
Abstract
Convolutional neural networks (CNNs) have been successfully applied to music genre classification tasks. With the development of diverse music, genre fusion has become common. Fused music exhibits multiple similar musical features such as rhythm, timbre, and structure, which typically arise from the temporal information in the spectrum. However, traditional CNNs cannot effectively capture temporal information, leading to difficulties in distinguishing fused music. To address this issue, this study proposes a CNN model called MusicNeXt for music genre classification. Its goal is to enhance the feature extraction method to increase focus on musical features, and increase the distinctiveness between different genres, thereby reducing classification result bias. Specifically, we construct the feature extraction module which can fully utilize temporal information, thereby enhancing its focus on music features. It exhibits an improved understanding of the complexity of fused music. Additionally, we introduce a genre-sensitive adjustment layer that strengthens the learning of differences between different genres through within-class angle constraints. This leads to increased distinctiveness between genres and provides interpretability for the classification results. Experimental results demonstrate that our proposed MusicNeXt model outperforms baseline networks and other state-of-the-art methods in music genre classification tasks, without generating category bias in the classification results.
Introduction
Music genre classification (MGC) [1] is an important task in the field of music information retrieval (MIR), and it holds significant significance for the music industry, music recommendations, search engines, and organizations. With the diversification of music development, genre fusion has become a common phenomenon. It promotes music exchange and collaboration while profoundly influencing music creation. However, this also gives challenges to the task of genre classification. Traditional classification methods lack sufficient discriminative power, making it difficult to effectively differentiate between multiple elements in fusion music.
There is no universally agreed-upon methodology for defining genres, making precise definitions difficult. Compared to other classification tasks, the label of music genre is subjective in nature. It is influenced by various factors such as culture, national context, and ethnic traditions. With the continuous development of music, artists are blending features and styles from different genres to create new music genres. This phenomenon is known as genre fusion, and it has resulted in music that exhibits cross-genre similarities. For example, the influence of blues music has permeated into country music and rock music, contributing to their development and evolution. Blues shares similarities with them in various aspects such as melody, rhythm, and harmony. Rock music, in particular, has evolved from Blues, Country, and Rhythm and Blues (R
Some researchers have recognized the impact of cross-genre similarity. For example, Esparza et al. [2] analyzed the subtle influences between rhythm and genre from a musicological perspective by synthesizing quantitative analysis by considering Computational and Musicological. Costa et al. [3] noticed a high confusion rate between the Forró and Gaúcha genres in their experiments, and consider that this could be explained by their similarities in rhythm and timbre content. These explanations remain somewhat ambiguous and do not propose a solution to address the issue of result bias in classification tasks. However, they highlight the connection between cross-genre similarities and features such as rhythm and timbre, which express musical characteristics. Therefore, to address the classification problem in fusion music, it is necessary to place more emphasis on features that capture the musical traits and better adapt to and understand the complexity and diversity of fusion music.
ConvNeXt-Tiny network structure.
With the successful application of deep learning and CNNs, recent research has focused on improving model structures for classification based on spectrograms. Generally, to extract deep features and improve classification performance, the depth, and complexity of the network are increased, which leads to an increased risk of overfitting and higher computational demands. To address this issue, Liu et al. [4] analyzed the structure and parameters of the Swin Transformer and proposed the ConvNeXt model as illustrated in Fig. 1, a pure convolutional neural network based on the improvement of ResNet-50. It achieved better classification results through architectural optimizations, rather than model enrichment. The comprehensive performance surpasses Transformer, demonstrating that a well-designed model structure and architecture are more effective than increasing complexity. However, for music classification tasks, CNN architectures still have some limitations. Music spectrograms differ from regular images as they encompass the temporal information of the audio signal. The temporal information plays a vital role in capturing the rhythm, dynamics, and expression in music, which cannot be fully harnessed by CNN networks. Therefore, we propose a content-based music genre classification model called MusicNeXt. It has the advantage of effectively extracting musical features and accurately classifying them. Specifically, we introduced a genre-sensitive adjustment layer. It enhances the learning of differences between different genres by imposing intra-class angular constraints. This layer diminishes the impact of shared elements among fused genres, thus reducing bias in the classification results.
