
Abstract
Multi-label image classification aims to predict a set of labels that are present in an image. The key challenge of multi-label image classification lies in two aspects: modeling label correlations and utilizing spatial information. However, the existing approaches mainly calculate the correlation between labels according to co-occurrence among them. While the result is easily affected by the label noise and occasional co-occurrences. In addition, some works try to model the correlation between labels and spatial features, but the correlation among labels is not fully considered to model the spatial relationships among features. To address the above issues, we propose a novel cross-modality semantic guidance-based framework for multi-label image classification, namely CMSG. First, we design a semantic-guided attention (SGA) module, which applies the label correlation matrix to guide the learning of class-specific features, which implicitly models semantic correlations among labels. Second, we design a spatial-aware attention (SAA) module to extract high-level semantic-aware spatial features based on class-specific features obtained from the SGA module. The experiments carried out on three benchmark datasets demonstrate that our proposed method outperforms existing state-of-the-art algorithms on multi-label image classification.
Introduction
Multi-label image classification is a fundamental and challenging task in computer vision, which aims to predict the presence of multiple objects in an image. Researchers have developed a series of methods for multi-label image classification [29, 8, 14]. Multi-label image classification has more extensive applications than its single-label counterpart, such as medical diagnosis recognition [2], remote sensing image classification [18], attribute recognition [39], scene understanding [27], and emotion recognition [22]. For Example, in medical diagnosis, chest X-ray (CXR) is one of the common screening techniques used in the diagnosis of chest diseases. Multi-label image classification model can automatically predict the possible diseases for patients based on their CXR images [2], such as Atelectasis, opacity, and Consolidation. Since the presence of multiple objects and abundant semantic information in multi-label images, traditional methods that convert multi-label image classification problems into a series of single-label classification problems without modeling the label correlations, which can greatly affect classification performance. Furthermore, accurately locating object regions in an image facilitates the extraction of spatial features corresponding to the categories. Therefore, modeling label correlations and correlations between labels and object regions are significant to improve the performance of classification.
With the emergence of graph neural networks, recent works [6, 17, 15] capture label correlations by propagating node messages via graph convolution networks. For example, ML-GCN [6] proposed to generate multiple label-specific classifiers via a graph convolution network. In these graph-based approaches, the label correlation matrix is typically obtained by counting the co-occurrence of label pairs in the training data. However, the model performance will be affected by the label noise and occasional co-occurrences. Subsequently, several works [20, 38] optimized the topology of the graph by learning multiple graph structures. But they only construct label correlation by label embeddings and ignore the visual features. In addition to modeling label correlations, the researchers propose to address multi-label image classification tasks based on image spatial information. Some works [31, 5] have been proposed to model the spatial relationships among features, but they are modeled without the guidance of label semantic information. Furthermore, some works [37, 43] try to model the correlation between labels and spatial features, but the correlation among labels is not fully considered to model the spatial relationships among features.
To address the above issues, we propose a cross-modality semantic guidance (CMSG) based framework for multi-label image classification, which models the correlation between features corresponding to different labels and learns the semantic-aware spatial features with the guidance of semantic label embeddings. Specifically, the proposed framework, CMSG, is composed of two critical modules. First, we design a semantic-guided attention (SGA) module to learn the class-specific feature representation for different labels. In the SGA module, the label correlation matrix obtained by calculating the cosine similarity based on the label embeddings is utilized to model the relationship among features corresponding to different labels with the proposed multi-head mask attention. Second, we design a spatial-aware attention (SAA) module which is composed of a multi-head cross-attention. SAA can further extract the high-level semantic-ware spatial features based on the class-specific features obtained by the SGA module. Extensive experiments carried out on three benchmark multi-label datasets, including MS-COCO 2014, VOC 2007, and VOC 2012, show that the proposed method CMSG achieves competitive performance on multi-label classification. The main contributions of this paper are summarized as follows:
We propose a novel cross-modality semantic guidance-based framework for multi-label image classification, namely CMSG, which is composed of two critical modules. we design a semantic-guided attention (SGA) module which is composed of a multi-head masked attention. SGA applies the label correlation matrix to guide the learning of class-specific features, where the semantic correlation among labels is implicitly modeled. We further design a spatial-aware attention (SAA) module to extract high-level semantic-aware spatial features based on class-specific features obtained from the SGA module, where the correlation between labels and spatial features is modeled. We evaluate our methods on three benchmark datasets, including MS-COCO 2014, VOC 2007, and VOC 2012 and demonstrate that our proposed method can achieve competitive performance.
