
Abstract
Unsupervised action recognition based on spatiotemporal fusion feature extraction has attracted much attention in recent years. However, existing methods still have several limitations: (1) The long-term dependence relationship is not effectively extracted at the time level. (2) The high-order motion relationship between non-adjacent nodes is not effectively captured at the spatial level. (3) The model complexity is too high when the cascade layer input sequence is long, or there are many key points. To solve these problems, a Multiple Distilling-based spatial-temporal attention (MD-STA) networks is proposed in this paper. This model can extract temporal and spatial features respectively and fuse them. Specifically, we first propose a Screening Self-attention (SSA) module; this module can find long-term dependencies in distant frames and high-order motion patterns between non-adjacent nodes in a single frame through a sparse metric on dot product pairs. Then, we propose the Frames and Keypoint-Distilling (FKD) module, which uses extraction operations to halve the input of the cascade layer to eliminate invalid key points and time frame features, thus reducing time and memory complexity. Finally, the Dim-reduction Fusion (DRF) module is proposed to reduce the dimension of existing features to further eliminate redundancy. Numerous experiments were conducted on three distinct datasets: NTU-60, NTU-120, and UWA3D, showing that MD-STA achieves state-of-the-art standards in skeleton-based unsupervised action recognition.
Introduction
With the rapid development of science and technology, artificial intelligence has become one of the most important development directions in all walks of life. Human motion recognition, as an important field, has been widely used in many fields such as human-computer interaction, film and television production, semi-automatic driving, motion analysis, and game entertainment [1, 2, 3]. While supervised human motion models have achieved remarkable success, they still face significant challenges in the face of large-scale data sets, real-world engineering environments, and production scenarios. First of all, for very large data sets, we cannot fully label and annotate them, which will require a lot of manpower and resources. Second, due to cognitive errors, the labels we give may be inaccurate or untrue to a certain extent.
Various formats can be used to represent motion data, including video (RGB), depth (+D), and 3D skeletal keypoint data. 3D skeleton key point data is more difficult to process than other data, but it can describe human motion more accurately while avoiding the influence of body shape and clothing as much as possible, and its robustness can deal with the interference of environmental noise. Therefore, in this study, we use the 3D skeleton key point data as the basic data.
At present, there are many unsupervised training models, but they can be roughly divided into three categories according to their overall structure. The first is the encoder-decoder model [4, 5, 6], where the input skeleton sequence first enters the encoder for various processing, then becomes hidden features, and finally, the hidden features enter the decoder to get the output sequence. Zheng et al. [4] extracted long-term global motion dynamics in skeleton sequences and designed a conditional skeleton inpainting architecture for learning fixed-dimensional representations. Nie et al. [5] proposed a new Siamese denoising autoencoder, which uses the pose-dependent and view-dependent features separated from human skeleton data as a three-dimensional pose representation, and combines the kinematics and geometry of the human skeleton. A sequential bidirectional recurrent network (SeBiReNet) is proposed to model human skeleton data, Ahn et al. [6] proposed the Spatiotemporal Crossover (STAR) Transformer, which can effectively represent two cross-modal features, spatiotemporal features, and skeleton features, into one identifiable vector. The current Encoder-Decoder model has been very mature with the help of various tasks, such as skeleton reconstruction [4], skeleton coloring prediction [7], and skeleton displacement prediction [8], and has achieved significant results. The second method is contrastive learning [9, 10, 11]. Because of its high degree of freedom of positive and negative sample definition and excellent performance, it has become an important research direction in unsupervised learning. This method is mainly to learn the common features between similar instances and distinguish the differences between different instances. Rao et al. [9] proposed a contrastive action learning paradigm called AS-CAL, which gives skeletons different strengths of augmentation to learn action representations. Thoker et al. [10] let the network learn higher-level semantics of 3D skeleton data by learning the similarity between different skeleton representations and enhanced views of the same sequence. Gao et al. [11] proposed a new method for contrastive self-supervised learning. Use enough viewpoints for comparison, and finally, select distinguishing features for action recognition. Contrastive learning does not need to pay attention to the cumbersome details of the instance but only needs to learn to distinguish the data in the feature space of the abstract level. Therefore, the complexity of the model is low, and the optimization of the model becomes simple. At the same time, it also has a strong generalization ability. A third method was born at the same time: Hybrid method [12, 13, 14]. A hybrid approach is a variant that combines an encoder-decoder model with a contrastive learning model. The parameters and optimization process of this model are extremely complex but have achieved some success so far. Su et al. [12] proposed a predict & cluster model, using a weakened decoder, namely a fixed weight decoder, to force the encoder to learn more effective features and then drop the learned effective features into a linear classifier for classification after dimensionality reduction. Su et al. [13] propose a new self-supervised learning (SSL) method to learn 3D skeleton representation, interpolate skeleton data to construct continuous skeleton data, and model it to enhance learning features. Chen et al. [14] proposed a self-supervised hierarchical pre-training scheme to learn spatial, short-term, and long-term temporal dependencies.
From the perspective of feature extraction, current skeleton sequence processing methods mainly start from two perspectives of time and space. At the time level, many previous methods used RNN to model time series [4, 12, 15, 16], Zheng et al. [4] adopted a new conditional framework to capture the long-term global motion dynamics of different length sequences, Su et al. [12] used RNN to extract features and reduce dimensions of time series. Lin et al. [15] learn time characteristics by solving jigsaw puzzle games, and Gao et al. [16] propose Multi-ScaleTCN to capture richer features between adjacent frames. At the spatial level, many existing methods process the overall skeleton sequence and extract the features of the global skeleton sequence [1, 15, 16]. Su et al. [1] use a weakened decoder to force the encoder to learn more global skeleton features. Lin et al. [15] models skeleton dynamics through motion prediction by predicting future sequences. Gao et al. [16] introduce the perception of joint types in the analysis of motion dynamics. Our approach takes into account the characteristics of both perspectives.
