
Abstract
Intrusion detection systems (IDSs) are essential elements of IT systems. Their key component is a classification module that continuously evaluates some features of the network traffic and identifies possible threats. Its efficiency is greatly affected by the right selection of the features to be monitored. Therefore, the identification of a minimal set of features that are necessary to safely distinguish malicious traffic from benign traffic is indispensable in the course of the development of an IDS. This paper presents the preprocessing and feature selection workflow as well as its results in the case of the CSE-CIC-IDS2018 on AWS dataset, focusing on five attack types. To identify the relevant features, six feature selection methods were applied, and the final ranking of the features was elaborated based on their average score. Next, several subsets of the features were formed based on different ranking threshold values, and each subset was tried with five classification algorithms to determine the optimal feature set for each attack type. During the evaluation, four widely used metrics were taken into consideration.
Keywords
Introduction
Nowadays, only automated tools called Intrusion Detection Systems (IDSs) are capable of efficiently detecting attacks against IT systems. They continuously monitor and evaluate the parameters of network packages. An IDS is a software or hardware solution that can detect out-of-the-ordinary packages and activities capable of damaging the computer or even the network. An IDS device monitors traffic passing through network interfaces. As soon as it detects malicious activity, it sends an alarm message to a pre-configured monitoring system that can prevent further attacks by re-configuring network devices such as security appliances or traffic controllers. The IDS is often deployed at the boundary of the trusted network, sometimes even outside the firewall.
Intrusion detection systems can be categorized in several ways, e.g., by the intrusion detection approach used (anomaly-based or signature-based), by the type of system protected (host, network, hybrid), by the IDS architecture (centralized, distributed), by the source of data used for analysis (network packages, system analysis), by the level of service provided after attack detection (active, passive), and by the timing of analysis (continuous, time interval) [1].
The results being reported in this paper were obtained in the course of an investigation focusing on anomaly-based intrusion detection systems (also called Behavior-based IDSs – BIDSs). These systems operate in two modes (learning and detection). In the learning mode, the system is fed with sensor data that contain typical (normal) network and malicious (attack) data. The classification unit is trained and tested based on the labels associated with the data records. In detection mode, the fully trained classification module aims to determine whether the current activity is harmful to the system or not. The anomaly-based approach has the advantage of being able to adapt quickly and dynamically to unknown attack types. BIDSs can be classified into three main categories based on the way they process data, namely statistical-based, knowledge-based, and computational intelligence-based [2].
Ensemble Feature Selection (EFS) is a technique that exploits the strengths of multiple feature selection algorithms to improve the identification of significant features in a dataset. The benefits of ensemble feature selection include increased classification accuracy, reduced overfitting and increased stability of the selected features. This approach can be particularly beneficial in machine learning-driven applications, such as intrusion detection systems, where the diversity of features can affect the accuracy and learning time of the model. By combining the benefits of different feature selection algorithms, joint feature selection can facilitate the identification of the features that are most relevant to a given task, leading to more efficient and effective data analysis. However, the use of EFS also has drawbacks. Running all models requires significant computational resources and finding the right balance between model accuracy and computation time can be challenging
The classification module is the most important component of an IDS. Its efficiency and speed are affected to a great extent by the right selection of the features being monitored and used for the classification. The main focus of the research reported in this paper was on determining these features in the case of several network datasets containing normal data as well as data related to different attack types. For each attack type, the rank of each feature was determined based on the average score obtained from the results of the application of several feature selection methods. Next, different classification methods were used to evaluate a series of rank threshold values to determine the optimal threshold and feature set for each attack type.
The rest of the paper is organized as follows. Section 2 contains a literature review. Section 3 presents the used datasets and the preprocessing steps. The applied feature selection methods are described in Section 4. Section 5 describes the classification algorithms used in the course of the evaluation while the results are discussed in Section 6. The conclusions are drawn in Section 7.
Related works
Danroujing et al. [4] investigated the rumors spreading on social media on the subject of COVID-19. Their objective was to develop an epidemic rumor detection model based on meta-learning training and FSL. The proposed CNFRD model can effectively improve the rumor detection. The accuracy of their model is higher by 7.1% to 23.7% than the accuracy of the three existing classical deep learning models (SVM-TS, GRU, CNN), proving its effectiveness.
Yang Lyu et al. [5] provided an overview of several feature selection methods (PCC, Chi2, IG, MI, MRMR, FCBF, MMI, MIFS, MMIFES, CFS, ECOFS) for five data sets (KDDcup’99, NSL-KDD, ISCX, CIC-IDS2017, and MQTT-IoT-IDS2020).
Venkatesan [6] used Decision Tree, SVM and Random Forest methods, and ANOVA for feature selection for NSL-KDD dataset. The best accuracy (0.87-DoS, 0.86-Probe, 0.76-R2L and 0.98-U2R) was achieved with Random Forest.
Ankit and Ritika applied the DNN methods for the different datasets (NSL-KDD, UNSW-NB-15, and CICIDS-2017). The proposed approach achieved better performance compared to existing feature selection techniques for all the three intrusion detection datasets with reduced execution time 99.84% accuracy for NSL-KDD 89.03% accuracy for UNSW-NB-15 and 99.80% accuracy for CICIDS-2017 [7].
Farhan et al. used the CNN-LSTM, CNN-RNN, CNN-GRU methods for the UNSW-NB15, CIC-IDS2017, and NSL-KDD datasets. Their recommended methods outperformed the baseline methods having 99% precision, 100% recall, 99% f1-score, and 99.21% accuracy [8].
The sample data based development possibilities of IDS classification modules have been intensively investigated in the last decade. Kurniabudi et al. [9] used Information Gain (IG) method to rank and cluster features of the CICIDS-2017 dataset and then applied Random Forest (RF), Bayes Net (BN), Random Tree (RT), Naive Bayes (NB) and J48 classification algorithms to select the features, which yielded good classification results.
Rahman et al. [10] performed AWID dataset analysis using Support Vector Machine (SVM) and C4.5 as feature selection methods using artificial neural networks (ANN) based classification achieving 99.95% accuracy.
Javadpour et al. [11] used Pearson Linear Correlation and IG to select the features of the KDD99 dataset and CART, ANN, Decision Tree, and Random Forest (RF) algorithms for classification. They obtained the best results (99.98% accuracy) using the neural network method.
Taher et al. (2019) used correlation and Chi-square-based techniques as feature selection methods for the NSL-KDD dataset, followed by ANN and SVM classification algorithms achieving 94.02% recognition rate [12].
Kocher et al. used the Chi-square approach for dimensionality reduction on the UNSW-NB15 dataset followed by k-Nearest Neighbors (KNN), Stochastic Gradient Descent (SGD), Random Forest, Logistic Regression (LR) and Naive Bayes (NB) algorithms for classification, and resulting in a classifier accuracy of 99.64% [13].
