
Abstract
Effective identification of anomalous data from production time series in the oilfield affects future analysis and forecasting. Such time series is often characterized by irregular time intervals due to uneven manual sampling, and missing values caused by incomplete measurements. Therefore, the identification task becomes more challenging. In this paper, an Attention-Embedded Time-Aware Imputation Network (ATIN) with two sub-networks is proposed for this task. First, Time-Aware Imputation LSTM (TI-LSTM) is designed for modeling irregular time intervals and incomplete measurements. It decays the long-term memory component as the producing well conditions may be varied during the water cut stage. Second, Attention-Embedding LSTM (ATEM) is designed to improve the effectiveness of anomaly detection. It focuses on the correlation between the last and historical measurements in a given sequence. Comparison experiments with several state-of-the-art methods, including mTAN, GRU-D, T-LSTM, ATTAIN, and BRITS are conducted. Results show that the proposed ATIN performs better in accuracy,
Introduction
The petroleum industry generates a large amount of data such as seismic, core, and production data [1, 2]. The application of neural network methods in the petroleum industry has been widely explored [3, 4, 5, 6]. However, reality factors such as equipment quality, bad weather, and human activities can cause unreliability of data [7]. Therefore, an important task is to predict whether to adopt newly generated production data, especially fluid rate, and water cut, based on historical data from producing wells. Accurate predictions help oilfield management to schedule effective production measures [8].
This task is challenging because the oil well production data is an irregular multivariate time series (IMTS [9]) with many missing values and varying intervals. The production data of a producing well is shown in Fig. 1. The sampling of data by oilfield workers is irregular. For producing well data, there is a time gap of either two or three days between the first and second measurements. In addition, the data measured each time may be incomplete, and staff often only measure some of the characteristics. Uneven and incomplete measurement of data is the key challenge of this task.
Production data of a producing well. Three features of pump frequency, fluid rate, and water cut are shown. The three enlarged graphs framed by dashed lines show that the intervals between sampling points are heterogeneous. Furthermore, it should be noted that not all features were recorded at every time point.
Machine learning, particularly neural networks, has exhibited notable success in modeling oil production time series. Among these approaches, the artificial neural network (ANN) has been widely employed for successful oil production prediction [10, 11, 12, 3]. Nevertheless, a more effective strategy involves the utilization of recurrent neural networks (RNNs) to handle such data [13, 14]. Remarkably, [13] reported experimental results demonstrating the superior performance of the LSTM (Long Short-Term Memory) [15] over ANN. Furthermore, studies conducted by [16, 17] show that bidirectional GRUs exhibit superior performance compared to other unidirectional RNNs. However, it is worth noting that they all assume uniform sampling data without any missing values.
Recently, many deep learning methods focus on IMTS. One approach is using IMTS RNNs (RNNs for IMTS). GRU-D [18] inputs missing values by combining the mean and last observation and capturing irregular time-interval of features using a trainable decay mechanism. However, the imputation method of fixing missing values has limitations, which assumes that the data must tend to maintain past and mean values. T-LSTM [19] decays the short-term memory in the cell state of LSTM and retains the long-term memory, so that it is more prepared to capture the irregular time interval characteristics of a specific sequence, but it does not deal with missing values. Brits [20] simply regresses the hidden layer of RNNs to estimate the data at the next time point, completing the imputation without any specific assumptions. ATTAIN [21] simultaneously utilizes the decay function and attention mechanism to capture the time interval irregularity and global characteristics of sequence data. The decay function of FT-LSTM [22] superimposes three subfunctions representing convex, linear, and concave to increase its flexibility and generality. These RNNs perform well in modeling IMTS. While these methods do not address both irregular sampling and incomplete measurement problems.