However, these methods have the following problems:
Part of the method from the perspective of time only focuses on the features between adjacent frames and rarely extracts the connections between frames that are far away in the sequence, which will not only lose a lot of key information but also cannot capture long-term dependencies well. Although the model [14, 17, 18] applying the Transformer method extracts all the features between frames, most of the extracted features are actually invalid, and messy and invalid features will affect the prediction results of the decoder. As shown in Fig. 1, the key points of the last few frames of the drinking action change very little. Most of the methods from the perspective of space only convert the skeleton sequence into a sequence vector or a two-dimensional pseudo image. Most of the methods from the perspective of space only convert the skeleton sequence into a sequence vector or a two-dimensional pseudo image. Although the relatively complete features of the skeleton sequence are extracted from it, they do not pay special attention to the important features at the joint points and even ignore the internal linkages of a single key point. Different dimensions of a single key point can extract different features, and different three-dimensional perspectives have different effects on different actions. Even if there are a small number of methods to extract a large number of bone key point features [19], these features, like the method of extracting features from a sequence perspective, focus on a large number of invalid key points. In fact, in the task of human skeleton action recognition, the displacement of some key points from the first frame to the end of the last frame is very small, and the extracted features of these key points are not only invalid but also affect the effectiveness of the spatial features.
Visualization of the original skeleton sequence ‘S001C001P002R002A001.skeleton’, The last three frames of the drinking action are frame 82, frame 83, and frame 85. The key points of each frame change little compared to the key points of other frames, and the attention between them is basically invalid. Therefore, we ignore these frames when calculating attention and eliminate these frames in the distilling module. For the method that extracts all the features between frames and extracts a large number of bone key features, the spatiotemporal complexity is higher. When the input sequence is longer, the key points are more, and there are multiple encoder/decoder layers stacked, the stacking of M encoder/decoder layers makes the total memory usage of the time stream

In response to the first problem, we proposed a module called distilling and dim-reduction-based attention (DDA), which combines a self-attention mechanism and traditional RNNS to co-capture the temporal and spatial features of 3D skeleton sequences. It extracts the relationship between distant frames in time series and distant key point coordinates in spatial series through Screening Self-attention (SSA)module, and further captures the long-term dependence between time frame sequence and spatial key point sequence. By Frames and Keypoint-Distilling (FKD)module, invalid frames and invalid key point coordinates are eliminated to reduce the influence of clutter features.
For the second problem, we propose Multiple frames and the Keypoint-Distilling-attention module, which selects the best dot product pairs and avoids the calculation of invalid dot product pairs. The computation amount of a single attention block is reduced from
A description of our framework: It is a two-flow Embedding encoder-decoder architecture. It is composed of two independent parts, scalar projection and local time stamp (location), realizing location coding and preserving local context. The middle module of Embedding is the encoder, and the encoder will pass the learned features to the decoder to generate a new sequence. The upper branch (yellow) is the feature extraction process of the time frame, while the lower branch (blue) is the feature extraction process of key points in space. Each branch must pass through three layers of Attention and two layers of Distilling. Take the square blue branch as an example. The luminescence of the key points indicates the key points with stronger features in Attention. After passing Distilling, the luminous key points are saved for the next step of Attention, while the non-luminous key points are distilled away by the Distilling module.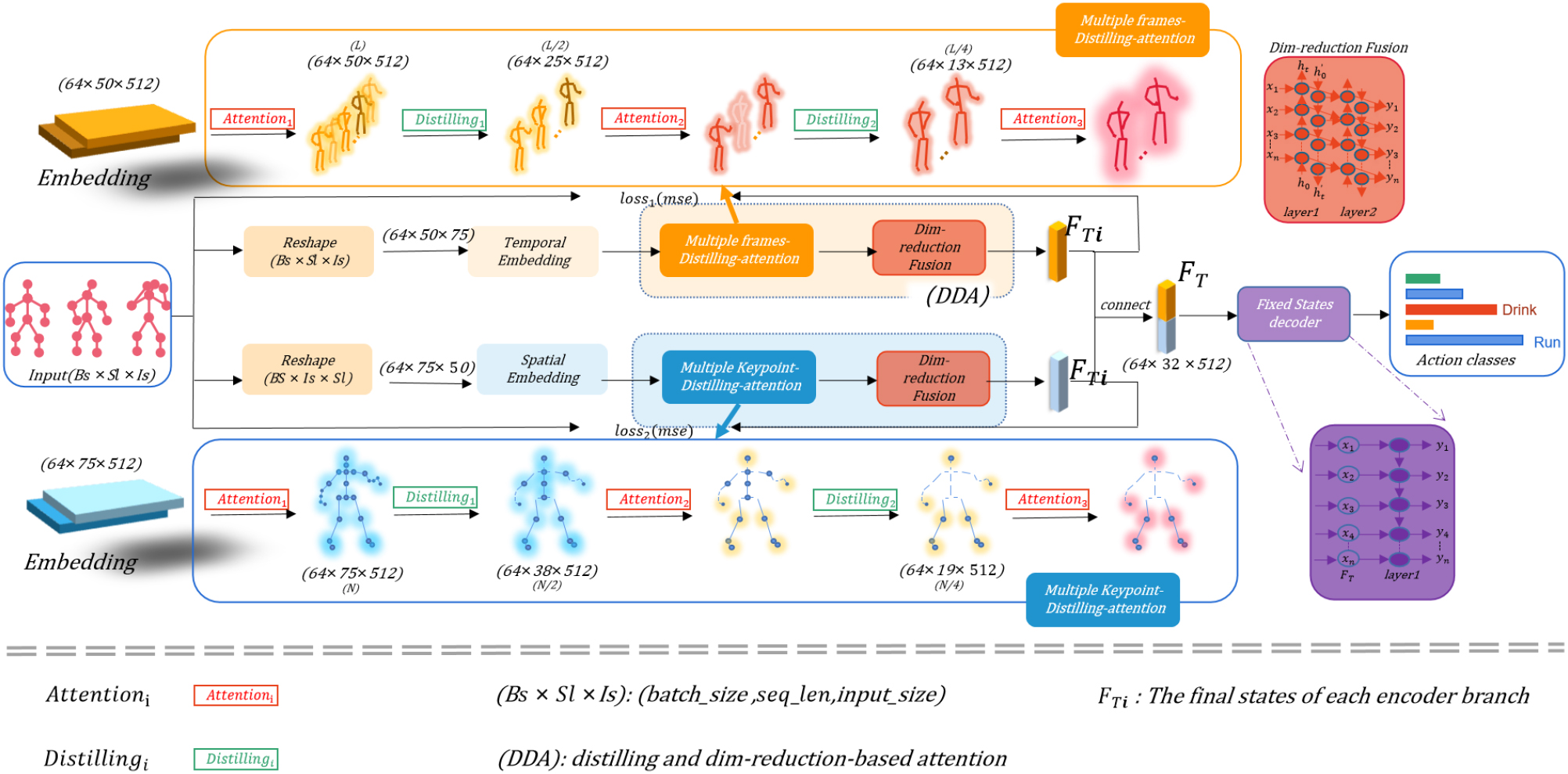
Based on the above two designs, we propose a Multiple Distilling-based spatial-temporal attention (MD-STA) networks. Our model is divided into two spatial-temporal paths, as shown in Fig. 2. It is composed of Embedding, Screening Self attention (SSA), Frames and Keypoint-Distilling (FKD), and Dim-reduction Fusion (DRF) modules.