Alkasassbeh [14] used BayesNet, MLP, and SVM machine learning methods, and IG, ReliefF (RF), and Genetic Search (GS) for feature selection. The best accuracy (99.9%) was achieved with BayesNet and GS.
Thaseen et al. used the Chi-square approach to select features of the NSL KDD dataset and did the classification with an SVM classifier. The proposed model resulted in a high detection rate and a low false alarm rate [15].
Awotunde et al. compared NSL-KDD and UNSW-NB15 datasets using hybrid rule-based feature selection and the DFFNN deep learning algorithm, with a recognition rate of 99.0% for NSL-KDD and 98.9% for UNSW-NB15 [16].
Sasan et al. applied the J48 and Classification & regression Trees (CART) methods for the NSL-KDD dataset using 29 features and achieved 88.23% accuracy [17]. However, the article does not describe how the 29 features were selected. Biswas presented a comparison of feature selection methods (CFS, IGR, PCA) and classifier algorithms (NB, SVM, DT, NN, k-NN) on the NSL-KDD dataset, which shows that the k-NN classifier performs better than the others and among the feature selection methods, IGR feature selection method is better [18].
Shaukat et al. investigated the CICIDS-2017 dataset using CFS and Naive Bayes feature selection methods with MLP and IBK algorithms, which showed that IBK is more accurate than MLP [19]. Malhotra et al. used Naive Bayes, Bayes Net, Logistic, Random Tree, Random Forest, J48, Bagging, OneR, PART, and ZeroR classifiers for the analysis of the NSL-KDD dataset, out of which Random Forest, Bagging, PART, and J48 were the best four in terms of model construction time. However, Random Tree achieved good accuracy in a short time without using feature selection and dimension reduction methods [20].
Krishnaveni et al. used IG, Chi-square, Gain Ratio, Symmetric Uncertainty, and Relief methods for feature selection for Real-Time Honeypot, NSL-KDD, and Kyoto datasets, and also used SVM, Naive Bayes, Logistic Regression, and Decision Tree classification algorithms [21].
Kumar et al. used CFS, IGF, and GR methods for the feature selection in the case of the NSL-KDD dataset and applied Naive Bayes, J48, and RepTree algorithms for classification. The feature subset identified by GR and Ranker improved the proposed Naive Bayes classification [22].
Pattawaro and Polprasert utilized a feature selection method based on attribute ratio (AR) for the NSL-KDD dataset combined with k-Means clustering and XGBoost classification. The proposed model achieved an accuracy of 84.41% [23]. Tohari et al. worked with k-Nearest Neighbor (k-NN), SVM, and Naive Bayes classifiers on the KDD Cup99, Kyoto 2006, and UNSW-NB15 datasets, where the best performance is achieved by SVM with 99.9291% accuracy and 0% false positive rate [24].
Summary of related works
Summary of related works
The classification module is the core module of an IDS. Usually, it is developed using one or more sample datasets and applying statistical or machine learning techniques. These datasets contain an immense amount of data describing normal (benign) and malicious traffic. The raw data obtained from the sensors usually have to undergo several preprocessing steps until it can be used for the training of the classification module. These steps can be divided into three main phases: data cleaning, data transformation, and data reduction. In the following subsections, after a short introduction of the available and used datasets the preprocessing applied in course of this investigation is presented in detail.
Datasets
The first sample dataset used for IDS training purposes was the famous KDD’99 [25], which has served later as a starting point for the development of several IDS solutions. It contains information about simulated traffic corresponding to normal activities and several attack types (DOS, guesspassword, buffer overflow, remote FTP, synflood, Nmap, rootkit). Subsequently, some other datasets have been also created containing samples of new attack types as well as some additional features. The most relevant datasets are presented in Table 2. The second column presents the attack types covered by the given dataset.
IDS datasets
IDS datasets
The dataset used in course of the research reported in this paper is the CSE-CIC-IDS2018 on AWS [26] that was created by the Canadian Institute for Cybersecurity lab. This dataset was chosen because it is one of the most recent ones and meets all the criteria (e.g. total traffic, many attacks, labeling) required for the research. The dataset includes seven different attack types, i.e., Intrusion, Brute Force, Heartbleed, Botnet, DoS, DDoS, web attacks, and network infiltration. The infrastructure used for the simulation of the attacks consisted of 50 machines while the victim organization consisted of 5 departments, 420 machines, and 30 servers. The dataset contains a record of the network traffic and system logs of each machine and 80 attributes extracted from the recorded traffic using CICFlowMeter-V3 [36] (see Table 3).
Complete feature list of the CSE-CIC-IDS2018 on AWS dataset
The dataset actually consists of several files. The files selected for investigation and the attack types covered by them are presented in Table 4. The preprocessing started with merging these files. The three stages of the preprocessing workflow are presented in the next three subsections.
Selected datasets
In order to create a proper dataset to train and test the model one has to preprocess the raw data. The preprocessing workflow starts with data cleaning, which usually includes deleting rows (records) containing invalid or missing data, deleting one-valued columns (e.g. columns where all values are zero), as well as deleting features (columns) that are a-priory known to be irrelevant regarding the classification. The main steps are illustrated in Fig. 1. This could already achieve some dimensionality reduction, which can provide various advantages that will be discussed later.
