
Abstract
For modern Intelligent Transportation System (ITS), data missing during traffic raster acquisition can be inevitable because of the loop detector malfunction or signal interference. Nevertheless, missing data imputation is meaningful due to the periodic spatio-temporal characteristics and individual randomness of traffic raster data. In this paper, traffic raster data collected from all spatial regions at each time interval are considered as a multiple channel image. Accordingly, the traffic raster data over a period of time can be regarded as video, on which an unsupervised generative neural network called MSST-VAE (Multiple Streams Spatial Temporal-VAE) is proposed for traffic raster data imputation, and this model can even robustly performs at varied missing rates while many other approaches fail to conduct. Two major innovations can be summarized in MSSTVAE: Firstly, it uses multiple periodic streams of Variational Auto-Encoders (VAEs) with Sylvester Normalizing Flows (SNFs), which shows strong generalization ability. Secondly, after the traffic raster data are transferred into videos, an ECB (Extraction-and-Calibration Block) consisting of dilated P3D gated convolution and multi-horizon attention mechanism is employed to learn global-local-granularity spatial features and long-short-term temporal features. Extensive experiments on three real traffic flow datasets validate that MSST-VAE outperforms other classical traffic imputation models with the least imputation error.
Introduction
Along with the population growth, traffic raster data have become one of the largest kind of data in Intelligent Transportation System (ITS). Just like other typical scenes of Internet of Things (IoT), the traffic situation can be pretty unfavorable, such as too low or too high temperature, strong wind, intense sun exposure and so on [1].
For one thing, bad traffic situation may cause the loop detector aging and affect the data collection integrity. For another, poor signal strength can result in the losing of transmitted data. According to [48], traffic data missing rates in China and USA are 10% and 15% respectively, which have become a common problem for ITS [43]. Nonetheless, a lot of decision making algorithms (such as [2, 3]) in ITS require traffic raster data to be integrated and consecutive. Missing values can severely impact the performance of the algorithms, and some of them can not even function normally [42]. Therefore, in order to ensure the normal running of ITS, it is of great significance to fill in the missing traffic raster data before other algorithms or modules use them.
Traffic raster data, which are collected by loop sensor embedded underneath the roads to measure the traffic flow [4], is a typical data form in ITS. In this paper, the puzzle of traffic raster data imputation is investigated through learning them as videos. The transportation network map of one city can be segmented into several grids, and the raster data corresponding to each grid show multiple features (e.g., traffic inflow and outflow) at single temporal intervals. For each interval, the raster data can be considered as an image snapshot with multiple channels. Therefore, the whole urban traffic raster data over a time period can be learned as a video. The video-like traffic raster data show three strong features, a
Two challenges appear when populating missing value of traffic raster data in ITS: 1) How to join periodic temporal feature with spatial feature fully and effectively. 2) How to complete the imputation task considering both universal periodic spatio-temporal dependencies and individual stochasticity at the same time. To tackle the challenges above, a novel generative neural network called MSST-VAE (Multiple Streams Spatial Temporal-VAE) is proposed to model spatio-temporal representations of traffic raster data robustly and then populate the missing value accurately, inspired by [5]. The model is mainly based on multiple streams of variational auto-encoders (VAEs), which can grasp the probabilistic densities of hidden variables rather than deterministic latent representations, giving MSST-VAE the ability of generalization. The periodic feature can be learned through multiple streams as well. To further generalize the distribution of traffic raster data, Sylvester normalizing flows (SNFs) [6] is adopt to transfer an isotropic normal distribution to a more flexible one through a series of invertible transformations, which adds more robustness to MSST-VAE. Moreover, we propose a model named Extraction-and-Calibration Block (ECB) for the encoder part of MSST-VAE. ECB is composed of two main techniques: dilated P3D gated convolution and multi-horizon attention mechanism. The former is utilized to extract global-local-granularity spatial dependencies and long-short-term temporal dependencies. The latter is employed to fine-tune features in dimension of channel, time, and space.
The contribution of the study can be encapsulated in the following:
Traffic raster data are innovatively viewed as videos from an extraordinary aspect, considering both spatial and temporal dependencies simultaneously. MSST-VAE, a generative neural network based on multiple periodic VAE streams is proposed to ensure the generalization ability of the model, which can robustly performs at varied missing rates. To the best of our knowledge, this is the first work that applies multiple periodic streams of VAEs together with normalizing flows to resolve traffic raster data imputation issue. Dilated P3D gated convolution and multi-horizon attention mechanism are proposed and deployed in ECB to capture global-local-granularity spatial dependencies and long-short-term temporal dependencies, therefore spatio-temporal features in traffic raster data can be fully learned from all aspects. Extensive comparison and ablation experiments are conducted on three real-world traffic datasets to verify that MSST-VAE exhibits better performance than classical traffic imputation approaches under different missing rates.
The rest of this paper is organized as follows: Section 2 introduces and analyzes the related work about traffic data imputation. Section 3 explains the preliminary knowledge of this paper. Section 4 describes the architecture of MSST-VAE network at length. Section 5 presents the experiment settings and processes in detail, then discusses and analyzes the results obtained in the experiment. Section 6 summarizes the conclusions we get.
Related works
To address the problem of various traffic data imputation, plenty of solutions have been put forward, which may mainly be summarized into five groups: the prediction-based method, the interpolation-based method, the decomposition-based method, the statistic method, and deep learning method.
Prediction-based method
The prediction-based method tends to build a connection between historical and future missing value. Auto-regressive integrated moving average (ARIMA), one of the most popular prediction models for time series, is utilized in [7] for the imputation of traffic counts for highway agencies. [10] presents an approach to selecting and estimating ARIMA models for traffic volume imputation. However, the shortcoming of this method is obvious that the information following the missing data are not employed during the imputation, making it less effective.
