
Abstract
Histograms are among the most popular methods used in exploratory analysis to summarize univariate distributions. In particular, irregular histograms are good non-parametric density estimators that require very few parameters: the number of bins with their lengths and frequencies. Although many approaches have been proposed in the literature to infer these parameters, most existing histogram methods are difficult to exploit for exploratory analysis in the case of real-world data sets, with scalability issues, truncated data, outliers or heavy-tailed distributions. In this paper, we focus on the G-Enum histogram method, which exploits the Minimum Description Length (MDL) principle to build histograms without any user parameter. We then propose to extend this method by exploiting a new modeling space based on floating-point representation, with the objective of building histograms resistant to outliers or heavy-tailed distributions. We also suggest several heuristics and a methodology suitable for the exploratory analysis of large scale real-world data sets, whose underlying patterns are difficult to recover for digitization reasons. Extensive experiments show the benefits of the approach, evaluated with a dual objective: the accuracy of density estimation in the case of outliers or heavy-tailed distributions, and the effectiveness of the approach for exploratory data analysis.
Introduction
Histograms are among the most popular methods used in exploratory analysis to summarize univariate distributions. Regular histograms are the simplest savor of histograms to represent a distribution: all bins are of the same width and the only parameter to select is the number of bins. While they are suited to roughly uniform distributions [1], they fail to capture the density of more complex distributions. Irregular histograms are non-parametric piecewise constant density estimators that require very few parameters: the number of bins with their widths and frequencies. Several irregular histogram methods have been proposed in the literature, but they often require user-defined parameters, such as the number of bins or the accuracy
The G-Enum method [6] extends the MDL method [2] with an automatic choice of
This paper presents an extension of the G-Enum method that exploits the floating-point representation of real number on computers, and a methodology for univariate exploratory analysis of large scale real-world data sets. The first key contributions are related to
histograms for density estimation:
introduction of a space of floating-point bins, as an alternative to equal-width bins, extension of the G-Enum method with new criterion and algorithm, extensive experiments in the case of outliers or heavy-tailed distributions.
However, while the method works very well on challenging artificial data sets with known distributions, preliminary experiments show the limitations of the approach when applied to real-world data sets, where the aim is to provide a better understanding of the data through exploratory analysis. The second key contributions are related to
histograms for exploratory analysis:
characterization of some issues that come with real-world data, proposal of a methodology for effective exploratory analysis using histograms, illustration with several use cases related to challenging real-world data sets.
The rest of the paper is organized as follows. We briefly recall the G-Enum method in Section 2. We illustrate the limit of histogram methods in the case of outliers and discuss possible solutions to push these limits in Section 3. We introduce the notion of floating-point bins in Section 4, and exploit them to suggest an approach named G-Enum-fp in Section 5. We perform extensive experiments with artificial data sets in Section 6. We then propose a methodology for the exploratory analysis of real-world data sets in Section 7, which we evaluate in Section 8. Finally, we give a summary and suggest future work in Section 9.
G-Enum method: Summary
This section is a brief reminder of the G-Enum method [6].
Problem formulation
We consider a sample of
Let
These endpoints define
A histogram model is entirely defined by the choice of the number of intervals, the set of endpoints that define them and their data counts. We thus note a histogram model
Granularity and choice of
The role of approximation accuracy
To get rid of this user parameter
This new criterion, which is called
Enum and G-Enum criteria for histogram models
Term comparison of the Enum and G-Enum criteria
Term comparison of the Enum and G-Enum criteria
Table 1 recalls the Enum criterion for histogram models and its granulated extension G-Enum. The
For additive criteria such as Enum, a dynamic programming algorithm can be applied to obtain the optimal solution. However, its computational complexity is cubic w.r.t. the number endpoints
Experimental results
We summarize below the results of the comparative experiments performed to evaluate the G-Enum method [6]. The comparison includes the following irregular and regular histogram methods:
It is worth noting that the Enum and NML methods are similar in that they both require a
The histogram methods are evaluated on artificial data sets with known distributions: Normal, Cauchy, Uniform, Triangle, Triangle mixture and Gaussian mixture. The methods are compared on three criteria: accuracy evaluated with the Hellinger distance, parsimony using the number of intervals and computation time. The analysis of the experimental results shows that the G-Enum method achieves state of the art accuracy while being much more parsimonious and faster than its closest competitors.
“Although rarely the best for each distribution type, G-Enum histograms are consistently among the best estimators, and this without the high variability of the other methods. Focusing on irregular histograms, G-Enum is certainly among the most parsimonious in number of intervals. For exploratory analysis, this is an important quality because it makes the interpretation of the results easier and more reliable. G-Enum is also by far the fastest of irregular methods, making it suitable to large data sets.” [6]
In particular, in the case of the heavy-tailed Cauchy distribution with the largest evaluated data set size (
Limits of histogram methods w.r.t. outliers
We first give an illustrative example of the limits of the G-Enum method in the case of outliers, and then discuss possible solutions to push these limits.
Illustative exemple
Let us consider a data set containing
Let us now assume that we have an outlier data entry in our data set, with value
Let us note that, to the best of our knowledge, this problem is likely to occur with most alternative histogram methods. In the following we investigate on solutions to push these limits.
Possible solutions to push these limits
We suggest possible solutions to push the limits of the G-Enum method and summarize their potential benefits and drawbacks.
Use of long integers
The use of computer integers beyond
this greatly increases computation time, as large integers are not processed at processor level. this poses numerical problems in calculating the optimization criterion for integers beyond this cannot work well when small
Removing outliers
Removing outliers before calculating the histogram could be considered. Outlier detection has been widely studied [11] and many methods have been proposed in the literature. There is no generic or universally applicable outlier detection method, and most existing methods require user thresholds, which are difficult to adjust. In the case of exploratory data analysis with no prior knowledge of the data, outlier removal prior to histogram calculation is questionable. For example, in the case of a heavy-tailed distribution with no mean or variance, such as a Cauchy or Lévy distribution, many extreme values could be removed regardless of the user threshold, and the remaining extreme values could still be considered outliers.
The primary purpose of histograms is to provide an initial overview of the data for exploratory analysis without any prior knowledge, and ideally no data should be excluded. The resulting histograms can then be used as building blocks for anomaly and outlier detection methods [12, 13].
Extension to hierarchical histogram models
One solution to cope with outliers consists in extending the G-Enum method to a hierarchical model. A histogram consists in a set of adjacent intervals, whereas a hierarchical histogram consists in a tree of intervals, where:
each leaf node is an interval, each intermediate node can be seen both as an interval, union of its children intervals, and as a histogram, set of its children intervals, the root node represents the whole value domain.
Such a hierarchical histogram could potentially cope with outliers. For example, using the data set described in Section 3.1, we could have one root node with three children nodes; the first one for all the Gaussian data entries, the second one with an empty interval and the last one with the outlier. Then the first node could be divided again to produce a standard histogram focused on the Gaussian data entries, without any outlier issue.
This possible solution looks appealing, but its implementation may encounter several problems:
devising an effective prior for hierarchical models is not an easy task, optimizing hierarchical models is known to be difficult, with little hope of achieving optimality efficiently, the optimization algorithm may face numerical problems, since many models to be compared may have almost the same cost.
Bi-level heuristic for histograms
A heuristic variant of hierarchical histogram models have been investigated in [14]. The resulting bi-level heuristic exploits a logarithmic transformation of the data to split the data set into a list of data subsets with a controlled range of values. The second level builds a sub-histogram for each data subset and aggregates them to obtain a complete histogram. Extensive experiments have demonstrated the applicability of the method to a wide range of data sets, including the case of outliers or heavy-tailed distributions. However, this method is hampered by some heuristic trade-offs:
it relies on several hard to tune heuristic thresholds, mainly to split or not the initial data set into a list of data subsets and to deal with tiny value ranges that reach the limit of the precision of the mantissa of real values, it relies on a sub-optimal heuristic to split the initial data set into a list of data subsets, it requires hard to tune heuristic methods to aggregate the independent sub-histograms, with potentially different granularity parameters, obtained per data subset, the overall optimization heuristic is tricky to implement, with a significant computation time overhead, an overall evaluation criterion is missing for the bi-level method, which prevents from providing a quality indicator and from post-optimizing the overall histogram or simplifying it wisely.
Floating-point bins for histograms
Histogram methods are univariate non-parametric density estimators which provide a summary of the underlying distribution using piece-wide constant densities per interval. These methods are devised with the assumption of data values belonging to
Floating-point representation
Let us first summarize how real values are encoded on computers using the floating-point representation [15]. Computer real values with double-precision floating-point format are stored on 8 bytes and thus encoded using 64 bits:
sign: exponent: mantissa:
The sign bit encodes the sign of the number,
Whereas mathematical real values that belong to
Impact on histograms
While histograms are invariant to translation in
And all intermediate behaviors can be observed between these two extremes.
Floating-point bins
The direct exploitation of floating-point representation to design a histogram modeling space is of great interest, as all the data that can be observed and processed are stored on computers.
Histograms where the length of intervals are multiple of
Let us first introduce floating-point bins, that can be divided into:
main bins
exponent bins of length
central bins of length
mantissa bins of equal-width
Examples of floating-point bins.
Figure 1 shows an example of main bins and mantissa bins that form a partition of the
Standard histograms rely on a set of equal-width elementary bins, which seems well suited to the inference of piecewise constant density estimators. Our objective is to exploit the floating-point representation while keeping close to equal-width bins across the entire value domain. We need to take care of the value 0, which is a singular value in the floating-point representation. For parsimony reasons, we try to avoid unnecessary exponent bins around zero, and for smoothness reasons, we look for a set of floating-point bins that are as close possible as possible to equal-width bins.