Our contributions in this paper can be summarized as follows:
To extract deep features from the temporal information in spectrograms, a network stacking module using depthwise convolution is designed. A lightweight network called MusicNeXt is proposed for MGC tasks. A genre-sensitive adjustment layer is designed to enable differentiated classification, addressing the bias issue caused by genre fusion. This improves classification accuracy and provides a geometric interpretation of the classification results. Compared to several state-of-the-art methods, our approach achieves excellent performance on three datasets while significantly reducing computational costs.
In order to extract music features more effectively, researchers have been continuously improving the architectures of neural networks. In this section, we introduce the progress made in CNNs for MGC using spectrograms, and describe the improvements in feature extraction.
Music genre classification with spectrograms
In recent years, with the rapid development of deep learning in computer vision, neural networks have also been successfully applied to various tasks in MIR, such as music tagging [5], automatic singer recognition [6], music emotion recognition [7] and more. Deep learning models combine low-level features to discover distributed representations of data, enabling the learning of abstract high-level features. This approach has led to an increasing number of researchers considering content-based music classification tasks as image classification problems, and replacing traditional methods of manually selecting features with improved feature learning through model enhancements.
Dong et al. proposed BCRSN [7], a bidirectional convolutional recurrent sparse network based on convolutional neural networks (CNNs) and recurrent neural networks (RNNs), for music emotion analysis. This method adaptively learns influential features containing sequential information from spectrograms, reducing computational complexity. They also introduced a weighted mixed-binary representation method, transforming regression prediction into a weighted combination of multiple binary classification problems. Bian et al. [8] utilized DenseNet as a building block for the CNN architecture to enhance the performance of music audio classification and achieved data augmentation for music-specific data through time overlap and pitch shifting of spectrograms. Yu et al. [9] observed that spectrograms with different temporal resolutions have varying importance, and proposed a novel model combining bidirectional recurrent neural networks with attention mechanisms, introducing parallel and serial attention mechanisms for classification. Chang et al. [10] designed a multi-scale SincNet (MS-SincNet) for learning 2D representations from 1D raw waveform signals, jointly learning 1D and 2D kernels for classification. Liu et al. [11] proposed a CNN architecture that incorporates multi-scale audio features, considering the sensitivity of feature performance to frequency accumulation of sound events in the time domain. Inspired by traditional K-nearest neighbors (KNN), Zhang et al. [12] introduced KNN-Net for automatic singer identification (SID), restricting the decision scope of CNN within a relative range.
These previous studies have all utilized neural networks for classification tasks in MIR. Compared to traditional handcrafted features, the improved neural network models have a distinct advantage in automatically extracting features, resulting in better classification performance. However, these studies failed to recognize the influence of genre fusion on classification bias and did not fully leverage the temporal information of the spectra for classification. They cannot discern multiple musical elements, and as a result, the classification results still exhibit bias.
Improvements in feature extraction methods
Extracting effective music features is crucial for music classification. During the feature extraction process in traditional music classification tasks, short-term features are initially extracted from the music signal to capture its local or transient characteristics. Then, these short-term features are integrated or aggregated to form long-term features that reflect the overall nature of the music signal. The classical audio features used in MGC include Mel-frequency cepstral coefficients (MFCC) [13], short-time energy [14], zero-crossing rate (ZCR), spectral centroid/flux [15], discrete wavelet coefficient histogram (DWCH) [16], timbral texture, rhythmic content, and pitch content feature groups [17].
Some researchers have improved the classification performance by enhancing the feature extraction methods. Dielema et al. [18] conducted feature learning by analyzing raw audio signals to enable the model to autonomously discover audio frequency decompositions, as well as phase and shift-invariant feature representations. Choi et al. [19] proposed a CRNN model for music tagging that handles feature extraction and summarization tasks. Liang et al. [20] introduced the PiRhDy that integrates pitch, rhythm, and dynamic perception features. It is based on symbolic music in melodic and harmonic contexts and can be applied to various MIR tasks. Cai et al. [21] proposed a novel auditory-inspired feature set based on auditory image processing, which mimics the human auditory system. They also presented a classification framework that combines auditory image features with traditional acoustic and spectral features.
