
Abstract
Named Entity Recognition (NER) is a fundamental task that aids in the completion of other tasks such as text understanding, information retrieval and question answering in Natural Language Processing (NLP). In recent years, the use of a mix of character-word structure and dictionary information for Chinese NER has been demonstrated to be effective. As a representative of hybrid models, Lattice-LSTM has obtained better benchmarking results in several publicly available Chinese NER datasets. However, Lattice-LSTM does not address the issue of long-distance entities or the detection of several entities with the same character. At the same time, the ambiguity of entity boundary information also leads to a decrease in the accuracy of embedding NER. This paper proposes ELCA: Enhanced Boundary Location for Chinese Named Entity Recognition Via Contextual Association, a method that solves the problem of long-distance dependent entities by using sentence-level position information. At the same time, it uses adaptive word convolution to overcome the problem of several entities sharing the same character. ELCA achieves the state-of-the-art outcomes in Chinese Word Segmentation and Chinese NER.
Introduction
Named Entity Recognition (NER) is a widely used technology for information extraction in Natural Language Processing (NLP) [27]. NER mainly aims to accurately identify and classify named entities (e.g., names of people, organizations, location, etc) within unstructured text. Thus, NER plays a crucial role in real-world NLP because it provides accurate named entities for various downstream applications such as text understanding [12], information retrieval [30], text clustering [5], question answering [16], machine translation [32], and knowledge base construction [2]. Since sentences in Chinese are not naturally segmented, Chinese NER for social media text is more challenging than English NER [17, 21]. Therefore, to segment Chinese sentences, most existing Chinese NER for social media text models uses existing Chinese Word Separation (CWS) systems to perform word segmentation [10, 40]. However, due to the fact that the same characters in Chinese may have multiple parts of speech and represent different entities, Chinese Word Segmentation (CWS) systems incorrectly segments the sentences. As a consequence, Chinese NER for social media text may cause inaccuracy in entity boundary detection and entity category prediction. To address these issues, some studies have worked on the enhancement of information between characters [22, 25]. For instance, “BMES” [45] is a lattice structure that effectively uses word information to avoid word error propagation and segmentation. [25] point out that characters always outperform words in the framework of deep learning. In Chinese NER for social media text words often contain more important information than characters. Therefore the inability to use lexical information effectively is the fatal flaw of character-based NER methods.
Sentence-level and word Position Attention Informations.
A drawback of the purely character-based NER methods is that the word information is not fully exploited. Zhang and Yang [45] presented the lattice-LSTM, which combines the character-based NER with a lexicon created using words. In addition, when characters match many words in the dictionary, that keeps all words matched with characters and lets the latter NER model determine the word to be applied instead of heuristically selecting that word. The LSTM’s structure takes into account a temporal sequence, resulting in a significant computational costs. Peng et al. [29] proposed word information as well as adaptive word convolution is considered to enhance the boundary problem of the lexicon. The graph attention mechanism in PGAT [39] calculates different attention to the four dimensions of the character’s tokens (B, M, E, S) to make effective use of lexical information. However, this approach does not take into account the location of the characters, which leads to unclear boundaries in Chinese text. For example, “UTF8gbsn货拉拉拉拉布拉多吗? (Cargo Lara Lara Labrador?)” In Chinese, we can use position selective attention fundamentally to distinguish the five “UTF8gbsn拉 (La)” in the sentence to enhance the entity boundaries of “UTF8gbsn货拉拉 (Cargo Lala)” and “UTF8gbsn货拉拉拉 (Labrador)”.
In recent years, in order to speed up the computation, FLAT [19] proposed a Transformer-based Chinese NER for Social Media Text method for characters as well as location. Jia [13] proposed to use adaptive convolution of characters and words, and this approach enhances the role of words. However, this approach does not consider word position and the fact that sentence position information also affects the NER results. Jin [15] propose an implicit Transformer-based encoding of relative position information is proposed to enhance the boundary information of entities. This method, however, does not work with entities that are dependent on long-distance communication and entities repeated in sentences. As Fig. 1 shows, when the two entities “UTF8gbsn小米 (Xiaomi)” and “UTF8gbsn小米粥 (Xiaomi porridge)” have two Chinese characters (Xiaomi) repeated, this will pose a challenge to the Chinese NER for Social Media Text.