We suggest to cover the numerical domain
We formalize this below, assuming that
if use exponent bins:
if plus two central bins: if use exponent bins:
if plus one central bin: if use exponent bins for negative values: use exponent bins for positive values: plus two central bins:
We get a set of
If
All the interval boundaries
Finally, like in the G-Enum method, we propose to define the granulated bins by building a hierarchy of bins based on these elementary bins. At the maximal depth, we keep all our elementary bins. Then each time we decrease the depth
Let us notice that at any depth of the hierarchy, all the granulated bins are exact floating-point bins, except for the two extrema bins that contain
Example with one single main bin
Granulated bins in case of one single main bin.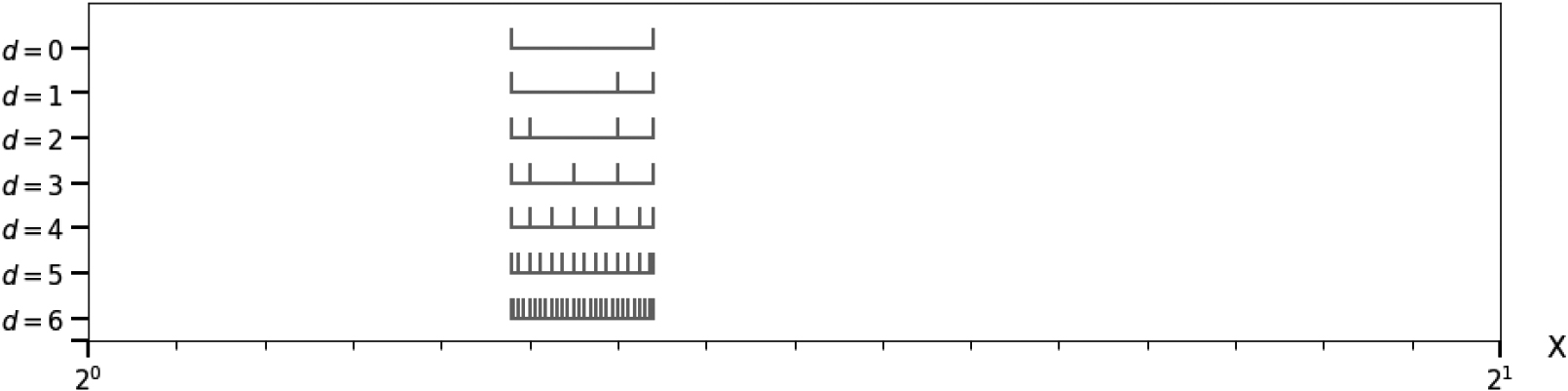
Let us consider a data set with values in
Example with multiple main bins
Let us consider a data set with values in
Granulated bins in case of multiple main bins.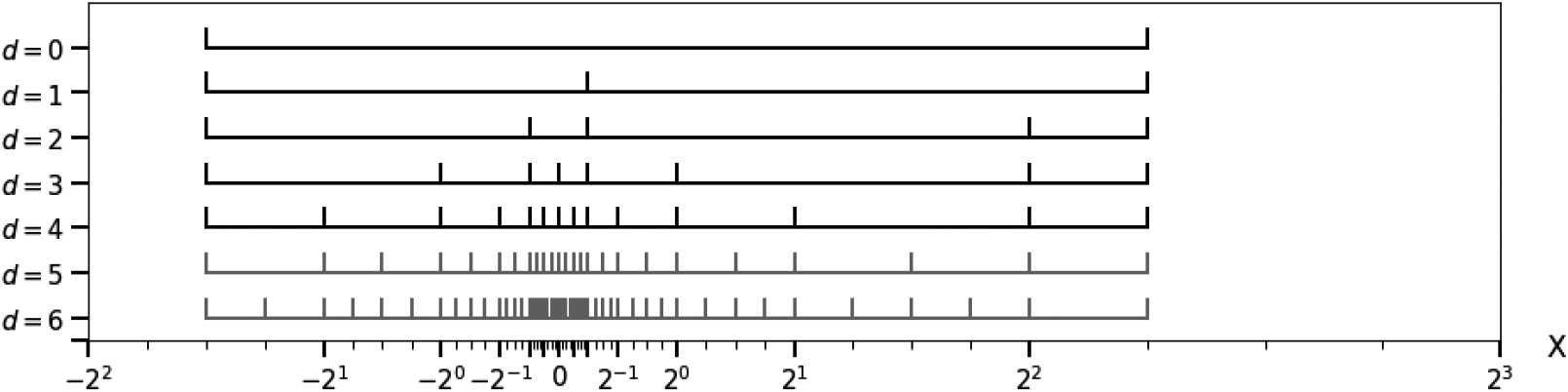
Granulated bins in case of multiple main bins, using a logarithmic scale.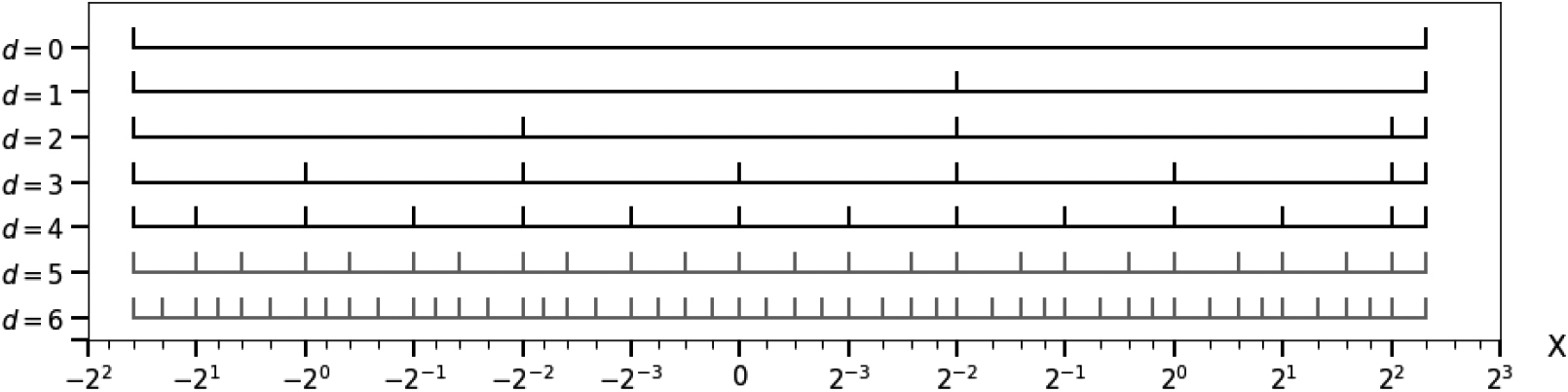
Figure 4 presents an alternative view of Fig. 3, keeping the linear scale within the central bins and exploiting a logarithmic scale for the negative and positive exponent bins. This shows that the lengths of the granulated bins are quite balanced when the relative precision of the interval boundaries is considered rather than their absolute precision. This also suggests an appealing visualization for histograms related to data sets with a dynamic range of values both in the negative and positive domains.
In the previous section, we have exploited the floating-point representation of real values to introduce an alternative definition of the elementary bins used as building blocks for a new histogram method called
Principle
The G-Enum method exploits a representation space based on elementary equal-width bins, using a granularity parameter
The main novelty of the G-Enum-fp method is to replace the elementary equal-width bins of G-Enum with the floating-point bins and their granulated hierarchy introduced in Section 4. This makes a radical difference regarding the impact of the granularity parameter
with the G-Enum method, with the G-Enum-fp method and the same
In addition to this major change, the G-Enum-fp method extends the modeling space and the optimization algorithms of the G-Enum method to take full account of the particularities of floating-point bins. To begin with, the bounds of the entire numerical domain are explicitly specified as hyper-parameters. The other difference related to the floating-point representation is the management of the singularity around 0, which relies on the choice of a central bin, treated as an additional model parameter. These extensions are summarized in the following subsections and detailed in Appendix A. Some properties of the G-Enum-fp method are also discussed in Appendix B.
Specification of domain bounds
With the G-Enum method, the domain bounds are implicitly derived from the data using
main bin containing the domain lower bound, main bin containing the domain upper bound, central bin exponent of the domain if necessary, digit precision used for mantissa bins, mantissa bins containing the domain bounds.
These domain lower and upper bounds are inferred once for all, before optimizing the histogram. An evaluation criterion is obtained using a MDL-based approach. Its optimization consist of two steps:
recover the extreme values encode a lower bound of
The details regarding the specification and optimization of these hyper-parameters are given in Appendix A.2.
Choice of the central bin
With the G-Enum-fp method, we introduce a new parameter
Optimizing the exponent of the central bin is mainly a matter of calling the G-Enum optimization algorithm twice, keeping its overall computational complexity:
optimize a first histogram search for the largest value optimize a second histogram
The introduction of this new parameter
G-Enum-fp criterion
G-Enum-fp criterion
G-Enum-fp criterion
Table 2 shows the G-Enum-fp criterion for the parameters of histogram models. Compared with the G-Enum criterion recalled in Table 1, the only differences concern the indexing terms:
the term the exponent the exact number of considered floating-point bins
In addition, new hyper-parameters have been introduced for the domain bounds (see Table 4 for the corresponding criterion). Note that the G-Enum-fp method is parameter-free, as all its parameters and hyper-parameters belong to the modeling space.