These studies have approached feature extraction from different perspectives, aiming to capture features that better align with the characteristics of music for classification purposes. However, fusion music often exhibits similar characteristics, and assigning equal weights to all features is unreasonable. To address this issue, we introduced genre-sensitive adjustment layers, enhancing the separability between genres and reducing the intra-class distance within the same genre.
Method
In this section, we introduce the design of MusicNeXt. It is a deep convolutional model aimed at extracting musical features and conducting differentiated classification for fused music.
Architecture of MusicNeXt
The MusicNeXt architecture consists of a feature extraction module and a classifier. The structure of MusicNeXt is illustrated in Fig. 2. In the feature extraction module, we start with the stem layer, which is used for preprocessing the input data and extracting local features for subsequent processing. It is followed by four stacked basic modules that utilize deep convolutions to extract temporal and frequency-related information from the music. At the same time, skip-connected connections are employed to alleviate the problem of gradient vanishing and promote model convergence. The modules are connected with downsampling to reduce computational burden and integrate deep-level features. Moreover, we have removed the batch normalization (BN) layers and most of the activation functions, keeping only the ELU activation function for the deep convolutional layers. This improves the stability and generalization capability of the model. In the ConvNeXt architecture, the feature extraction module achieves the best experimental results with the stacking ratio of 3:3:9:3. Therefore, we have considered this as a reference for our model.
MusicNeXt network structure.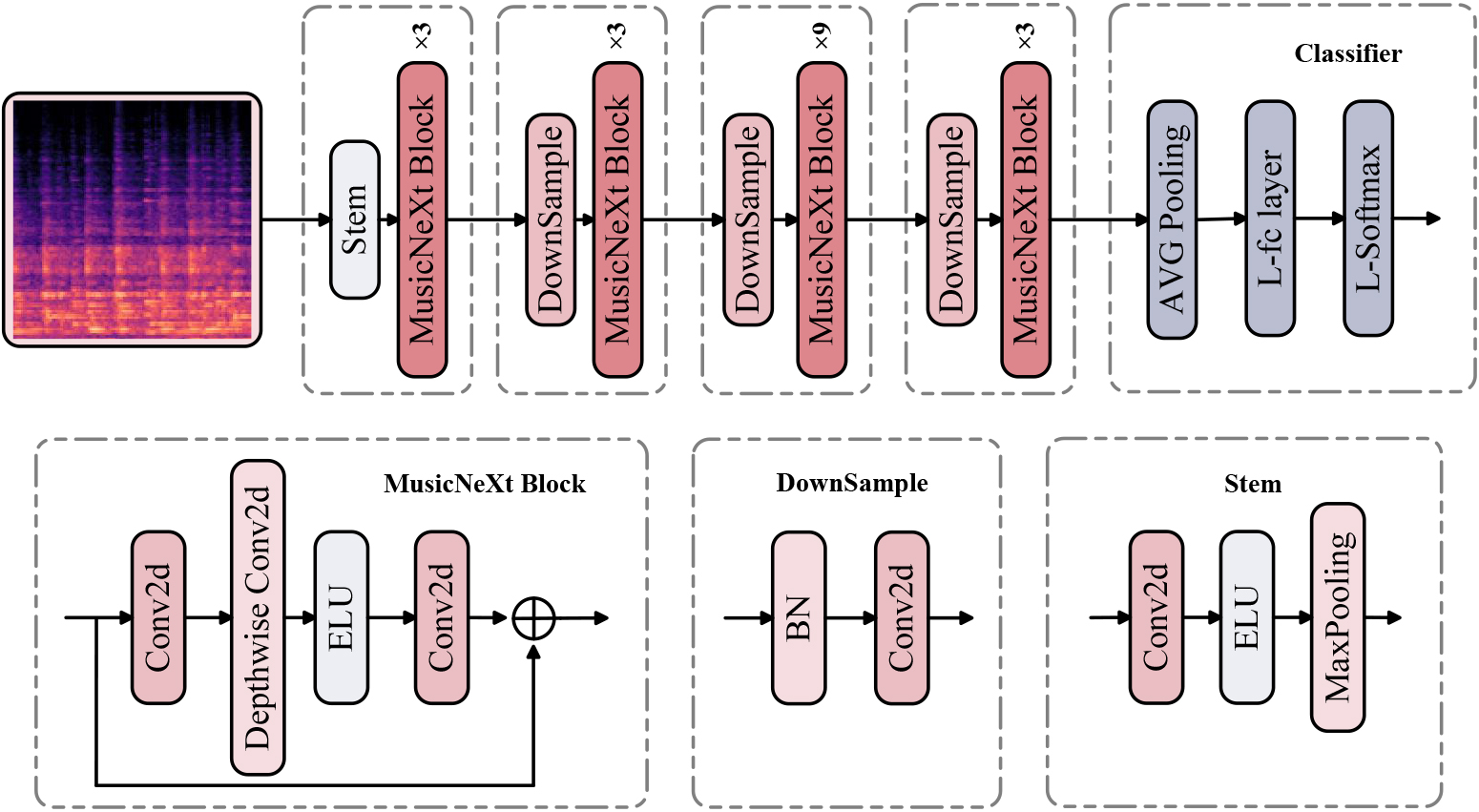
In the classifier part, we integrate the global information of the spectrograms, and employ a fully connected layer with L-softmax to map the features to the respective categories. L-softmax is an improved fully connected structure that incorporates angular cosine to enhance the boundaries between classes, thereby improving inter-class discrimination. It allows genres with partially similar features to have larger inter-class distances. Subsequently, L-softmax loss is employed to adjust the sensitivity to music genres, aiming to enhance the model’s ability to capture differences among different music genres and eliminate classification bias in the results. Based on the improvements made to the classifier component and the hints about its classification performance, we refer to this module as the genre-sensitive adjustment layer.