Some approaches use attention mechanisms to model IMTS [23, 24, 25]. Like [26], most of these methods learn a time representation and then use the attention mechanism to model sequences. One noteworthy approach is mTAN [27] which only uses the time embedding. It takes irregularly sampled time points and the corresponding values as keys and values, and produces a fixed dimensional representation at the query time points. Building upon mTAN, UnTAN [28] further models the heteroskedasticity of the sequence based on mTAN. However, the production process of a producing well built on complex mechanics [14, 13] is non-repeatable. Using time embedding to get attention weights limits the expressiveness of the model. ATTAIN [21] and MCE [29] also use attention mechanisms. However, instead of encoding time, they put it into a time-aware mechanism as a more intuitive representation of the positional relationships in the sequence.
Apart from approaches based on IMTS RNNs and attention mechanisms, recent advancements have introduced methods grounded in neural ordinary differential equations (ODEs) [30] for establishing continuous dynamics relationships between hidden states of two observations. Nonetheless, the solution of an ODE is primarily determined by its initial conditions, lacking a mechanism to adapt the trajectory based on subsequent observations. GRU-ODE Bayes [31] and ODE-RNN [32] employ RNNs to update the hidden states of novel observations. On the other hand, NJ-ODE [33] assumes that the data is a continuous stochastic process and that the predictions approximate the conditional expectation given the currently available information. Drawing parallels to neural ODEs are neural controlled differential equations (CDEs) [34, 35]. Unlike neural ODEs, the vector field of neural CDEs relies on time-varying data, thereby enabling the system trajectory to be influenced by a sequence of observations. While neural ODEs are elegant network models, their reliance on numerical ODE solvers often results in considerably longer training times compared to RNNs [36].
In addition, Generative Adversarial Networks (GANs) [37, 38, 39, 40, 41] with IMTS RNNs as generators are also designed. However, GAN-structured networks have the problem of training difficulties [42]. Some models interpolate data by combining non-deep learning methods (e.g., Gaussian process, Kalman filter) and RNNs [9, 43]. They assume that the data satisfy a Gaussian process or a mutually independent Gaussian distribution.
In this paper, ATIN is proposed for anomalous production data detection. This model does not require any assumptions. The problems of irregular time intervals and incomplete measurement are addressed simultaneously. The downstream task of anomalous production data detection is also handled. It consists of two sub-networks:
TI-LSTM is a combination of our modified T-LSTM [19] with RITS-I [20]. It can perform both imputation and time-aware tasks. During production in the water cut stage, the formation physical properties are varied. Meanwhile, experts estimate the fluid rate and water cut based on historical production data from the last one to two weeks. Therefore, the idea behind TI-LSTM is to retain the short-term memory and decay the long-term memory. However, it is difficult for TI-LSTM to focus on the downstream task of detecting anomalous production data since it is mainly used for imputation. ATEM is used for this downstream task, and it has different forward and backward network structures. Its structure is referenced from ATTAIN [21]. It takes the hidden states of TI-LSTM as input so that a two-layer stacked RNN is formed. TI-LSTM is responsible for learning the representation of the points in the production sequence. ATEM is concerned with the correlation between the last point and the rest of the points in the sequence.
Comparative experiments with state-of-the-art methods, including mTAN, GRU-D, T-LSTM, ATTAIN, and BRITS are implemented using a realistic producing well dataset. The results show that ATIN is better to learn the distinguished representation from uneven producing well data with missing values.
The rest of the paper is organized as follows: Problem formulation and some necessary preliminaries are introduced in Section 2, the detailed implementation of our method is presented in Section 3, comparison of the experimental results with other typical methods is presented in Section 4, and the study is concluded in Section 5.
The problem formulation and some necessary preliminaries are presented in this section. Table 1 lists the main notations used in this paper.
Notations
Notations
The anomalous production data with missing values is a multivariate time series
where
In many cases, features are continuously missing. For the
The anomalous detection task is to predict the label of the current time point according to historical and current data. Suppose that the current label is related to at most
where
RNNs, such as LSTM [15] are powerful sequence models. In the standard LSTM cell unit, the cell state
where
In this section, ATIN, which consists of sub-networks is introduced. Figure 2 shows an overview. Section 3.1 introduces TI-LSTM, which works for the tasks of time-aware and imputation, i.e., stage 1. It performs regression based on the observations and learns to fill in the missing values. Section 3.2 introduces ATEM, which performs anomalous production data detection by focusing on the correlation between the last measurement and other measurements in the sequence, i.e., stage 2. Section 3.3 briefly describes two decay functions. Finally, Section 3.4 analyzes the execution process of ATIN.