Dataset preprocessing workflow.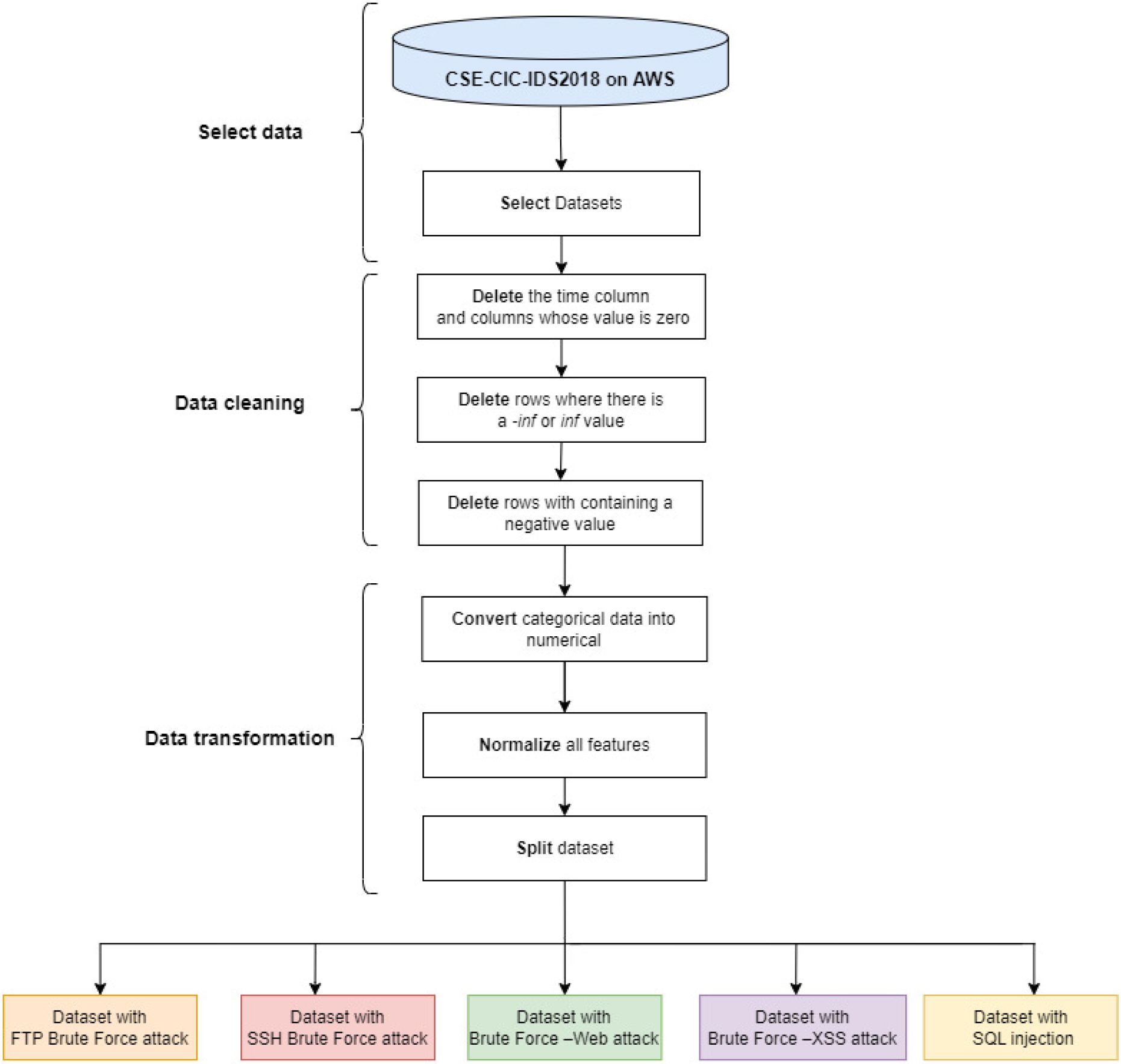
For the current analysis, the time parameter is not needed, nor are the columns where all values are zero since they do not influence the output, i.e. the value of the last column. The data cleaning step resulted in 69 remaining columns after deleting 11 columns out of the original 80 ones. The next step was to delete rows containing invalid values. Therefore, first, the rows with the values inf and
In course of this research, the data transformation phase comprised three operations, i.e. the transformation of categorical data into numerical, normalization, and splitting of the dataset. To perform further calculations, all non-numerical elements of the dataset were converted into numbers. It was carried out in the case of each categorical column by assigning a number to each category. For example, each occurrence of the string “FTP-BruteForce” was replaced by the value 1. The order of the values was determined arbitrarily not taking into consideration any conceptual distance metrics mainly because later on the dataset was split into subsets containing only data corresponding to one attack type and normal traffic.
Data normalization is a common practice in machine learning, which consists of converting numeric columns to a common scale. In machine learning, some feature values are several times greater than others. Thus the features with higher values could dominate the learning process. However, it does not mean that these variables are more important in predicting the model output. Data normalization converts multiple scaled data to the same scale. After normalization, all variables have similar scale-related effects on the model, which improves the stability and performance of the learning algorithm. There are several types of normalization techniques. The simplest and most used type is the min-max scaling Eq. (1), which rescales a feature into the fixed range [0,1] by subtracting the minimum value of the feature (
As a final step in the preprocessing, the selected datasets were split so that each resulting file contained only records corresponding to one attack type as well as records describing normal traffic. This operation resulted in five data files (see Fig. 1). Some of their features are presented in Table 5.
Datasets generated during preprocessing
The data reduction phase focuses on feature selection and dimensionality reduction, which can provide several advantages. One of the most important benefits is that many data mining algorithms work better when the number of dimensions – the number of attributes (columns) in the data – is smaller. This is partly because dimensionality reduction eliminates irrelevant attributes and reduces noise. Another advantage is that it can lead to a more comprehensible model because there will be fewer features in it. In addition, the reduced amount of data requires less storage space and less time for its processing.
There are many software tools that can be used to preprocess and analyze large datasets (e.g. Matlab, SPSS, Orange, Python). In the course of this research, we opted for the usage of the Python programming language because it is free of charge and its modules and libraries can produce fast and efficient results. The applied methods and the obtained results are presented in the next section.
Feature selection
Feature selection focuses on finding the most relevant attributes, which can be used to carry out an effective classification or prediction [37, 38, 39]. It contributes to the reduction of the dimensionality of the problem and so to the decrease of the resource requirements (storage, computation) as well as it can improve the performance of machine learning algorithms [40], i.e. faster training reduced over-fitting, and sometimes better prediction power. Although this approach may seem to lead to loss of information, this is not the case when redundant or irrelevant information is present. Redundant features are copies of most or all of the information found in one or more other attributes or they can be obtained as a combination of other features.
Irrelevant attributes contain almost no information that is useful for the data mining task to be performed. Redundant and irrelevant features can reduce the accuracy of the classification and the quality of the clusters discovered. While some irrelevant and redundant attributes can be removed immediately by common sense or professional knowledge, the selection of the best subset of at-tributes often requires a systematic approach.
The ideal approach to feature selection is trying all possible subsets of features as input to the data mining algorithm used and then selecting the subset that produced the best results. However, this technique would require an enormous amount of time and computational power. Therefore, several other methods have been developed for this purpose primarily based on statistical assumptions. There are three basic approaches to feature selection.
Wrapper methods: the feature selection algorithm uses the learning method as a subroutine with the computational burden of invoking the learning algorithm to evaluate each subset of features. It finds the best feature set for a given type of machine learning algorithm. Embedded methods: the machine learning algorithm decides what attributes to use and what features to ignore. Filter methods: the features are selected before the data mining algorithm is run, using a method that is independent of the data mining task.
Strengths and weaknesses of FS techniques
Strengths and weaknesses of FS techniques
All the feature selection methods presented in the next subsections and used in course of this investigation belong to the group of filter methods. Their advantage is that their time complexity is the lowest among the three groups, and usually, after their application, the machine learning algorithm is less prone to over-fitting.
