving, road monitoring, and traffic sign recognition, the application of deep learning for traffic object detection has emerged as one of the most prominent research areas in recent years. In support of this endeavor, various traffic datasets have been meticulously curated to facilitate the utilization of machine learning for distinguishing traffic objects. Among these datasets, one of the most comprehensive and extensive is the BDD100K dataset [13], authored by Fisher Yu et al. It comprises 100,000 images and encompasses 10 distinct benchmarks, all designed to assess and significantly advance the capabilities of autonomous driving object detection algorithms while concurrently enhancing traffic detection. Nonetheless, the availability of datasets specifically tailored to Chinese traffic conditions remains relatively limited. This scarcity is attributed to the substantial disparities that exist between traffic conditions and traffic signage in different countries. In China, there are several relatively mature public traffic datasets, each with its own focus, such as CCTSDB (only traffic signs) [14], D2-city (no traffic sign) [15], TT100K (only diverse categories of Chinese traffic signs) [16], ApolloScape (no traffic sign) [17]. Evidently, these public datasets do not encompass benchmarks for a comprehensive range of traffic targets. Another major issue is the enormous workload and time consumption involved in manually annotating Chinese traffic signs as well as vehicles, pedestrians, and other traffic objects.
To address these problems, We explored a data cross-augmentation method based on object detection algorithms in our research, with the aim of creating a comprehensive dataset that encompasses labels for both traffic objects and Chinese traffic signs. Figure 1 illustrates the research workflow. We hope our approach can enhance the dataset by using AI for automatic annotation, replacing manual labeling and reducing the labor and time required for human annotation. Datasets like BDD100K and CCTSDB have been considered for this study, and it is necessary to note their respective limitations. The BDD100K dataset, collected in foreign countries, comprises 10 labels, including vehicles, persons, bikes, traffic lights, and more. However, it may not entirely align with Chinese traffic conditions. On the other hand, the CCTSDB dataset is a traffic dataset collected within China but exclusively covers labels for 3 types of traffic signs. In our approach, We began by assessing the performance of existing target detection algorithms, and under favorable hardware conditions, we opted to train the YOLOX model on the BDD100K dataset. We then conducted hyperparameter tests on YOLOX and compared the optimal results with other relevant studies. Subsequently, We improved the output method of YOLOX and enhanced the CCTSDB dataset by combining YOLOX with the pre-trained models from the BDD100K dataset using the transfer learning approach. In the experiments, we demonstrated that this dataset cross-augmentation method allows object detection algorithms to automatically annotate categories present in the BDD100K dataset, such as vehicles, pedestrians, and traffic lights, within the CCTSDB dataset. Ultimately, we evaluated the performance of this innovative dataset, which we refer to as ACCTSDB. To thoroughly assess the effectiveness of our method on other datasets, we replicated our approach on the TT100K dataset, which contains a more detailed categorization of Chinese traffic signs. We also introduced the ATT100K dataset. The experiments demonstrated the effectiveness and generalizability of our method.
Flow chart of a cross-augmentation method for image datasets.
In summary, our motivation is to use AI techniques to enhance datasets, addressing the shortcomings of publicly available traffic datasets in China as well as the limitations of manual annotations. we conducted an extensive series of experiments and made the following contributions:
We devised a dataset cross-augmentation technique based on a target detection algorithm, enabling AI to automatically learn benchmarks from one dataset for annotating another dataset expand labels, and address the limitations of manual annotation. We introduced a dataset called ACCTSDB, consisting of 11 traffic target labels, including benchmarks for three types of Chinese traffic signs, for addressing the scarcity of large-scale public traffic datasets aligned with Chinese traffic conditions. We reproduced our data cross-augmentation method on the TT100K dataset and obtained the ATT100K dataset, which encompasses annotations of 181 categories, demonstrating the versatility of our approach.
Our primary work involved the BDD100K dataset, the CCTSDB dataset, and the YOLOX algorithm. We conducted data analysis on the BDD100K and CCTSDB datasets, evaluating why the CCTSDB dataset is suitable for enhancement. Additionally, we analyzed the YOLOX algorithm and demonstrated its suitability for our work.
The BDD100K dataset
As its name suggests, the BDD100K dataset is a comprehensive and extensive driving dataset, comprising 100,000 images of varying sizes, each meticulously annotated. Within this dataset, benchmarks have been recorded for ten types of traffic targets, encompassing 816,661 cars, 104,700 persons, 213,192 traffic lights, 274,876 traffic signs, 13,285 buses, 34,259 trucks, 5,171 riders, 8,234 bikes, 3,454 motors, and 151 trains. However, it is evident, as shown in Fig. 2, that the labels within BDD100K are not evenly distributed, particularly with only 151 annotations for trains. This imbalance poses a challenge for the trained model’s ability to accurately identify trains. The BDD100K dataset provides invaluable support to current research in vision tasks, including a Vulnerable Road User (VRU) detection based on YOLOv3 and YOLOv4 to facilitate the reduction of traffic accidents [18], and a lightweight boundary refinement module called BRPS exploiting point supervision to decrease the prediction error of the segmentation results [19].
BDD100K label count.