Interpolation-based method
Interpolation-based approach fills the missing value with the neighboring value. As for spatio-temporal data, neighboring value can either be the temporal-liking value or spatial-liking value. [8] proposes a data-driven imputation method for sections of road based on their spatial and temporal correlation using a modified K-Nearest Neighbor method. [9] compares Local Least Squares (LLS) with K-Nearest when dealing with missing traffic data imputation. Both the research mentioned above use interpolation-based approaches. Nevertheless, this kind of method is determinative and cannot extract stochastic variations in spatio-temporal data.
Decomposition-based method
The decomposition-based approach intends to decompose the original tensor into multiple lower-dimension tensors, and then fills in the missing value on the lower-dimension tensors. Liu J, Musialski P, Wonka P, et al first come up with High Accuracy Low Rank Tensor Completion (HaLRTC), which extends the matrix case to the tensor case by proposing the definition of the trace norm for tensors for the first time and then building a working algorithm [11, 12] estimates traffic speed for ITS by combining HaLRTC and k-means++. Though the accuracy of this kind of approach is high, the computation complexity is sometimes unbearable.
Statistic-based method
The statistic-based approach learns the statistical rule of the data directly, and undertakes the imputation task based on the rule. The most widely-used method is Principal Component Analysis (PCA), and many improvements have been conducted on it [13] employs PPCA (Probabilistic Principal Component Analysis) to conduct probabilistic interpretation on PCA when dealing with traffic flow value imputation, while [14] adds Bayesian network to PCA to solve the same problem, which is known as BPCA (Bayesian Principal Component Analysis) [15] uses KPPCA (Kernel Probabilistic Principal Component Analysis) as imputing methods without any temporal or spatial dependency, and replaces linear kernel with non-linear kernel in PCA. However, this kind of approach focuses too much on constructing probability distribution model, thus loses detailed information varying in different situations.
Deep learning method
In recent years, the deep Learning methods have made noticeable achievement from all aspects, and various DL approaches have been improved to deal with data imputation issue [16] utilizes BRITS, an approach based on recurrent neural networks for imputing missing values in time series data without any specific assumption. Though the bidirectional temporal dependency within time series is considered during data imputation, little attention is given to spatial dependency among different time series [17] first transforms raw data into spatial-temporal images and then implements data imputation task with the help of convolution neural network (CNN). In [18], a deep auto-encoder for missing spatio-temporal data imputation is put forward, and the auto-encoder is designed as a combination of CNN and Bi-LSTM (Bi-Long Short Term Memory). Moreover, [19] deploys CNN based GAN (Generative Adversarial Network) to reconstruct missing multivariate time series. All these deep learning methods are limited to 2D-convolution when dealing with spatial feature extraction, and long-short term temporal dependencies are not considered.
Preliminaries
Missing data type
According to [20], missing data can be summarized into three categories: Missing Completely at Random (MCAR), Missing at Random (MAR) and Missing Not at Random (MNAR).
If the missing is irrelevant to observed or unobserved data, that is MCAR, which may happen in any region at any time randomly. MAR refers to the missing that can be described using observed data. For example, in-flow data missing in one region may be related to the out-flow data missing in adjacent regions. When the missing depends on unobserved attribute or on the missing attribute itself [21], we call it MNAR. MNAR occurs when devices are in long-term failure. The study mainly focuses on the former two kinds of missing, for it is of little significance to populate the missing value in MNAR.
Traffic raster data
As [20] depicts, an urban traffic network can be regarded as a raster map
Problem statement
Under the MCAR assumption that data are missing completely at random [21], it seems that incomplete traffic raster data that are i.i.d. can be described as a set
For tensor-based traffic raster data imputation that this paper discusses on, an incomplete tensor
Method
In this part, the architecture of MSST-VAE is presented at first, and then we propose the crucial modules ECB (Extraction-and-Calibration Block) and TCB (Transposed Convolution Block) used in MSST-VAE. Finally, we describe the engineering practice of our model in the ITS, which includes two parts: offline model training and online imputation.
As Fig. 1 shows, Multiple Streams Spatial Temporal-VAE (MSST-VAE) is mainly based on multiple periodic streams of variational auto-encoders, which contains four parts: Pre-processing, Encoder, Sylvester NFs, and Decoder. Generally, multiple streams help to catch the periodic feature of traffic raster data on the whole. VAE is utilized to model the distribution of hidden variables rather than deterministic latent representations, and then rebuild data. By this means, both universal periodic spatio-temporal dependencies and individual stochasticity are considered at the same time when imputing missing value. However, the distribution of latent variables in traditional VAE is limited to Gaussian distribution, which makes the model less robust. To improve the extensibility of amortized variational inference based approximate posterior, Sylvester normalizing flows (SNFs) as an iterative process, is adopted to remodel a diagonal Gaussian distribution to be more flexible. Moreover, Extraction-and-Calibration Blocks (ECBs) are used in Encoder part to extract global-local-granularity spatial features and long-short-term temporal features with the help of dilated P3D gated convolution and multi-horizon attention mechanism.
