
Abstract
Due to the rapid development of industrial manufacturing technology, modern mechanical equipment involves complex operating conditions and structural characteristics of hardware systems. Therefore, the state of components directly affects the stable operation of mechanical parts. To ensure engineering reliability improvement and economic benefits, bearing diagnosis has always been a concern in the field of mechanical engineering. Therefore, this article studies an effective machine learning method to extract useful fault feature information from actual bearing vibration signals and identify bearing faults. Firstly, variational mode decomposition decomposes the source signal into several intrinsic mode functions according to the actual situation. The vibration signal of the bearing is decomposed and reconstructed. By iteratively solving the variational model, the optimal modulus function can be obtained, which can better describe the characteristics of the original signal. Then, the feature subset is efficiently searched using the wrapper method of feature selection and the improved binary salp swarm algorithm (IBSSA) to effectively reduce redundant feature vectors, thereby accurately extracting fault feature frequency signals. Finally, support vector machines are used to classify and identify fault types, and the advantages of support vector machines are verified through extensive experiments, improving the ability of global search potential solutions. The experimental findings demonstrate the superior fault recognition performance of the IBSSA algorithm, with a highest recognition accuracy of 97.5%. By comparing different recognition methods, it is concluded that this method can accurately identify bearing failure.
Introduction
Currently, with the development of the industrial sector, there is an increasing demand for various types of machines. Rolling bearings are prevalently acknowledged as the prominent mechanical elements observed in nearly all types of rotating machinery, and their condition directly affects the operation of the entire equipment [1,2]. Due to prolonged high-temperature and high-speed operation, the possibility of mechanical failures in rolling bearings is quite high [3]. Bearing failures account for more than 30% of all failures in rotating machinery. When these failures become severe, they can lead to increased production losses and maintenance costs. Consequently, the accurate identification and assessment of rolling bearing failures are of utmost importance in maintaining the reliable and safe operation of equipment [4,5].
Extracting the characteristic information of bearing faults from non-stationary signals is crucial for identifying bearing faults [6]. Currently, signal decomposition methods commonly employed encompass time-domain analysis, frequency-domain analysis, and time-frequency domain reconstruction techniques. Xue et al. [7] proposed using adaptive interpolation-based Fourier transform to efficiently analyze and model pulse eddy current signals, thereby calculating changes in harmonic impedance. However, Fourier transform has limited processing capabilities for non-stationary signals and can only obtain overall frequency components contained in a segment of the signal without knowledge of the occurrence time of each component. Additionally, Wang et al. [8] proposed a novel approach by combining empirical mode decomposition (EMD) with time-frequency peak filtering (TFPF) to address noise in the accelerometer calibration procedure. This innovative method proves successful in suppressing random noise that arises during the calibration process. However, EMD also has drawbacks, such as mode mixing, endpoint effects, and difficult-to-determine stopping conditions. To overcome these drawbacks, scholars have proposed variational mode decomposition (VMD). Luo et al. [9] used VMD in wind turbine gearbox fault diagnosis to decompose current signals and obtain intrinsic mode functions related to faults, which has significant advantages in terms of classification accuracy, simplicity, and efficiency. He et al. [10] effectively extracted fault information of flywheel energy storage system bearings using parameter-optimized VMD energy entropy method, taking into account the nonlinearity and non-stationarity of bearing signals. The results show that VMD can accurately extract the main mode, improve the mixing effect and endpoint effect in EMD modes, and have stronger robustness to noise. Given the successful experience mentioned above, this article uses VMD to decompose the source signal into multiple intrinsic mode functions, which are a combination of different frequency and amplitude features in the original signal. By using these intrinsic mode functions to decompose and reconstruct the bearing vibration signal, and through iterative search, adjusting the parameters of the VMD model and the selection of intrinsic mode functions, the optimal mode function that can better describe the characteristics of the original vibration signal is ultimately found.
The effective application of machine learning algorithms in fault recognition technology can solve many specific problems. For the bearing fault problem in rolling elements, machine learning methods can eliminate some irrelevant and redundant feature information. Feature selection refers to the process of eliminating redundant features and identifying an optimal subset of features for addressing a given problem [11]. This elimination of features serves multiple purposes: reducing data size, improving feature quality, and reducing complexity, which all contribute to the effective performance of diagnostic models [12]. Evaluation criteria classify feature selection methods into three main categories: wrapper, filter, and embedded methods [13]. Classic feature selection methods include univariate feature selection, linear modeling and regularization, recursive feature elimination, etc. [14]. However, due to the involvement of various complex sensor data such as vibration, sound, and temperature in bearing faults, these multi-dimensional data features often have high correlation and interactivity. Traditional feature selection methods are difficult to adapt to specific problems and data characteristics. The metaheuristic algorithm has good global search ability and can effectively handle complex feature selection problems. Therefore, the search algorithm based on metaheuristic has attracted great attention to solving feature selection problems. This article adopts a commonly used optimization algorithm to search for feature subsets for feature selection, filtering the decomposed signal to obtain maximum accuracy and fewer signal features.
