
Abstract
The exponential growth of academic papers necessitates sophisticated classification systems to effectively manage and navigate vast information repositories. Despite the proliferation of such systems, traditional approaches often rely on embeddings that do not allow for easy interpretation of classification decisions, creating a gap in transparency and understanding. To address these challenges, we propose an innovative explainable paper classification system that combines Latent Semantic Analysis (LSA) for topic modeling with explainable artificial intelligence (XAI) techniques. Our objective is to identify which topics significantly influence the classification outcomes, incorporating Shapley additive explanations (SHAP) as a key XAI technique. Our system extracts topic assignments and word assignments from paper abstracts using LSA topic modeling. Topic assignments are then employed as embeddings in a multilayer perceptron (MLP) classification model, with the word assignments further utilized alongside SHAP for interpreting the classification results at the corpus, document, and word levels, enhancing interpretability and providing a clear rationale for each classification decision. We applied our model to a dataset from the Web of Science, specifically focusing on the field of nanomaterials. Our model demonstrates superior classification performance compared to several baseline models. Ultimately, our proposed model offers a significant advancement in both the performance and explainability of the system, validated by case studies that illustrate its effectiveness in real-world applications.
Keywords
Introduction
In the swiftly evolving landscape of academic research, the proliferation of academic papers has been driven by technological advancements, global collaboration, and the increasing recognition of publications as a metric of academic and professional success. This expansion is further accelerated by funding prerequisites, specialized fields of study, and the burgeoning realm of interdisciplinary research. These dynamics collectively forge an environment where the volume of academic papers is not just growing, but doing so exponentially.
Given the escalating number of publications, there is a pressing need for an efficient classification system to manage and organize this vast trove of information. A robust classification system is crucial for facilitating the standardization of categories, ensuring consistent access across various databases and institutions, and supporting effective communication within the academic community. Additionally, such a system plays a vital role in enhancing information management strategies in academic research, bolstering knowledge management practices, and refining paper recommendation systems.
Topic modeling is an essential unsupervised learning technique used to identify latent thematic structures within extensive collections of unstructured documents [1,2,3,4,5]. This method relies on analyzing the distribution and co-occurrence of words across documents, thereby revealing underlying themes and enhancing the interpretability of large datasets by clustering related documents together [6]. Such algorithms not only discern the fundamental topics embedded within texts but also provide human-readable labels, which facilitate further analysis and focused exploration of specific themes within a corpus [7]. Consequently, topic modeling significantly augments the interpretability of document classification by organizing content into coherent themes and deepening the understanding of the underlying textual data, thus proving invaluable for paper classifiers [8].
In the specific application of topic modeling, this study seeks to advance our comprehension of document themes through the incorporation of latent semantic analysis (LSA) [9]. LSA distills documents into a lower-dimensional space, capturing essential semantic relationships and thereby refining the differentiation between topics [10]. This process generates keywords that epitomize each topic, enabling users to quickly identify papers corresponding to specific thematic areas. Employing LSA in classifying papers leverages traditional embedding techniques and is poised to enhance the accuracy and comprehensiveness of topic detection in academic papers. The expected contribution of this approach is to provide a more nuanced understanding of the thematic structures within the academic papers, thereby supporting more effective classification and retrieval practices in scholarly databases.
The complexity inherent in deep learning models, particularly when utilized for classification tasks, presents significant interpretive challenges [11,12]. This complexity often obscures the decision-making process, making it difficult to understand how outcomes are derived. Such opacity can be a major hurdle in settings where transparency and accountability are critical. Explainable artificial intelligence (XAI) technologies offer a promising solution to this dilemma by elucidating the mechanisms behind model predictions, thereby enhancing the interpretability of results [13,14].
We utilize Shapley additive explanations (SHAP) [15] to interpret the classification outcomes of academic papers. SHAP, a widely recognized XAI technique, provides a detailed decomposition of the predictive contribution of each feature, allowing for an in-depth understanding of model behavior [16,17]. This technique is particularly valuable when integrated with topic modeling, as it enables a granular analysis of how specific topics and their associated keywords influence the classification results. By applying SHAP, we not only elucidate the direct contributions of individual topics but also provide a basis for validating the model’s reliability and fairness.
The necessity of integrating SHAP with topic modeling arises from the goal of creating a transparent and accountable classification system. The interpretability facilitated by SHAP ensures that users can comprehensively understand and trust the outcomes of the classification process. This integration is expected to enhance the trustworthiness of the classification system, which is crucial for its adoption in academic and research settings where decision rationales need to be clearly articulated.
Furthermore, the insights gained from this approach are anticipated to drive improvements in the model’s design and implementation [18,19]. By understanding which topics and words are most influential in the classification decisions, researchers and developers can fine-tune the model to better align with academic and research priorities. This level of analysis not only supports more accurate classifications but also aids in the discovery of emerging trends and gaps within academic papers, thereby guiding future research directions.
In this paper, we present a novel explainable paper classification system that integrates topic modeling and SHAP to categorize academic papers effectively. Employing LSA enhances the interpretability of the classification process by enabling a nuanced understanding of the thematic structures within documents. Further, by leveraging SHAP values, we provide a detailed elucidation of how individual topics and critical words influence classification outcomes, thus ensuring a comprehensive interpretative framework. This integration allows for interpretation at three distinct levels: the corpus-level, document-level, and word-level, offering a granular insight into the classification dynamics. Such multi-level analysis is pivotal for understanding the varying influences that specific topics and terms have on the classification results, providing a clear roadmap for adjustments and improvements in the classification process. To validate the robustness and explainability of our system, we apply it to the Web of Science (WoS) dataset in the field of nanomaterials. This application demonstrates the system’s superior capability in classifying academic papers, thereby affirming its utility in real-world academic settings.
The remainder of the paper is structured as follows. We present the system flow of the proposed system and provide a detailed explanation of the system in Section 2. Section 3 provides a summary of the literature pertaining to paper classification systems. Section 4 delves into the experimental procedure, offering detailed information about the datasets, preprocessing methods, and a comparative study to evaluate the performance of the proposed system. In Section 5, we perform real data analysis focusing on the interpretability of the proposed system. Finally, Section 6 concludes this work and describes future work.