Overall architecture of MSST-VAE. The upper part and the bottom part are for long and short periodicity streams respectively.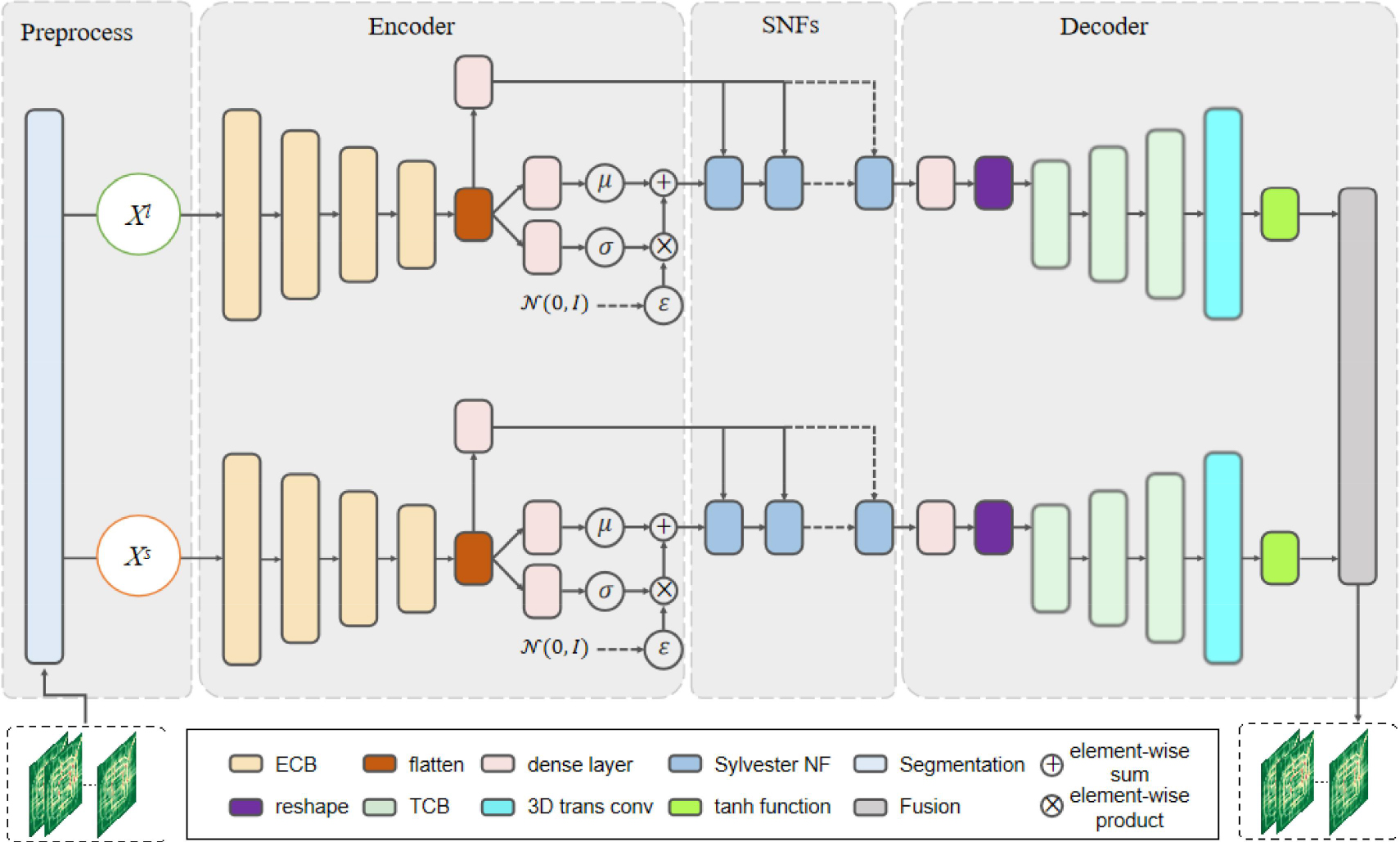
1) Pre-processing. It is known that traffic raster data show strong hourly, daily, weekly, and yearly periodicity when regarded as a whole [40]. In order to reflect this multi-periodic feature (mentioned in Section 1), the original traffic raster data are segmented into two kinds of samples
2) Encoder. After Pre-processing, both two streams of traffic raster data transfer to the Encoder part and flow along four ECBs (elaborated in Section B) in sequence to generate the deterministic hidden representations denoted as
3) Sylvester NFs. However, the output of the encoder
4) Decoder. The decoder deploys single dense layer and reshaping operation to transform
1) Extraction-and-Calibration Block. As the major component in the encoder part, Extraction-and-Calibration Block (ECB), mainly involves two sub-modules: dilated P3D gated convolution and multi-horizon attention mechanism. Assume that a feature map
where
The workflow of the Extraction-and-Calibration Block (ECB) where 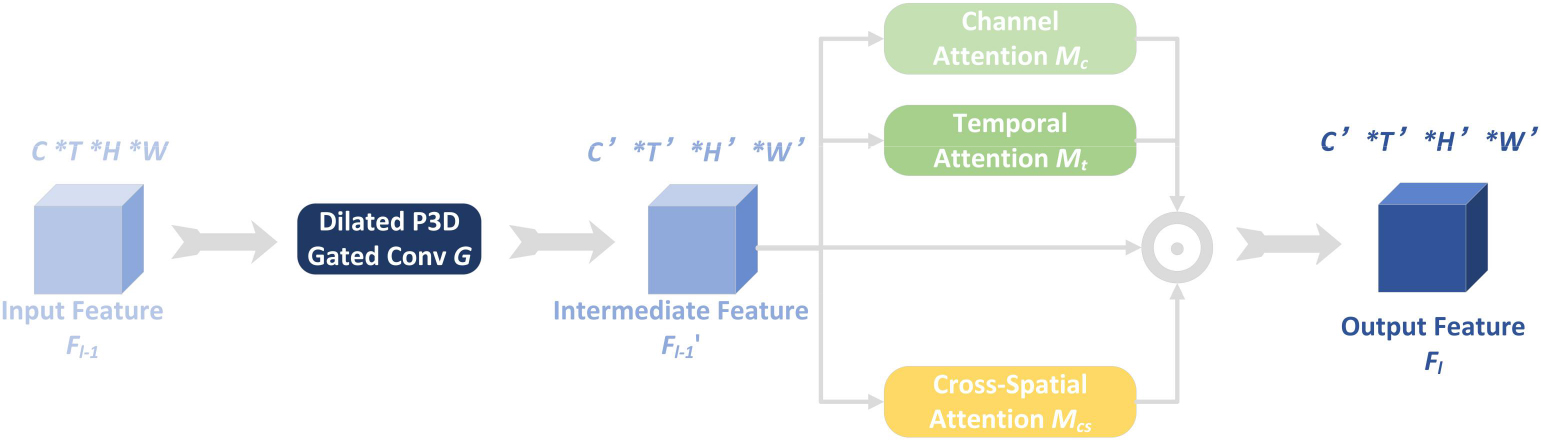
Left Part: Schematic Diagram of 3D CNN. Right Part: The designs for P3D CNN [27].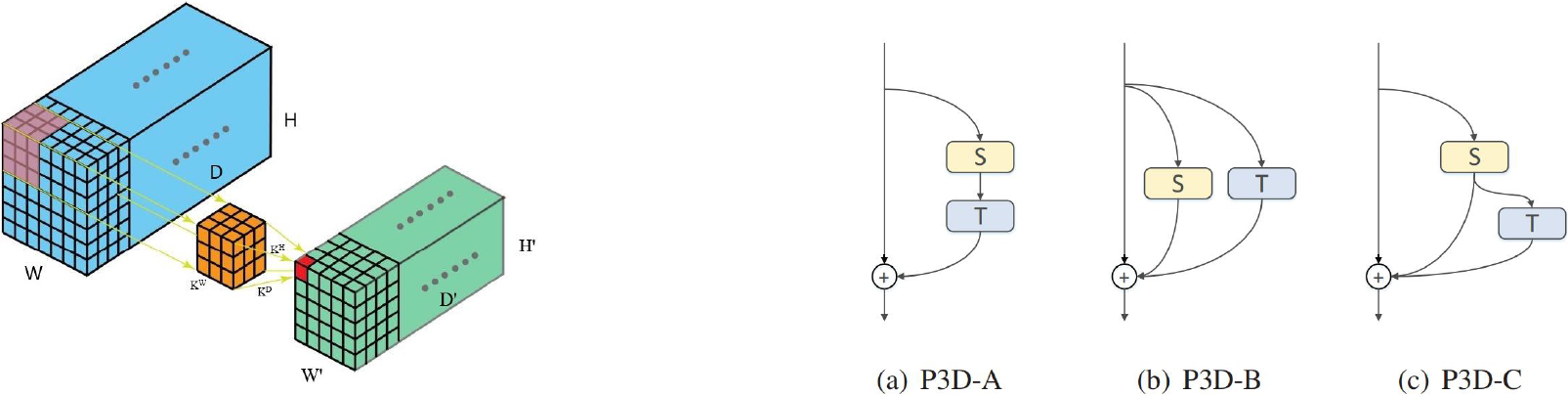
a) Dilated P3D gated convolution. In order to extract spatio-temporal features from data (like video), one natural way is to extend convolution kernels in CNN from 2D to 3D, like what [26] does to deal with video in-painting issue. To be more specific, in each layer of 3D CNN, a set of N maps of size
Different from [27], in dilated P3D gated convolution, two parts (
Overview of dilated P3D gated convolution consists of two workflows.
The workflow of dilated P3D gated convolution is displayed in Fig. 4, in which the upper part is for nonlinear spatio-temporal feature learning while the bottom part is used as a gating for soft weights calibration to the upper part by a sigmoid function. Finally, both parts are fused by the element-wise product. Dilated convolution was first proposed in [29] to increase the receptive filed in convolution operation.
