
Abstract
The goal of feature selection in machine learning is to simultaneously maintain more classification accuracy, while reducing lager amount of attributes. In this paper, we firstly design a fitness function that achieves both objectives jointly. Then we come up with a chaos-based binary dragonfly algorithm (CBDA) that incorporates several improvements over the conventional dragonfly algorithm (DA) for developing a wrapper-based feature selection method to solve the fitness function. Specifically, the CBDA innovatively introduces three improved factors, namely the chaotic map, evolutionary population dynamics (EPD) mechanism, and binarization strategy on the basis of conventional DA to balance the exploitation and exploration capabilities of the algorithm and make it more suitable to handle the formulated problem. We conduct experiments on 24 well-known data sets from the UCI repository with three ablated versions of CBDA targeting different components of the algorithm in order to explain their contributions in CBDA and also with five established comparative algorithms in terms of fitness value, classification accuracy, CPU running time, and number of selected features. The results show that the proposed CBDA has remarkable advantages in most of the tested data sets.
Keywords
Introduction
The expansion of data in fields such as data mining, pattern recognition, and machine learning has resulted in an increase in unnecessary and repetitive information, hindering the development of learning algorithms [1]. In high-dimensional data sets, there may be numerous unhelpful or misleading features. Therefore, it is crucial to find ways to efficiently select valid data by removing irrelevant ones from the data set being analyzed [2].
Feature selection is a type of dimensionality reduction technique that aims to choose the most optimal subsets from entire data sets while maintaining the classification accuracy of the original data [3]. Feature selection methods are commonly used in various fields, including active matter [4], supervised learning [5], compression, and cluster analysis in spectroscopy [6], among others.
There are three main types of feature selection methods: filters, wrappers, and embedded approaches [7]. The filter-based methods assess features based on their statistical scores, keeping those with high scores and discarding those with low scores [8]. The wrapper-based methods utilize a defined classification algorithm, such as a machine learning classifier, to determine the quality of feature subsets. This method typically achieves better classification accuracy than filter-based methods [9]. The embedded approach is a specific case of the wrapper-based method, as it is integrated into the learning process [10].
Feature selection involves selecting subsets of features and evaluating their effectiveness. The search method used for feature selection can be categorized into three types: complete, random, and heuristic search. In the complete search method, all possible feature subsets are evaluated, which can be impractical for high-dimensional data sets since the number of combinations is
Swarm intelligence algorithms are a type of meta-heuristic algorithm that generates a population of initial solutions and updates them at each iteration based on the previous iteration. Compared to traditional methods, swarm intelligence algorithms present distinct advantages in dealing with feature selection problems [13]. Several swarm intelligence algorithms, such as particle swarm optimization (PSO) [14], invasive weed optimization (IWO) [15], ant colony optimization (ACO) [16], gray wolf optimization (GWO) [17], artificial bee colony (ABC) [18], and grasshopper optimization algorithm (GOA) [19], are commonly applied to handle optimization problems. Among these algorithms, dragonfly algorithm (DA) was originally proposed by Mirjalili et al. in 2016 [20] that simulate the behaviors of dragonflies in nature, which can effectively contribute to find the global optimal solutions [21] in some optimized problems. Nevertheless, the deficiencies of DA are also obvious, such as being designed for continuous optimization problems and lacking the ability to converge quickly or avoid local optima when used for complex optimization problems [22]. For this reason, there is ongoing research focused on enhancing the efficiency of conventional DA for feature selection optimization.
The key accomplishments of this paper can be outlined as follows:
Our goal is to achieve two optimization objectives: reducing the number of selected features while improving classification accuracy. To achieve this, we have developed a fitness function aimed at optimizing both objectives simultaneously. We have developed a novel algorithm named the chaos-based binary dragonfly algorithm (CBDA) to address the fitness function we formulated. CBDA leverages a chaotic map to enhance the exploitation potential of the traditional dragonfly algorithm by regulating the primary parameters of dragonflies’ movements. Moreover, we have integrated a fitness-based evolutionary population dynamics (EPD) mechanism to maintain a balance between the algorithm’s exploration and exploitation capabilities. Lastly, we have introduced a binarization technique to transform the continuous solution space into binary, rendering it appropriate for feature selection solutions. We have carried out comprehensive experiments to assess the efficacy of CBDA against other algorithms on 24 well-known UC Irvine (UCI) Machine Learning Repository data sets. Furthermore, we have evaluated the algorithms based on various criteria such as fitness value, classification accuracy, CPU running time, and the number of selected features. In particular, the experiments are categorized into two sets: the ablation experiments involving different iterations of CBDA, and the comparative experiments involving five established optimized algorithms (notably, these include four meta-heuristic algorithms and one neural network algorithm). Furthermore, the superoirity of CBDA are additionally consolidated and outlined.
The remaining sections of this paper are structured as follows. In Section 2, we provide a concise overview of the relevant literature. Section 3 outlines the background of the research focus in this paper. Section 4 provides an in-depth explanation of CBDA. Section 5 presents the outcomes of the experimental analysis. Lastly, for the Section 6, we make a conclusion to the whole research and suggest potential areas for future research.
Related work
The wrapper-based selection methods are playing important roles in feature selection optimizations [23]. The wrapper-based methods treat feature selection as a black box, where meta-heuristic algorithms and classifier are deployed to obtain the optimal subset [24]. Many classical meta-heuristic algorithms have been modified to solve the feature selection problems, such as binary bat algorithm (BBA) [25], bare bones particle swarm optimization algorithm (BPSO) [26], binary gray wolf optimization algorithm (BGWO) [27], binary gravitational search algorithm (BGSA) [28], and so on.
In recent years, more and more new-designing algorithms are proposed to optimize various wrapper-based feature selection problems because of the importance they play. For instance, Hou et al. [29] propose a binary improved fruit fly optimization algorithm (BIFFOA) and employ four different EPD strategies to enhance the BIFFOA in solving feaure selection problems. Thaher et al. [30] propose an efficient feature selection approach based on a Boolean variant of BPSO boosted with EPD, aiming at avoiding local optima obstacles via boosting the algorithm’s exploration ability. Mafarja et al. [31] innovatively propose an enhanced hybrid meta-heuristic approach using GWO and WOA to alleviate the drawbacks of both algorithms in feature selection. In [32], Xue et al. propose a self-adaptive particle swarm optimization (SaPSO) algorithm with a typical self-adaptive mechanism for feature selection, particularly for large-scale feature selection. In literature [33], the researchers utilize binary variants of the Butterfly Optimization Algorithm (BOA) to select the optimal feature subset for classification purposes in a wrapper-mode. In [34], Paniri et al. propose a novel multi-label relevance-redundancy feature selection method named MLACO, which is based on Ant colony optimization (ACO) to search in the features space to find the most promising features through introducing two unsupervised and supervised heuristic functions. Alilbrahim et al. [35] present a hybrid optimization approach combining with the slap swarm algorithm (SSA) and PSO to improve the efficacy of the exploration and the exploitation steps. Zhang et al. [36] introduce the Gaussian mutation operator and the chaotic local search strategy into the basic fruit fly optimization algorithm (FOA) to improve the exploitative tendencies and enhance the local searching ability of FOA in dealing with feature selection problems.
