
Abstract
While time series data are prevalent across diverse sectors, data labeling process still remains resource-intensive. This results in a scarcity of labeled data for deep learning, emphasizing the importance of semi-supervised learning techniques. Applying semi-supervised learning to time series data presents unique challenges due to its inherent temporal complexities. Efficient contrastive learning for time series requires specialized methods, particularly in the development of tailored data augmentation techniques. In this paper, we propose a single-step, semi-supervised contrastive learning framework named nearest neighbor contrastive learning for time series (NNCLR-TS). Specifically, the proposed framework incorporates a support set to store representations including their label information, enabling a pseudo-labeling of the unlabeled data based on nearby samples in the latent space. Moreover, our framework presents a novel data augmentation method, which selectively augments only the trend component of the data, effectively preserving their inherent periodic properties and facilitating effective training. For training, we introduce a novel contrastive loss that utilizes the nearest neighbors of augmented data for positive and negative representations. By employing our framework, we unlock the ability to attain high-quality embeddings and achieve remarkable performance in downstream classification tasks, tailored explicitly for time series. Experimental results demonstrate that our method outperforms the state-of-the-art approaches across various benchmarks, validating the effectiveness of our proposed method.
Keywords
Introduction
Time series are utilized for a variety of tasks in a wide range of scientific and industrial areas, including health assessment in medical fields, human activity recognition, and industrial process monitoring [1, 2, 3]. Recently, interest in time series classification tasks has grown substantially due to the increase in the amount of available data. With this increase in data, achieving optimal classification performance becomes increasingly crucial [4]. The success of the classification task depends not only on the quantity and quality of the observed data but also on the availability of sufficient annotated label information [5, 6].
Unlike other types of data, time series can be continuously generated as long as the source remains available for collection [1]. This is highly likely to result in the accumulation of large amounts of unlabeled data in practice, which is attributed to the fact that labeling time series sequences is a time-consuming and labor-intensive process [7, 8, 9]. Consequently, the lack of labeled data poses a huge challenge in applying deep learning approaches to time series tasks. This is due to the inherent limitation of deep neural networks, which heavily rely on a large number of labeled samples for training [6].
There has been a surge in research efforts aiming to tackle these challenges through self-supervised representation learning methods [5, 10]. In particular, contrastive learning has emerged as a promising approach in computer vision, demonstrating superior classification performance compared to other representation learning techniques [11, 12]. It leverages the data structure to learn meaningful representations without relying on explicit labels, effectively utilizing the information inherent in the data. This method focuses on maximizing agreement between differently transformed views of the same instance, while minimizing it between others. As a result, it can capture complex, high-level features without the need for extensive labeled data, making it particularly effective for tasks with limited annotations [13, 14].
Meanwhile, self-supervised contrastive learning models carry the risk of treating instances from the same class as negatives, which could potentially undermine their performance. To further enhance the potential of this approach, semi-supervised contrastive learning attempts to utilize a subset of labeled instances, leading to improved performance and potentially surpassing the capabilities of self-supervised methods in time series analysis [15, 16].
Many of these studies follow multi-step approaches where they first generate pseudo-labels from a pretrained encoder and then train the model using them. This sequential process implies that valuable label information is not exploited in the initial phase of encoder training, which is a key period for learning representation. Although some strategies have attempted to address these issues with the use of supervised contrastive loss and hard pseudo-labeling [15], these methods still face challenges due to the reduced learning efficiency from inaccuracies in pseudo-labeling in the early stages of training [17, 18].
On the other hand, data augmentation is also known to be essential for successful learning in contrastive learning for time series [19]. Augmentation methods using random transformations, such as jittering and scaling, have had a significant effect on improving learning performance in the field of computer vision [20]. However, directly applying these methods to time series data may not produce comparable results as those observed in other fields [21]. This may be attributed to the possibility that existing methods do not take into account the unique characteristics of time series, such as stationarity and seasonality [22, 23].
To address the aforementioned issues, we propose a single-step semi-supervised contrastive learning framework called nearest neighbor contrastive learning for time series (NNCLR-TS). First, we introduce a novel decomposition-based data augmentation algorithm tailored for time series, employing a sampling-based approach that respects the inherent properties of the data. This method focuses on selectively augmenting the trend component, thus enhancing the model’s ability to learn from the data’s temporal dynamics. Using different views of the data from this augmentation method, the model learns to capture transformation invariance in time series.
Furthermore, following the structure proposed in [13], we employ the notion of a memory buffer, called the support set, in which the representations and their labels/pseudo-labels are stored. By utilizing the support set, we perform pseudo-labeling on unlabeled data, where the assigned pseudo-label is determined by majority votes of its nearby samples in the latent space.
Lastly, we introduce two innovative loss functions, namely Instance-wise Cross Entropy (IW-Xent) and Intra-batch Similarity (IBS) losses, designed to enhance contrastive learning in our proposed model. The former takes full advantage of label information by selecting the nearest neighbor (NN) representations for both positive and negative views, effectively utilizing them in the design of the loss function. The latter contributes by exploiting the similarities among representations within a batch. Together, these new loss functions enable our framework to employ both labeled and unlabeled data efficiently, enhancing the model’s ability to generalize and improving the quality of the learned representations. We combine our proposed loss functions with the well-established normalized temperature-scaled cross entropy (NT-Xent) loss [14] to form a composite loss function. Empirically, we show that this strategy results in a significant performance improvement, demonstrating the effectiveness of our novel loss functions.
In this work, our contributions are summarized as follows:
A novel semi-supervised contrastive learning framework, called NNCLR-TS, is proposed for time series classification tasks in label-deficient scenarios. Also, we develop a new data augmentation algorithm based on decomposition that respects time series properties. By employing a memory buffer referred to as a support set, we store the representations and their corresponding labels/pseudo-labels. We utilize the support set for pseudo-labeling and selecting NN representations of input data, which will be used for computing the loss function. We propose a new composite contrastive loss function that makes use of the NN representations, called IW-Xent loss, and a new intra-batch similarity loss, named IBS loss. This composite function, alongside NT-Xent loss, facilitates the effective use of both labeled and unlabeled data. Our approach outperforms previous methods across a wide range of benchmarks for classification tasks. Furthermore, comprehensive ablations on each component clearly confirm the effectiveness of our method.
Semi-supervised learning
Semi-supervised learning is a learning paradigm that leverages both labeled and unlabeled data for training. This approach aims to better understand the underlying structure of the data [24]. The labeled data offers foundational understanding based on explicit annotations, while unlabeled data helps to capture the broader underlying structure of the data. Combining these two types of data can not only enhance model performance but also mitigate the risk of overfitting [25, 26].
A frequently used approach in semi-supervised learning is consistency regularization [27, 28]. This method encourages consistent predictions across different perturbations of a given input for improved model generalization. Perturbation methods range from simple techniques like random max-pooling and dropout [29] to more complex strategies such as temporal ensembling [30] and virtual adversarial training [31]. Recently, Mixup augmentation [32] has been utilized in various studies to further extend the capabilities of this technique [33, 76, 77]. While consistency regularization is a flexible approach, its performance can be sensitive to the choice of domain-specific augmentations [34].
On the other hand, there have been research efforts focused on joint training of labeled and unlabeled data using pseudo-labeling. This approach involves initially training a model on labeled data and then using it to predict labels for unlabeled data. These predicted labels, known as pseudo-labels, are treated as if they were true labels in subsequent training iterations to leverage information from the unlabeled data [35]. Pseudo-labels serve as a regularizer during training, leading to improved performance on downstream tasks [36]. Some studies [37, 38] have adopted hard pseudo-labeling based on the class with the highest predicted probability.
While such approaches are straightforward and task-agnostic, they are susceptible to what is known as confirmation bias [36, 39]. This issue arises particularly in the early stages of training when the model reinforces potentially incorrect initial predictions through hard pseudo-labeling. Another notable issue is that these methods often prioritize the class with the highest predicted probability, neglecting other factors such as prediction uncertainty or confidence level. This could lead to less robust pseudo-labels, affecting the model’s overall performance if not managed carefully [40].
To alleviate these issues, several studies have explored alternative pseudo-labeling and training schemes based on information from nearby representations or clustering constraints [41, 42, 17]. These adaptations can lead to improvements in the reliability and accuracy of pseudo-labeling. Although these methods have demonstrated success in computer vision, to the best of our knowledge, there has been no similar exploration in time series analysis.
Contrastive learning
The goal of contrastive learning is to enable models to extract meaningful features and generate more discriminative representations. This is achieved by maximizing the similarity between representations for pairs of augmentations from the same data and minimizing the similarity between views from others [14]. It has demonstrated significant success in representation learning across diverse domains, including computer vision, natural language processing, and speech recognition [43, 44, 45].
However, its effectiveness is not as straightforward when applied to time series analysis. One of the significant challenges is the method’s limited capability to capture the temporal dependencies inherent in time series data [46]. Additionally, the non-stationarity nature of the time series data, where statistical properties shift over time, further complicates its adaptability [47].
In response to these challenges, specialized methodologies like [19] and [22] have been introduced. For example, [19] proposed a novel temporal contrasting module to foster robust representation learning. Additionally, [22] introduced a method that computes the contrastive loss in a hierarchical manner, incorporating temporal information through leveraging progressive max-pooling of representations. These approaches are designed to capture the distinctive temporal dynamics of time series data, demonstrating superior performance over conventional contrastive learning techniques in time series.
Although contrastive learning has been employed in time series analysis, techniques such as memory banks, have not been extensively explored for time series data [48, 49, 50]. Memory banks have demonstrated improved performance in computer vision tasks, as seen in works such as [13]. This research proposed a variant of contrastive learning that utilizes a modified memory-bank architecture, referred to as the support set, in combination with an NN approach for sample pair selection. This innovative method not only diversifies the sample pairs but also significantly enhances the learning process, achieving competitive results on ImageNet classification tasks.
Despite its success in computer vision, this method has not been extensively applied to contrastive learning for time series data. This suggests a promising opportunity to enhance performance in time series classification through the integration of memory bank techniques. Our research aims to investigate the potential benefits of applying memory banks to time series.
Data augmentation for time series
Data augmentation plays a pivotal role in contrastive learning, contributing to the model’s robustness by encouraging the learning of transformation invariance from input data [51]. Conventional random transformations widely adopted in image processing, such as flipping and jittering, have also been explored in the context of time series [20]. Additionally, transformation strategies tailored to the unique characteristics of time series data, including window warping and window slicing, have been proposed [52, 86].
Despite the introduction of various augmentation methods, there has not been a one-size-fits-all solution, especially given the unique and diverse nature of time series data [2, 53]. This inconsistency is presumably due to the diversity in the temporal characteristics of datasets, where recurring features like seasonality can be compromised during the augmentation process.
Thus, recognizing the need for preserving such crucial temporal structures, the development of novel augmentation strategies specifically for time series data has become imperative [20]. In response to this need, methods based on Dynamic Time Warping (DTW) have emerged as promising solutions, aimed at maintaining the integrity of temporal structures within the datasets [54, 55, 56].
However, these methods have significant computational complexity due to the need to align two time series [57, 58], making them impractical for online training scenarios or handling large datasets. Given these challenges, there is a need for exploration and development of augmentation methods that are computationally efficient and suitable for time series, to fully leverage the potential of contrastive learning in this domain.
Method
A set of univariate time series of