Proposed method
Overview
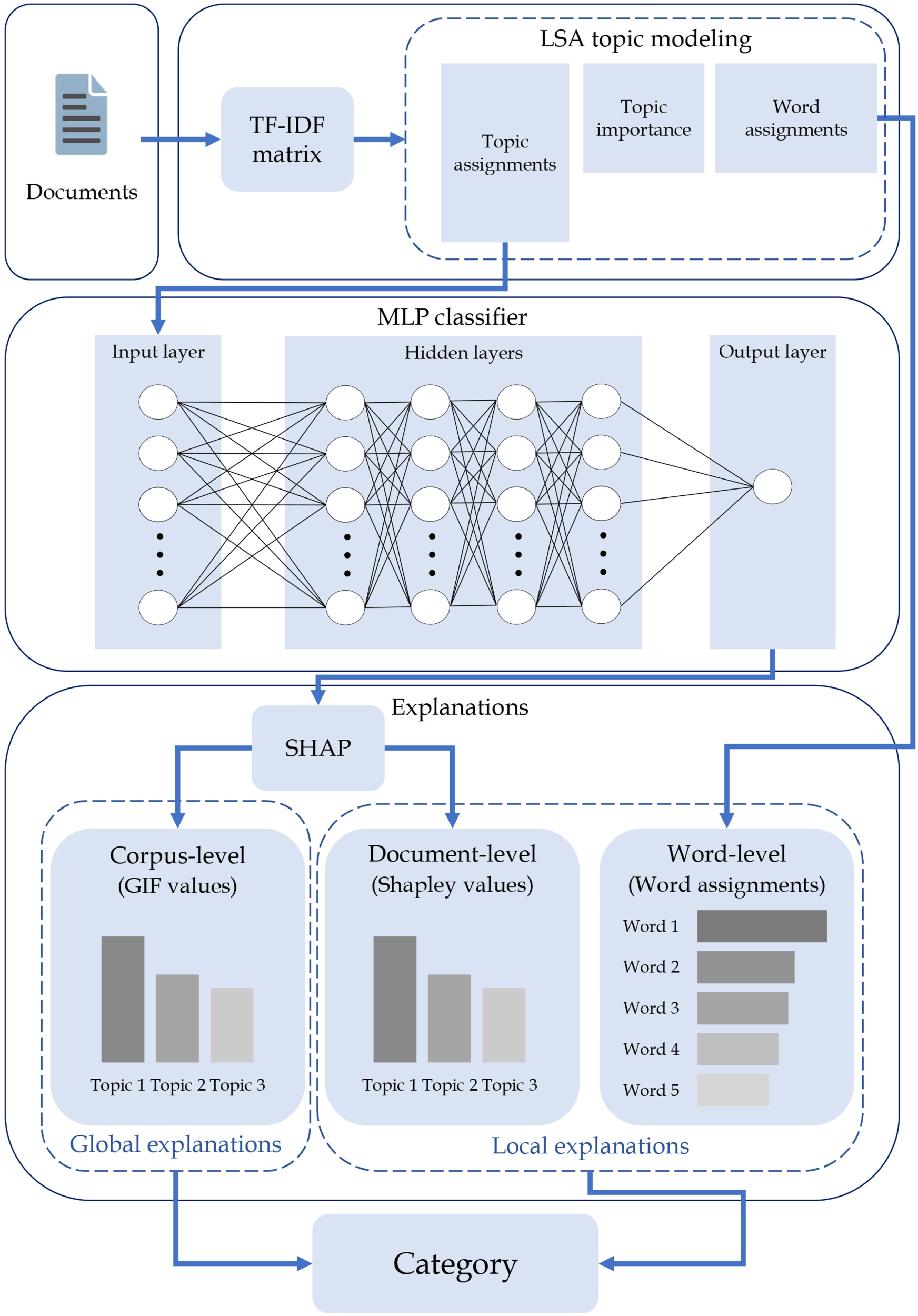
Flow chart of the proposed classification system, illustrating the sequence from document processing to the final classification and explanation stages. The diagram outlines the transformation of documents into a TF-IDF matrix, followed by LSA topic modeling to determine topic assignments. These assignments feed into an MLP classifier, with SHAP providing both global and local explanations of the classification outcomes at the topic and word levels.
Let
Figure 1 illustrates the flow chart of the proposed system in this paper.
Latent semantic analysis (LSA) was initially introduced by Deerwester et al. [9] as a method for analyzing the relationships between a set of documents and the terms they contain. It operates under the foundational principle that words that share similar meanings often occur in comparable contexts [21]. LSA seeks to exploit this premise by utilizing mutual document constraints to deduce underlying topics. This conceptual framework posits that semantic structures can be discerned through patterns of word usage across texts, providing a robust mechanism for the induction and representation of knowledge [22].
Let
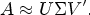
Let K be the number of latent topics. The matrix
In this context, the i-th row of U,
The multilayer perceptron (MLP) is a neural network architecture consisting of multiple perceptron layers organized in a hierarchical structure [26]. This architecture typically includes an input layer, several hidden layers, and an output layer, with each layer containing multiple neurons [27]. Neurons within these layers are interconnected through weights and biases, which are parameters adjusted during the learning process. Non-linearity in the network is introduced via activation functions, enhancing the model’s capability to capture complex patterns in the data [28].
The MLP is particularly adept at learning intricate and abstract representations through its multilayer structure, which allows the model to handle non-linear relationships and recognize diverse features across data sets [29]. We configure our MLP classifier with four hidden layers containing 128, 64, 32, and 16 neurons, respectively. Each hidden layer utilizes the rectified linear unit (ReLU) activation function,
The training of our MLP classifier involves up to 1,000 iterations with a batch size of 32, and the initial learning rate is set at 0.001. To mitigate overfitting and improve convergence, early stopping is implemented, halting training if no improvement in validation performance is observed over 10 consecutive iterations [32]. The operational framework of the classifier for a document’s topic embedding vector
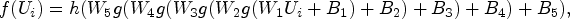
SHAP, suggested by Lundberg et al. [15], offers a robust mechanism for attributing the prediction influence of individual features, accounting for their interaction and contribution across all possible coalitions of features. This method not only supports local explanations but also facilitates global understanding of feature importance, making it exceptionally useful for identifying and analyzing the topics that significantly impact paper classification [34,35].
In implementing SHAP, we prioritize its ability to handle complex and interactive effects among features, which provides a more nuanced and comprehensive interpretation. SHAP’s theoretical foundation in Shapley values ensures fairness and consistency in feature contribution, which is crucial for our analysis of how specific topics influence the classification outcomes across the entire corpus [36]. Consequently, SHAP allows us to present both specific and aggregate insights into how certain topics and words sway the classification process, thereby enhancing the transparency and accountability of our predictive modeling.
The concept of global feature importance is pivotal in understanding the overall influence of each input variable on the predictive outcomes. This measure is particularly essential when explaining complex models to stakeholders who require insights into which features most significantly drive model predictions. Global feature importance can be calculated by averaging the contributions derived from each local explanation, as highlighted by the concept of Shapley values [37]. These contributions are consolidated into a simplified predictive model that approximates the behavior of the original complex model [15]:
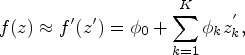
The local importance, or the Shapley value
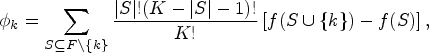
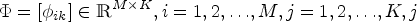
In the classification task, the influence of topics that negatively affect the model is considered less crucial compared to those with a positive influence [36,37,40]. This perspective stems from the observation that a specific class typically correlates with a relatively small subset of topics from the total available K topics. Topics that exhibit large Shapley values are interpreted as exerting substantial influence on model predictions.