There are some state-of-the-art researches related to DA algorithms in feature selection optimizations. DA was designed to solve the continuous problems, thus transfer functions are required to convert the conventional DA to a binary one (BDA) [37], by which enables it tackle feature selection optimizations. Hammouri et al. [38] use different strategies to update the values of its five main coefficients of BDA to solve feature election problems. Cui et al. [39] propose a hybrid improved dragonfly algorithm (HIDA), which combines the advantages of both mRMR and improved dragonfly algorithm (IDA) in order to generate promising candidate subset and achieve higher classification accuracy rate. Li et al. [40] try to solve feature selection problems by extending from BDA to develop an improved BDA (IBDA). The improved factors in their paper include EPD, crossover operator, and a novel binary mechanism. Tawhid et al. [41] present a new hybrid binary version of dragonfly and enhanced PSO algorithm named HBDESPO to solve feature selection problems. In order to prevent DA fall into local optimal solution, Chen et al. [42] put forward a spark-based BDA for feature selection, which integrates the global optimization ability of DA with the parallel computing ability of spark. In addition, in [43], the authors embed various chaotic maps into searching iterations of DA for discriminating features.
Despite the above works have successfully solved some or certain feature selection problems in various scenarios, according to no free lunch (NFL) theorem [44], there is no method can solve all problems in the field of optimizations. In addition, none of the above works can find the optimal subsets for all tested data sets. Due to the strong potential of DA in the area of feature selection optimizations, we plan to employ several improved factors into DA and solve feature selection problems more efficiently in this work.
Background
Population-based evolutionary computation algorithms for feature selection
Population-based evolutionary computation is a computational intelligence approach inspired by the principles of natural evolution. It involves creating a population of potential solutions and iteratively applying genetic operators such as mutation, crossover, and selection to evolve and improve the solutions over generations [45].
In the context of feature selection, evolutionary computation algorithms aim to search for an optimal subset of features that maximizes the performance of a given learning algorithm or model. By representing potential feature subsets as individuals in a population, these algorithms iteratively evaluate and evolve the solutions based on their fitness, which is typically determined by the performance of the selected features on a specific evaluation criterion [46].
However, the task of feature selection using evolutionary computation can be challenging due to several factors:
The large search space of possible feature subsets makes it computationally demanding to explore all possible combinations. The number of potential feature subsets grows exponentially with the number of features, leading to a combinatorial explosion [47]. The evaluation of fitness for each individual in the population requires training and evaluating the learning algorithm on the selected features. This process can be time-consuming, especially for large and complex data sets. The presence of redundant or irrelevant features, noisy data, and the existence of interdependencies among features can further complicate the optimization process [48]. These factors introduce additional complexity and make it challenging to find the optimal subset of features that truly captures the relevant information for accurate and efficient learning.
Overall, using population-based evolutionary computation for feature selection lies in its ability to explore the vast search space of feature subsets. However, the inherent complexity of this problem, including the large search space, computational demands, and the presence of various challenges, makes it a difficult task to achieve optimal results.
Based on the preceding analysis, it is evident that exploring the adaptation of an existing nature-inspired algorithm into a population-based evolutionary computation algorithm presents a viable research approach for addressing the challenges associated with feature selection.
On the other hand, DA mimics the behavior of dragonflies in their search for prey. This algorithm utilizes the concept of swarming behavior, where dragonflies communicate and coordinate their movements to optimize their hunting efficiency. This collective intelligence enables DA to effectively explore the search space and find promising solutions for feature selection [49]. DA incorporates a combination of local search and global search strategies. The local search component allows dragonflies to exploit the local neighborhood and refine their solutions, while the global search component enables exploration of the entire search space to discover potentially better solutions. This balance between exploration and exploitation enhances the algorithm’s ability to find optimal or near-optimal feature subsets [50]. Additionally, DA employs adaptive mechanisms that dynamically adjust its parameters during the optimization process. These adaptive mechanisms improve the algorithm’s adaptability and robustness, allowing it to handle different types of data sets and feature selection objectives effectively.
Given the aforementioned benefits of DA in addressing feature selection problems, integrating genetic operators such as mutation and crossover makes DA a feasible and potentially efficient evolutionary computation algorithm for tackling feature selection problems.
Conventional DA
DA is a simulation of the swarm behaviors of dragonflies in natural environments, which can be divided into two types: static (feeding) swarm and dynamic (migrating) swarm. In the static swarm, dragonflies converge in clusters to search for prey in various areas. They create sub-swarms to hunt for food, which involves local movements and flight-path mutations. In the dynamic swarm, a large number of dragonflies migrate long distances in one direction. The static and dynamic clusters of dragonflies correspond to the global search (exploitation) and local development (exploration) in the algorithm, respectively.
There are five main behaviors of dragonflies in sub-swarms, which are separation (
The separation behavior involves avoiding collisions with other individuals. Mathematically, this behavior can be expressed as:
The equation comprises multiple variables. The alignment behavior involves matching the velocity of a dragonfly with that of other individuals in its vicinity. This behavior of alignment is modeled as follows:
the equation comprises the variable The cohesion behavior refers to dragonflies’ tendency to congregate towards the center of the sub-swarm. This behavior can be represented using the following model:
Following the cohesion behavior, dragonflies are drawn to a food source. This procedure can be modeled as:
where Dragonflies endeavor to maintain distance from their adversaries. The distraction mechanism can be computed using the following formula:
where
The step factor which integrates the combined with the five behaviors metioned above is as follows:
where
In summary, the position updating method of the conventional DA is listed as follows:
It should be noted that in the absence of a nearby sub-swarm, DA utilizes the Lévy flight mechanism to facilitate the dragonflies’s search for additional potential solutions. This improves DA’s capacity for exploration. The technique for updating positions, in conjunction with Lévy flight, is outlined below:
This article will not delve into the specifics of Lévy flight, but interested readers can refer to [37] for information on the Lévy mechanism employed in DA.
The key steps of the conventional DA are presented in algorithm 3.2.
Feature selection is a challenging optimization problem that involves multiple objectives. Typically, the two primary goals are minimizing the number of features selected and improving classification accuracy [51]. To address these objectives, we have developed a single-objective fitness function that considers both goals using the linear weighting method. The fitness function is designed to balance the trade-off between the two objectives and is expressed as follows:
where the variable
We can see that the Eq. (9) has two parts: the first part represents classification accuracy, and the second part represents the number of selected features. In practice, if the goal is to achieve higher classification accuracy, the value of
In addition, the classification accuracy is dependent on the specific classifier being used. Previous research has shown that the
Feature selection is a challenging problem that is often considered NP-hard [53], making it cannot be easily resolved through conventional algorithms. Population-based evolutionary computation algorithms which belong to the meta-heuristic algorithms, are promising methods for solving this problem. Nevertheless, these algorithms may not be effective in dealing with high-dimensional and discrete optimization problems, leading us to seek ways to improve existing evolutionary computation algorithms to solve the optimization problem. In this study, we have proposed CBDA, which combines a chaotic map, EPD mechanism, and binarization strategy with conventional DA to improve the effectiveness of solving feature selection problems.
CBDA
Based on the prior research and analysis [54], DA outperforms some other meta-heuristic algorithms to some extent. Although DA was initially designed to address continuous problems, the optimization of feature selection is discrete and the solution space is binary and considerably large. This may lead to conventional DA lacking the ability to efficiently exploit the solution space and solve such optimization problems. For this part, we introduce CBDA, an enhanced version of DA that incorporates several improved factors, including a chaotic map, EPD mechanism, crossover strategy, and binarization strategy, to make it well-suited for feature selection problems.