In this paper, we propose an enhanced boundary Location for chinese NER Via contextual association (ELCA) for nested Chinese NER for Social Media Text to overcome the above problems. ELCA solves the problem of long entities by adaptive convolution between characters. In detail, we link the index of the current character in context, find the first three characters associated with it and the next three characters. In contrast to conventional word separation methods, this paper employs adaptive word convolution to establish connections between the current character and contextual characters. This innovative approach enhances the delineation of Chinese entities, allowing for more precise identification of the most appropriate entity. As a result, it significantly improves the recognition rate of NER. This ensures that the current character cannot form an entity with both the previous character and the next character, and then continues with the next character so that no long entity is missed. ELCA uses sentence-level positional information with inter-character positional information to solve the problem that the same characters represent different entities. Unlike typical attention mechanisms, the position-selective attention discussed in this paper fundamentally employs a flat structure for encoding position information. This flattened position encoding has the potential to enhance the accuracy of Chinese NER. We set the index of two character codes (character and sentence), and the index value can determine and judge whether the current entity appears in other sentences, so as to determine the accuracy of the current entity.
In summary, the contributions of this paper are as follows:
In this study, we have enhanced the embeddings of entities in the text by incorporating their absolute positional information. The boundaries of embedded entities are now primarily determined by positional encodings. Consequently, our approach has yielded superior results in NER for social media texts. Contextual fragments of characters of different lengths are encoded to dynamically generate word-level representations of location-specific characters. As a result, our approach is able to capture useful word-level semantic information while reducing the impact of segmentation error cascades. The experimental results show that ELCA performs significantly better in both NER and CWS datasets in terms of characteristics compared to the baseline using character information. Specifically, the performance on OntoNotes is improved by 2.3%.
Several studies have employed character-based word representations obtained from end-to-end neural models, rather than relying solely on word-level representations, as the primary input [8]. [9] shows that the accuracy and efficiency of constructing cross-lingual bilingual mappings is low due to unclear information if entities in the corpus. These character-based representations capture additional information about the words and help improve the performance of named entity recognition (NER). In rule-based NER approaches, manual rules based on domain-specific gazetteers, syntactic-lexical patterns, and pre-processed synonym dictionaries are utilized. These rules aid in identifying protein mentions, putative genes, and other relevant entities [18]. Tran [36] proposed a neural NER model that extracts word features from word embeddings and character-level recurrent neural networks (RNNs). The model incorporates stack residual LSTM and trainable bias decoding techniques to enhance its performance. To capture informative morphological representations from word character sequences, Vzukov et al. [47] employed a deep bidirectional GRU. The resulting character-level representations are then combined with word embeddings through concatenation to form the final word representation. In summary, researchers have utilized character-based word representations, rule-based techniques, and the combination of character and word embeddings to improve the accuracy and effectiveness of NER systems. These approaches enhance the models’ ability to capture morphological information and identify specific entities within text.
Although co-training might improve the validity of the word segmentation, the NER module still had no specific measures to avoid segmentation errors [31]. The above existing methods suffered the potential issue of error propagation and confusion of entity boundaries. To address the challenges mentioned above, researchers have employed automatic dictionary construction techniques for Chinese named entity recognition (NER). These dictionaries are pretrained on large automatically segmented text and contain vocabulary with both boundary and semantic information [32]. Boundary information is provided by the dictionary itself, while semantic information is obtained through pre-trained word embeddings [1, 26].