To quantitatively assess the impact of each topic, the mean absolute Shapley value is used as a metric for global interpretability [41,42,43]. In this paper, we introduce the Global Influence Factor (GIF)

A high GIF value indicates that the corresponding topic significantly influences the classification process. This metric allows us to systematically identify the most impactful topics at the corpus level, enhancing the explainability of the classification results.
In summary, the proposed system offers a three-fold advantage in enhancing the interpretability of classification outcomes:
(Corpus-level) The system identifies which topics significantly impact classification outcomes through the GIF values calculated as per Eq. (6). (Document-level) The system elucidates the reasons behind the classification of a document into a particular category, based on the Shapley values defined in Eq. (4). (Word-level) The system provides insights into which words contribute to the classification of a document by examining the significant words within influential topics, utilizing the word assignments in the matrix
These enhancements collectively foster a comprehensive understanding of the classification mechanism, from the broad perspective of topic influence down to the specific words that drive document classification.
The classification of academic papers is a critical task for organizing scholarly materials, enabling efficient access to relevant research within various fields. Over time, numerous techniques have emerged to categorize papers based on content, keywords, and structure.
Initial paper classification strategies employed traditional embedding techniques such as Word2Vec [44], Doc2Vec [45], FastText [46], and TF-IDF [47]. These were often paired with classical classification models like support vector machines (SVM) [48] and k-nearest neighbor (KNN) algorithms [49]. While these methods laid the groundwork, they generally lacked in performance and did not provide explanations for their classification decisions, limiting their utility for deeper research analysis.
Further enhancements in topic modeling have incorporated embedding techniques to refine thematic clustering. Nguyen et al. [50] proposed a sophisticated hybrid model that combines the probabilistic likelihoods from LDA with a log-linear model employing pre-trained word embeddings to enhance topic specificity. Similarly, Bunk and Krestel [51] introduced an innovative approach termed WeLDA, which involves randomly substituting words associated with a particular topic with their corresponding embeddings, sampled from a Gaussian distribution, to enrich the semantic texture of the topics. Xu et al. [52] explored a geometric method by utilizing Wasserstein distances to concurrently learn topics and word embeddings, providing a more mathematically grounded approach to topic discovery. Additionally, Keya et al. [53] created the neural embedding allocation (NEA), which parallels the generative process of the embedded topic model (ETM) but optimizes it using a pre-fitted LDA model, thereby enhancing topic accuracy and relevance [54].
The advent of deep learning models, including MLP [55], long short-term memory (LSTM) [56], and convolutional neural network (CNN), significantly enhanced performance [57]. Hybrid models like Bi-LSTM-CNN [58] and C-LSTM [59] combined LSTM and CNN capabilities to better capture complex patterns in text. However, these models continued to struggle with explaining results when using traditional embeddings.
A significant drawback of deep learning models, despite their enhanced performance, is their lack of interpretability. The inability to explain classification results remains a substantial hurdle, as understanding the reasoning behind decisions is crucial for validation and trust in automated systems. The concept of explainable artificial intelligence (XAI) has emerged to address this challenge, with numerous studies utilizing SHapley Additive exPlanations (SHAP) to provide insights into the decisions made by complex models. Vilone and Longo [60] have proposed a system that classifies all scientific studies hierarchically using XAI technique. Kim et al. [61] proposed the Explaining and Visualizing Convolutional Neural Networks for Text Information (EVCT) framework using XAI technique, which effectively minimizes information loss while enhancing the explanations for predictions made by the algorithm. Ayoub et al. [62] used explainable natural language processing models to counter the COVID-19 infodemic, employing SHAP to explain the outputs of the DistilBERT model.
Integrating XAI technologies with embedding-enhanced topic modeling marks a significant advancement in paper classification. Such technologies elucidate the influence of specific topics on classification outcomes, improving decision-making transparency and fostering trust in automated systems. These methodologies not only elevate classification accuracy but also provide vital insights into the rationale behind model decisions [63].
Dataset and experiments
Dataset
We utilize a dataset comprising 456,472 academic paper abstracts related to nanomaterials, sourced from the Web of Science (WoS) and spanning publications from 2012 to 2017. We focus on five specific fields within nanomaterial research: Carbon Nanotube, Quantum Dot, Graphene, Nanosilica, and Nanosilicon. By analyzing abstracts, we aim to capture a broad spectrum of topics covered in each paper, which allows for a more detailed understanding of the research trends and themes within the field of nanomaterials. The true labels of the dataset were generated by nanotechnology experts from the Nanotechnology Policy Center at the Korea Institute of Materials Science in the project “Study of Nanotechnology Policy and Information Analysis” (2017M3A7A7057113) of the National Research Foundation of Korea. It is worth noting that papers may be categorized under multiple nanomaterial fields, indicating the interdisciplinary nature of many studies. Table 1 provides a breakdown of the number of papers associated with each of the five nanomaterial fields.
Distribution of academic papers across five nanomaterial fields from the WoS database.

Distribution of academic papers across five nanomaterial fields from the WoS database.

The experimental process for real data analysis, illustrating each step from data preprocessing to model training.
Figur 2 illustrates the experimental process of real data analysis. Before applying LSA topic modeling, the dataset underwent a series of preprocessing steps. The abstracts were converted to lowercase, and the tokenization of sentences into words was performed using the NLTK (version 3.8.1) library in Python. Lemmatization was applied to normalize different forms of words to their base forms, including converting plural to singular forms and standardizing verb tenses. Additionally, insignificant special characters, particles, articles, single-letter words, and words from the NLTK English stopword list were removed.
Upon preprocessing completion, the dataset was divided into training, validation, and testing sets. Initially, the dataset was split into training and testing sets in a 9:1 ratio. The training set was further subdivided into training and validation subsets with an 8:2 split.
To implement LSA topic modeling on the training and test datasets, we first trained the LSA model using the training data corpus and constructed a vocabulary set limited to words appearing in at least 30 documents. This approach ensures efficient computation and minimal discrepancies across various performance metrics, resulting in a lexicon containing N= 23,055 words. Words not present in the established vocabulary were excluded from both the training and test datasets. Subsequently, the data were transformed into TF-IDF matrices, where the TF-IDF matrix for the test data was generated based on the word importance derived from the training data.
The optimal number of topics, K, was established at 200 after conducting iterative adjustments ranging from 50 to 300 topics during the training phase. This number was selected based on its contribution to maximizing classification accuracy.
To address the class imbalance, undersampling techniques were employed, involving the random removal of indices of papers not pertaining to each specific nanomaterial field [64,65]. This approach was aimed at equalizing the number of papers across nanomaterial fields to improve model performance.
Distribution of academic papers across five nanomaterial fields in the training and test datasets after applying undersampling.