The rest of this paper is organized as follows. Section 2 reviews the previous works on multi-label learning. Section 3 introduces the proposed method CMSG in detail. Comparative experiment results and analyses are presented in Section 4. Finally, we conclude this paper in Section 5.
In recent years, various multi-label image classification approaches have been proposed. In the following subsections, we will review these approaches from label correlation and spatial information modeling two aspects.
Label correlation-based approaches
Early works for multi-label learning focus on the decomposition of a multi-label classification task into multiple single-label classification tasks. For example, Boutell et al. [1] proposed to convert a multi-label classification problem into a set of independent binary classification problems, where each binary classification problem corresponds to a label. But these methods ignore the issue of label correlations in multi-label images. In multi-label classification, labels are often correlated with each other, and modeling label correlations can significantly improve the performance of classification. Wang et al. [29] introduce recurrent neural networks (RNNs) to achieve effective multi-label classification by considering label co-occurrence in the training data. Chen et al. proposed an order-free RNN [3] that predicts label sequences using a confidence-ranked LSTM, rather than requiring a predefined label order. Unlike these sequential approaches with RNNs, some works use graph structures to construct label relations. Recently, the success of graph neural networks has aroused growing concerns. In [6], graph convolutional neural networks are adopted to propagate label representations to model label correlations. In [4], SSGRL is proposed, which learns inter-label dependencies through a graph with gated recurrent neural networks. However, these works construct graph structures directly by counting label co-occurrences according to the training data, which may cause model overfitting. In [36], ADD-GCN is proposed to generate dynamic graphs with an attention mechanism to achieve dynamic graph convolution. Currently, several approaches utilize the multi-head self-attention mechanism in Transformer [28] to model label correlations. Lanchantin et al. [16] adopt the Transformer encoder to capture label long-range dependencies. S-MAT [33] employs masked attention to filter the redundant label dependencies and enhance the robustness of the model.
Spatial information-based approaches
The spatial information of images plays a key role in multi-label image classification. With the development of object detection, many works utilize pre-trained object detection models to roughly localize multiple regions and then to recognize each region with convolution neural networks [25, 44, 7]. For example, Wei et al. [32] propose HCP which generates numerous proposals with object detection models and treats each proposal as a single-label classification task, but this method incurs a huge computational cost because of the proposal generating. Wang et al. [31] introduce a spatial transformer network to extract features of regions of interest and predict the labels of each region sequentially using LSTM. In [11], a two-stream framework MCAR is developed to identify multi-class objects from global to local. In addition to generating the regions, it is also important to explore the association between spatial information of images and semantic labels. Chen et al. [4] propose a semantic decoupling module to capture the interaction between labels and visual features. Zhu et al. [43] aggregate visual features from spatial streams to semantic streams to update label semantic information. You et al. [37] introduce cross-modality attention to measure the importance of each location by computing the similarity between spatial features and semantic labels. Different from these methods, this paper adopts the cross-attention mechanism to learn spatial features with the guidance of the semantic information of labels, which is a simple yet effective method.
