
Abstract
Code search, which locates code snippets in large code repositories based on natural language queries entered by developers, has become increasingly popular in the software development process. It has the potential to improve the efficiency of software developers. Recent studies have demonstrated the effectiveness of using deep learning techniques to represent queries and codes accurately for code search. In specific, pre-trained models of programming languages have recently achieved significant progress in code searching. However, we argue that aligning programming and natural languages are crucial as there are two different modalities. Existing pre-train models based approaches for code search do not effectively consider implicit alignments of representations across modalities (inter-modal representation). Moreover, the existing methods do not take into account the consistency constraint of intra-modal representations, making the model ineffective. As a result, we propose a novel code search method that optimizes both intra-modal and inter-modal representation learning. The alignment of the representation between the two modalities is achieved by introducing contrastive learning. Furthermore, the consistency of intra-modal feature representation is constrained by KL-divergence. Our experimental results confirm the model’s effectiveness on seven different test datasets. This paper proposes a code search method that significantly improves existing methods. Our source code is publicly available on GitHub.1
Introduction
Code search aims to search and reuse the code available on large-scale code repositories based on some specific needs in the form of a query. Existing code search tools can support different types of queries, such as natural language-based queries used by GitHub search and structured code-based queries. Figure 1 illustrates an example of natural language-based query “Downloads Sina videos by URL”, which is usually a short description of the developers’ requirements. A code snippet as shown in Fig. 1 meets the developers’ requirements. In this paper, we focus on code search based on a natural language-based queries. Obviously, precise and automatic code search has the potential to improve the efficiency of software development.
Approaches for code search can be roughly classified into information retrieval-based, deep learning-based, as well as pre-trained model-based. Given a search query, early research on code search [1, 2, 3] focused on the lexical information of code snippets and employed information retrieval methods to find relevant code snippets. With the development of deep learning approaches, approaches for code search embedded both code snippets and queries into a shared high-dimensional vector space and compare their semantic similarity using neural networks [4, 5, 6, 7, 8, 9]. Recently, pre-trained models have been widely employed since they can learn semantic representations of code fragments and search queries and capture their semantic relevance efficiently. For example, pre-trained models trained on large-scale multi-programming language datasets have improved the understanding of code semantics and the performance of code search engines is improved [10, 11, 12, 13].
In spite of some success of the pre-trained models for code search, these approaches solely rely on the representations learned from large-scale pre-trained models and return a list of codes based on the cosine similarity between the natural language to the programming language. The alignment between query and code representations is not fully explored in the fine-tuning phase. As a result, search results are subject to bias. As shown in Fig. 1, Query
Examples of code search.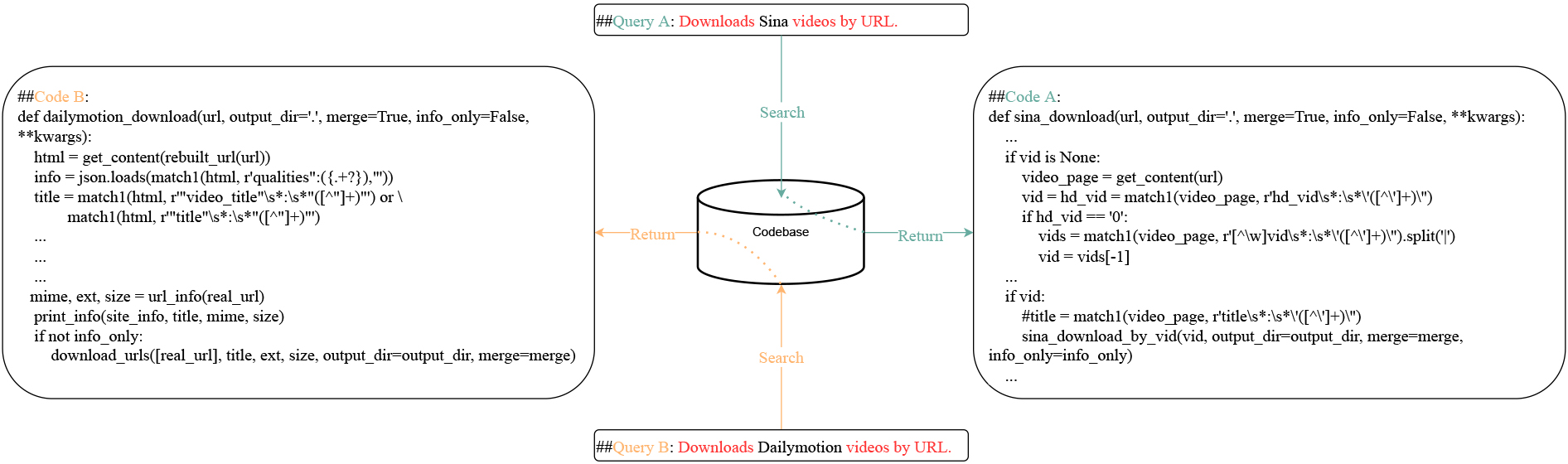
To tackle the challenges mentioned above, firstly, to capture the differences between Query
The main contributions are summarized as follows:
We propose a novel framework for intra- and inter-modal representation learning (I2R). In this framework, contrastive learning is used to optimize the information contained in inter-modal representations, while R-drop technique is used to improve the consistency of intra-modal representations. Extensive experiments are conducted on seven benchmark datasets and experimental results show that the proposed I2R framework outperforms several state-of-the-art approaches for code search. Moreover, experimental results show that other pre-trained models can be easily adapted to the proposed framework and some improvements are achieved.