When performing feature selection for machine learning tasks, the goal is to identify the most relevant features that contribute the most information to the target variable. Features with high mutual information are those that are closely related to the target variable and contain valuable information for making predictions. While mutual information (MI) is a valuable metric for feature selection and has several advantages, it also has some limitations that one should be aware of.
Assumption of Independence: Mutual information assumes that the relationship between variables is purely probabilistic and does not consider the underlying causal structure. Bias towards Variable Complexity: MI can favor variables with high complexity, even if that complexity doesn’t directly contribute to prediction accuracy. Variables that have more distinct values or categories might have higher MI values, but those values might not necessarily be relevant for the target prediction. Sensitivity to Variable Discretization: The calculation of MI can be sensitive to how you discretize continuous variables. Different discretization schemes can lead to different MI values, impacting the feature selection process. Limited to Bivariate Relationships: MI only captures the relationship between two variables at a time (bivariate relationships). It doesn’t account for interactions or dependencies involving more than two variables. Doesn’t Capture Non-Linear Relationships Well: While MI can capture both linear and non-linear relationships to some extent, it might not be able to fully capture intricate non-linear dependencies between variables. Ignores Irrelevant Information: MI considers all information in a feature equally, even if some of that information is irrelevant or redundant for the target prediction. This can lead to the inclusion of redundant features. Sensitive to Sample Size: The effectiveness of MI can be affected by the size of your dataset. In cases of small datasets, MI values might not be reliable indicators of feature relevance. Domain Knowledge is Needed: Interpretation of MI values requires some domain knowledge. High MI values don’t necessarily guarantee that the selected features will be meaningful or actionable. Bias in Class Imbalanced Data: In cases where the target classes are imbalanced, MI might be biased towards features that are correlated with the majority class, potentially ignoring features that are relevant for the minority class. Computational Complexity: Calculating mutual information for large datasets with many features can be computationally intensive.
We tried to combine the advantages of the different feature selection methods by creating an ensemble method that employs feature ranking techniques that can address the problem of redundancy ( Symmetric Uncertainty and ANOVA).
where
where
IG is a symmetrical measure. The method provides an orderly classification of all the features, and then a threshold is required to select a certain number of them according to the order obtained. A weakness of the IG criterion is that it is biased in favor of features with more values even when they are not more informative [41].
The information gain method prefers to select attributes having a large number of values, which led to the development of the feature selection method gain ratio (GR) which is a modification of the information gain aiming the decrease its bias. Originally developed for decision trees GR takes the number and size of the branches into account when choosing an attribute. It improves the evaluation given by information gain by taking into account the number of splits in the feature, i.e., how equally they are distributed [42]. GR reflects the relevance of each feature the higher its value is the higher the influence of the feature is. Gain ratio is calculated by Eq. (5)
where
The Relief method calculates a weight value for each feature (
where
The shortcoming of Relief is that it does not identify redundant features, and it can be used only in the case of binary classification problems.
Symmetric uncertainty (SU) can be used to calculate the rank of features for feature selection by calculating the relevance between the feature and the class label. A feature with a high SU value gets high importance [45]. SU is calculated by normalizing the double value of IG to the sum of the entropies of the two variables.
where
The Chi-squared test is a statistical hypothesis test that measures divergence from the expected distribution if one assumes that the feature occurrence is actually independent of the class value [47]. The higher the value of chi-squared, the more relevant the feature with respect to the class is. Its calculation is based on the Eq. (10) [48].
where
Analysis of Variance (ANOVA) is a statistical analysis technique used to compare the means of multiple groups to determine if there is a significant difference between them. Similar to the Chi-squared approach a discretization is necessary before its usage [49]. The key idea of ANOVA is to compare the total variance of the data to the variation within the groups and the variation between the groups. The within-group sum of squares (SSW) Eq. (11) measures the variation within the groups. It is defined as
where
The Sum of Squares between groups (SSB) Eq. (12) measures the variation between the means of the groups. It is defined as
where
The total sum of squares (SST) Eq. (13) is
The null hypothesis of ANOVA is that all groups have the same mean, i.e., the values of the investigated feature do not have effect on the final class. The alternative hypothesis is that at least one group has a different mean. The null hypothesis is tested by the help of the F-ratio, which is the ratio of SSB to SSW Eq. (14). An F-ratio higher than a threshold value (called critical F-value) indicates that there is a significant difference between the means of the groups, and so the null hypothesis can be rejected.
The critical F-value is that value of the F-distribution, which is defined by the degrees of freedom for the numerator (
Individual feature selection methods often express the importance of examined features at varying scales. Consequently, the initial step in an ensemble method that combines these scores is to standardize the values using the Eq. (15).
where
where
Classification methods are used to predict the class of an object instance based on a feature vector. Machine learning-based classification algorithms build models that can learn from labeled datasets and use them to predict the class of new, unseen data points. In this investigation, we used five different classification algorithms representing four main classification groups. These groups are linear models, probabilistic models, tree-based models, and kernel-based models.
Linear models are represented by the Logistic Regression method, which models the probability of a binary outcome using a sigmoid function.
Probabilistic models are represented by the Naive Bayes model, which assumes that the features are independent given the class and uses Bayes’ theorem to compute the posterior probabilities of each class.
Tree-based models are represented by two methods: the Decision Tree method, a non-parametric model that recursively partitions the feature space into a tree structure, and the Random Forest method, an ensemble model that uses multiple decision trees and aggregates their predictions to improve performance.
Kernel-based models are represented by the Support Vector Machine (SVM) method, which maps the input data into a high-dimensional feature space and finds a hyperplane that maximally separates the classes.
The following subsections provide a brief description of the classification algorithms mentioned above.
Logistic regression
Logistic Regression (LR) is a linear classification method that estimates the probability of a certain instance belonging to a class (e.g. attack). LR belongs to the family of linear methods and is an alternative to discriminant analysis. Its application prerequisites are less strict than those of discriminant analysis [50]. The key idea of Logistic Regression is to calculate a linear combination (see Eq. (17)) of the feature values
To determine the probability of belonging to the attack class (class 1) Logistic Regression applies a sigmoid function to
Finally, the classifier decides the final class of the observation by comparing the resulting probability value
The threshold value
The Naive Bayes classification method is based on Bayes’ theorem of conditional probability. It determines the predicted class of an
The Naive Bayes classification method is based on Bayes’ theorem of conditional probability. It predicts the class of an observation
where
In the case of categorical features
where
Support Vector Machine (SVM) [51] is a statistically based supervised classification technique that can be used to efficiently handle high-dimensional data. It creates a multi-dimensional hyperplane that separates the two classes in the case of binary classification problems. Multiclass problems are reduced to multiple binary classification problems.