Some approaches have explored performing Chinese NER directly at the character level, which has proven to be effective in empirical studies [22]. Ma et al. [25] addressed the computational efficiency challenges associated with utilizing word lexicons in Chinese NER. Stanis-lawek et al. [33] proposed encoding the lattice into a graph neural network (GNN), such as the Lexicon-based Graph Network (LGN) [33]. Additionally, the Flat-Lattice Transformer (FLAT) [20] introduced four codes to the NER process by considering the head and tail positions of characters within words, albeit with increased computational costs. BERT, with its bi-directional transformer architecture, swiftly incorporates character information into the NER process. Enhanced character embeddings have been achieved by incorporating the ALBERT pre-training language model and Multi-word Information (MWI) [21]. While this paper provides a comprehensive overview of Named Entity Recognition (NER) techniques, it is important to acknowledge that recent advances in the field extend beyond its scope. For instance, multi-modal NER [14] and financial domain [43].
In summary, scholars have utilized automatic dictionary construction, character-level NER, graph neural networks, and enhanced character embeddings to overcome the challenges in Chinese NER. These techniques leverage boundary and semantic information, address computational efficiency concerns, and incorporate character-level details into the models.
Methodology
Datasets
Datasets
The architecture of our model.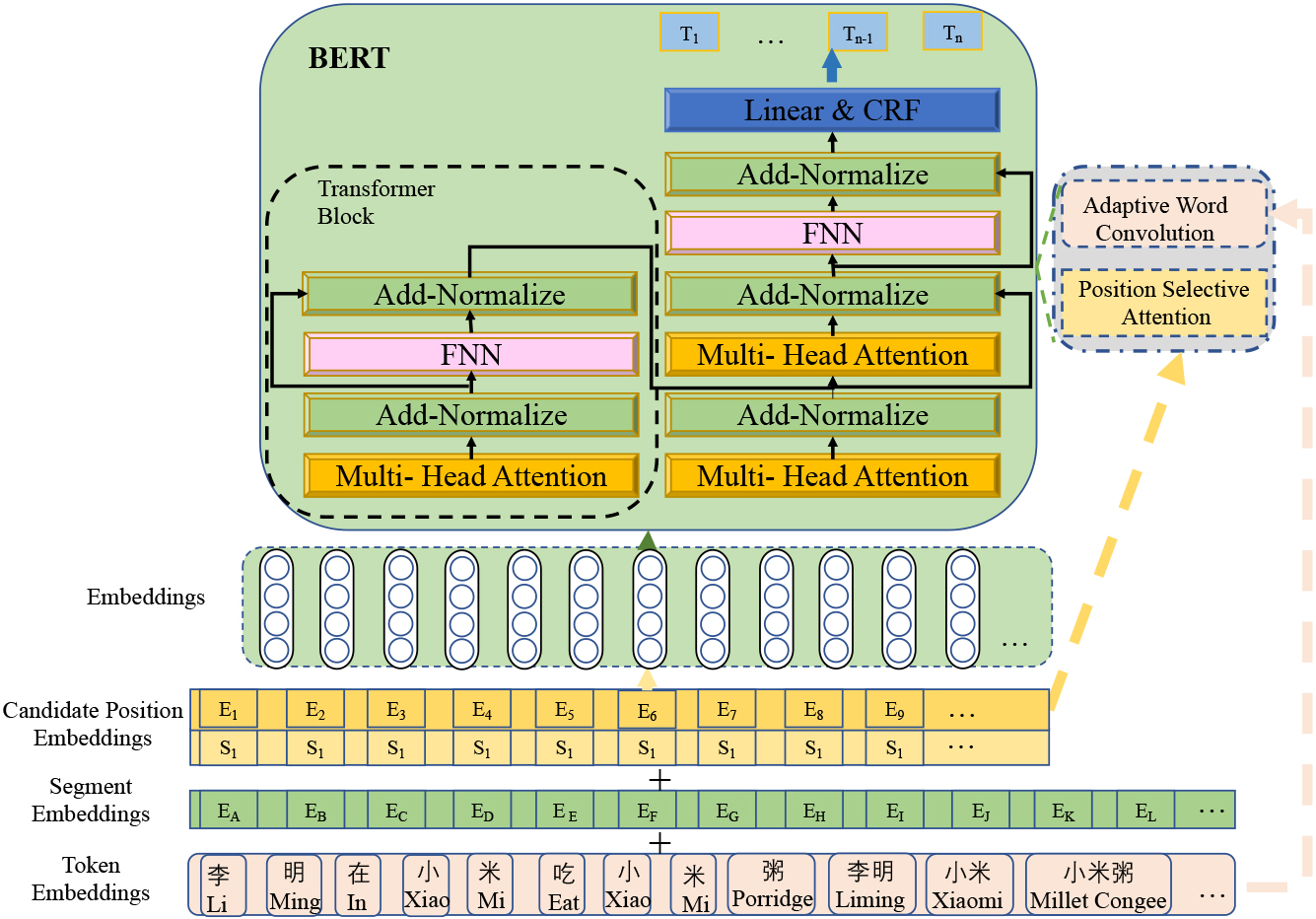
ELCA implementation details.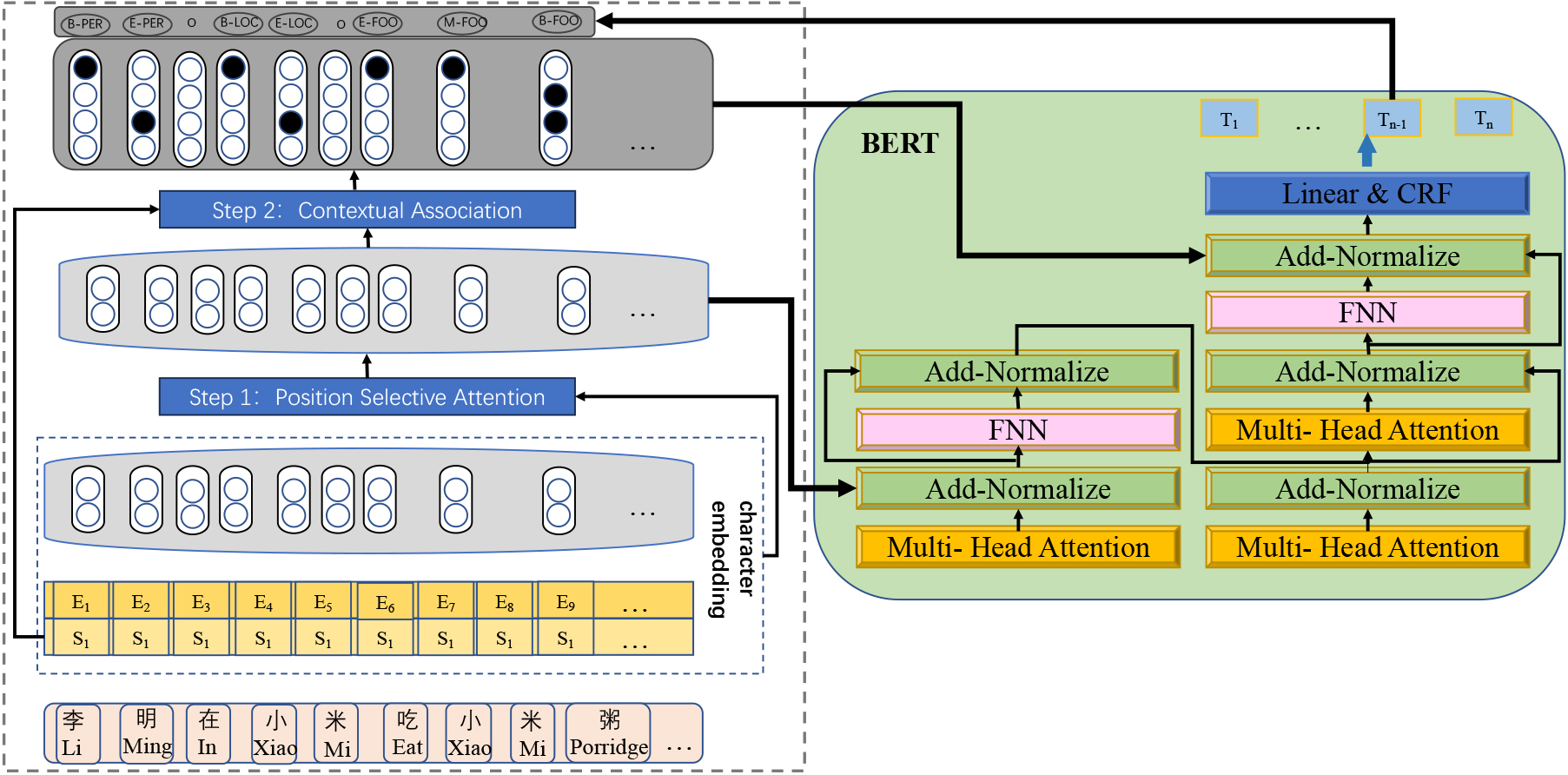