Over the years, code search has evolved from using basic Information Retrieval (IR) techniques to more advanced deep learning models. However, these models still face challenges in capturing the semantics of code and queries. To overcome these limitations, researchers have proposed co-attentive representation learning models that focus on learning interdependent representations of embedded codes and queries. Additionally, context-aware code translation techniques have been developed to translate code fragments into natural language descriptions, enabling more effective code search. Furthermore, large-scale code pre-training models have shown promising results in improving code search tasks. On the other hand, in the field of natural language processing, pre-training methods have revolutionized the acquisition of image representations from text through transformer-based models. Similar advancements have been made in programming language pre-training models, enhancing the understanding of code semantics and improving code search tasks. Contrastive learning techniques, which bring similar representations closer together and push apart different ones, have been successfully applied to various domains, including images and natural language text. In the multimodal context, aligning and unifying visual and textual representations has been a significant challenge. However, recent approaches have aimed to overcome this challenge by leveraging large-scale image-text pairs and cross-modal contrastive learning methods. The ability of contrastive learning to align and differentiate representations makes it a suitable approach for solving code search problems. We describe code search, multi-modal pre-trained models, and contrastive learning in the following.
Code search
Early code search models used Information Retrieval (IR) techniques in order to index a large corpus of code and return relevant code depending on a developer’s search query. Unfortunately, IR-based models cannot capture the semantics of code and queries. Deep learning techniques have been applied to code search models to address this problem. A deep learning-based model (i.e., DeepCS) was proposed by Gu et al. and demonstrated significant improvements compared to previous models [24]. DeepCS embeds codes and natural language queries into vectors with two LSTMs (Long Short Term Memory) and returns to the developer that the code is more similar to the code search query. However, it should be noted that the embedding approach does not take into account the internal semantic relevance of the two isolated representations of the code query. Consequently, learning isolated representations of the code and query may limit the search’s effectiveness. In order to address these issues, a co-attentive representation learning model (CARLCS-CNN) has been proposed [5]. A co-attentive mechanism is employed by the CARLCS-CNN to learn interdependent representations of embedded codes and queries. The TabCS performs a two-stage attentional network structure to extract code and query information from code features (e.g., method names, API sequences, and tokens), code structure features (e.g., abstract syntax trees), and query features (e.g., tokens) [7]. Taking into consideration the semantic gaps in code and queries, the first phase uses attention mechanisms to extract semantics. To determine the semantic relevance of each code/query, the second phase applies the co-attention mechanism. TranCS [9], a revolutionary context-aware code translation technique, is proposed to translate code fragments into natural language descriptions (known as translations) using extensive experiments on a large, multilingual dataset. Next, the similarity calculation between the natural language and the translated natural language based on the code fragment is implemented to achieve code search. Simulating the execution of machine instructions allows code translation to be performed on machine instructions. Contextual information is gathered by simulating the execution of the instructions. It further includes a shared word mapping function that generates embeddings for translations and queries based on a vocabulary. In recent years, large-scale code pre-training models have acquired generic source code representations and have demonstrated substantial improvements in code search tasks [10, 12].
Multi-modal pre-trained models
The field of natural language processing has undergone a revolution as pre-training methods that learn directly from the unsupervised raw text have been introduced. During the past few years, Transformer-based models have become increasingly popular for cross-modal representation learning [25, 10, 26, 18]. In recent studies, CLIP [19] and VirTex [25] have used new architectures and pre-training methods to demonstrate transformer-based language modeling, masked language modeling, and contrastive learning for the acquisition of image representations from the text. Similarly, large-scale programming language pre-training models [10, 27, 11, 12, 13] improved understanding of code semantics and resulted in significant improvements in code search tasks. UniXcoder [12], CodeBERT [10], and GraphCodeBERT [11] are all based on the RoBERTa [28] architecture. In terms of code representation, CodeBERT utilizes lexical information to mimic as much as possible the natural semantics of the identifier through WordPiece’s subsumption. Syntactic information is not explicitly modeled, and the model needs to learn syntactic information from a large amount of code. As input, GraphCodeBERT takes source code with a digest and a corresponding data stream and pre-trains it with a Mask Language Model (MLM), edge prediction tasks, and node alignment routines. In UniXcoder, the syntactic information is explicitly modeled, while the abstract syntax tree (AST) of code is recovered and spread into sequences. Additionally, a unified model for generating and understanding codes is proposed. It is easy to apply our approach to these pre-trained models for downstream tasks and improve their performance.
Contrastive learning
Contrastive learning [29], which brings similar representations closer together and pushes apart different ones, has been successfully used for self-supervised representation learning for images [25, 18] and natural language text [21, 23]. Recently, several studies [30, 12] have also applied contrastive learning to learn cross-modal representations of video/images and text. To accommodate multimodal scenarios, a series of multimodal pre-training methods have been proposed and pre-trained on a corpus of image-text pairs, such as VisualBERT [26], and UNITER [17], which greatly improve the ability to handle multimodal information. The biggest challenge in unifying different modalities is to align and unify them into the same semantic space, which can be generalized to different data modalities. Several existing cross-modal pre-training approaches attempt to align visual and textual representations by simple image-text matching based on a limited corpus of image-text pairs [26, 17]. As the randomly sampled negative text or images are usually very different from the original text or images, they can only learn a very rough alignment between text and visual representations. CLIP [19] uses large-scale image-text pairs to learn transferable visual representations through image-text matching, which allows the model to be transferred to various visual classification tasks with zero samples. WenLan [31] further was proposed, which has a similar two-tower Chinese multimodal pre-training model to improve the contrastive cross-modal learning process. The end-to-end visual language pre-training architecture SOHO [32] does not extract significant image regions by pre-training object detection models jointly learning Convolutional Neural Networks (CNN) and Transformer to perform cross-modal alignment from millions of image-text pairs. UNIMO [18] leverages large-scale free text corpora and image collections to improve visual and text comprehension and uses cross-modal contrastive learning (CMCL) to align text and visual information into a unified semantic space, adding relevant images and text to the corpus of image text pairs. Contrastive learning methods [29], which bring together representations of positive samples and push apart negative samples, are well suited to solve code search problems that expect pairs of code fragments and queries to have tight representations and unpaired code fragments and queries to have different representations.