Metaheuristic optimization algorithms are divided into evolutionary-based algorithms, physics-based algorithms, swarm intelligence-based algorithms, and human-based algorithms [15]. The most noteworthy of these is swarm intelligence (SI)-based algorithms, which solve optimization problems by imitating cooperative social behaviors of birds, animals, fish, and insects. Some popular SI-based algorithms include genetic algorithm (GA), particle swarm optimization (PSO), bat algorithm (BA), etc. They are all random optimization techniques that attempt to obtain better solutions by invoking feedback and heuristic information. However, these traditional optimization algorithms have a slow convergence speed and are sensitive to parameter settings when dealing with complex fault data, requiring a lot of parameter settings to balance the exploration and utilization capabilities of the algorithm. More importantly, due to the lack of differentiation in the search process, it is difficult to fully explore the whole solution space, resulting in these traditional optimization algorithms more easily falling into the local optimal solution. The Salp Swarm Algorithm (SSA) is a relatively new swarm intelligence algorithm that simulates the foraging behavior of simulated groups in the ocean. As a new heuristic optimization algorithm, SSA has the advantage of minimizing parameter requirements and being effective for both continuous and discrete problems. Integrating multiple random operators into SSA can effectively improve the initial random solution, making the algorithm better avoid using local solutions in multimodal search environments, thereby improving optimization efficiency and accuracy. Since bearing faults often show complexity and uncertainty, once a bearing fault occurs, fault diagnosis must be carried out immediately according to the fault characteristic frequency signal [16]. However, the performance of SSA in bearing fault diagnosis is rarely reported in the literature. Therefore, this study introduces an improved binary salp swarm algorithm (IBSSA). IBSSA utilizes the advantages of the SSA algorithm in solving search space difficulties and unknown practical problems, overcoming the binary encoding problem of the original SSA algorithm in processing binary space optimization problem sets, efficiently searching feature subsets, effectively reducing redundant feature vectors, and accurately extracting fault feature frequency signals.
When useful fault features are successfully extracted, some machine learning methods can be used to automatically identify the type of rolling bearing fault. Support vector machine (SVM) is a powerful classifier, and SVM models can compress and reduce the dimensionality of raw data to reduce the impact of redundant information and noise. Due to its remarkable capability in extracting latent knowledge from limited samples, handling nonlinear data, and operating in high-dimensional spaces, SVM have gained significant popularity and usage as a vital data processing and classification technique across diverse pattern recognition applications, especially in fault state recognition for complex industrial processes [17]. Researchers have studied an adaptive microgrid fault accurate identification scheme based on support vector machines. The overall adaptable approach utilizes a two-step SVM classifier framework, which can accurately detect unstable changes in microgrids under normal and fault conditions [18]. In a previous study by Nadji Hadroug et al. [19], a fault monitoring and detection technique for gas turbine systems was proposed. The method utilized support vector machine (SVM) as its underlying framework.By using SVM for gas turbine vibration monitoring, faults can be effectively located and identified. Therefore, this paper uses SVM for fault type classification and recognition, and the advantage of SVM is verified through a large number of experiments, improving the classification accuracy and the ability to globally search potential solutions.
Overall, this article has the following contributions:
This article proposes a new method for identifying rolling bearing faults. Firstly, preprocess the vibration signals of different bearings. The denoising stage uses a VMD filtering algorithm to remove noise. Then, the packaging method is used for feature selection to identify the optimal combination of features and extract the most valuable information from the signal. The improved salp swarm algorithm effectively reduces redundant feature vectors, making it more accurate in extracting fault feature frequency signals. Finally, using support vector machines for fault classification and recognition, rolling bearing fault diagnosis is achieved. This study applies SSA to the feature selection problem in bearing fault diagnosis, benefiting from the flexibility and high randomness advantages of the algorithm in handling parameters and local solutions in different ranges. Compared with other traditional metaheuristic algorithms, SSA has the advantages of small parameter requirements, fast convergence speed, and effectiveness for both continuous and discrete problems, enabling more accurate processing of complex fault data. Integrating several random operators into SSA can effectively improve the initial random solution, avoid using local solutions in multimodal search environments, and effectively improve the accuracy and efficiency of global optimization, thus better adapting to the feature extraction requirements in the bearing fault diagnosis process. In IBSSA, an improved chaotic mapping is used to unify the initialization of population positions, achieving the goal of avoiding local optima and improving global convergence. By using the IBSSA algorithm, the continuous optimization problem is transformed into binary form, allowing the salp to move freely at any point in the search space. At the same time, using dynamic weight factors for position updates makes the population less likely to fall into local optima. Through experimental analysis, it can be concluded that IBSSA can effectively solve multi-objective optimization problems and has a strong ability to search for optimal solutions.
The remaining structure of this article is summarized as follows: Chapter 2 introduces the essential theories of relevant algorithms, including Variational Mode Decomposition (VMD), Salp Swarm Algorithm (SSA), and Support Vector Machine (SVM). Chapter 3 provides an in-depth introduction to the feature selection process based on IBSSA. In Chapter 4, a comprehensive comparative experimental analysis was conducted on the proposed bearing fault identification method, demonstrating its superiority. Chapter 5 is the conclusion.
Variational mode decomposition
VMD is a process that iteratively seeks the optimal solution of the variational model for decomposing the real-valued input signal