Since feature selection solutions are binary, the distance between dragonflies cannot be clearly determined in a discrete space, and thus, in CBDA, we assume that all dragonflies belong to a single sub-swarm.
Algorithm 4.1 outlines the overall structure of CBDA, and the details are provided below.
Chaotic map in CBDA
Parameter determination is crucial for the performance of an evolutionary algorithm. However, adjusting five parameters (
where
In DA, the initial populations are usually generated randomly, which can lead to a search lacking direction and cause DA to become stuck in local optima. To avoid this, it is crucial to improve DA’s capability to explore a wide range of solutions, which entails careful consideration of
Chaos is a dynamic system that is extremely sensitive to its initial conditions and parameters. As a result of its properties, such as ergodicity, randomness, and irregularity [56], chaos can be utilized in optimization to generate chaotic numbers between 0 and 1 instead of relying on a pseudo-random number generator. Studies have demonstrated that utilizing chaotic sequences for population initialization, selection, crossover, and mutation can have a significant impact on the algorithm’s overall performance, often resulting in superior outcomes compared to using pseudo-random numbers [57].
This paper utilizes a chaotic map called Tent to modify the value of
The variable
The curve of 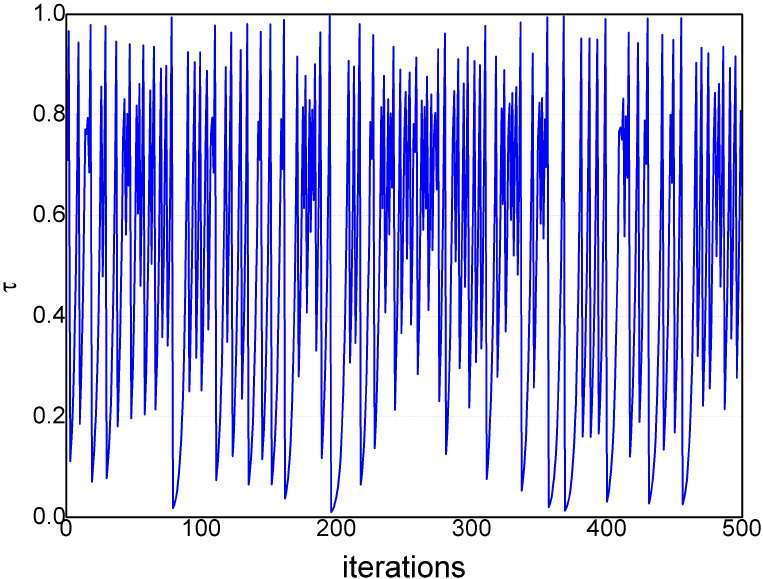
Specifically,
where
EPD is a technique that falls under the umbrella of self-organized criticality (SOC) [60]. SOC refers to a phenomenon where a small modification to a specific population can be amplified throughout the entire population and influence them in a complex manner without any external intervention [61]. EPD is a process inspired by evolutionary algorithms (EAs) that involves removing the worst solutions (i.e., individuals with the lowest fitness values) by repositioning them around the guide solutions (i.e., the selected individuals with the highest fitness values). In EPD, mutation and crossover operations are performed to eliminate the worst solutions, rather than simply replacing them with guide solutions. This approach can effectively maintain the diversity of the population. Hence, we have integrated EPD into CBDA to balance its exploitation and exploration capabilities.
The EPD mechanism in CBDA comprises the following fundamental steps:
(a) The selection method for EPD
The selection method plays a crucial role in balancing the intensification and diversification aspects of EPD. There are several selection methods available, including best-based selection (BB), roulette wheel selection (RWS), linear rank-based selection (LRS), stochastic universal sampling (SUS), and others. However, not all selection mechanisms are appropriate for DA. Li et al. discovered in their study [40] that using LRS in DA yields better results. We have adopted a fitness-based selection method called exponential rank selection (ERS) as the selection method in EPD, inspired by their research. To maintain the diversity of populations in CBDA, we have introduced a novel approach called EPD_ERS.
Algorithm 4.1 outlines the primary steps of EPD_ERS, and additional information on ERS can be found in [62].
As illustrated in Algorithm 4.1, each individual is sorted in ascending order based on its fitness value. Subsequently, each individual from the top half of the population will calculate its own chosen probability as follows:
where
The mechanism of EPD in CBDA.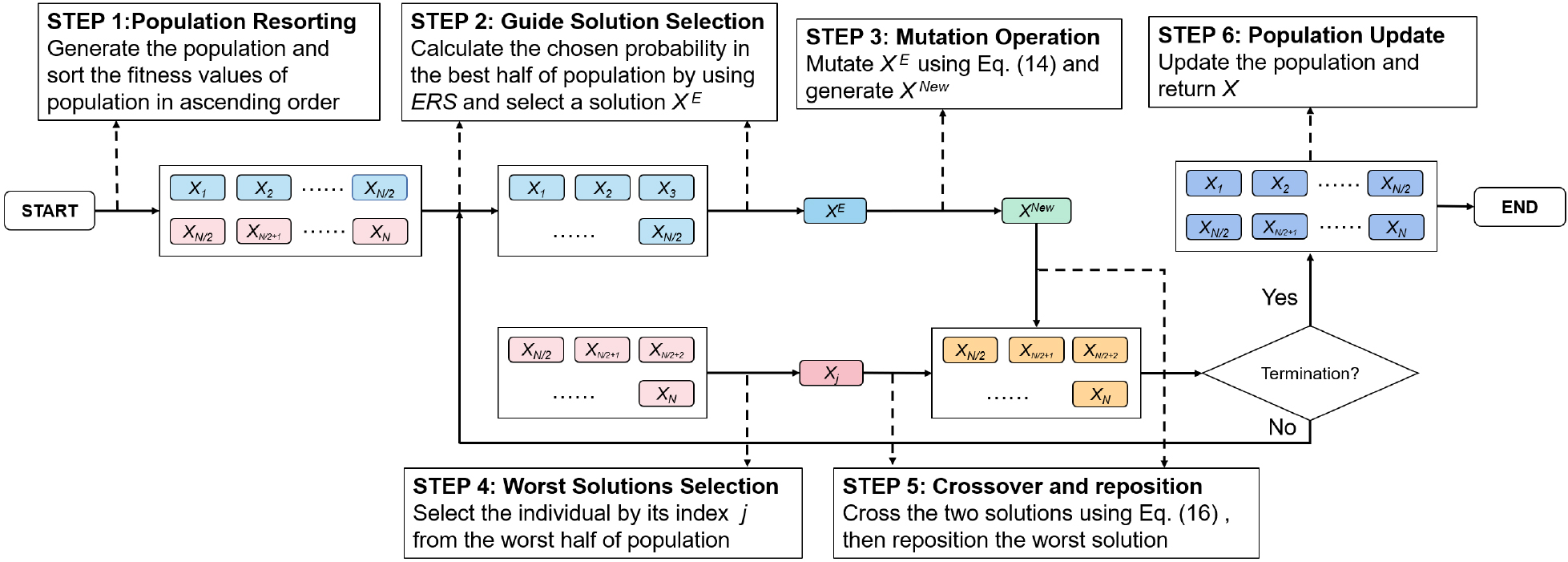
(b) The mutation and crossover operation for EPD
Once the guide solutions have been identified for each member in the worst half of the population, mutation and crossover operations are employed to maintain the variety of population. This approach improves EPD_ERS’s ability to explore a broader range of solution space in CBDA. Furthermore, if the solution dimension is
where
The present guide solution,
The last step of EPD_ERS involves creating new solutions that lie between the worst solutions and guide solutions. To achieve this, the crossover operator is used with the aim of exploiting EPD. The crossover operator used in EPD_ERS is defined as follows, based on [63].