The proposed approach
Figure 2 shows the architecture of I2R. In general, I2R employs UniXcoder as the encoding model which encodes code and query separately to obtain semantic representations. UniXcoder is a multilayer bi-directional transformer encoder-decoder that can perform both code generation and code understanding operations. Inter- and intra-modal representations are captured by comparative learning and KL-divergence. Our approach consists of a siamese network model where code is encoded by two UniXcoders, while another two UniXcoders encode queries. A pair of UniXcoder models are incorporated to explicitly constrain the consistency of the code and query representations by implementing KL-divergence. Additionally, we introduce contrastive learning in which negative samples are used to model the semantic mapping between code and query. Finally, we use the trained model to perform code search. In the following sections, we will describe in detail how each module was designed.
Intra- and inter-modal representation learning approach.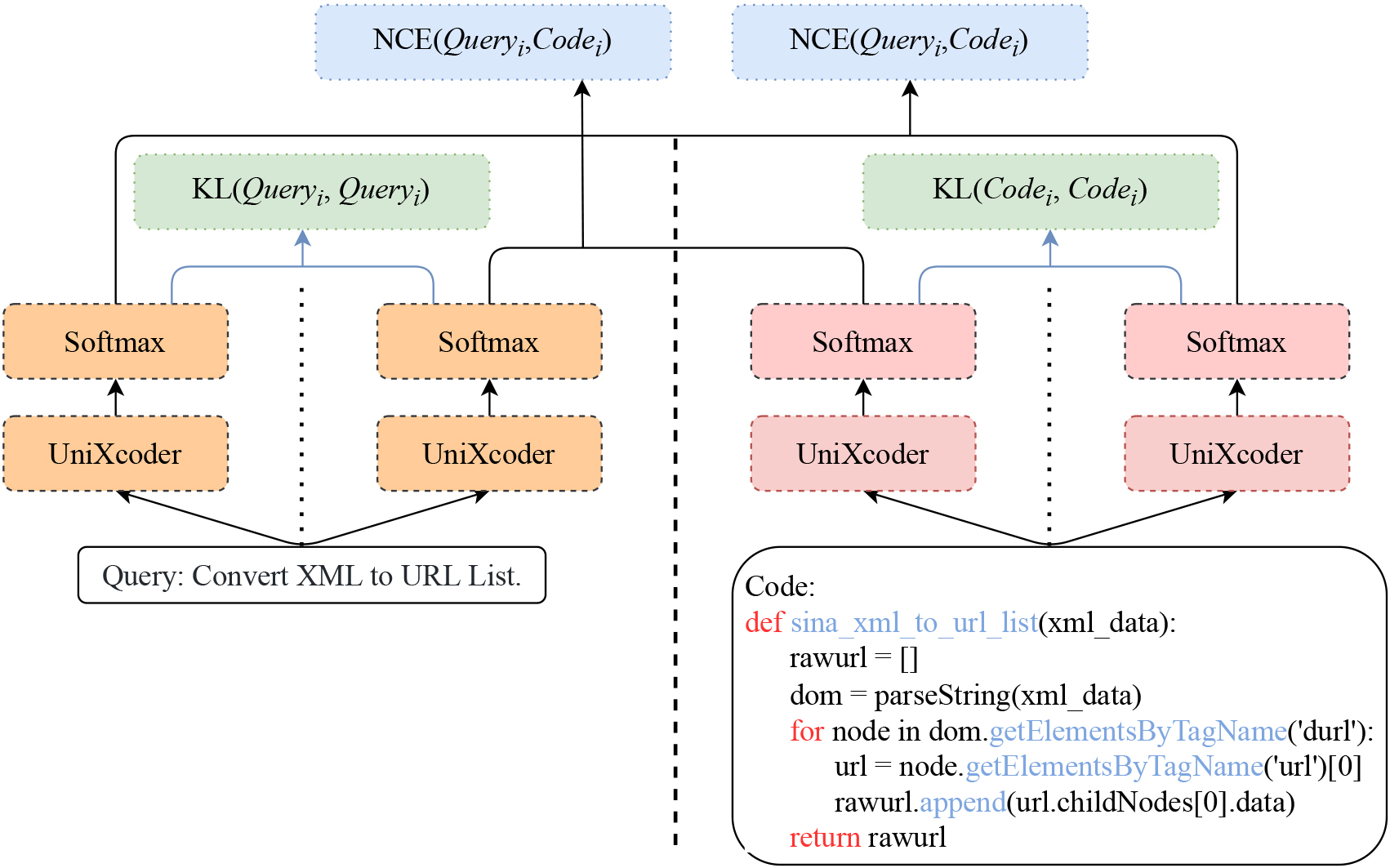
Given the training dataset
Inter-modal representation learning
Inter-modal representation learning.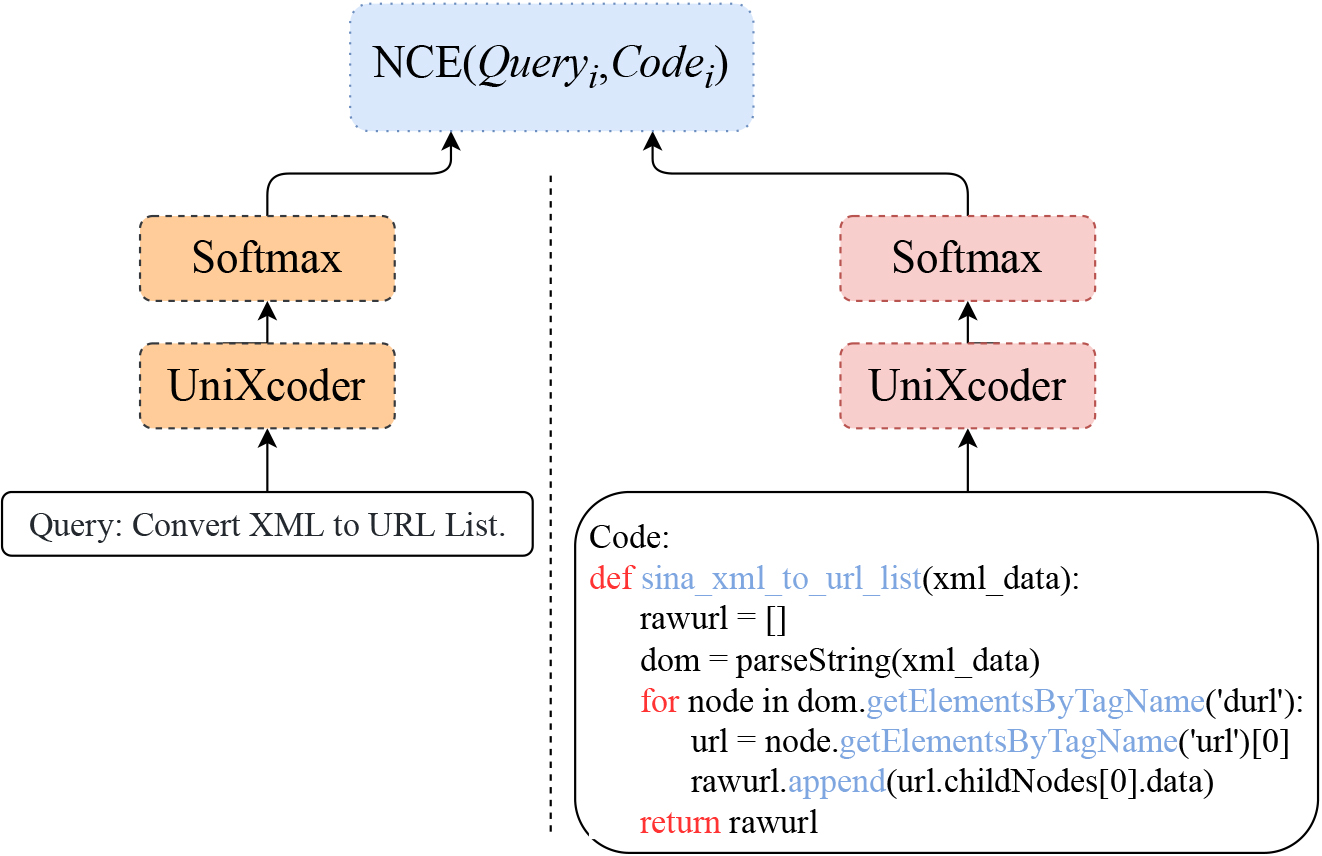
As shown in Fig. 3, with the encoding of UniXcoder, we obtain a representation of query
We introduce positive and negative samples guided by queryi into the comparison loss, as shown in Eq. (1). Moreover, we similarly introduce codei-guided positive and negative samples into the contrastive loss, as shown in Eq. (2), to achieve a bidirectional alignment of query-code representations.
Since in Section 3.3 we use KL-divergence to achieve consistency constraints on the intra-modal representation, we need to implement the above operation twice, as shown in Fig. 2. In turn,
Learning inter-modal representations requires a stable representation of the intra-modal representation as the first step.
Wu et al. found that if a training sample has two different input formats, the performance of the model produced by the various inputs is required to improve significantly if the high-level representations are consistent across the inputs [14]. Furthermore, Bengio et al. proposed a technique known as “Fraternal Dropout” where they first trained two identical RNNs (with shared parameters) with different dropout masks and minimized the difference in their (pre-softmax) predictions [15]. With the development of pre-trained models, large-scale pre-trained representations enabled significant development of natural language processing tasks. Wu et al. used the pre-trained model fine-tuning process to make the prediction distribution of any two randomly sampled sub-models consistent via KL divergence [16]. Also, they theoretically demonstrate that consistency between submodels ensures consistency between the submodels and the whole model.
In this study, we seek to apply the R-drop technique to the learning of natural and programming language representations across modalities and to maintain the stability of both representations within each mode. We draw on Wu et al.’s work to apply the R-drop technique to the learning process [16]. The specific implementation details are described below.