An overview of NNCLR-TS architecture.
The representation
We illustrate the overall architecture of our proposed model, NNCLR-TS, in Figure 1, with each step from A to E corresponding to subsections of Section 3. In step A, we generate two views using our proposed augmentation method, named STLDDA. Step B describes the process of inputting these views into the encoder, composed of two identical networks. Each network is designed to capture either the temporal or spectral characteristics of the input data. In step C, the output representations are stored in a memory buffer known as the support set. Concurrently, pseudo-labels are generated using our proposed technique and are stored alongside the data. Step D outlines how the NN samples from the augmented data are identified. Finally, in step E, we explain how these samples are used in computing the loss function. The whole procedure of NNCLR-TS training is described in Algorithm 1. The corresponding subsections further detail each component for a comprehensive understanding.

We propose a new augmentation method, termed “STL Decomposition-based Data Augmentation” (STLDDA). Seasonal and trend decomposition using LOESS (STL) [59] is a widely used classical decomposition method for time series, which decomposes the data

The overall process of STLDDA. The original data is decomposed into trend, seasonal, and residual components using STL. To respect the properties of time series data, augmentation is performed while preserving the periodical information, i.e., keeping the seasonal component unchanged. Specifically, we augment only the trend component where the augmented signal is sampled from the empirical cumulative distribution, which is obtained from Eq. (1), in the frequency domain.
STLDDA process is depicted in Figure 2. We begin by applying the real fast Fourier transform (RFFT) to the trend component 
where 
Note that the amplitude 
Here, IFFT denotes the inverse fast Fourier transform, and

Contrastive learning necessitates the generation of two different augmented time series data for the computation of its loss function [14]. Following this standard, our proposed loss function also requires the creation of two unique augmented sets. To fulfill this requirement, we execute the STLDDA process twice on the original data, thus producing two distinct augmented time series data.
In conclusion, our augmentation method offers several distinct advantages. By sampling in the frequency domain, the method preserves essential spectral information. Furthermore, this is not dependent on label information, which broadens its applicability across a wide range of contexts. Additionally, our method constructs empirical distributions based on the entire dataset, thus ensuring the augmented data follows the probability distribution of the trend component. Consequently, this strategy mitigates the creation of outlier instances, further enhancing its utility.
In order to extract richer information from a given input data,
These two networks operate independently, sharing no learned parameters, yet follow the same architecture derived from Ts2Vec’s encoder [22]. This architecture is composed of a dilated convolutional neural network (CNN) module followed by a linear input projection layer. Each network is specialized to process its respective component – either temporal or spectral – of the input data.
The roles of these networks are to extract embedding representations from the original data,
Support set & pseudo-labeling
The goal of training the proposed encoder is to cluster data from the same class closely in the latent space. To achieve this, we propose a novel pseudo-labeling method that assigns labels to unlabeled data based on majority voting of nearby samples within that space. This enables effective training with a limited amount of labeled data, guided by loss functions that will be detailed later.
In the pursuit of reliable pseudo-labeling, it’s important to have a sufficient number of representations. To achieve this, inspired by [13], we employ a queue-type memory buffer known as a support set, denoted by
To facilitate this process at the beginning, we obtain representations for labeled data and pretrain the encoder. In this stage, the representations of all labeled instances are stored in the support set. Subsequently, the training process begins using the complete dataset, which includes both labeled and unlabeled data. If an incoming sample is labeled data, the true label is simply stored with the newly obtained representation. However, if the given sample 
where