If no simple linear separation can be carried out it transforms the data by using so-called kernel functions that calculate the hyperplane in a higher dimension. The nonlinearity of the hyperplane can also be tuned with the help of the regularization and the gamma parameters. The value of the regularization parameter describes how much one wants to avoid misclassification in the case of training instances. A high value could result in a more complex hyperplane with a small amount of wrongly classified data points if any.
In the case of high gamma values, only training instances close to the hyperplane will be considered in the course of its definition.
Decision tree
Decision trees offer an easy-to-interpret and visualize tool for classification. They make the decision based on rules inferred from the feature values of the training sample. Each leaf of the tree corresponds to a class label. At each node, only one feature is taken into consideration and no root-to-leaf path contains twice the same feature. A Classification tree may also provide a confidence measure regarding the quality of the classification. The tree is built up from the training sample in a recursive manner [52]. It is an iterative process whereby data is partitioned into partitions and then further partitioned on each branch. The features used at different nodes are selected using statistical methods like Information Gain or Gini Index. If all features are already used and the remaining sample contains instances belonging to more than one class a leaf is created and its class will be decided using a majority vote.
Random forest
The Random Forest (RF) method [53] was developed to overcome a shortcoming of Decision Trees, i.e., having the tendency to overfit the sample data. RF mitigates this problem by using a statistical technique called bootstrapping, which generates multiple models and combines their results to make a final decision. The main idea behind RF is that by aggregating the predictions of multiple classifiers, the impact of individual errors can be minimized.
In course of Bootstrapping several smaller samples are drawn from the training dataset randomly with replacement. Each sample is used to train a separate classifier. Thus when classifying a new observation its final class prediction is made by aggregating the results given by the individual models. Usually, it is done by applying a majority voting solution.
Experimental results
All five datasets contained a very large number of instances (see Table 5). Therefore when creating the training and test samples only a part of the original data was used. The steps of the training-test sample construction are presented in Fig. 2.
Creation of training and testing datasets.
Both in the case of the FTP and SSH Brute Force attacks training samples contained 20% of the original instances. We applied stratified sampling to ensure that each class (attack and benign traffic) is represented in the sample. Thus the resulting collection of records contained 20% of the attack rows and 20% of the rows describing benign traffic. The sampling was carried out without replacement. The test samples were created in a similar way by choosing records from the remaining datasets so that the resulting collection of data points represented 10% of the original ones. The resulting record numbers are shown in Tables 7 and 8, respectively.
In the case of the Brute Force Web, Brute Force XSS, and SQL Injection attack types the selection process was slightly different owing to the fact that the number of records describing malicious traffic was very small. Therefore in each case, the collection of attack rows was split into two parts, i.e., 70% was used for training and the remaining 30% for test purposes. Next, the training samples were created by adding 20% of the data points belonging to the benign traffic. Finally, the test samples were compiled by adding 10% of the benign traffic record to the attack rows allocated for test purposes. The resulting record numbers are shown in Tables 7 and 8, respectively.
Training datasets
Test datasets
The six feature selection methods presented in the previous section were applied for all five datasets using 30 university lab computers as well as the ELKH cloud services [54]. The feature selection workflow is presented in Fig. 3. All the necessary program elements were implemented in Python [55][56]. Although several tasks were performed in parallel the whole process took more than two months.
In the case of each dataset and each method, the feature score values obtained at the end of the feature selection process were normalized. Next, the final feature score was calculated in the case of each dataset separately as the mean of the normalized scores.
We then took the normalised value of the final characteristic scores for each dataset and calculated the final value using the EFS method with the arithmetic mean (see Eq. 16) of the 6 values for each characteristic. The detailed results can be found in the Appendix in Tables A1–A5.
Finally, five feature ranking threshold values were set starting from 0.35 and increasing by a step of 0.5. In the case of each value, we selected the features whose score was higher than the threshold. The results are presented in Table 9. In the case of each attack type a separate list of relevant features was identified. Each feature is represented by its ordinal value. Each row of the table contains those features whose score was greater or equal to the threshold given in the first cell. Starting from the second column each column represents an attack type.
Having the selected feature groups we continued our investigation by applying different classification methods that will be presented in the following section.
Feature selection based on threshold values
Feature selection based on threshold values
Feature selection workflow.
The training and testing of the five classifiers was carried out in Orange 3.34, which is an open-source data visualization, machine learning, and data mining toolkit. It offers a visual programming front-end for interactive data visualization and exploratory, quick qualitative data analysis. Its components are called widgets and they range from simple data visualization, subset selection, and preprocessing to empirical evaluation of learning algorithms and predictive modeling. Visual programming is implemented through an interface in which workflows are created by linking predefined or user-designed widgets, while advanced users can use Orange as a Python library for data manipulation and widget alteration. Orange uses common Python open-source libraries for scientific computing, such as numpy, scipy, and scikit-learn, while its graphical user interface operates within the cross-platform Qt framework.
The classifier training and testing workflow used in course of the investigation is shown in Fig. 4. It was carried out separately for each attack type and for each relevant feature collection. For example, in the case of the FTP Brute Force attack and the 0.40 ranking threshold value three features (44, 56, and 59) were supposed to play a significant role. Thus in total 21 workflow executions were necessary and 105 classifiers were trained.