In this subsection, we present ELCA and outline its implementation steps. As shown in Fig. 2, ELCA consists of two main parts: position selective attention and contextual association. More details are shown in Fig. 3. Firstly, ELCA obtains the vector representation of the character through the embedding of the character, and the vector representation of the position information through the position selective attention. ELCA enhances the entity boundaries formed by the position information of the entity by feeding the vector representation of the character’s position information into the add-normalize layer of the BERT for the self-attention mechanism of the operation, thus enhancing the entity boundary formed by the entity position information. The position information and the original character embedding are input into the contextual association step to form the contextual association calculation of the text characters, and then input into the BERT to calculate the accurate boundary information to achieve the optimal recognition effect. In the position selective attention stage, we use positional coding to construct character-level and sentence-level positional information that can be used to more accurately represent entity information in the text. In the contextual association stage, we use adaptive word convolution and contextual association of characters to find and enhance the entity boundary information, which further improves the NER accuracy. Our framework consists of two main steps: pre-training and fine-tuning.
During the pre-training phase, the ELCA model is trained on unlabeled datasets using various pre-training tasks. This allows the model to learn meaningful representations from the data. In the fine-tuning phase of ELCA, the model initializes the pre-trained parameters and then fine-tunes them using sentence pair positional selective attention. This attention mechanism helps the model focus on relevant information while considering the position of each word in the sentence. It’s important to note that each word has its own separate fine-tuned model, although they all share the same pre-training parameters. This allows the model to capture word-specific characteristics during fine-tuning. To illustrate the concepts discussed, we will use a quiz example, depicted in Fig. 4, as a running example throughout this section.
As for sequence encoding, we use convolutional operations as our basic encoding unit. Chinese text in everyday use usually has no standardized syntax or grammar and presents semantics in a fragmented form, for example, UTF8gbsn来到杨过曾经生活过的地方, UTF8gbsn小龙女动情地说: “UTF8gbsn我也想过过过儿过过的生活” (Coming to the place where Yang had lived, Little Loong Girl said emotionally: “I also want to live through the life of the child over.”).
An illustration of our pre-training framework in BERT.
BERT [6] (Bidirectional Encoder Representations from Transformers) is a pre-trained language model comprising a stack of multi-head self-attention layers and fully connected layers. For each head in the
where
The original BERT model was not specifically designed to handle lattice diagrams, which encode sequences of characters as well as nested and overlapping words from different partitions. Incorporating position information from the lattice diagram accurately into the interaction between symbols is not straightforward. To address this, we propose an expansion of the position embedding of the attention plane and introduce position selective attention.