An illustrative figure of our pseudo-labeling process. If the data is identified as unlabeled or pseudo-labeled, a pseudo-label is newly assigned based on the majority vote of
Remarks. Here, we would like to provide additional details on how a newly computed representation is stored along with its label or pseudo-label, as well as the size of support set
Given an input data
To achieve this, the NN operation is performed on 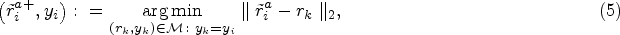

The normalized temperature-scaled cross-entropy (NT-Xent) loss, which is a widely utilized loss function in contrastive representation learning, is adopted in this study [14]. The NT-Xent loss is defined as follows:
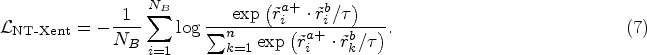
Here,
First, the instance-wise cross entropy (IW-Xent) loss encourages the proximity between the input representation and its NN-positive in the latent space, while simultaneously pushing the input representation away from its NN-negative. The IW-Xent loss is defined as:

Notably, the IW-Xent loss is effective in promoting similarity between positive pairs and dissimilarity between negative pairs in the support set.
The last one is the intra-batch similarity (IBS) loss, which is derived from the disparity in similarities between instances within each mini-batch. The objective of this loss is to increase the similarity of each instance to the least similar representation of the same (pseudo) label, while simultaneously reducing the similarity to the most similar instance with a different (pseudo) label.
This strategy establishes a local structure within the latent space, ensuring that instances of the same class are densely clustered while maintaining distinct separation from instances of different classes. The IBS loss is as follows:
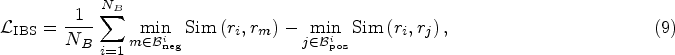
where
Finally, the total triplet loss can be defined as follows:

By combining these three losses, the model aims to learn a more discriminative and structured latent space, which is expected to improve the performance in classification tasks. The algorithmic description of our overall learning procedure is given in the Algorithm 1.
Datasets
To assess the performance of our proposed model, we conduct experiments on several publicly available datasets. Detailed characteristics of each dataset, including the number of instances, time series length, and number of classes, are provided in Table 1.
Epilepsy seizure prediction
The Epileptic Seizure Recognition (Epilepsy) dataset [62] consists of electroencephalogram (EEG) recordings from 500 patients. Each recording has a duration of 23.6 seconds and contains 4,097 data points. The dataset is divided into 23 segments that are randomly shuffled, resulting in a reduced data length of 178 points per segment. Originally, the dataset was categorized into five classes. However, since only one class corresponds to epileptic seizures, the remaining four classes are merged into a single class, transforming the task into a binary classification problem.
UCR classification archive
The UCR Time Series Classification Archive (UCR archive) [63] is a comprehensive repository of benchmark datasets for univariate time series classification. The UCR archive encompasses a diverse range of datasets from various application areas, such as images, medical data, and other engineering-related fields. For performance evaluation, 13 datasets are selected from the archive that satisfies the condition of having at least two training data points for all classes when only 1% of the training data is labeled. The selected datasets are as follows: Crop, DistalPhalanxOutlineCorrect (DPOC), ElectricDevices, FordA, FordB, HandOutlines, MiddlePhalanxOutlineCorrect (MPOC), PhalangesOutlinesCorrect (POC), ProximalPhalanxOutlineCorrect (PPOC), StarLightCurves, Strawberry, TwoPatterns, and Wafer.
A brief description of selected datasets for evaluation. Since the Epilepsy dataset does not have predefined train and test sets, we split the data in an 8:2 ratio. Although the Epilepsy dataset originally contains five classes, we merge four classes into a single class as only one class represents seizures.