It should be noticed that spatial 2D filters of P3D CNN in [27] are replaced with 2D-dilated convolution to extract global-local-granularity spatial features, and temporal 1D filters are substitute for 1D-dilated convolution for long-short-term temporal features. More details about these two parts will be discussed later.
According to [38], treating traffic raster data as images and simply applying plain CNN may not achieve the best performance, for correlations among ‘far away’ regions in the image are not taken into account. Inspired by [39], 2D-dilated spatial convolution (i.e., the blue block in Fig. 5) is utilized in dilated P3D gated convolution to catch local-granularity and global-granularity spatial features. Its structure is shown in Fig. 6. For each layer of ECB, traffic raster images with time interval
Network of dilated P3D convolution used in ECB. The bottom part is 1D dilated temporal convolution and the upper part is 2D dilated spatial convolution. The yellow blocks and blue blocks represent the receptive field of 1D-dilated and 2D-dilated temporal convolution respectively, and the red dots represent the real features maps that need to be convoluted.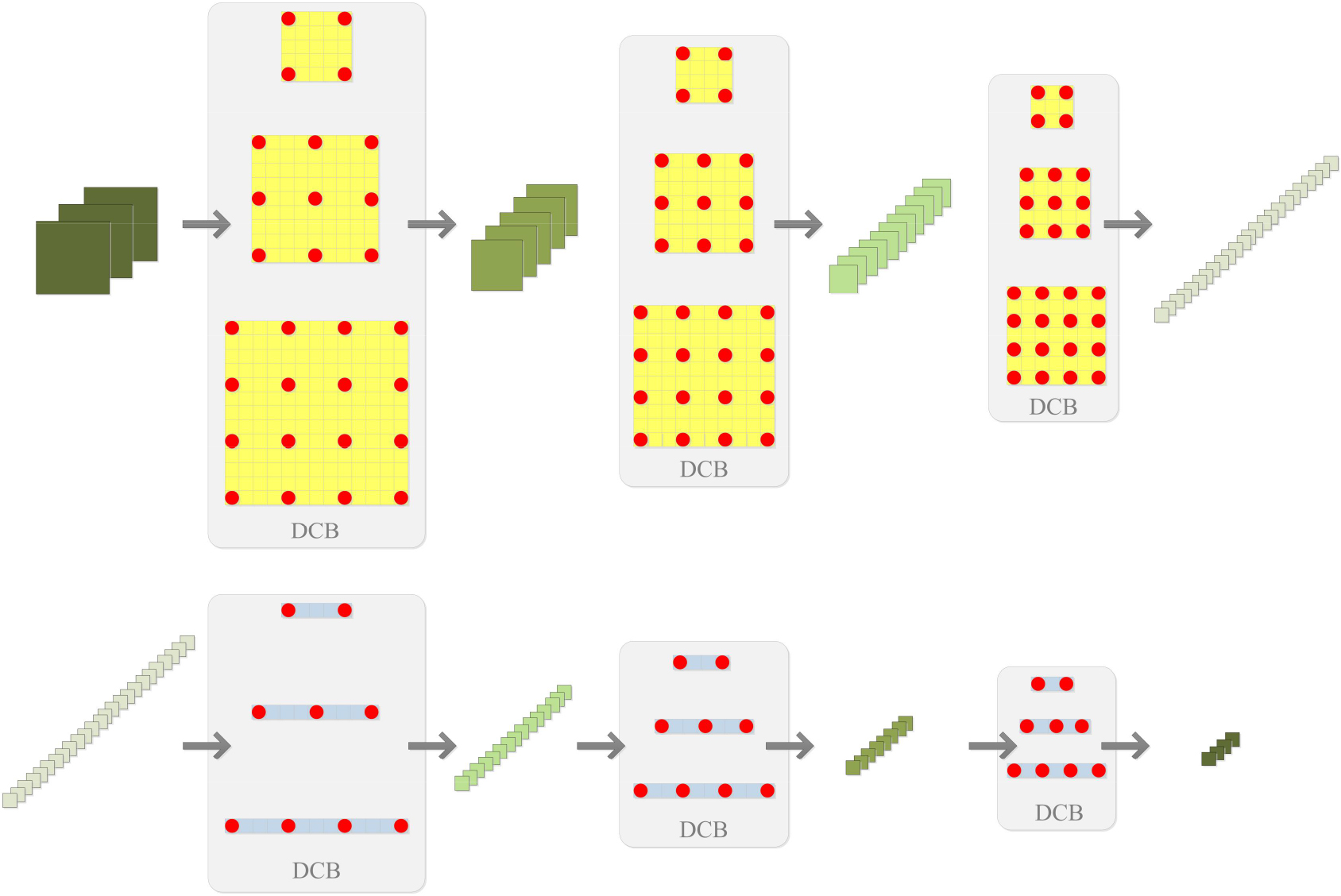
According to [37], time series is characterized by its numerical and continuous nature, so it is always seen as a whole instead of individual numerical fields. Traffic raster data can be viewed as 2D time series. Therefore, 1D-dilated temporal convolution (i.e. the yellow block in Fig. 5) is utilized in dilated P3D gated convolution to catch long-term and short-term temporal features. Its structure is similar to 2D-dilated temporal convolution, as shown in Fig. 5. Feature maps derived from 2D-dilated spatial convolution is convoluted by 1D kernel at temporal dimension. Kernel sizes are the same among most different layers, but differ in one certain layer. When the network goes deeper, the dilation factor gets smaller gradually.