Overview of the proposed ATIN. It is a multitasking model that operates in two stages. In the first stage, our TI-LSTM fills missing values in an irregular sequence 
In the subsequent discussion of this paper, the word “measurement” in petroleum engineering with “observation” is replaced to unify the expression and facilitate understanding.
TI-LSTM structure. It has four inputs: the observation 
Most existing RNN models implicitly require periodic sampling (i.e., a constant sampling interval) and complete data. However, oil field data does not meet these requirements. First, let
Figure 3 illustrates our TI-LSTM to cope with these difficulties. Specifically, it borrows the idea of T-LSTM [19] to incorporate the elapsed time information, and adopts the RITS-I of BRITS [20] for imputation. More detail about these two techniques are explained as follows.
T-LSTM divides the cell state
where
The application scenario of TI-LSTM is different from that of T-LSTM. The manual detection of anomalous data is usually performed by experts based on the production records of the previous one to two weeks. Due to the variability of the formation physical properties and the modification of production measures, the long-term production situation may be inapplicable to the estimation of current data. Meanwhile, Long-term information should not be completely ignored.
Therefore, for the cell states in TI-LSTM, long-term memory should be suppressed. Discounted long-term memory is calculated by
where
The imputation operation [20] is given by
Here the missing values of the observed data
where
In accordance with Eq. (4), By substituting
For the input sample
To prevent overfitting, the estimation error calculation does not incorporate the loss associated with the
Estimates of sequential data can be derived from both forward and backward directions. Consistency loss facilitates consistency between forward and backward derived estimates. This enhances the learning and improves the stability [39]. Meanwhile, the consistency loss can accelerate the convergence of training [20]. Our consistency loss is given by
where
The training objective of TI-LSTM is imputation rather than targeting downstream tasks. In addition, TI-LSTM will inevitably cause the attenuation of information, due to the vanishing gradient problem. Standard LSTM obtains memory from the most recent cell state, i.e.
Figure 4 shows the structure and process of forward ATEM. During the production of a producing well, anomalous data can be generated at any time. In a given sequence, other possible anomalies can help determine the anomaly at the last observation.
Forward ATEM, including ATEM structure and the forward process. 