A brief description of selected datasets for evaluation. Since the Epilepsy dataset does not have predefined train and test sets, we split the data in an 8:2 ratio. Although the Epilepsy dataset originally contains five classes, we merge four classes into a single class as only one class represents seizures.
For the Epilepsy dataset, we divide the data into 60% for training, 20% for validation, and 20% for testing. As for the 13 datasets selected from the UCR archive, the test sets are already separated, but no validation sets are provided. Therefore, we partition the training data into 75% for training and 25% for validation. To ensure the consistency of the experiments, we conduct the experiments five times using different seeds and record the average and standard deviation of the test accuracy accordingly.
The experimental settings of the proposed model follow Ts2Vec [22]. The batch size is set to 8, and we adopt the SWA optimizer [64] with a learning rate of 1e-3. The number of optimization iterations is set to 200 for datasets with a size less than 100,000 and 600 otherwise. The representation dimension is set to 80, and the dropout is set to 0.1. As for the losses,
Baseline models
In our experiments, we include several baseline models for comparative evaluation. We compare the performance of our proposed method with the following baseline models:
Supervised [19]: Supervised learning where the encoder and the projection layer are adopted from CA-TCC [15]. Ts2Vec [22]: A self-supervised contrastive learning framework that learns contextual representation for arbitrary sub-series at various semantic levels. MixupCLR [65]: A self-supervised contrastive learning framework that predicts the amount of mixing between data points using Mixup [66] augmentation. SemiTime [67]: A semi-supervised learning framework that jointly trains the supervised classification of labeled data along with the self-supervised temporal relation prediction of segment pairs CA-TCC [15]: A semi-supervised model that learns representation from the data points with a cross-view prediction task and supervised contextual contrast.
By comparing our proposed method with these models, we provide a comprehensive evaluation of the effectiveness of our approach in the context of semi-supervised learning for time series classification. In the case of self-supervised baselines like Ts2Vec and MixupCLR, we adopt the training procedure from CA-TCC, which involves self-supervised training of the encoder. Afterward, the encoder is frozen and used in conjunction with a linear layer for supervised training.
The supervised model serves as a baseline, representing the lower boundary of performance when trained solely on labeled data. In order to explore whether extending self-supervised models to semi-supervised approaches could provide a more efficient alternative to traditional semi-supervised methodologies, we selected models based on self-supervised approaches, such as Ts2Vec and MixupCLR.
While certain baseline models, such as CA-TCC, reported experimental results on subsets of our selected dataset, they merged the provided train and test files into new splits. In alignment with the UCR Archive’s recommendation to exclusively utilize the predefined test data for testing, we conducted our experiments and re-evaluated other baselines in accordance with this guideline.
Performance comparison with baseline models
To measure the performance of our experimental models, we utilized the average accuracy on test data as our evaluation metric. The results for the selected datasets, with labeled data ratios set at 1% and 5%, are presented in Table 2. Across all 14 datasets, our proposed model, NNCLR-TS, achieved the highest average test accuracy of 71.0% and 78.2% when the proportion of labeled data is 1% and 5%, respectively. These results demonstrate that the proposed method outperformed the second-best model by a margin of 3.8 percentage points (pp) and 3.1 pp, respectively.
When 1% of labeled data is used for training, NNCLR-TS yielded the highest performance in 7 out of 14 datasets and the second-highest in one, demonstrating its superior capability to learn representations more efficiently than other models. Furthermore, in comparison with Ts2Vec, which employs the same backbone network as NNCLR-TS, NNCLR-TS exhibits an average performance enhancement of 5.1 pp. This suggests that the newly proposed elements, including STLDDA, the support set, and the proposed losses, contribute to further performance improvements. With 5% of labeled data, NNCLR-TS achieved the highest performance in 6 datasets and ranked second on another 6 datasets. This reinforces that our proposed model consistently demonstrates robust performance across a variety of datasets.
Analyzing the effect of the ratio of labeled data
We evaluated the performance of NNCLR-TS compared to other baseline models with varying labeled data ratios: 1%, 5%, 10%, 50%, and 80%. Figure 4 presents the test accuracy of SemiTime, CA-TCC, and NNCLR-TS on Crop, TwoPatterns, and Wafer.
Comparative performance of self-supervised and semi-supervised baselines with 1% and 5% labeled training data; Best results per row are in bold and the second-bests are underlined.

Comparative performance of self-supervised and semi-supervised baselines with 1% and 5% labeled training data; Best results per row are in
It is observed that the test accuracy of all models displayed a trend of improved test accuracy with increasing proportions of labeled data. Nevertheless, NNCLR-TS outperformed both SemiTime and CA-TCC across most scenarios. Notably, on Crop dataset, while CA-TCC and NNCLR-TS exhibited similar performance at lower labeled data ratios, the performance gap widened as the labeled data proption increased. At the 80% level, NNCLR-TS achieved a test accuracy of 72.2%, outperforming CA-TCC’s 67.7%.
For TwoPatterns, NNCLR-TS attained 100.0% test accuracy when only 5% of training data was labeled, showing performance close to its maximum potential, while other models required 50% or 80% of labeled data to reach comparable results. The necessity for a relatively smaller amount of labeled data to obtain the potential peak performance of the model was also evident in Wafer. With only 10% of the data labeled, NNCLR-TS achieved a test accuracy of 98.2%, which approached the maximum accuracy of 99.3% when 80% of the data was labeled. In contrast, the other baseline models required a larger proportion of labeled data to achieve similar performance.
From these observations, we can infer that NNCLR-TS excels in environments with limited labeled data, demonstrating test accuracies close to its maximum performance. This suggests NNCLR-TS’s adaptability to variations in data availability, making it a practical choice for applications where labeled data may be scarce. Additionally, when sufficient labeled data is provided, NNCLR-TS is capable of further widening the performance gap with other semi-supervised baselines. This highlights the capacity of NNCLR-TS to leverage the availability of labeled data to enhance its performance relative to other models.

