
Abstract
In typical cases, air traffic controllers make the schedule for arrivals and departures of aircraft on a runway based on the pre prepared schedule, where aircraft that are scheduled first are served first (a.k.a. First Come First Served – FCFS rule). In practice, it often happens that two or more aircraft are scheduled at the same time, and since only one can be served at a time, the others have to be shifted from service at a later time. Hence, the main issue stands at selecting the aircraft that have to be shifted, as, in general, their delay is correlated to excessive expense based on various factors, such as number of passengers, type of aircraft, precedence, ambient pollution, etc. For schedules with a large number of aircraft, deciding manually – which aircraft should be shifted based on FCFS sequence becomes quite complex. Consequently, in this paper, we present a genetic based algorithm to solve the problem of aircraft sequencing in a runway within a computation time of dozens of seconds by using a computing device with standard processing and memory capabilities. The results of the proposed algorithm are compared against three state of the art algorithms on existing test sets that in total consist of 527 instances. For 49.34% of instances, the proposed algorithm finds the optimal solutions, while its results are also quite competitive for difficult instances when compared against a state of the art solution based on the tabu search meta-heuristic. The computational results show that the proposed approach can be easily adapted and fine-tuned for application in practice.
Introduction
In the airports, the air traffic controller has to communicate with the pilots, in order to direct them in their process of landing or taking off. The communication between them is done through a voice or data communication channel, where the exchange of intentions, directives and other important information takes place. In the perspective of the cognitive info-communication field [1], the mode of the communication can be classified as an intra-cognitive info-communication schema, as, in both ends of the communication channel, the human actors (i.e. a pilot and an air traffic controller) are utilized. More in depth, their type of information transfer can be classified as a sensor sharing communication, since the information, obtained or experienced by the envisioned actors, is merely transferred to the other end of the communication channel. Among the others, the shared information, can be used for improving the schedule of aircraft departure/arrival in a congested runway. For example, the pilot knows the actual weight of the aircraft (including its load), which can be used by the air traffic controller as one of the factors to determine the level of importance of the aircraft, and with that an eventual priority could be granted. In addition, the pilot can inform the air traffic controller about the time he/she estimates to land or depart, or even further important information such as the state of the flight: ambulance, state flight, military flight, etc. All such information can be useful in the process of preparation of the schedule for runway usage for a certain period of time.
In general, the airport slot coordination office receives requests, for allocating time slots for arrivals or departures, from aircraft operators. Often, the time slots required by some particular aircraft operator overlap with the time slot wanted by some other operators, as depicted in Fig. 1. Consequently, it is expected that two or more requests from aircraft operators are scheduled to arrive or depart at the same time slot. In cases of airports with only one runway, it is impossible to serve two aircraft at the same slot. Furthermore, for safety reasons, the International Civil Aviation Organization (ICAO) has put in place separation rules, which require that two different aircraft, being served consecutively, need to be separated from each other by some marginal time (see Fig. 2), which, in aviation domain terms, is known as separation minima. Depending on the type of succeeding and preceding aircraft, the separation minima can have different values, e.g., in situations where two consecutive aircraft include a light and medium or a medium and heavy aircraft, then the separation minima is 2 minutes, while in situations where a light aircraft is serviced after a heavy aircraft, the separation time is increased to 3 minutes.
Aircraft sequence as per operator preferences.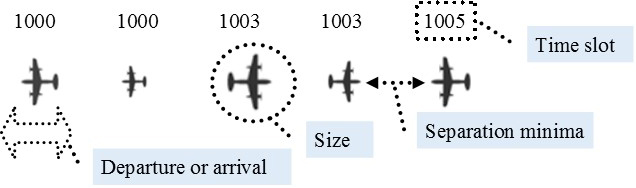
In order to comply with ICOAs rules for separation minima, the initial proposed schedule from the operators need to be adjusted. One of the most trivial methods used by the air traffic control is the First Come First Served (FCFS) sequence, where the operator that is first registered for a given time slot is the first to be served, while the others are scheduled for latter available time slots. Nonetheless, such an approach is fairly naive, as it ignores important factors, denoted as delay cost, about individual aircraft, such as number of passengers, weight, air pollution and other influencing factors. Hence, the aim is to find an optimized sequence that reschedules some of the aircraft in a way that those aircraft with smaller delay cost are shifted at later time slots for service.