The training dataset used for classification is detailed in Table 2, which presents the distribution of papers across the five nanomaterial fields after undersampling. Due to the varying amounts of training data per field, individual models were trained and evaluated separately for each field. Binary classification models were developed for each field, and the average of the individual evaluation results was calculated to derive comprehensive performance metrics across all five nanomaterial fields [66].
Shapley values for topics within each nanomaterial field were computed based on the test data. By taking the absolute values of these Shapley values for all papers and averaging them, GIF values for each topic were determined. This method allowed for an assessment of the average importance of each topic across all papers within each field.
We conducted a comparative analysis between our proposed system, which utilizes LSA and MLP, and four alternative embedding methods coupled with three different classification models. This comparison was designed to demonstrate the enhanced performance of our system in the task of paper classification. The effectiveness of each combination of embedding techniques and classification models was assessed using several model performance metrics, including accuracy, F1-score, and the area under the receiver operating characteristic curve (AUC).
Embedding methods
We utilized a range of embedding techniques to analyze the effectiveness of different textual representations. The selected methods include Word2vec [67,68], Doc2vec [69], LDA [1], and BERTopic [70] as the embedding techniques.
Word2vec is a prominent word embedding technique that represents words as vectors based on their meanings and contextual usage [67,68]. This model assesses the context of a word by considering up to five words preceding and following it within a sentence, including only those words that appear with a frequency of 40 or more. Notably, the Skip-Gram model was selected over the Continuous Bag of Words (CBOW) model due to its superior performance in predicting the center word from its surrounding context [67,71,72]. This choice enhances the model’s ability to capture contextual meanings. Each word is represented by a 200-dimensional vector. For document embedding, the average of word vectors within the document is used to form a document vector, providing a consolidated representation that encapsulates overall semantic content [73].
Doc2vec, an extension of Word2vec, uniquely assigns vectors to entire documents, effectively representing them as vectors [69]. Like Word2vec, it examines up to five words before and after the target word within a sentence, including only those that meet a minimum frequency threshold. The distributed memory version of the paragraph vector (PV-DM) model was utilized for our Doc2vec implementation [69,74,75]. This model captures the semantic meanings of words within their contexts, enhancing the overall document representation. Each document is thereby represented by a 200-dimensional vector, which ensures a rich, context-aware embedding that encapsulates the thematic essence of the text.
LDA is a topic modeling technique that probabilistically infers the topic structure within documents [1,76]. To train the LDA model, the same dictionary generated via LSA was utilized. The batch size for document processing was set to 2,000, and the model was configured to discern 200 topics. The parameters of the Dirichlet distribution for each topic distribution were set equally, resulting in
BERTopic leverages clustering technology and class-based TF-IDF to model topics effectively, generating discernible topic representations and enhancing the granularity of topic detection [70]. Documents are embedded into a vector space using the Sentence-BERT (SBERT) framework, specifically employing the all-MiniLM-L6-v2 model [77]. This version of SBERT has been trained on a vast corpus of 1,170,060,424 training tuples, including sources like Reddit comments and Wikipedia pages. It is known for its state-of-the-art performance on various sentence embedding tasks, facilitating effective semantic comparisons [78]. To manage the high dimensionality of the data, uniform manifold approximation and projection (UMAP) is applied, reducing dimensions to a three-dimensional space that preserves the semantic similarity of documents [79]. This step involves setting the number of neighboring points to 20 and the minimum distance between points to 0.1, using the Euclidean distance metric for calculations. Following dimensionality reduction, hierarchical density-based spatial clustering of applications with noise (HDBSCAN) is employed to identify dense clusters and segregate noise [80]. Additionally, clustering incorporates Prim’s algorithm, which utilizes k-dimensional (KD) trees to enhance clustering efficiency [81]. The minimum cluster size is set to 200, with a minimum of 30 neighbors required to form a cluster. The Euclidean distance metric and an excess mass method are used to select and validate clusters [82]. Finally, class-based TF-IDF (C-TFIDF) is implemented to refine topic representations. Unlike traditional TF-IDF, C-TFIDF assesses word importance within clusters, facilitating the generation of specific topic-word distributions for each document cluster. To optimize topic coherence, the representation of the least prevalent topic is iteratively merged with the most similar one, reducing the number of topics to 200.
Classification models
As classification models, we utilized logistic regression (LR) [83], randomforest (RF) [84], extreme gradient boosting (XGBoost) [85].
LR is widely used for binary classification, leveraging the logistic function to predict probabilities [83,23]. This method compares the output probability against a fixed threshold, set at 0.5, to categorize observations into binary classes (0 or 1) [86]. In our implementation, the model incorporates an L2 regularization penalty to prevent overfitting. We optimize the model using the limited memory Broyden-Fletcher-Goldfarb-Shanno (LBFGS) algorithm, renowned for its effectiveness in large-scale applications. The optimization process is controlled with a maximum of 1,000 iterations and a convergence tolerance of 0.001.
RF is an ensemble method that enhances predictive accuracy by aggregating outputs from multiple decision trees [84,83]. This method not only increases the robustness of predictions but also helps control overfitting through its ensemble approach. We configured our RF with 200 trees, employing the Gini index as the criterion for optimizing splits [87]. We capped the maximum depth of each tree at 20, allowing for complex pattern recognition while preventing overfitting. Each internal node in the trees requires at least 5 samples to split, ensuring sufficient data for reliable decision-making and maintaining an equilibrium between bias and variance.
XGBoost builds upon traditional gradient boosting frameworks by iteratively correcting the errors of previously built trees [85,88]. We use 200 trees, and each tree can grow to a maximum depth of 20 to capture complex interactions, and the minimum child weight is set at 10 to control overfitting by making the algorithm more conservative. The learning rate is fixed at 0.3 to moderate the impact of each individual tree and prevent rapid convergence to suboptimal solutions. Additionally, the gamma parameter, which specifies the minimum loss reduction required to make further splits on a leaf node, is set at 0.1.
Results
Results of comparative study
Table 3 presents a comparison of classification performance outcomes for nanomaterial academic papers. For performance comparisons on datasets related to Science & Engineering and Medical academic papers, please refer to the Appendix A. The F1 score, a crucial metric that harmonizes precision and recall, is particularly emphasized given its relevance in addressing class distribution imbalances [89]. This metric is instrumental in assessing classification performance on imbalanced datasets and elucidates distinct patterns of model efficacy.
Comparative performance metrics of five embedding methods paired with four classification models. The table displays accuracy, F1 score, and AUC for each method-model combination, highlighting the superior performance of the proposed LSA-MLP configuration.