b) Multi-horizon attention mechanism. Channel attention and spatial attention in Convolution Block Attention Module (CBAM) [22] are employed to image classification task. In this study, we extend CBAM from spatial attention to cross-spatial attention, and temporal attention is also added as shown in Fig. 6. In the multi-horizon attention mechanism, channel attention is utilized to learn the channel relations, such as inflows and outflows of traffic crowd, while temporal attention and cross-spatial attention are employed to enlarge or weaken the influence of features computed by dilated P3D gated convolution. Moreover, max-pooling and average-pooling are introduced to accelerate the computing as well as avoiding over-fitting.
The overview of multi-horizon attention mechanism consisting of channel attention (left), temporal attention (left) and cross-spatial attention (right).
For channel attention, we first perform max-pooling and average-pooling operations to generate two channel-wise variables
For temporal attention, the architecture of which is the same with that of channel attention, and the temporal attention map
For cross-spatial attention, max-pooling and average-pooling are operated on feature map
c) Cross-Convolution. Cross-Convolution mainly consists of two operations: Lat-Conv and Lon-Conv, just as Fig. 7 depicts. The former is utilized for learning spatial attention of latitude dimension and the latter is for spatial attention of longitude dimension, which is typical for traffic raster data.
where
Detailed design of Cross Convolution.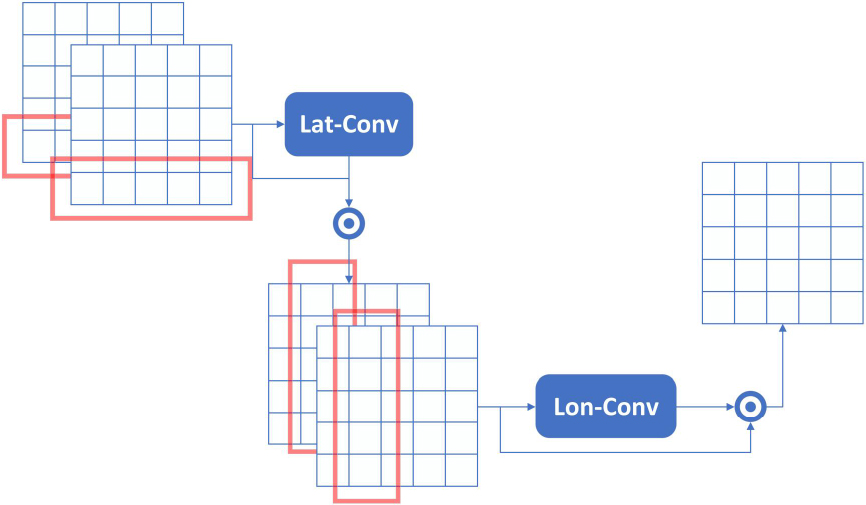
2) Transposed Convolution Block. Transposed Convolution Block (TCB) is the main component for up-sampling in Decoder part of MSST-VAE. Compared with ECB, the architecture of TCB is relatively simpler, for it only consists of P3D gated transposed convolution, without multi-horizon attention mechanism. The workflow of P3D gated transposed convolution is similar with Fig. 5, and the convolution operation is replaced with the transposed convolution operation.