In this section, we evaluate the G-Enum-fp method using artificial data sets with known underlying data distribution. We focus on resistance to outliers and heavy-tailed distribution, beyond the limits of state-of-the art methods. A binary standalone implementation of the method is available here:
Evaluation protocol
Metrics
The accuracy of histograms for density estimation is evaluated using the Hellinger distance to the original model density, which is known in the case of artificial data sets. The Hellinger Distance (HD)
A HD close to 0 indicates a strong similarity between probability distributions. The HD measures reported are obtained via numerical integration to estimate the probability distributions of the model density and of the histogram that models it.
The number of intervals per histogram is also collected.
Histogram methods
Histogram methods are limited in the case of outliers or heavy-tailed distribution, as indicated in Section 3. We evaluate the G-Enum-fp method in these challenging cases. We also report the results obtained by the G-Enum method, chosen as a strong baseline, especially in the case of heavy-tailed distributions and large data sets (cf Section 2.5). Since our aim is to push the limits of histograms with data set sizes and value domain widths several orders of magnitude larger than those evaluated in [6], the G-Enum method is in fact the most appropriate method that can be used for comparison purposes.
Data sets
As a sanity check, we first evaluate the behavior of the methods in the case of common distributions, using the uniform, normal and a mixture of normal distributions. The results of these experiments are presented in Appendix C. We then analyze the case of data sets with outliers and heavy-tailed distributions using the Lévy distribution and a pathological mixture of lognormal distributions. The results of these experiments are presented in the following subsections.
Normal distribution with an outlier
The objective of this experiment is to evaluate the impact of an outlier on the quality of the built histograms. We exploit a data set of size
Hellinger distance and number of intervals for 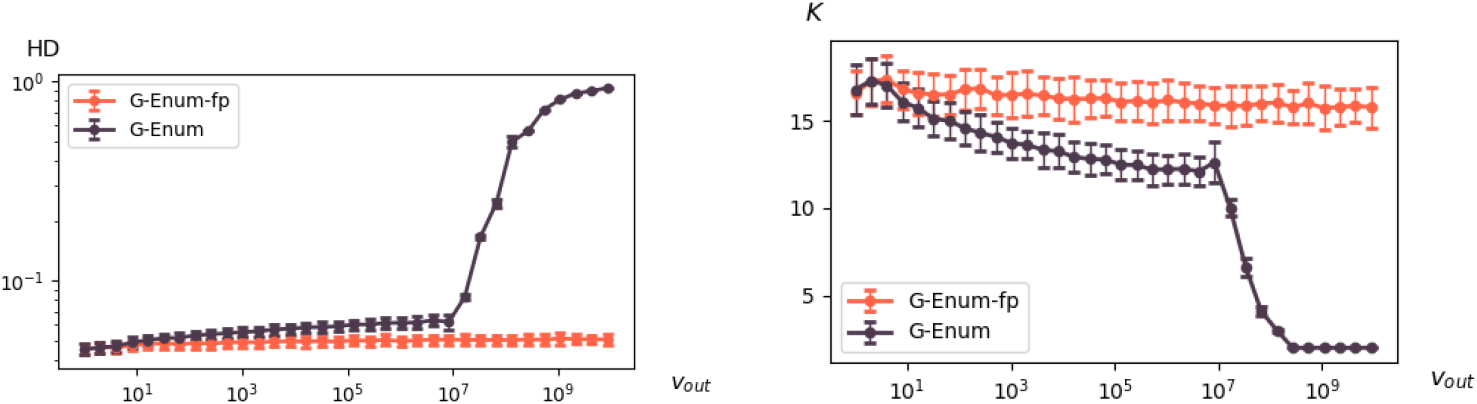
The overall results are reported in Fig. 5. They show that the G-Enum is rather resilient to the outlier on a large scale of values, up to about
The G-Enum-fp method benefits from its floating-point representation to be highly resilient to the outlier. Beyond
The objective of this experiment is to compare the behavior of the methods in the case of a heavy-tailed distribution. We exploit the Lévy distribution that is pathological, having neither mean nor variance. We also evaluate the scalability of the methods, by generating samples of size
Hellinger distance and number of intervals for a Lévy distribution.
The overall results are reported in Fig. 6. The G-Enum method is not able to produce an accurate approximation of the underlying density for
The G-Enum-fp method exploits up to 66 exponent bins to cover the huge range of values for
Figure 7 shows an example of the histograms obtained by each method for
Density and histograms for a Lévy distribution, with 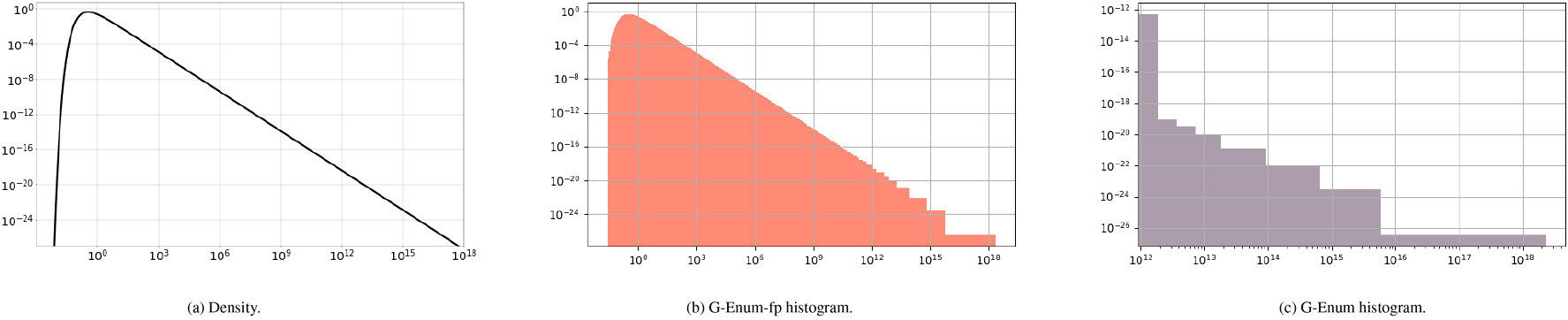
The objective of this last experiment is to push the G-Enum-fp to its limits, using a pathological mixture of heavy-tailed distributions. We generate data sets of size
Number of intervals for a mixture of lognormal distributions.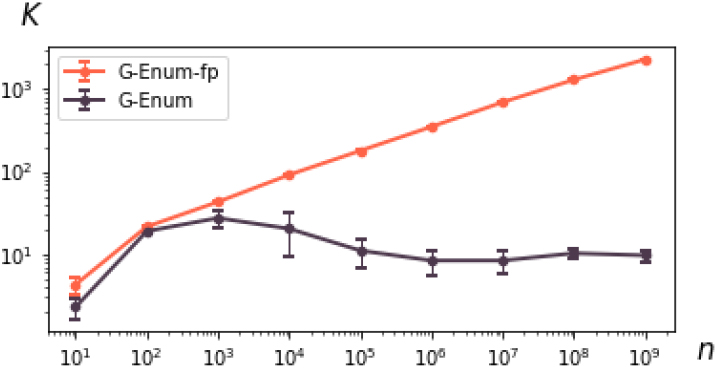
The experiment is repeated 10 times and Table 9 reports the mean and standard deviation of the number of intervals per sample size. With this pathological distribution, the range of values is enormous, from
Density and histograms for a mixture of lognormal distributions, with 
Figure 9 displays an example of the histograms obtained by each method for
In this section, we apply the G-Enum-fp method to real-world data sets. However, histograms may not be directly useful for the exploratory analysis of real data, as shown in a first example. We then propose heuristics to better process real data and suggest a methodology for using histograms in the context of exploratory analysis. This methodology is illustrated using some standard data sets.
Applying histograms to real-world data sets
We apply the G-Enum-fp method to the petal length variable of the iris data set [16]. The obtained histogram is presented in Fig. 10
Iris petal length histogram, with the density on a linear scale (left) and a logarithmic scale (right).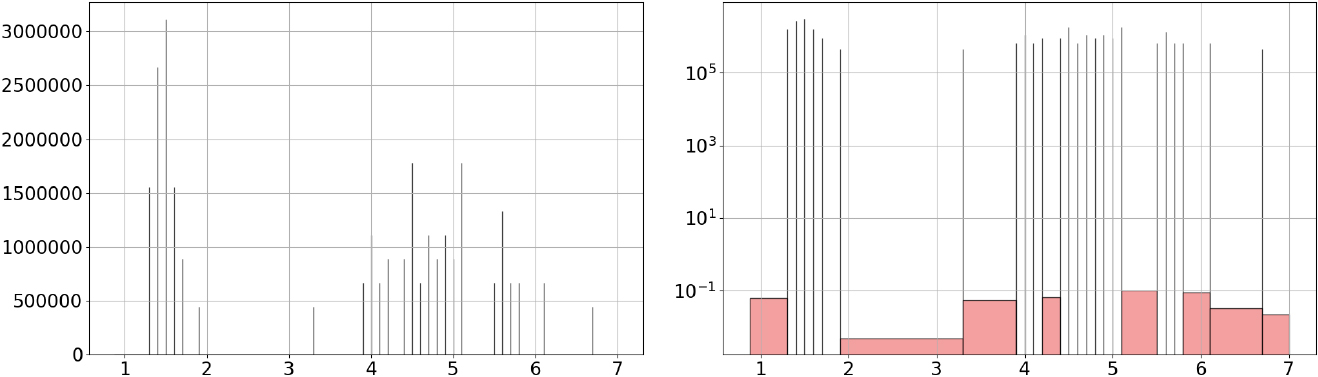
The resulting combed histogram consists of 51 intervals, 25 of them containing one single value and of width
However, this combed histogram is not very useful for exploratory analysis. Usually, this problem of truncated data is solved by practitioners by setting an adequate minimum bin width, the truncation gap, for the histogram intervals. This can be a tricky task for new data for which there is no prior knowledge to guess this truncation gap, and tedious trial and error testing may be required.