A large number of experiments have been carried out on the three data sets of NTU-60, NTU-120, and UWA3D. We prove that the proposed MD-STA model can perform well under the benchmarks of different divided data sets, including cross-view, cross-subject, and cross-setup, significantly outperforms other methods, and our visualization results, including t-SNE and confusion mastic, also demonstrate the effectiveness of our model. The main contributions of this work are summarized as follows:
We propose a Multiple Distilling-based Spatial-temporal Attention Network(MD-STA), which aims to capture effective and comprehensive motion correlations at temporal and spatial channel-wise and resolve the problem of the extraction of long-term dependencies and the capture of high-order motion relationships between non-adjacent nodes for motion relationship learning. In MD-STA, we propose Multiple Frames and keypoint- Distilling-attention based on probability, which contains two core modules: Screening Self-attention(SSA) to extract the most effective motion representations at temporal and spatial level, respectively, frames and Keypoint- Distilling ( FKD ) module to reduce the training process time complexity and memory consumption. Extensive experiments were conducted to verify our model’s advanced nature quantitatively. In the cross-subject and cross-view of the NTU-60 dataset, the model accuracy is 21.5% and 7.2% higher than the existing methods, respectively. In the cross-subject and cross-setup of the NTU-120 dataset, the model accuracy is 11.7% and 14.8% higher than the existing methods, respectively.
Unsupervised action recognition
Action recognition based on unsupervised skeletons, that is, without assigning label classes to data, learns important features of skeleton actions from a large amount of unlabeled data and classifies actions. Due to its lightweight and good robustness, this work has attracted extensive attention from researchers. Zheng et al. [4] originally proposed GAN encoders, which was a milestone in unsupervised training. SU et al. [12] proposed a weak decoder model. Since the decoder needs to regenerate the sequence, this forces the encoder to generate more powerful features and ultimately trains a better encoder. Lin et al. [15] Combined various methods, such as motion prediction and bone reconstruction, to learn the features of bone sequences from different aspects. Ahn et al. [6] Proposed the space-time intersection (STAR) converter, which can effectively fuse the two cross-modal features of space-time features and skeleton features. Gao et al. [16] and Rao et al. [9] proposed a contrastive learning approach, which is also a recent mainstream approach, to reduce the gap between classes. Thoker et al. [10] made the network learn a higher level of 3D skeleton data semantics by learning the similarity between different skeleton representations and enhanced views of the same sequence. Cheng et al. [14] proposed a layered converter to learn more spatial features. In our work, our encoder effectively integrates multidimensional features and improves the encoder’s performance by combining a weak decoder.
Attention mechanism
The attention Mechanism is a unique structure used to learn and calculate the contribution of input data to output data. Badanau et al. [20] first proposed addictive attention, which improved word misalignment in the translation task of the encoder-decoder structure. Then Luong et al. [21] proposed location, general and dot-product attention, significantly improving the accuracy of English-German two-way translation. Later, Vaswani et al. [22] proposed a self-attentional Transformer model with higher parallelism, significantly improving the BLEU score and reducing the time spent on model training. Ma et al. [23] propose Cross-Dimensional Self Attention(CDSA) to capture attention in multiple dimensions, such as time and space, and reduce computational complexity. Child et al. [24] proposed a sparse decomposition of attention mechanisms for fast training models. In our work, our model combines attention mechanisms with traditional RNNS to capture multidimensional features of 3D skeleton sequences.
Extraction of temporal and spatial features
Earlier methods represent data as 2D and 3D coordinate vector sequences and use CNN and RNN to drive data [25, 26, 27, 28]. Liu et al. [26] have proposed a method to calculate the size and direction of 3D skeleton sequences. Zhang et al. [27] have proposed a method to convert 3D skeleton sequences into pseudo-images. Dedeoglu et al. [29] proposed a method to realize real-time human action recognition by using contour difference degree, and Yu et al. [19] proposed to use an adaptive convolutional neural network to learn spatiotemporal features. However, the extraction effect of these models on the features of spatial key points is too low, and the interaction of some human key points is basically ignored, resulting in the loss of a large number of features, and the human body mechanics are not taken into account. Liu et al. [28]proposed using RNN to capture the global dependence of human motion from 3D skeletal motion sequences. However, this cannot extract features between pairs of skeletal joints in the human body. Cheng et al. [30] proposed the GCNs method to capture the geometric space dependence of joints in the three-dimensional skeletal body and achieved good results. Peng et al. [31] proposed a dynamic GCN to improve the capability of the model. Liu et al. [32] proposed multi-scale spatio-temporal GCNs to enhance the ability of the model to extract spatio-temporal features. However, their performance in the extraction of key features that are far away from each other is still poor. Spatiotemporal feature fusion is still the bottleneck of existing methods. Some methods only extract time features or space features. Even for the models with time feature and space feature extraction methods, the performance of the integrated features of the two dimensions is not optimistic, even lower than that of the branch method, due to the different semantics represented by different dimensions of the two features. In our work, our model obtains excellent results in extracting features of spatial key points, not only extracting features among a large number of key points but also extracting the internal relations of a single key point.