The application of MSST-VAE in engineering practice can be divided into two phrases: offline model training and online imputation. The former is for training the model to converge, and the latter is to utilize the trained model to impute missing value in real time. Therefore, both share the same network architecture and the models as well as parameters of the latter are derived from the former.
1) Offline Model Training. Since the true value of missing data are unavailable, the objective of MSST-VAE is to minimize the negative log likelihood of the observed data in offline model training. In Fig. 1, each stream is trained separately and then the fusion parameter in Decoder is fine-tuned as expressed in Eq. (3). For the i-th sample
2) Online Imputation. Once the model is well-trained in offline model training, incomplete traffic raster sample
In this section, we firstly introduce the datasets utilized in all experiments and list model settings followed by evaluation metrics in this paper. Then, MSST-VAE is compared with some typical baseline methods from all aspects. Finally, we also conduct ablation experiments to figure out the validity of major modules in MSST-VAE.
Datasets and experiment settings
1) Datasets. Experiments in this paper are conducted on three real-world traffic flow datasets: TaxiBJ [2], TaxiNYC [33] and BikeNYC [2], as shown in Table 1. TaxiBJ and TaxiNYC are GPS tracking data of taxis in Beijing and New York, BikeNYC contains trip data from New York bike rental system.
Detailed description of three datasets
Detailed description of three datasets
An example of the imputation effectiveness of MSST-VAE on TaxiBJ described in Table 1. Green means unblocked, whereas red means congested. Left: Truth-ground data matrix. Mid: Incomplete data with missing rate of 30%. Right: Reconstructed data.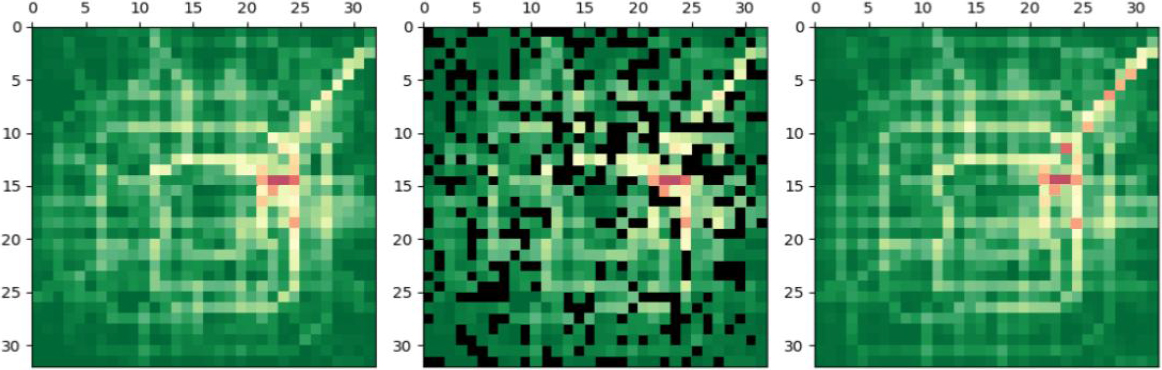
Missing values are manually generated with different missing rates at random. In this paper, traffic raster data within each day and hour is regarded as a sample for long-periodicity stream and short-periodicity stream respectively, considering the time interval of three datasets. Taking TaxiBJ as an example, if
2) Model Configuration. The hyper-parameters of MSST-VAE is set empirically as follows: Window size in long-periodicity stream is set to be 1 day, and 1 hour for short-periodicity stream. The dimension of each latent variable
Besides, all the hyper-parameters and thresholds are set by our experience or at random initially, and hyper-parameter-searching is utilized to test all the assemblies to get the best performance hyper-parameter. The same operation is performed with other baseline approaches. All the hyper-parameters involved in some baseline methods of comparison experiments is shown as follows, and the hyper-parameters of the rest deep learning baseline methods are according to the configurations in the original papers.
Hyper-parameters of comparison experiments
The reduction ratio
3) Evaluation Metrics. In order to compare our approach with other baseline methods, the matching of truth-ground data and imputed data are measured by Refined Normalized Mean Square Error (NMSE), Refined Root Mean Square Error (RMSE) and Mean Absolute Error (MAE) expressed in Eqs (13), (14), and (15). NMSE is used to calculate absolute error of single-timestamp traffic raster data for each region in detail, while RMSE and MAE is for single-timestamp traffic raster data for all regions as a whole. Therefore, the former one can represents individual similarity and the latter two targets can be utilized to verify the global similarity. Moreover, RMSE is relatively more sensitive to ‘abnormal’ data when compared with MAE. So, high RMSE means textremely ‘bad’ padding value exists.
Where
According to [13, 44, 45], to test the effectiveness and robustness of MSST-VAE as well as other comparing approaches in all kinds of situations, different missing ratios ranging from 10% to 50% with 10% interval are considered. Therefore, even when some sensors are in failure, data imputation can ensure the integrity of data and avoid system failure of ITS before the related sensors to be repaired.
In this section, a comparison is made among MSST-VAE and ten baseline methods: ARIMA [7], LLS [9], PPCA [13], HaLRTC [34], SDAE [35], MLP-VAE [5], CombCN [36], 3DConvGAN [46], DeepSTN+ [47], and STVAE [41], which can be classified into two groups. ARIMA, LLS, PPCA, and HaLRTC are traditional methods corresponding to the four sub-categories in Section 2. SDAE, CombCN, MLP-VAE, 3DConvGAN, DeepSTN+ and STVAE are deep learning-based methods. Moreover, MLP-VAE and STVAE are also VAE-based model for data imputation. Figures 9 and 10 show the comparison results of our approach with other baseline methods on three datasets at different missing rates.