Intra-modal representation learning.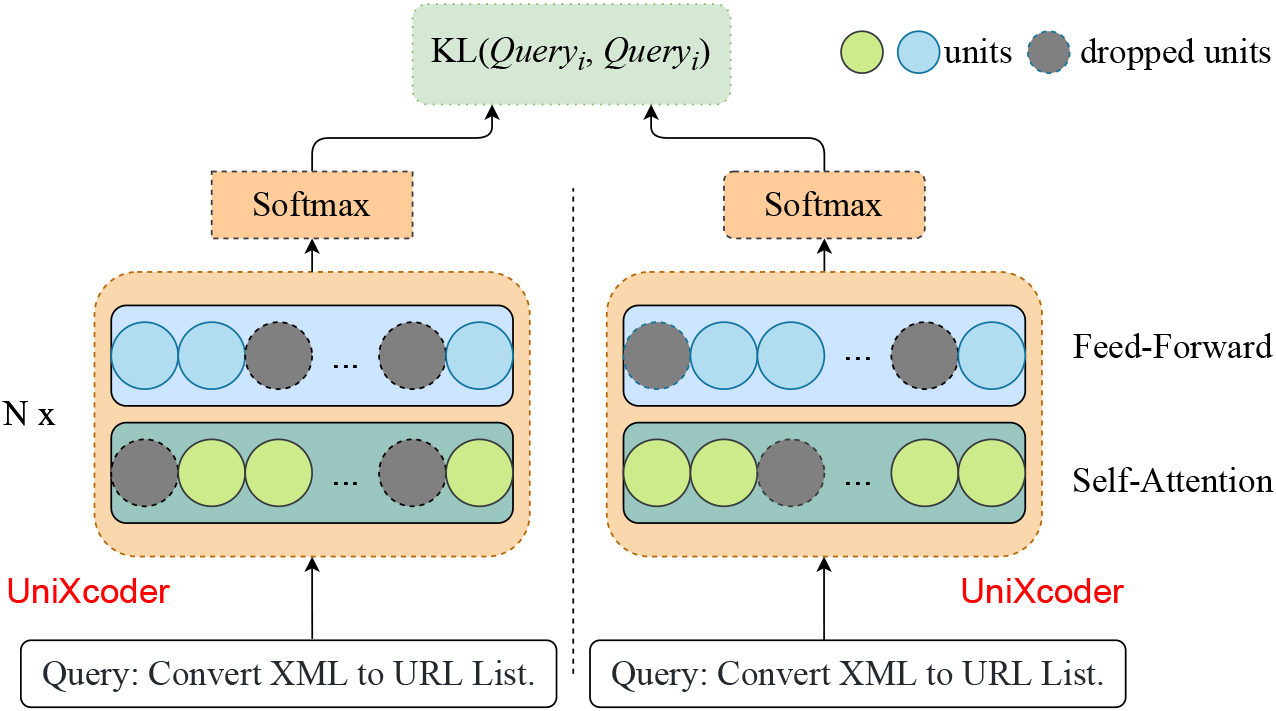
As shown in Fig. 4, we have obtained two semantic representations of the query after encoding the query twice using UniXcoder. We will then implement intra-modal representation learning, utilizing KL-divergence to maintain intra-modal consistency in our intra-modal representation learning technique.
Similarly, we do the same for code, as shown in Eq. (7).
In the overall I2R, the optimization objective for intra-modal representation learning is shown in Eq. (8).
With Sections 3.2 and 3.3, we obtain optimisation objectives
I2R Training AlgorithmTraining data
The overall training algorithm based on our I2R is given in Algorithm 1. In each training step, line 3 shows that we advance the model once and obtain the output distribution
An evaluation of the performance of I2R was conducted using a code search task where the impact of inter-modal and intra-modal representations on performance was investigated. We extend the I2R approach to other pre-trained models, such as the GraphCodeBERT model. Finally, we explore the impact of the Dropout rate on the performance of I2R. We conclude that I2R is an effective tool for evaluating opinions based on our responses to the following research questions.
To validate the effectiveness of the I2R in the code search task, we use six datasets from CSN, as well as the Advtest dataset, to validate it compared to the current state-of-the-art models.
It is the purpose of this study to investigate the impact of intra-modal and inter-modal representations on performance in a learning task. As a result, we performed the corresponding ablation experiments by neutering the I2R model and comparing the effects of neutering on performance across a variety of cases.
In addition to UniXcoder, there are also a number of other pre-trained models that have also been successful in achieving acceptable results in code search tasks. During the course of our research, we wondered whether the migration of I2R to other pre-trained models would similarly have the same effect on code search. The model that we replaced with GraphcodeBERT was compared to the baseline model that was developed with UniXcoder, the pre-trained model.
It was observed that the performance of I2R was negatively impacted by different dropout rates, which were assigned to I2R, and verified their impact on the performance of code search using the I2R interface.
It is the main objective of a code search to find the most relevant codes among a collection of candidate codes for a given query in natural language. A series of experiments were conducted on these datasets, namely the CSN [11], which comprises six different programming language datasets, and the AdvTest [33].
The CSN dataset was constructed from a CodeSearchNet dataset in six languages, unlike the dataset and setup used by Husain et al. [34]. A detailed analysis of Guo et al. found that low-quality queries were filtered by hand-made rules, and the 1000 candidates were extended to include all the code in the corpus, which is closer to a real-life scenario. To test the model’s understanding and generalization abilities, Lu et al. normalized the Python function names and variable names in the AdvTest dataset from the Python language of the CSN dataset. The reason for this was better to test the model’s understanding and generalization abilities. We present the statistics on this dataset in Table 1.