CCTSDB label count.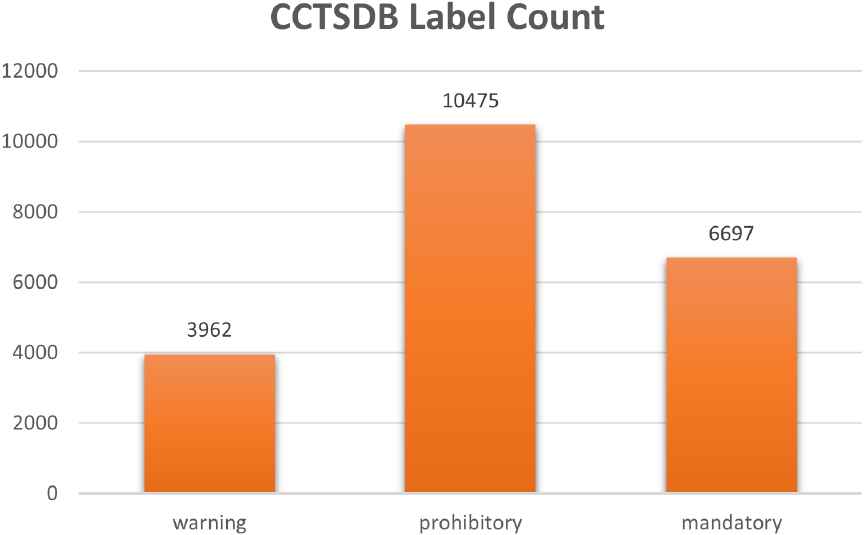
The CCTSDB dataset contains about 15, 000 images, including original images, images of horizontal changes in the original image, images of noise adding, and images of adjustable brightness. The label count of the CCTSDB is shown in Fig. 3 which contains 3962 warning traffic signs, 10475 prohibitory traffic signs, and 6697 mandatory traffic signs. In recent years, numerous research efforts have introduced new traffic sign detection algorithms based on the CCTSDB dataset. These innovations aim to enhance both the speed and precision of detecting minor targets within traffic scenes. Notable examples include a pioneering small target detection method that leverages YOLOv3 for multi-scale networks [20] and an improved algorithm known as YOLO-MXANet [21].
It is important to note that while the CCTSDB dataset exclusively contains benchmarks for these three types of Chinese traffic signs and lacks benchmarks for other traffic objects, it is possible to enhance the CCTSDB dataset through transfer learning using other datasets that include benchmarks for general traffic objects. On the flip side, when both datasets share the same label for certain objects, the process of data enhancement via transfer learning can potentially disrupt the benchmarks associated with that particular label. This is why the CCTSDB dataset serves as the base for enhancement. Compared to the BDD100K dataset, the CCTSDB dataset specializes in Chinese traffic signs. The detector trained on the BDD100K dataset can be applied to identify cars, pedestrians, and other traffic objects in the CCTSDB dataset. This simplifies the process of enhancing the CCTSDB dataset by adding annotations for common traffic objects.
YOLOX
On the COCO 2017 dataset [22], YOLOX has outperformed the YOLOv3, YOLOv4, and YOLOv5 series, while maintaining highly competitive inference speeds. Specifically, YOLOX-X achieved an impressive 69.6% mAP_50 at 57.8 FPS on the COCO 2017 dataset, surpassing all state-of-the-art detectors [10]. The baseline model of YOLOX is YOLOX-DarkNet53, which is an improvement of YOLOv3-spp. Its overall improvement strategy integrates several effective research approaches. It incorporates two data augmentation methods, Mosaic and Mixup, at the input end. Furthermore, in the Prediction layer, the Decoupled Head is utilized instead of the traditional Yolo Head. Experimental results have shown that this method leads to faster convergence and higher accuracy. Unlike YOLOv3, YOLOv4, and YOLOv5, which use Anchor-Based approaches, YOLOX employs Anchor-Free methods, reducing the detector’s parameters while achieving faster detection speed and superior performance. The exceptional performance of Anchor-Free is also attributed to YOLOX simplifying the OTA algorithm (SimOTA), enabling optimal sample matching in a short time frame. These improvements have all elevated the AP of the YOLOX baseline model on the COCO dataset by one to two percentage points.
The significant performance superiority of YOLOX over all the state-of-the-art detectors at that time is a key reason for us choosing it as the foundation for our method. Moreover, YOLOX offers a variety of optional networks, including standard architectures like YOLOX-s, YOLOX-m, YOLOX-l, YOLOX-x, YOLOX-Darknet53, and lightweight architectures such as YOLOX-Nano and YOLOX-Tiny. This means using YOLOX as our foundation allows our method to be adaptable to projects with different requirements, especially in situations with limited computational resources. Rather than saying YOLOX is the best algorithm, it is more accurate to say YOLOX is the most suitable algorithm for our method.
Since YOLOX was published, YOLOX has been developed and applied to different scenarios for target detection. For example, using a light attention module and channel shuffle technique in YOLOX for fire scenario detection [23], aggregating both spatial and channel information in the feature map to improve the accuracy of test on transmission line environment dataset [24]. Meanwhile, YOLOX has proved that its detection accuracy is higher than that of YOLOv4 and YOLOv5 for detecting engineering vehicles in aerial images [25].
Method
Framework introduction
As shown in Fig. 1, our framework primarily consists of three components: the target detection algorithm, training dataset 1, and dataset 2 for enhancement. Dataset 2 should not include the benchmarks in dataset 1. We train the target detection algorithm using dataset 1 and perform transfer learning using the trained model and YOLOX to annotate dataset 2 based on the benchmarks learned from dataset 1. The new dataset 3 can encompass the annotations of categories from dataset 1 detected in dataset 2 and the benchmarks of dataset 2. This cross-augmentation method for image datasets can be represented by the following mathematical formula. In this context,
To demonstrate this method, we chose YOLOX as the target detection algorithm, the BDD100K dataset as the training dataset, and the CCTSDB dataset as the enhanced dataset for experimentation. The specific methods include data preprocessing, and enhancement steps, explained in sections 3.2, 3.3. A detailed description of the experiments is provided in Section 4. The formula can be represented as follows in this experiment, where
Dataset preprocessing
The main dataset formats for object detection tasks are COCO, Pascal VOC (hereinafter referred to as VOC), and YOLO. The source code of YOLOX supports both the VOC dataset format and the COCO dataset format. The VOC dataset format contains information about object categories and bounding box coordinates. This format usually has a smaller dataset size, making it suitable for experiments with limited computational resources. On the other hand, the COCO dataset format includes additional information such as object occlusion and keypoint locations, resulting in a larger dataset. It is well-suited for large-scale detection tasks. Although YOLOX’s performance testing is conducted on the COCO dataset [10], due to the limited computational resources available for this project and the focus on adding bounding box annotations for other traffic objects in the CCTSDB dataset, we ultimately chose to convert the BDD100K dataset into the VOC dataset format for training YOLOX in the experiment.