Performance comparison of CA-TCC, SemiTime, and NNCLR-TS with varying ratios of labeled data acress three datasets: (a) Crop, (b) TwoPatterns, and (c) Wafer. In all scenarios, NNCLR-TS consistently ourperforms other baselines, achieving the highest accuracy among the three models across all label ratio intervals.
In semi-supervised learning, the labeling of unlabeled data points can potentially introduce biases that may not be appropriate for the domain, leading to suboptimal performance. To investigate the effectiveness of our proposed pseudo-labeling approach in various scenarios, we introduce a metric that quantifies the degree of bias in the labeled data. By comparing the performance of NNCLR-TS with Ts2Vec (which shares the same backbone architecture but forgoes pseudo-labeling) across different levels of this bias metric, we can experimentally evaluate the robustness and benefits of our pseudo-labeling technique. Additionally, we compare the performance of NNCLR-TS with other semi-supervised learning models to assess the effectiveness of our proposed model in handling biased labeled data and its potential advantages over other approaches.
The introduced metric, termed “label biasness”, is defined as follows:

where 
where
We conducted experiments in scenario where the ratio of the labeled data is 5%. Biasness is introduced into the labeled data by varying the label biasness from 0.1 to 0.9 in increments of 0.2, i.e., 0.1, 0.3, 0.5, 0.7, and 0.9. For each level of label biasness, five random experiments were performed to ensure the robustness of our results. In each experiment, the sampled labeled data remained consistent across all models to ensure a fair comparison. We compared the performance of NNCLR-TS with other baseline models under these varying levels of label biasness. Furthermore, we included the results of the proposed model, NNCLR-TS, with labeled data sampled randomly without any intentional biasness. These results were obtained from the main experiments presented in the previous section, specifically from Table 2.
Performance comparison of NNCLR-TS and other baselines on the HandOutlines and Strawberry datasets with varying label biasness. The best results per row are in

Table 3 presents the average test accuracy (%) of NNCLR-TS compared to other baselines under varying label biasness levels in the HandOutlines and Strawberry datasets. HandOutlines has an average label biasness of 0.36 when randomly sampled, while Strawberry has an average label biasness of 0.34. For the HandOutlines dataset, NNCLR-TS consistently outperformed other models across all label biasness levels. Notably, it exhibits a smaller performance degradation compared to other methods when the bias is severe (0.7 or 0.9). For instance, at a label biasness of 0.9, NNCLR-TS achieves an accuracy of 76.38%, which is 31.73%p higher than the second-best model, CA-TCC, at 44.65%. Furthermore, even in the presence of biasness, NNCLR-TS maintained performance not significantly different to its performance under random sampling. The largest difference observed is at a label biasness of 0.9, with a difference of 9.22%p compared to random sampling. At moderate levels of label biasness (0.3 and 0.5), the difference is even smaller, with delta values of
Similar trends can be observed in the Strawberry dataset. NNCLR-TS outperformed other baselines across all levels of label biasness, with the performance gap widening at higher bias. For example, at a label biasness of 0.9, NNCLR-TS achieved an accuracy of 55.24%, which is 10.01%p higher than the second-best model.
It is worth noting that Ts2Vec, which shares the same backbone architecture as NNCLR-TS but does not employ pseudo-labeling, experiences a widening performance gap with the proposed model as the label biasness increases. This suggests that Ts2Vec’s architecture might be more vulnerable to the effects of label bias compared to NNCLR-TS. Although pseudo-labeling may introduce biases that can negatively impact the model’s performance, the results demonstrate that this technique used in NNCLR-TS effectively addresses this concern in the HandOutlines and Strawberry dataset. This leads to improved performance even in the presence of severe label biasness.
Interestingly, both the HandOutlines and Strawberry datasets share common characteristics. They are both binary classification tasks with relatively long data lengths (2,709 and 235, respectively) compared to other datasets. These characteristics may enable the presence of periodic features, including trends and seasonality within the data, which can be effectively captured by the proposed data augmentation method, STLDDA. This could explain why NNCLR-TS performs particularly well on these datasets, even under high levels of label biasness.
To investigate the generalizability of NNCLR-TS’s performance beyond binary classification, we conducted additional experiments on two multi-class datasets: Crop and TwoPatterns. These datasets were chosen because they represent common challenges in multi-class semi-supervised learning. Table 4 presents the changes in average test accuracy (%) of NNCLR-TS compared to other baselines under varying levels of label biasness in these datasets.
Performance comparison of NNCLR-TS and other baselines on the Crop and TwoPatterns datasets with varying label biasness. The best results per row are in