Classifier training and testing workflow.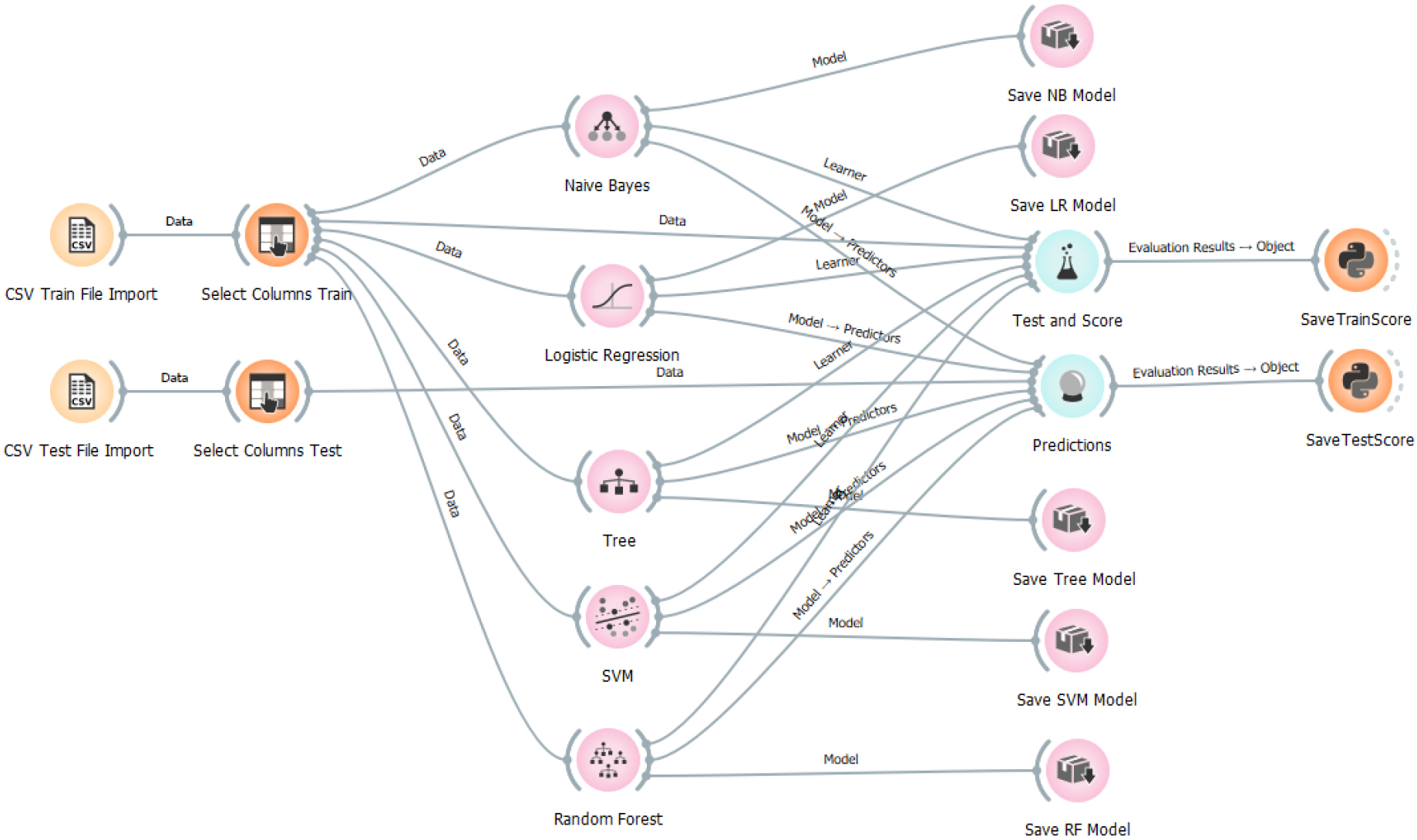
All the classifiers were evaluated against the training and test samples using four measures, i.e., accuracy, precision, recall, and F1. The goal of a binary classifier is to classify input data into one of two possible categories or classes. The goal of the training process is to produce a classifier able to do correct classification not only for the cases used for its training but also for new, different examples. Each example in the training dataset has a label (classification label) that indicates its class. The performance of the classification algorithms is evaluated based on the occurrence number of the four cases presented in Table 10.
Classification cases
The possible cases:
True Positive (TP): it occurs when an attack is categorized as attack. False Positive (FP): it occurs when the classifier categorizes benign traffic data as an attack. True Negative (TN): it occurs when the classifier categorizes correctly benign traffic as benign. False negative (FN): it occurs when the classifier incorrectly identifies an attack as benign traffic.
All classifiers were evaluated on the basis of train and test samples using four measures, i.e. Accuracy, Precision, Recall and F1, which can be calculated using the following equations.
The detailed results can be found in the Appendix in Tables A6–A11.
This section presents the evaluation of the classifiers. Their accuracy is visualized using 3D column charts. In case of each figure the horizontal axis (x) corresponds to the classifier algorithm types, the vertical axis (y) shows the achieved accuracy value, with a maximum value of 1 (best achievable accuracy), and the z axis shows the number of features used for the training of the classifier.
Accuracy values in case of the FTP attack and the training dataset.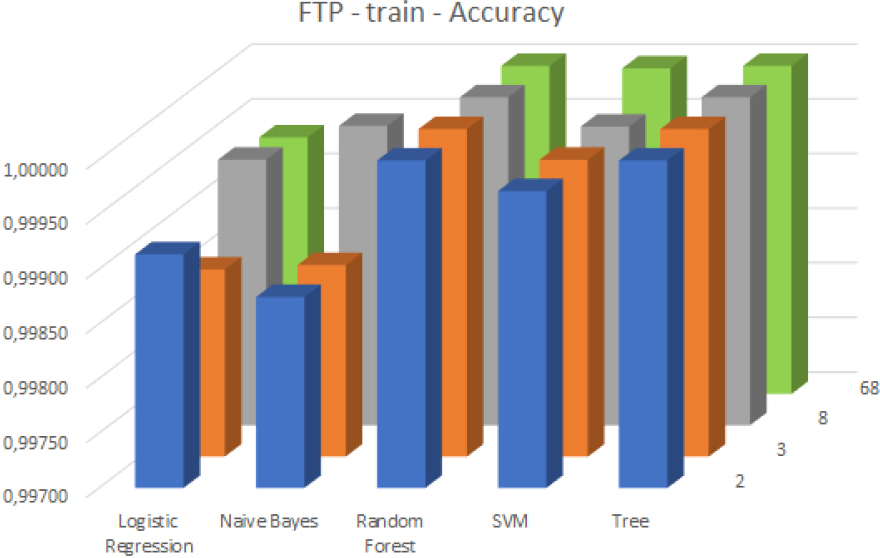
Accuracy values in case of the FTP attack and the test dataset.