As a result, we have successfully carried out all the steps of the EPD mechanism in CBDA. The proposed enhancements of EPD in CBDA are depicted in Fig. 2. The figure illustrates the process of selecting guide solutions using the ERS method, choosing the worst solutions in populations, applying the mutation operation to guide solutions, crossing the two solutions, and ultimately repositioning the worst solutions around the guide solutions. By doing so, we have achieved a balance between the exploitation and exploration capabilities of CBDA, making it a potentially superior algorithm for solving feature selection problems compared to other methods.
Conventional DA was designed to tackle continuous optimization problems, but feature selection involves binary dimensions in the form of discrete variables. Therefore, DA cannot be directly employed for feature selection. To address binary optimization problems without modifying their structure, transfer functions are frequently utilized [64]. There are three primary types of binarization methods [30]: two-step binarization, operator transformation, and K-means Transition Algorithm.
In this study, we have employed a
where
where
The curve of 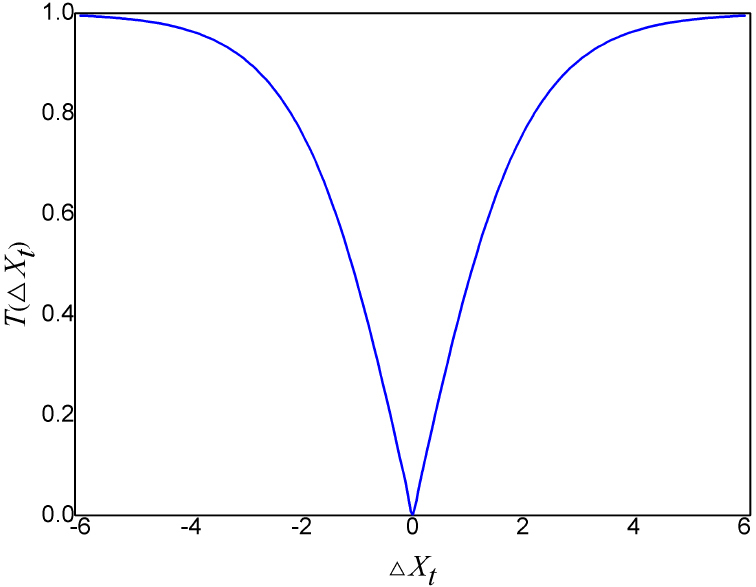
Accordingly, in each iteration, the binarization technique has been integrated into CBDA to convert continuous solutions to binary ones without altering the structure of DA. Additionally, by integrating the chaotic map, EPD mechanism, ERS method, mutation and crossover operation, CBDA can effectively address feature selection problems.
This section provides an analysis of the complexity of CBDA. Assuming that the maximum number of iterations is
Benchmark data sets
Benchmark data sets
An example of binary representation of dragonfly.
Parameter tunning results of
Parameter tuning results of
The solution obtained from CBDA is a binary vector of length
where
The setups of the comparative algorithms in the ablation experiments