Backward ATEM, including ATEM structure and the backward process. After reversing the sequence, 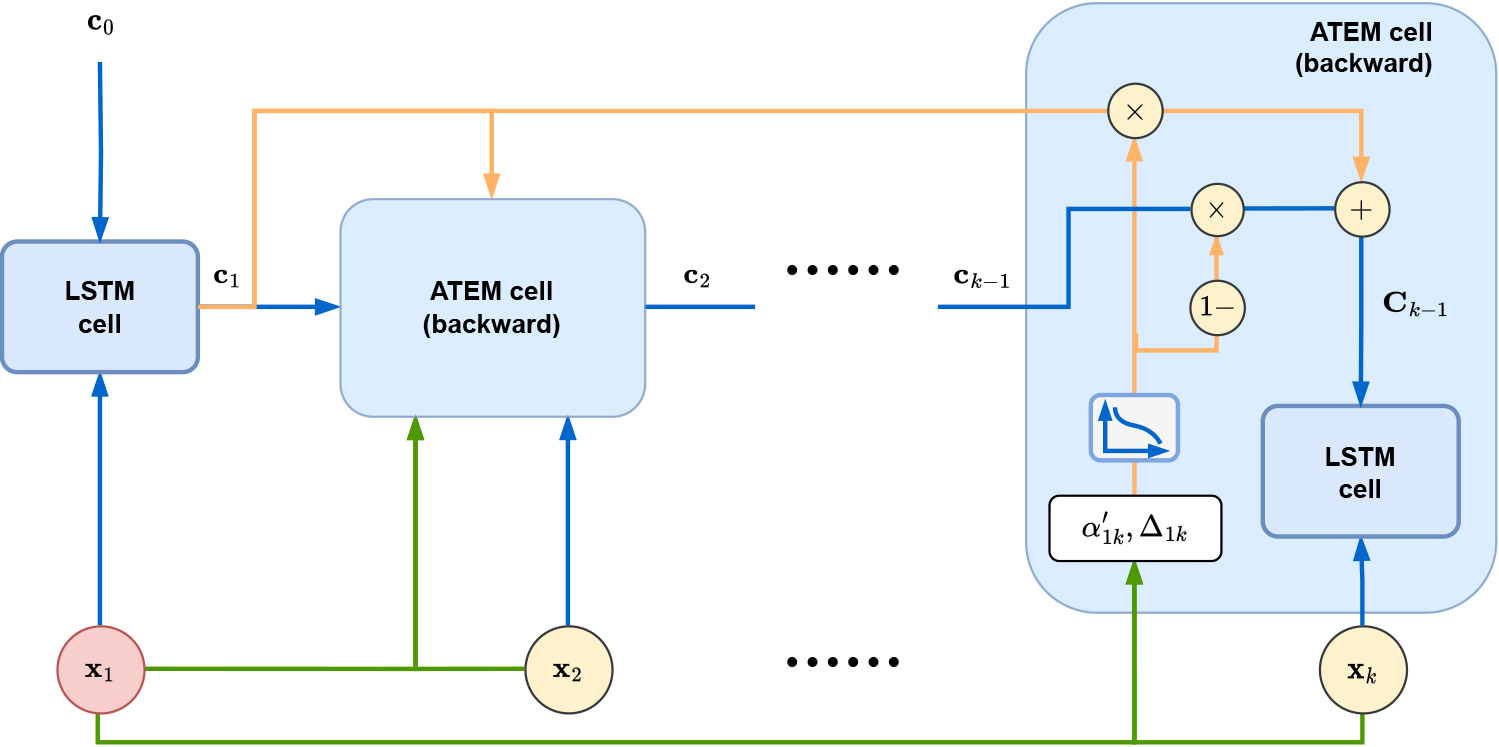
Here forward ATEM has an attention mechanism that can collect multiple previous memories. Inspired by ATTAIN [21], in a given sequence
where
Figure 5 illustrates our backward ATEM. In the backward process, the last observation to be detected is input to the standard LSTM first. Its information will be passed as key information in the standard LSTM. The cell state of it will be retained at each time step.
Reversing the sequence
where
Now we discuss how to make use of the results of forward ATEM depicted in Fig. 4 with backward ATEM depicted in Fig. 5. The last hidden states of the forward ATEM and backward ATEM are fed into a Multi-Layer Perception (MLP) to predict the probability that the last observation in the sequence is anomalous data, i.e.,
where
The number of samples in the positive and negative classes is unbalanced (positive: negative
where FL means the function of Focal Loss [44],
The range of time intervals can vary and may be very short minutes, seconds, or longer days. Several works propose different decay functions [45, 19]. In our task, the time interval between each observation is days. According to the guidelines of these works, the decay function for the cell state [19] in Eqs (7), (16) and (17) is
and the decay function for the hidden states [20] in Eq. (11) is
[b]
[1] Original data matrix
The overview of ATIN is presented in Fig. 2. Algorithm 3.3 summarizes the forward process of ATIN. TI-LSTM and ATEM form a network structure like stacked RNN. TI-LSTM performs preliminary computation of hidden states
Experiments
This section reports experimental results on a real production well dataset. The software and hardware environments are Pytorch and an NVIDIA GeForce RTX 3060 laptop.
Dataset
Our dataset includes production data from 35 production wells in an oil field in Iraq. Each producing well is characterized by multivariate time series with 26 features. Production data is collected from June 21, 2011, to March 14, 2022. Features are well type, nozzle size, pump frequency, fluid rate, water cut, wellhead pressure, casing pressure, back pressure, and a total of 26 features. The record of each day has a remark. Based on these remarks, only the records that have measured behaviors are extracted to prepare datasets with different sequence lengths. In total, 18,764 sequences of length
Datasets
Datasets
where TP is True Positive, TN is True Negative, FP is False Positive and FN is False Negative. Precision quantifies the proportion of correctly identified positive predictions among all instances classified as positive. Recall, also known as sensitivity, indicates the model’s effectiveness in detecting existing anomalies within the dataset.