Accuracy values in case of the SSH attack and the training dataset.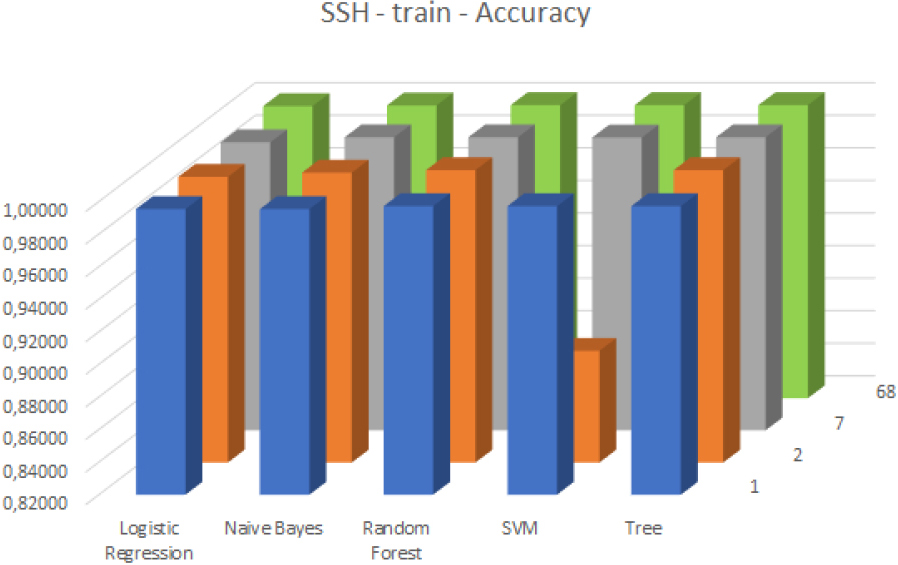
Accuracy values in case of the SSH attack and the test dataset.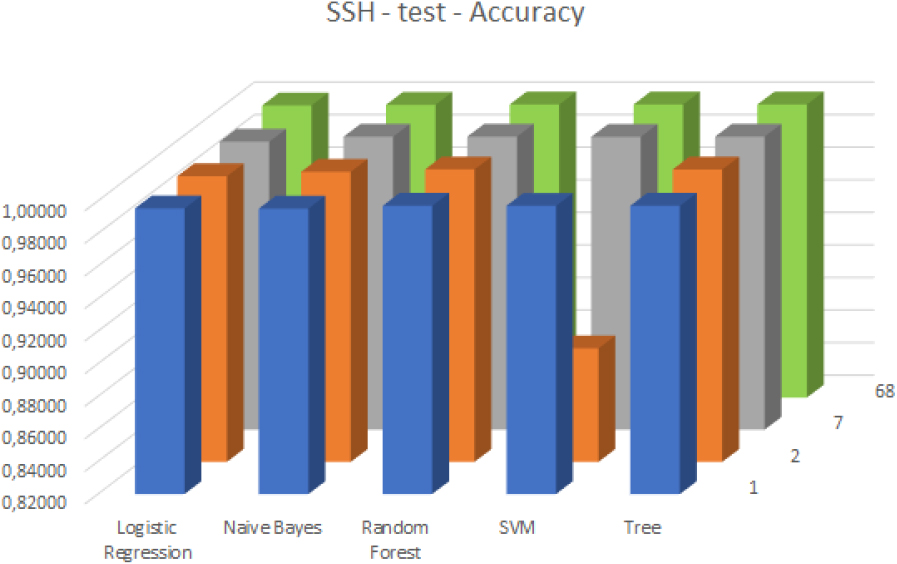
Accuracy values in case of the WEB attack and the training dataset.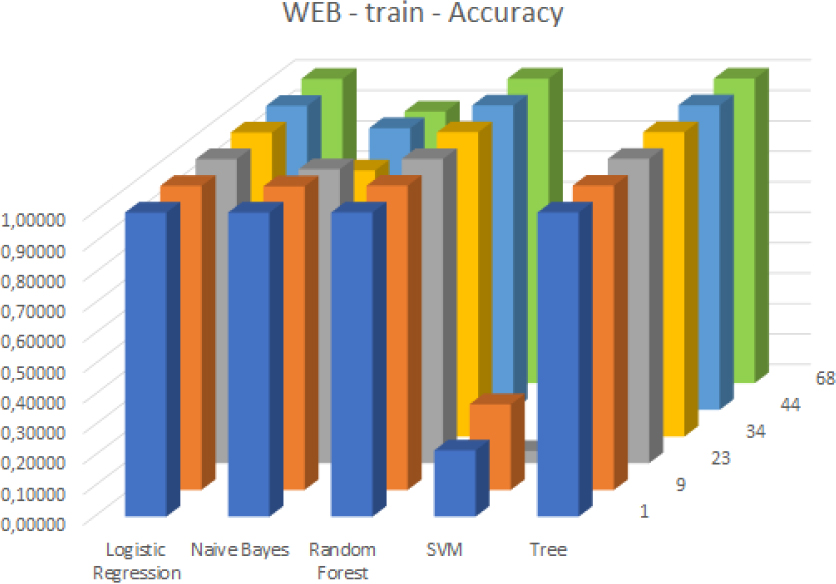
Accuracy values in case of the WEB attack and the test dataset.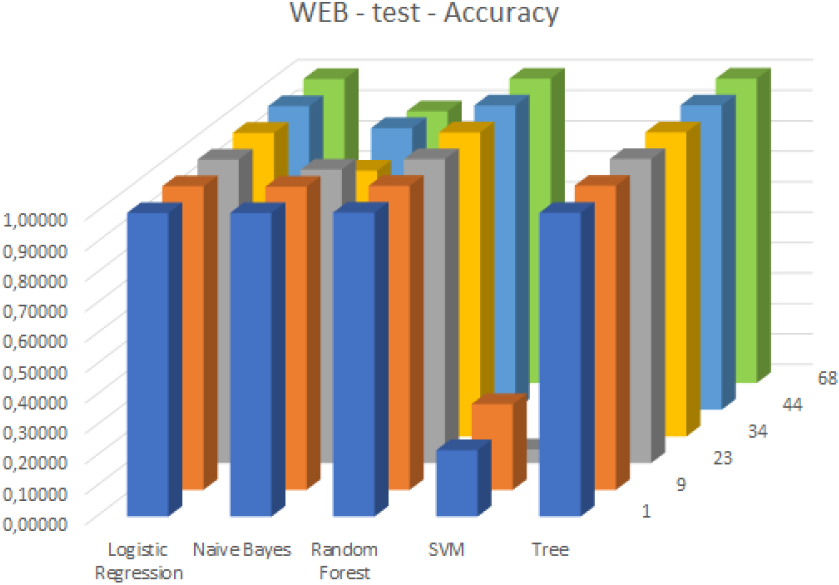
Accuracy values in case of the XSS attack and the training dataset.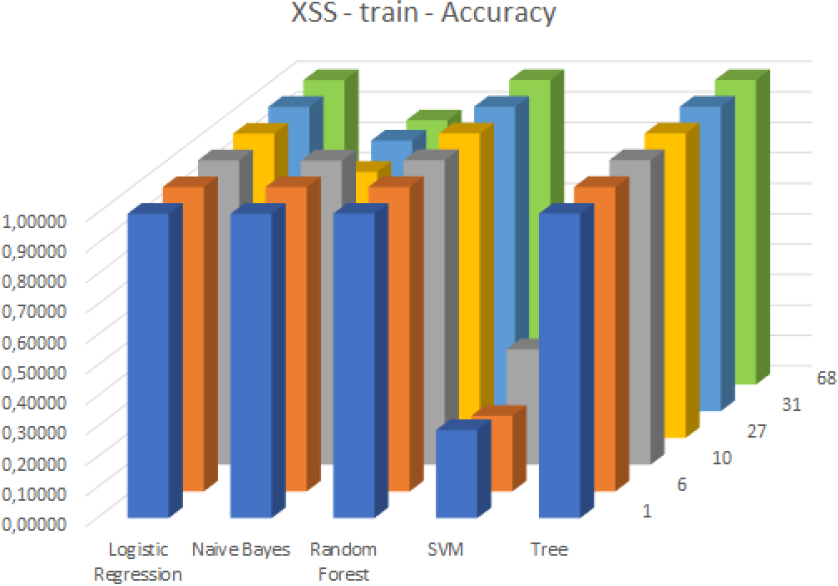
Accuracy values in case of the XSS attack and the test dataset.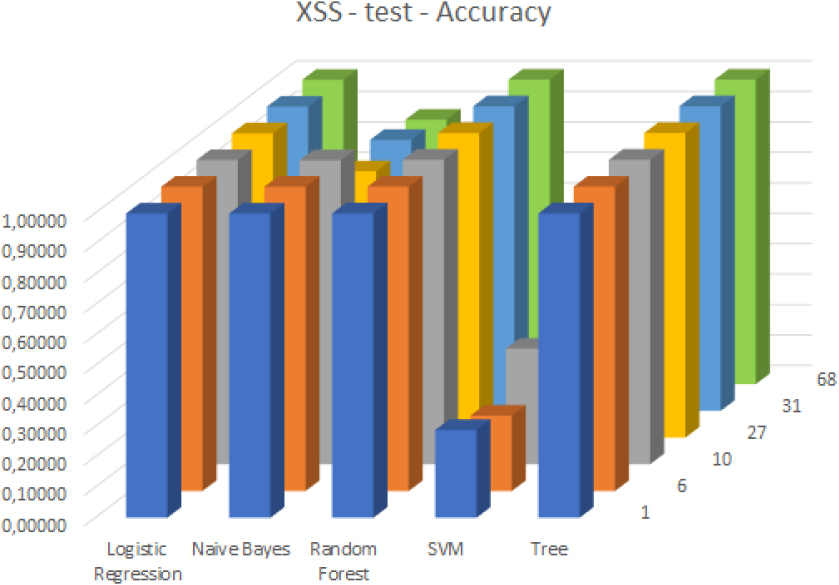
Accuracy values in case of the SQL attack and the training dataset.
Accuracy values in case of the SQL attack and the test dataset.
In the case of FTP attacks, each of the classifiers performed quite well having high accuracy values and the highest possible recall rates for almost all of the feature subset-classifier type pairs. Except for the case of the logistic regression-based classifier, the accuracy against the training dataset usually improved with increasing the number of selected features (see Fig. 5). However, when evaluating the classifiers with the test dataset a slight decay in accuracy performance could be measured in the case of Naive Bayes and Random Forest classifiers as well (see Fig. 6).
The classifiers also exhibited strong performance against SSH attacks, with high accuracy observed for all feature subset-classifier pairs. Increasing the number of selected features led to improved accuracy against the training dataset, except in the case of the SVM-based classifier (see Fig 7). When evaluating the classifiers against the test dataset revealed a very similar behavior (see Fig 8).
In the case of Web attacks, the SVM classifier provided a low accuracy rate compared to the others both in the case of the training (see Fig. 9) and test (see Fig. 10) datasets. However, Logistic regression, Random Forest, and Decision Tree based classifiers were able to successfully predict the nature of the traffic with a very high accuracy rate. Although the Naive Bayes model in the case of 23 and 34 selected features showed a declining performance its results were not too much fallen behind.
Among the classifiers tested for XSS attacks, the SVM classifier had a low accuracy rate for both the training dataset (see Fig.11) and test dataset (see Fig.12) in comparison to others. The Logistic Regression, Random Forest, and Decision Tree based classifiers performed exceptionally well with a very high accuracy rate. While the Naive Bayes model showed declining performance in the case of 27 and 31 selected features, its results were still competitive.
For SQL Injection attacks, four of the five classifier models demonstrated high accuracy rates against both the training dataset (see Fig. 13) and test dataset (see Fig. 14). The Naive Bayes model was the only exception, showing slightly declining performance when using 26 and 31 selected features, but still having accuracy values over 0.9.
The best-performing classifiers along with ranking threshold values and selected feature number as well as the evaluation results are highlighted in Table 11.
Best performing classifiers