The overall pipeline of our proposed framework CMSG.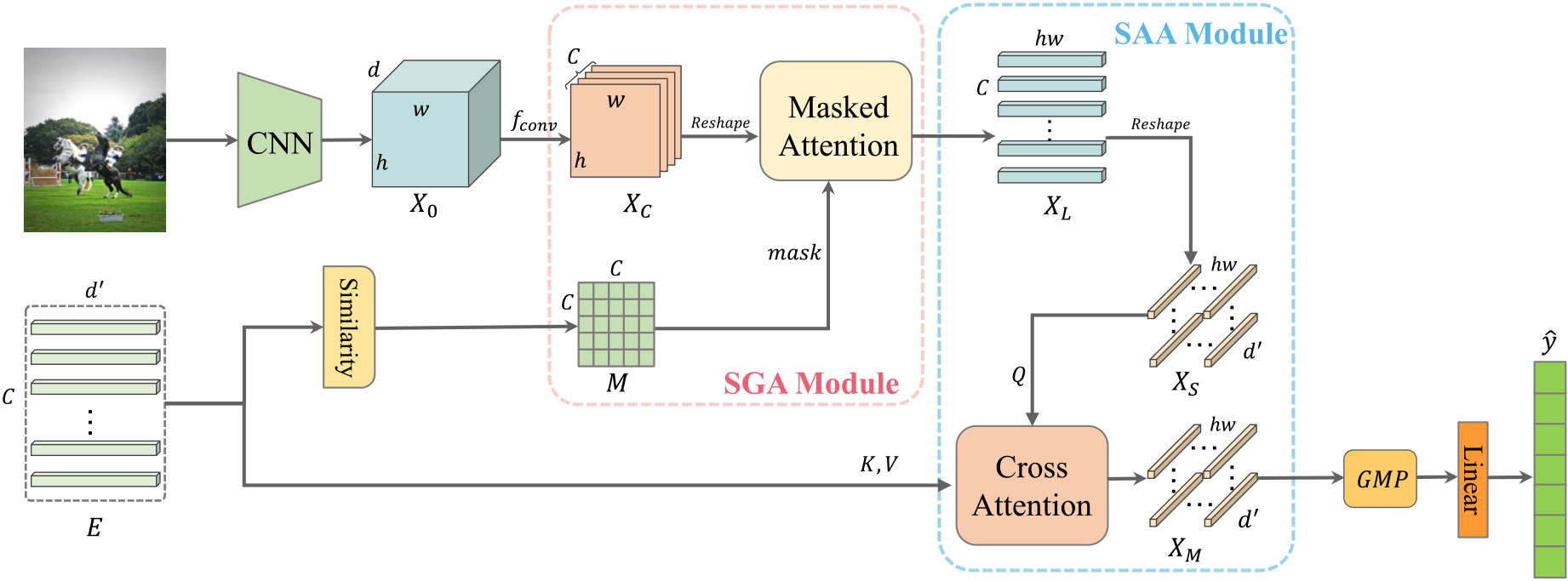
Overview
In this section, we will introduce the proposed framework CMSG, which consists of two main modules, i.e., the semantic-guided attention (SGA) module and the spatial-aware attention (SAA) module. The overall pipeline of the proposed framework is shown in Fig. 1.
Specifically, given an image, we first feed it into the backbone to generate the feature map
Feature extraction
Given an image
where
In multi-label image classification, labels are often correlated with each other, and modeling label correlations can significantly improve the performance of classification. Many methods calculate the label correlation according to co-occurrence among labels. However, the result is easily affected by the label noise and occasional co-occurrences. In this paper, following [38], we construct a semantic correlation matrix by calculating the similarity between label embeddings which are trained on a large-scale unsupervised corpus that usually contains rich semantic information.