FA-score is used to select the final appropriate threshold. It is given by
In Section 4.3, a particular explanation will be provided for utilizing the FA-score. The
The receiver operating characteristic (ROC) curve is a graphical representation illustrating the relationship between the true positive rate (y-axis) and the false positive rate (x-axis) across various decision thresholds. AUC, which stands for Area Under the Curve, quantifies the extent of the region beneath the ROC curve. For reference, a naive classifier corresponds to an AUC value of 0.5, indicating random performance. On the other hand, a perfect classifier achieves an AUC value of 1.0.
The computation of peak
Our baseline methods are the following.
Ablation experiments are also performed to show the performance gains achieved by our Time-Aware Mechanism and ATEM:
To validate the reliability of time perception, a comparative analysis is conducted between I-ATTAIN and TI-ATTAIN, as well as between I-ATEM and ATIN. The objective is to assess the effectiveness and accuracy of these respective models in capturing temporal information. The performance evaluation of I-ATTAIN against I-ATEM and TI-ATTAIN against ATIN provides critical insights into the robustness and viability of ATEM, the anomaly detection framework under investigation. FTI-ATTAIN is employed to validate the efficacy of forward and backward networks.
Experiments are conducted using datasets with sequence lengths of 16, 32, and 48, respectively. Table 3 shows scores of each baseline model and ATIN. The effectiveness of mTAN improves as the sequence grows. mTAN has good imputation and classification for data with correlation with time stamps. But it does not work well in anomalous production data detection. This shows that Multi-Time Attention Mechanism is inapplicable to production data anomaly detection. The non-time embedded model has better results. ATTAIN has the best performance in the baseline methods. This is due to its Temporal Convolutional Network-like structure and a special attention mechanism. GRU-D implicitly models missing values through a feature-level decay mechanism (decaying hidden state) and is better in terms of performance. T-LSTM does not have the same feature-level decay mechanism as GRU-D, but it captures the information of the observation interval. It is worth noting that BRITS is capable of interpolation, but the classification performance is not outstanding. The performance issue of BRITS is also explained in Section 3.2.
Performance (
standard deviation) of baselines and our approach
Performance (
Ablation study
Score curves. Subplots display the score curves of each baseline method and the proposed ATIN. The green curve is the ROC curve. 
In Table 4, the ablation experiments verify that the Time-Aware Mechanism and ATEM are effective. TI-ATTAIN outperforms I-ATTAIN for sequence lengths of 16 and 32, which shows that the time-aware mechanism has a gain effect. The same is true for I-ATEM and ATIN. However, the advantage of Time-Aware is not obvious when the sequence length is 48. From the perspectives of TI-ATTAIN and ATIN (as well as I-ATTAIN and I-ATEM), it becomes evident that ATEM exhibits improvements across metrics of FA-score, AUC, and peak
Figure 6 shows the score curves of each baseline method in the test set. If the binary classification threshold corresponding to peak
Since there may be continuous inconsistencies between the measured data and the expert judgment, the expert tends to trust the measured data at this time. Therefore, the model can be enhanced by using historical labels as input. The effect after adding historical labels as input for each model is shown in Appendix A.
Diverse irregular time series tasks may require the utilization of distinct decay functions. Additionally, cell states and hidden states could also demand diverse decay functions. The experimental exploration of several decay functions is detailed in Appendix B.
In this paper, ATIN is proposed for oil production data anomaly detection. This hypothesis-free network not only supports time-aware and imputation but also has a network structure specialized for anomaly data detection. To the best of our knowledge, the proposed ATIN is the first deep learning method for modeling irregular multivariate production time series in oil fields. TI-LSTM models irregular sampling as well as incomplete measurements simultaneously to take advantage of the information that is missing. ATEM has a backward network whose information accumulation improves anomaly detection for new measurements. Experiment results show that ATIN demonstrates more accurate results for anomalous production data detection than state-of-the-art methods.