NMAE and MAE results of comparison experiment conducted on TaxiBJ, TaxiNYC and BikeNYC datasets.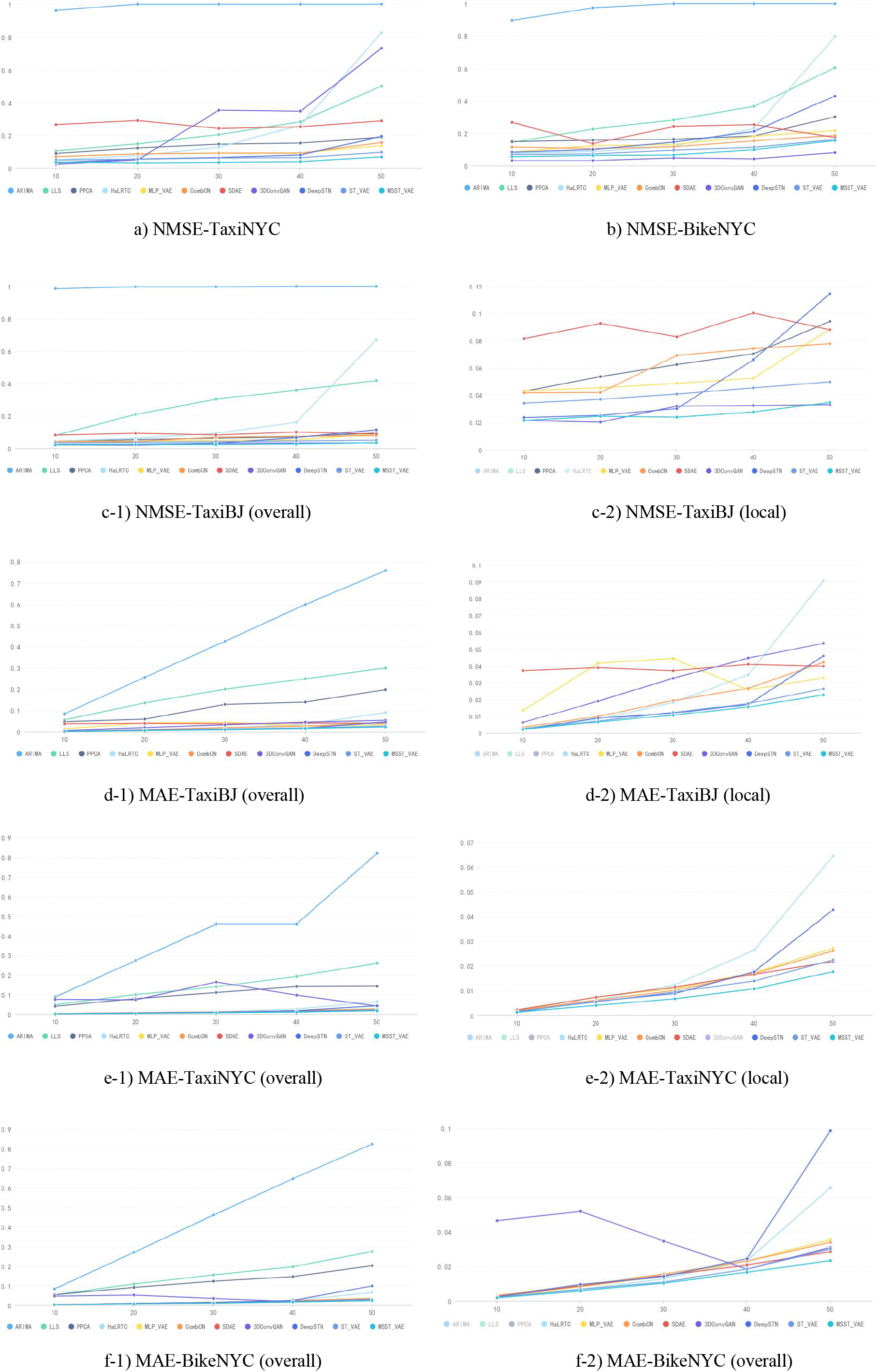
RMSE result of comparison experiment conducted on TaxiBJ, TaxiNYC and BikeNYC datasets.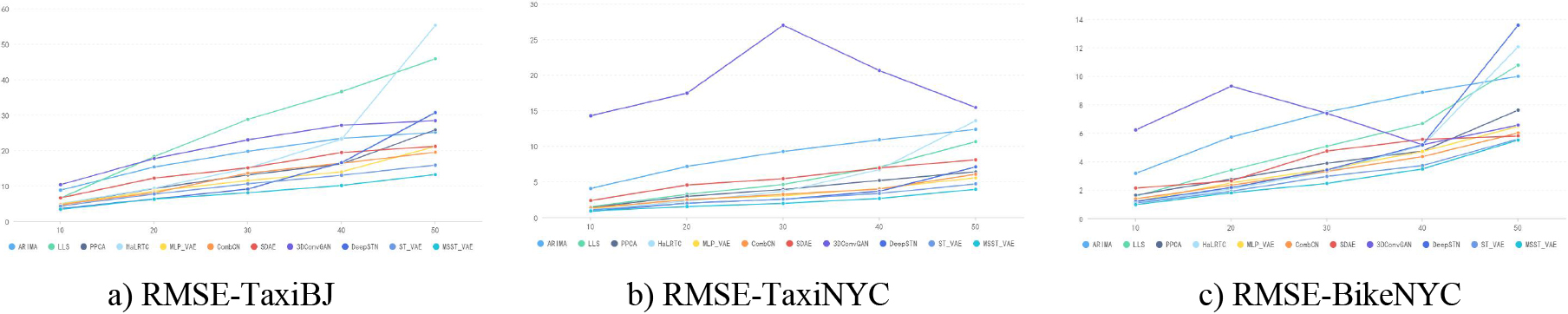
From the discussion above, we can draw a conclusion that MSST-VAE fulfills a more competitive imputation performance on traffic raster data than all the baseline models including the state-of-the-art VAE-based model ST-VAE, especially when the missing rate is high. Moreover, MSST-VAE shows steady performance on three indexes: Lowest NMSE and MAE demonstrating good local and global imputation ability, and lowest RMSE showing little extremely bad imputed value. What’s more, MSST-VAE displays strong robustness even at different missing rates.