Furthermore, depending on the possibility to add new aircraft into the sequence, the ASP problem is labeled as static or dynamic one. In the static case, the sequence of aircraft is generated for a longer period (usually for a whole day), where no new aircraft can be added, whereas, in the dynamic case, new aircraft can be added into the sequence at any time.
In this paper, the static case of ASP problem is considered, where the corresponding aircraft sequence includes landings as well as departures. The envisioned problem is solved with a genetic algorithm approach, where four different variants are presented. In order to test the performance of proposed variants, the computational experiments are conducted on an extended data set from the literature.
The remainder of this paper is organized as it follows: Section 2 presents the related work regarding the different algorithms existing in the literature for the aircraft sequencing problem; Section 3 depicts the mathematical formulation of the problem; Section 4 describes the proposed genetic algorithm approach; Section 5 presents the computational experiments on the state of the art test set; and finally Section 6 concludes the paper.
An early proposed formal specification of the aircraft sequencing problem (ASP), considering only arriving aircraft, is the mixed integer linear programming (MILP) model [2], which is solved by using two distinct approaches. The first approach is a deterministic one that is based on the branch and bound algorithm, whereas the second approach is non deterministic one based on genetic algorithms, which uses a neighborhood exploration mechanism consisting of a one point random crossover and a mutation operator that randomly changes a gene (aircraft landing time) within the chromosome that represents the aircraft sequence. Further, Stevens [3] designed an approach that is also based on genetic algorithms, whilst imposing constraints and conditions arising from practical situations in regard to constantly changing conditions of aircraft landings.
Aircraft sequence when considering separation minima.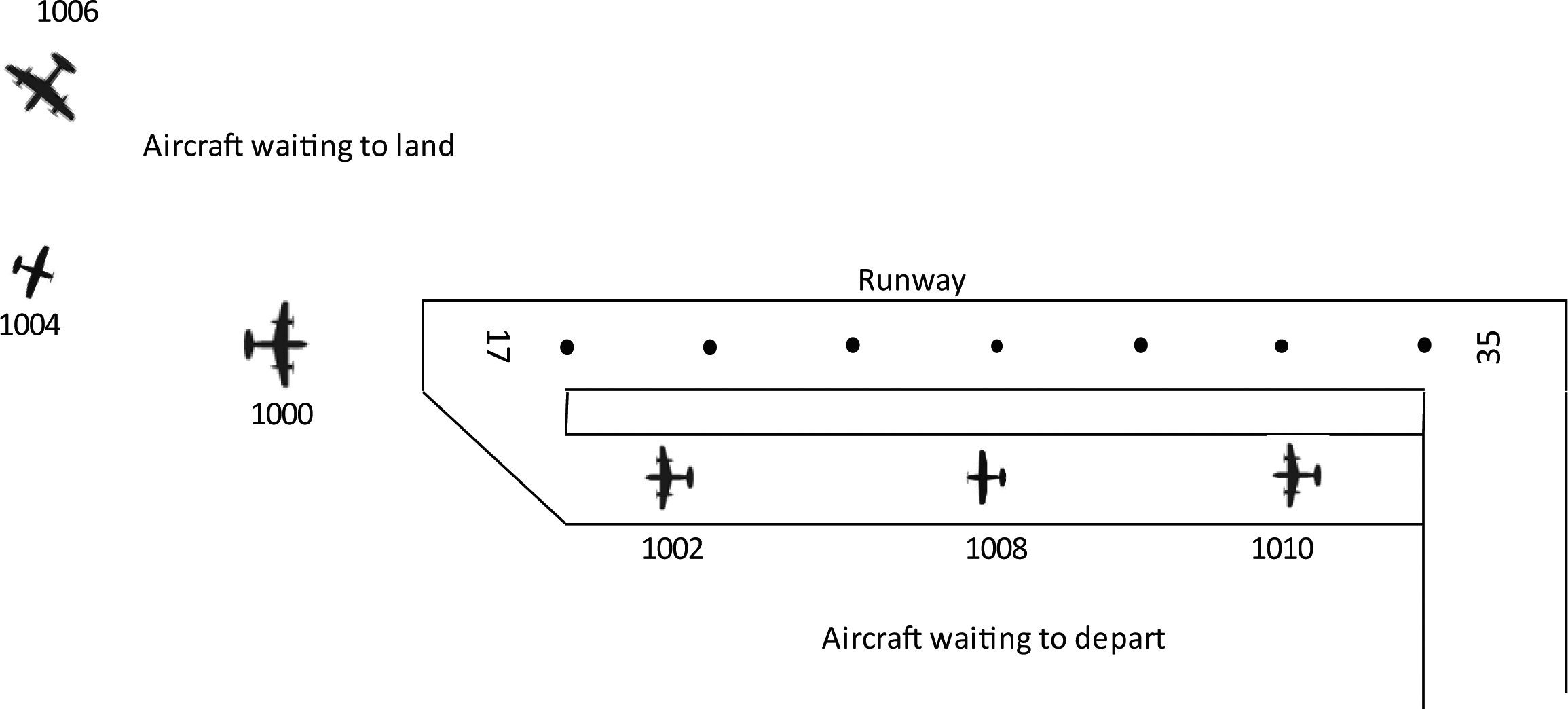
Ciesielski and Scerri [4] developed a genetic algorithm for the ASP problem that employed specialized crossover and mutation operators for favoring selected members of the population. The proposed approach was evaluated against a real data sets originating from Sydney Airport.
Beasley et al. [5] formulated the static case of an ASP problem for single and multiple runways by using a MILP model, which employs constraints that arise as limitations from real life (e.g. precedence, restricting the number of landings, etc.) [6]. Further, authors solve the problem to optimality by using a tree search approach based on linear programming, and present a heuristic algorithm for speeding up the search process.