A method was proposed to evaluate modal components as follows: (1) The Hilbert transform was employed to calculate the relevant analytic signal for each mode, resulting in a one-sided spectrum. (2) The spectrum for each mode was shifted to baseband, and the exponent was adjusted to match the estimated center frequency. (3) The bandwidth was estimated by parameterizing the smoothness of the demodulated signal,specifically by evaluating the square of the gradient.Assuming that the signal has been decomposed into K intrinsic mode functions (IMFs) through VMD processing, the K modal functions denoted as


In order to solve the optimal solution of the variational constrained model, a quadratic penalty function along with the utilization of a Lagrange multiplier is incorporated, and it is transformed into an unconstrained optimization search problem. The classical quadratic penalty function method usually adds Gaussian noise and reconstructs fidelity, where in the weighting of the penalty term relates inversely to the level of noise inherent in the data. The Lagrange multiplier is a commonly used method for strictly enforcing constraints. Therefore, the unconstrained optimal search problem benefits from both the good convergence of the quadratic penalty and the strict enforcement of constraints by the Lagrange multiplier. The expression for the optimal solution is as follows:

To update the modal components, obtain each IMF through Fourier transform in Eq. (5), and update the central frequency of the power spectrum of each IMF as shown in Eq. (6).

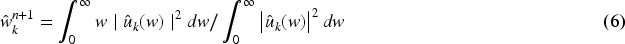
The VMD method solves the end effects and mode mixing problems of the EMD method. It splits the original signal into multiple subsets of relatively stable sequences at different frequency scales. Consequently, the ensuing analysis involves the handling of time series data characterized by elevated intricacy and robust nonlinear patterns. [21] All decomposed modes mainly include signal mode and noise mode, and the mode containing the main signal is reconstructed to achieve the denoising effect. VMD uses non-recursive iteration to decompose the signal into fewer modes represented by smaller feature subsets. Therefore, the VMD algorithm has reliable and robust decomposition results in signal decomposition.
Mirjalili et al. [22] proposed an algorithm for salp swarm and divided the whole population into leaders and followers. In which, the leader is located at the front end and guides some follower population to search for the best solution in the multidimensional search space, as shown in Fig. 1.

Structure diagram of ascidian group.
In this algorithm, the whole population is situated in the

The random initialization group formula is as follows:

Given that the search range of the search space is
Update the position formula of the leader as follows:
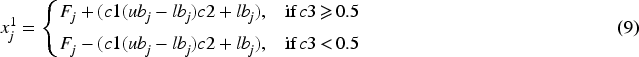



In the linear SVM classifier, the decision hyperplane can correctly separate the data points in the training set. Two regions of two types of data are separated by a straight line 
When the features in the feature space have non-linear correlations, a straight line is no longer able to achieve maximum separation between two classes of data points. Therefore, to address this issue, non-linear problems are transformed into linear problems by introducing the minimization function formula into support vector machines. SVM is then integrated with Gaussian kernel function.