Resource-consuming of HalRTC, 3DConvGAN, and MSST-VAE
In order to validate the effectiveness of major techniques in MSST-VAE, ablation experiments are conducted in this section. We reconfigure MSST-VAE to create four variants described as follows: 1) single-stream MSST-VAE. 2) MSST-VAE w/o SNFs. 3) MSST-VAE w/o dilated P3D convolution. 4) MSST-VAE w/o multi-horizon attention mechanism. Table 4 presents the NMSE and RMSE of MSST-VAE and four variants on three datasets at different missing rates.
In order to validate the effectiveness of major techniques in MSST-VAE, ablation experiments are conducted in this section. We reconfigure MSST-VAE to create four variants described as follows: 1) single-stream MSST-VAE. 2) MSST-VAE w/o SNFs. 3) MSST-VAE w/o dilated P3D convolution. 4) MSST-VAE w/o multi-horizon attention mechanism. Table 4 presents the NMSE and RMSE of MSST-VAE and four variants on three datasets at different missing rates.
Results of ablation experiment on three datasets
Results of ablation experiment on three datasets
Sensitive study of ECB number 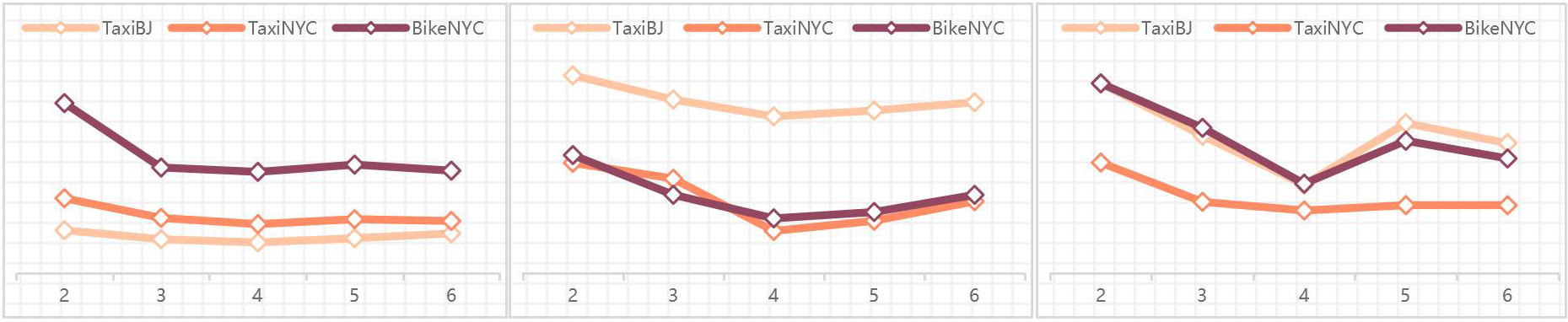
Sensitive study of length of NFs 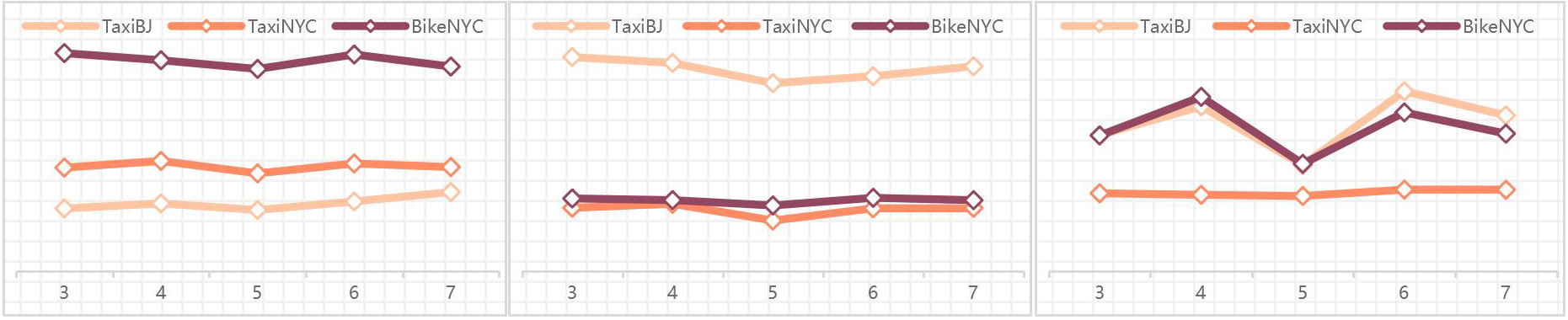
In order to evaluate the effectiveness of various parameterizations of MSST-VAE, hyper-parameter sensitive study is conducted on public datasets with average missing rates. Two major hyper-parameter is selected as the object of the study: number of ECB n and length of NFs
In this paper, a Multiple Streams Spatial Temporal-VAE (MSST-VAE) is proposed to address the challenge of periodic traffic raster data imputation task. In MSST-VAE, multiple periodic streams of VAE that leverages Sylvester NFs not only take multi-grained periodicity into account but also guarantee the generalization and accuracy of imputed data. Moreover, dilated P3D convolution and multi-horizon attention mechanism that deployed in Extraction-and-Calibration Block (ECB) make the MSST-VAE capable of fully extracting global-local-granularity spatial feature and long-short-term temporal feature of traffic raster data at the same time. The results of comparison experiment and ablation experiment also indicate that the MSST-VAE is effective and superior to the existing work of periodic traffic raster data imputation. In future studies, the authors will extend data imputation task from traffic raster data to traffic trajectory data, and the P-3D convolution may be replaced by graph convolution network to extract non-Euclidean spatial features when missing value are imputed.
Statements and declarations
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper
Data availabilities
The original code can be accessible on reasonable request after evaluation.
Footnotes
Acknowledgments
This work is financially supported by Shenzhen Science and Technology Program under Grant No. GXWD20220817124827001 and No.JCYJ20210324132406016.