For a multi-label classification problem with
Inspired by [6], we set a threshold
Consequently, we can get a re-weighted semantic correlation matrix
After obtaining the label semantic correlation matrix
The detailed illustration of multi-head masked attention (MHMA). 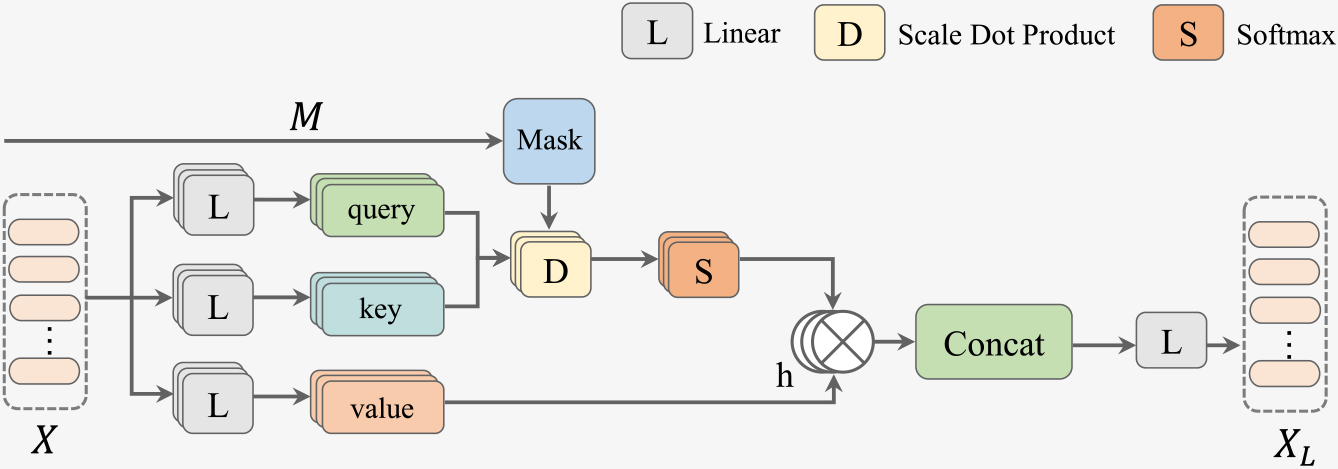
Concretely, the feature
where
By introducing the semantic correlation matrix in the calculation of self-attention scores, it allows the semantic relations of the labels to participate in the calculation of the attention scores. As a result, label semantic correlation is implicitly embedded into the features, and the high-level class-specific feature representations can be learned.
MHMA is a multi-head extension of the above masked single attention mechanism, which is defined as
where
Our proposed SGA is a multi-layer architecture, where each layer is composed of a multi-head attention mechanism and a Feed-Forward Network (FFN). Specifically, the
where
In order to fully consider the correlation between the label semantic information and spatial features, in this section, we design a spatial-aware attention (SAA) module to further extract the semantic-aware spatial features based on the class-specific feature
The detailed illustration of the multi-head cross-attention (MHCA). 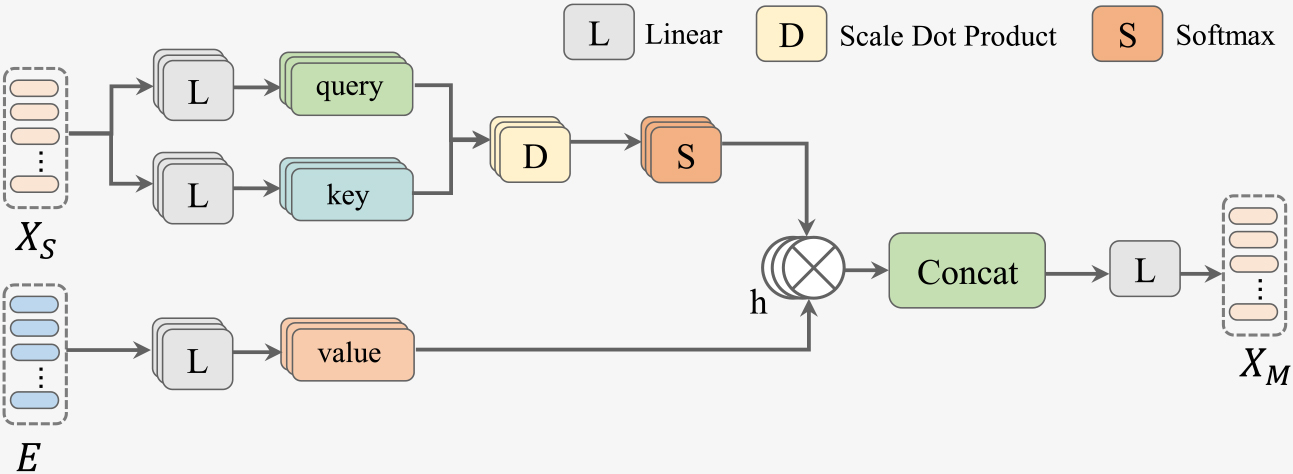
Specifically, the feature representation
where
The representation
Next, to capture the correlations between each position of the visual features and the semantic label embeddings,
The SAA module is composed of several layers of multi-head cross-attention (MHCA) which is a multi-head extension of the above single cross-attention mechanism. Specifically, we define it as
where
where
With the learned feature representation
where
In order to better solve the imbalance problem of sample positive and negative labels, in this paper, we adopt Asymmetric loss [26], which is defined as
where
Datasets
To verify the effectiveness of our proposed method CMSG, three widely used multi-label benchmark datasets, including Pascal VOC 2007, Pascal VOC 2012, and MS-COCO2014, are used. Below is a detailed introduction to these datasets.