Method
In this part, we first preprocess the input sequence, including downsampling, noise reduction, and removing a few frames, so as to adapt to our model. After reshaping, the processed input sequences are respectively mapped to higher dimensional Spaces on the Embedding layer, to realize position encoding and retain the local context. After mapping sequences into our Screening Self – attention (SSA) module, get a lot of features in the module after entering Frames and Keypoint Distilling (FKD) module, a large number of features are distilled into a few more important ones. In fact, the data is entered twice (SSA) and (FKD) modules to get the most important features. Then, the data flows into the Dim-reduction Fusion (DRF) module to be dimensionally reduced, and the dual-way time and space features are fused to get the final feature. The task of 3D skeleton action recognition is completed with the KNN classifier.
At the time level, our work maps the spatial key points of each frame sequence to a higher dimensional space, achieves position coding in high dimensional time, and retains the local context. Secondly, we calculate the partial dot product of the overall time frame sequence to obtain a large number of time features. Moreover, we selectively calculate the attention probability distribution
This is our time flow branch detail diagram, an illustration of our framework: This is an Embedding-encoder-decoder architecture. Embedding consists of two independent parts: scalar projections (blue blocks) and local timestamps (yellow blocks). The 75-dimensional key points enable position encoding and preserve local context. The middle gray module is an encoder comprising the above six modules and realizes operations such as feature extraction and distillation. The encoder passes the learned fusion features (purple blocks) to the decoder to generate a new sequence, and the generated sequence and the forward evolution sequence calculate the loss to complete the human action recognition task.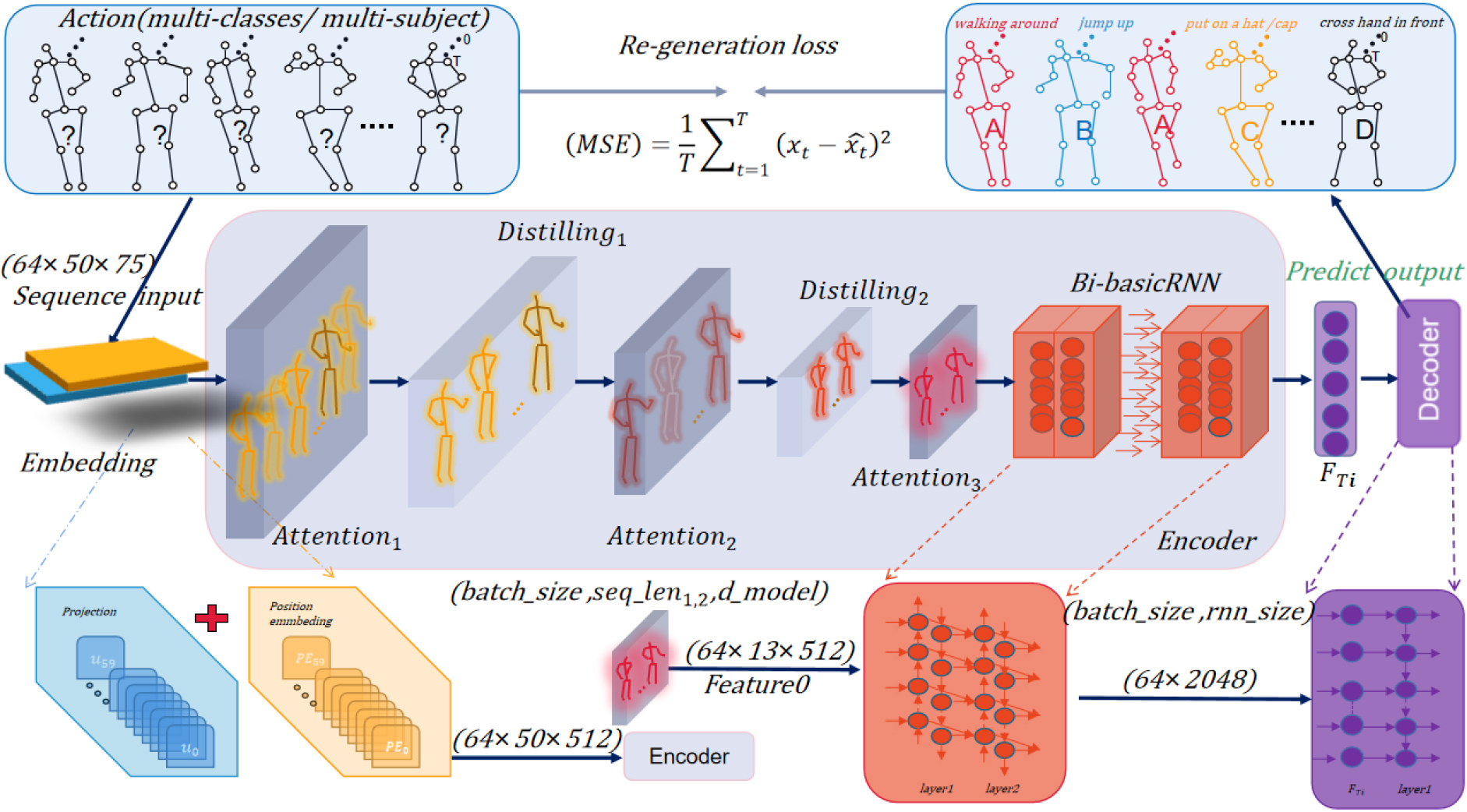
At the spatial level, we map the spatial key points of each frame sequence to a higher dimensional space, realize position coding in the high dimensional space, and retain the local context. Secondly, we calculate the partial dot product of the overall key point sequence to obtain a large number of spatial features. We not only calculate the dot product of the key points that are far away or near, we also compute the dot products of different dimensional coordinates for different key points and the dot products of different coordinates for the same key points, and we selectively compute the attention probability distribution
The output after processing by the above modules is divided into two parts: spatial flow output and time flow output. They respectively obtain the output of the encoder through the Dim-reduction Fusion (DRF) module. In the Dim-reduction Fusion (DRF) module, we use the two-way flow, which not only reduces the dimension of the time feature and the space feature but also reduces the redundancy of the time feature and the space feature after distillation and integrates them together. It fits our current model better than other neural networks, and this module improved the overall model score by 4 percentage points. Finally, we improve the feature extraction ability of the encoder combined with the fixed-state decoder.