That is, the inner product of
To limit the range of 
The SVM algorithm utilizes high-dimensional data and fully utilizes existing detection data to identify the maximum distance between faulty and normal data, divide them by a hyperplane, and organize a fault diagnosis model.

Flowchart of IBSSA.
This section uses feature selection methods to extract prominent signals representing underlying features, and introduces an improved salp swarm algorithm for iterative search of feature subsets. Convert the continuous versions of SSA into binary representations and introduce chaotic mapping to evenly distribute the initial population within the spatial range. At the same time, use dynamic weight factors for position updates to prevent the population from falling into local optima. This method can find values closer to the expected value in fewer iterations, improving the accuracy and efficiency of the algorithm’s solution. The flowchart of IBSSA is shown in Fig. 2.
Improved binary salp swarm algorithm
Binary salp swarm algorithm
This article optimizes feature selection problems through SSA, benefiting from the flexibility and highly stochastic advantages of the algorithm in handling parameters and local solutions of different ranges. Transforming SSA into binary form to achieve feature selection, the search restriction of salps moves within the binary space, allowing the algorithm to search and optimize the solution space more effectively.
In this paper, the V-shaped transfer function (TF) is used to transform continuous algorithms into binary versions. The function represents the probability of converting elements in the feature subset to 0 or 1. Eq. (15) represents mapping the continuous position of truth values to a binary position.

According to this function expression, use the following formula to convert it into a binary vector, where each cell in the vector has a value of 1 or 0. 1 indicates the selection of the corresponding feature; otherwise, the value is represented as 0. The position update is as follows:


The basic bifurcation diagram of the Tent map.
In the IBSSA algorithm, the population is typically initialized randomly, which increases the risk of premature convergence and can hinder the exploration of the global optimal solution. To address this issue, chaos strategies are used to allow the initial population to explore locations widely and evenly with both randomness and ergodicity. This paper introduces the Tent map initialization for the population, which has better chaotic properties than the Logistic map. The basic bifurcation diagram of the Tent map is shown in the Fig. 3, different chaotic behaviors of the x sequence obtained through iterative calculations are demonstrated for various values of r. The original Tent mappingF formula is shown in Eq. (17).

However, the Tent map is prone to getting stuck in fixed points and small cycles, resulting in simple, repetitive, and less diverse output. Therefore, this paper introduces an improved Tent map formula, as shown in Eq. (17). When 
The effectiveness of the binary SSA algorithm can be enhanced by avoiding local optima through the use of an improved Tent map, thereby enhancing global convergence. The improved Tent map introduces a sine function and a

To enhance convergence accuracy and mitigate the likelihood of encountering local optima, a weight factor 
Here, 
Due to the fact that feature selection helps to eliminate redundant features and improve the accuracy of fault diagnosis, finding representative features makes a greater contribution to fault diagnosis. In this section, for any signal decomposed into K feature vectors, different fault types will be multiples of K, which is a huge feature space that requires a thorough search. Therefore, IBSSA is used to adaptively search for the feature space representing the optimal subset of all features. The most ideal feature subset among them is to ensure the minimum classification error rate while selecting the minimum number of features. So, in IBSSA, a fitness function is used to evaluate search individuals, and the formula for the fitness function is as follows:

The proposed IBSSA-based rolling bearing diagnosis algorithm model is illustrated in Fig. 4. The process begins with data preprocessing, where the original fault vibration signal’s energy varies across frequencies. To attain a high-dimensional subset of fault features, the VMD method decomposes the signal into K IMF components. Redundant features are then eliminated from the high-dimensional feature vector using the feature selection wrapper method. The iterative search process of the IBSSA algorithm generates a low-dimensional feature subset, which is subsequently divided into a testing set and a training set. Finally, the SVM classification algorithm assesses the classification efficiency of the selected feature subset. Upon completing the model training, the trained SVM model is used to identify different bearing vibration fault states by introducing the test dataset. Figure 2 demonstrates the overall process of the proposed approach for the incipient fault diagnosis of rolling bearings.