We propose an adaptation of the G-Enum-fp method to process integer data, then a heuristic to automatically process truncated data.
Dealing with integer data
First, note that all integers
the domain bounds represented by the hyper-parameters need to be integers, the exponent of the central bin is at least 0, the granulated bins are constrained to be of width at least 1.
In the main algorithm (cf. Section A.4), at each depth
This extension of G-Enum-fp to integer data allows to process truncated data with a truncation gap of 1, which translates into floating-point bins with a minimum width of
Dealing with truncated data
Our objective is to automatically process truncated data to facilitate the task of exploratory analysis. We then suggest a three-steps truncation management heuristic (TMH):
detection of truncated data, calculation of the truncation gap, construction of a histogram adapted to truncated data.
Detection of truncated data
Let us define a peak as a histogram interval which density is greater than that of its previous and next intervals, a spike as a peak containing one single value and a singularity as a spike which previous and next intervals are empty. For example, the combed histogram in Fig. 10 contains 25 spikes, 14 of which being singularities. We assume that spikes are a signature of truncated data and choose to trigger the next steps in the presence of at least one spike. We expect this very simple criterion to correctly identify most of the relevant cases while avoiding unnecessary additional computation time in the other cases.
Calculation of the truncation gap
After sorting the
Histogram of variations of values for petal length.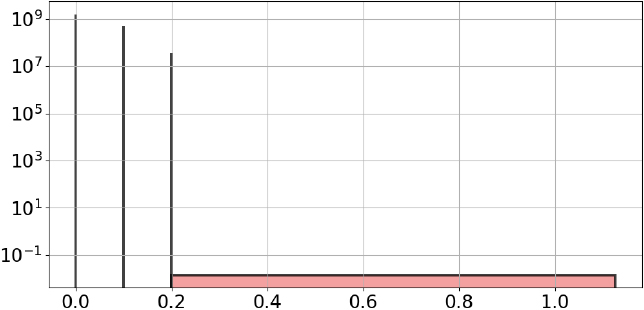
As an example, the resulting variation histogram is shown in Fig. 11 in the case the petal length variable of the iris data set. We propose to detect the following truncation pattern within the variation histogram to confirm whether the data is truncated:
the first interval contain only the value 0, the second interval is empty, the third interval has a strictly smaller length than the second interval.
This pattern is present in Fig. 11, which contains two spikes related to the variation of values 0.1 and 0.2. Note than we do not impose that the third interval of the variation histogram be a spike, in order to be resilient to potential rounding errors. We finally exploit the truncation pattern to calculate the truncation gap, as the mean value contained in the third interval, that is the averaged minimum distance between two consecutive distinct values.
Construction of a histogram adapted to truncated data
If a non-zero truncation gap
To transform the initial data and get values that are all multiples of the binary truncation gap, we project the data on the upper bounds of the floating-point bins of width
Symmetrically, the reverse transformation of the interval bounds is calculated using
Iris petal length histogram, taking into account truncated data.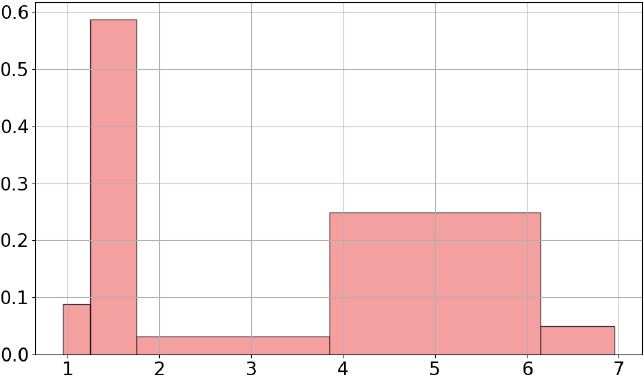
For example, the obtained histogram related to the petal length variable of the iris data set is presented in Fig. 12. It consists in five intervals, which looks reasonable given that the data set contains only 150 data entries. Its shape seems consistent with the knowledge available concerning the iris data set. It is mixture a three classes of iris flowers, setosa, versicolor and virginica, of small, medium and large sizes, with the petal lengths in
Our first objective in this paper was to devise a histogram method that could be applied automatically for the exploratory analysis of any real-world data set. While this goal seems attained in the case of artificial data set where the data generation process is controlled (see Section 6), it may not be achievable with real-world data sets. During the digitization process, the data may exhibit a wide range of tricky patterns beyond rounding or truncation issues, meaning that
“the digitized structure of the data is a much more robust feature than the statistical structure of the original data. In such cases, an uninvertible transformation has been applied to the data, and information has been irrevocably lost.” [17]
The method based on an optimal histogram algorithm [17] allows to identify digitization problems, which is useful as “it may be desirable for researchers to know that information has been discarded”. Beyond this useful feature, our relaxed goal is to help the data analyst filter the digitized structure of the data and discover its statistical structure. We suggest first computing a series a histograms of varying granularities, the finest grain allowing to discover local patterns and the coarsest grain allowing to focus on global patterns. We then provide a list a indicators per histogram to facilitate the task of exploratory analysis.
It is worth noting that this methodology may also be used with other histogram methods. However, its deep integration with the G-Enum-fp method brings several interesting advantages: resistance to outliers and heavy-tailed distributions (cf. Section 6), fine-tuning of the criterion and algorithms in the case of truncated data (cf. Section 7.2.1), and reuse of the intermediate histograms obtained at each depth of granularity as a by-product of the main G-Enum-fp optimization algorithm (cf. Section 7.3.1).
Series of histograms
We optimize a first histogram using the G-Enum-fp method and keep it even in the case of singularities, as it may bring some information regarding digitization problems (as in [17]). We then apply the TMH heuristic to build an adequate histogram if the data are detected as truncated. The current histogram, obtained for an optimal depth of granularity
To summarize, we get a list of interpretable histograms by decreasing depth of granularity,
Indicators per histogram
To facilitate the exploration of the list of interpretable histograms, we provide the following indicators based on elementary patterns: number of intervals, peaks, spikes and empty intervals. We also introduce a last indicator based on the level-fp criterion (see Section B.4) that is the percentage of information kept in an interpretable histogram compared to the finest grained interpretable histogram:
We illustrate the exploratory analysis methodology introduced in this section using some simple data sets. Extensive evaluation is performed in Section 8.
Old faithful geyser
This data set contains 272 data entries related to eruptions of the Old Faithful geyser [18], with duration and waiting time between eruptions. The duration is used in [9] to illustrate the difficulties of correctly identifying density peaks applying automatic histogram methods on heavily rounded real data. Whereas histograms with two peaks are usually expected, nine automatic histogram methods evaluated in [9] largely disagree on the shape of the histogram, building 5, 11, 19, 23, 37, 42, 111, 143 or 149 intervals.
Similarly, the G-Enum-fp method fails to identify the underlying statistical pattern and reveals the digitization structure with a histogram having 71 intervals, including 35 spikes. The TMH method identifies a truncation gap of 0.001 and outputs the interpretable histogram shown in Fig. 13a. Its contains two density peaks as expected, and its shape seems to correspond with the underlying statistical density, as suggested by a visual inspection of the scatterplot in Fig. 13b.
Old faithful geyser.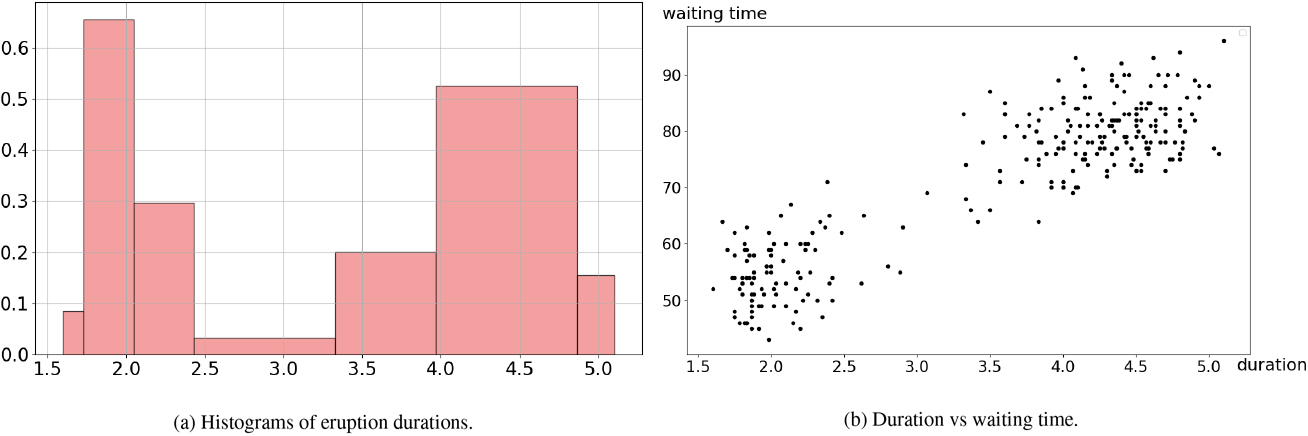
Note that the truncation pattern seems rather surprising for this data set, as only two pairs of successive values are separated by 0.001, while 31 are separated by 0.016 and 57 by 0.017. As
The adult data set [16] contains 48,842 data entries extracted from a census database. We apply our method to the age variable, which is an integer variable as ages are commonly recorded with one year precision. The G-Enum-fp method builds a raw histogram with 143 intervals, 70 of which being spikes, including 67 singularities. The TMH method correctly identifies a truncation gap of 1 and outputs the interpretable histogram shown in Fig. 14.