Caprì and Ignaccolo [7] are the first to combine arrivals and departures into a single aircraft sequence within ASP, where they propose a genetic algorithm solution that utilizes two specialized crossover operators and a modified mutation mechanism. One of the crossover operators operates only on some genes, which are chosen randomly, while the other operator does the opposite procedure, by fixing some genes and operating with the others. The mutation mechanism, instead of producing a random change in a chromosome, produces a random swap between two genes on a chromosome.
Pinol and Beasley [8] consider the multiple runway case of the static Aircraft Landing Problem, where they present two population based heuristic approaches namely, Scatter Search and the Bionomic Algorithm.
Atkin et al. [9] propose four metaheuristic approaches for scheduling aircraft departures at London Heathrow airport that consists of two runways. All proposed metaheuristics, which include first descent, simulated annealing, steeper descent and tabu search, have similar neighborhood designed that is made of three operators, namely, swap single aircraft, shift aircraft and randomize a set of aircraft.
Hu and Chen [10] consider only arrivals in the ASP sequence and solve the problem by using a Receding Horizon Control (RHC) genetic algorithm. The introduction of the RHC strategy into the genetic algorithm has the function of speeding up the optimization process, by optimizing the aircraft arrival sequence only for N time slots ahead. At each time slot, the actual information on disposal is evaluated, and based on that, the optimized arrival sequence is generated for N time slots in the near future.
Likewise, Hu and Di Paolo [11] consider only arrivals in the ASP sequence and propose a binary genetic algorithm that is based on a binary representation instead of earlier permutation based solutions. The resulting representation is a binary matrix that enables employing a uniform crossover operator, which wouldn’t be feasible in earlier permutation based representations. Further, the strategy of RHC algorithm is also integrated into the proposed solution with the aim of allowing dynamic sequencing of aircraft arrivals. Later, Hu and Di Paolo [12] extend their genetic algorithm approach, based on the described uniform crossover, to be used for scheduling arriving aircraft in airports with multi runways.
In addition, Hu and Di Paolo [13] further modify their approach for sequencing aircraft arrivals by introducing the phenomenon of ripple-spreading on liquid surfaces into the genetic algorithms. In this approach, the original one dimensional aircraft sequence is projected into a two dimensional space, where aircraft, presented as points, are linked between each other by using a deterministic approach based on the ripple-spreading strategy.