Time frame and key point data preprocessing: We preprocess the input data so that it fits our model better. The input form for the data used in this article is as follows.
In the time flow branch, Given an input skeleton sequence
In the space flow branch, Given an input skeleton sequence
In order to enhance the learning ability of the model, we randomly zero two frames of each action of the training data and keep the test data unchanged. In this way, the training difficulty is improved, the features encoded by the encoder are stronger, and the robustness of the model is improved.
Hyper-parameter search: We use hyperparameter search so that the network can achieve the best performance. The optimization of hyperparameter search can indeed be completed one by one in small-scale cases. It is the variable control method, which keeps one variable unchanged, adjusts the value of the other variable, and then repeats the experiment all the time. This is also true in the case of higher dimensional variables. They interact with each other, so in order to get a more accurate model and achieve better-expected results, we use the standard grid search method. Each combination of hyperparameter values requires end-to-end training of the model. Our hyperparameters, such as embedding dimension, number of convolution layers, number of RNN cells, etc., are essentially small search space, and we want to make sure that we find the best option, so we use the standard grid search method, which tries all possible combinations to get the optimal solution that we need.
Temporal and Spatial Sequence embedding: We used the Embedding layer to preserve the local context, specifically, Given an input skeleton sequence
where
We project the scalar context
where
where
Screening Self-attention: We propose Screening Self-attention so that the network can better represent the skeletal action with less computation. The full self-attention in [22] is about query, key, and value.
The formula for this is
where
However, the actual situation is that only a few frames and in the whole sequence have effective attention, and most frames actually have very limited or even ineffective attention with other parts of the frame, so we only select a small number of frames and key points to calculate the attention, which greatly reduces the computational complexity.
Where
Set the sampling factor as a, then
A detailed introduction to the encoder architecture. The dark gray square represents Screening Self-attention, which consists of the above four parts. The red layer represents the n-head attention mechanism, and the remaining three layers are other operations. The light gray square represents Self-attention Distilling, which contains two layers of different operations to distill the output of the dark gray square. The red square on the far right is a two-layer bidirectional RNN, and each layer consists of 2048 basicRNN units.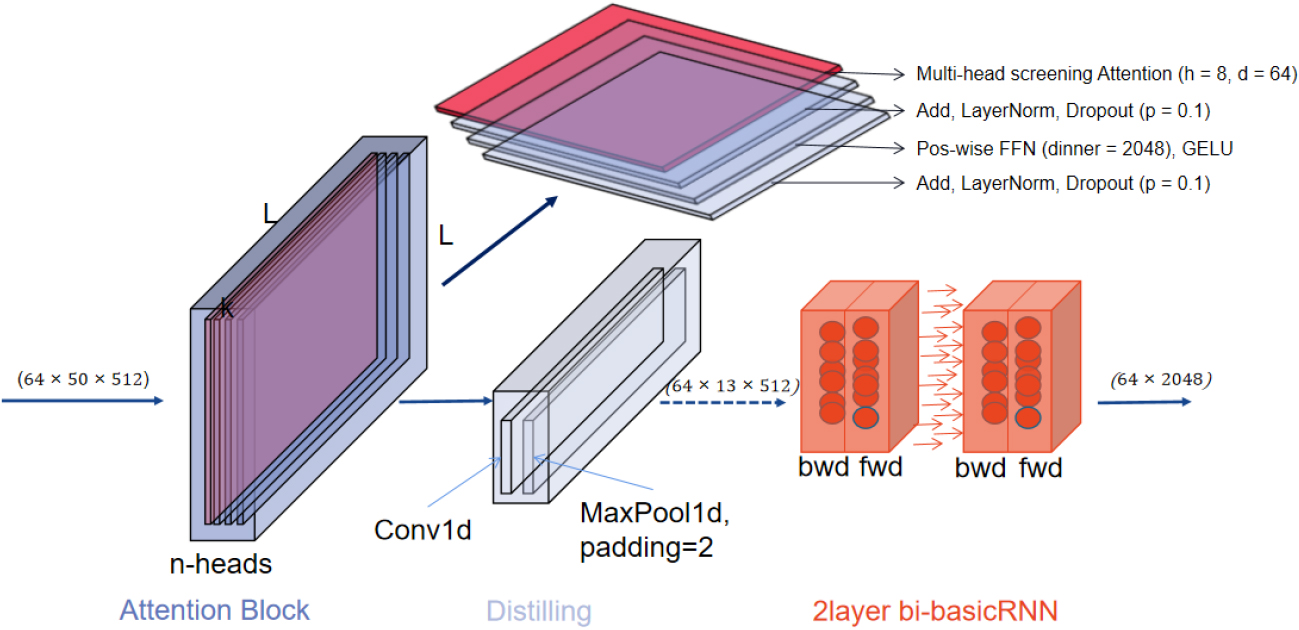
Frames and Keypoint-Distilling: We proposed Frames and Keypoint-Distilling to reduce the effect of ineffective features on training. Since the feature mapping of the encoder is a redundant combination of values v, we use a distillation operation to filter and accumulate the features so that the previous sequence length L is distilled to L/2. The key point before N is distilled into N/2. In fact, we repeat the operation twice, and the sequence length is finally distilled to L/4, and the number of key point coordinates is finally distilled to N/4. After the distillation operation, the next layer of essential feature combinations is generated, and the Screening Self-attention continues, as shown in Fig. 3. Inspired by the dilated convolution [34, 35], our “distilling” procedure forwards from
where
Where
Dim-reduction Fusion (DRF): We propose a bidirectional flow so that the network can capture better long-term dependencies in the sequence of actions. Specifically, the network is a multilayer bidirectional gated loop unit (BasicRnn), its input is Feature0 after being processed by the embedding layer and the self-attention layer.