Age in adult data set.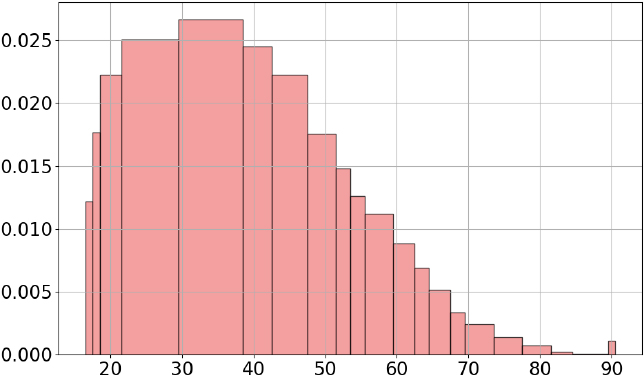
Note that there is a surprising increase of density at age 90. This pattern is confirmed by a close examination of the three last intervals of the histogram, with 39 people between 82 and 84 years of age, 17 between 85 and 89 years of age, and 55 for 90 years of age, the maximum age in the data set. This may indicate that people over the age of 90 were all recorded with the age of 90.
Discussion
For illustration purposes, the raw histogram obtained before applying the TMH heuristic is shown in Fig. 15a. This raw histogram is a very accurate density estimator for this data set containing 48,842 data entries for only 74 distinct values. All ages except two are distributed in bins of very small width separated by empty bins almost a year wide. The two exceptions contains too few data entries to be isolated: one data entry for age 86 and two for age 89. Although this histogram is very accurate, it is of little interest for exploratory data analysis.
A regular histogram with a suitably chosen equal-width (value 1 year) is also presented in Fig. 15b. It gives the overall shape of the data, but is very noisy, compared to the interpretable histogram obtained using the TMH heuristic (see Fig. 14) which recovers a smooth version of the distribution.
Let us note that histograms for mixed discrete-continuous data have been proposed [19], with a user-defined threshold (e.g. 5) for detecting discrete values and a histogram method for the rest of the data. In the case of the adult data set, this approach would result in a histogram similar to that shown in Fig. 15a, as most values would be detected as discrete. It is not suitable in the case of truncated data, where the discrete nature of the data is an artifact of the digitization process, masking the underlying statistical patterns of interest.
Raw histogram (log scale) and regular histogram (equal-width 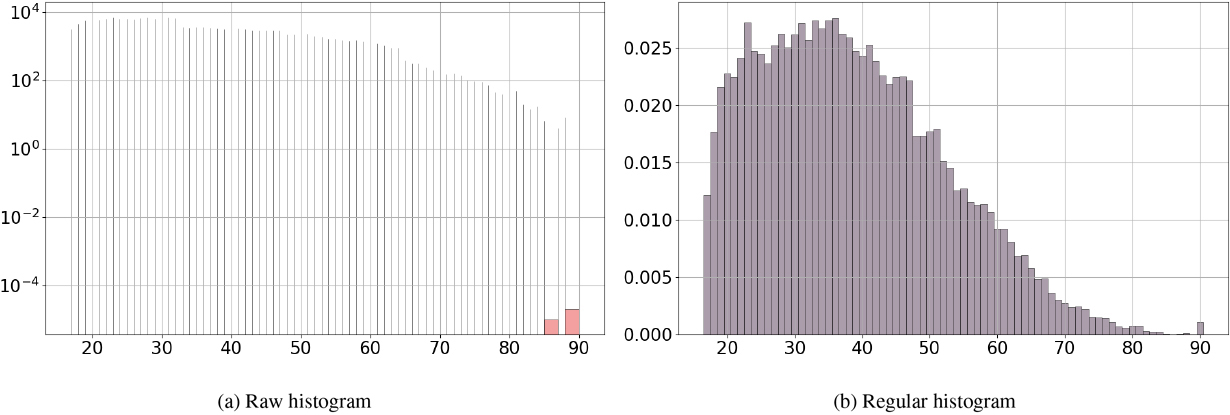
The forest cover type data set [16] contains 581,012 observations (
Forest cover type: Indicators per depth of granularity.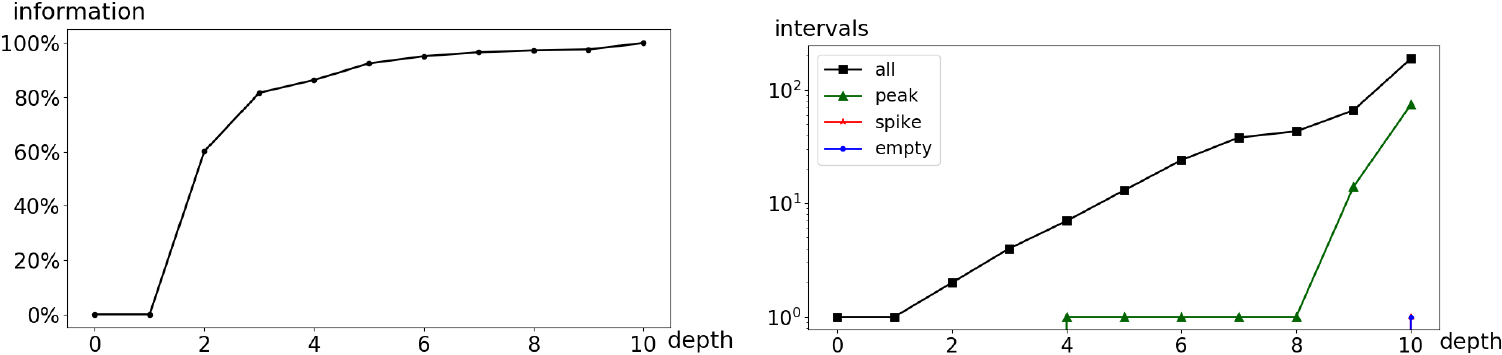
Applying the methodology introduced in Section 7.3, a series of histograms is collected for all the coarse-grained depths of granularities, starting from the 1st interpretable. The indicators collected per histogram are displayed in Fig. 16. They suggest to exploit a two times coarsened histogram to eliminate the comb-like pattern while preserving most of the information. The resulting unimodal histogram shown in Fig. 17b is rather smooth and suitable for an easy interpretation, while keeping 98.9% of the information.
Horizontal distance to nearest roadway in forest cover type data set.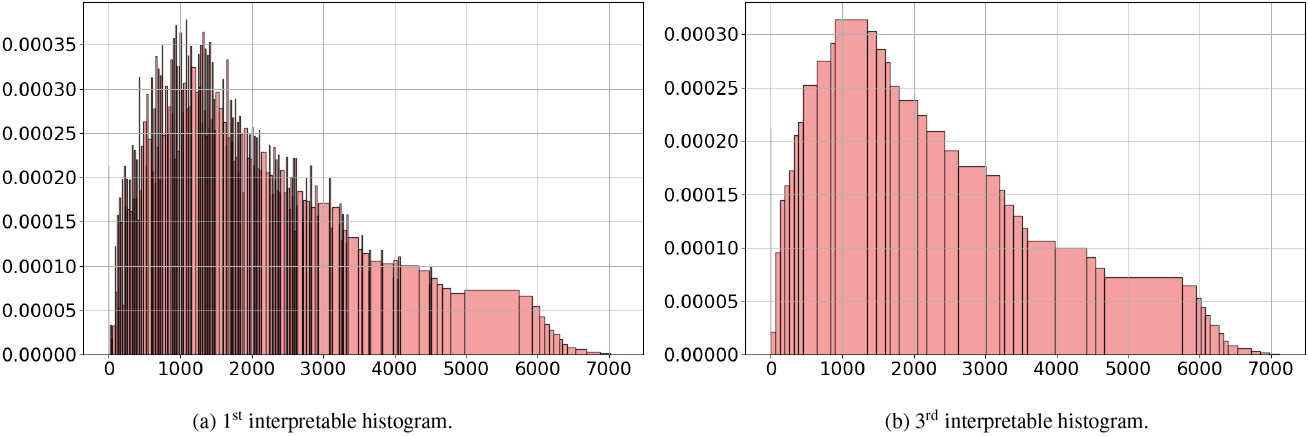
In this section, we evaluate the floating-point histograms as well as the methodology introduced in this paper for exploratory data analysis, using several large scale real-world data sets.
Evaluation protocol
Histograms are widely used in exploratory data analysis (EDA) [20] as visualization tools in the data discovery process. However, in the case of challenging real-world data sets, they are difficult to use in practice. Even state-of-the-art histograms are hardly usable in the following cases:
The purpose of this section is to assess whether the proposed exploratory methodology, based on the G-Enum-fp method, is capable of pushing the limits of the effective use of histograms for EDA. The approach is evaluated using several real world data set that combine multiple challenges: heavy-tailed distribution, integer data, large scale, complex patterns. As there is no ground truth in EDA, the evaluation cannot be measured objectively. Instead, the patterns recovered using the proposed approach are compared to the prior knowledge available for each data set.