More recently, Furini et al. [14, 15, 16] formulate the ASP problem for real scenario situations, where airports have single runways, which are used for both arrivals and departures. The problem was formalized using the Mixed Integer Linear Programming (MILP) model, and it was initially solved by using a rolling horizon algorithm (RHA) [13], which is then advanced to an iterative rolling horizon algorithm (IRHA) [15] that featured elements from the tabu search algorithm. The results obtained by RHA algorithm were compared against the results of First Come First Served (FCFS) rule, where it was evidenced that, for a data set of 12 realistic scenarios generated instances, an improvement of around 15% can be made over the sequences produced by the FCFS rule.
In the IRHA algorithm [15], the aircraft sequence is divided into smaller parts (chunks), which are then solved individually. Further, different methods are proposed for the chunk generation with a fixed number of aircraft, where individual methods are guided based on a number of predefined algorithm parameters, such as fixed cardinality, time gap and weight gap. The tabu search algorithm is used to enable escaping from local optima, whilst the neighborhood of the running solution is generated by using either the shift operator, which shifts an aircraft into the sequence, or swap operator, which swaps two aircraft in the sequence. The IRHA algorithm obtained much better results in comparison to the previous RHA algorithm, where the average improvement for the same data set is around 14%.
Furini et al. [15] also developed a dynamic programming approach for the ASP problem where they enforce the constraint for aircraft position shifting. This approach uses heuristic based upper bounds and a completion-lower bound mechanism for reducing the state space. The presented experimental results on real traffic data show that the presented algorithm outperforms the prior state of the art approach, which is based on a MILP model.
Just recently, an ongoing work in [17] has presented an Iterated Local Search based algorithm for aircraft sequencing, where, both arrivals and departures are considered. The algorithm uses a neighborhood exploration mechanism based on two operators, where the first one swaps any two fights in the sequence, whereas the second one shifts a given flight in some other position within the same sequence.
By analyzing the existing literature, we conclude that the version of ASP problem that considers both, arrivals and departures, is not intensively explored in terms of application of the genetic algorithm approaches. Nevertheless, Caprì and Ignaccolo [7] tackle the ASP problem with a genetic algorithm approach, but they present a computational study with a limited data set that includes only four instances with a maximum of forty aircrafts. Therefore, in this paper, we propose an extended genetic algorithm solution to the ASP problem, which, based on the technique used for updating the population, is presented in four different variants, namely generational, steady state, elitism and direct reproduction. Compared with the existing literature, this work can be distinguished with three main contributions: (1) presentation of four different variants of solutions to the ASP problem based on genetic algorithms; (2) introduction of a unique two point crossover that can be fine-tuned based on two parameters; (3) an intensive experimentation with the state of the art algorithms that show the effectiveness of the proposed solution on benchmark data sets from the literature.
In the variant of aircraft sequencing problem (ASP) that encompasses departures and arrivals, a set of
In the literature, there are two different MILP formulations for the ASP problem, where the first one was presented by Beasley et al. [5], and the second one was presented by Furini et al. [14]. These two mathematical formulations differ in the way they use the decision variables. Beasley et al. [5] use a decision variable to model the relative order between any two aircraft, whereas Furini et al. [14] use a decision variable for each aircraft, which models its position in the sequence. In the following, we present a mathematical formulation that is based on the model of Beasley et al. [5], which is defined by using two decision variables, namely
where:
The objective function of the problem is represented by Eq. (1), which aims at minimizing the overall time unit delay of the complete sequence of the scheduled aircraft that include both, the departing and the arriving ones. Constraint (2) sets the time frame limits for rescheduling individual aircraft, which should be obeyed when they get reassigned in a particular time slot either for departure or arrival. Constraint (3) ensures that all aircraft are assigned a time slot for departure/arrival in the sequence. Constraints (4) and (5) together ensure that individual aircraft are assigned only once throughout the sequence. Constraint (6) defines the minimum separation time between consecutive aircraft that should be maintained, in order to avoid any interference between them. Finally, constraint (7) defines the scope of the values for the decision variable
In air traffic control industry, the process of sequencing the arrivals and departures of the aircraft should be done in a matter of few seconds. Therefore, local search based metaheuristic techniques are utilized for solving the ASP problem. In this paper, the approach to solve the ASP problem is based on the framework of the Genetic Algorithm (GA), which is invented by Holland [18] and it is inspired by the genetics of living beings. The GA algorithm, at the beginning, constructs an initial random population, which then undergoes three generic procedures that are repeated for a number of times (generations). In the first procedure, each individual of the population is evaluated, whereas, in the second procedure, based on this evaluation, a number of individuals (parents) from the current generation are selected to form a group of children that are candidates to join the new generation of the population. The third procedure joins the parents and the newly formed children to create a new generation of the population, and then the GA algorithm restarts a new cycle from the first procedure.