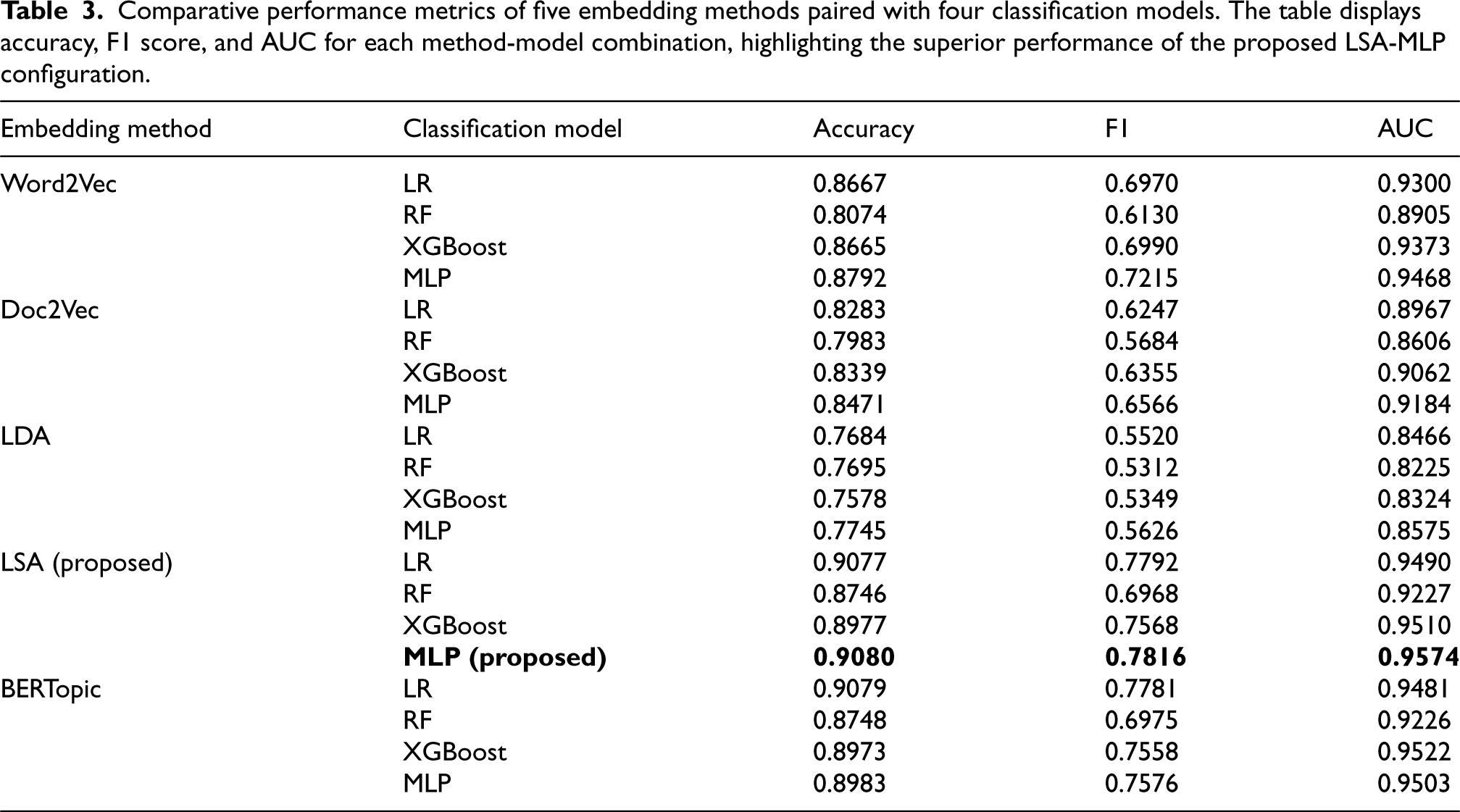
Comparative performance metrics of five embedding methods paired with four classification models. The table displays accuracy, F1 score, and AUC for each method-model combination, highlighting the superior performance of the proposed LSA-MLP configuration.
The results demonstrate that the choice of embedding methods significantly influences the overall performance of the classification models. Among the evaluated combinations, the integration of LSA with the MLP classifier exhibited superior performance, achieving an F1 score of 0.7816. This result suggests an enhanced capability to capture and utilize semantic similarities and complex relationships within the data [90,91].
Interestingly, despite the advanced capabilities of BERTopic, which leverages a pre-trained model on extensive datasets to capture a broad semantic scope, it did not outperform the LSA-MLP configuration. The BERTopic and MLP combination achieved an F1 score of 0.7576, indicating that while it remains highly effective, it does not surpass the LSA-MLP setup in this specific evaluation. This finding is noteworthy, as it suggests that our proposed combination of LSA and MLP not only competes with but also slightly exceeds the performance of sophisticated pre-trained models like BERTopic in navigating the unique challenges presented by our dataset.
Evaluation for SHAP
The fidelity measures the degree to which the explanations approximate the original predictions of the model [92]. A lower fidelity error indicates a higher accuracy in the explanations provided by SHAP values in approximating the model’s predictions [93,94]. The smaller the fidelity value, the better the SHAP explanations align with the model’s output, suggesting that the interpretations are more faithful to the actual decision-making process of the model.
Fidelity scores for SHAP across five nanomaterial fields.

Fidelity scores for SHAP across five nanomaterial fields.
Table 4 presents the fidelity scores across all nanomaterial fields, calculated as the mean squared error between the SHAP values’ sum and the model’s predicted probabilities. The fidelity values for all fields are exceptionally low, indicating that the SHAP explanations are highly consistent with the MLP classifier’s predictions in these fields. The overall average fidelity score, 0.00073, further corroborates the efficacy of SHAP in providing reliable explanations across all fields, thus validating the utility of SHAP in enhancing the transparency and reliability of the classification model.
Summary of the top three topics with the highest GIF values for each nanomaterial field, along with the top five most influential words within each topic, based on their absolute assignments in the
matrix.