In the VOC dataset format, each image has a corresponding XML annotation file that includes ‘Filename’, ‘Image Size’, and ‘Object Annotations’. ‘Object Annotations’ consist of ‘Class’ labels and their corresponding ‘Bounding Box Coordinates’. To enable the YOLOX algorithm to efficiently train on the dataset, preprocessing is necessary. The annotation files for the test and validation sets in the BDD100K dataset are provided as JSON files. To convert these JSON files into the required XML format, Python is used to extract object data from the JSON files and generate corresponding XML files. Subsequently, XML files are placed in the ‘Annotations’ folder, image files are stored in the ‘JPEGImages’ folder, and the file paths for the training set, validation set, and test set are placed in TXT files within the ‘ImageSets’ folder. YOLOX utilizes this VOC dataset format to access the images and associated information during training.
As the enhanced dataset, we did not convert the CCTSDB dataset into the VOC dataset format. Instead, we made simple modifications to its annotation files to facilitate updating the annotations detected by YOLOX into its annotation files. The annotation file in the CCTSDB dataset is a GroundTruth.txt file, where each line follows this format: image name
Procedure of enhancing the CCTSDB dataset
Since the original output method of YOLOX not being able to write prediction results and bounding boxes into files, we improved the output method of YOLOX. This enhancement is necessary to enable YOLOX to detect using the pre-trained BDD100K model and write the results into the annotation files of the CCTSDB dataset. The specific implementation steps for enhancing the CCTSDB dataset are as follows:
The first step involves outputting the coordinates of prediction boxes along with their corresponding labels. In the YOLOX source code’s prediction section, the default behavior is to display the results on images without saving them. To address this, the ‘vis’ method in the ‘yolox/utils/visualize.py’ file is modified to write new information for each image into its corresponding TXT annotation file, following the idea outlined below:
The Python file mode should be changed to ‘a The Python file mode should be changed to ‘w If there are no predicted box coordinates output, the step of writing TXT files should be skipped. The second step involves converting these TXT files, which contain the new labels, into XML files following the format required for the VOC dataset. The label names are written into ‘
Experiments
Experimental environment
Our Python environment is primarily configured with Python version 3.8, CUDA toolkit version 11.1, and PyTorch version 1.8. We converted both the BDD100K dataset and the CCTSDB dataset into the VOC dataset format. The training code we used for YOLOX was from the source code file located at ‘./exps/example/yolox_voc/yolox_voc_s.py’. Our method implementation experiments were primarily conducted on a single PC equipped with an 11th-generation Intel i7-11800H CPU and an NVIDIA GeForce RTX 3060 GPU. Our hyperparameter test experiments were conducted on a single PC equipped with 4 NVIDIA GeForce RTX 3090 GPUs.
Hyperparameter test
Since the accuracy of the YOLOX-Darknet53 baseline model is relatively low, we primarily tested four different parameter sizes provided by YOLOX. Among these, YOLOX-s has a parameter size of 9 m with an average speed of 9.8 ms, YOLOX-m has a parameter size of 25.3 m with an average speed of 12.3 ms, YOLOX-l has a parameter size of 54.2 m with an average speed of 14.5 ms, and YOLOX-x has a parameter size of 99.1 m with an average speed of 17.3 ms. We evaluated the performance of these models on the BDD100K dataset after training for 10 epochs. All initial models utilized corresponding pre-trained models provided by YOLOX, and the results are presented in Fig. 4. After 10 epochs, the smallest YOLOX-s achieved an accuracy of 45.99% map_50 on the BDD100K dataset, whereas the largest YOLOX-x model achieved an accuracy of 58.03% map_50, with a map_5095 of 35%. The performance of the YOLOX-x model significantly outperformed the other three models. We also observed that YOLOX’s sensitivity to different parameters in the BDD100K dataset. As the model parameters increased, from YOLOX-s to YOLOX-l, mAP_50 increased by approximately 5%, and mAP_5095 increased by about 2%. However, the increase in performance decreased significantly from YOLOX-l to YOLOX-m, with only a 2% improvement in mAP_50 and a 0.5% increase in mAP_5095. After balancing between training speed and accuracy, we selected YOLOX-s and YOLOX-x for further experiments on the BDD100K dataset to obtain the detector.
Hyperparameter test BDD100K for 10 epochs.
YOLOX-s & YOLOX-x BDD100K for 100 epochs.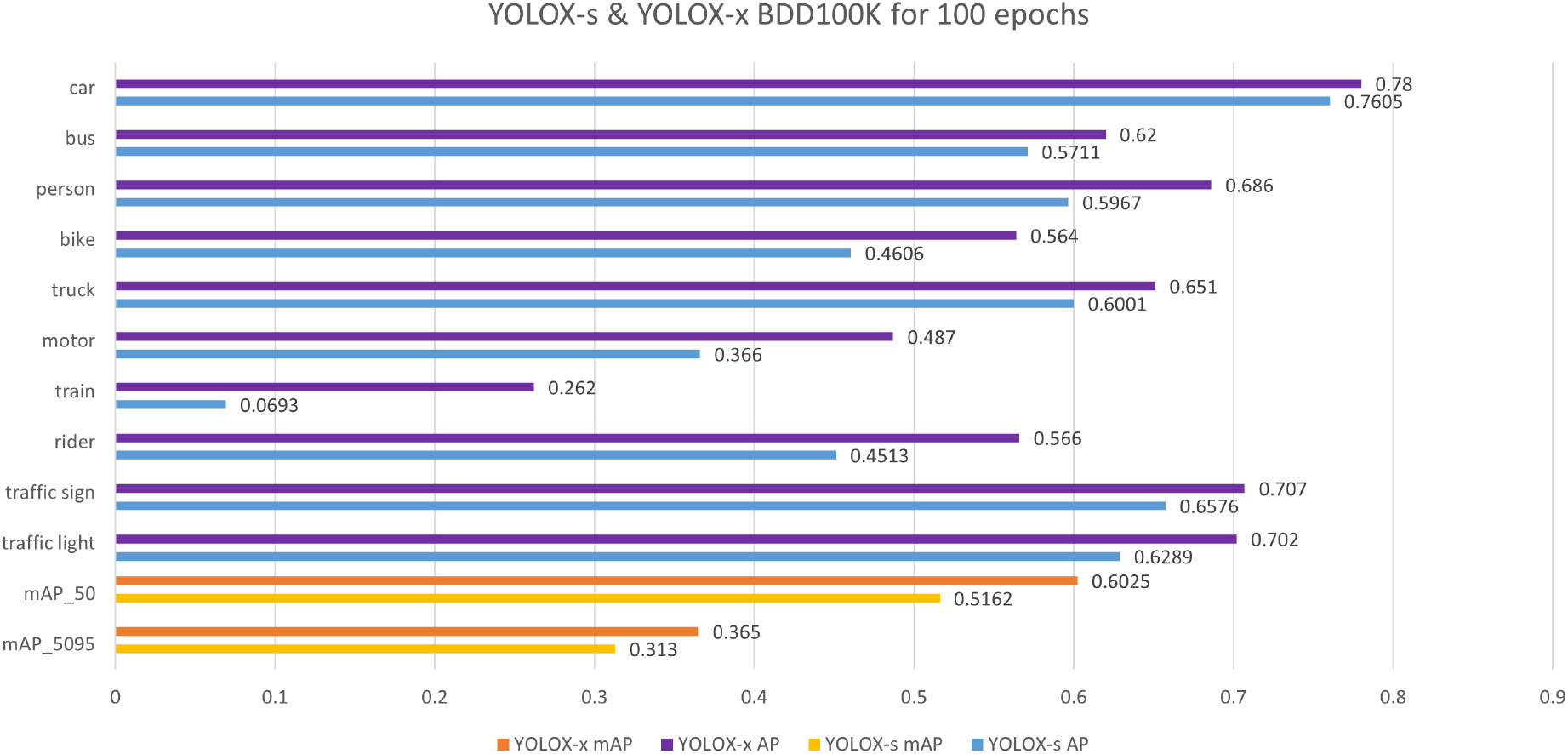