In traditional convolution, the kernel slides and performs convolution operations on the input feature map. At each sliding position, the local pixels are element-wise multiplied with the kernel and the results are accumulated to generate the output feature map. This operation captures both global and local features of the image, and the parameter count is given by:
where
Depthwise convolution is a convolutional operation that first performs separate convolutions on each input channel and then linearly combines the features from different channels to generate the final output feature map. Each channel of the input feature map is convolved with its corresponding kernel, which is responsible for extracting specific local features in that channel. The parameter count for depthwise convolution is:
a
The advantage of depthwise convolution lies in capturing multi-level features from the width perspective, effectively extracting deep features. By stacking depthwise convolutional layers, convolutional neural networks can learn more complex and abstract deep features, enhancing the network’s expressive power and learning capability. In the field of MIR, depthwise convolution can better learn music features and patterns, leading to improved performance and results in tasks such as music classification and music generation.
Differences between MusicNeXt, ConvNeXt, and ResNet in basic stacking block.
The Exponential Linear Unit (ELU) activation function was introduced by Clevert et al. [22] in 2015 as a solution to the vanishing gradient problem. It is defined as:
where
Compared to the Rectified Linear Unit (ReLU), ELU allows for negative values, which leads to function outputs close to zero, similar to the effect of Batch Normalization. This property enhances the model’s sensitivity to variations in the input data while requiring lower computational complexity. Additionally, ELU exhibits a soft saturation property, which improves its tolerance to noise and enhances the stability and generalization capabilities of the model.
In recent years, the effectiveness of the ELU has been demonstrated in the field of MIR [6, 23, 24]. Therefore, we use ELU as the activation function in our model. Due to the characteristics of ELU, it can achieve good performance in the network. As shown in Fig. 3, we have deleted the normalization layers from the stem and MusicNeXt blocks.
Comparison of the accuracy of MusicNeXt with softmax and L-softmax. The horizontal axis represents the number of epochs, while the vertical axis represents the accuracy.