Statistical information on the dataset
Statistical information on the dataset
Our work is deployed on a GPU server with two Intel Xeon Gold 6142 (2.7GHz) CPUs, 128GB of RAM, a 1TB solid-state drive for the system, and a 4TB hybrid hard drive for the storage. And there are four Nvidia RTX3090 GPUs with 24G of graphics memory. We set the learning rate as 2e-5, the batch size as 64, the dropout rate of two submodels in intra-modal as 0.1 and 0.4, and the max sequence length of code and query as 256 and 128, respectively. We use the Adam optimizer to fine-tune the model for 10 epochs and perform early stopping on the development set. The temperature hyperparameter
Evaluation metrics
In order to determine the performance of a code search system, MRR (Mean Reciprocal Rank) is calculated by ranking the correct search results in order to obtain the best ranking of the search results.
where
Over the past few years, significant advancements have been made in the field of natural language processing for programming languages. Researchers have developed several pre-training models that aim to improve code understanding and facilitate various code-related tasks. In this section, we will explore some of these state-of-the-art pre-training models and their unique features.
RoBERTa’s pre-training strategy has been modified, including removing the pre-training target for the next sentence prediction in BERT [35], as well as training with larger batches and learning rates. Furthermore, Roberta receives an order of magnitude more training over a more extended period than BERT. Consequently, RoBERTa is able to generalize more effectively to downstream tasks than BERT. According to Liu et al., RoBERTa is trained by treating code as a sequence of tokens, thus producing the code-based model that has been pre-trained [28]. CodeBERT is a pre-trained model that can handle bi-modal data (programming language PL and natural language NL) and can represent generic downstream NL-PL applications (e.g., natural language code search, code document generation, etc.). CodeBERT is a cross-modal pre-training model derived from RoBERTa, developed on the Transformer architecture, and designed to combine a pre-training task involving replacement token detection with a hybrid objective function [10]. With GraphCodeBERT, code representations can be learned based on the semantic structure of the source code by implementing the BERT pre-training model. To achieve a vector representation of the source code based on the data stream, there are two new pre-training tasks proposed (data stream edge prediction, variable alignment of the source code and the data stream) in addition to the traditional MLM task. With GraphCodeBERT, code representations can be learned based on the semantic structure of the source code by implementing the RoBERTa pre-training model [11]. The SynCoBERT pre-training model allows for better representation of code using syntax-guided multimodal contrastive learning [30]. Based on the symbolic and syntactic properties of the source code, two new pre-training targets were developed, namely Identifier Prediction (IP) and AST Edge Prediction (TEP), for anticipating edges between identifiers and AST nodes, respectively. A multimodal contrastive learning strategy is also proposed in order to capitalize on the complementary information in the semantic equivalence modalities of the code (i.e., code, annotation, AST). CodeT5-base [27] is based on the same architecture as Google’s T5 (Text-to-Text Transfer Transformer) framework [36] but with a better understanding of programming language. It proposes to make use of developer-designed identifiers in the code. A new objective function that incorporates code-specific knowledge is proposed. This objective function trains the model to distinguish between tokens that represent identifiers as well as to recover them when they are blocked. Furthermore, annotations in the code are used to allow the model to learn better representations by studying the alignment properties of the code and the text. UniXcoder is a unified cross-pattern pre-training model for programming languages [12]. In the model, a masked attention matrix with prefix adapters is used to control the behavior of the model. Additionally, cross-modal content such as ASTs and code annotations are used to enhance the representation of the code. This thesis proposes a method for encoding ASTs that are represented in parallel as trees that maintains the sequence structure of all the structural information contained within the AST. The model also uses multimodal content to learn the representation of code fragments through comparative learning, followed by a cross-modal generation task to align the representation between programming languages.
In this section, we conducted an evaluation of the performance of the I2R model in the context of code search. We aimed to investigate the impact of intra-modal and inter-modal representations on the code search performance and explore the feasibility of applying I2R to other pre-trained programming language models. Additionally, we examined how different Dropout rate settings affected the performance of I2R. The findings from our research provide insights into the effectiveness of I2R as a tool for evaluating opinions in the code search domain.
Effectiveness in code search (RQ1)
Performance of each method on AdvTest and CSN datasets
Performance of each method on AdvTest and CSN datasets
A comparison among the different methods are shown in Table 2 in terms of their performance in the code search task. As shown in the table, the most popular methods for code search that use pre-trained models are currently the most effective in terms of finding codes.
In general, I2R achieved the best performance among all the methods compared. In Table 2, we can see that I2R is able to outperform the baseline model on all datasets compared to the baseline models, with a particular improvement of more than 1% on the AdvTest, Ruby, and Python datasets, and significant improvements on the Javascript, Java, PHP, and Go datasets.
On the CSN task, it has been shown that the standard I2R model has improved by 0.8% over the current state-of-the-art model UniXcoder. Also, it was found that the I2R model performed 2.5% better on the AdvTest dataset as compared to the UniXcoder model.
It has been shown that I2R can achieve the current state-of-the-art in code search tasks, which is a very effective result in code search tasks.
Our ablation experiments were conducted on the I2R model, as shown in Table 3. The first row of the table shows the base model UniXcoder, where I2R is improved from the UniXcoder model to be as efficient as possible.