We trained two YOLOX models, YOLOX-s and YOLOX-x, with different parameter sizes on the BDD100K dataset. The performance after 100 epochs is shown in Fig. 5 for both models (neither model exhibited overfitting). YOLOX-x has an average inference time of 16.34 ms on the BDD100K dataset, which is 4 times longer than YOLOX-s under the same conditions, resulting in a substantial increase in accuracy. In the figure, it can be observed that the AP values and mAP values for each category of YOLOX-x far exceed the corresponding values for YOLOX-s. After training, YOLOX-x has AP values exceeding 70% for three categories, while YOLOX-s only achieves this for the “car” category. Additionally, YOLOX-x has AP values over 60% for six categories after training, compared to only four categories achieving such high AP values for YOLOX-s. The outstanding performance of YOLOX-x is further demonstrated by its mAP_50 value of 60.25%, approximately 9 percentage points higher than YOLOX-s with an mAP value of 51.62%. However, the difference in their mAP_5095 values is small, mainly due to lower accuracy as confidence increases.
mAP comparison with recent works on the BDD100K dataset
We also compared the performance of YOLOX on the BDD100K dataset with recent works on the same dataset. The results are shown in Table 1. Vicent Ortiz Castello et al. [18] applied YOLOv3 to train the BDD100K dataset and the mAP reaches 45.15%. Youngjun Kim et al. [26] proposed an Adversarial Defence Module and Adversarial Training for traffic environment detection and the mAP of the model trained with BDD100K was 39%. Zhengquan Piao et al. [27] proposed an algorithm called AccLoc obtained 51.5% mAP on the BDD100K dataset. Moreover, they applied MMDetection to test the performance of other major traffic detection algorithms with default settings on the BDD100K dataset, and obtained an mAP of 39.3% and 47.3% with Faster R-CNN and YOLOv3, respectively [27]. Sepehr Sabeti et al. [28] proposed an Integrative Design framework that combines the latest advances in artificial intelligence and augmented reality and achieved an mAP of 48.7% on the BDD100K dataset. Feng Yang et al. [29] improved YOLOv4 and gained 48.01% on the BDD100K dataset. YOLOX-s has already outperformed recent works on the BDD100K dataset, and the accuracy of YOLOX-x significantly surpasses that of YOLOX-s. This indicates that YOLOX is a state-of-the-art object detection algorithm and can be applicable for detecting and annotating the CCTSDB dataset.
Detect the CCTSDB dataset using transform learning.
The accuracy of YOLOX-x on the BDD100K dataset proves its competence for annotation tasks. However, the model’s AP values for the three categories did not exceed 50%, which might not be convincing for the automatically annotated instances in these classes. This is primarily due to the extremely limited number of training examples for these categories, attributed to the small size of the objects they represent, a common challenge in object detection. Our method aims to reduce the workload of manual annotation through automatic labeling. Therefore, our main focus was to demonstrate the model’s performance in detecting large and significant objects. We used the YOLOX-x model trained on the BDD100K dataset for transfer learning on YOLOX to detect the CCTSDB dataset to validate our approach, as shown in Fig. 6. Through this experiment, we believe that the model trained on the BDD100K dataset using YOLOX-x can accurately detect the large and significant targets in the CCTSDB dataset, such as people, cars, and traffic lights, which are also benchmarks present in the BDD100K dataset.
Therefore, following the method described in section 3.3, we used the YOLOX-x model trained on the BDD100K dataset for 100 epochs to perform transfer learning on YOLOX and detect the entire CCTSDB dataset. We wrote the results of the automatic detection into the annotation files corresponding to each image in the CCTSDB dataset to enhance it. It is worth noting that when adding new annotations, we excluded bounding box data with the label “traffic sign”. This decision was made because the CCTSDB dataset already contains benchmarks for three types of Chinese traffic signs, which conflicted with the “traffic sign” label. Furthermore, images in the CCTSDB dataset were captured by devices such as car dash cameras and traffic surveillance cameras in China. After manual inspection, we confirmed the presence of 9 targets from the BDD100K dataset, excluding “train”, in the images of the CCTSDB dataset. However, due to the low AP value of the “train” category, which was only 26.2%, we chose not to include the detected bounding box data for trains in the annotation files of the enhanced CCTSDB dataset. Therefore, the enhanced CCTSDB dataset retains its original three benchmarks and adds annotations for eight categories present in the BDD100K dataset, totaling 11 classes. We named this dataset the ACCTSDB dataset.