In the development of music, different genres mutually influence each other, and some genres exhibit high similarity. This emphasizes the importance of improving both intra-genre compactness and inter-genre separability. To enhance cross-genre similarity classification, we introduce genre-sensitive adjustment in this study, replacing the conventional softmax loss with L-softmax loss. Convolutional neural networks commonly use the softmax and cross-entropy loss functions as classifiers. The softmax loss function is defined as:
where
Although softmax loss is simple and performs well, it lacks boundary discrimination and class sensitivity, making it less effective for music genre classification. In this paper, we introduce the L-softmax with a large-margin angle constraint to enhance the learning of differences between different classes. As shown in Fig. 4, it demonstrates superior performance compared to the softmax loss. Moreover, L-softmax exhibits better robustness against the vanishing gradient problem, leading to more stable network training and providing interpretability for neural network classification. The L-softmax loss function is defined as:
where
The genre labels and the actual number of songs used in the datasets
We evaluate our method on three widely-used public datasets. In this section, we will provide descriptions of these datasets and then give the experimental results. MusicNeXt was compared with state-of-the-art methods to verify the effectiveness of the approach.
Datasets
In this work, we use the GTZAN, ISMIR2004, and Extended Ballroom for evaluation performance. Detailed information about the datasets, including the genre labels and actual number of songs used, is provided in Table 1.
GTZAN.
GTZAN is a publicly available dataset for music genre classification, created by Tzanetakis [17]. The dataset consists of 10 genres: blues, classical, country, disco, hip-hop, jazz, metal, pop, reggae, and rock, each with 100 music clips of 30 seconds, totaling 1000 clips. The GTZAN dataset has been widely used in many studies for music genre classification. In this work, we divided the given training dataset employing a random 8:2 split.
ISMIR2004.
The ISMIR2004 dataset [25] consists of 1458 music tracks from 6 unbalanced classes of genres, including classical, electronic, jazz-blues, metal-punk, rock-pop, and world. The dataset has been split with 729 music tracks used for training and the remaining for testing. In addition, the full songs were not used in the experiment. We deleted audio tracks that were less than 30 seconds long, and a 30-second audio track was segmented from each song. If the duration of the audio is less than 60 seconds, take the last 30 seconds of the audio, else take the 30 seconds after the first 30 seconds of the audio. After preprocessing, we had 724 files for training and 720 files for testing in our dataset.
Extended Ballroom.
The Extended Ballroom dataset is a genre classification dataset proposed in 2016 by Marchand [26], which extended the original Ballroom dataset. There are 4,180 tracks of 13 genres: Chacha, Jive, Quickstep, Rumba, Samba, Tango, Vienne sewaltz, Waltz, Foxtrot, Pasodoble, Salsa, Slow waltz, Wcswing, and each music track in Extended Ballroom lasts about 30 seconds. To balance the dataset, we used the first 9 genres for the experiment.
Experiment settings
Data preprocessing
In this work, we employed the short-time Fourier transform (STFT) provided by Librosa to extract mel-spectrograms with 128 mel-filters, resulting in spectrograms of size 2560
A spectrogram image obtained from the STFT of a 30-second Blues audio file. Each audio segment is divided into 10 fragments, with each fragment sized at 256 
In this study, accuracy and test loss are utilized as the evaluation metric to assess the classification performance of the proposed approach. And the confusion matrix is used to more visually demonstrate the effect of our model on the classification bias.
Implementation details
In this experiment, we employed the Adam optimizer for model training and utilized random horizontal flipping of images as a data augmentation technique to mitigate overfitting. The model was configured with a batch normalization size of 50 and trained for 50 epochs. Following the strategy of ConvNeXt, we increased the number of channels from 64 to 96 and set the margin parameter
Experimental results
Selection of the angular margin values
The angular margin is an important parameter that influences the genre-sensitive adjustment layer. To investigate the impact of the parameter
Accuracy of MusicNeXt under different angular margin values on GTZAN, ISMIR2004, and Extended Ballroom. The horizontal axis represents the angular margin value, while the vertical axis represents the accuracy.
Experimental results of comparing different stacking block ratios in MusicNeXt and MusicNeXt with softmax.
To study the performance differences of different feature extraction module stacking ratios, we conducted experiments by varying the stacking ratios, and the experimental results are shown in Fig. 7. We can observe that the 3:3:9:3 stacking ratio for the feature extraction block achieved the best classification performance for both the MusicNeXt and MusicNeXt with softmax models on the three datasets. This indicates that appropriately increasing the stacking ratio of stage-3 improves the classification performance, but too many stage-3 modules result in a worse performance. Based on the results in Fig. 7, we chose the 3:3:9:3 stacking ratio as the baseline for the feature extraction module.