VOC2007 Dataset [10] contains 9963 images with 20 categories, and it is split into trainval set and test set, in which the trainval set has 5011 images and the test set has 4952 images. VOC2012 Dataset [10] has 22531 images with 20 categories, among which 11540 are used as the trainval set and 10991 are used as the test set. MS-COCO 2014 Dateset [19] has 82081 images as the train set and 40504 images as the validation set, and it contains 80 categories with approximately 2.9 labels per image.
To fairly compare with the state-of-art approaches, the widely used metrics are adopted, including the mean average precision (mAP) for all categories, the per-class precision (CP), recall (CR), and F1-measure (CF1), and overall precision (OP), recall (OR), F1-measure (OF1). In addition, to compare with other existing methods on the MS-COCO dataset, we also report the top-3 results for precision, recall, and F1-measure.
Implementation details
All the experiments are conducted on a Linux server equipped with two NVIDIA RTX 3090 GPUs. The proposed method CMSG is implemented by the deep learning framework PyTorch [21]. The ResNet101 [12] is utilized as the backbone which is pre-trained on ImageNet [9]. The label embeddings are obtained by GloVe [23] which is trained on the Wikipedia dataset, and the dimension is set to 300. During the training, we use the data augmentation method proposed in [30]. The input images are randomly cropped and resized to
Experiment results
For the comparing approaches, we utilized the experimental results provided by their respective publications for comparisons. The experimental results for all the approaches are summarized in Tables 2–3, where the numbers in bold indicate the best performance and the numbers underlined indicate the second performance.
| Methods | aero | bike | bird | boat | bottle | bus | car | cat | chair | cow | table | dog | horse | motor | person | plant | sheep | sofa | train | tv | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CNN-RNN [29] | 96.7 | 83.1 | 94.2 | 92.8 | 61.2 | 82.1 | 89.1 | 94.2 | 64.2 | 83.6 | 70.0 | 92.4 | 91.7 | 84.2 | 93.7 | 59.8 | 93.2 | 75.3 |
|
78.6 | 84.0 |
| ResNet101 [12] | 99.5 | 97.7 | 97.8 | 96.4 | 75.4 | 91.8 | 96.1 | 97.6 | 74.2 | 80.9 | 85.0 | 98.4 | 96.5 | 95.9 | 98.4 | 70.1 | 88.3 | 80.2 | 98.9 | 89.2 | 89.9 |
| HCP [32] | 98.6 | 97.1 | 98.0 | 95.6 | 75.3 | 94.7 | 95.8 | 97.3 | 73.1 | 90.2 | 80.0 | 97.3 | 96.1 | 94.9 | 96.3 | 78.3 | 94.7 | 76.2 | 97.9 | 91.5 | 90.9 |
| ML-GCN [6] | 99.5 | 98.5 | 98.6 | 98.1 | 80.8 | 94.6 | 97.2 | 98.2 | 82.3 | 95.7 | 86.4 | 98.2 | 98.7 | 96.7 | 99.0 | 84.7 | 96.7 | 84.3 | 98.9 |
|
94.0 |
| SSGRL [4] | 99.5 | 97.1 | 97.6 | 97.8 | 82.6 | 94.8 | 96.7 | 98.1 | 78.0 |
|
85.6 | 97.8 | 98.3 | 96.4 | 98.8 | 84.9 | 96.5 | 79.8 | 98.4 | 92.8 | 93.4 |