YOLOX-x ACCTSDB for 100 epochs.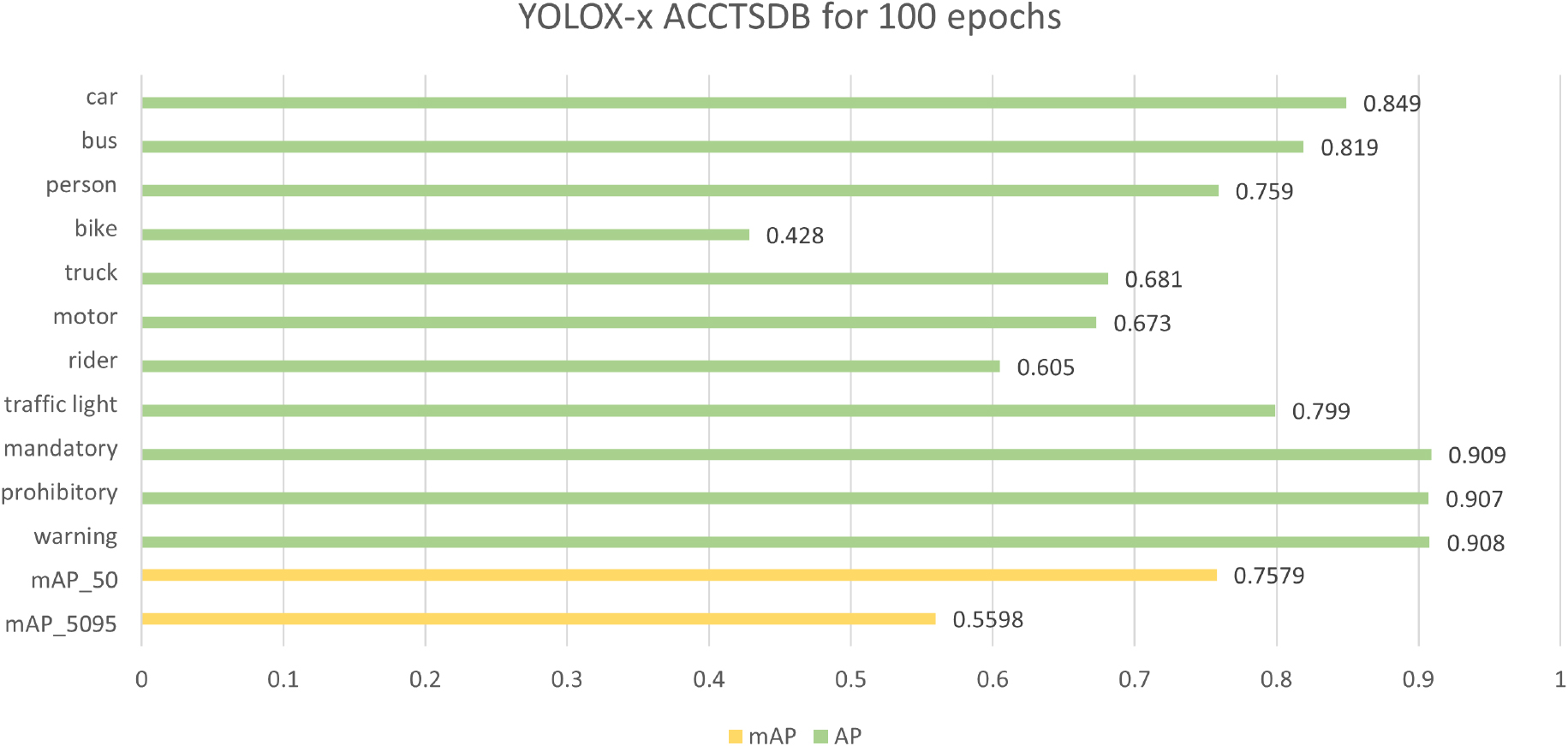
Prediction results of the ACCTSDB dataset.
After constructing the ACCTSDB dataset, we trained it using YOLOX-x for 100 epochs to assess its performance. The cross-validation scores of the trained model on the ACCTSDB dataset are illustrated in Fig. 7. It is evident that the AP values for all categories in this model, except for “bike,” exceed 60%. Notably, the AP values for all three Chinese traffic sign categories, which are “warning”, “prohibitory”, and “mandatory”, are above 90%, demonstrating that the detector trained on the ACCTSDB dataset can accurately detect and classify Chinese traffic signs in Chinese road conditions. Additionally, the model achieves AP values close to or above 80% in four categories, with an impressive mAP_50 of 75.79%. Even the mAP_5095 value surpasses 50%. This implies that the detector trained on the ACCTSDB dataset can accurately identify common traffic targets such as cars, persons, traffic lights, buses, and motors, in addition to the three Chinese traffic signs. This capability goes beyond what detectors trained solely on the BDD100K dataset or the CCTSDB datasets can achieve. Unfortunately, the AP value for the “bike” category is only 42.8%, indicating that the trained detector may struggle to accurately identify bicycles.
The output bounding box results for the ACCTSDB dataset images detected by this model are shown in Fig. 8. These results indicate that the detector trained on the ACCTSDB dataset can successfully identify most traffic objects, addressing many challenges faced by Chinese domestic traffic datasets. However, there are still some limitations in both the dataset and the detector. Certain Chinese traffic signs are not consistently recognized, and small targets within this traffic dataset are sometimes misidentified. Additionally, there are instances where the detector confuses a building for a vehicle. The distribution of labels in the ACCTSDB dataset is illustrated in Fig. 9. This dataset offers a comprehensive blend of the BDD100K dataset and the CCTSDB dataset, incorporating additional labels for 132361 cars, 18932 persons, 7786 trucks, 5113 riders, 10319 traffic lights, 1817 bikes, 8076 buses, and 4754 motors, in addition to the traffic signs. The detector developed from this dataset can accurately detect common traffic targets and Chinese traffic signs. The ACCTSDB dataset encompasses 11 categories, including car, bus, person, bike, truck, motor, rider, traffic light, mandatory, prohibitory, and warning.