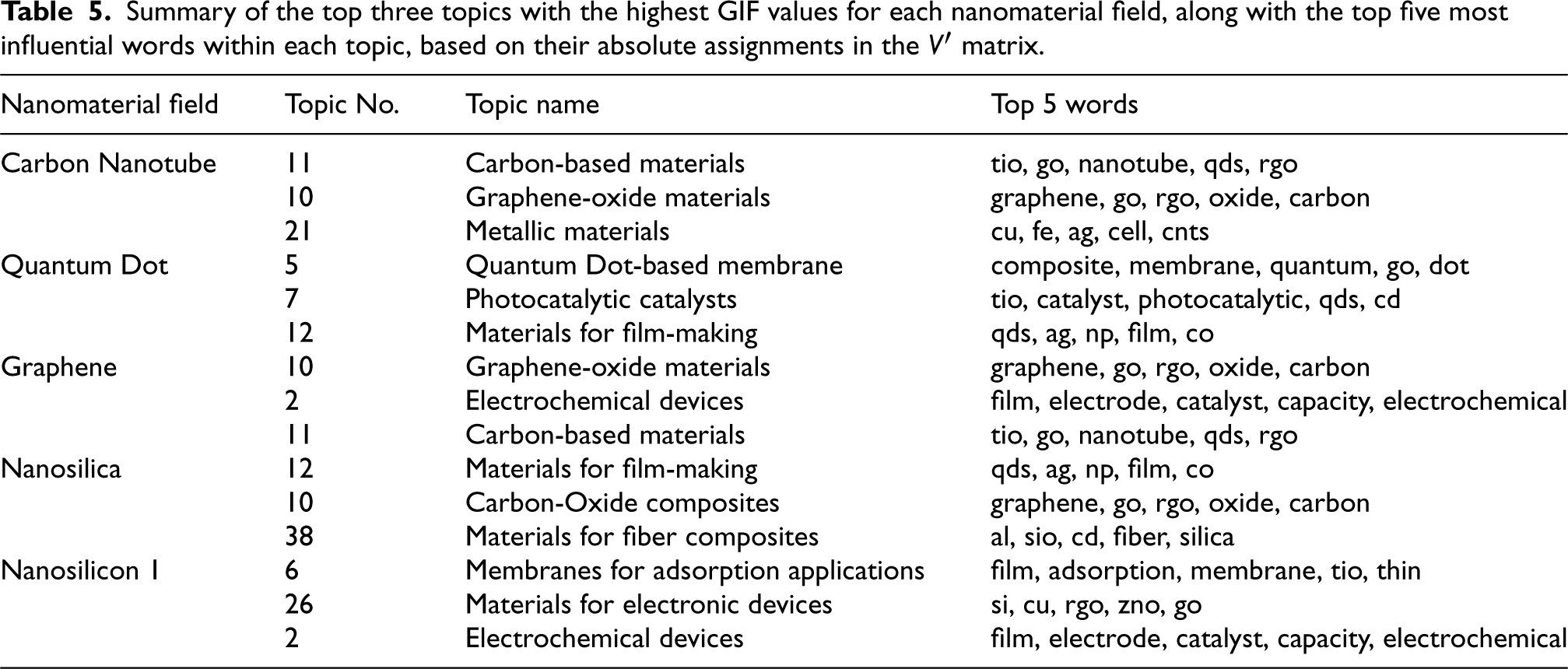
Summary of the top three topics with the highest GIF values for each nanomaterial field, along with the top five most influential words within each topic, based on their absolute assignments in the

Graphical representation of the GIF values for the top three influential topics within each nanomaterial field. Each bar’s length in the graph reflects the GIF value, illustrating the relative impact of these topics on the classification outcomes across different nanomaterial fields.
We focus on corpus-level explanations to identify which topics significantly influence the classification into five distinct nanomaterial fields based on the defined GIF values in Section 2.4. Table 5 lists the top three topics with the highest GIF values for each nanomaterial field. Additionally, it provides the names of these topics, which were manually derived from the analysis of the five most significant words associated with each topic. The significance of these words is assessed based on their absolute values in the
Carbon Nanotube
Carbon Nanotubes are cylindrical allotropes of carbon known for their unique nanostructure [95]. Renowned for their remarkable strength, high electrical conductivity, and low density, carbon nanotubes are highly valued in advanced applications such as batteries and composite materials [96,97,98]. The topics significantly influencing the classification of papers within the Carbon Nanotube field are Topics 11 (Carbon-based materials), 10 (Graphene-oxide materials), and 21 (Metallic materials).
Topic 11 predominantly covers carbon-based nanomaterials including nanotubes [95], quantum dots (qds) [99], reduced graphene oxide (rgo), and graphene oxide (go) [100]. Topic 10 is closely associated with graphene and its derivatives such as graphene oxide and reduced graphene oxide, reflecting the relevance of graphene-related research in this field [100]. Meanwhile, Topic 21 captures the classification of papers focusing on metals like copper (cu) [101], iron (fe) [102], and silver (ag) [103], known for their high electrical conductivity, alongside their interaction with carbon nanotubes [98].
Figure 3a presents the GIF values for these topics, where
Quantum Dot
Quantum dots are ultrafine semiconductor particles that are pivotal in developing display devices, offering vivid colors, longer lifespans, and greater cost-effectiveness compared to traditional LEDs and OLEDs [104]. The significant influence on the classification of Quantum Dots is chiefly guided by Topics 5 (Quantum Dot-based membranes), 7 (Photocatalytic catalysts), and 12 (Materials for film-making).
Topic 5 pertains to the use of membranes comprising quantum dot composites, essential for various nanotechnology applications. Topic 7 includes research on photocatalytic substances such as titanium dioxide (tio2), which is often abbreviated as ‘tio’ in processed texts [105], qds [106], and cadmium (cd) [107] used in photocatalytic reactions. Topic 12 deals with materials employed in the manufacturing of displays, prominently featuring qds [104], silver (ag) [103], and cobalt (co) [108].
According to Fig. 3b, the GIF values for Topics 5, 7, and 12 are
Graphene
Graphene is a two-dimensional nanomaterial comprised of a single layer of carbon atoms arranged in a hexagonal lattice, celebrated for its remarkable electrical and thermal conductivities [109]. Its versatility makes it a pivotal material in the development of advanced biocomposites for dental and medical applications [110]. The classification of Graphene-related papers is predominantly influenced by Topics 10 (Graphene-oxide materials), 2 (Electrochemical devices), and 11 (Carbon-based materials).
Topic 2 includes terms associated with electrochemical applications, underscoring its relevance to devices that capitalize on graphene’s exceptional conductive properties. Topics 10 and 11 effectively describe both Carbon Nanotubes and Graphene. This is attributed to their similar properties to carbon allotropes [95,109].
As illustrated in Fig. 3c, the GIF value for Topic 10 is
Nanosilica
Nanosilica refers to silica synthesized on the nanometer scale, which consists primarily of silicon and oxygen [111]. The classification of Nanosilica-related papers is significantly influenced by Topics 12 (Materials for film-making), 10 (Graphene-oxide materials), and 38 (Materials for fiber composites).
Topic 38, in particular, is characterized by its focus on fiber composite materials that often incorporate elements like aluminum (al) [112] and cadmium (cd) [113], demonstrating direct applications in Nanosilica technology. Notably, the term ‘sio’ within this topic represents silicon dioxide (SiO2), further emphasizing the connection to Nanosilica. This topic provides a comprehensive description of how Nanosilica is utilized within various composite materials, highlighting its widespread application.
Figure 3d presents the GIF values, with Topic 12, 10, and 38 showing values of
Nanosilicon
Nanosilicon refers to silicon at the nanoscale [114], with its properties and applications extensively explored in the realms of bio- and energy-related materials [115,116]. The classification of Nanosilicon-related papers is notably influenced by Topics 6 (Membranes for adsorption applications), 26 (Materials for electronic devices), and 2 (Electrochemical devices).