In this section, we present the fundamental architecture of Transformer and leverage its encoder, known as the BERT block, for optimizing the NER task. The BERT block comprises a self-attention network and a feedforward network (FFN). Each layer in the network includes residual connections and normalization. The FFN is a position-wise multi-layer Perceptron that performs nonlinear transformations. Transformer conducts self-attention over the sequence individually for each distance of attention (
where
In Fig. 4, the distance-lattice exhibits spans of various lengths. Given a sentence
Create the candidate position embedding.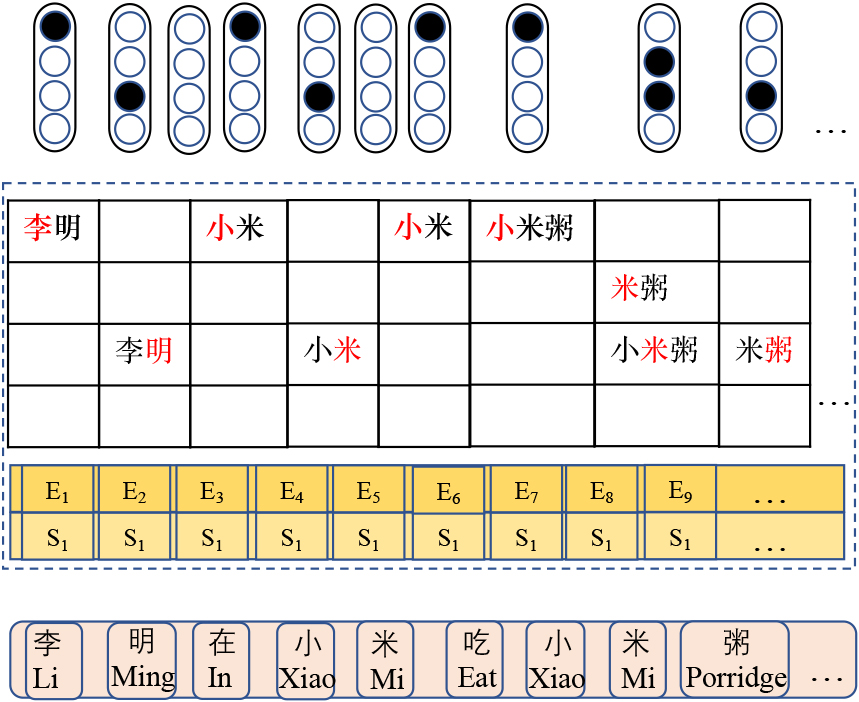
in the calculation mentioned above, we use
where
where
where
In this stage, we aim to encode the word-level semantics based on the positional choices of each character and the sentence position. This encoding process is essential for capturing the complete meaning of each word. For each character
where
To automatically correspond to subwords, we construct feature maps
To compute the contextual associations of characters, we use
Display the tabulation of subwords. The red vertical lines identify correct word segmentations. The ✓shows the subwords that fit each character.
where
It is clear from the Eq. (12), a type of adaptive valid character can be used to pick the candidate character information learned in step 1, and then the representation
In calculating Eq. (16), based on the properties of Chinese, we simply traverse f from 0 to 6 (no more than 6 entities in Chinese). We gain meaningful word-level semantic information from location information after going through steps 1 and 2 and avoid the issue of segmentation error cascade.
Experimental settings
Our experimental settings are similar with the protocols of [34], including tested datasets, evaluation metrics (P, R, F1) and etc.
The character embeddings are pretrained using word2vec on the original microblog text with a dimension of 100. For the basic BiLSTM The basic CNNs Other parameters are adjusted accordingly, with a learning rate of 0.001 and a dropout rate of 0.5. The validation set is created by randomly selecting 20% of the training set. We train each model for up to 120 epochs using the Adam optimizer, stopping if the validation loss does not decrease for 20 consecutive epochs. Additionally, for our specific implementation, we set the learning rate to 2e-5 and the dimensions We have experimented with different options and found these settings to be the most reasonable.
During the experiment, we discuss the Hyperparameters of Ontonotes and MSRA
Hyperparameters of Weibo and Resume
Performance on OntoNotes
Performance on resume
Performance on Weibo
Performance on MSRA
Performance on CWS
Chinese NER and CWS case
As shown in Tables 4–6, ELCA outperforms baseline models and other lexicon-based models on four Chinese NER datasets. ELCA outperforms lattice-LSTM [45] by 3.62 in average F1 score. For the state-of-the-art SoftLexicon (LSTM) [25], ELCA has an average F1 score improvement of 0.86. Probably due to the improvement of BERT features based on absolute location information, Lexicon-base based on small datasets is not as obvious as it is on large datasets compared to other datasets.
Effectiveness study
show the performances of our method against the compared baselines. In this experiment, we mainly compare the model from lexicon model and a single bidirectional LSTM.