Comparison among the number of instances in the ACCTSDB dataset and other traffic datasets
ACCTSDB label count.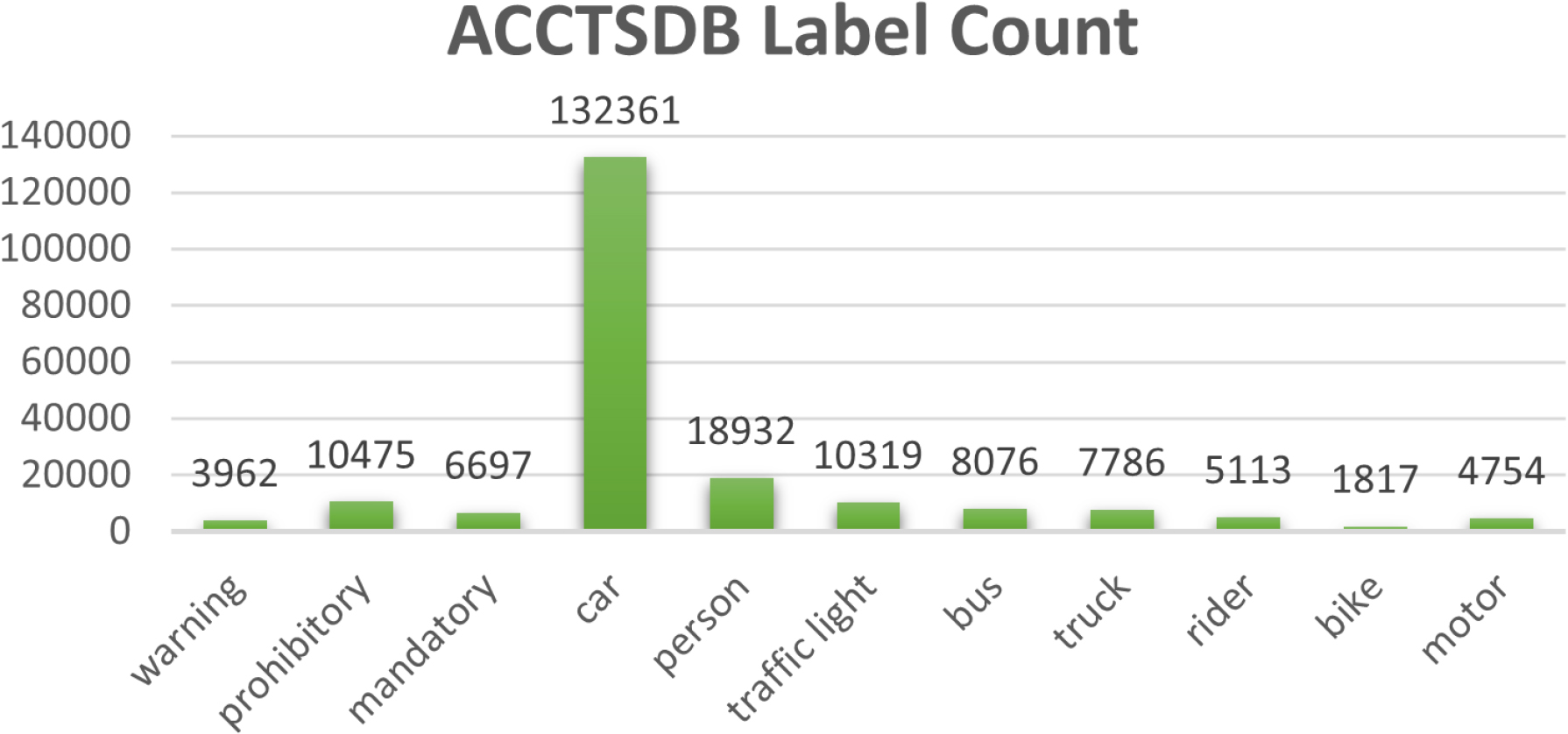
We also compared the ACCTSDB dataset with commonly used datasets in other traffic object detection works. The COCO dataset [22] is one of the most popular evaluation datasets, but it includes 80 different categories, making it challenging to directly compare with the ACCTSDB dataset. We compared ACCTSDB with the BDD100K dataset and another well-known traffic dataset, KITTI [30] for 2D object detection. In the KITTI dataset, We combined the labels “car” and “van” into a single category labeled as “car”, and similarly, the labels “pedestrian” and “person sitting” were combined into a category labeled as “person”. Table 2 shows the comparison among the number of instances in the ACCTSDB dataset and these two traffic datasets, it can be observed that the KITTI dataset has fewer categories and instances, while the BDD100K dataset provides a rich benchmark. The ACCTSDB dataset, with annotations surpassing those of the KITTI dataset and incorporating benchmarks of Chinese traffic signs, further demonstrates the success of our method. Despite certain annotations not being considered benchmarks, our method has enabled the automatic annotation of a high-performance dataset.