Representation and initialization
An individual member (candidate solution)
In a typical instance of an ASP problem, all aircraft are sorted, in ascending order, based on their departure/arrival time, where some of the aircraft might happen to have the same scheduled departure/arrival time. In this approach, the initialization of an individual member
Crossover operator.
Within the first procedure of GA algorithm, the members of the population get evaluated using only the “sum part” of Constraint [1] (i.e. without the objective of minimization). Whereas, the second procedure makes the process of the selection of some of the members from the population, who would take part in breeding new population for the next generation. The selection process is based on the tournament selection procedure, as shown in the following pseudo-code, which is quite straightforward and self-descriptive [19].
Genetic operators
The genetic operators comprise a unique crossover operator that is applied between two selected population members, and a mutation operator that mutates the children that are generated by the crossover operator.
Crossover
The proposed crossover operator (see Fig. 1) makes a recombination between any two selected members (parents)
Mutation
The mutate operator swaps any two randomly selected aircraft in a given sequence that is represented by a population member (child)
In regard to defeating the infeasibility, only the constraint about the time frame limit need to be checked for the aircraft that are involved in the swap operation and the subsequent aircraft in the sequence. Still, the procedure for regulating the separation minima is the same as in the case of crossover operator.
Genetic algorithm
The implemented genetic algorithm can be qualified as generative in its nature, as the respective population is updated entirely at each generation. As presented in Algorithm 3, the approach at hand, besides the usual GA parameters, such as population size, maximum generations and tournament size, also uses some unique arguments, namely crossover wideness threshold(cwt), mutate distance threshold (mdt), crossover wideness percentage list (cwpl) and mutate distance percentage list (mdpl). All these parameters serve as a means to control the upper bound values for the arguments of the crossover operator (i.e. the parameter of crossover maximal difference and crossover window width) and mutation operator (i.e. the parameter of mutate maximal distance), respectively.
After creating the initial population that consists of ps individuals (solutions), the algorithm enters into a loop, which defines the number of generations that the algorithm will undergo, as specified by the maximum generations parameter. At each generation, the individuals in the population are assessed, and in case a particular individual shows that it is better than the best solution found so far, that individual is accepted as the new best found solution. Further, the values of the crossover maximal difference, crossover window width and mutate maximal distance parameters are reset randomly within the range that is described in Algorithm 3 (see lines 18 to 22). Next, until an entirely new population is created, at each run of the inner loop (see line 24), two individual
Exploitative variations
The generative approach of the GA algorithm, described in Subsection 4.4, has more explorative attributes than exploitative ones, as its population is renewed entirely in each generation, hence making the algorithm more explorative in different regions of the search space. In order to create some exploitative variants of the algorithm, we have developed three additional approaches, namely elitism, steady-state and direct reproduction, which, in turn, are discussed more in details in the following.
Elitism
In the elitism version of GA algorithm, an additional parameter, namely the percentage of elite individuals (pei), is used to determine what portion of the elite (best fit) individuals from the current population will go directly into the population of the next generation. These elite individuals will make the algorithm exploit the neighborhood around them more in depth, hence making it more exploitative.
In order to select the portion of best fit individuals, at each generation, after the process of the evaluation of the population members, it is necessary to sort the members of the population based on the quality of the solutions they represent, which, in this implementation, is done by using the quick sort algorithm. Further, at the process of the selection, in case a number of individuals has the same evaluation and in the same time compete to enter the portion of best fit individuals, the resolution is made by randomly selecting individuals of the same quality, until the predefined elite quota is attained.