Fitness function values for various versions of CBDA
Convergence curves for various versions of CBDA in first 12 data sets.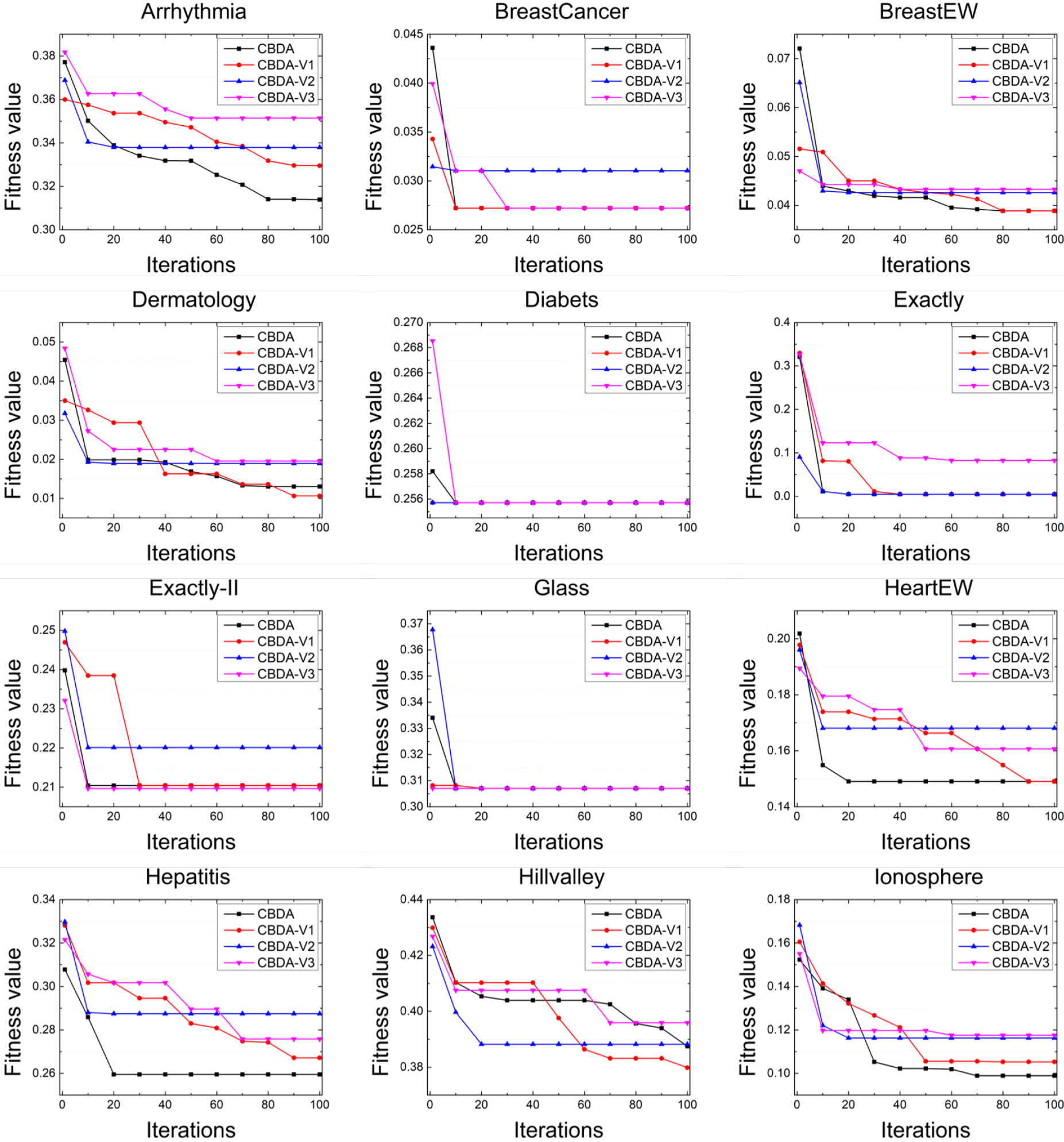
Convergence curves for various versions of CBDA in last 12 data sets.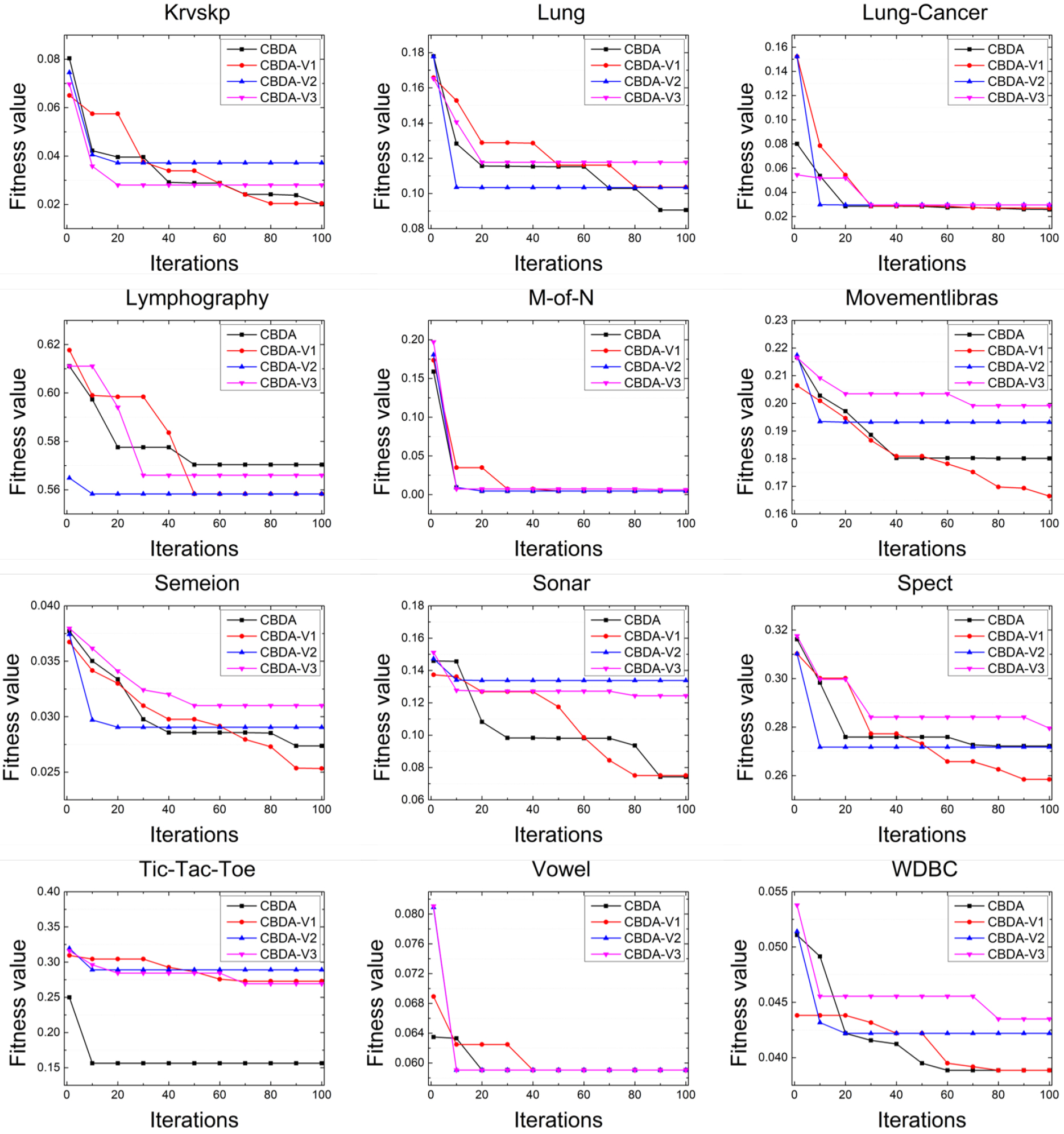
Classification accuracies for various versions of CBDA
CPU running time for various versions of CBDA (unit: seconds)
Number of selected features for various versions of CBDA
The instructions of the comparative algorithms in this paper
Fitness function values for CBDA versus other optimizers
Convergence curves for CBDA and other optimizers in first 12 data sets.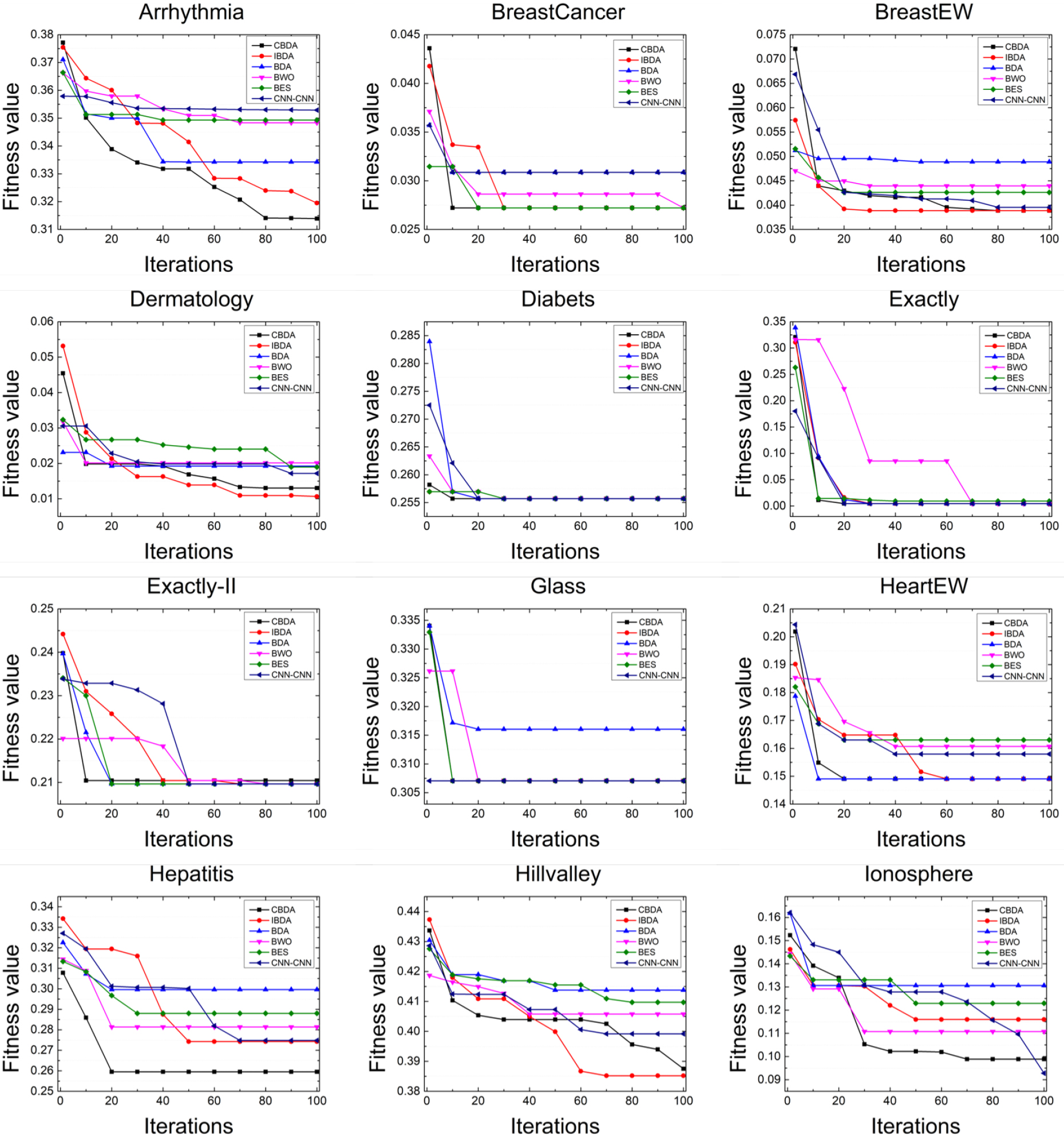
Convergence curves for CBDA and other optimizers in last 12 data sets.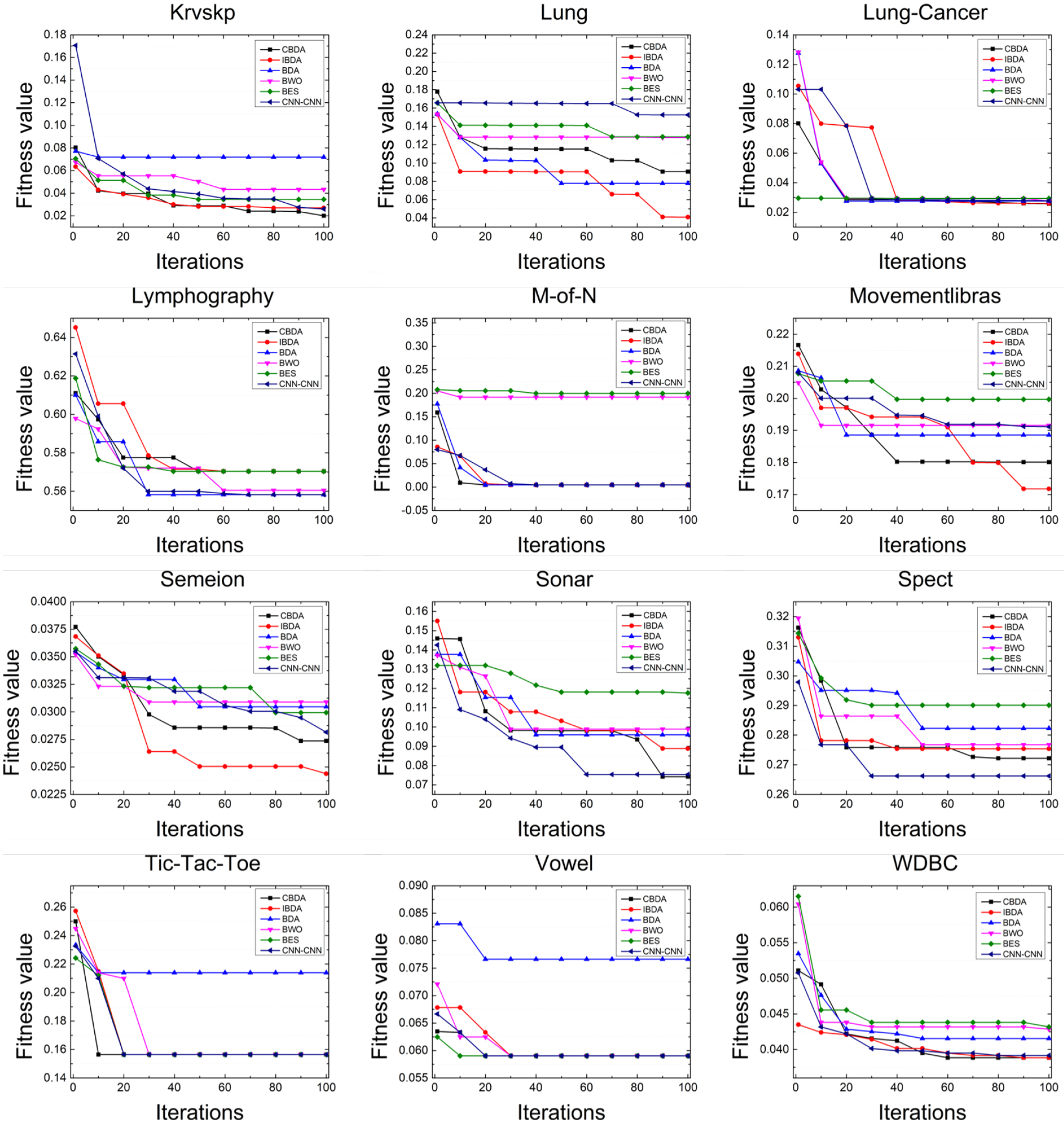
This section showcases the outcomes of CBDA on various data sets. Initially, we describe the data sets employed in this study. Subsequently, we elaborate on the experimental configuration. Lastly, we present and scrutinize the experimental findings.
Benchmark data sets
In this study, we evaluate the effectiveness of CBDA by conducting experiments on 24 data sets obtained from the UCI data repository [66]. The specifics of these data sets are outlined in Table 1.
Parameter tuning and experiment setups
Parameter tuning
As discussed in Subsection 4.1.1, the values of
The determination of crucial parameters, such as the initial value of the chaotic sequence and the value of
Experiment setups
Python 3.10 was utilized to implement the proposed CBDA algorithm, and the experiments were performed on a computer equipped with an 8th generation Intel processor (i5-8500U) and a 16 GB RAM. As mentioned in Section 3.3, the
Moreover, all of these algorithms were configured with the same values of
Experiment results
This section showcases the feature selection outcomes achieved by various algorithms, accompanied by corresponding analyses. The optimal values attained by an algorithm in a variety of metrics are emphasized in bold typeface.