As we can see from the second row, it represents the optimization only for intra-modal representation, and it corresponds to Section 3.3. On the basis of the results in the table, it can be concluded that the introduction of KL-divergence for inter-modal representation learning based on the UniXcoder model significantly improves code search on the AdvTest, Ruby, Javascript, Python, Java, and PHP datasets. Moreover, there is an average improvement of 0.6% on the CSN task. As can be seen from the third row, the optimization only refers to the inter-modal representation, which corresponds to Section 3.2. The implementation of contrastive learning to align the inter-modal representation on top of the UniXcoder model significantly improves the performance of the code search model. In the fourth row, we present experimental results for the simultaneous optimization of the intra- and inter-modal representation. Findings indicate that the superimposed effect of optimizing both the intra- and inter-modal representations can further enhance the performance of code searching.
Performance of each ablation method based on UniXcoder
Performance of each ablation method based on UniXcoder
Performance of each ablation method based on GraphCodeBERT
Performance of each ablation method based on GraphCodeBERT
We evaluated the performance of I2R-GraphCodeBERT and compared it to the baseline model GraphCodeBERT, as shown in Table 4. Using the same experimental setup as I2R-UniXcoder, we set the learning rate as 2e-5, the batch size as 64, the dropout rate of two submodels in intra-modal as 0.1 and 0.4, and the max sequence length of code and query as 256 and 128. We use the Adam optimizer to fine-tune the model for 10 epochs and perform early stopping on the development set. The temperature hyperparameter
Besides migrating the I2R method to GraphCodeBERT, we also carried out a series of ablation experiments on I2R-GraphCodeBERT in order to investigate its efficacy. It is important to note that the experimental results are consistent with the ablation scheme described in Section 4.5.2, I2R-UniXcoder. It was demonstrated in the experiments that intra-modal representation learning and inter-modal representation learning are extremely effective in the GraphCodeBERT model, respectively. Due to the fact that the parameters of the I2R-GraphCodeBERT-based model were directly transferred from the I2R-UniXcoder model, the dropout rate was not adjusted, making the integration of the two modalities not significantly beneficial.
Performance of I2R under different dropout rates
Performance of I2R under different dropout rates
As well as the studies that have been mentioned above, we also examine I2R from another perspective, and that is the dropout rate.
There are two distributions between the modalities in the current training, which are based on different dropout rates across the two modalities. It is important to note that one of the distributions is always based on the UniXcoder dropout rates, but the other distribution has a variable dropout rate range of {0, 0.1, 0.2, 0.3, 0.4, 0.5}. In this study, we used the two different dropout rates of the two output distributions during training to observe the difference in the performance of the code search, and the results are shown in Table 5.
Among these various results, we can see that 1) a dropout rate of 0.4 for the other distribution is the most appropriate choice (current setting), and 2) R-Drop consistently achieves better performance when the dropout rate of the other distribution is in a reasonable list {0.3, 0.4}. To make sure that the results are not distorted, a dropout rate of 0.4 was chosen as a compromise in our experiments.
The I2R method, which is shown in Tables 3 and 4, is far more effective than the UniXcoder model when compared to the GraphCodeBERT model. This is evidenced by the improvement that it shows.
UniXcoder is a unified cross-modal pre-training model for programming languages. As part of the model, a prefix adapter with a masked attention matrix is used to control the behavior of the model, as well as cross-modal content like ASTs and code annotations that enhance the code representation. As part of the thesis, a one-to-one mapping method is proposed to encode ASTs represented in parallel as trees, which preserves the sequence structure of all structural information contained within the AST. A multimodal representation of code fragments can also be learned through comparative learning on multimodal content, and then the representation can be aligned between programming languages through a cross-modal generation task.