For the Crop dataset, NNCLR-TS’s performance was relatively lower than the self-supervised model, Ts2Vec. At a label biasness of 0.3, Ts2Vec outperformed NNCLR-TS by 0.31%p, and this gap widened to 5.38%p and 3.26%p at label biasness levels of 0.7 and 0.9, respectively. This suggests that in this particular case, pseudo-labeling might have a detrimental effect on the model’s performance.
Our analysis revealed several factors that could contribute to this observation. First, the Crop dataset contains a significantly higher number of classes (24) compared to other datasets in our experiments. Pseudo-labeling techniques might be less effective with a larger number of classes due to the increased difficulty in accurately assigning pseudo-labels. Second, the Crop dataset also has the shortest data length (46) among all datasets, which may limit the effectiveness of trend and seasonal decomposition through STL. Consequently, this could lead to a decline in the performance of STLDDA and NNCLR-TS.
However, it is important to note that having multiple classes does not always hinder the performance of NNCLR-TS. In the case of the TwoPatterns dataset, NNCLR-TS demonstrated superior performance compared to other models across all levels of label biasness. Even at a label biasness of 0.9, NNCLR-TS exhibited minimal performance degradation (e.g., a decrease of less than 3%p in accuracy) and significantly outperformed the second-best model, Ts2Vec, by 45.05%p. This could be attributed to the fact that TwoPatterns is a simulated dataset, making it easier to capture periodic features. Additionally, the data length of TwoPatterns is 128, which is longer than that of Crop, allowing STLDDA to have a more positive impact on the model’s performance.
In conclusion, while pseudo-labeling may have a negative effect on the model’s performance in some cases, such as datasets with a high number of classes and short data lengths like Crop, the proposed model still exhibits a relatively smaller decline in performance compared to other semi-supervised methods. Furthermore, for datasets with distinct regularities and sufficient data length, like TwoPatterns, the proposed model demonstrates good performance even in the presence of high label biasness.
In this section, we present a comprehensive model analysis to assess the robustness of our proposed model and identify the key factors contributing to its performance improvement.

Heatmap representation of test accuracies on (a) DPOC, (b) PPOC, and (c) Strawberry with varying
Figure 5 demonstrates the effects of varying coefficients,
For example, in PPOC, when both
However, when the values of
Maximum support set capacity
Although the support set plays a vital role in NNCLR-TS, increasing the maximum support set capacity could potentially introduce scalability problems. This is because retrieving nearest neighbors within the support set has a computational complexity of
For the FordA, increasing the support set capacity appears to improve the performance in general. The median test accuracy rises gradually from 90.9% with a 50% capacity, to 91.5% at 80% capacity, and finally reaching 91.7% when the capacity is unrestricted. It is noteworthy that even with a reduced support set size, the model continues to perform admirably, with only a marginal decrease in performance.

Variations in performance according to the maximum capacity of the support set when only 5% of the dataset is labeled, for (a) FordA, and (b) DPOC.
On the other hand, for the DPOC, there is a more pronounced variation in performance as the support set size capacity changes. When the support set is limited to 50% of the training data, the median accuracy is 58.9%. This improves dramatically to 61.4%, when the capacity is increased to 80%. Notably, enabling the support set to utilize the entire training data yields a significant performance boost, with a median accuracy of 63.8%.
These results emphasize that while larger support set capacities can lead to improvements, the decline in performance with reduced capacities is minimal. This indicates that NNCLR-TS remains effective even when computational resources or memory are constrained, highlighting its potential for a broad spectrum of applications.
To validate the effectiveness of the proposed augmentation technique, STLDDA, for contrastive learning in time series, we conducted experiments to investigate the influence of different augmentation choices on model performance in NNCLR-TS. In addition to no augmentation, we selected commonly used techniques such as jittering, scaling, and rotation, along with permutation and window warp, which have been studied to be generally effective for time series classification according to [68] for comparison.
Table 5 presents the average test accuracy results for each augmentation method used in NNCLR-TS across 13 UCR Archive datasets. Even without explicit augmentation, our model achieved a relatively high test accuracy of 76.4%, ranking third among all methods. This may be attributed to the fact that the selection of nearest neighbors itself appears to function as a type of data augmentation, contributing to the enhanced performance.
The performance exhibited further improvement with the implementation of our proposed STLDDA method, which recorded the highest test accuracy of 76.8%. Additionally, a pairwise t-test at a significance level of 0.10 supports our claim regarding the STLDDA method’s effectiveness. This enhancement demonstrates the effectiveness of STLDDA, which leverages the concept of nearest neighbors to generate more diverse and representative augmentations. Given the inherent variability within the datasets, STLDDA consistently demonstrated superior performance, highlighting its robustness and versatility in processing a wide range of time series data.
Performance of NNCLR-TS on 13 UCR Archive datasets using various augmentation methods, with only 5% of the data labeled.