TT100K label count.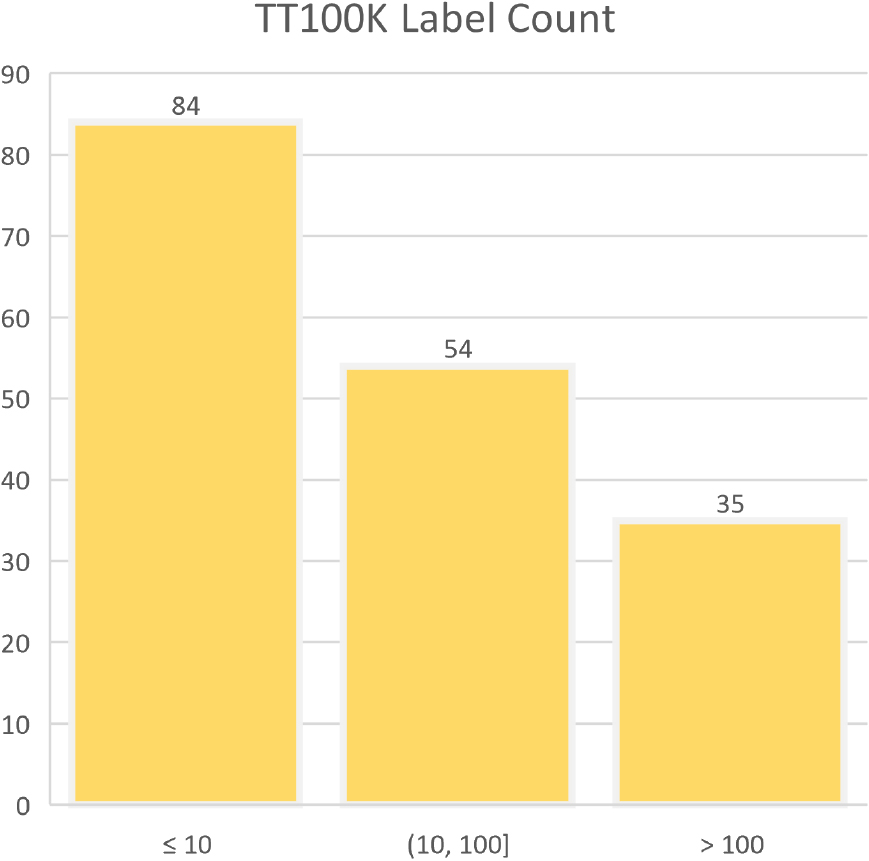
ATT100K label count.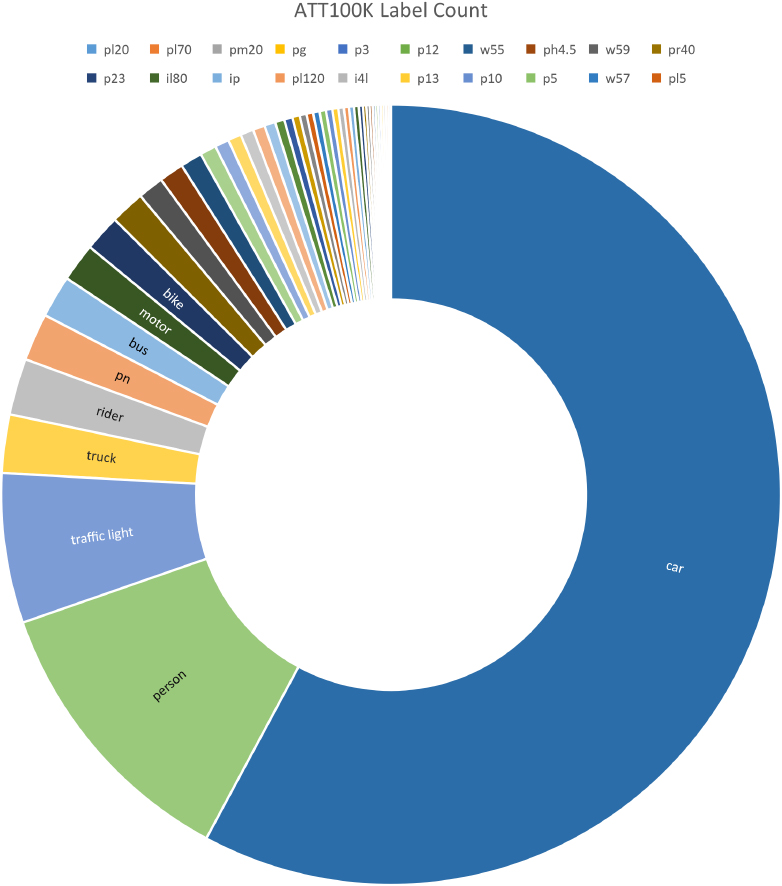
The TT100K dataset is a publicly available dataset based on real-world Chinese traffic signs, jointly released by Tsinghua University and Tencent Labs. It comprises a total of 9176 images containing traffic signs, with 6107 images used for training. The dataset classifies each traffic sign individually. Through statistical analysis, the dataset contains 173 different categories, exhibiting a significant imbalance in the number of instances for each category. Figure 10 illustrates the histogram of instance counts, where 84 categories have instances in single digits, while only 35 categories have more than 100 instances. We successfully replicated our method on the TT100K dataset and enhanced it by combining pre-trained models from the BDD100K dataset with YOLOX, resulting in the ATT100K dataset with 181 categories. Due to the large number of categories and the scarcity of instances for most labels, it can significantly degrade the model’s performance. Therefore, when training the ATT100K dataset using YOLOX-x, we only selected categories with more than 100 instances, 43 in total, as shown in the label counts in Fig. 11.
After training the ATT100K dataset for 50 epochs using YOLOX-x, the model’s performance is illustrated in Fig. 12. Only one category, “pl20”, did not achieve an AP value exceeding 50%. The model achieved a mAP_50 of 80.93% and a mAP_5095 of 60.45%. This demonstrates the successful replication of our method on the TT100K dataset. The detector trained using YOLOX on the new ATT100K dataset exhibited outstanding performance. To further validate the detector’s predictive capabilities on images, we randomly selected several images for experimentation. The experimental results, as shown in Fig. 13, indicate that the trained detector accurately classifies various Chinese traffic signs and annotates vehicles and pedestrians. However, some traffic signs were not recognized because we only selected 43 categories with more than 100 instances for training. Consequently, certain traffic signs were not included in the training data, leading to the model’s inability to classify all Chinese traffic signs. In summary, this experiment confirms the effectiveness and versatility of our approach.