Moon crater Salamuniccar: indicators per depth of granularity.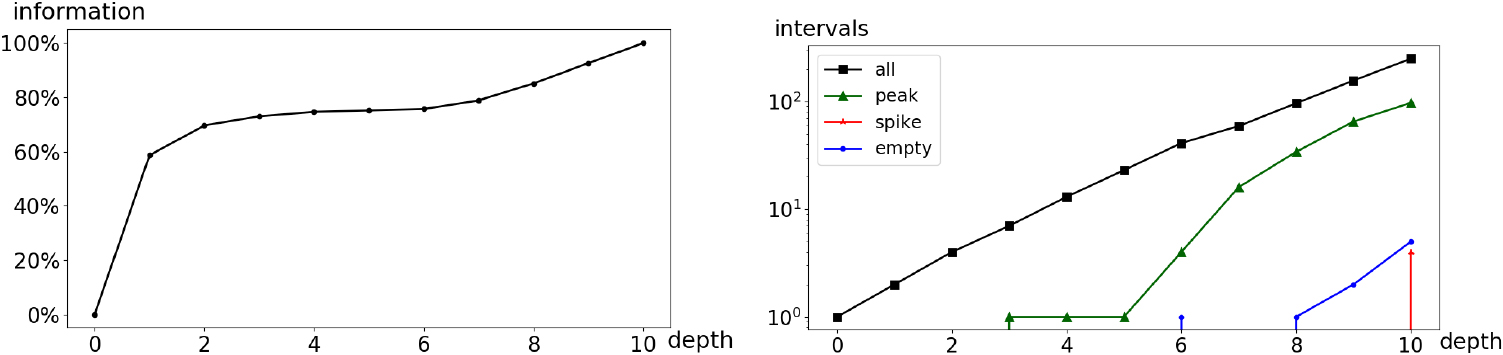
Moon crater Salamuniccar database.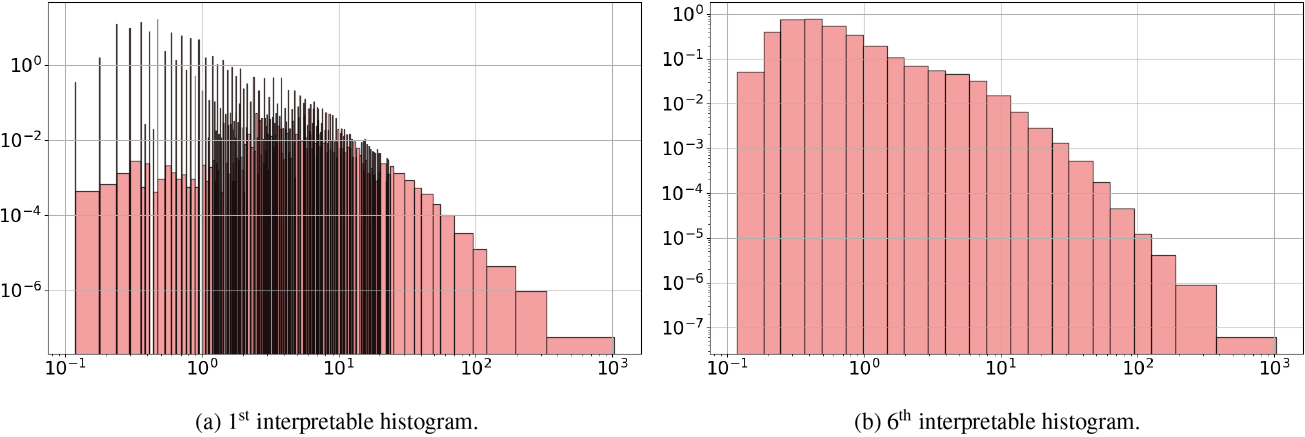
The moon crater Salamuniccar database [21]2 is a catalog of 78,287 lunar crater impacts. We exploit this database to analyze the distribution of the radius of the craters. The raw histogram output by the G-Enum-fp method contains 2,497 intervals, including 1,204 spikes and 325 singularities. The TMH method identifies a truncation gap of
Applying the methodology introduced in Section 7.3, the indicators related to coarser-grained histograms are displayed in Fig. 18. They suggest using the 6th histogram, obtained at depth 5, which is reduced to a unimodal distribution summarized with 23 intervals (see Fig. 19b). Even with this small number of intervals, the floating-point representation allows to recover a global shape in power law. Still, the information curve in Fig. 18 suggests a loss of information of more than 20% during this coarsening process, especially for crater diameters smaller than 10 km, as shown in Fig. 20. This is consistent with the data collection process and may caution the data analyst to avoid drawing too precise conclusions from this data set.
Moon crater Salamuniccar database: intermediate histograms.
The moon crater Robbins database [22]3 contains approximately 1.3 million lunar impact craters. This recent database is estimated to be a complete census of all craters larger than approximately 1 to 2 km. The G-Enum-fp method directly builds an accurate and smooth histogram with 87 intervals that looks easy to interpret, as shown in Fig. 21. It captures a power law decrease of the densities for craters between 1 km and 2,500 km, in line with astrophysics literature: power or multiple power laws are often used to fit the crater size distribution [23].
Moon crater Robbins database.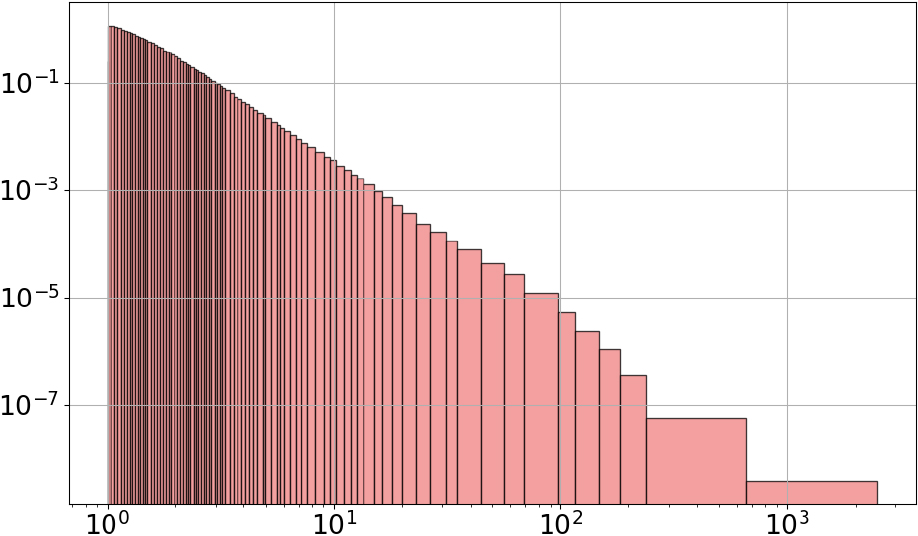
The HYG stellar database [22]4 contains 119,614 star records from three catalogs: Hipparcos, Yale Bright Star and Gliese. We exploit this database to analyze the distribution of stars’ luminosity, as multiples of the Solar luminosity. The raw histogram output by the G-Enum-fp method contains 17,032 intervals, including 8,513 spikes and 7,348 singularities (see Fig. 22a). Although the luminosity is recorded with an accuracy of 10 decimal digits, there are only 13,451 distinct values for 119,614 records, which explains the raw histogram with a very comb-like shape.
HYG stellar database.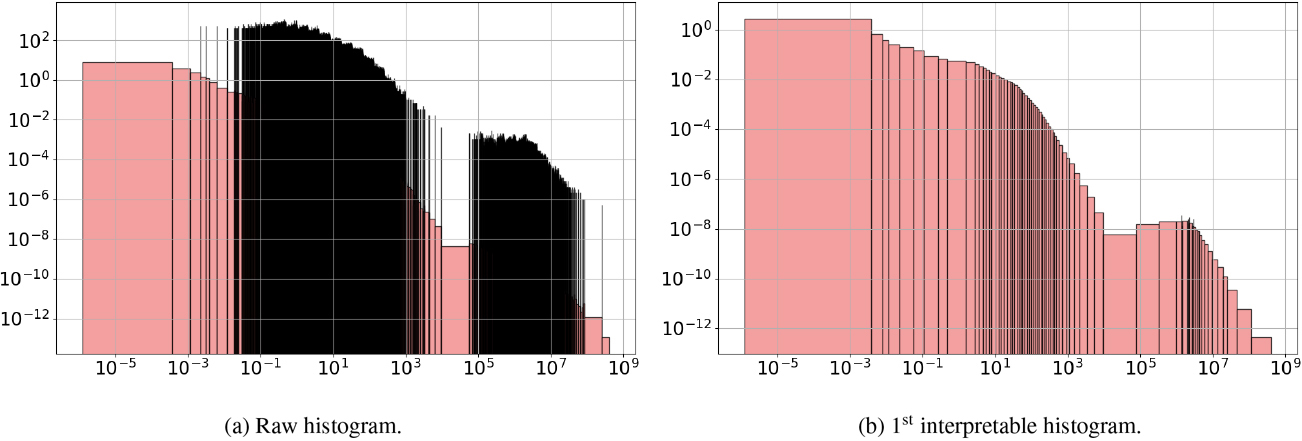
No truncation gap is identified, and the
The data set studied here is composed of nearly 25 million entries of cumulated call durations for incoming calls collected during one day, for a large sample of phone numbers of the Orange telecommunication company.5 The TMH method correctly identifies a truncation gap of 1 related to a one second precision and directly outputs the histogram displayed in Fig. 23, that consists of 222 intervals, with no singularity.