Performance of NNCLR-TS on 13 UCR Archive datasets using various augmentation methods, with only 5% of the data labeled.
Note: **p < 0.05, *p < 0.10. Significance levels indicate the result of pairwise comparisons with STLDDA.
The encoder network in our proposed model is a combination of temporal and spectral networks that are designed to learn from input data through multiple perspectives. To investigate the potential advantages of including the spectral component, we conducted a performance evaluation using solely the temporal network. Table 6 presents the average accuracy across 13 UCR Archive datasets when 1% and 5% of the training data are labeled.
The results demonstrate that regardless of the proportion of labeled data, the model incorporating the spectral network consistently achieved higher test accuracy. Performance improvements of 0.7% and 1.5% were observed at the 5% and 1% levels, respectively. These findings suggest that integrating spectral network into the encoder can enhance the overall performance of the proposed model.
Pseudo-labeling is conducted based on the labels (or pseudo-labels) of the K-nearest neighbor representations closest to the selected representation in the support set. Therefore, it is necessary to investigate how changes in model performance are influenced by the value of
The highest average test accuracy, 76.8%, was recorded when
One possible explanation for the performance drop observed at
Our experimental results suggest that the optimal performance for our model is achieved when
Average test accuracy (%) on 13 UCR Archive datasets with respect to the choice of encoder network.

Average test accuracy (%) on 13 UCR Archive datasets with respect to the choice of encoder network.
Performance comparison of NNCLR-TS across 13 UCR Archive datasets, using different numbers of


t-SNE visualizations on the representations of the test data from SemiTime, CA-TCC, and NNCLR-TS applied for HandOutlines and TwoPatterns. All models were trained with 1% of the training data labeled.
For qualitative evaluation of the learned representations, the test data was processed through the trained encoder to extract features. These features were then visualized in a 2D space using t-SNE [69]. Figure 7 presents visualized results of the learned representations from SemiTime, CA-TCC, and NNCLR-TS for HandOutlines and TwoPatterns, with only 1% of the training data being labeled.
For HandOutlines, our proposed model displays a clearer separation between the two classes (0 and 1) compared to other baselines, indicating more effective feature extraction. Although SemiTime and CA-TCC do show a certain level of separation, there remain overlapping regions which could contribute to misclassifications. Moreover, the clusters formed by NNCLR-TS are notably more compact, suggesting a more consistent representation.
TwoPatterns introduces a scenario with four classes. Notably, NNCLR-TS clearly separates each class into its own cluster without any overlap. In contrast, both SemiTime and CA-TCC exhibit overlapping regions, especially among classes 0, 1, and 2. It’s worth noting that NNCLR-TS consistently outperforms across both datasets, suggesting the model’s potential to generalize across different complexities.
In conclusion, as visualized through t-SNE embeddings, the NNCLR-TS model demonstrates clear advantages in terms of class separation and clustering density over its counterparts in these scenarios. Its strong performance on the presented datasets highlights its potential in time series analysis.
Conclusions
We introduced a novel semi-supervised contrastive learning framework, NNCLR-TS, designed for time series classification. The NNCLR-TS framework utilizes an asynchronously updated support set that includes both data representations and label information. This design is crucial for assigning pseudo-labels to unlabeled data and for identifying the nearest representations in the context of contrastive learning. To further enhance the capabilities of NNCLR-TS, we developed STLDDA that aims to generate a diverse set of time series while preserving seasonal information, emphasizing the importance of retaining seasonal properties during augmentation.
Along with the standard NT-Xent loss, we introduced two additional losses: IW-Xent and IBS. These losses are designed to bring representations of the same class closer together while separating them from others. Our results suggest that NNCLR-TS outperforms other self-supervised and semi-supervised benchmarks in time series classification, particularly in scenarios with limited labeled data, such as the 1% and 5% settings.
In our comprehensive model analysis, we observed that performance remains fairly consistent across different hyperparameters. Although certain parameters, such as support set capacity, have an influence on the outcomes, these variations are not substantial. This consistent performance indicates the model’s robustness, reducing the necessity for extensive hyperparameter tuning.
As we look ahead, our research goals include the application of NNCLR-TS in multivariate contexts and the advancement of classification in diverse multivariate time series datasets. We also plan to explore cases where not every class is represented in the labeled datasets, delving into the challenges of zero-shot learning.
Footnotes
Acknowledgments
This work was supported by the National Research Foundation of Korea (NRF) grants funded by the Korea government (MSIT) (No. NRF-2022R1F1A1066744 and NRF-2020R1G1A1007453).