| MCAR [11] | 99.7 |
|
98.5 | 98.2 | 85.4 | 96.9 | 97.4 | 98.8 | 83.7 | 95.5 | 88.8 | 99.1 | 98.2 | 95.1 |
|
84.8 | 97.1 |
|
98.3 | 94.8 | 94.8 |
| DAGAT [41] | 99.4 | 97.3 | 98.2 | 98.2 | 80.5 | 95.3 | 97.3 | 97.6 |
|
94.6 | 86.5 | 98.4 | 98.5 | 95.8 | 98.8 |
|
97.7 | 82.8 | 98.5 | 93.9 | 93.8 |
| SST [5] |
|
98.6 |
|
98.4 |
|
94.7 |
|
98.6 | 83.0 | 96.8 | 85.7 | 98.8 | 98.9 | 95.7 |
|
85.4 | 96.2 | 84.3 | 99.1 | 95.0 | 94.5 |
| CMSG | 99.5 | 98.7 | 98.8 |
|
83.7 |
|
97.7 |
|
82.9 |
|
|
|
|
|
|
86.9 |
|
86.6 | 98.9 |
|
|
| CMSG* |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
96.6 |
|
Experimental results on PASCAL VOC 2012, and “*” indicates that ResNext-101 32X16d is used as the backbone
1) Performance on the VOC2007 Dataset. The results on the VOC2007 dataset of the proposed method and the state-of-the-art methods are shown in Table 2. Our method achieves the best mAP performance and outperforms other methods in 13 out of 20 categories in terms of AP. Compared with the graph neural network-based methods, including SSGRL [4], DAGAT [41], and ML-GCN [6], the result of mAP of CMSG is 2.0%, 1.6%, and 1.4% higher than that of them, respectively. Compared with the Transformer based method SST [5], the result of mAP is increased by 0.9%. It is noted that our method achieved an mAP of 96.9% when ResNext-101 32X16d [34] network with a semi-weakly supervised pre-trained model on ImageNet [35] is utilized as the backbone.
2) Performance on the VOC2012 Dataset. The results on the VOC2012 dataset of the proposed method and the state-of-the-art methods are shown in Table 2. Similar to the results on VOC2007, CMSG achieves the best mAP performance and outperforms other methods in 16 out of 20 categories in terms of AP. CMSG achieves a high mAP of 96.2% when ResNext-101 32X16d [34] is utilized as the backbone.
3) Performance on the MS-COCO 2014 Dataset. The results on the VOC2012 dataset of the proposed method and the state-of-the-art methods are shown in Table 3. For a fair comparison, we utilized the experimental results of the comparing approaches provided by their respective publications for comparisons when the input images are randomly cropped into the size of
Experimental results on MS-COCO, “*” indicates that ResNext-101 32X16d is used as the backbone, and “–” denotes that the result was not reported
According to these experimental results, we can see that our proposed method CMSG achieves the best performance among all compared approaches and outperforms all baselines by a significant margin in terms of every evaluation criterion. The better performance of our proposed method demonstrates the effectiveness of multi-label image classification with cross-modality semantic guidance.