Topic 6 is particularly centered on research pertaining to advanced membrane materials that are pivotal in adsorption applications, often employing thin-film technologies. This topic’s focus reflects the innovative use of nanoscale materials in enhancing the functionality and efficiency of adsorption processes. Topic 26 delves into materials used in electronic device applications, encompassing a range of essential components such as silicon (si) [112], zinc oxide (zno) [117], cu [101], rgo, and go. The inclusion of diverse materials underscores the broad application spectrum of Nanosilicon in modern electronics.
Figure 3e illustrates the GIF values for these topics, with
Various topics related to the characteristics and applications of nanomaterials have been identified for each nanomaterial and provide insights into diverse research trends in the nanomaterial field. Carbon Nanotubes, Quantum Dots, and Graphene, which are all nanostructures primarily based on carbon [95,104,109], exemplify the versatility and wide-ranging utility of carbon in nanotechnology. Conversely, Nanosilica and Nanosilicon, which are derived from silicon [111,114], showcase the diverse applications of silicon-based materials. The shared utilization of these elemental nanomaterials across similar application domains not only underscores their comparable properties but also highlights their integral role in advancing the nanotechnology field.
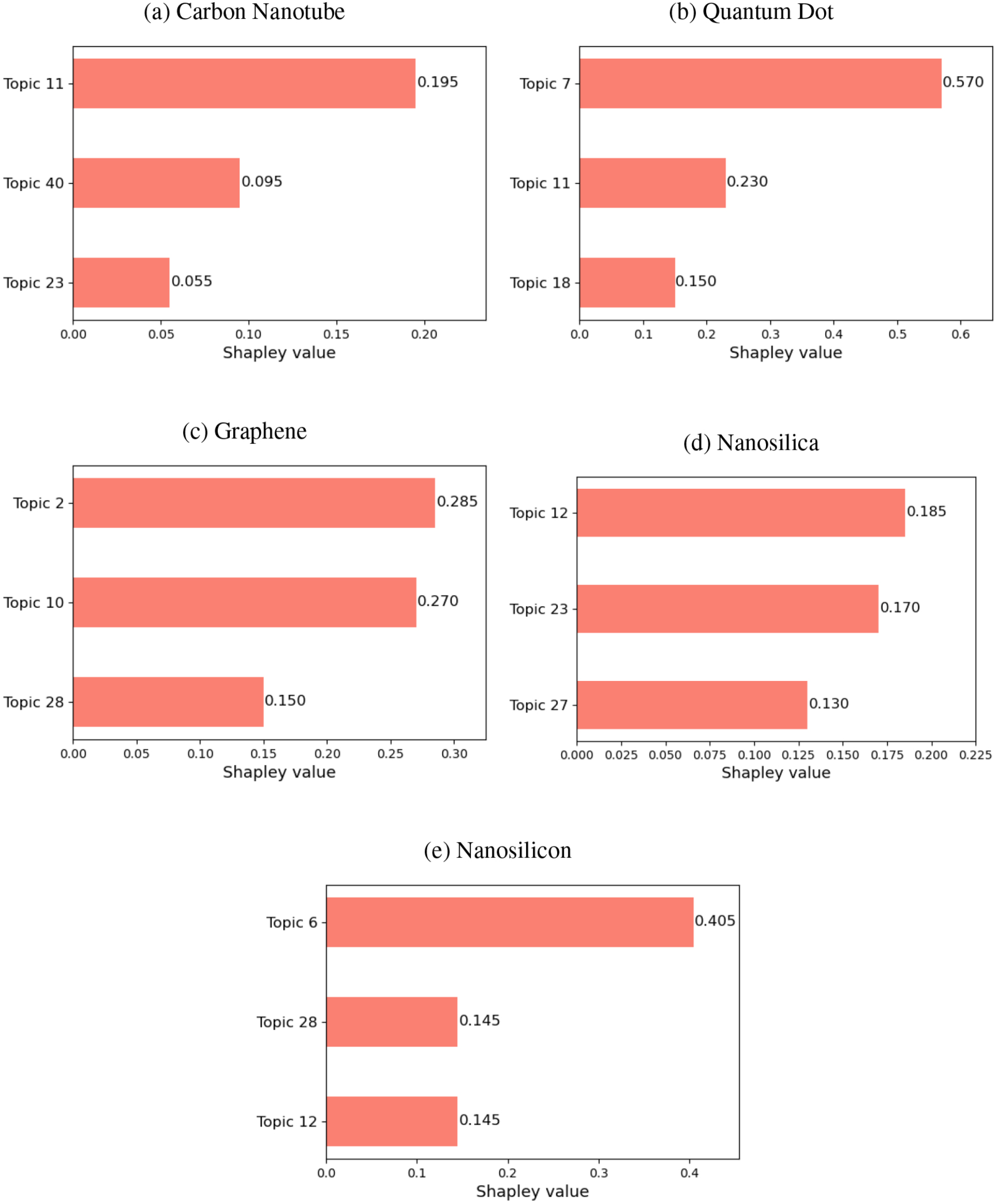
Visual representation of the top three topics with the highest Shapley values for documents classified into each nanomaterial field, used in the document-level analysis. The length of each bar in the graph correlates with the Shapley value, illustrating the relative impact of these topics on the classification of the respective documents.
Frequencies of the top five significant words for each major topic as identified in Table 5, displayed for documents within each nanomaterial field. This table supports the word-level analysis by illustrating how frequently specific terms appear in the texts, aiding in understanding their influence on the classification of the documents into their respective nanomaterial fields.

Local explanations delve into why individual documents are classified into specific nanomaterial fields, offering a granular view of the underlying classification mechanisms. For this analysis, five representative documents, one from each nanomaterial field, were selected. These documents are examined at both the document-level and word-level to pinpoint the topics and words driving their classification.
At the document level, the influence of each topic on classification is quantified by Shapley values. We identify and compare the top three topics with the highest Shapley values for each document against those with the highest GIF values as listed in Table 5. The relative influence of each topic is visually illustrated in Fig. 4, where the horizontal length of each bar correlates directly with the Shapley value, indicating the topic’s impact on the classification.
The word-level analysis focuses on the word assignments from the
Through these detailed local explanations, we aim to provide a comprehensive understanding of which topics and words decisively influence the classification outcomes, enhancing the interpretability of our classification model within the context of nanomaterials research.
Carbon Nanotube
In the document-level analysis, the Shapley values clearly indicate a strong association with Topic 11, which has a Shapley value of 0.195. This value significantly surpasses those of Topics 40 and 23, which are 0.095 and 0.055, respectively, as shown in Fig. 4a. This prominent association suggests that the document is primarily influenced by the themes encapsulated in Topic 11.
At the word-level, the document contains several keywords critical to the Carbon Nanotube field: ‘nanotube’ appears 16 times, ‘carbon’ twice, and ‘cnts’ three times. The term ‘graphene’ was mentioned once, which may indicate a comparative discussion between Carbon Nanotube and Graphene. The frequent mentions of ‘nanotube’ align well with the themes of Topic 11, reinforcing its relevance.