Orange CDR.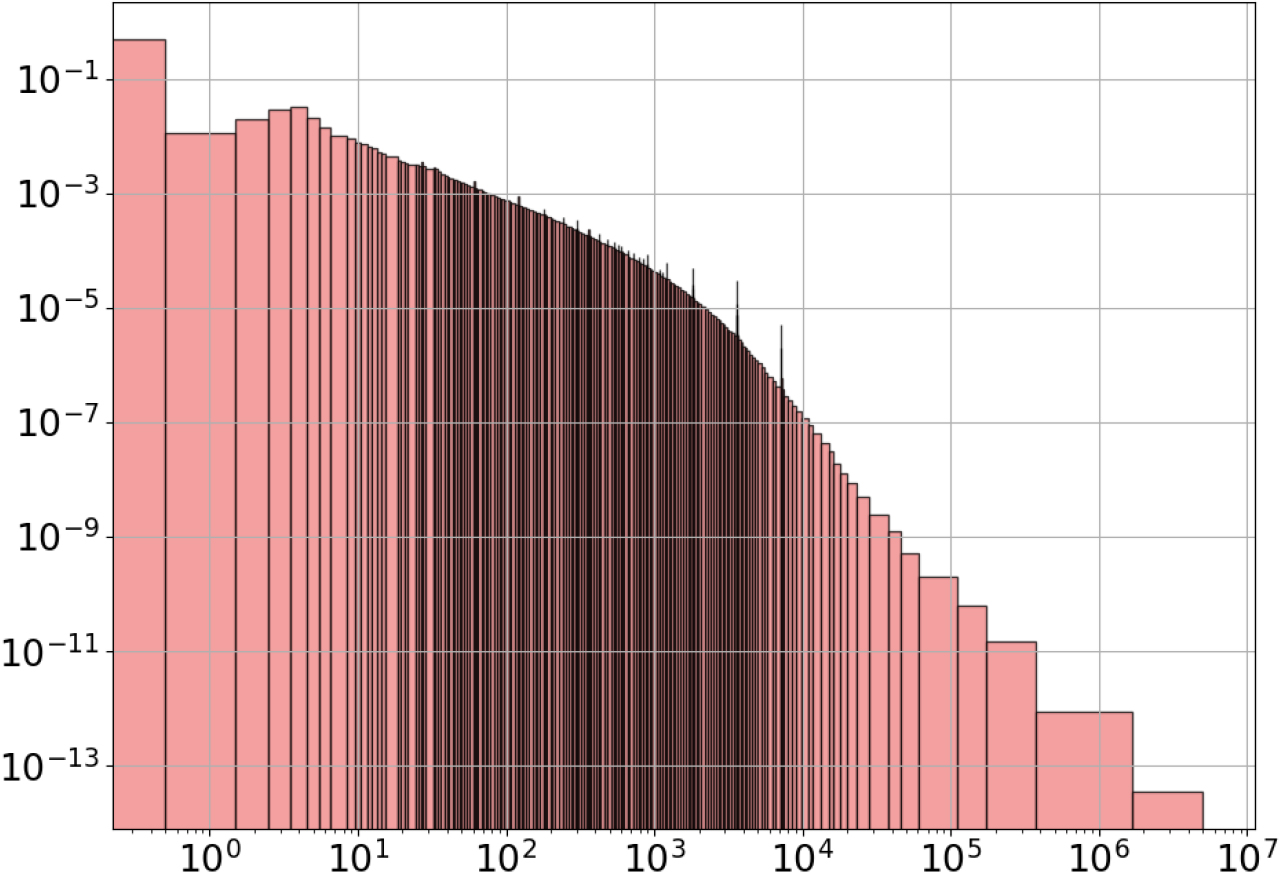
The fairly compact representation provided by this histogram summarizes a lot of information, beyond the overall shape of the distribution previously known as being heavy-tailed. For example, the first dense interval corresponds to phone numbers without any calls during the day, resulting in a cumulated call duration of 0 seconds. It spans over just one second but represents about half of the data set. Strikingly, the last interval covers about 3 million seconds and only accounts for 3 data entries, related to incoming calls collected one day that lasted more than one month. Another finding is that the heavy-tailed form exhibits two distinct power-law regimes, with a transition for durations of around one hour.
While the histogram looks globally smooth, there still are several dense peaks in-between. One could apply the methodology introduced in Section 7.3 to treat these peaks as digitization patterns and discard them, but they seem to be robust patterns that can only be eliminated after coarsening the histogram almost ten times. The three most notable peaks in the right (in the range
Overall, this histogram provides an insightful summary with both global and local patterns that were previously unknown to domain experts.
The eu-2015 data set6 is a large snapshot of the Web graph for European countries in 2015, collected by the Laboratory for Web Algorithmics [24, 25]. It consists of about 1 billion nodes and 92 billion edges. We focus on the in-degrees per node, that is the number of edges that point to a given node. These values range from 1 to more than 20 million, with 86 on average. There are only about 71,000 distinct values for in-degrees, which is a surprisingly very small number given the billion data entries. The visualization plot proposed on the website for the data set is shown in Fig. 25a. It shows a frequency plot of the in-degrees, as well a smooth approximation of the distribution using Fibonacci binning.
LabWeb: Indicators per depth of granularity.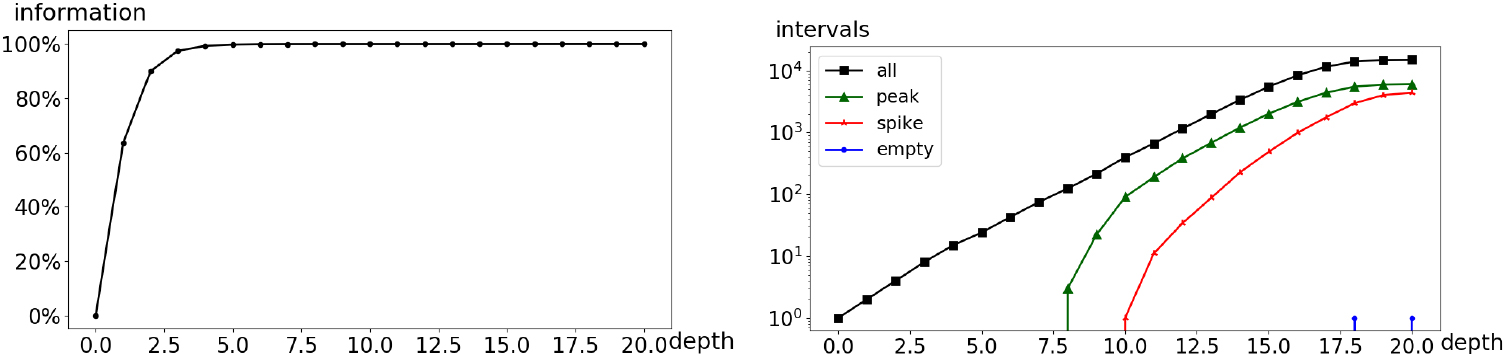
LabWeb.
The values of the in-degrees are integers, which is correctly retrieved by the TMH method, with a truncation gap of 1. The 1st obtained interpretable histogram, presented in Fig. 25b, contains 15,034 intervals. The histogram shows a clear decreasing power law behavior, with most of the nodes having a very small in-degree, and very few nodes having huge in-degrees. The first interval contains about 230 million nodes with a in-degree of 1. The last interval contains only 7 nodes (among 1 billion), for in-degrees spanning from 2 million to 20 million.
Although the general shape of the histogram is quite straightforward, it looks noisy for in-degrees between 1,000 and 1,000,000. A close inspection at some of these dense peaks shows that they are not pure noise: they actually reveal some surprising patterns. For example, there is one interval that contains 59 nodes with 297,690 or 297,691 in-degrees. It is surrounded by two intervals that are about one thousand times less dense: one with 14 nodes spanning over 2000 in-degrees values and another with 152 nodes spanning over 15,000 in-degrees values. Having such a concentration of node with almost exactly the same huge in-degree might be the signature of a Web farm.
Applying the methodology introduced in Section 7.3 allows to get a simplified summary of the in-degrees distribution and to capture its global shape. The indicators displayed in Fig. 24 suggest to coarsen the histogram from its initial granularity depth 20 down to 7, which is a considerable coarsening albeit with minimal loss of information. The simplified histogram, shown in Fig. 25c, consists of 75 intervals chosen among only 93 floating-point bins. It has a smooth decreasing power-law shape on seven orders of magnitude for the in-degrees and 15 orders of magnitude for the densities. The density estimation is accurate enough to distinguish two regimes for the power law, before and after around 10,000 in-degrees. It should be noted that these results are visually consistent with the frequency plot and Fibonacci binning provided with the data set (cf. Fig. 25a), both for the noisy patterns for in-degrees above 1,000 and for the overall shape of the distribution.
The New York Times Annotated Corpus (NYTAC)7 contains over 1.8 million articles written and published by the New York Times between January 1, 1987 and June 19, 2007. Texts can be decomposed into sets of tokens, where tokens can be words, letters or even bytes, or their sequences named n-grams: n-grams of words, letters or bytes. In this section, we study the decomposition of the articles of the NYTAC into n-grams of bytes. There are about 166,000 distinct 3-grams in the corpus and their total number of occurrences is about 6.2 billion. Let us call the popularity of a 3-gram its number of occurrences in the corpus. A popular 3-gram has a large number of occurrences, while a noteless one has a small number of occurrences.8 We apply the G-Enum-fp method to summarize the density of this popularity variable for the 3-grams in the NYTAC. The popularity is an integer variable, which is recovered by the TMH method using a truncation gap of 1. The resulting histogram has 73 intervals and is directly interpretable, with a very smooth shape, as shown in Fig. 26a.