To demonstrate the effectiveness of each component of our proposed method, we conduct several ablation experiments on the VOC2007 and MS-COCO datasets. For the proposed method CMSG, we have two main modules, i.e., the semantic-guided attention (SGA) and spatial-aware attention (SAA) modules. To evaluate the effectiveness of each module, we performed module ablation experiments by sequentially removing each module to validate its importance. Table 4 displays the results for different combinations of these modules in terms of mAP, where CMSG w/o SAA and CMSG w/o SGA denote our framework CMSG is executed without the SAA module and the SGA module respectively. CMSG w/o
As shown in Table 4, the baseline ResNet-101 without the semantic-guided attention (SGA) and spatial-aware attention (SAA) modules obtains 77.1% on mAP. When the SGA module is added, the results of mAP are 1.8% and 1.4% higher than that of ResNet-101 on VOC2007 and MS-COCO, respectively. Similarly, when the SAA module is added, the results of mAP are 2.7% and 2.5% higher than that of ResNet-101 on VOC2007 and MS-COCO, respectively. This observation indicates that the SAA module plays a more important role than SGA in multi-image classification for the proposed method. When both modules are equipped, CMSG achieves the highest performance on both datasets. Additionally, when we remove the semantic correlation matrix in the SGA module, the results of mAP are 0.2% and 0.3% lower than that of our framework CMSG on VOC2007 and MS-COCO, respectively. This result clearly demonstrates the effectiveness of incorporating the label correlation matrix
Experimental results of ablation study on VOC 2007 and MS-COCO 2014 datasets
Experimental results of ablation study on VOC 2007 and MS-COCO 2014 datasets
The proposed method CMSG has several hyperparameters, i.e., the number of heads and the number of layers of the multi-head masked attention and cross-attention modules. To fully understand the impact of these hyperparameters on the model performance, we conduct experiments on the VOC 2007 dataset.