YOLOX-x ATT100K for 50 epochs.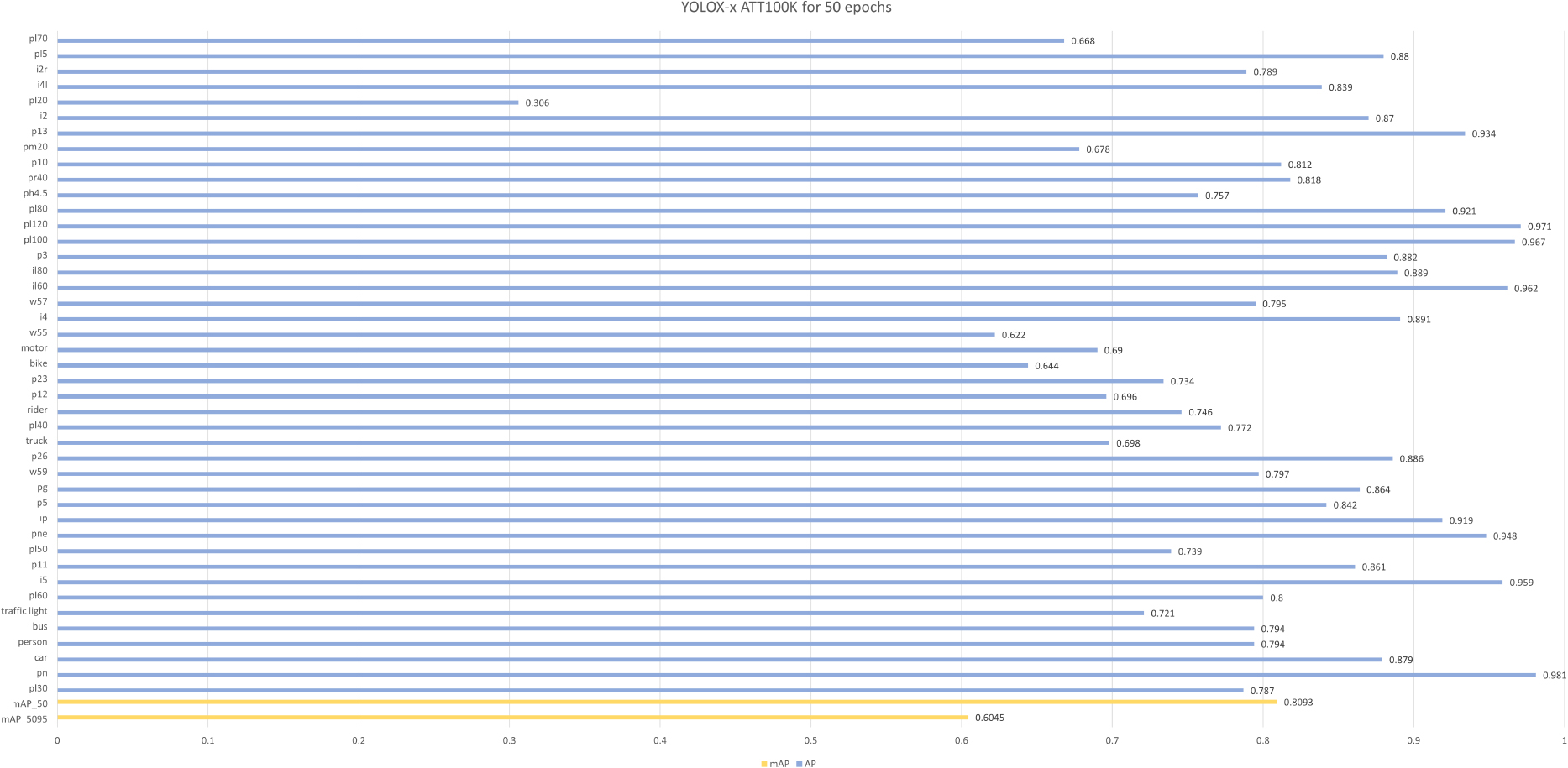
Prediction results of the ATT100K dataset.
This paper introduces a cross-augmentation method for image datasets. The feasibility of this method was validated using the YOLOX algorithm, the BDD100K dataset, and the CCTSDB dataset. We trained the YOLOX-x model on the BDD100K dataset and achieved an mAP of 60%, surpassing the accuracy of other algorithms in past works. Subsequently, we employed the trained model for transfer learning to make YOLOX detect and enhance the CCTSDB dataset. Detection results excluding the “traffic sign” and “train” annotations were integrated into the annotations of the CCTSDB dataset, forming the ACCTSDB dataset, which incorporates annotations for 8 categories of general traffic targets and benchmarks of 3 types of Chinese traffic signs. The ACCTSDB dataset was then trained with YOLOX-x, producing a detector capable of recognizing 8 types of traffic objects and 3 classifications of Chinese traffic signs. This detector reached an mAP of 75%, demonstrating excellent performance in image tests, which validates the usability of the new dataset. We tested the effectiveness and versatility of our approach on the TT100K dataset and introduced the ATT100K dataset with 181 categories. Our work demonstrates that this method can utilize object detection algorithms to learn benchmarks from one dataset and enhance another dataset, reducing the challenges of manual annotation. The proposed ACCTSDB dataset and ATT100K dataset are expected to compensate for the limitations of various classifications lacking in publicly available Chinese traffic datasets.
There is still room for future improvements in our method. Firstly, the issue of instance imbalance in categories is a common problem in almost every traffic dataset, including the BDD100K dataset. It affects the performance of the trained model in detecting classes with low instances, a concern that researchers will need to address in the future. Secondly, to enhance datasets using YOLOX, we modified the output section of YOLOX and proved the method’s generalization on similar datasets. When using other algorithms, similar modifications to the output function of the algorithm need to be made following our approach. Thirdly, our method achieved good results in annotating large and significant objects in the enhanced dataset. However, recognizing small objects is a widespread problem in the field of object detection. Future research in this regard is needed to reduce the workload of manual annotation. To further enhance our work, we recommend focusing on utilizing advanced target detection algorithms, such as Swin Transformer v2 [31], to augment the latest version of CCTSDB 2021 [32]. This approach will provide the ACCTSDB dataset with more precise annotations.
Footnotes
Acknowledgments
This work was partially supported by the Suzhou Municipal Key Laboratory for Intelligent Virtual Engineering (SZS2022004), the Xi’an Jiaotong-Liverpool University (XJTLU) Key Programme Special Fund (KSF-A-19), the XJTLU Research Development Fund (RDF-19-02-23), the XJTLU AI University Research Centre, Jiangsu Province Engineering Research Centre of Data Science and Cognitive Computation at XJTLU and SIP AI Innovation Platform (YZCXPT2022103).