Overall process of the proposed method for incipient fault diagnosis of rolling bearings.
Dataset description
Given that the CWRU (Case Western Reserve University) dataset [23] is commonly used as the standard case for experiments in literature, which contains test samples with different types of faults, our research results are easier to compare with previous works. This dataset uses accelerometers to collect bearing vibration data, with the accelerometer mounted on a housing with a magnetic base at the 6 o’clock position on the drive end bearing of the motor housing. Due to measurement noise interference, the initial health status of each unit is also different during the data collection process in the dataset.The CWRU rolling bearing test stand is shown in Fig. 5.
For each test case, the dataset is divided based on its speed of 1797 rpm (0HP), 1772 rpm (1HP), 1750 rpm (2HP), and 1730 rpm (3HP). Each operating condition has a complete dataset represented by different fault locations, including normal, inner race, outer race, and rolling element (ball). A sampling rate of 12 kHz was used to introduce single point faults in the test bearings with defect diameters of 7 mils, 14 mils, and 21 mils and a fault depth of 0.011 inches.
The experiment was conducted using a single-machine setup consisting of a 2 horsepower electric motor with a motor torque sensor and encoder connected to the drive end, and a generator connected to the shaft, both using a 6205-2RS JEM SKF type bearing. Four different types of faults were distinguished based on different loads and defect diameters, as shown in Table 1 of the CWRU bearing dataset. For each operating condition, 50 datasets were selected, each containing 2000 data points and 24 features, including 11 time-domain features and 13 frequency-domain features.

The CWRU rolling bearing test stand.
In this article, in order to obtain better accuracy results, it is necessary to define the VMD mode in advance. Firstly, the parameter
Data set description.

Data set description.

The original signal and the time-domain waveform and frequency spectrum of IMF1-IMF4 (from top to bottom) decomposed by VMD.

Envelope spectra of IMF1-IMF4 with different fault types.
When
Entropy analysis evaluates changes in frequency characteristics of data to ensure the accuracy of coarse-grained sequence information and provide more reliable entropy estimates. To further validate the optimal number of modes for measured signals, envelope spectrum analysis is performed on the inner circle, outer circle, and rolling unit of the IMF obtained by decomposing the fault status using the VMD algorithm. The VMD algorithm decomposes the fault signal into components 

Here,
When the optimal value of VMD parameter combination [K,
Due to the reduced fault information contained in the IMF components after IMF4, adjacent components are prone to mixed effects. If the fault characteristic frequency and biphase line amplitude are not prominent, the background noise is severe, and there are too many interference spectral lines, this will affect the analysis effect of further research. Figures 6(a) to (d) show the time-domain waveform and frequency spectrum analysis of the original signal and IMF1-IMF4, respectively (from top to bottom). The amplitude spectrum is the amplitude expression of the best component instantaneous frequency, and its amplitude is represented in a single peak form, indicating that the characteristic frequency of the vibration signal has been completely decomposed without multi-peak phenomena, and the demodulation effect is best.
From Fig. 7(b), the actual fault characteristic frequency obtained by envelope spectrum demodulation of the outer race fault is 77.46 Hz, and its fault characteristic harmonics increase to 77.64 kHz, 137.7 kHz, 215.3 kHz, and 293 kHz. Therefore, we believe that this fault is caused by periodic characteristics due to inner race defects. Figure 7(c) clearly distinguishes the fault characteristic frequency of the rolling element, with actual fault characteristic frequencies of 41.02 kHz, 98.88 kHz, 146.5 kHz, and 185.3 kHz, approximately 2, 3, 4 times the fault characteristic frequency, respectively. This indicates that the fault is caused by periodic characteristics due to rolling element defects.
Through signal analysis, it has been found that feature extraction plays an important role in fault diagnosis and can affect the accuracy and efficiency of fault diagnosis models. This article proposes three methods of feature combination, which are time-domain and frequency-domain features extracted from the original vibration signal, as well as features extracted from the IMFs obtained through VMD decomposition [24]. The feature values are then used as input subsets for building and testing the model.
To validate the performance of the IBSSA method, the CWRU dataset was divided into a 4:1 ratio of training set samples and test set samples. The experiment in this section aims to evaluate different optimization schemes for selecting important features using different algorithms, selecting 23 benchmark functions of different dimensions to test the performance of IBSSA, and comparing them with binary particle swarm optimization (BPSO), binary genetic algorithm (BGA), and binary bat algorithm (BBA). All algorithms are tested under fair and equal computing conditions, with a population size of
Table 2 lists 23 benchmark functions with different dimensions from CEC2005, where F1-F7 is an unimodal function, F8-F13 is a simple multimodal function, and F14-F23 is a composite function. Figure 8 shows a two-dimensional version example of 23 benchmark functions, from which it can be seen that the unimodal function has a unique optimal solution, which is used to evaluate the basic search and convergence ability of the optimization algorithm. Multimodal and composite functions have multiple optimal values, which are used to test the algorithm’s ability to avoid local optima and search for global optima, and the composite function is more similar to the actual search space, making it more challenging. Set the dimension to 30 to test the performance of the algorithm in challenging problems with a large number of variables.
List of the benchmark functions used in the experiments of the paper and their related information.