Details about the flights in the simulation days
Details about the flights in the simulation days
In the steady state approach [20], the population of the algorithm is updated in a piecemeal mode, rather than updating it in its entirety. In comparison to generational approach, the steady state approach uses an additional parameter, namely the percentage of individuals to replace (pir), which defines what portion of the population will be renewed in the next population. The lower the value of this parameter is, the steadier the population will be, thus enabling the algorithm to be more exploitative around individuals that remain for longer generations into the population.
At each generation, a percentage of individuals, as specified by the respective parameter, will be randomly removed from the current population, in order to make room for the new individuals, which will be breaded based on the earlier described procedure for the processes of selection and crossover.
The variant with a direct reproduction structure
In this approach, we apply a special breading technique for genetic algorithms, proposed by Koza [21] when developing a tree style based genetic programming approach. The envisioned method uses an additional parameter, named probability of performing direct reproduction (ppdr), to determine the chance that individuals have to go directly into the next generation, without undergoing the regular processes of selection and crossover. This makes the algorithm highly exploitative [19], as several individuals of the current population will again show up in the next population.
In individual generations, after selection of the parents and before applying the crossover procedure, a particular number is generated randomly. If the generated number is smaller than the value of the parameter for performing direct reproduction, then the first selected parent is passed directly to the next population, otherwise the regular procedure for the crossover (using both parents) is applied to bread two new children that will get into the next population.
Computational experiments
In this section, the experimental results that are completed using the state of the art instances are presented. At first, a description of the different sets of instances that are used for experimentation is given, and then, the computational results are given for each set of instances, as well as the results for the best case scenario for some difficult instances.
The algorithm is developed by using the C# programming language through the developing environment of MS Visual Studio 2012. The experiments are completed by using an Intel i3 3.3 GHz processor with 1 GB of RAM memory in Windows Server 2008 operating system.
Test set details
Test set details
In order to make an empirical study against the state of the art solutions, in the following experiments, we use the test set for the ASP problem that was created by Furini et al. [14, 16], with the purpose of testing RHA and IRHA approaches. The test set originates from the commercial air traffic schedule at Milano Linate Airport, which is the largest airport in Italy, consisting of two runways, although only one of them is used for commercial traffic. The test instances are created based on two simulation days, as shown in Table 1.
With the aim of making more congested air traffic schedules, Furini et al. [16] merged both simulation days into one. Since the 48 flights operating in both simulation days are not duplicated, the resulting congested schedule has a total of 173 flights, with 94 and 79 arrivals and departures, respectively.
A particular instance contains information about a number of scheduled flights within a period of time, where each flight is described with information such as: name, type of aircraft (e.g. Airbus A321, Boeing B737-800, etc.), size of aircraft (Light-L, Medium-M or Heavy-H), type of flight (Departure-D or Arrival-A), scheduled time, and weight of flight, which corresponds to the cost of time unit delay
The calculation of the minimum separation distance
As specified in Table 2, the test set consist of three subsets, named A, B and C, which are all generated by combining the instances from the two simulation days taken from Milan Linate Airport. Set A consists of instances with 60 flights that are scheduled within a period of about 2.5 hours until 3.5 hours, whereas Set B consists of instances with a smaller number of flights (15–24) that are scheduled to be served in period that varies from 20 minutes to approximately one hour. Set C consist of instances with larger number of flights (70–150), with a scheduling period that varies from about 2 hours until 5 hours. Due to the smaller number of flights, Set B is considered to be more easily solvable, whereas because of the large number of flights, Set A and Set C are more difficult to be solved, and this is especially the case with Set C. A more detailed description of the Set A can be found in [14], whereas Set B and Set C are described more in depth in the other paper of Furini et al. [16].