It becomes evident that the document is classified as relating to Carbon Nanotube primarily due to its strong thematic alignment with Topic 11, as demonstrated by both the Shapley values and the predominant occurrence of related keywords. This correlation not only highlights the document’s substantial alignment with the identified topics but also confirms the influence of specific terms like ‘nanotube’ in steering the classification towards Carbon Nanotube. Consequently, the classification is strongly justified by the combined evidence from the document- and word-level insights.
Quantum Dot
At the document-level, the analysis reveals that Topic 7 dominates with a Shapley value of 0.570, significantly higher than those for Topics 11 and 18, which are 0.230 and 0.150, respectively, as depicted in Fig. 4b. This substantial value strongly suggests that the primary influence on this document stems from Topic 7.
Word-level scrutiny shows that the document extensively uses terms directly linked to Quantum Dot, such as ‘quantum,’ ‘dot,’ and ‘qds,’ which collectively appear eight times. Additionally, the frequencies of ‘tio,’ ‘photocatalytic,’ and ‘ag’ – terms integral to the discussion on silver-doped titanium dioxide photocatalysts – further aligns the content with Topic 7. In particular, ‘tio’ appears eight times, and ‘photocatalytic’ three times, reinforcing the document’s focus on photocatalytic materials.
This comprehensive analysis indicates that the document’s classification as Quantum Dot is convincingly justified by its alignment with Topic 7, as evidenced by the high frequency of relevant terms and the substantial Shapley values. The document’s content, enriched with specific references to Quantum Dot components and applications in photocatalysis, firmly positions it within this nanomaterial field.
Graphene
In the document-level analysis, the Shapley values from Fig. 4c show that Topic 2 has a Shapley value of 0.285, closely followed by Topic 10 with a value of 0.270, indicating that the paper is significantly influenced by both topics. This near equivalence in Shapley values highlights a substantial overlap in thematic content associated with electrochemical applications and graphene materials.
Turning to the word-level analysis, the paper’s text includes multiple instances of key terms that anchor it within these topics: ‘graphene’ is mentioned three times and ‘carbon’ four times, directly pointing to its focus on Graphene. Additionally, ‘go,’ ‘rgo,’ and ‘oxide’ appear once and twice, respectively, which are terms linked to chemically oxidized forms of graphene. The words ‘electrode’ and ‘electrochemical’ are mentioned twice and three times, respectively, emphasizing the discussion on graphene’s role in electrode materials. The combination of these words aligns perfectly with the themes of both Topics 2 and 10, corroborating the Shapley value analysis. The inclusion of every keyword from Topic 10 at least once within the document underscores its strong alignment with this topic. Given the significant representation of themes and vocabulary for both Topics 2 and 10, the paper is aptly classified under Graphene.
Nanosilica
The document-level analysis indicates a strong association with Topic 38, as evidenced by the highest Shapley value of 0.185 displayed in Fig. 4d. Topic 38’s dominance is further corroborated by the word ‘sio’ and ‘silica,’ terms that are quintessential to Nanosilica, appearing a combined total of four times. The presence of ‘np’ (mentioned six times) and ‘al’ (also six times) points towards discussions related to silica’s applications in cleaning agents.
Additionally, Topic 12 shows a significant influence with a Shapley value of 0.170. Keywords from this topic, appearing five times, denote it as the second most relevant topic for this paper. This topic’s presence supports the notion that the paper covers broader aspects of silica use, likely extending beyond just cleaning applications.
Given the frequent appearance of key terms from both Topics 38 and 12 and their respective Shapley values, the paper’s classification as Nanosilica is well justified.
Nanosilicon
In the document-level analysis, Topic 6 emerges as the predominant theme, with a Shapley value of 0.405 as shown in Fig. 4e. This value is significantly higher than those assigned to other topics, indicating a strong association with Topic 6. The analysis reveals that terms pertinent to Topic 6 appear nine times within the document, emphasizing its central theme.
At the word-level, the document frequently uses ‘si,’ a direct indicator of Nanosilicon, mentioned five times. The frequent mentions of ‘film’ and ‘thin,’ appearing eight and once respectively, support the notion that the paper discusses the use of Nanosilicon in the fabrication of thin films for displays. This context is well-aligned with the focus of Topic 6, which deals with advanced materials for electronics and displays.
The comprehensive presence of specific keywords from Topic 6, combined with the dominant Shapley value, substantiates the classification of this paper as Nanosilicon. The strong thematic ties to Nanosilicon highlighted by both the document-level Shapley values and the word-level frequency analysis convincingly justify the paper’s categorization within this nanomaterial field.
Overall, we can say that papers are typically classified into specific nanomaterial fields based on the prominence of elemental symbols or abbreviations that directly represent the nanomaterial, as well as terms associated with its applications, within the abstract. This trend underscores the importance of targeted vocabulary in accurately categorizing academic papers according to their focus within the realm of nanomaterials.
In this study, we developed an explainable paper classification system integrated LSA topic modeling for embeddings, an MLP classification model, and SHAP. Our system, evaluated against four other embedding techniques and three classification models, demonstrated superior performance, achieving an F1 score of 0.7816. Enhanced interpretability was achieved through SHAP value calculations, which provided corpus, document and word level explanations of the model’s decisions, increasing both transparency and accountability.
Despite its effective classification performance and interpretability, LSA’s reliance on linear assumptions can sometimes result in oversimplifications and misinterpretations of text data. Recent advancements have favored transformer-based pretrained models like BERT for more complex text interpretation tasks. In our comparative study, the proposed LSA-MLP combination turned out to outperform BERTopic-MLP combination, confirming its efficacy in classifying nanomaterial-related literature. Additionally, while SHAP values enhance model interpretability, they depend heavily on the underlying model’s accuracy. Misinterpretations or biases in the model can distort SHAP outcomes, and their computational intensity might limit their use in real-time or large-scale applications.
The system is poised to significantly assist researchers by efficiently classifying papers, enabling them to identify current research trends and essential keywords. The use of XAI technology ensures result transparency, helps researchers understand classification criteria, and ensures reliable access to research outcomes. Moreover, visualizing the impact of specific topics or words on classifications enhances decision-making. This system’s utility extends beyond academic papers to other domains, like meeting minutes and news articles, facilitating improved information retrieval and organizational efficiency. Ultimately, it is designed to reduce researchers’ efforts, accelerating scholarly progress.
Future research will explore extending this system’s application beyond the nanomaterials domain to include broader datasets. We plan to assess its adaptability and scalability across various fields, aiming to enhance its performance and utility. Investigating improvements in handling diverse datasets and optimizing computational efficiency are key areas of interest, promising to broaden the system’s applicability and effectiveness in academic and practical applications.
Footnotes
Acknowledgments
This study was supported by the Sungshin Women’s University research grant of 2023 (H20230054).
Data availability statements
The datasets are available from the corresponding author upon request.