List of the benchmark functions used in the experiments of the paper and their related information.

2D images of 23 test functions.
CEC2005 test results.

Table 3 provides the mean and standard deviation of the objective function values for each algorithm to display the average execution and stability of the IBSSA algorithm overall running cycles. From the Table 3, it can be seen that the average and standard deviation of the IBSSA algorithm are better than other algorithms on most test functions, indicating that IBSSA is easier to find and converge to the global optimum on unimodal problems, verifying its stronger global exploration ability. From the results of the multimodal test function
The Wilcoxon rank sum test [25] is a nonparametric statistical test used to determine whether there are significant differences between the IBSSA algorithm and other algorithms. Therefore, we take the results of 30 independent tests on 23 test functions for each of the four algorithms as samples. Perform the Wilcoxon rank sum test at a significance level of 0.05 to determine whether there is a significant difference between the solution results of the four comparison algorithms and those of IBSSA. The test results are shown in Table 4. When
CEC2005 Wilcoxon rank sum test results.

As shown in Fig. 9, IBSSA began to converge at the 20th iteration, and the improvement speed of IBSSA was significantly faster than that of other algorithms, enabling the algorithm to quickly reach a balance during the search process, indicating that IBSSA’s optimization performance has good robustness.
IBSSA uses SVM as the fault classifier, introducing penalty parameter
Comparison of different feature selection methods.


Convergence curve of fitness value of different algorithms.
To further evaluate the influence of feature subsets on the algorithm, Fig. 10 shows the accuracy fluctuations corresponding to different optimization algorithms as the number of features varies. Both IBSSA and BPSO showed relatively stable accuracy when extracting optimal feature subsets, and IBSSA had already extracted the most effective feature subset when the feature quantity was set to 8. The experimental results demonstrate the good performance of the IBSSA method.
To demonstrate the superiority of the algorithm, multiple classification evaluation metrics will be used to analyze IBSSA, SSA, and standard SVM. In addition to accuracy analysis, two useful indicators are precision and recall [26]. The formula of accuracy rate, recall rate, and F-value is shown as follows, where TP represents true positives, FP represents false positives, FN represents false negatives, and TN stands for true negatives. On the one hand, to reduce the cost burden caused by unnecessary factors such as a high recall rate and low accuracy rate, a lower false positive rate is required. On the other hand, if only true errors are labeled without reporting false positive results, the accuracy rate is high but the recall rate is low. For each type of fault, a comprehensive balance of these two indicators requires the passage of time and can be calculated based on the precision and recall rates of each type of fault to obtain the F-score until the actual fault occurs, triggering an alarm without missing or false alarm.




To ensure the fairness of the experiments and the reliability of the results, we conducted 30 experiments using the same dataset. As shown in Table 6, when training with standard SVM, the algorithm iteration optimization for a certain part of features is not required due to the lack of a feature selection process, resulting in a relatively shorter training runtime and lower accuracy rate. The IBSSA algorithm selects effective feature frequencies, improving overall efficiency. Moreover, as traditional algorithms perform poorly in executing multiple classification tasks and cannot adaptively learn fault features, their feature classification effect is inferior, leading to significantly lower testing accuracy compared to other models. The experiments demonstrate that IBSSA performs well in various evaluation indicators.
Comparison of different algorithms.