GraphCodeBERT is based on a pre-trained model to learn code representations based on code semantic structure information (rather than AST information), which is derived via data flow to obtain semantic structure information for the code. Additionally to the MLM pre-training task, two supplementary code-structure-related pre-training tasks have been introduced, and these tasks will help to develop code representations from source code and data flows, which are related to code representations.
Model-specific code-query representations. Where red indicates the representation of code and blue indicates the representation of query.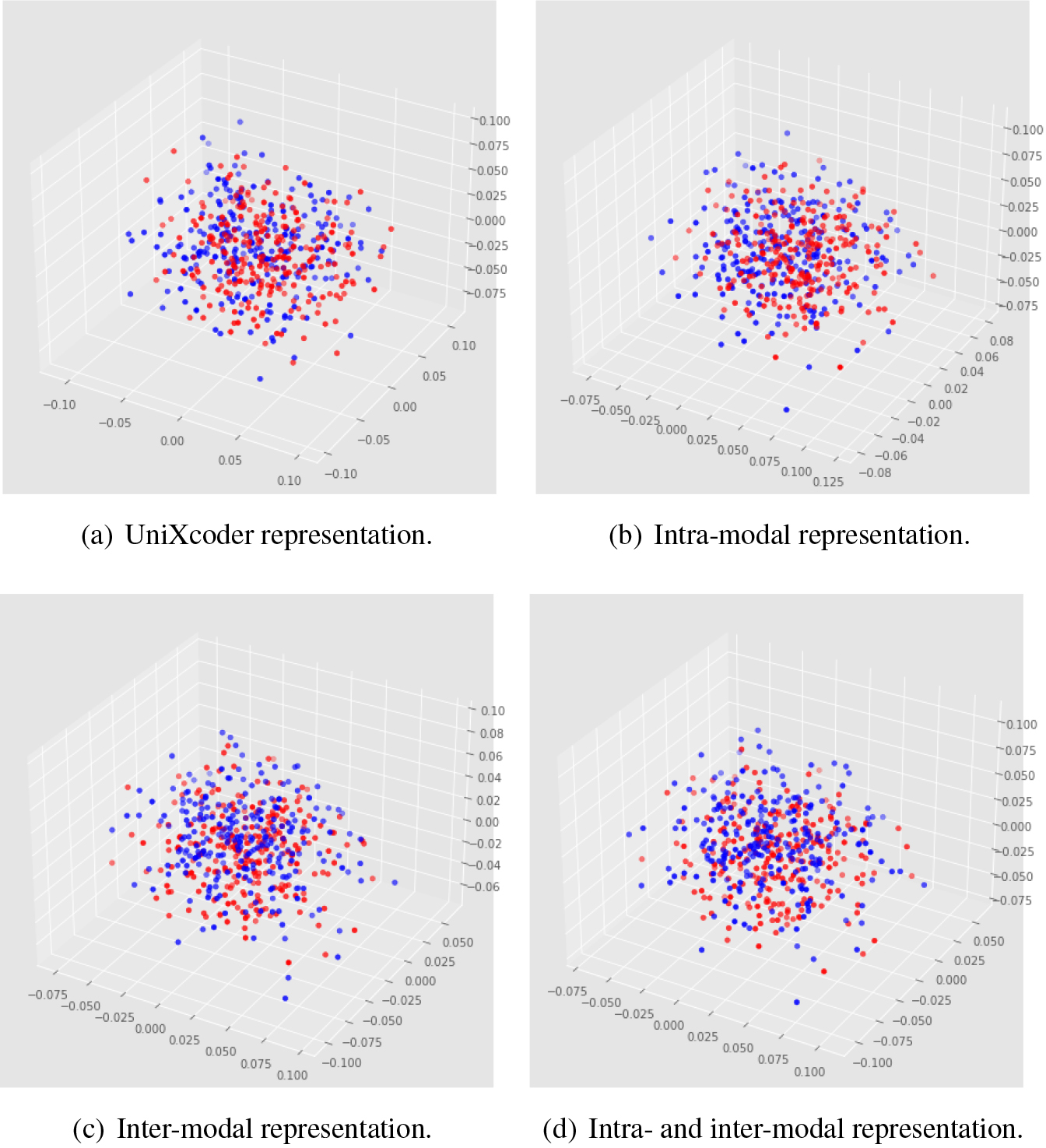
As compared to GraphCodeBERT, UniXcoder learns code representations better and aligns representations between programming languages through cross-modal generation tasks. Therefore, the generic representation of UniXcoder pre-training model is more suitable for code search tasks than GraphCodeBERT. It is evident from Table 2 that UniXcoder performs much better on the code search task than GraphCodeBERT, as can be seen in the results. In terms of the code search, GraphCodeBERT has a poor performance on the code search task because there is no good pre-training task to achieve alignment between code and natural language during GraphCodeBERT pre-training, and therefore it is less effective than UniXcoder. As can be seen from the comparison of the experimental results in Tables 3 and 4, it can be seen that the introduction of I2R on top of GraphCodeBERT is able to make the I2R-GraphCodeBERT model comparable or better than UniXcoder in the code search task when compared to UniXcoder using the I2R method. Therefore, we can conclude that our model is capable of effectively aligning the inter-modal representations while improving the stability of the intra-modal representations at the same time.
We can see in Fig. 5 how the representations of code-query pairs vary among the different models. In Fig. 5a, we can see the representation of code-query pairs obtained using the UniXcoder model, where code and query are encoded separately, and then a direct similarity calculation is performed to implement the code search. The model based on intra-modal representation learning has produced the representation of code-query pairs in Fig. 5b. Next, Fig. 5c shows the representation of code-query pairs obtained from the model based on inter-modal representation learning. Finally, Fig. 5d illustrates the representation of code-query pairs derived from the model using intra- and inter-modal representation learning.
The comparison of Fig. 5a–c shows that the introduction of intra-modal representation learning and inter-modal representation learning leads to a more concentrated representation distribution of the code-query pair, as can be seen from the figures on the axes. Additionally, it is evident that the clusters of code representations and query representations are more closely clustered. This suggests that intra-modal representation learning can effectively improve the effect of unimodal representation. Furthermore, the closer distance between the code-query pairs shown in Figure c achieves the alignment of the different modal representations. Using the I2R model in Fig. 5d, the superimposition of the model effects in Fig. 5b and c results in further clustering of the code-query pair representations, more stable unimodal inter-modal representations, and further alignment between modalities is achieved.
Conclusion
For the purpose of addressing the problem of code search, a novel approach to intra- and inter-modal representation learning (I2R) is presented in this research. The objective of this approach is to improve the consistency of intra-modal representations by R-drop while optimizing the information related to inter-modal representations through contrastive learning. A unified framework for solving code search problems has been developed by integrating intra-modal representation learning as well as inter-modal representation learning into a single framework. The inter-modal representation learning module has been introduced in order to achieve alignment between the two types of representations; meanwhile, the randomness of unimodal representations has been mitigated through the use of R-drop in order to achieve a constraint on the consistency of the distribution of outputs in unimodal models. There have been extensive experimental and ablation studies conducted to test the efficacy of the proposed I2R approach, which has been developed to achieve state-of-the-art performance for code search tasks. In the future, we plan to investigate more fine-grained feature representations of source code in order to improve the performance of code representation learning.
Footnotes
Acknowledgments
The authors would like to thank the anonymous reviewers for their insightful comments. This work was funded by the National Natural Science Foundation of China (62176053).