To further improve the detection, there are still some topics that deserve further investigation.
Transfer learning. This work only trains the model for a general overview of producing wells in an oil field, but each well may have very different production conditions. Transfer learning can be performed on each well individually using the pre-trained ATIN. Graph neural networks. In a field, producing wells may be drilled into the same reservoir and they may be communicating. In such cases, graph neural networks can be employed to establish the relationship between these wells. TI-LSTM can be used as an encoder for the IMTS of each producing well. Sequence-Level attention mechanism. In ATEM, an attention mechanism is used for different observations in a given sequence. Further, external information can be used to aid in the detection process [47]. In the first stage, during the training of ATIN, important sequence samples are encoded and stored in the memory module. In the second stage, the attention mechanism is used to query the stored important sequences and evaluate the sequences to be classified. Combining injection wells. Oil wells are distinguished into producing wells and injection wells, and the production data of producing wells may be greatly influenced by injection wells in the water cut stage. However, they are not taken into account in this work.
In addition to anomaly detection, how the model interprets production data anomalies can offer valuable insights for manual diagnosis. The attention weights utilized in ATEM aid in identifying timestamps linked to anomalous production data, thereby enhancing the interpretability of the detection results. Recently, analyzing production data in petroleum reservoirs to estimate future production has become popular. TI-LSTM can be applied not only for the complementation of irregular multivariate production data but also for the prediction of future production. In the forecasting phase, its ability to infer all characteristics is limited to inferring only yield characteristics.
Footnotes
Acknowledgments
This work is supported by the Central Government Funds of Guiding Local Scientific and Technological Development (No. 2021ZYD0003) and the National Social Science Foundation of China under Grant (No. 22FZXB092).
Appendix
Detection with historical labels
Score curves with historical labels. Subplots display the score curves of each baseline method and our proposed ATIN. The green curve is the ROC curve. 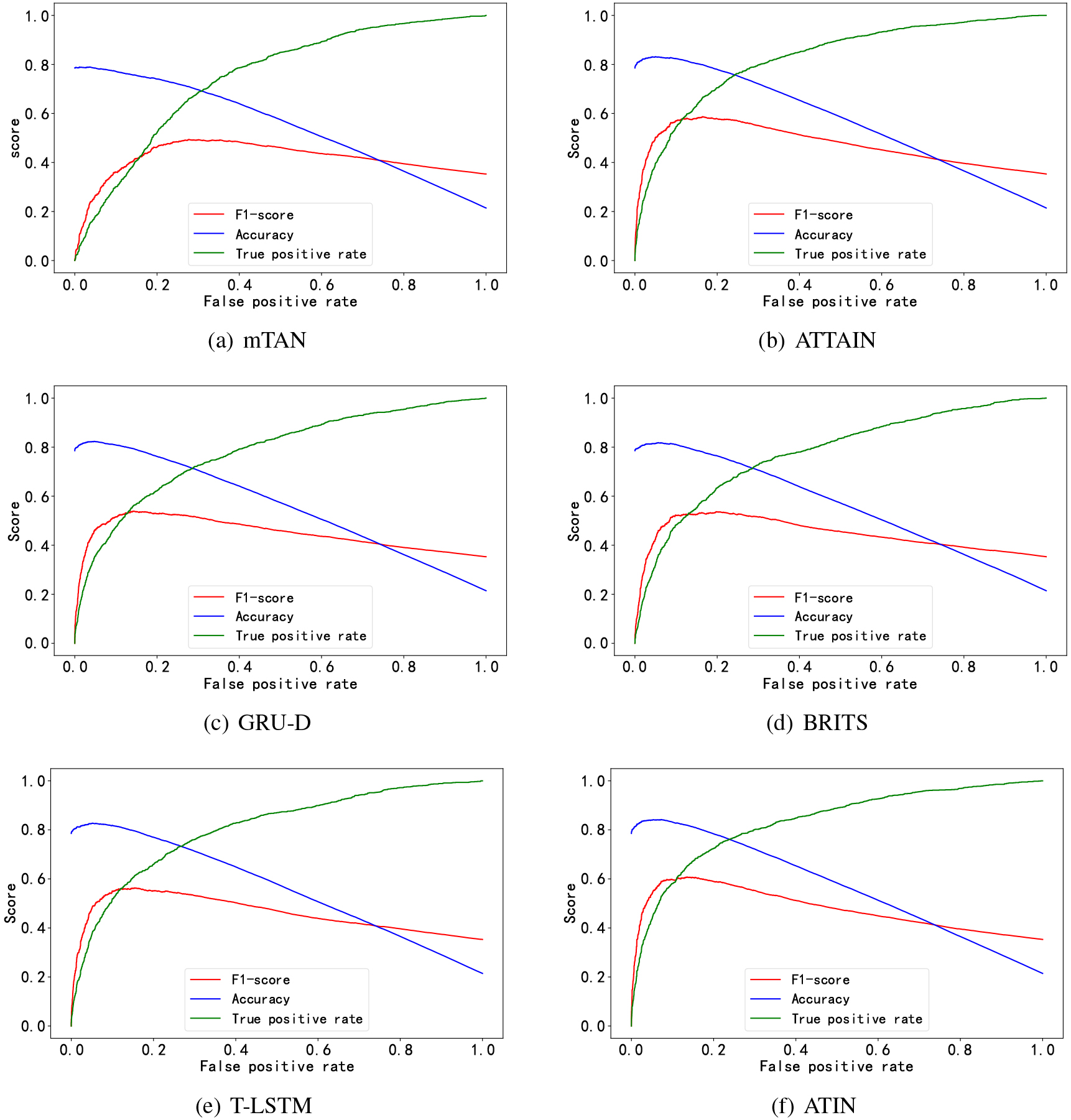