Evaluation metrics
The fundamental metrics utilized in the outcomes obtained from various experiments are the average value (AVG) and standard deviation (STD). Additionally, two non-parametric statistical tests, Wilcoxon rank-sum and Friedman, are conducted at a 5% significance level for each algorithm to demonstrate the significance of the results obtained in this study.
Furthermore, the cumulative scores of the four metrics are also used to represent a more equitable distribution of wins for each method. The term “win” is employed to count the number of methods that achieve the best outcomes, and this “win” count is normalized to “1” for all comparative methods within each data set. Consequently, a win score of 1 is assigned to a method when it is the sole winner. On the other hand, if multiple methods tie for the best result, the “1 win” is divided among all tied methods, with each method receiving a fractional win score inversely proportional to the number of tied methods. For instance, if five methods all achieve the best result in one data set, each winner would receive a win score of 0.2, and so on. Therefore, the terms “wins” represents the sum of these win scores across the entire data set for each method.
The results of ablation experiments of CBDA
In this experimental section, we conduct ablation experiments to compare the distinct impacts of various enhanced factors, including the chaotic map, EPD mechanism, and binarization strategy, on the algorithm. The purpose of these experiments is to analyze and understand the individual contributions of these factors to the overall performance.
In this section, we consider four comparative algorithms: IBDA-V1, IBDA-V2, and IBDA-V3 to conduct the comprehensive experiments with CBDA. These algorithms incorporate different enhanced factors, which have been introduced to improve their performance. The details of these algorithms are brought out in Table 4.