The final states of each encoder branch are
Fixed States decoder: We use a fixed-state decoder to improve the overall feature extraction capability of the encoder. The decoder includes internal I/O and external I/O. In this decoder configuration, the encoder’s final state is the input to the internal decoder, the output of each time step is the external input to the next time step, the external input to the decoder is conditional (the external input of each time step length is the output of the previous time step), and the internal input, usually the hidden state of the previous step, is replaced by the encoder’s final state. Our decoder consists of RNNS, that is, in RNN cells
where
The MD-STA network components in detail
A detailed introduction to the Multiple keypoint-Distilling-attention architecture, The red squares represent Screening Self-attention, and the green squares represent keypoint Distilling.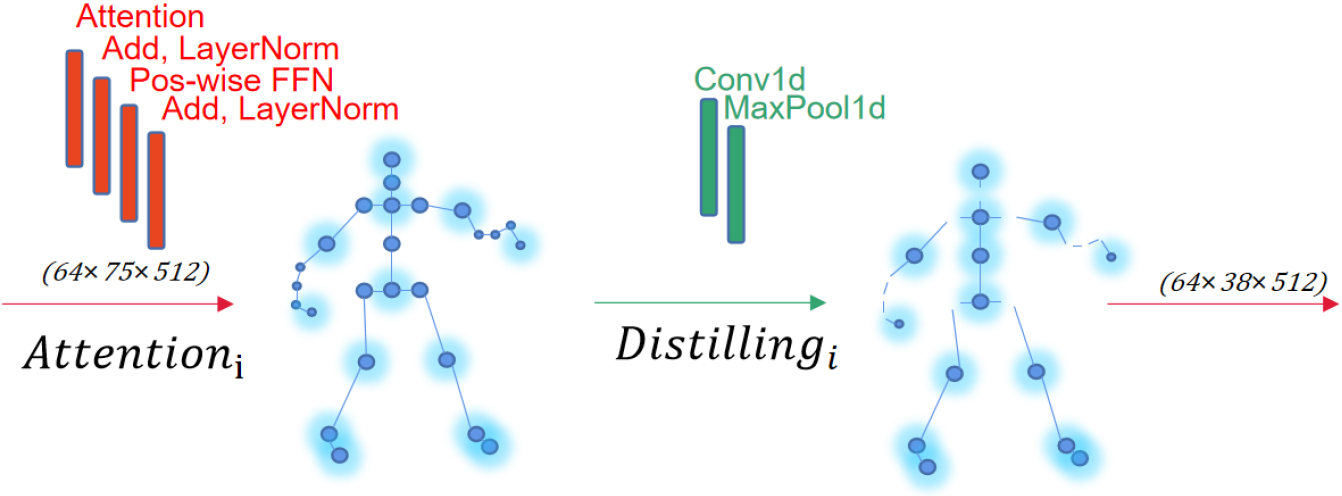
Implementation details
Inspired by references [37, 38, 39, 40, 41, 42, 43], our data preprocessing method is also related to view invariance, action sequences are captured from different views by depth cameras, e.g., Microsoft Kinect.
where
Datasets
We use three different datasets for training, evaluating, and comparing our system with related approaches.
NTU RGB+D 60[45]: The data set contains 60 classes, with a total of 56880 samples, of which 40 are daily movements, 9 are health-related movements, and 11 pairs mutual movements. They were performed by 40 people aged from 10 to 35. The data set was captured by Microsoft’s Kinectv2 sensor using three different camera angles in the form of depth information, 3D skeleton information, RGB frames, and infrared sequences. The NTU dataset uses two benchmarks when dividing the training and test sets. Cross-subject divides the training set and test set by person ID. The training set contains 40,320 samples, and the test set contains 16,560 samples. Cross-View divides the training set and the test set by the camera. The samples collected by camera 1 are used as the test set, and cameras 2 and 3 are used as the training set. The sample numbers are 18,960 and 37,920, respectively. We test our method on both cross-view and cross-subject protocols.
NTU RGB+D 120[46]: This dataset extends NTU RGB+D 60, a total of 113,945 samples over 120 classes performed by 106 volunteers and captured with 32 different camera setups. Like the NTU RGB+D 60 data set, it adopts the SsssCcccPpppRrrrAaaa format (for example, S001C001P001R001A003.skeleton ), where the last three digits of S represent the setting number (the angle of the camera setting), the last three digits of C represent the camera ID, and the last three digits of P represent Action executor (person) ID, the last three digits of R represent the number of repetitions of the action (repeat 1 or 2 times), the last three digits of A represent the action label, There are a large number of samples with missing bones in the data, and we deleted them as required during training and testing. The original paper on this dataset recommends two benchmarks: (1) the cross-subject (X-Sub) benchmark and (2) the cross-setup (X-Setup) benchmark, on which we test our method.
Multiview Activity II (UWA3D)[47]: dataset contains 30 human actions performed 4 times by 10 subjects. 15 joints are recorded, and each action is observed from four views: frontal, left and right sides, and top. The dataset is challenging due to many views and the resulting self-occlusions from considering only parts of them. In addition, there is a high similarity among actions, e.g., the two actions “drinking” and “phone answering” have many key points being nearly identical, and in the dynamic key points, there are subtle differences. We tested our approach on one of these perspectives.
Evaluation
We use a K-neighbors (KNN) classifier to evaluate our method of action recognition task. Specifically, we apply the KNN classifier (with
Accuracy comparison
We compare the performance of the NTU RGB+D 60, NTU RGB+D 120, and UW A3D datasets with previous skeleton-based unsupervised action recognition methods. The results of these three comparisons are shown in Tables 2, Table 3, and Table 4, respectively. The four benchmarks of our method on the NTU RGB+D 60 and NTU RGB+D 120 datasets are far superior to other methods, reaching the state-of-the-art. Especially in the X-View benchmark, our method achieves an accuracy of 0.884, demonstrating the accuracy of our method. The performance of our method on the UW A3D dataset is only 0.012, different from the current state-of-the-art method. We think the main reason is that the capacity of the UWA3D dataset is too small, significantly limiting what our model can extract during training. Secondly, the number of samples in the data set is too small to cause large errors, and the skeleton key points of the UWA3D data set are only 15, which has a great impact on our extraction of spatial features. Even so, we have surpassed other methods, second only to RGCA [48].