Performance with historical labels
Method
FA-score
Acc (FA)
AUC
Peak
LSTM
mTAN
ATTAIN
GRU-D
BRITS
T-LSTM
ATIN
Ablation with decay functions
Method
FA-score
Acc (FA)
AUC
Peak
I-ATTAIN
TI-ATTAIN
I-ATEM
FTI-ATTAIN
ATIN
Based on expert experience, experts will believe the current measurement if there are recent consecutive historical measurements that are judged to be anomalous. In brief, the historical labels will influence the current anomaly detection. Therefore, we incorporate historical labels into the inputs of the model. Equation (10) is adjusted as
To maintain the format of the input data, at the last point, we let
Table 5 shows the effect with the addition of historical labels when the sequence length is 16. The results of all models are significantly improved. The proposed ATIN still achieves outstanding performance. Meanwhile, ATTAIN and the proposed model with an attention mechanism (I-ATTAIN, TI-ATTAIN, I-ATEM, ATIN) performed more consistently in all evaluation metrics. Interestingly, LSTM outperforms other baseline models as it is aided by historical labels to make a better classification. In contrast, models such as mTAN, BRITS, T-LSTM, and GRU-D, which are specifically designed for IMTS, fail to make optimal use of historical labels. Table 6 shows the results of the ablation experiments. Time-Aware and ATEM continue to have gaining effects. Figure 7 shows the score curves of each respective model after adding the historical labels.
Detection with different decay functions
For different tasks, their best-dapted decay functions may be varied. Here are a few of the most commonly used decay functions:
Using ATIN as the base model, the functions
The outcomes demonstrate that employing
Results (FA-score) with decay functions
Results (AUC) with decay functions
Results (Peak
In addition, the decay function can be selected based on the validation set. The percentage of training set, validation set, and test machine can be set as desired. For example, in this task, all sequences are arranged chronologically and divided into three groups: the first 70% is the training set, the middle 15% is the validation set, and the remaining 15% is the test set. After training using different decay funtions, the model that performs best on the validation set is selected for the final evaluation. Assuming the validation set and test set share the same data distribution, the experimental outcomes observed on the validation set are expected to closely approximate the experimental outcomes on the test set during the final evaluation.