Effect of the number of attention heads
The multi-head attention mechanism can capture information from multiple perspectives. To investigate the impact of the number of attention heads
Results of parameter sensitivity analysis w.r.t the number of heads 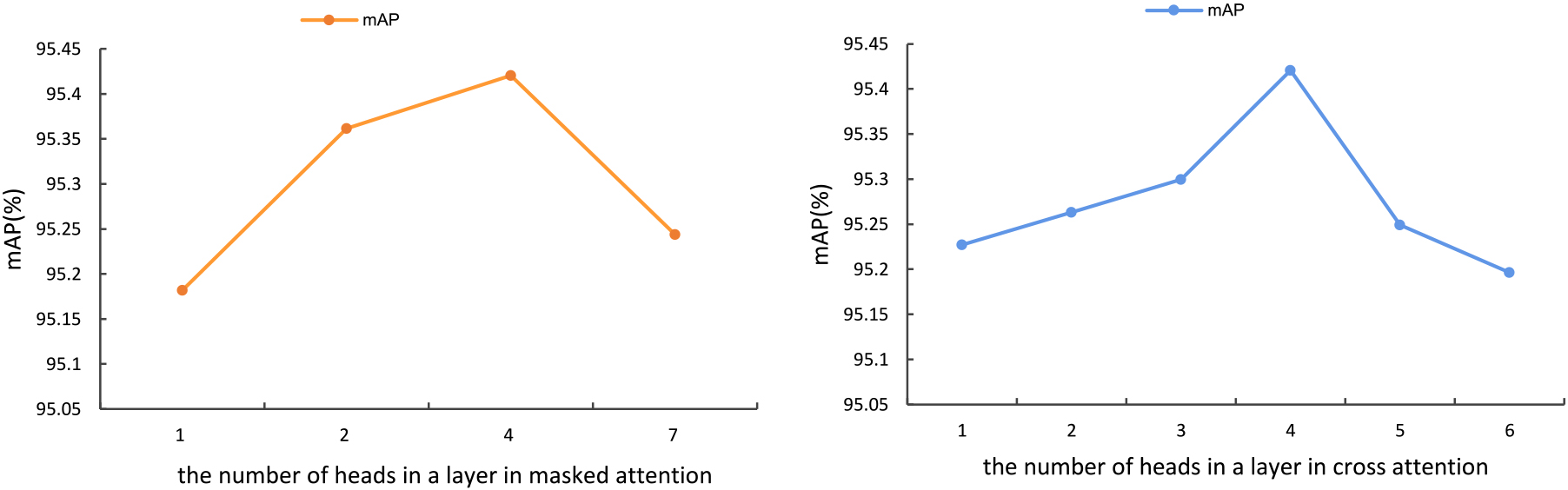
In order to explore the impact of the number of layers
Results of parameter sensitivity analysis w.r.t the number of layers 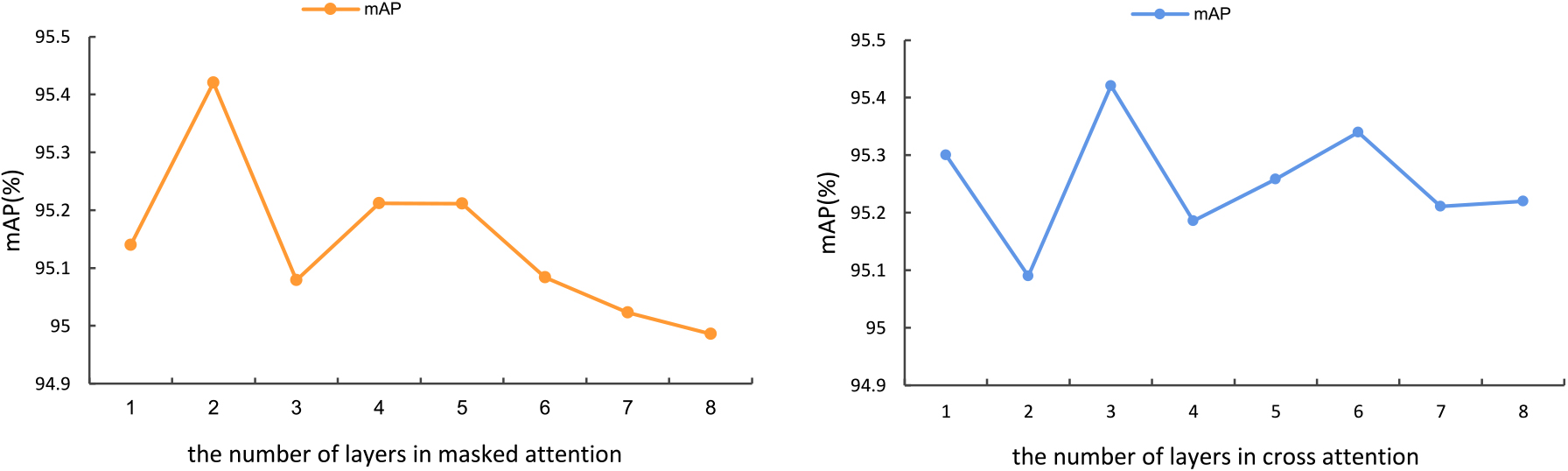
In this paper, to exploit the relationship between labels and features, as well as to capture semantic-aware spatial features, we propose a cross-modality semantic guidance-based framework CMSG for multi-label image classification. The proposed framework is mainly composed of two multi-head attention modules. The semantic-guided attention (SGA) module uses the label correlation matrix to guide features to implicitly capture semantic correlations through a multi-head masked attention mechanism. The spatial-aware attention (SAA) module utilizes the multi-head cross-attention mechanism to capture the correlations between semantic label embeddings and individual spatial locations to learn high-level semantic-aware spatial features. Experimental results demonstrate that our proposed method, CMSG, achieves superior performance compared to state-of-the-art approaches. Furthermore, our results verify that effectively modeling the correlation between labels, and the correlations between labels and individual spatial locations can further improve the performance of multi-label image classification.
Footnotes
Acknowledgments
This work is supported by the Natural Science Foundation of China: 61806005, the University Synergy Innovation Program of Anhui Province: GXXT-2022-052 and GXXT-2020-012, the Outstanding Young Talents Support Program of Anhui Province: gxyqZD2022032, and the Natural Science Foundation of the Educational Commission of Anhui Province of China: KJ2021A0373.