Comparison with unsupervised learning methods on NTU RGB+D 60 dataset
Comparison with unsupervised learning methods on NTU RGB+D 60 dataset
Comparison with unsupervised learning methods on NTU RGB+D 120 dataset
Comparison with unsupervised learning methods on UWA3D dataset
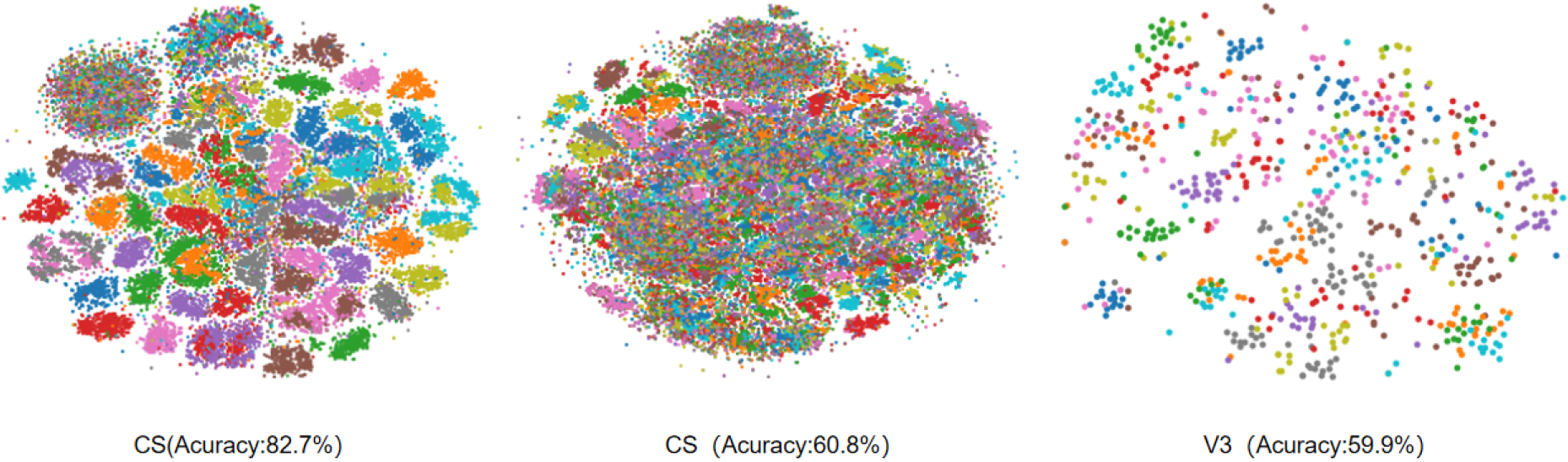
t-SNE visualization results: We selected all the categories of the three datasets for t-SNE visualization. The embedding space dimension we set was 2, and the PCA initialization method was used. The random seed value was 42. The results are shown in Fig. 6. Obviously, the visualization results of the NTU60 data set are awe-inspiring, which verifies our super high accuracy rate. Other data sets have not achieved such impressive results, which is related to their own accuracy rate, but they are basically clustered successfully.
Confusion matrix visualization results: We generated the confusion matrix diagrams of the three data sets, and the results are shown in Fig. 7. The visualization results of the NTU60 data set are better. For the NTU120 data set, we found that various actions of a single person can basically be recognized. However, the recognition effect of two-person interactive motion could be better. The reason is that we have adopted the same method as single-person action in the feature extraction of two-person interactive movement, and we have not been able to specially deal with the relationship between a total of 50 key points between two people. , this is where we need to improve in future work. In the UWA3D dataset, we found that the distinction between similar actions is poor, such as drinking and making a phone call, walking, and walking irregularly. As mentioned in the dataset introduction, the dataset is challenging, and there is a high similarity between actions.
Confusion matrices for testing MD-STA performance on the three datasets (from left to right): NTU RGB+D 60 (60 actions); NTU RGB+D 120 (120 actions); UWA3D (30 actions).
t-SNE visualization results: We selected all categories of the three data sets respectively for t-SNE visualization on the time branch. The embedded space dimension, initialization method, and random seed we selected were consistent with the double path, and the results are shown in Fig. 8. In the NTU60 data set, it was obvious that the effect of the single-path time dimension was inferior to that of the double-path.
t-SNE visualization of learned features on the three datasets (from left to right): NTU RGB+D 60 (60 actions); NTU RGB+D 120 (120 actions); UWA3D (30 actions).
Confusion matrix visualization results: We generated the confusion matrix diagram of the three data sets in the time branch, and the results are shown in Fig. 9.
Model complexity
Confusion matrices for testing MD-STA performance on the three datasets (from left to right): NTU RGB+D 60 (60 actions); NTU RGB+D 120 (120 actions); UWA3D (30 actions).
Analysis of time and space complexity visualization results: In order to verify the reduction effect of the module (SAD) on the amount of computation and the complexity of time and space, we generated graphs of the time spent on each round of training for three data sets, processor: Intel(R) Core(TM) i7-10700 CPU@2.90GHz(16 CPUs), 2.9 GHz, chip type: NVIDIA GeForce RTX 2060. The results are shown in Fig. 10. Compared with other methods without a (SAD) module. Our method leads by a large margin in terms of computational speed. And compared with other models in terms of time and space complexity, our model has a lower complexity, as shown in Table 5. Thus, it is proved that our module (SAD) reduces the computational load of the model and reduces the time and space complexity.
Chart of training time per round on the three datasets (from left to right): NTU RGB+D 60 (60 actions); NTU RGB+D 120 (120 actions); UWA3D (30 actions).
To verify the effectiveness of each component in our proposed framework, we conduct ablation studies on NTU-60. All the experiments are conducted in the context of the skeleton-based action recognition downstream task.
Effectiveness of spatio-temporal fusion features: We conducted experiments on different branches, and the experimental results are shown in Table 6 and Fig. 11. The effect of the time branch exceeds that of the space branch, and the effect of the double branch exceeds that of any other branch. The results show that the two-flow network structure of our model is necessary.