We conduct ablation experiments to prove the effectiveness of our contributions. First, we conduct the main analysis through the small datasets Weibo and Resume. Second, we conduct different ablation experiments on four Chinese datasets, as shown in Table 11.
The performance of models in training and testing time. Time is measured in seconds. Lattice means the Lattice-LSTM
The performance of models in training and testing time. Time is measured in seconds. Lattice means the Lattice-LSTM
An ablation study of the proposed model
F1-value against the sentence length.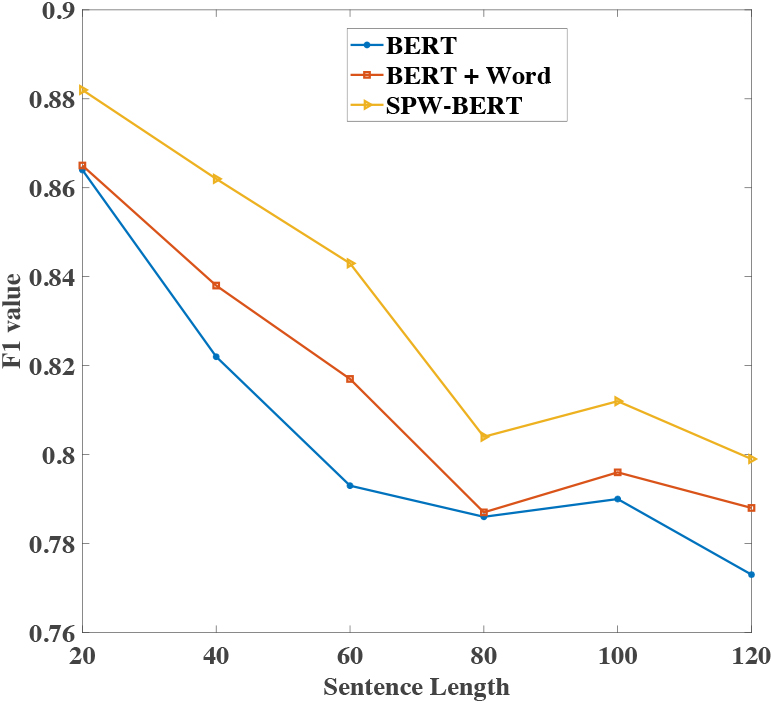
Only Sentence-level Position Attention Information.
We talk about location information in the course of our experiments as location information of characters and location information of sentences. As shown in Table 11, when we consider only sentence position information in our experiments, the results are about 6% higher than SoftLexicon (LSTM) results. When we consider only the character information in our experiments, the F1 value is reduced by about 5%.
Only Adaptive Word Convolution.
We removed the Sentence-level Position Attention Information in the ablation experiment part and determined the effect of a single Only Adaptive Word Convolution on the F1 index.
Sentence Length.
As show in Fig. 7, the F1 value trend of change the baselines and ELCA on Ontonotes dataset are shown. All models can show their performance as a function of sentence length with such a performance curve. The shorter the sentence, the smaller the impact on performance. We speculate that since the complexity of sentences increases with sentence length, this poses a greater challenge for NER.
ELCA: Sentence-level Position Attention Information and Adaptive Word Convolution for Chinese NER is proposed in this paper. ELCA solves the problem of long-distance dependent entities in Chinese NER that cannot be detected using absolute location information and adaptive word convolution. At the same time, adaptive word convolution can improve the character relationship. ELCA, on the other hand, does more than merely improve boundary word information; it also provides dynamic word-level representations for letters at specified points by encoding segments of varying lengths. It has a promising research future. In the future, we plan to extend the application of ELCA to additional Named Entity Recognition (NER) tasks in low-resource languages. Our goal is to improve the efficiency of low-resource models by developing a unified NER model that can be applied to a range of low-resource languages, thereby reducing the computational overhead associated with building separate NER systems for each language.
Footnotes
Acknowledgments
The work described in this paper is funded by the National Natural Science Foundation of China under Grant Nos. 61772210 and U1911201, Guangdong Province Universities Pearl River Scholar Funded Scheme (2018) and the Project of Science and Technology in Guangzhou in China under Grant No. 202007040006.