Comparison with the state-of-the-art
Comparison of the performance of different state-of-the-art methods on the GTZAN dataset
Comparison of the performance of different state-of-the-art methods on the GTZAN dataset
Comparison of the performance of different state-of-the-art methods on the ISMIR2004 dataset
Comparison of the performance of different state-of-the-art methods on the Extended Ballroom dataset
We compare our proposed method with the state-of-the-art methods based on the GTZAN, ISMIR2004, and Extended Ballroom datasets. According to the results shown in Tables 2–4, our classification accuracy performs the best on the GTZAN and Extended Ballroom datasets, reaching 92.45% and 95.82%, respectively. On the ISMIR2004 dataset, the FusionNet method proposed by Ng et al. [27] achieves the best classification performance. FusionNet considers eight different features and combines them, obtaining the best test results on each dataset. However, when considering the mel-spectrogram as a single feature, its classification accuracy is only 86.42%. This indicates that our method consistently achieves the best classification performance when performing music genre classification tasks using a single model.
MusicNeXt demonstrates its classification advantage on the GTZAN dataset, which contains a significant amount of genre fusion. In the ISMIR2004 dataset, similar genres are merged into a single class for classification tasks due to an imbalanced distribution of song quantities. The Extended Ballroom dataset clusters different dance genres with similar timbres together. These two datasets artificially eliminate some cross-genre fusion issues, yet our model still exhibits strong feature extraction capabilities for classification. Overall, the results demonstrate that our method exhibits excellent generalization capabilities on datasets of different scales, suggesting potential applications in handling other MIR problems in the future.
The ablation to evaluate the effectiveness of the proposed method with three baseline models on the GTZAN, ISMIR2004, and Extended Ballroom datasets
Confusion Matrices (%) of MusicNext with Softmax
Confusion Matrices (%) of MusicNext with L-Softmax
As shown in Table 5, neural networks with L-softmax generally outperform networks with softmax in all tested models. This indicates that L-softmax, with its large margin angle constraint, provides better class discrimination. Furthermore, our model achieved the highest classification accuracy on the GTZAN, ISMIR2004, and Extended Ballroom datasets, reaching 92.45%, 92.13%, and 95.82% respectively. These results demonstrate our model’s effective ability to extract deep features and its good compatibility with L-softmax.
For the GTZAN dataset, most studies [21, 11] have misclassified genres as Rock. This aligns with the understanding that the Rock genre often blends and influences other genres, highlighting the impact of cross-genre similarity on classification. As shown in the confusion matrix in Tables 6 and 7, our model effectively addresses this issue by reducing the bias towards a specific genre and improving the overall classification accuracy.
Figure 8 presents a comparison of training loss curves for different networks on the GTZAN dataset. The graph illustrates the contrast in loss between MusicNeXt and three baseline networks. The results indicate that our network exhibits enhanced learning capacity, enabling it to rapidly grasp the deep features of spectrograms.
Comparison of MusicNeXt and other baseline models in music genre classification, where MusicNeXt-S is MusicNeXt with softmax. The horizontal axis represents the number of epochs, while the vertical axis represents the loss.
In this paper, we introduce a CNN architecture called MusicNeXt for precise music genre classification. It effectively utilizes temporal information from spectrograms to extract musical features and employs intra-class angle constraints to enhance the learning of differences between different genres. As a result, our model can accurately classify fused music and address the issue of classification bias. We stack feature extraction modules to extract time and frequency-related information from music using deep convolutions. Additionally, we utilize the genre-sensitive adjustment layer to enhance intra-class compactness and significantly improve the classification performance for fused music. We evaluate our model on multiple datasets and demonstrate its superiority over state-of-the-art methods, showing its effectiveness for MGC tasks.
In the present work, we adopt the genre-sensitive adjustment layer based on L-softmax, which improves feature representation learning but is sensitive to data distribution. It may not necessarily yield better results than softmax for other datasets. Therefore, in future work, we plan to explore other improved softmax variants for classification performance and further investigate the performance of our proposed model in other MIR tasks.
Footnotes
Acknowledgments
This work is supported by Tianjin “Project