Comparisons on NTU RGB+D 60 dataset on different model flows
Comparisons on NTU RGB+D 60 dataset on different model flows
Comparisons on NTU RGB+D 60 dataset on different model structures
Confusion matrices for testing MD-STA performance on the different branches (from left to right): MD-SA; MD-TA; MD-STA.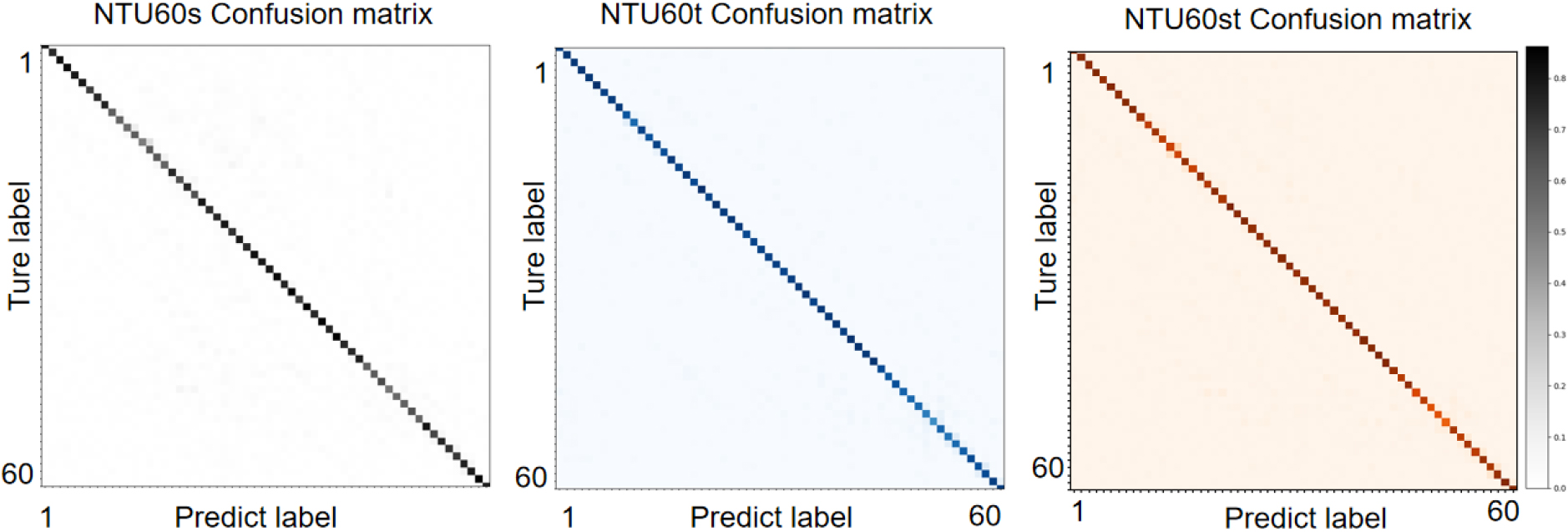
The effectiveness of each module: To avoid the influence of spatiotemporal fusion features on each module, we conducted experiments on different model structures in a single time branch, and the experimental results are shown in Table 7 and Fig. 12. The effect of structural EPDG exceeds that of structural EPG, proving that our Disstiling module is necessary, while the effect of structural MD-TA exceeds all other structures, proving that the use of Dim-reduction Fusion(DRF) modules is also required. The results show that each module of our model is a necessary condition for action recognition tasks.
The effectiveness of different attentions: Table 8 illustrates the performance of the model when different attention mechanisms are used in the time branch. The accuracy of the model using ScreenAttention exceeds that of the model using FullAttention, but the gap is not noticeable enough. The gap is not obvious enough because Full attention calculates the relationship between all sequence frames and compensates for its accuracy with a high amount of calculation. The results show that modeling with ScreenAttention is effective.
Comparisons on NTU RGB+D 60 dataset with different attentions
The effectiveness of different layers: To evaluate the effect of different RNN layers, we compare the models with different bidirectional RNN layers. From Table 9, we can clearly see that too many bidirectional RNN layers will lead to a loss of accuracy. Our model achieves the best results when the number of layers of the bidirectional neural network is set to 2. We infer that this is because of the gap between the pre-training task and the final action recognition task. Too many bidirectional RNNs will lead to vanishing gradients, thereby reducing the performance of the action recognition task. And the effect of single-layer bidirectional RNN is even worse. Only one layer of RNN neural units is not enough, and the feature extraction ability is not enough. The results show that modeling with a two-layer bidirectional RNN is effective.
Comparisons on NTU RGB+D 60 dataset with different layers in Dim-reduction Fusion(DRF) module
Comparisons on NTU RGB+D 60 dataset with different distillation amplitude and distillation times
t-SNE visualization of learned features on NTU RGB+D 60 for three structure (from left to right), EPG; EPDG; MD-STA.
The effectiveness of distilling intensity: To further explore the effects of distilling intensity on the final performance, we conduct ablation experiments with different distillation amplitudes and distillation times. The recognition results are shown in Table 10. It can be easily observed that the best performance is achieved when the sequence length is set to L/4. We attribute this to higher distillation intensity leading to the loss of effective features, while less distillation benefits the redundancy of invalid features, and neither of them can better characterize the skeleton action sequence.
In this paper, we propose a new bone-based unsupervised model for motion recognition. Compared with the previous approach, our system achieves better performance because the new training strategy has a powerful encoder to learn more efficient spatiotemporal fusion features, a slightly deleted sequence, and a weak decoder to enhance the training of the encoder so that the network learns more separable representations. Experimental results show that our unsupervised model can effectively learn different action features on the three benchmark data sets, and is better than the previous unsupervised method.
In this paper, our method failed to extract the hierarchical time features of bone sequences. The sequence with length L could be divided into several segments to extract the connections between each segment, or the spatial key points could be fused into several parts of the body to extract its geometric spatial features combined with human osteology. These two features gradually become important features of human 3D bone recognition. In future work, hierarchical time features will be added into the Embedding layer, and a module with the ability to extract geometric space features will be added into the Screening Self-attention layer combined with the human skeleton so that the model will achieve better results.
Declarations
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Footnotes
Acknowledgments
This work is supported by the National Natural Science Foundation of China under grant 61771322 and the Shenzhen Science and Technology Program under Grant JCYJ20220531100814033.