In CBDA-V3, we utilize the Sigmoid transfer function (referred to as the “
Table 5 presents the fitness function values of CBDA compared to its ablated versions, namely CBDA-V1, CBDA-V2, and CBDA-V3. CBDA demonstrates a superior performance compared to its ablated counterparts, with the fitness values ranked as follows: CBDA
Table 6 illustrates the significance obtained by Wilcoxon sum-rank test for CBDA against its ablated versions. Intuitively, CBDA outperforms CBDA-V1 and CBDA-V2 on almost all the data sets. Specifically, for CBDA-V2, CBDA shows its superiority on 22 data sets, except the data sets named Diabets and Hillvalley. For CBDA-V3, CBDA shows a better significance on 19 data sets. Theses results imply that the EPD mechanism and
The convergence curves obtained from CBDA and its ablated versions are presented in Figs 5 and 6. It is important to note that these curves correspond to the 15th test of each experiment. Upon visual inspection, it is evident that CBDA exhibits a faster convergence rate on 18 data sets. Specifically, CBDA achieves optimal convergence on data sets such as Arrhythmia, Hepatitis, Ionosphere, Lung, and Tic-Tac-Toe. Additionally, CBDA-V1 demonstrates exclusive optimal convergence on 5 data sets, namely Dermatology, Hillvalley, Movementlibras, Semeion, and Spect. However, CBDA-V2 and V3 fail to achieve any minimum convergence across the 24 data sets when compared to the other algorithms. These observations indicate that the utilization of chaos in the proposed algorithm may expedite the search for optimal solutions more effectively than the other two improvement factors in CBDA.
The average classification accuracies achieved by different versions of CBDA are presented in Table 7. The distribution of results aligns with the fitness values shown in Table 5. CBDA demonstrates significantly superior performance compared to its counterparts, with a total of 16.58 wins, accounting for 69.08% of the total number of data sets. CBDA-V1 ranks second with 5.58 wins (23.25%), and the
To assess the significance of the classification accuracies obtained by CBDA in comparison to other competing methods, we perform the Wilcoxon sum-rank test shown in Table 8. The results indicate that CBDA exhibits significant advantages over CBDA-V2 and CBDA-V3. This demonstrates the effectiveness and rationality of the optimization strategy (more specifically, it refers to the EPD mechanism and
Table 9 presents the average computational time of CBDA and its various versions. CBDA demonstrates the lowest CPU time consumption on 8 data sets, achieving the highest number of wins. CBDA-V1 follows closely with 7 data sets. In terms of standard deviation (STD) results, CBDA maintains a leading position among the four algorithms, achieving the minimum value on 11 data sets. CBDA-V3 performs well on 8 data sets and ranks second in this aspect. Overall, CBDA exhibits the characteristics of low time complexity and good stability. The F-test statistic further supports our argument in favor of CBDA’s superiority in this regard.
The final comparison between CBDA and its ablated versions focuses on the number of selected features and the corresponding results are presented in Table 10. It is widely acknowledged that a higher number of features theoretically leads to better classification accuracy. Therefore, it is challenging to achieve a satisfactory classification accuracy while maintaining a lower number of selected features. However, CBDA consistently selects fewer features compared to other methods, achieving a remarkable 9.41 wins in the overall comparison, which ranks it first. Following closely, CBDA-V1 ranks second with 8.41 wins. The analysis of standard deviations for CBDA demonstrates that it is a relatively stable algorithm across various data sets. Additionally, the F-test results for CBDA show that it consistently achieves the highest ranking, suggesting that CBDA is capable of obtaining statistically optimal solutions in terms of selected features. These findings indicate that CBDA effectively selects a reasonable number of features while maintaining superior classification accuracy. In other words, the improved features of CBDA synergize well, enabling it to achieve high efficiency. Consequently, CBDA can be considered as a promising approach to address the proposed feature selection problem.
In this research, we compared the performance of CBDA with five cutting-edge optimizers: IBDA [40], BDA [69], BWO [70], BES [71], and CNN-CNN [72]. The detailed instructions of these optimization algorithms are listed in Table 11.
Table 12 exhibits the comparative numerical outcomes of fitness values attained by CBDA and other comparative algorithms on each data set. CBDA attains the optimal average fitness value on 13 data sets (the number of wins is 11.5, accounting for near half of the total wins), followed by IBDA with 7 data sets (the number of wins is 6, accounting for 25% of the total wins) and CNN-CNN with 5 data sets (the number of wins is also 5). The STD outcomes suggest that CBDA performs satisfactorily on most data sets because it reached to the optimal on 10 data sets and ranked first among the algorithms. The F-test statistic conducted on average fitness values shows that CBDA achieves the best rank compared to other algorithms, which supports the fact that CBDA performs better in terms of fitness value.
Table 13 displays the
Figures 7 and 8 illustrate the convergence curves of CBDA and other algorithms during their execution. It should be noted that we used data from the middle of the running times, specifically the 15th test, as the data source for each curve. As can be observed from these figures, CBDA achieves a faster or equivalent convergence rate compared to other algorithms on 17 data sets. In particular, CBDA achieves the minimum on 4 data sets, which are named Arrhythmia, Hepatitis, Krvskp and Sonar, respectively. These results confirm that the introduced improved factors can enhance CBDA’s ability to converge rapidly to optimal solutions.
Table 14 illustrates the classification accuracies attained by CBDA versus other algorithms. The numerical outcomes are akin to those in Table 12. It clearly shows that CBDA achieves the highest average accuracy on 17 data sets and get a high sore of wins, which is 12.52 in 30 times of experiments, which is notably superior to other algorithms. IBDA is ranked second with 6.27 wins. Moreover, the STDs of accuracies obtained by CBDA are the best on 11 data sets, ranking second among the six algorithms. The F-test outcomes of average accuracy suggest that CBDA outperforms the comparative algorithms. Consequently, CBDA is a competitive algorithm in terms of fitness value and classification accuracy.
As the comparative results obtained by the ablation experiments in Section 5.3.2, the main reason of the superiority of CBDA can be primarily attributed to and the EPD mechanism and
Consequently, CBDA has a higher likelihood of discovering optimal solutions in comparison to other algorithms. We also employed the Wilcoxon sum-rank test for classification accuracy as a statistical analytical method to further verify the outcomes. Table 15 corroborates the aforementioned arguments. It can be observed that CBDA significantly outperforms BDA, BWO and BES on most data sets. Furthermore, CBDA surpasses IBDA on four data sets, namely Exactly, Hillvalley, Movementlibras, and Spect.
Classification accuracies for CBDA versus other optimizers
Classification accuracies for CBDA versus other optimizers
Table 16 exhibits the running time in seconds for all algorithms. It is evident that CBDA delivers commendable computing performance on six data sets. Although it is not the swiftest, the difference is not noteworthy, which is also substantiated by the F-test statistic. Consequently, we can infer that the enhanced factors in CBDA do not necessitate much supplementary computing time in comparison to conventional ones, and the overall overhead of CBDA is reasonable.