Results for Set A – score gap (%)
Results for Set A – computation time (seconds)
The results are computed for each of the four variants of the genetic algorithm presented in the previous section, which, in the following, will be referred using the subsequent abbreviations: E (
The Mixed Integer Linear Programming (MILP) model, which was presented by Beasley et al. [5], but it was solved by Furini et al. [16] using CPLEX 12.5 (with default parameter settings), hereinafter referred as Model A, The Rolling Horizon Algorithm [14] (tested only using Set A), which is executed on an Pentium 4 processor with 3.00 GHz and 1 GB RAM under Linux operating system, hereinafter referred as RHA, The Iterative Rolling Horizon Algorithm [16], which is executed on an Intel(R) Core(TM) 2 Duo processor with 3.2 GHz and 2 GB RAM under Linux operating system, hereinafter referred as IRHA.
The results of the Model A are used as benchmarks when calculating the average gap of the four variants of GA presented in this paper.
Note that in order to be able to compare the results of the proposed approaches versus state of the art approaches [14, 16], the partial constraint about the allowable time unit delay required for a particular flight (see Constraint (2) in Section 3) is not enforced, hence enabling the flights to be assigned at any time that is equal or later than the initial scheduled time.
In each experiment, every instance of a particular set is executed for 20 times, where respective minimal, maximal and average values are outlined for both, the quality of solution and the computation time.
Based on the preliminary experiments with a selected number of instances from different test sets, the values of the algorithm parameter are fine-tuned, and read as it follows: ps
Results for Set B – score gap (%)
Results for Set B – computation time (seconds)
The instances in Set A were solved to optimality by Model A [16], therefore the corresponding results are used as benchmark for compering the results of the different variants of the genetic algorithm proposed in this paper. Further, the optimal results of the IRHA approach for Set A are computed by Furini et al. [16] with a computation time of 120 seconds, expect for instance “FPT12”, whose results are generated only for 40 seconds.
In Table 3, the results, expressed in percentage gap against Model A, of the two state of the art solutions (denoted as RHA and IRHA) are presented, along with the results of the four proposed variants of GA (denoted as E, G, SS and DR). From Table 3, it is evident that, on average, all four variants of the GA algorithm outperform the state of the art algorithms (denoted as RHA and IRHA), as their average margin against the optimal solutions (obtained by Model A) is lower than 1%, as opposed to RHA and IRHA algorithms, whose score gap margin is 16.36% and 2%, respectively. In between the variants of the GA algorithm itself, the generational approach (G), in average, produces better results than the other three approaches with an advantage, in terms of score gap, of slightly more than 0.05%.
Results for Set C – score gap (%)
Results for Set C – score gap (%)
Results for Set C – computation time (seconds)
Best results for Set A and Set C
In terms of computation time, due to differences in the capacities of machines used, no direct comparison can be made against the state of the art algorithms. Nevertheless, when comparing the different variety of GA (see Table 4), the variant with Direct Reproduction (DR) approach is approximately as twice as fast as the Generational (G) approach, and around 50% faster than the remaining two approaches, although this goes at the cost of a slight decrease in the side of the quality of the solutions obtained. The speed of the DR variant can be reasoned when considering the process of the population update, which, in the case of DR variant, occurs much rarely. On the other hand, the generational (E) variation is much slower due to the need for a complete population updated in every single generation.
Table 5 shows the experimental results of the four variants of the GA algorithm along with the results the IRHA algorithm, which are averaged over the subsets of instances that contain equal number of flights. The benchmark results of Model A and IRHA approach were computed by Furini et al. [16] by imposing a time limit of 15 seconds.
In terms of quality of solutions, the averaged figures in Table 5 show that, for Set B, the generative (G) variant of the proposed algorithm equals the results obtained by IRHA algorithm, while the other three variants of the GA algorithm remain slightly behind the results that are obtained by IRHA algorithm, with the direct reproduction (DR) variant having the largest score gap of 18.31% against the lower bound values obtained by Model A. All GA algorithm variants find the lower bound solutions for 49.6% of instances (i.e. 248 out of 500), except for DR variant, which finds 48.4% of the lower bound solutions in the same instance set (i.e. 242 out of 500). These results prove that the proposed GA algorithm variants are competitive to the IRHA algorithm for the Set B of instances.
Table 6 shows the computation time of the four variants of GA, where results are averaged over the instances that have the same number of flights. As it can be seen in Table 6, the steady state (SS) variant, with an average running time of less than half of the second, is the fastest, whereas the elitism (E) variant, with an average running time of 1.34 s, is the slowest. This longer computation time required by the elitism (E) variant can be reasoned due to the need for sorting the population members in each generation.