Feature selection F value of different algorithms.
As shown in Figs 11 and 12, fault label 1 represents the normal type, label 2 represents the inner race fault, label 3 represents the outer race fault, and label 4 represents the rolling element fault. Samples of the same category are well-classified in the feature space, while samples between different categories are far apart. The IBSSA-based fault diagnosis algorithm mainly focuses on misclassifying test samples labeled as 2. After multiple runs, we found that the SSA fault diagnosis errors were distributed on the inner race fault, outer race fault, and rolling element fault, exhibiting unstable performance. Due to its lack of ability to find global optimum solutions, it has poor convergence. At the same time, it has weak capabilities in handling outliers and missing values, making it difficult to ensure stability when processing real-time massive data. In contrast, IBSSA significantly optimized the algorithm’s error diagnosis. The results show that the IBSSA iterative algorithm has the least number of error diagnoses and good stability.

IBSSA algorithm diagnosis result.

SSA algorithm diagnosis result.
From the diagnostic results of various algorithms, it becomes apparent that the feature selection technique proposed in this paper, known as IBSSA, surpasses alternative approaches, reflecting the most stable and highest fitness value of 98.7%. The results show that IBSSA can effectively improve the algorithm’s efficiency. Therefore, the SVM model based on IBSSA has advantages in all aspects of fault diagnosis, and the proposed feature selection method helps eliminate redundant features and improve the accuracy of fault diagnosis.
As mentioned above, the good performance of IBSSA has been verified. To provide additional evidence of the algorithm’s superior performance, we conducted a comparative analysis between the model developed in this study and three alternative fault recognition models. The results of this comparative assessment are summarized in Table 7. In these models, the experimental dataset is not processed and is split completely the same under the same dataset. As shown in the Table 7, Double SVM combined with wavelet denoising and machine learning for bearing fault diagnosis achieved an experimental accuracy of 96%. IMDE extracts multi-scale fault features from the original signal through an improved multi-scale diffusion entropy (IMDE) method, and automatically selects sensitive features using the maximum correlation minimum redundancy algorithm with an accuracy rate of 95.15%. Using the Principal Component Analysis (PCA) method to reduce the dimensionality of feature subsets. By inputting the filtered feature subset into the neural network for diagnosis, the highest recognition accuracy of 94.17% was achieved on the same dataset. These bearing fault diagnosis results indicate that the rolling bearing fault recognition method based on IBSSA proposed in this article has significant improvements compared to other traditional fault recognition methods, and the fault diagnosis rate has been significantly improved compared to other algorithms, which strongly verifies the effectiveness of this method.
Comparison of the accuracy of different classification fault models.

In this paper, the IMF obtained by VMD decomposition was chosen as the initial feature for fault diagnosis, and the feasibility of this method was demonstrated through experiments. In order to eliminate redundant and unrelated information, a feature selection method based on IBSSA was proposed to extract significant features from all features. We observed that the difference in testing accuracy between our proposed solution and other studies is not equal in magnitude. However, due to the efficient iterative calculation of the algorithm, it has improved the recognition accuracy to some extent, while also efficiently extracting features of test samples, thus better enhancing the signal extraction with practical physical significance and achieving global optimization of classification performance.
As industrialization continues to advance, high-quality processing of industrial big data has become particularly important. In order to accurately identify different fault states of bearings in massive data and prevent production stagnation and increased maintenance costs due to faults, this article proposes a new method for bearing fault diagnosis based on an improved salp swarm algorithm. Through performance testing of the algorithm and instance simulation analysis, the results show that:
Vibration signal fault diagnosis is mainly divided into three parts: data preprocessing, feature selection, and fault recognition. The VMD method is used to preprocess the collected vibration signals, observe the amplitude of the impact pulse and the spectrogram of its time domain waveform, and determine the size of K value using the center frequency. The IBSSA algorithm converts continuous space into binary space and introduces chaotic mapping and inertia weighting factor to balance the trade-off between global search and local search, in order to achieve higher search efficiency and better global optimal solution. The wrapper method of feature selection is used to reduce the dimensionality of fault feature components, and the IBSSA algorithm is used to iteratively search for low-dimensional feature subsets in the feature space. Finally, BPSO, BGA, BBA, and BSSA are selected for analysis, and the performance of the algorithms under different evaluation criteria is compared. The results show that the research method proposed in this paper has the best classification effect and is superior to other methods in terms of accuracy and stability. By analyzing the vibration signals of bearings and identifying the type of fault, the industrial bearing fault problem is effectively solved, thereby reducing the error rate of faults and repairing them more effectively.
It should be noted that this method is only validated based on the data obtained by the testers from the signals. In practical engineering, the signals emitted by faulty equipment will be even weaker and more complex. Therefore, before actual application, this method still needs to undergo further preprocessing. This is our future research direction.