CPU running time for CBDA versus other optimizers (unit: seconds)
Moreover, the results in Table 17 reveal the average number of selected features obtained by the proposed CBDA and other optimizers. However, CBDA is not dominant on most data sets, as selected feature numbers and classification accuracies are not consistently correlated. Although CBDA has the best classification accuracies in Table 14, its selected feature numbers are often higher than other algorithms. Nonetheless, CBDA’s stability is superior to other algorithms in fact (it reaches to optimal on 11 data sets). The F-test statistic on average numbers of selected features shows that CBDA performs better than BWO, BES, and CNN-CNN. Overall, CBDA can achieve the best average classification accuracy by selecting slightly more features, which is acceptable in most cases.
Numbers of selected features for CBDA versus other optimizers
In this section, we compare the classification accuracy of CBDA with that of five well-known filter-based algorithms: CFS, FCBF, F-score, IG, and Spectrum, as reviewed in [73]. The comparative results of classification accuracy on the same benchmark data sets are reported in [74], and Table 18 shows the results of other established algorithms.
As seen in Table 18, CBDA outperforms those filter-based algorithms on 76.92% of the data sets. A more visual comparison of classification accuracy is presented in Fig. 9, which shows that CBDA performs better than most algorithms in all evaluation criteria. The only three data sets where CBDA does not achieve the best accuracies are Breastcancer, Lymphography, and Spect, which share similar characteristics, such as having a small number of features and relatively few instances (except for Breastcancer). However, due to the randomness of initial populations, CBDA may reach the optimal solution on Breastcancer in another experiment. Therefore, we can conclude that CBDA is more advantageous than the five filter-based algorithms in feature selection optimizations. The main reason for the superior accuracy of CBDA is the effectiveness of the introduced improved factors, which enable CBDA to alleviate stagnation problems and avoid getting trapped in local optima, thus discovering more high-quality solutions and achieving better performance on most data sets. But here we would like to illustrate that this does not means that CBDA is always better than the filter-based algorithms on dealing with other feature selection problems, especially in the scene that the tackled problems need a method with a faster running time to address, which indicates that the filter-based method may be more suitable than CBDA.
Visualization of classification accuracy results.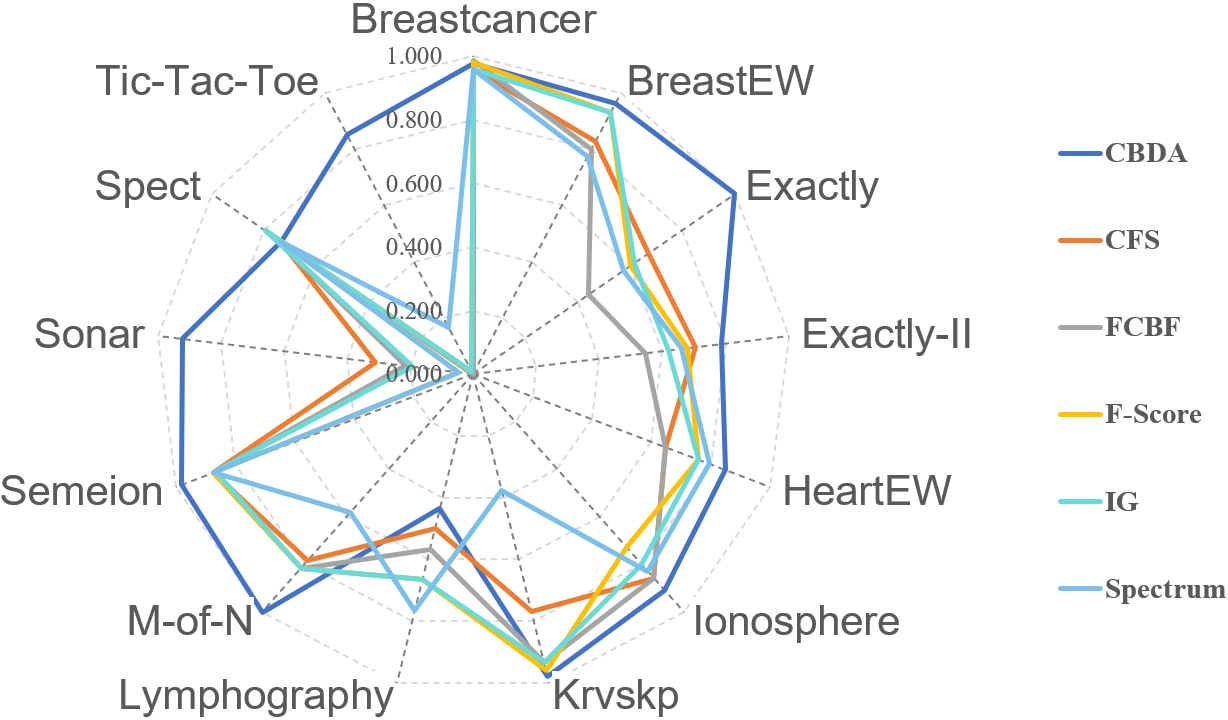
Classification accuracies for CBDA versus other filter-based algorithms
After thoroughly analyzing the comparative experimental results presented in this study, it becomes evident that the incorporation of improvement factors contributes significantly to CBDA in the following ways:
In summary, the comprehensive evaluation of comparative experimental results highlights the significant contributions of incorporated improvement factors to CBDA, including its strong global search capability, efficient performance through EPD, and enhanced stability and reliability through the binarization strategy. Moreover, the superiority of CBDA and the specific circumstances that CBDA can be applied to are summarized as follows:
Global search capability: CBDA possesses strong global search capability, allowing it to quickly find the optimal feature subset within the search space. This enables it to handle feature selection problems in high-dimensional data sets and identify the most representative and discriminative features. Efficient performance: BDA has parallel search strategies and the improvement factors in CBDA, enables simultaneous exploration of multiple solution spaces and accelerates the search process. Additionally, it utilizes adaptive parameter adjustment and adaptive neighborhood search mechanisms, further enhancing the algorithm’s efficiency and performance. Scalability: CBDA exhibits flexibility in adapting to different problems and data sets, and can be combined with other optimization algorithms. It can adapt to different feature selection tasks by adjusting parameters and modifying fitness functions, and is capable of handling large-scale data sets. Robustness: CBDA demonstrates a certain level of robustness against noise and outliers. It can adapt to different data feature distributions and noise conditions through adaptive neighborhood search and parameter adjustment, thereby improving the stability and reliability of feature selection.
In conclusion, CBDA possesses strong global search capability, efficient performance, scalability, and robustness in feature selection, making it an effective method in this domain.
Conclusions and future works
This work conducts a specific study on the problem of feature selection in machine learning. Firstly, the fitness function is designed to reduce the number of selected features while improving classification accuracy. Based on conventional DA, we propose a new algorithm called CBDA with several improved factors, including chaos, EPD_ERS mechanism, and a
However, CBDA has some drawbacks naturally, such as selecting more feature numbers than others to ensure classification accuracy and possibly being unstable in dealing with specific data sets. For the future work, we plan to overcome these drawbacks and apply CBDA to solve extensive multi-objective formulation solving problems. We also intend to introduce more effective improved measurements to other evolutionary computation algorithms to solve feature selection problems.
Footnotes
Acknowledgments
This study is supported in part by the National Natural Science Foundation of China (62172186, 62002133, 61872158, 62272194), in part by the Science and Technology Development Plan Project of Jilin Province (20210101183JC, 20210201072GX), and in part by the Young Science and Technology Talent Lift Project of Jilin Province (QT202013).