New York Times Annotated Corpus: Popularity of n-grams.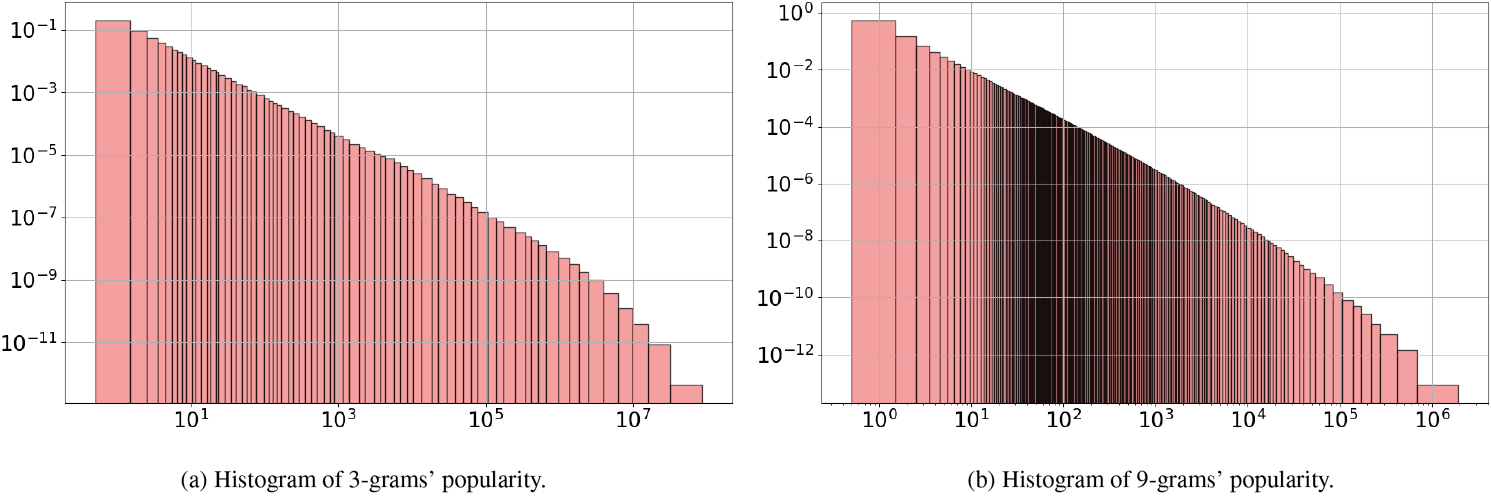
We evaluated the popularity of all n-grams of bytes, from 1-grams to 9-grams. We report the results for the 9-grams, which are the most numerous, with about 254 million distinct 9-grams in the corpus. The noteless 9-grams are very frequent, with over 134 million 9-grams having a popularity of 1. And the popular 9-grams are rare, the most popular “for the” having a popularity of around 1.9 million. The resulting histogram displayed in Fig. 26b is very accurate, with 230 intervals and a density spanning over 12 orders of magnitude. The length of the 65 first intervals is 1 while that of the last interval is greater than 1.2 million. This last interval contains the 27 most popular 9-grams, that behave as outliers in this histogram.
The histograms build for each kind the n-grams provide a smooth and accurate estimation of the underlying probability density function of the popularity of the n-grams. Although the data set combines several challenges, with integer data in addition to heavy-tailed distribution and large size, the retrieved histograms do not suffer from com-shaped or noisy patterns such as those displayed in Fig. 15. They are remarkably smooth and parsimonious, which make them easy to analyze and interpret. The shape of the density function given by the histograms is very similar for each kind of n-grams. It is almost a straight line, especially for the noteless n-grams, but is still concave, especially for the popular n-grams.
New York Times Annotated Corpus: Zipf curves of 3-grams.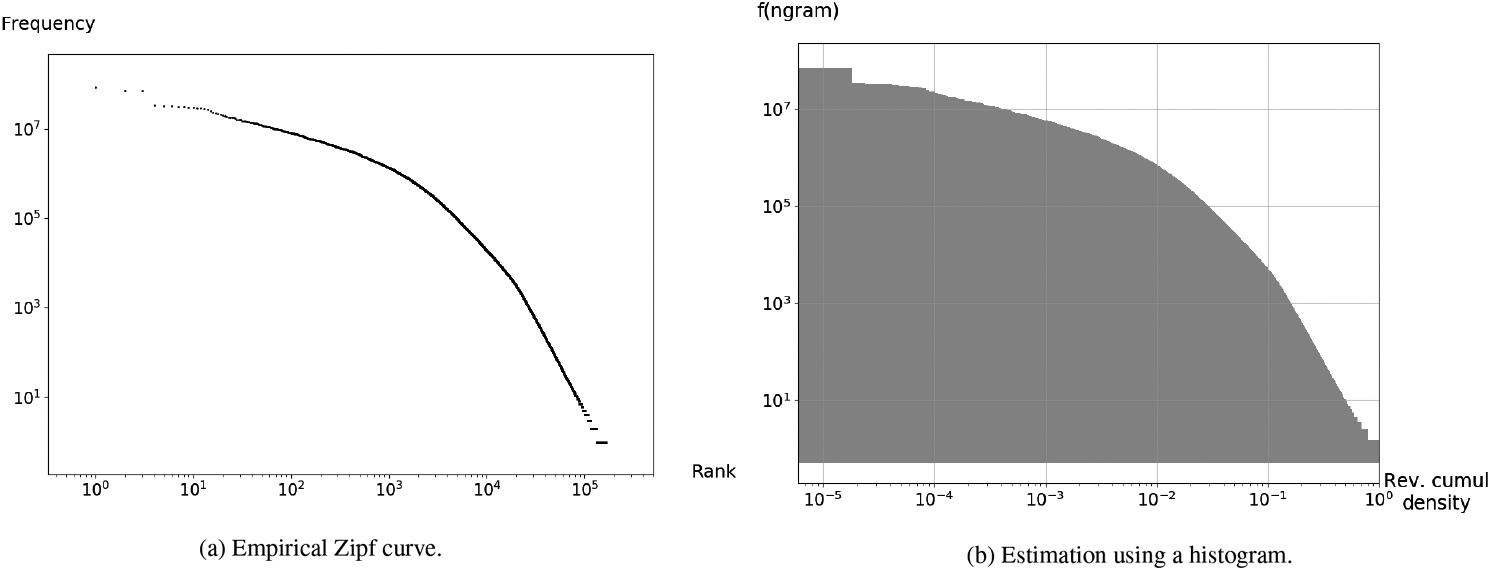
The frequency of tokens in text corpora has been widely studies in the literature. The Zipf’s law [26] for word tokens in a corpus states that if
The Zipf curve for 3-grams in the NYTAC is drawn in Fig. 27a. Except for the least frequent 3-gram on the right side of the curve, the shape of the curve is clearly concave, far from a straight line. We now focus on the relationship between the Zipf curve for 3-grams in Fig. 27a and the probability density function of the popularity of 3-grams in Fig. 26a. Let
where
where
This demonstrates that the Zipf curve is none other than the empirical ccdf of the popularity drawn using a
In line with our goal of exploratory analysis of large scale real-world data sets, we chose the G-Enum histogram method [6] as our starting point because it is automatic, scalable, parsimonious and achieves state-of-the art accuracy in density estimation. The G-Enum method builds irregular histograms with intervals of variable lengths, based on a modeling space consisting of equal-width elementary bins. This makes sense for a piecewise-constant density estimator for distributions with real values in
In this paper, we have suggested to extend the G-Enum method, by replacing its equal-width elementary bins by floating-point elementary bins that exploit the floating-point representation of real numbers on computers. This alternative representation space enables to treat any data set that can be represented on a computer, rather than data sets with values in
However, these very promising results collapsed during the first experiments with real data. The problem is not the limited precision of the computer representation of real numbers. As shown by artificial experiments with known distributions, the precision of the 15-digit decimal mantissa is clearly sufficient, even in the case of very large data sets. The problem is that real-world data sets involve a digitization process, with many potential issues such as for example, inherently integer data, biased data collection, limited recording accuracy, data transformation, rounding or truncation errors. As the size of the data sets increases, the digitized structure of the data may dominate the statistical structure of the original data, and accurate histograms retrieve the dominant structure, which may be of little interest for exploratory analysis. Abandoning the objective of fully automated histograms for exploratory analysis, we have proposed heuristics to process truncated data and eliminate singularities, as well as a methodology to facilitate the task of recovering the statistical structure of the data beyond their digitization structure. Extensive experiments on large scale real-world data sets show the effectiveness of the approach.
The first immediate objective of future work is to apply the methodology proposed in this paper to discover new insights in areas where histograms could not be easily applied previously. Another research direction includes extensions of the G-Enum-fp method to the processing of huge data stores or fast data streams. Finally, it is noteworthy that one of the most striking surprises in this article is the strong interweaving of digitization and statistical structures in large real-world data sets. This implies that accurate methods can sometimes produce results without much interest. As the current trend in supervised classification is to apply methods with numerous parameters on very large data sets, one can cautiously consider the excellent accuracy of the predictions obtained. Analyzing this potential issue appears to be a promising direction for research.
Footnotes
User parameters (e.g.
For privacy reasons, this data set is not publicly available.
Available at
Available from the Linguistic Data Consortium (LDC) at
This notion of popularity for 3-grams has been introduced to avoid confusing comments such as “frequent words are rather infrequent” or “rare words are very frequent”.
The normalized word frequency
Appendix
G-Enum-fp histogram method
In the Section 4, we have exploited the floating-point representation of real values to introduce an alternative definition of the elementary bins used as building blocks for a new histogram method called
Properties of G-Enum-fp method
In this section, we further analyze the G-Enum-fp criterion and investigate on some of its properties.
Experiments with common artificial data sets
In this appendix, we evaluate the G-Enum-fp method in the case of common artificial data sets, using the uniform, normal and a mixture of normal distributions. The evaluation protocol is that of Section 6.1.