In course of the investigation reported this paper, six feature evaluation techniques were performed on five datasets after completing the data cleaning and transformation steps. Each dataset comprised records that described two types of traffic cases: benign and attack, and featured 69 attributes. An average score was calculated after normalization and used to rank individual features. Next, six ranking thresholds were defined, which led to the selection of several relevant feature collections for each attack type. The number of included attributes varied widely, ranging from 1 (SSH) to 44 (Web).
Next, five classifier models were trained for each collection using the Orange software tool, and their performance was evaluated against the train and test datasets using four classification metrics. It was observed that, in some cases, accuracy improved slightly when increasing the number of features. However, excellent results were achieved in most cases, even with a low number of attributes. Table 11, which shows the best-performing classifiers for each attack type, clearly indicates that no general threshold can be set for the feature scores. The results suggest that tree-type classification algorithms represent the most appropriate solution for the investigated attack types when feature selection followed the presented workflow.
The methodology utilized in the current investigation can be applied to other scenarios involving high-dimensional data, such as clustering (e.g. [57, 58]), object identification [59], classification [60], indor localization [61], or technology optimization [62].
Examining network communication (including normal and attack cases) with the help of the ensemble feature selection method, actual data and information can be configured for the sensors of an IDS system for certain types of attacks with the help of the features included in the defined feature groups. From the network communication data with originally 80 characteristics, only the groups of the selected characteristics need to be taken into account in order to achieve a good classification result for an IDS to detect the appropriate attacks. There are IDS software that can be configured at a professional level, such as Suricata. The code provided to integrate machine learning features into Suricita consists of two parts: the Suricata source files and the new classification scripts with associated configuration files [63].
Further research will focus on the investigation of the suitability of different aggregation techniques (e.g. [64, 65]) that could replace the average score in feature relevance calculation. Furthermore the applicability of further computational intelligence methods.
Footnotes
Acknowledgments
On behalf of the project we are grateful for the possibility to use ELKH Cloud [![]() ]; (
]; (
This research was supported by 2020-1.1.2-PIACI-KFI-2020-00062 “Development of an industrial 4.0 modular industrial packaging machine with integrated data analysis and optimization based on artificial intelligence, error analysis”. The Hungarian Government supports the Project and is co-financed by the European Social Fund.
Author contributions
Conceptualisation, L.G. and Z.C. J.; formal analysis, L.G. and Z.C. J.; Funding acquisition, L.G. and Z.C. J.; investigation, L.G. and Z.C. J.; methodology, L.G. and Z.C. J.; Writing-review & editing, L.G. and Z.C. J.; supervision, L.G. and Z.C. J. All authors have read and agreed to the published version of the manuscript.