Results for Set C
Table 7 presents the results for Set C of all variants of GA algorithm and also the IRHA approach, which are shown in the form of percentage score gap versus the lower bound values obtained by Model A, where the results are computed by Furini et al. [16] using CPLEX by imposing a time limit of 5 hours.
It could be seen that, on average, all four variants of the GA algorithm outperform IRHA approach by a margin of around 7.6%. In this test set, the best performing variants of the GA algorithm are the elitism (E) and direct reproduction (DR) variants, which, in terms of quality of solutions, have an average score gap against the lower bound values of 79.72%, as opposed to other two variants, whose score gap stands at 79.76%.
Results of best case scenario for difficult instances
Since Set A and Set C of instances have many more flights in their schedules than Set B of instances, the level of difficulty in solving an instance from Set A or Set C is much higher than solving an instance from Set B [16].
In Table 9, we present the best results obtained for these two test sets, where the best results for the state of the art approaches (i.e. Model A and IRHA) are presented, along with the results for the respective variants of the GA algorithm and their comparison versus the state of the art algorithms. The results show that the GA algorithm finds the lower bound solutions for 44.44% instances (12 out of 27 instances), whereas for 100% of instances, it is either better (48.15%) or equal (51.85%) than the IRHA algorithm. When the results are averaged over these two difficult sets of instances, the quality of the solutions obtained by the GA algorithm is better than the quality obtained by the IRHA algorithm for 8.88%. If the results of different instances among the different variants of the GA algorithm are compared, it can be noticed that the generational (G) variant has managed to find either the lower bound solution or the best found solution among all variants, for instances with up to 110 aircraft, whereas for instances with 130 and 150 aircraft, there are the elitism (E) and direct reproduction (DR) variants the ones that dominate.
Conclusion and future work
This paper deals with the aircraft sequencing problem, which has to do with making the sequence of arrivals and departures of the aircraft in a distinct runway of a given airport. An optimized scheduled sequence is aimed at minimizing the delays of individual aircraft in the sequence subject to a predefined number of hard constraints that might be applicable in the domain of aircraft sequencing. The paper at hand, considers hard constraints such as the minimal separation time between aircraft, disallowing aircraft assignments before their scheduled time and allowing no possibility for two particular aircraft to be assigned at the same time.
Being grounded on the procedure for updating the population, four different variants of genetic algorithm, namely elitism, generational, steady state and direct reproduction, are designed to solve the ASP problem efficiently for the state of the art instances. Within a computation time of one minute or less, high quality solutions are found in the three sets of test instances. The comparison results versus the state of the art IRHA algorithm show an average improvement of around 1.3% and 7.6% for the most difficult sets A and C, respectively, whereas an equivalent score gap is achieved for easier instances that are part of Set B. For all three sets, with a total of 527 instances, the lower bound (LB) solutions were found in 49.34% of them.
Based on the presented experimental results, we conclude that on congested airport runways, in situations where all flight information is known beforehand (i.e. the static case of aircraft sequencing), the proposed algorithm can be used to implement practical applications to assist air traffic controllers in making runway operation schedules, for both, arrivals and departures of aircraft. As future work, it might be interesting to investigate the fine tuning of the algorithm parameters, in order to come with a version of the algorithm that has a faster computation time, even though this might lead to a slight reduction in terms of quality of obtained solutions. A faster computation time might be needed in situations where dynamic re-scheduling is required to cope with changes that often arise due to different causes (e.g. weather conditions, emergency landing, congested air traffic, etc.).
The solution to the problem at hand is searched only in the feasible part of the search space, hence, as a future work, it would be worth investigating the possibility to allow the algorithm to also move around the infeasible part of the search space by applying the so called strategic oscillation mechanism proposed by [22].
Footnotes
Acknowledgments
The authors would like to thank prof. Dr. Bujar Krasniqi for proof reading this paper. Further, we would like to thank two anonymous reviewer for their valuable feedback, which helped improve the correctness and readability of the paper.